Redis基础数据结构之 quicklist 和 listpack 源码解读
目录标题
- quicklist
- 为什么要设计 quicklist?
- quicklist特点
- ziplist
- quicklist数据结构
- listpack
- listpack是什么?
- listpack数据结构
- ziplist干啥去了?为什么有listpack?
- 什么是ziplist的连锁更新?
- listpack 如何避免连锁更新?
- listpack替代了quicklist吗?
quicklist
为什么要设计 quicklist?
ziplist 有两个问题
- 不能保存过多的元素,否则访问性能会下降
- 不能保存过大的元素,否则容易导致内存重新分配,甚至引起连锁更新
quicklist特点
quicklist 的设计,其实是结合了链表和 ziplist 各自的优势。简单来说,一个 quicklist 就是一个链表,而链表中的每个元素又是一个 ziplist。
- 结构定义:quicklist.h
- 实现:quicklist.c
ziplist
Ziplist(压缩列表)之所以在特定场景下效率高,主要是因为它在内存使用方面进行了优化,特别是在存储小数据集时能够显著减少内存占用。
内存效率
Ziplist 通过对存储的数据进行紧凑编码来减少内存使用。它不仅记录了数据的实际内容,还记录了每个元素的长度信息,使得读取时可以快速确定每个元素的边界。这样做的好处是,对于短字符串或小整数,Ziplist 可以以非常紧凑的方式存储,从而节省内存。
快速访问
Ziplist 中每个元素的长度信息是显式存储的,这意味着访问特定元素时,可以直接跳转到相应的位置,无需遍历整个列表。这样,即使列表中有许多元素,访问特定元素的效率仍然很高。
Ziplist中的显式长度信息确实有助于定位元素,但它并不提供真正的随机访问能力。对于连续访问或数据量较小的情况,Ziplist的表现是不错的,但在需要频繁随机访问的场景下,可能需要考虑其他数据结构,如哈希表或索引结构。
假设Ziplist中存储了三个元素:“foo”(长度3)、“bar”(长度3)和"baz"(长度3)。为了找到第三个元素"baz",你需要先读取第一个元素的长度(3字节),然后加上第二个元素的长度(再加3字节),才能定位到第三个元素的位置。
适合小数据集
Ziplist 主要适用于存储少量且大小适中的元素。当列表或哈希中的元素数量不多,且每个元素的大小也不大时,使用Ziplist可以大大节省内存。例如,对于包含少量字符串或整数的列表,Ziplist的紧凑存储方式可以减少内存开销。
紧凑存储
Ziplist使用紧凑的数据格式存储整数和字符串,通过使用不同的编码方式来适应不同类型的数据。例如,对于整数,Ziplist会根据整数值的大小选择合适的字节数(如1字节、2字节、4字节或8字节)来存储,这样可以有效地利用内存。
适用场景
Ziplist特别适用于内存敏感的应用场景,例如在存储大量小字符串或小整数时。当数据量不大时,Ziplist可以提供较高的性能和较低的内存使用。
自动转换
当Ziplist中的元素数量或大小超过了预先设定的阈值时,Redis会自动将其转换为其他数据结构,如linkedlist或hashtable,以保持良好的性能。这种机制确保了在数据量增长时,Redis仍能保持高效。
Ziplist通过紧凑的数据编码和显式的长度信息记录,能够在存储小数据集时提供高效的内存使用和快速的数据访问。然而,对于大型数据集,Ziplist的性能优势会减弱,此时Redis会自动选择更合适的数据结构来替代。
quicklist数据结构
quicklist 是一个链表,所以每个 quicklistNode 中,都包含了分别指向它前序和后序节点的指针* prev 和* next。同时,每个 quicklistNode 又是一个 ziplist,所以,在 quicklistNode 的结构体中,还有指向 ziplist 的指针* zl。
每个元素节点 quicklistNode 的定义如下:
typedef struct quicklistNode {// 前一个 quicklistNodestruct quicklistNode *prev;// 后一个 quicklistNodestruct quicklistNode *next;// quicklistNode 指向的 ziplistunsigned char *zl;// ziplist 的字节大小unsigned int sz;// ziplist 的元素个数unsigned int count: 16;// 编码方式,『原生字节数组』或「压缩存储」unsigned int encoding: 2;// 存储方式,NONE==1 or ZIPLIST==2unsigned int container: 2;// 数据是否被压缩unsigned int recompress: 1;// 数据能否被压缩unsigned int attempted_compress: 1;// 预留的 bit 位unsigned int extra: 10;
} quicklistNode;quicklist 的结构体定义如下:
typedef struct quicklist {// quicklist 的链表头quicklistNode *head;// quicklist 的链表尾quicklistNode *tail;// 所有 ziplist 中的总元素个数unsigned long count;// quicklistNodes 的个数unsigned long len;……
} quicklist;图示

