第L6周:机器学习-随机森林(RF)
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊
目标:
1.什么是随机森林(RF)
随机森林(Random Forest, RF)是一种由 决策树 构成的 集成算法 ,采用的是 Bagging 方法,他在很多情况下都能有不错的表现。其是由很多决策树构成的,不同决策树之间没有关联。当我们进行分类任务时,新的输入样本进入,就让森林中的每一棵决策树分别进行判断和分类,每个决策树会得到一个自己的分类结果,决策树的分类结果中哪一个分类最多,那么随机森林就会把这个结果当做最终的结果。个人理解:就是通过不维度去使用决策树去分类,每个决策树都有自己的分类结果 ,再把所有的结果进行统计,得出分类最多的那个分类就是预测的最终结果 。
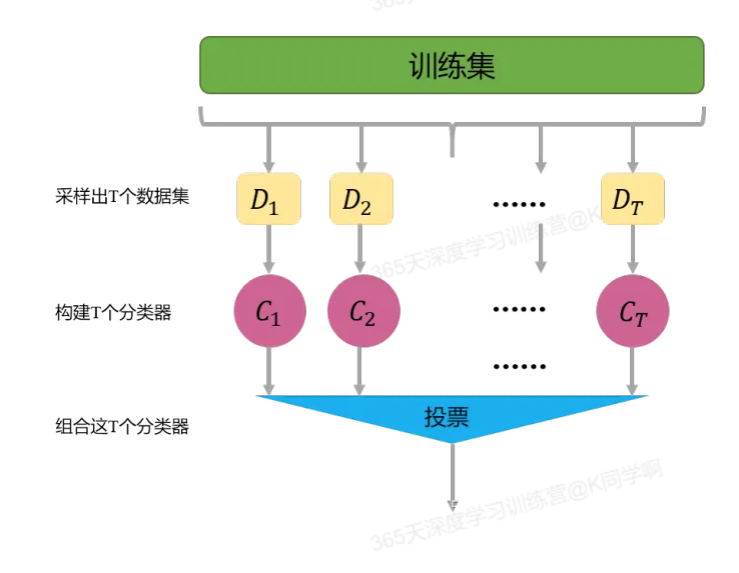
2. Bagging方法:Bagging的主要思想如下图所示,首先从数据集中采样出T个数据集,然后基于这T个数据集,每个训练出一个基分类器,再讲这些基分类器进行组合做出预测。Bagging在做预测时,对于分类任务,使用简单的投票法。对于回归任务使用简单平均法。若分类预测时出现两个类票数一样时,则随机选择一个。
3.目标:从一个天气数据集去推送天气情况,这个天气数据集包含很多维度的数据,比如温度、温度、气压、风速、云量等等;
具体实现:
(一)环境:
语言环境:Python 3.10
编 译 器: PyCharm
