深度学习中实验、观察与思考的方法与技巧
在深度学习中,实验、观察与思考是理解和改进模型性能的关键环节。以下是一些有效的方法与技巧,可以帮助你在深度学习实践中系统性地开展实验、分析结果并进行深入思考:
1. 明确实验目标
在开始实验前,确保对实验的目标有清晰的定义:
- 你是要优化模型的准确率、减少计算资源,还是探索新技术的有效性?
- 实验假设是否明确?例如,“增加卷积层会提升图像分类精度”。
技巧:
- 在实验日志中记录每次实验的目标、假设和期望结果,以便后续对比和总结。
2. 逐步修改,控制变量
深度学习模型通常包含大量超参数(如学习率、网络深度、激活函数等),为了有效进行实验,最好一次只修改一个变量:
- 控制变量法:一次只改变一个参数(如学习率或层数),这样可以确定具体的改动对模型性能的影响。
- 实验分组:设立一个基准模型(baseline),并在基准上逐步进行调整。每个实验都要记录改动的参数和结果,以便进行对比分析。
技巧:
- 使用不同参数的组合并行进行多次实验,这样可以提高实验效率。例如使用网格搜索或随机搜索方法。
3. 观察并记录重要指标
在训练和测试过程中,持续观察模型的关键性能指标,如:
- 训练损失:表明模型在训练集上的表现。持续下降说明模型在学习。
- 验证损失与准确率:验证集的表现能反映模型的泛化能力。观察是否出现过拟合(验证损失上升、训练损失下降)。
- 混淆矩阵:用于分类问题,可以分析模型在哪些类别上表现较差。
技巧:
- 定期绘制损失曲线和准确率曲线,通过图表来判断模型训练的动态变化。
4. 学习率与训练过程
- 学习率的调整:学习率决定了梯度下降的步长。太大会导致训练不稳定,太小则收敛缓慢。
- 常用的策略是使用学习率调度器(如学习率衰减、余弦退火等)或动态调整学习率(如 Adam)。
技巧:
- 通过绘制损失曲线观察训练过程,如果损失在大部分时间波动很大,可能需要降低学习率。如果收敛太慢,尝试提高学习率。
- 使用 learning rate finder 方法,在开始训练前通过实验寻找最佳学习率。
5. 调优超参数
调整超参数是实验中的关键步骤,常见的超参数有:
- 学习率、批次大小:小批量(mini-batch)训练会对噪声更为鲁棒,但批次太小可能导致不稳定。
- 网络深度和宽度:调整网络层数和每层神经元数量,观察模型容量对性能的影响。
- 正则化参数:Dropout 率、L2 正则化等可以避免过拟合,但也可能削弱模型的表达能力。
技巧:
- 采用 随机搜索 或 贝叶斯优化 等自动化调参技术,在大量实验中找到超参数的最佳组合。
6. 验证模型的泛化能力
仅在训练集上表现良好的模型可能无法泛化到新的数据集,因此要验证模型的泛化能力:
- 使用 验证集 或 交叉验证 来测试模型在未见过的数据上的表现。
- 观察验证集的损失是否与训练集同步下降,以及验证集的准确率是否随着训练集的过拟合而下降。
技巧:
- 定期在验证集上进行评估,不要等训练结束后才进行验证。
- 使用 K 折交叉验证 方法,确保模型泛化到不同的数据子集。
7. 实验日志与数据管理
在深度学习实验中,管理多个实验版本非常重要:
- 实验日志:记录每次实验的超参数配置、模型架构、数据集、结果和思考,方便日后回顾。
- 版本控制:使用 Git 或者其他代码版本管理工具,记录代码和模型的不同版本变化。
- 数据记录:在多次实验中要确保使用相同的数据集分割方式,否则会因为数据差异导致结果不一致。
技巧:
- 使用自动化工具(如 Weights & Biases、TensorBoard)来可视化和记录训练过程中的关键数据。
8. 诊断模型表现
深度学习模型的训练可能遇到一些常见问题,学会通过观察数据来诊断问题:
- 过拟合:训练集损失持续下降,验证集损失上升。可尝试减少网络复杂度、增加正则化。
- 欠拟合:训练集损失高且无法下降,说明模型容量不足。可尝试增加层数、调整学习率或使用更复杂的模型。
- 梯度消失或爆炸:训练过程中梯度无法有效更新。可使用更好的初始化方法、适当的激活函数(如 ReLU)或梯度剪切技术。
技巧:
- 学会观察梯度和权重的变化,通过可视化工具(如 TensorBoard)监控训练中梯度和损失的动态。
9. 持续思考与总结
在实验过程中,思考每次实验的结果:
- 哪些改动导致了模型性能提升或下降?与预期一致吗?背后原因是什么?
- 哪些超参数对结果影响最大?哪些对模型收敛最为敏感?
- 通过实践中遇到的问题来学习新的知识,比如当遇到过拟合问题时,思考如何在类似任务中解决该问题。
技巧:
- 每次实验后进行复盘,记录思考过程,逐步积累自己的经验库。
- 关注领域内的前沿研究,借鉴其他研究者的思路和方法。
10. 与他人讨论和交流
参与深度学习社区的讨论,或与团队成员分享你的实验结果:
- 在 GitHub、Kaggle 等平台上分享你的代码和思路,吸取他人的反馈和建议。
- 参与相关的研究或比赛,了解别人是如何优化模型的,这可以拓展你的思路和实践技巧。
通过这些方法,你可以在深度学习实验中有条不紊地推进,从而加深对深度学习原理的理解,并通过不断的实践、观察和思考,逐步提升模型性能和你的技术水平。
相关文章:

深度学习中实验、观察与思考的方法与技巧
在深度学习中,实验、观察与思考是理解和改进模型性能的关键环节。以下是一些有效的方法与技巧,可以帮助你在深度学习实践中系统性地开展实验、分析结果并进行深入思考: 1. 明确实验目标 在开始实验前,确保对实验的目标有清晰的定…...
记一次 FastDFS 存储节点迁移:基于 scp 的实践与经验分享
一、背景 某某项目,机房到期,需要迁移至其他机房; 此项目已经运行了3年多,fastdfs累计数据大概在250G 左右,现需要把旧的fastdfs数据迁移到新的fastdfs上; 采用scp物理迁移数据的方式,停机迁移…...

http连接github远程仓库密码问题解决办法
目录 一、问题:使用http连接失败 二、解决办法:使用个人访问令牌。 1、生成访问令牌: 步骤 1: 登录 GitHub 步骤 2: 进入设置页面 步骤 3: 生成新的访问令牌 步骤 4: 配置访问令牌 步骤 5: 复制令牌 2. 使用访问令牌 一、问题&#…...

LAMP环境下项目部署
目录 目录 1、创建一台虚拟机 centos 源的配置 备份源 修改源 重新加载缓存 安装软件 2、关闭防火墙和selinux 查看防火墙状态 关闭防火墙 查看SELinux的状态 临时关闭SELinux 永久关闭SELinux:编辑SELinux的配置文件 配置文件的修改内容 3、检查系统…...

Visual Studio 2022从外部引入dll导致的问题
这里以我学MapGIS二次开发的一个小demo为例 一、如何引入dll 1、在解决方案资源管理器中,有个引用的选项 2、然后右键点击添加引用 点击之后会出现如下: 3、点击浏览选项,选择想要引入dll的路径,这里我选择下载MapGIS 10的路径 …...

大模型从失败中学习 —— 微调大模型以提升Agent性能
人工智能咨询培训老师叶梓 转载标明出处 以往的研究在微调LLMs作为Agent时,通常只使用成功的交互轨迹,而丢弃了未完成任务的轨迹。这不仅造成了数据和资源的浪费,也可能限制了微调过程中可能的优化路径。论文《Learning From Failure: Integ…...

10.web应用体系以及windows网络常见操作应用
一、Dos命令 1.启动方式:winR,输入cmd 2.切换盘符/路径:盘符名称: (C:) cd 目录 (cd B111)(目录名按table键自动补全) 3.查看目录:dir dir /p 分页展示目录及…...
【数据结构与算法 | 灵神题单 | 前后指针(链表)篇】力扣19, 61,1721
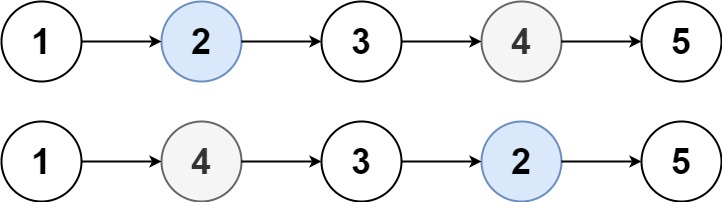
1. 力扣19:删除链表的倒数第N个节点 1.1 题目: 给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。 示例 1: 输入:head [1,2,3,4,5], n 2 输出:[1,2,3,5]示例 2: …...