typedef struct quicklistEntry {const quicklist *quicklist;quicklistNode *node;unsigned char *zi;unsigned char *value;long long longval;unsigned int sz;int offset;
} quicklistEntry;
quicklistCreate
quicklist *quicklistCreate(void) {struct quicklist *quicklist;quicklist = zmalloc(sizeof(*quicklist));quicklist->head = quicklist->tail = NULL;quicklist->len = 0;quicklist->count = 0;quicklist->compress = 0;quicklist->fill = -2;quicklist->bookmark_count = 0;return quicklist;
}quicklistDelIndex 删除节点
REDIS_STATIC int quicklistDelIndex(quicklist *quicklist, quicklistNode *node,unsigned char **p) {int gone = 0;// 在该节点下的 ziplist 中删除node->zl = ziplistDelete(node->zl, p);// count-1node->count--;// ziplist 数量为空,直接删除该节点if (node->count == 0) {gone = 1;__quicklistDelNode(quicklist, node);} else {quicklistNodeUpdateSz(node);}// 更新所有 ziplist 中的总元素个数quicklist->count--;return gone ? 1 : 0;
}quicklistDelEntry 删除节点
核心还是调用了 quicklistDelIndex,但是 quicklistDelEntry 要维护 quicklistNode 的节点,包括迭代器。
void quicklistDelEntry(quicklistIter *iter, quicklistEntry *entry) {quicklistNode *prev = entry->node->prev;quicklistNode *next = entry->node->next;int deleted_node = quicklistDelIndex((quicklist *)entry->quicklist,entry->node, &entry->zi);iter->zi = NULL;// 如果当前节点被删除,更新 iteratorif (deleted_node) {if (iter->direction == AL_START_HEAD) {iter->current = next;iter->offset = 0;} else if (iter->direction == AL_START_TAIL) {iter->current = prev;iter->offset = -1;}}
}quicklistInsertBefore, quicklistInsertAfter 前插和后插
插入分为两种:
void quicklistInsertAfter(quicklist *quicklist, quicklistEntry *node,void *value, const size_t sz);
void quicklistInsertBefore(quicklist *quicklist, quicklistEntry *node,void *value, const size_t sz);其底层都调用了_quicklistInsert 函数:
void quicklistInsertBefore(quicklist *quicklist, quicklistEntry *entry,void *value, const size_t sz) {_quicklistInsert(quicklist, entry, value, sz, 0);
}void quicklistInsertAfter(quicklist *quicklist, quicklistEntry *entry,void *value, const size_t sz) {_quicklistInsert(quicklist, entry, value, sz, 1);
}_quicklistInsert 函数比较长,但是逻辑很简单,就是判断应该在哪里插入新元素:
在后面插入当前 entry 的 ziplist 未满:直接插入
当前 entry 的 ziplist 已满:
entry->next 的 ziplist 未满:在其头部插入
entry->next 的 ziplist 已满:拆分当前 entry在前面插入当前 entry 的 ziplist 未满:直接插入
当前 entry 的 ziplist 已满:
entry->prev 的 ziplist 未满:在其尾部插入
entry->prev 的 ziplist 已满:拆分当前 entry省略 _quicklistInsert函数实现。。。
listpack
listpack是什么?
紧凑列表,用一块连续的内存空间来紧凑保存数据,同时使用多种编码方式,表示不同长度的数据(字符串、整数)。
- 结构定义:listpack.h
- 实现:listpack.c
listpack数据结构