**(二)具体步骤:
- 导入库:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
- 导入数据:
data = pd.read_csv('./weather_classification_data.csv')
print(data)
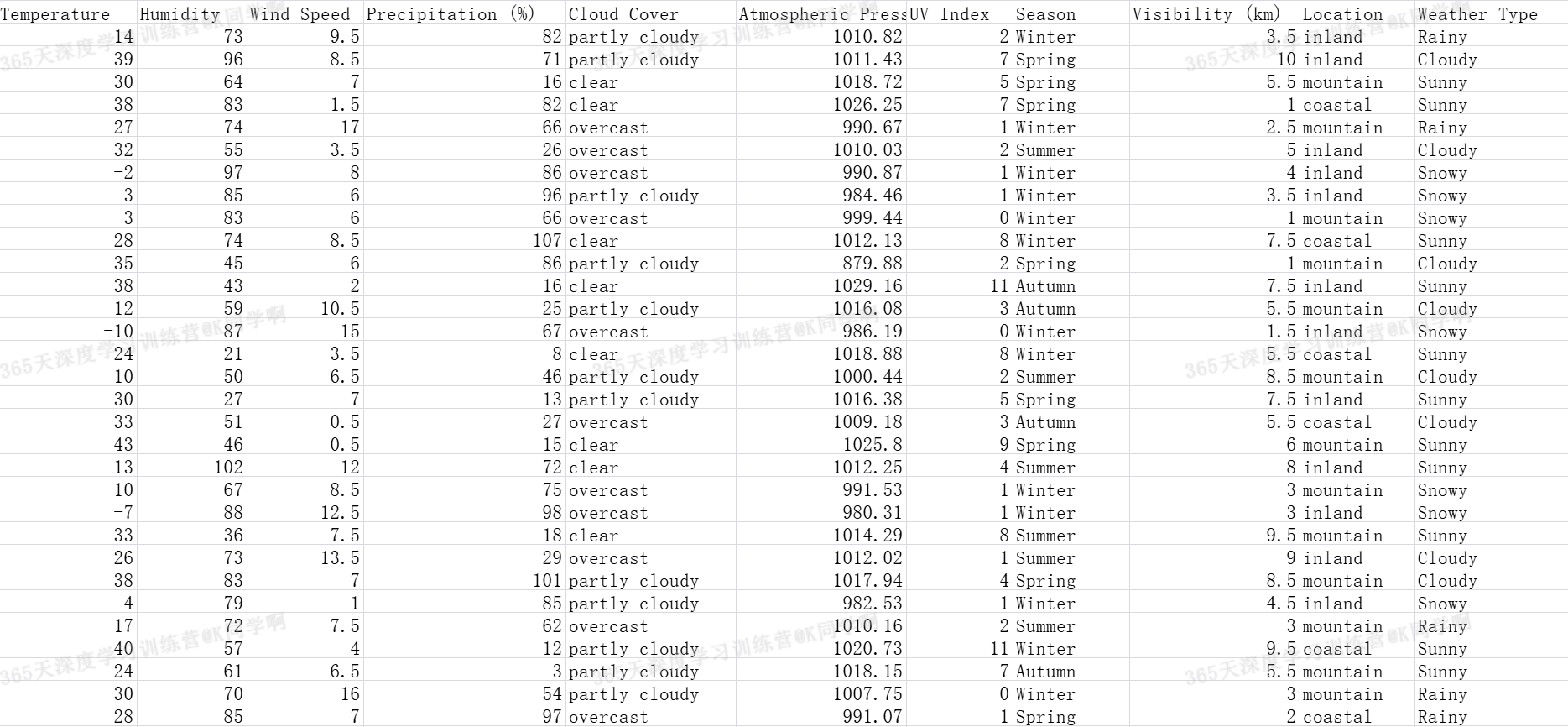
字段解释:
3. 查看数据信息:
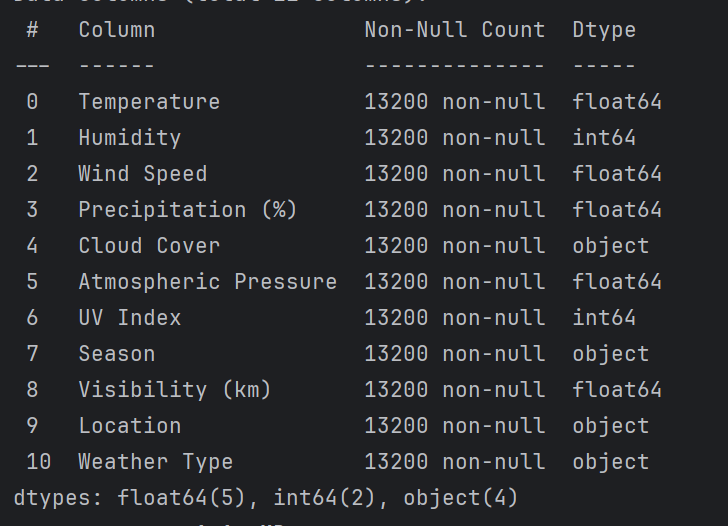
# 数据检查和预处理
print(data.info())
# 查看分类特征的唯一值
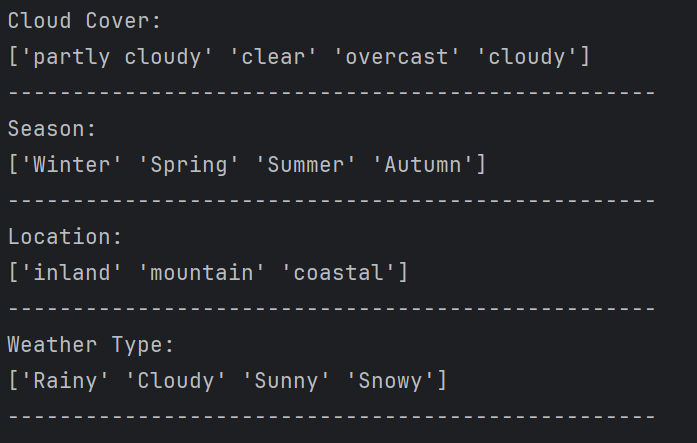
characteristic = ['Cloud Cover', 'Season', 'Location', 'Weather Type']
for i in characteristic: print(f'{i}:') print(data[i].unique()) # 过滤重复值print('-' * 50)
# 继续探索
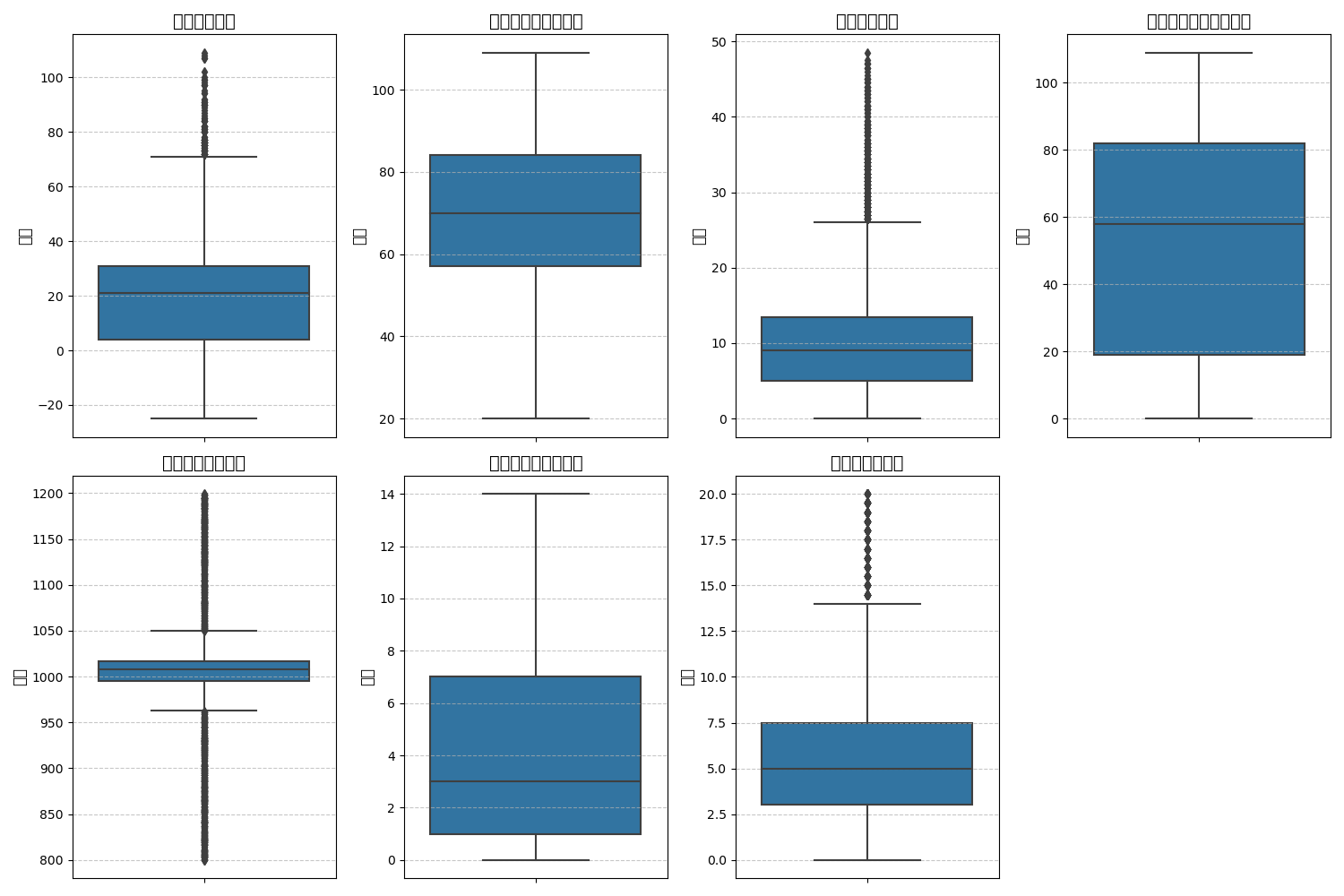
feature_map = { 'Temperature': '温度', 'Humidity': '湿度百分比', 'Wind Speed': '风速', 'Precipitation (%)': '降水量百分比', 'Atmospheric Pressure': '大气压力', 'UV Index': '紫外线指数', 'Visibility (km)': '能见度'
