YOLOv9改进策略【卷积层】| AKConv: 具有任意采样形状和任意参数数量的卷积核
一、本文介绍
本文记录的是利用AKConv优化YOLOv9的目标检测网络模型。标准卷积操作的卷积运算局限于局部窗口,无法捕获其他位置的信息,且采样形状固定,无法适应不同数据集和位置中目标形状的变化。而AKConv旨在为卷积核提供任意数量的参数和任意采样形状,以在网络开销和性能之间提供更丰富的权衡选择。本文利用AKConv模块改进YOLOv9,来提高网络性能。
文章目录
- 一、本文介绍
- 二、AKConv介绍
- 2.1、AKConv原理
- 2.2、AKConv优势
- 三、AKConv的实现代码
- 四、添加步骤
- 4.1 修改common.py
- 4.1.1 基础模块1
- 4.1.2 创新模块2⭐
- 4.2 修改yolo.py
- 五、yaml模型文件
- 5.1 模型改进版本一
- 5.2 模型改进版本二⭐
- 六、成功运行结果
二、AKConv介绍
AKConv: 具有任意采样形状和任意参数数量的卷积核
2.1、AKConv原理
- 定义初始采样位置:
- 通过新的坐标生成算法为任意大小的卷积核定义初始位置。具体来说,先生成规则采样网格,再为剩余采样点创建不规则网格,最后拼接生成整体采样网格。以 3 × 3 3×3 3×3卷积操作为例,其采样网格 R = { ( − 1 , − 1 ) , ( − 1 , 0 ) , . . . , ( 0 , 1 ) , ( 1 , 1 ) } R = \{(-1,-1),(-1,0),...,(0,1),(1,1)\} R={(−1,−1),(−1,0),...,(0,1),(1,1)},但
AKConv针对不规则形状的卷积核,通过算法生成卷积核 P n P_n Pn的初始采样坐标。在算法中,将左上角 ( 0 , 0 ) (0, 0) (0,0)点设为采样原点。定义在位置 P 0 P_0 P0的相应卷积运算为 C o n v ( P 0 ) = ∑ w × ( P 0 + P n ) Conv(P_0) = \sum w \times (P_0 + P_n) Conv(P0)=∑w×(P0+Pn),其中 w w w表示卷积参数。
- 通过新的坐标生成算法为任意大小的卷积核定义初始位置。具体来说,先生成规则采样网格,再为剩余采样点创建不规则网格,最后拼接生成整体采样网格。以 3 × 3 3×3 3×3卷积操作为例,其采样网格 R = { ( − 1 , − 1 ) , ( − 1 , 0 ) , . . . , ( 0 , 1 ) , ( 1 , 1 ) } R = \{(-1,-1),(-1,0),...,(0,1),(1,1)\} R={(−1,−1),(−1,0),...,(0,1),(1,1)},但
- 可变卷积操作:
- 标准卷积采样位置固定,只能提取当前窗口的局部信息,无法捕获其他位置的信息。
Deformable Conv通过学习偏移来调整初始规则模式的采样网格,以弥补卷积操作的不足,但它和标准卷积不允许卷积核有任意数量的参数,且卷积参数随卷积核大小呈平方增长,对硬件环境不友好。 AKConv类似于Deformable Conv,先通过卷积操作获得对应核的偏移,其维度为 ( B , 2 N , H , W ) (B, 2N, H, W) (B,2N,H,W)( N N N为卷积核大小),然后通过偏移和原始坐标求和得到修改后的坐标,最后通过插值和重采样获得对应位置的特征。- 对于不规则卷积核难以提取对应采样位置特征的问题,可采用多种方法解决。例如,在
Deformable Conv和RFAConv中,通过在空间维度堆叠 3 × 3 3×3 3×3卷积特征,然后用步长为3的卷积操作提取特征,但此方法针对正方形采样形状。因此,可以将特征按行或列堆叠,使用列卷积或行卷积来提取对应不规则采样形状的特征;也可以将特征转换为四维 ( C , N , H , W ) (C, N, H, W) (C,N,H,W),然后用步长和卷积大小为 ( N , 1 , 1 ) (N,1,1) (N,1,1)的Conv3d提取特征;还可以将特征在通道维度堆叠为 ( C N , H , W ) (CN, H, W) (CN,H,W),然后用(1×1)卷积降维为 ( C , H , W ) (C, H, W) (C,H,W)。在AKConv中,按照上述方法对特征进行重塑并使用相应卷积操作即可提取对应特征。最终,AKConv通过不规则卷积完成特征提取过程,能根据偏移灵活调整样本形状,为卷积采样形状带来更多探索选项。
- 标准卷积采样位置固定,只能提取当前窗口的局部信息,无法捕获其他位置的信息。
- 扩展AKConv:
AKConv可以通过重新采样初始坐标呈现多种变化,即使不使用Deformable Conv中的偏移思想,也能实现多种卷积核形状。- 根据数据集目标形状的变化,设计对应采样形状的卷积操作,通过设计特定形状的初始采样形状来实现。例如,为长管状结构分割任务设计具有相应形状的采样坐标,但形状选择仅针对长管状结构。
AKConv真正实现了卷积核操作具有任意形状和数量的过程,能够使卷积核呈现多种形状。而Deformable Conv旨在弥补常规卷积的不足,DSConv针对特定对象形状设计,它们都没有探索任意大小和形状的卷积。AKConv通过Offset使卷积操作能高效提取不规则样本形状的特征,允许卷积有任意数量的卷积参数和多种形状。

2.2、AKConv优势
- 提高检测性能:在COCO2017、VOC 7 + 12和VisDrone - DET2021等数据集的目标检测实验中,AKConv显著提高了YOLOv5等模型的目标检测性能。例如,在COCO2017数据集上,当AKConv大小为5时,不仅使模型所需的参数和计算开销减少,还显著提高了YOLOv5n的检测精度, A P 50 AP_{50} AP50、 A P 75 AP_{75} AP75和 A P AP AP均提高了三个百分点,且对大物体的检测精度提升更为明显。
- 灵活的参数选择:与标准卷积和Deformable Conv相比,AKConv允许卷积参数数量呈线性增减,有利于硬件环境,可作为轻量级模型的替代选择,减少模型参数和计算开销。同时,在大内核且资源充足的情况下,它有更多选项来提高网络性能。
- 丰富的选择:与Deformable Conv不同,AKConv为网络提供了更丰富的选择,它可以使用规则和不规则卷积操作。当AKConv大小设置为(K)的平方时,它可以成为Deformable Conv,但Deformable Conv没有探索不规则卷积核大小,而AKConv可以实现参数为5和11等的卷积操作。
论文:https://arxiv.org/pdf/2311.11587v2
