gpt2 adapter finetune
1. 安装依赖:
pip install -U adapter-transformers
pip install datasets
2.训练代码:
from datasets import load_dataset
from transformers import AutoModelForCausalLM
from transformers import GPT2Tokenizer
from transformers import AdapterTrainer, TrainingArgumentsdataset = load_dataset("poem_sentiment")
print(dataset)def encode_batch(batch):"""Encodes a batch of input data using the model tokenizer."""encoding = tokenizer(batch["verse_text"])# For language modeling the labels need to be the input_ids#encoding["labels"] = encoding["input_ids"]return encodingtokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# The GPT-2 tokenizer does not have a padding token. In order to process the data
# in batches we set one here
tokenizer.pad_token = tokenizer.eos_token
column_names = dataset["train"].column_names
dataset = dataset.map(encode_batch, remove_columns=column_names, batched=True)block_size = 50
# Main data processing function that will concatenate all texts from our dataset and generate chunks of block_size.
def group_texts(examples):# Concatenate all texts.concatenated_examples = {k: sum(examples[k], []) for k in examples.keys()}total_length = len(concatenated_examples[list(examples.keys())[0]])# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can# customize this part to your needs.total_length = (total_length // block_size) * block_size# Split by chunks of max_len.result = {k: [t[i : i + block_size] for i in range(0, total_length, block_size)]for k, t in concatenated_examples.items()}result["labels"] = result["input_ids"].copy()return resultdataset = dataset.map(group_texts,batched=True,)dataset.set_format(type="torch", columns=["input_ids", "attention_mask", "labels"])model = AutoModelForCausalLM.from_pretrained("gpt2")
# add new adapter
model.add_adapter("poem")
# activate adapter for training
model.train_adapter("poem")training_args = TrainingArguments(output_dir="./examples", do_train=True,remove_unused_columns=False,learning_rate=5e-4,num_train_epochs=3,
)trainer = AdapterTrainer(model=model,args=training_args,tokenizer=tokenizer,train_dataset=dataset["train"],eval_dataset=dataset["validation"], )trainer.train()model.save_adapter("adapter_poem", "poem")3.测试代码:
from transformers import GPT2LMHeadModel, GPT2Tokenizermodel = GPT2LMHeadModel.from_pretrained("gpt2")
# You can also load your locally trained adapter
model.load_adapter("adapter_poem")
model.set_active_adapters("poem")PREFIX = "In the night"encoding = tokenizer(PREFIX, return_tensors="pt")
output_sequence = model.generate(input_ids=encoding["input_ids"],attention_mask=encoding["attention_mask"],do_sample=True,num_return_sequences=5,max_length = 50,
)for generated_sequence_idx, generated_sequence in enumerate(output_sequence):print("=== GENERATED SEQUENCE {} ===".format(generated_sequence_idx + 1))generated_sequence = generated_sequence.tolist()# Decode texttext = tokenizer.decode(generated_sequence, clean_up_tokenization_spaces=True)# Remove EndOfSentence Tokenstext = text[: text.find(tokenizer.eos_token)]print(text)4.结果输出
=== GENERATED SEQUENCE 1 === In the night, he would go;and she is the queen, and a mistress,and she keeps in the nightthe king who died" (the "giant," said the ancient, as a poet)and a child in his home === GENERATED SEQUENCE 2 === In the night,when one thinks of the war upon the world, and of men who live in it;that's all you have, though, that's all, that's what you want. and that makes me want, but here's th === GENERATED SEQUENCE 3 === In the night, she was the first, for once, the girl of good cheer!--of the people, the love of her life, she has not come to see her sister again;yet i think if i could not have loved her I wer === GENERATED SEQUENCE 4 === In the night, she sang the sweetest lullaby of morning-the very sound he heard:the silent and delicate voice of the holy sea,that his face would not come to grief.a quiet and silent night,the song as always i === GENERATED SEQUENCE 5 === In the nighttime, the king says:but there can be no peace or sorrow if that night's not a blessing,the only hope to her heart lies in the bright day.a good old fool, like a son of a friend,ho
相关文章:

gpt2 adapter finetune
1. 安装依赖: pip install -U adapter-transformers pip install datasets 2.训练代码: from datasets import load_dataset from transformers import AutoModelForCausalLM from transformers import GPT2Tokenizer from transformers import Adap…...