}
plt.figure(figsize=(15, 10)) for i, (col, col_name) in enumerate(feature_map.items(), 1): plt.subplot(2, 4, i) sns.boxplot(y=data[col]) plt.title(f'{col_name}的箱线图', fontsize=14) plt.ylabel('数值', fontsize=12) plt.grid(axis='y', linestyle='--', alpha=0.7) plt.tight_layout()
plt.show()
注意:
- 如果出现“KeyError"的错误,请一定保证features_map中的key和数据中的列名一致,否则找不到。
- 如果出现如下图plt无法显示中文的情况:
请在代码中加入这两句(加哪里?自己琢磨一下),参考:python:matplotlib绘图无法显示中文或负号,显示为框框 - 范仁义 - 博客园:
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["font.family"] = "sans-serif"
分析一下:
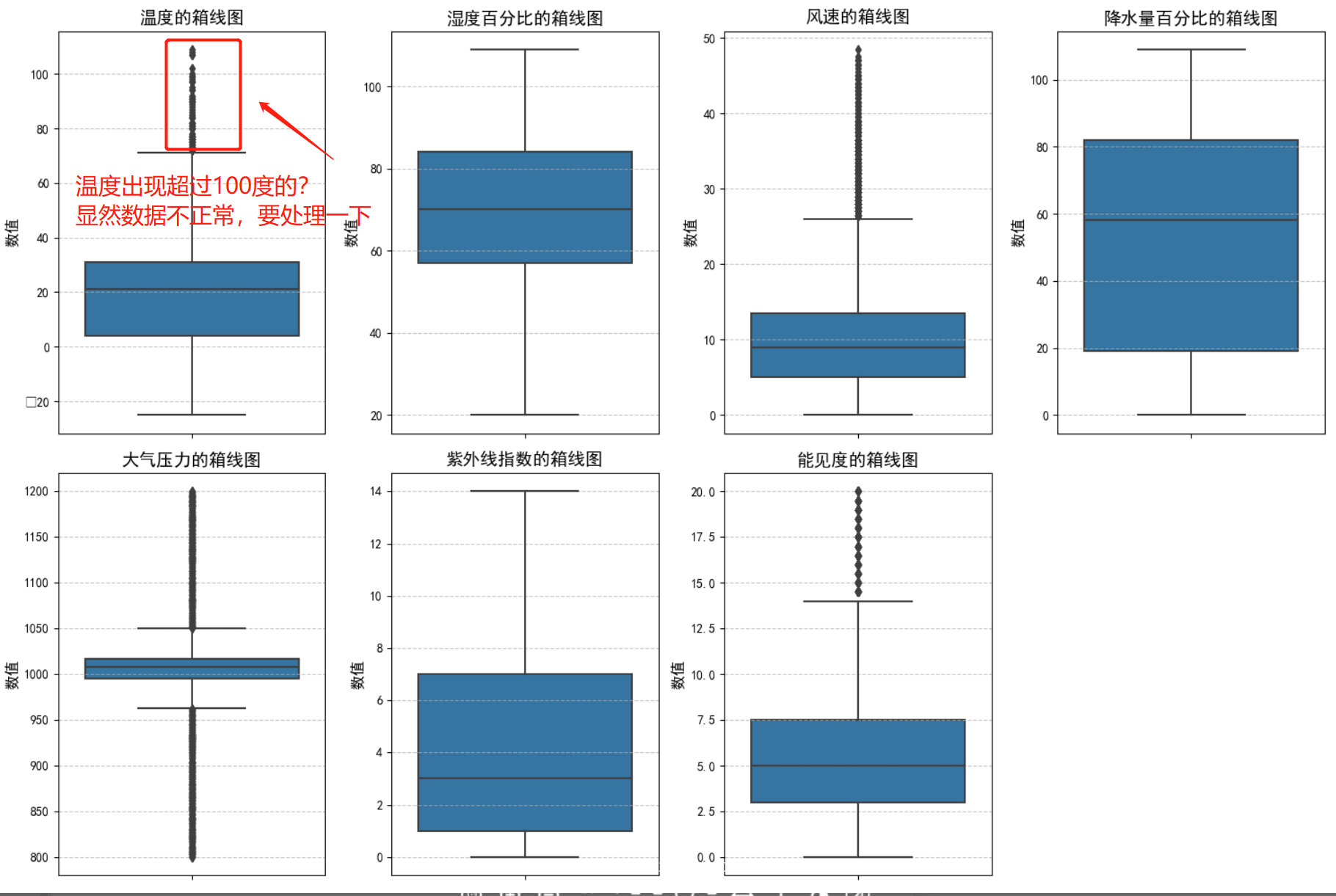
# 处理一下异常数据
print(f"温度超过60度的数据量: {data[data['Temperature'] > 60].shape[0]}, 占比{round(data[data['Temperature']>60].shape[0] / data.shape[0] * 100, 2)}%.")
print(f"湿度百分比超过100%的数据量:{data[data['Humidity'] > 100].shape[0]},占比{round(data[data['Humidity'] > 100].shape[0] / data.shape[0] * 100,2)}%。")
print(f"降雨量百分比超过100%的数据量:{data[data['Precipitation (%)'] > 100].shape[0]},占比{round(data[data['Precipitation (%)'] > 100].shape[0] / data.shape[0] * 100,2)}%。")
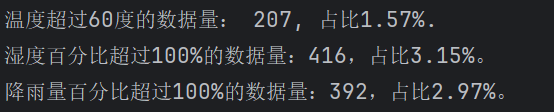
异常数据有点高,把这些异常数据清除掉,以免影响整体训练效果:
# 处理一下异常数据,以免影响训练效果
print("删前的数据shape:", data.shape)
data = data[(data['Temperature'] <= 60) & (data['Humidity'] <= 100) & (data['Precipitation (%)'] <= 100)]
print("删后的数据shape:", data.shape)