源码: https://github.com/CV-ZhangXin/AKConv
三、AKConv的实现代码
AKConv模块的实现代码如下:
from einops import rearrangeclass AKConv(nn.Module):def __init__(self, inc, outc, num_param=5, stride=1):super(AKConv, self).__init__()self.num_param = num_paramself.stride = strideself.conv = Conv(inc, outc, k=(num_param, 1), s=(num_param, 1) )self.p_conv = nn.Conv2d(inc, 2 * num_param, kernel_size=3, padding=1, stride=stride)nn.init.constant_(self.p_conv.weight, 0)self.p_conv.register_full_backward_hook(self._set_lr)@staticmethoddef _set_lr(module, grad_input, grad_output):grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))def forward(self, x):# N is num_param.offset = self.p_conv(x)dtype = offset.data.type()N = offset.size(1) // 2# (b, 2N, h, w)p = self._get_p(offset, dtype)# (b, h, w, 2N)p = p.contiguous().permute(0, 2, 3, 1)q_lt = p.detach().floor()q_rb = q_lt + 1q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2) - 1), torch.clamp(q_lt[..., N:], 0, x.size(3) - 1)],dim=-1).long()q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2) - 1), torch.clamp(q_rb[..., N:], 0, x.size(3) - 1)],dim=-1).long()q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)# clip pp = torch.cat([torch.clamp(p[..., :N], 0, x.size(2) - 1), torch.clamp(p[..., N:], 0, x.size(3) - 1)], dim=-1)# bilinear kernel (b, h, w, N)g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))# resampling the features based on the modified coordinates.x_q_lt = self._get_x_q(x, q_lt, N)x_q_rb = self._get_x_q(x, q_rb, N)x_q_lb = self._get_x_q(x, q_lb, N)x_q_rt = self._get_x_q(x, q_rt, N)# bilinearx_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \g_rb.unsqueeze(dim=1) * x_q_rb + \g_lb.unsqueeze(dim=1) * x_q_lb + \g_rt.unsqueeze(dim=1) * x_q_rtx_offset = self._reshape_x_offset(x_offset, self.num_param)out = self.conv(x_offset)return out# generating the inital sampled shapes for the AKConv with different sizes.def _get_p_n(self, N, dtype):base_int = round(math.sqrt(self.num_param))row_number = self.num_param // base_intmod_number = self.num_param % base_intp_n_x, p_n_y = torch.meshgrid(torch.arange(0, row_number),torch.arange(0, base_int), indexing='xy')p_n_x = torch.flatten(p_n_x)p_n_y = torch.flatten(p_n_y)if mod_number > 0:mod_p_n_x, mod_p_n_y = torch.meshgrid(torch.arange(row_number, row_number + 1),torch.arange(0, mod_number), indexing='xy')mod_p_n_x = torch.flatten(mod_p_n_x)mod_p_n_y = torch.flatten(mod_p_n_y)p_n_x, p_n_y = torch.cat((p_n_x, mod_p_n_x)), torch.cat((p_n_y, mod_p_n_y))p_n = torch.cat([p_n_x, p_n_y], 0)p_n = p_n.view(1, 2 * N, 1, 1).type(dtype)return p_n# no zero-paddingdef _get_p_0(self, h, w, N, dtype):p_0_x, p_0_y = torch.meshgrid(torch.arange(0, h * self.stride, self.stride),torch.arange(0, w * self.stride, self.stride), indexing='xy')p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)return p_0def _get_p(self, offset, dtype):N, h, w = offset.size(1) // 2, offset.size(2), offset.size(3)# (1, 2N, 