Day14_文件操作
一、数据存储 1.1 计算机数据存储 计算机内存分为运行内存和硬盘两种:保存在运行内存中的数据在程序运行结束后会自动释放,保存在硬盘中的数据会一直存在(除非手动删除或者硬盘损坏) 1)打开文件 open(文件路径, 文件打开方式‘r’, encod…...

leetcode 轮转数组 189
题目 给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。 示例 1: 输入: nums [1,2,3,4,5,6,7], k 3 输出: [5,6,7,1,2,3,4] 解释: 向右轮转 1 步: [7,1,2,3,4,5,6] 向右轮转 2 步: [6,7,1,2,3,4,5] 向右轮转 3 步: [5,6,7,1,2…...

Leetcode.1849 将字符串拆分为递减的连续值
题目链接 Leetcode.1849 将字符串拆分为递减的连续值 Rating : 1747 题目描述 给你一个仅由数字组成的字符串 s。 请你判断能否将 s拆分成 两个或者多个 非空子字符串 ,使子字符串的 数值 按 降序 排列,且每两个 相邻子字符串 的数值之 差 …...

Android布局层级过深为什么会对性能有影响?为什么Compose没有布局嵌套问题?
做过布局性能优化的同学都知道,为了优化界面加载速度,要尽可能的减少布局的层级。这主要是因为布局层级的增加,可能会导致测量时间呈指数级增长。 而Compose却没有这个问题,它从根本上解决了布局层级对布局性能的影响: Compose界…...
【UR机械臂CB3 网络课程 】
【UR机械臂CB3 网络课程 】1. 前言2. 概览:特色与术语2.1 机器人组成2.1.1控制柜2.1.2 UR 机器人手臂2.2 接通机器人电源2.3 移动机械臂3. 机器人如何工作3.1 选择臂端工具3.2 输入有关臂端工具的信息3.3 连接外部装置3.4 机器人编程4. 设置工具4.1 末端执行器配置4.2 工具中心…...