- 随机森林预测
# 随机森林预测
new_data = data.copy()
label_encoders = {}
categorical_features = ['Cloud Cover', 'Season', 'Location', 'Weather Type']
for feature in categorical_features: le = LabelEncoder() new_data[feature] = le.fit_transform(data[feature]) label_encoders[feature] = le for feature in categorical_features: print(f"'{feature}'特征的对应关系: ") for index, class_ in enumerate(label_encoders[feature].classes_): print(f" {index}: {class_}")

# 构建x, y
x = new_data.drop(['Weather Type'], axis=1)
y = new_data['Weather Type'] # 划分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3, random_state=15) # 构建RF模型
rf_clf = RandomForestClassifier(random_state=15)
rf_clf.fit(x_train, y_train) # 使用RF进行预测
y_pred_rf = rf_clf.predict(x_test)
class_report_rf = classification_report(y_test, y_pred_rf)
print(class_report_rf)
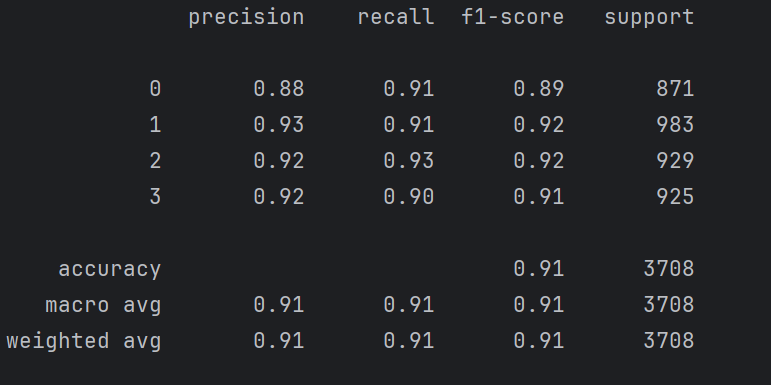
准确率还是很高。
相关文章:
第L6周:机器学习-随机森林(RF)
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 目标: 1.什么是随机森林(RF) 随机森林(Random Forest, RF)是一种由 决策树 构成的 集成算法 &#…...