编码类型
在 listpack.c 文件中,有大量的 LP_ENCODING__XX_BIT_INT 和 LP_ENCODING__XX_BIT_STR 的宏定义:
#define LP_ENCODING_7BIT_UINT 0
#define LP_ENCODING_7BIT_UINT_MASK 0x80
#define LP_ENCODING_IS_7BIT_UINT(byte) (((byte)&LP_ENCODING_7BIT_UINT_MASK)==LP_ENCODING_7BIT_UINT)#define LP_ENCODING_6BIT_STR 0x80
#define LP_ENCODING_6BIT_STR_MASK 0xC0
#define LP_ENCODING_IS_6BIT_STR(byte) (((byte)&LP_ENCODING_6BIT_STR_MASK)==LP_ENCODING_6BIT_STR)……listpack 元素会对不同长度的整数和字符串进行编码。
整数编码
以 LP_ENCODING_7BIT_UINT 为例,元素的实际数据是一个 7 bit 的无符号整数。
整数其余的编码方式有:
- LP_ENCODING_16BIT_INT
- LP_ENCODING_24BIT_INT
- LP_ENCODING_32BIT_INT
- LP_ENCODING_64BIT_INT
字符串编码
3 种类型:
- LP_ENCODING_6BIT_STR
- LP_ENCODING_12BIT_STR
- LP_ENCODING_32BIT_STR
ziplist干啥去了?为什么有listpack?
ziplist是存储在连续内存空间,节省内存空间。quicklist是个节点为ziplist的双向链表,其通过控制quicklistNode结构里的压缩列表的大小或者元素个数,来减少连锁更新带来的性能影响,但这并没有完全解决连锁更新的问题。这是因为压缩列表连锁更新的问题来源于它的结构设计。
从Redis 5.0版本开始,设计了一个新的数据结构叫做listpack ,目的是替代原来的压缩列表。在每个listpack节点中,不再保存前一个节点的长度,所以也就不存在出现连锁更新的情况了。
Redis7.0 才将 listpack 完整替代 ziplist。
什么是ziplist的连锁更新?
ziplist中元素个数多了,其查找效率就降低。若是在ziplist里新增或修改数据,ziplist占用的内存空间还需要重新分配;更糟糕的是,ziplist新增或修改元素时候,可能会导致后续元素的previous_entry_length占用空间都发生变化,从而引起连锁更新,导致每个元素的空间都需要重新分配,更加导致其访问性能下降。
listpack 如何避免连锁更新?
为了应对这些问题,Redis先是在3.0版本实现了quicklist结构。其是在ziplist基础上,使用链表将多个ziplist串联起来,即链表的每个元素是一个ziplist。这样可以减少数据插入时内存空间的重新分配及内存数据的拷贝。而且,quicklist也限制了每个节点上ziplist的大小,要是某个ziplist的元素个数多了,会采用新增节点的方法。
但是因为quicklist使用节点结构指向了每个ziplist,这又增加了内存开销。而为了减少内存开销,并进一步避免ziplist连锁更新的问题,所以就有了listpack结构。
listpack每个列表项都只记录自己的长度,不会像 ziplist 的列表项会记录前一项的长度。所以在 listpack 中新增或修改元素,只会涉及到列表项自身的操作,不会影响后续列表项的长度变化,进而避免连锁更新。
listpack是沿用了ziplist紧凑型的内存布局。而listpack中每个节点不再包含前一节点的长度,所以当某个节点中的数据发生变化时候,导致节点的长度变化也不会影响到其他节点,这就可以避免连锁更新的问题了。
listpack相比ZipList的主要优势就在于解决了连锁更新的问题,提高了Redis的处理性能
listpack替代了quicklist吗?
在Redis 7.0版本之前,quicklist是由双向链表和压缩列表构成的。然而,在Redis 7.0版本中,quicklist的底层实现由双向链表和压缩列表变为了由双向链表和listpack构成的结构。
这表明,虽然listpack在Redis 7.0版本中被引入并用于替代压缩列表(ziplist)的部分功能,但quicklist的结构仍然存在,只是其中的压缩列表部分被listpack所替代。因此,listpack并没有完全替代quicklist,而是作为quicklist的一部分,改变了其原有的实现方式

相关文章:
Redis基础数据结构之 quicklist 和 listpack 源码解读
目录标题 quicklist为什么要设计 quicklist?quicklist特点ziplist quicklist数据结构 listpacklistpack是什么?listpack数据结构ziplist干啥去了?为什么有listpack?什么是ziplist的连锁更新?listpack 如何避免连锁更新࿱…...

深入理解Go语言的方法定义与使用
在Go语言编程中,方法(Method) 是附属于特定类型的函数,使我们能够以面向对象的方式编写代码。通过方法,我们可以更自然地对类型进行操作。本文将通过实际的代码示例,深入探讨Go语言中方法的定义与使用。 一…...