dp-统计字典序元音字符串的数目
给你一个整数 n,请返回长度为 n 、仅由元音 (a, e, i, o, u) 组成且按 字典序排列 的字符串数量。 字符串 s 按 字典序排列 需要满足:对于所有有效的 i,s[i] 在字母表中的位置总是与 s[i1] 相同或在 s[i1] 之前。 示例 1: 输入&…...
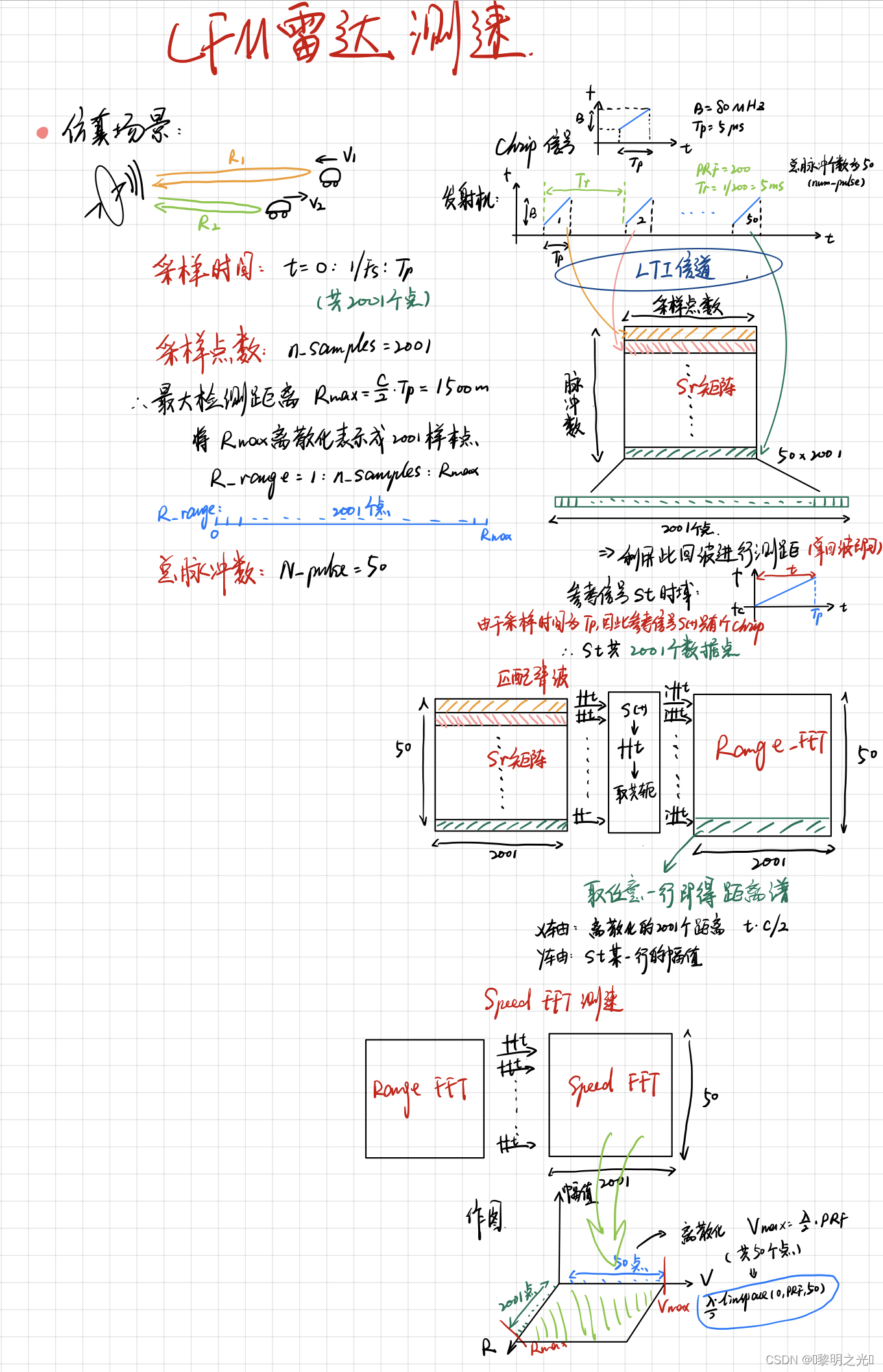
LFM雷达实现及USRP验证【章节3:连续雷达测距测速】
第一章介绍了在相对速度为0时候的雷达测距原理 目录 1. LFM测速 1.1 雷达测速原理 1.2 Chrip信号测速 2. LFM测速代码实现 参数设置 仿真图像 matlab源码 代码分析 第一章介绍了在相对速度为0时候的雷达测距原理,第二章介绍了基于LFM的雷达测距原理及其实现…...

COLMAP多视角视图数据可视化
这篇博文主要介绍多视角三维重建的实用工具COLMAP。为了让读者更快确定此文是否为自己想找的内容,我先用简单几句话来描述此文做的事情: 假设我们针对一个物体(人)采集了多个(假设60个)视角的照片ÿ…...

2023年全国最新高校辅导员精选真题及答案36
百分百题库提供高校辅导员考试试题、辅导员考试预测题、高校辅导员考试真题、辅导员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 92.校园文化形成与发展的主要影响因素有() A.学校的领导与管理活…...

ThreeJS-全屏和退出全屏、自适应大小(五)
下载新得组件 npm install gsap -S 新引入 import gsap from gsap //动画控制 代码: <template> <div id"three_div"> </div> </template> <script> import * as THREE from "three"; import {OrbitControls } f…...