【电路笔记】-差分运算放大器
差分运算放大器 文章目录 差分运算放大器1、概述2、差分运算放大器表示2.1 差分模式2.2 减法器模式3、差分放大器示例3.1 相关电阻3.2 惠斯通桥3.3 光/温度检测4、仪表放大器5、总结1、概述 在之前的文章中,我们讨论了反相运算放大器和同相运算放大器,我们考虑了在运算放大器…...

git 命令---想要更改远程仓库
在 Git 中,origin 是默认的远程仓库名称。可以使用以下命令查看当前 Git 仓库的 origin 名称及其对应的 URL: git remote -v这个命令会列出所有配置的远程仓库及其名称,其中 origin 通常是克隆时自动设置的默认远程仓库名称。输出示例&#…...
)
LeetCode:2848. 与车的相交点 一次遍历,时间复杂度O(n)
2848. 与车的相交点 today 2848. 与车的相交点 题目描述 给你一个下标从 0开始的二维整数数组 nums 表示汽车停放在数轴上的坐标。对于任意下标 i ,nums[i] [starti, endi] ,其中 s t a r t i start_i starti 是第 i 辆车的起点, e n …...

Xcode 16 RC (16A242) 发布下载,正式版下周公布
Xcode 16 RC (16A242) - Apple 平台 IDE IDE for iOS/iPadOS/macOS/watchOS/tvOS/visonOS 请访问原文链接:https://sysin.org/blog/apple-xcode-16/,查看最新版。原创作品,转载请保留出处。 作者主页:sysin.org Xcode 16 的新功…...

git 更换远程地址的方法
需要将正在开发的代码远程地址改成新的地址,通过查询发现有三个方法可以实现,特此记录。具体方法如下: (1)通过命令直接修改远程仓库地址 git remote 查看所有远程仓库git remote xxx 查看指定远程仓库地址git remote…...
9. 什么是 Beam Search?深入理解模型生成策略
是不是总感觉很熟悉? 在之前第5,7,8篇文章中,我们都曾经用到过与它相关的参数,而对于早就有着实操经验的同学们,想必见到的更多。这篇文章将从示例到数学原理和代码带你进行理解。 Beam Search 对应的中文翻…...

Spring自定义注解
目录 一、interface 关键字 二、元注解 三、简单实现 四、使用切面执行自定义注解逻辑 1) 首先将刚才的注解修改成放在方法上的: 2) 定义一个切面类: 3)将注解放入到接口方法中测试: 五、切点表达式 一、interface 关键字 …...

微信小程序:wx.login或调用uni.login时报错the code is a mock one
微信小程序,调用wx.login或调用uni.login方法,返回the code is a mock one 原因与解决 原因:没有关联真实的 appid,解决办法:绑定真实的微信小程序的appid...