堆排序,快速排序
目录 1.堆排序 2.快速排序 1.hoare版本 2.挖坑法 3.前后指针法 注意点 1.堆排序 void Swap(int* a, int* b) {int tmp *a;*a *b;*b tmp; } void adjustdown(int* a, int n, int parent) {int child parent * 2 1;while (child < n){if (child 1 < n &&am…...

系统架构师---数据库设计的四个阶段
需求分析、概念设计、逻辑设计和物理设计是数据库设计中的四个关键阶段,每个阶段都有其独特的任务和目标,以下是对这四个阶段的区别的详细阐述: 需求分析阶段 目标:全面理解用户对数据库系统的需求,包括业务需求、信…...

MySQL_简介及安装、配置、卸载(超详细)
课 程 推 荐我 的 个 人 主 页:👉👉 失心疯的个人主页 👈👈入 门 教 程 推 荐 :👉👉 Python零基础入门教程合集 👈👈虚 拟 环 境 搭 建 :…...

大数据处理技术:分布式文件系统HDFS
目录 1 实验名称: 2 实验目的 3 实验内容 4 实验原理 5 实验过程或源代码 5.1 HDFS的基本操作 5.2 HDFS-JAVA接口之读取文件 5.3 HDFS-JAVA接口之上传文件 5.4 HDFS-JAVA接口之删除文件 6 实验结果 6.1 HDFS的基本操作 6.2 HDFS-JAVA接口之读取文件 6.…...
组合数(模板)
1.杨辉三角求组合数,最高只能求几千内的组合数。 #include<bits/stdc.h> using namespace std; #define int long long int C[1005][1005]; signed main() {//求 1000 以内的组合数 for(int i0;i<1000;i){C[i][0]C[i][i]1;for(int j1;j<i;j){C[i][j]C[…...
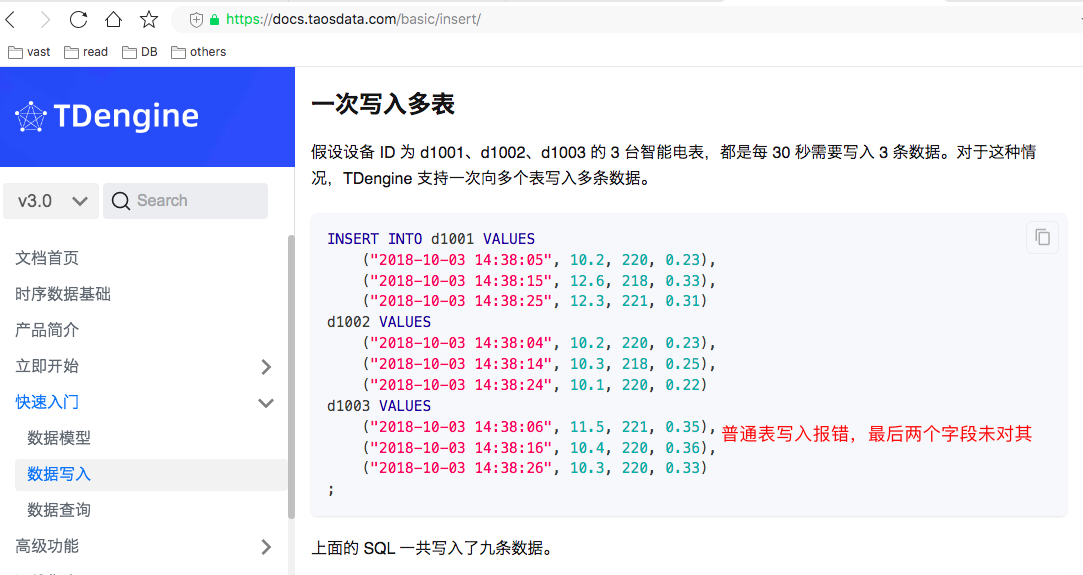
时序数据库 TDengine 的入门体验和操作记录
时序数据库 TDengine 的学习和使用经验 什么是 TDengine ?什么是时序数据 ?使用RPM安装包部署默认的网络端口 TDengine 使用TDengine 命令行(CLI)taosBenchmark服务器内存需求删库跑路测试 使用体验文档纠错 什么是 TDengine &…...