等级保护2.0要求及所需设备清单
等级保护的工作流程包括定级、备案、建设整改、等级测评,核心思想在于建立“可信、可控、可管”的安全防护体系,使得系统能够按照预期运行,免受信息安全攻击和破坏。 三级等保要求及所需设备 三级等级保护指标项: 物理访问控制…...

【大数据之Hadoop】六、HDFS之NameNode、Secondary NameNode和DataNode的内部工作原理
NN和2NN的内部工作原理 对于NameNode的存放位置: 内存中:好处:计算快 坏处:可靠性差,断电后元数据会丢失 磁盘中:好处:可靠性搞 坏处:计算慢 内存磁盘中:效率低 所以设…...

小黑子—Java从入门到入土过程:第四章
Java零基础入门4.0Java系列第四章1. 顺序结构2. if语句3. switch 语句3.1 default的位置和省略3.2 case 穿透3.3 switch 新特性 (jdk12开始)4. for 循环5. while 循环6.do...while 循环7. 无限循环8. 跳转控制语句9. 练习9.1 逢七过9.2 平方根9.3 求质数…...
数据库原理及应用(四)——SQL语句(2)SQL基础查询以及常见运算符
一、SELECT语句基础 数据库查询是数据库的核心操作,SELECT 语句用于从数据库中选取数据。 SELECT [ALL/DISTINCT] <列名>,<列名>...FROM <表名或视图名>,<表名或视图名>[WHERE <条件表达式>][GROUP BY <列名1> [HAVING <条…...

(算法基础)Floyd算法
适用情景Floyd算法适用于多源汇最短路,也就是他问你比如说从3号点到6号点的最短路距离,比如说从7号点到20号点的最短路距离,而不是单源最短路(从1号点到n号点的最短路距离)。在这个算法当中允许负权边的存在。但在求最…...

SQL语法:浅析select之七大子句
Mysql版本:8.0.26 可视化客户端:sql yog 目录一、七大子句顺序二、演示2.1 from语句2.2 on子句2.3 where子句2.4 group by子句2.4.1 WITHROLLUP,加在group by后面2.4.2 是否可以按照多个字段分组统计?2.4.3 分组统计时,…...

中国人民大学与加拿大女王大学金融硕士——去有光的地方,并成为自己的光
光是我们日常生活中一个重要的元素,试想一下如果没有光,世界将陷入一片昏暗。人生路亦是如此,我们从追逐光、靠近光、直到自己成为光。人民大学与加拿大女王大学金融硕士项目是你人生路上的一束光吗 渴望想要成为一个更好的人,就…...

Python数据结构与算法篇(五)-- 二分查找与二分答案
1 二分法介绍 1.1 定义 二分查找又称折半查找、二分搜索、折半搜索等,是一种在静态查找表中查找特定元素的算法。 所谓静态查找表,即只能对表内的元素做查找和读取操作,不允许插入或删除元素。 使用二分查找算法,必须保证查找表中…...
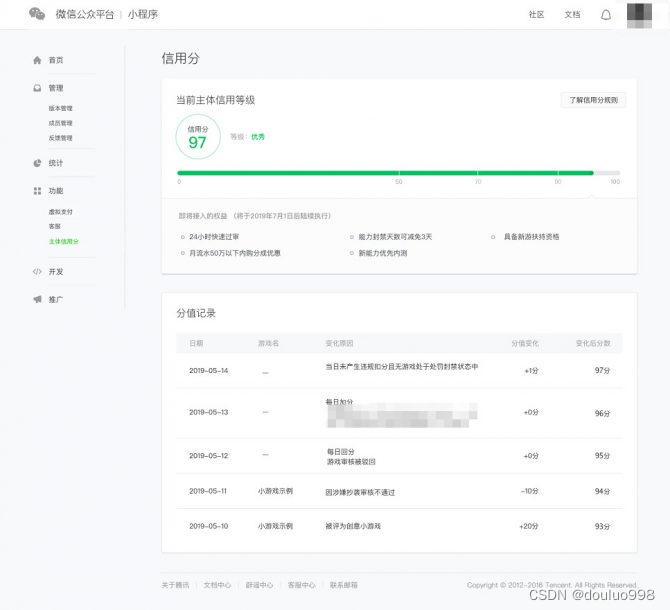
小游戏也要讲信用
当下,小游戏鱼龙混杂,官方为能更好地保护用户、开发者以及平台的权益,近日宣布7月1日起试行小游戏主体信用分机制。 主体信用分是什么呢?简单来说,这是针对小游戏主体下所有小游戏帐号行为,对开发者进行评…...