URL的执行流程
基本概念: URL(统一资源定位符,Uniform Resource Locator)的执行流程是指当你在浏览器中输入一个URL并按下回车键时,从输入URL到最终在浏览器中显示网页的完整过程。 1.解析协议 URL 以协议开头,如 http…...

双指针算法专题(2)
找往期文章包括但不限于本期文章中不懂的知识点: 个人主页:我要学编程(ಥ_ಥ)-CSDN博客 所属专栏: 优选算法专题 想要了解双指针算法的介绍,可以去看下面的博客:双指针算法的介绍 目录 611.有效三角形的个数 LCR 1…...

加密与安全_优雅存储用户密码的最佳实践
文章目录 Pre概述最佳实践避免使用MD5、SHA1等快速哈希算法加盐哈希 (不推荐)使用BCrypt、Argon2等慢哈希算法 (推荐)BCrypt Code1. 自动生成和嵌入盐2. 哈希结果的格式3. 代价因子 BCrypt特点 防止暴力破解1. 登录失败锁定2. 双因素认证(2FA…...

【多线程】深入剖析线程池的应用
💐个人主页:初晴~ 📚相关专栏:多线程 / javaEE初阶 还记得我们一开始引入线程的概念,就是因为进程太“重”了,频繁创建销毁进程的开销是非常大的。而随着计算机的发展,业务上对性能的要求越来越…...
『功能项目』切换职业面板【48】
我们打开上一篇47技能冷却蒙版的项目, 本章要做的事情是切换职业UI面板的功能 首先双击打开Canvas预制体在左上主角面板信息中新建一个button按钮 重命名(父物体是按钮Button,子物体Image即可) 创建一个Image 设计一下布局 复制三…...

【EasyExcel】@ColumnWidth(value = 20) EasyExcel设置列宽不生效
经过测试发现,只有XLS,ColumnWidth注解才会生效,选择CSV和XLSX都不会生效 //对应的导出实体类 EasyExcel.write(outputStream, Result.class)//excel文件类型,包括CSV、XLS、XLSX.excelType(ExcelTypeEnum.XLS)...

CPU 和 GPU:为什么GPU更适合深度学习?
目录 什么是 CPU ? 什么是 GPU ? GPU vs CPU 差异性对比分析 GPU 是如何工作的 ? GPU 与 CPU 是如何协同工作的 ? GPU vs CPU 类型解析 GPU 应用于深度学习 什么是 CPU ? CPU(中央处理器)…...

【机器学习】:解锁数据背后的智慧宝藏——深度探索与未来展望
欢迎来到 破晓的历程的 博客 ⛺️不负时光,不负己✈️ 文章目录 引言一、深入机器学习的内在机制二、最新进展与趋势三、对未来社会的深远影响结语 引言 在上一篇博客中,我们初步探讨了机器学习如何成为解锁数据背后智慧的关键工具。现在,让…...
)
【Kubernetes】常见面试题汇总(十八)
目录 55.简述 Kubernetes 共享存储的作用? 56.简述 Kubernetes 数据持久化的方式有哪些? 57.简述 Kubernetes PV 和 PVC ? 58.简述 Kubernetes PV 生命周期内的阶段? 55.简述 Kubernetes 共享存储的作用? Kubernet…...

无限边界:现代整合安全如何保护云
尽管云计算和远程工作得到广泛采用,零信任网络也稳步推广,但边界远未消失。相反,它已被重新定义。就像数学分形的边界一样,现代网络边界现在无限延伸到任何地方。 不幸的是,传统工具在现代无限边界中效果不佳。现代边…...