1, 1)p_n = self._get_p_n(N, dtype)# (1, 2N, h, w)p_0 = self._get_p_0(h, w, N, dtype)p = p_0 + p_n + offsetreturn pdef _get_x_q(self, x, q, N):b, h, w, _ = q.size()padded_w = x.size(3)c = x.size(1)# (b, c, h*w)x = x.contiguous().view(b, c, -1)# (b, h, w, N)index = q[..., :N] * padded_w + q[..., N:] # offset_x*w + offset_y# (b, c, h*w*N)index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)return x_offset# Stacking resampled features in the row direction.@staticmethoddef _reshape_x_offset(x_offset, num_param):b, c, h, w, n = x_offset.size()x_offset = rearrange(x_offset, 'b c h w n -> b c (h n) w')return x_offset四、添加步骤
4.1 修改common.py
此处需要修改的文件是models/common.py
common.py中定义了网络结构的通用模块,我们想要加入新的模块就只需要将模块代码放到这个文件内即可。
4.1.1 基础模块1
模块改进方法1️⃣:直接加入AKConv模块。
将上方的实现代码粘贴到common.py文件夹下,AKConv模块添加后如下:

注意❗:在4.2小节中的yolo.py文件中需要声明的模块名称为:AKConv。
4.1.2 创新模块2⭐
模块改进方法2️⃣:基于AKConv的RepNCSPELAN4。
改进方法是对YOLOv9中的RepNCSPELAN4模块进行改进。在将AKConv模块与 RepNCSPELAN4 结合后,,AKConv通过提供任意参数数量和采样形状的卷积核,弥补了常规卷积的不足,提高了网络性能,为网络开销和性能的权衡提供了更多选择,并为YOLOv9提供更丰富的特征表示
改进代码如下:
class AKRepNCSPELAN4(nn.Module):# csp-elandef __init__(self, c1, c2, c3, c4, c5=1): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()self.c = c3//2self.cv1 = Conv(c1, c3, 1, 1)self.cv2 = nn.Sequential(RepNCSP(c3//2, c4, c5), AKConv(c4, c4))self.cv3 = nn.Sequential(RepNCSP(c4, c4, c5), AKConv(c4, c4))self.cv4 = Conv(c3+(2*c4), c2, 1, 1)def forward(self, x):y = list(self.cv1(x).chunk(2, 1))y.extend((m(y[-1])) for m in [self.cv2, self.cv3])return self.cv4(torch.cat(y, 1))def forward_split(self, x):y = list(self.cv1(x).split((self.c, self.c), 1))y.extend(m(y[-1]) for m in [self.cv2, self.cv3])return self.cv4(torch.cat(y, 1))

注意❗:在4.2小节中的yolo.py文件中需要声明的模块名称为:AKRepNCSPELAN4。
4.2 修改yolo.py
此处需要修改的文件是models/yolo.py
yolo.py用于函数调用,我们只需要将common.py中定义的新的模块名添加到parse_model函数下即可。
AKConv模块以及AKRepNCSPELAN4模块添加后如下:

五、yaml模型文件
5.1 模型改进版本一
在代码配置完成后,配置模型的YAML文件。
此处以models/detect/yolov9-c.yaml为例,在同目录下创建一个用于自己数据集训练的模型文件yolov9-c-AKConv.yaml。
将yolov9-c.yaml中的内容复制到yolov9-c-AKConv.yaml文件下,修改nc数量等于自己数据中目标的数量。
在骨干网络中,将四个RepNCSPELAN4模块替换成AKConv模块,注意修改函数中的参数。
# YOLOv9# parameters
nc: 1 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()# anchors
anchors: 3# YOLOv9 backbone
backbone:[[-1, 1, Silence, []], # conv down[-1, 1, Conv, [64, 3, 2]], # 1-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 2-P2/4# elan-1 block[-1, 1, AKConv, [256]], # 3# avg-conv down[-1, 1, ADown, [256]], # 4-P3/8# elan-2 block[-1, 1, AKConv, [512]], # 5# avg-conv down[-1, 1, ADown, [512]], # 6-P4/16# elan-2 block[-1, 1, AKConv, [512]], # 7(可替换)# avg-conv down[-1, 1, ADown, [512]], # 8-P5/32# elan-2 block[-1, 1, AKConv, [512]], # 9(可替换)]# YOLOv9 head