机器学习之实战篇——MNIST手写数字0~9识别(全连接神经网络模型)
机器学习之实战篇——Mnist手写数字0~9识别(全连接神经网络模型) 文章传送MNIST数据集介绍:实验过程实验环境导入模块导入MNIST数据集创建神经网络模型进行训练,测试,评估模型优化 文章传送 机器学习之监督学习&#…...

ICLR2024: 大视觉语言模型中对象幻觉的分析和缓解
https://arxiv.org/pdf/2310.00754 https://github.com/YiyangZhou/LURE 背景 对象幻觉:生成包含图像中实际不存在的对象的描述 早期的工作试图通过跨不同模式执行细粒度对齐(Biten et al.,2022)或通过数据增强减少对象共现模…...

数据库系统 第54节 数据库优化器
数据库优化器是数据库管理系统(DBMS)中的一个关键组件,它的作用是分析用户的查询请求,并生成一个高效的执行计划。这个执行计划定义了如何访问数据和执行操作,以最小化查询的执行时间和资源消耗。以下是数据库优化器的…...

微服务杂谈
几个概念 还是第一次听说Spring Cloud Alibaba ,真是孤陋寡闻了,以前只知道 SpringCloud 是为了搭建微服务的,spring boot 则是快速创建一个项目,也可以是一个微服务 。那么SpringCloud 和 Spring boot 有什么区别呢?S…...

【Pandas操作2】groupby函数、pivot_table函数、数据运算(map和apply)、重复值清洗、异常值清洗、缺失值处理
1 数据清洗 #### 概述数据清洗是指对原始数据进行处理和转换,以去除无效、重复、缺失或错误的数据,使数据符合分析的要求。#### 作用和意义- 提高数据质量:- 通过数据清洗,数据质量得到提升,减少错误分析和错误决策。…...

如何分辨IP地址是否能够正常使用
在互联网的日常使用中,无论是进行网络测试、网站访问、数据抓取还是远程访问,一个正常工作的IP地址都是必不可少的。然而,由于各种原因,IP地址可能无法正常使用,如被封禁、网络连接问题或配置错误等。本文将详细介绍如…...

Sqoop 数据迁移
Sqoop 数据迁移 一、Sqoop 概述二、Sqoop 优势三、Sqoop 的架构与工作机制四、Sqoop Import 流程五、Sqoop Export 流程六、Sqoop 安装部署6.1 下载解压6.2 修改 Sqoop 配置文件6.3 配置 Sqoop 环境变量6.4 添加 MySQL 驱动包6.5 测试运行 Sqoop6.5.1 查看Sqoop命令语法6.5.2 测…...

【数据结构】排序算法系列——希尔排序(附源码+图解)
希尔排序 算法思想 希尔排序(Shell Sort)是一种改进的插入排序算法,希尔排序的创造者Donald Shell想出了这个极具创造力的改进。其时间复杂度取决于步长序列(gap)的选择。我们在插入排序中,会发现是对整体…...

c++(继承、模板进阶)
一、模板进阶 1、非类型模板参数 模板参数分类类型形参与非类型形参。 类型形参即:出现在模板参数列表中,跟在class或者typename之类的参数类型名称。 非类型形参,就是用一个常量作为类(函数)模板的一个参数,在类(函数)模板中…...

【机器学习】从零开始理解深度学习——揭开神经网络的神秘面纱
1. 引言 随着技术的飞速发展,人工智能(AI)已从学术研究的实验室走向现实应用的舞台,成为推动现代社会变革的核心动力之一。而在这一进程中,深度学习(Deep Learning)因其在大规模数据处理和复杂问题求解中的卓越表现,迅速崛起为人工智能的最前沿技术。深度学习的核心是…...
WebLogic 笔记汇总
WebLogic 笔记汇总 一、weblogic安装 1、创建用户和用户组 groupadd weblogicuseradd -g weblogic weblogic # 添加用户,并用-g参数来制定 web用户组passwd weblogic # passwd命令修改密码# 在文件末尾增加以下内容 cat >>/etc/security/limits.conf<<EOF web…...