HTML贪吃蛇游戏
文章目录 贪吃蛇游戏 运行效果代码 贪吃蛇游戏 贪吃蛇是一款经典的休闲益智游戏。本文将通过HTML5和JavaScript详细解析如何实现一个简易版的贪吃蛇游戏。游戏的主要逻辑包括蛇的移动、碰撞检测、食物生成等功能。以下是游戏的完整代码及注释解析。(纯属好玩&#…...
|YOLO目标检测训练数据集)
羊四种行为检测数据集(2000张高质量标注)|YOLO目标检测训练数据集
羊四种行为检测数据集(2000张高质量标注)|YOLO目标检测训练数据集 前言 在智慧养殖与畜牧业数字化转型的背景下,基于计算机视觉的动物行为识别逐渐成为研究与工程应用的热点方向。通过对动物行为的自动检测与分析,可…...

三维空间频谱时序预测模型开发完整报告
三维空间频谱时序预测模型开发完整报告 一、项目背景与目标 本项目基于UrbanRadio3D静态数据集,构建端到端的深度学习模型,实现对低空三维空间频谱(路径损耗)的时序演化预测。城市环境中的无线电传播受建筑物遮挡、反射等因素影响,呈现出复杂的空间分布和时间动态特性(…...

Shell程序
Shell脚本定义:以.sh结尾的文件,用于执行特定任务脚本参数传递:执行脚本时可在命令后添加参数(如start/stop)Hadoop脚本示例:sbin/hadoop-daemon.sh start namenodeShell编程特点:简单易用,适合自动化常见操作脚本执行方式:直接运行.sh文件即可执行其中命…...

嘉为蓝鲸应用发布中心V6.3发布:流自融合、安全提效,全方位护航企业级应用发布
前言 嘉为蓝鲸应用发布中心鲸舟是企业用于实现一体化应用投产发布的基础设施,能够对应用发布进行统一管理和自动化执行。平台支持单体/微服务应用发布、分布式/容器化发布、应用全生命周期管理,以及蓝绿/金丝雀发布等多种发布场景。发布总览 2026年春季&…...

从浮点到整数:深入解析QAT量化模型的推理计算机制
1. 量化感知训练(QAT)的核心思想 量化感知训练就像给模型提前打预防针。想象一下,你平时用计算器做数学题,突然有一天只能用整数计算(比如只能输入1、2、3,不能输入1.5),这时候直接硬…...

告别重复打卡:远程办公族的智能签到自动化解决方案
告别重复打卡:远程办公族的智能签到自动化解决方案 【免费下载链接】daily-check-in 一个打卡小程序 - 基于 leancloud 数据存储 项目地址: https://gitcode.com/gh_mirrors/da/daily-check-in 在数字化办公普及的今天,远程办公族每天需在项目管…...

DreamZero技术解析:当视频扩散模型成为机器人“物理大脑“
原文摘要翻译最先进的视觉-语言-动作(VLA)模型在语义泛化方面表现出色,但在新环境中难以泛化到未见过的物理动作。我们提出了 DreamZero,一种基于预训练视频扩散主干网络构建的世界动作模型(WAM)。与 VLA 不…...

如何用低代码工作流解决业务流程自动化难题:从设计到落地的实践指南
如何用低代码工作流解决业务流程自动化难题:从设计到落地的实践指南 【免费下载链接】Awesome-Dify-Workflow 分享一些好用的 Dify DSL 工作流程,自用、学习两相宜。 Sharing some Dify workflows. 项目地址: https://gitcode.com/GitHub_Trending/aw/…...

yuzu模拟器完整配置指南:从零开始打造完美Switch游戏体验
yuzu模拟器完整配置指南:从零开始打造完美Switch游戏体验 【免费下载链接】yuzu 任天堂 Switch 模拟器 项目地址: https://gitcode.com/GitHub_Trending/yu/yuzu yuzu是一款功能强大的开源任天堂Switch模拟器,让你在Windows、Linux和Android系统上…...

新手入门:借助快马平台轻松理解并解决战网更新睡眠问题
新手入门:借助快马平台轻松理解并解决战网更新睡眠问题 作为一个刚接触游戏客户端维护的新手,遇到战网更新服务进入睡眠模式的问题时,往往会感到无从下手。最近我在使用InsCode(快马)平台时,发现它可以帮助我们快速理解并解决这类…...