head:[# elan-spp block[-1, 1, SPPELAN, [512, 256]], # 10# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 7], 1, Concat, [1]], # cat backbone P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 13# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3# elan-2 block[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 16 (P3/8-small)# avg-conv-down merge[-1, 1, ADown, [256]],[[-1, 13], 1, Concat, [1]], # cat head P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 19 (P4/16-medium)# avg-conv-down merge[-1, 1, ADown, [512]],[[-1, 10], 1, Concat, [1]], # cat head P5# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 22 (P5/32-large)# multi-level reversible auxiliary branch# routing[5, 1, CBLinear, [[256]]], # 23[7, 1, CBLinear, [[256, 512]]], # 24[9, 1, CBLinear, [[256, 512, 512]]], # 25# conv down[0, 1, Conv, [64, 3, 2]], # 26-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 27-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 28# avg-conv down fuse[-1, 1, ADown, [256]], # 29-P3/8[[23, 24, 25, -1], 1, CBFuse, [[0, 0, 0]]], # 30 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 31# avg-conv down fuse[-1, 1, ADown, [512]], # 32-P4/16[[24, 25, -1], 1, CBFuse, [[1, 1]]], # 33 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 34# avg-conv down fuse[-1, 1, ADown, [512]], # 35-P5/32[[25, -1], 1, CBFuse, [[2]]], # 36# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 37# detection head# detect[[31, 34, 37, 16, 19, 22], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)]5.2 模型改进版本二⭐
此处同样以models/detect/yolov9-c.yaml为例,在同目录下创建一个用于自己数据集训练的模型文件yolov9-c-AKRepNCSPELAN4.yaml。
将yolov9-c.yaml中的内容复制到yolov9-c-AKRepNCSPELAN4.yaml文件下,修改nc数量等于自己数据中目标的数量。
📌 模型的修改方法是将骨干网络中的所有RepNCSPELAN4模块替换成AKRepNCSPELAN4模块。
# YOLOv9# parameters
nc: 1 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()# anchors
anchors: 3# YOLOv9 backbone
backbone:[[-1, 1, Silence, []], # conv down[-1, 1, Conv, [64, 3, 2]], # 1-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 2-P2/4# elan-1 block[-1, 1, AKRepNCSPELAN4, [256, 128, 64, 1]], # 3# avg-conv down[-1, 1, ADown, [256]], # 4-P3/8# elan-2 block[-1, 1, AKRepNCSPELAN4, [512, 256, 128, 1]], # 5# avg-conv down[-1, 1, ADown, [512]], # 6-P4/16# elan-2 block[-1, 1, AKRepNCSPELAN4, [512, 512, 256, 1]], # 7(可替换)# avg-conv down[-1, 1, ADown, [512]], # 8-P5/32# elan-2 block[-1, 1, AKRepNCSPELAN4, [512, 512, 256, 1]], # 9(可替换)]# YOLOv9 head
head:[# elan-spp block[-1, 1, SPPELAN, [512, 256]], # 10# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 7], 1, Concat, [1]], # cat backbone P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 13# up-concat merge[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 5], 1, Concat, [1]], # cat backbone P3# elan-2 block[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 16 (P3/8-small)# avg-conv-down merge[-1, 1, ADown, [256]],[[-1, 13], 1, Concat, [1]], # cat head P4# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 19 (P4/16-medium)# avg-conv-down merge[-1, 1, ADown, [512]],[[-1, 10], 1, Concat, [1]], # cat head P5# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 22 (P5/32-large)# multi-level