流分析模式:实时数据处理的设计模式与最佳实践
流分析模式:实时数据处理的设计模式与最佳实践 一、流分析模式的核心概念 1.1 流分析的演进历程 流分析(Stream Analytics)是一种实时数据处理技术,它能够持续处理无限的数据流,并从中提取有价值的信息。 阶段特征处理…...

2025届必备的五大降AI率工具推荐榜单
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 伴随人工智能内容生成被广泛运用,其潜在风险愈发明显地呈现出来。为了应对这些具…...

Maple Mono字体终极配置指南:3步解决连字显示难题,开启高效编程体验
Maple Mono字体终极配置指南:3步解决连字显示难题,开启高效编程体验 【免费下载链接】maple-font Maple Mono: Open source monospace font with round corner, ligatures and Nerd-Font icons for IDE and terminal, fine-grained customization option…...

Systemback实战:从系统备份到自定义镜像部署全流程
1. Systemback基础入门:你的系统时光机 第一次听说Systemback时,我正面临着一个典型运维困境:实验室20台Ubuntu工作站需要统一部署开发环境。传统的手动安装方式不仅耗时,还容易产生配置差异。直到发现这个开源神器,才…...

Paperless-ngx终极指南:如何打造智能文档管理系统的完整解决方案
Paperless-ngx终极指南:如何打造智能文档管理系统的完整解决方案 【免费下载链接】paperless-ngx A community-supported supercharged document management system: scan, index and archive all your documents 项目地址: https://gitcode.com/GitHub_Trending/…...

使用 Taotoken 后 API 调用延迟与稳定性体验分享
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用 Taotoken 后 API 调用延迟与稳定性体验分享 作为一名日常需要频繁调用大模型 API 的开发者,服务的稳定性和响应速…...

全球BGA锡球市场高速成长:2025年2.55亿美元筑基,2032年剑指4.43亿,8.3%CAGR锚定长期高增长逻辑
BGA锡球(BGA Solder Ball) 是用于替代IC元件封装结构中引脚的核心连接件,满足电性互连及机械连接的双重要求。简而言之,它是BGA封装工艺中不可或缺的焊接材料。QYResearch调研显示,2025年全球BGA锡球市场规模大约为2.5…...

VPS自动化配置脚本:Shell脚本实现服务器安全与开发环境一键部署
1. 项目概述:一个为开发者量身打造的VPS自动化配置脚本如果你和我一样,经常需要快速部署新的VPS(虚拟专用服务器)来跑一些临时的项目、搭建测试环境,或者只是厌倦了每次都要重复那些繁琐的初始化步骤,那么你…...

从硬开关到软开关:推挽谐振变换器原理与PSIM仿真实战
1. 从经典到谐振:为什么我们需要推挽变换器?在电源设计的工具箱里,推挽变换器(Push-Pull Converter)绝对算得上是一位“老将”。它的核心思想非常直观:利用一个带中心抽头的变压器,让两个开关管…...

CentOS 7服务器上,从零搞定NVIDIA驱动和CUDA 11.1的保姆级避坑指南
CentOS 7服务器NVIDIA驱动与CUDA 11.1实战避坑手册 接手一台老旧GPU服务器时,最令人头疼的莫过于搭建深度学习环境。那些看似简单的安装步骤背后,往往隐藏着无数个让新手崩溃的"坑"。本文将带你穿越雷区,用最稳妥的方式在CentOS 7上…...