leetcode:2710. 移除字符串中的尾随零(python3解法)
难度:简单 给你一个用字符串表示的正整数 num ,请你以字符串形式返回不含尾随零的整数 num 。 示例 1: 输入:num "51230100" 输出:"512301" 解释:整数 "51230100" 有 2 个尾…...
)
NotebookLM评论反馈功能全链路拆解(从Prompt响应延迟到语义锚定失效的7个致命断点)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM评论反馈功能的架构全景与设计初衷 NotebookLM 的评论反馈功能并非简单的 UI 层叠加,而是贯穿数据流、状态管理与协同语义理解的深度集成模块。其核心目标是让用户在阅读、引用或…...

离子阱量子计算机与SIMD编译优化技术解析
1. 离子阱量子计算机与SIMD的奇妙结合在量子计算领域,离子阱系统因其独特的物理特性而备受关注。与传统超导量子比特不同,离子阱量子计算机通过电磁场将带电原子(通常是镱或钙离子)悬浮在真空中,利用激光操控这些离子的…...

Linux内核PCIe热插拔驱动开发实战:从IDT芯片到稳定运行
1. 项目概述与核心价值最近在搞一个嵌入式设备项目,需要实现PCIe设备的热插拔支持。这玩意儿在服务器、存储阵列和工业控制领域太常见了,但真要在Linux内核里把它做稳定、做可靠,里面的门道可不少。我这次折腾的,就是一个基于Linu…...
)
超越点灯:深入探索高云FPGA云源软件的高级调试与优化功能(逻辑分析仪+时序约束实战)
超越点灯:深入探索高云FPGA云源软件的高级调试与优化功能(逻辑分析仪时序约束实战) 当LED流水灯项目已经无法满足你的FPGA开发需求时,意味着你正站在从入门到进阶的关键转折点。高云FPGA平台提供的云源软件不仅支持基础开发&#…...
)
告别IDE切换!在VS2022里用上C++ Builder的智能提示(保姆级路径配置)
在VS2022中无缝集成C Builder智能提示的终极指南 对于长期使用C Builder进行Windows桌面开发的工程师来说,Visual Studio 2022的现代化界面和强大调试功能一直是个诱人的存在。但频繁在两个IDE之间切换不仅打断工作流,还会显著降低开发效率。本文将揭示如…...

Redis分布式锁进阶第六十八篇
一、本篇前置衔接 第六十八篇我们完成了全系列终局复盘,整理了故障排查SOP与企业级落地铁律。常规单资源锁、热点分片锁、隔离锁全部讲透,但真实复杂业务永远不是单一资源:下单要扣库存、扣优惠券、扣积分、冻结余额,多资源并行争…...

COLMAP实战:跳过特征提取,直接用已知位姿完成三角测量与稠密重建
COLMAP高效重建实战:基于已知位姿的三角测量与稠密重建加速方案 三维重建技术正在机器人导航、AR/VR内容生成等领域快速普及,但传统流程中特征提取与匹配环节往往消耗超过70%的计算时间。当相机位姿已通过SLAM或其他传感器获取时,如何跳过这些…...

网站推广新纪元:品牌100工程引领下的精准引流与高效转化
在数字化转型的浪潮中,72%的企业网站上线后却陷入了“无人问津”的尴尬境地。缺乏系统的推广策略,仅31%的企业能通过科学推广实现流量与转化双提升。品牌100工程在深度陪跑实践中发现,2026年的网站推广已告别“盲目投放”时代,更注…...

AI工程师实战技能树:从特征工程到MLOps的完整指南
1. 项目概述与核心价值最近在GitHub上看到一个挺有意思的仓库,叫tqviet1978/ai-skills。光看名字,你可能会觉得这又是一个关于AI技能学习的普通教程合集。但当我点进去仔细研究后,发现它的定位和内容组织方式,与市面上大多数“AI学…...
气体传感器阵列与数据采集(附完整 C 语言驱动))
【嵌入式 AI 实战第 9 期】环境感知(一)气体传感器阵列与数据采集(附完整 C 语言驱动)
一、前言在物联网与人工智能快速发展的今天,环境感知能力已成为智能设备的核心功能之一。气体传感器作为环境感知的 "嗅觉器官",广泛应用于智能家居、工业安全、农业生产、医疗诊断等领域。传统的单一气体传感器只能检测特定类型的气体&#x…...