Qt-QPushButton按钮类控件(22)
目录 描述 使用 给按钮添加图片 给按钮添加快捷键 添加槽函数 添加快捷键 添加组合键 开启鼠标的连发功能 描述 经过上面的一些介绍,我们也尝试的使用过了这个控件,接下来我们就要详细介绍这些比较重要的控件了 使用 给按钮添加图片 我们创建…...

镜舟科技与中启乘数科技达成战略合作,共筑数据服务新生态
当今企业数据管理日益规范化,数据应用系统随着数据类型与数量的增长不断细分,为了提升市场竞争力与技术实力,数据领域软件服务商与上下游伙伴的紧密对接与合作显得尤为重要。通过构建完善的生态系统,生态内企业间能够整合资源、共…...

蒸!--数据在内存中的存储
一.整数在内存中的存储 对于整形来说:数据存放内存中其实存放的是补码。 为什么? 在计算机系统中,数值⼀律⽤补码来表⽰和存储。 原因在于,使⽤补码,可以将符号位和数值域统⼀处理; 同时,加法和…...

利用AI增强现实开发:基于CoreML的深度学习图像场景识别实战教程
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中…...

每个企业都需要 (但未使用) 的 BYOD 安全解决方案
远程办公模式的转变彻底改变了组织管理员工设备的方式。如今,员工希望能够灵活地在任何地方使用任何设备工作,这导致自带设备 (BYOD) 政策被广泛采用。 但随着越来越多的企业采用BYOD,一个问题依然摆在眼前:如何在不侵犯个人隐私…...

【多系统萎缩患者必看】科学锻炼秘籍,让生命之树常青
亲爱的小红书朋友们,👋 今天我们要聊一个温暖而坚韧的话题——关于多系统萎缩(MSA)患者的锻炼指南。在这个充满挑战的旅程中,锻炼不仅是身体的锻炼,更是心灵的滋养,是对抗病魔的勇敢姿态&#x…...

【Android】Room—数据库的基本操作
引言 在Android开发中,数据持久化是一个不可或缺的部分。随着应用的复杂度增加,选择合适的数据存储方式变得尤为重要。Room数据库作为Android Jetpack架构组件之一,提供了一种抽象层,使得开发者能够以更简洁、更安全的方式操作SQ…...

「数组」堆排序 / 大根堆优化(C++)
目录 概述 核心概念:堆 堆结构 数组存堆 思路 算法过程 up() down() Code 优化方案 大根堆优化 Code(pro) 复杂度 总结 概述 在「数组」快速排序 / 随机值优化|小区间插入优化(C)中,我们介绍了三种基本排序中的冒泡…...

Edegex Foundry docker和源码安装
edgex文档下载 https://github.com/edgexfoundry/edgex-docs/branches/all 在线文档查看 首先要安装python3环境 然后后安装 打开超级终端 #pip3 install mkdocs #mkdocs serve 在浏览器中输入 http://127.0.0.1:8000/edgex-docs/2.3/ 即可打开在线文档 edgex入门可以参考…...

阿里P8和P9级别有何要求
阿里巴巴的P8和P9级别,代表着公司的资深技术专家或管理者岗位,要求候选人具有丰富的职业经历、深厚的技术能力以及出色的领导力。以下是对P8和P9级别的要求、考察点以及准备建议的详细分析。 P8 级别要求 1. 职业经历: 8年以上的工作经验&a…...
【目标检测数据集】锯子数据集1107张VOC+YOLO格式
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):1107 标注数量(xml文件个数):1107 标注数量(txt文件个数):1107 标注…...
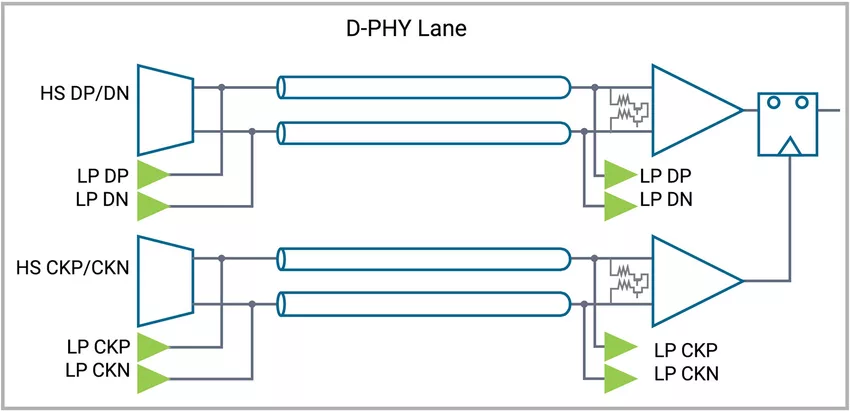
移动产业处理器接口(MIPI)协议是什么?
未来汽车的宏伟愿景备受瞩目,特别是驱动这些汽车的技术更是成为焦点。如今,传感器对于汽车视觉和安全技术的下一阶段至关重要,因为驾驶员和乘客都依赖于它们。这些传感器能够支持众多应用,这些应用往往基于人工智能(AI…...

自动化内容创作:OpenClaw+Qwen3.5-9B批量处理游记照片生成博客
自动化内容创作:OpenClawQwen3.5-9B批量处理游记照片生成博客 1. 为什么需要自动化内容创作流水线 去年夏天我从西藏旅行回来,手机里存了800多张照片。当我坐在电脑前准备写游记时,面对海量素材突然感到无从下手——每张照片都需要回忆拍摄…...

CSS如何避免浮动元素换行_计算所有浮动元素的总宽度不超过父容器宽度
浮动元素换行是因子元素总宽度(含padding、border、margin)超过父容器可用宽度,导致最后一个被挤至下一行;这是float原始行为,非bug,需用box-sizing:border-box、flex布局等规避。浮动元素换行是因为父容器…...

解决Tailwind Next.js博客构建9大痛点:从开发到部署全流程指南
解决Tailwind Next.js博客构建9大痛点:从开发到部署全流程指南 【免费下载链接】tailwind-nextjs-starter-blog This is a Next.js, Tailwind CSS blogging starter template. Comes out of the box configured with the latest technologies to make technical wri…...

Selenoid API完全解析:从会话管理到资源监控的终极指南
Selenoid API完全解析:从会话管理到资源监控的终极指南 【免费下载链接】selenoid Selenium Hub successor running browsers within containers. Scalable, immutable, self hosted Selenium-Grid on any platform with single binary. 项目地址: https://gitcod…...

RTV主题开发终极指南:如何从零开始创建自定义终端Reddit主题
RTV主题开发终极指南:如何从零开始创建自定义终端Reddit主题 【免费下载链接】rtv Browse Reddit from your terminal 项目地址: https://gitcode.com/gh_mirrors/rt/rtv RTV(Reddit Terminal Viewer)是一个强大的终端Reddit浏览工具&…...

三相四桥臂APF的双闭环控制的simulink仿真图,用的是Matlab2018a,可以看出
三相四桥臂APF的双闭环控制的simulink仿真图,用的是Matlab2018a,可以看出,控制前电网电流THD值达24%,中线电流10A,经过PID控制以后降低到了5%以下,母线电压稳定在800v,中线电流降为2A 随仿真有参考文献最近…...

模拟函数memmove
#include <stdio.h>//怎么实现是从前往后拷贝,还是从后往前拷贝 #include <assert.h>//拷贝函数,核心是可以处理内存重叠的情况 //定义 void *my_memmove(void *dest,const void *source,size_t n) {//准备工作 // assert(dest ! NULL); // …...

OpenClaw技能开发入门:为Qwen3-32B定制专属文件分类器
OpenClaw技能开发入门:为Qwen3-32B定制专属文件分类器 1. 为什么需要文件分类技能 上周我的桌面又变成了"数字垃圾场"——下载文件夹里混杂着PDF报告、会议录音、临时截图和一堆未命名的压缩包。当我第三次因为找不到客户合同而错过deadline时ÿ…...

PCK文件解析与资源提取全指南:从基础到高级的游戏资源逆向工程实践
PCK文件解析与资源提取全指南:从基础到高级的游戏资源逆向工程实践 【免费下载链接】godot-unpacker godot .pck unpacker 项目地址: https://gitcode.com/gh_mirrors/go/godot-unpacker 在游戏开发与学习过程中,我们经常需要分析游戏资源文件以理…...

33.3%提及率,直接提及却为0%:张雪机车的AI搜索“假性存在”危机
一次小范围诊断,暴露了一个关键信号:品牌在AI生成答案中的“存在感”,远没有看起来那么安全。近日,张雪机车在国内大火,各大媒体都对张雪本人做了铺天盖地的报道。我们是做GEO(生成式搜索优化)服…...