reversible auxiliary branch# routing[5, 1, CBLinear, [[256]]], # 23[7, 1, CBLinear, [[256, 512]]], # 24[9, 1, CBLinear, [[256, 512, 512]]], # 25# conv down[0, 1, Conv, [64, 3, 2]], # 26-P1/2# conv down[-1, 1, Conv, [128, 3, 2]], # 27-P2/4# elan-1 block[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 28# avg-conv down fuse[-1, 1, ADown, [256]], # 29-P3/8[[23, 24, 25, -1], 1, CBFuse, [[0, 0, 0]]], # 30 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 31# avg-conv down fuse[-1, 1, ADown, [512]], # 32-P4/16[[24, 25, -1], 1, CBFuse, [[1, 1]]], # 33 # elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 34# avg-conv down fuse[-1, 1, ADown, [512]], # 35-P5/32[[25, -1], 1, CBFuse, [[2]]], # 36# elan-2 block[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 37# detection head# detect[[31, 34, 37, 16, 19, 22], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)]六、成功运行结果
分别打印网络模型可以看到AKConv模块和AKRepNCSPELAN4模块已经加入到模型中,并可以进行训练了。
yolov9-c-AKConv:
from n params module arguments 0 -1 1 0 models.common.Silence [] 1 -1 1 1856 models.common.Conv [3, 64, 3, 2] 2 -1 1 73984 models.common.Conv [64, 128, 3, 2] 3 -1 1 175882 models.common.AKConv [128, 256] 4 -1 1 164352 models.common.ADown [256, 256] 5 -1 1 679434 models.common.AKConv [256, 512] 6 -1 1 656384 models.common.ADown [512, 512] 7 -1 1 1357834 models.common.AKConv [512, 512] 8 -1 1 656384 models.common.ADown [512, 512] 9 -1 1 1357834 models.common.AKConv [512, 512] 10 -1 1 656896 models.common.SPPELAN [512, 512, 256] 11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 12 [-1, 7] 1 0 models.common.Concat [1] 13 -1 1 3119616 models.common.RepNCSPELAN4 [1024, 512, 512, 256, 1] 14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 15 [-1, 5] 1 0 models.common.Concat [1] 16 -1 1 912640 models.common.RepNCSPELAN4 [1024, 256, 256, 128, 1] 17 -1 1 164352 models.common.ADown [256, 256] 18 [-1, 13] 1 0 models.common.Concat [1] 19 -1 1 2988544 models.common.RepNCSPELAN4 [768, 512, 512, 256, 1] 20 -1 1 656384 models.common.ADown [512, 512] 21 [-1, 10] 1 0 models.common.Concat [1] 22 -1 1 3119616 models.common.RepNCSPELAN4 [1024, 512, 512, 256, 1] 23 5 1 131328 models.common.CBLinear [512, [256]] 24 7 1 393984 models.common.CBLinear [512, [256, 512]] 25 9 1 656640 models.common.CBLinear [512, [256, 512, 512]] 26 0 1 1856 models.common.Conv [3, 64, 3, 2] 27 -1 1 73984 models.common.Conv [64, 128, 3, 2] 28 -1 1 212864 models.common.RepNCSPELAN4 [128, 256, 128, 64, 1] 29 -1 1 164352 models.common.ADown [256, 256] 30 [23, 24, 25, -1] 1 0 models.common.CBFuse [[0, 0, 0]] 31 -1 1 847616 models.common.RepNCSPELAN4 [256, 512, 256, 128, 1] 32 -1 1 656384 models.common.ADown [512, 512] 33 [24, 25, -1] 1 0 models.common.CBFuse [[1, 1]] 34 -1 1 2857472 models.common.RepNCSPELAN4 [512, 512, 512, 256, 1] 35 -1 1 656384 models.common.ADown [512, 512] 36 [25, -1] 1 0 models.common.CBFuse [[2]] 37 -1 1 2857472 models.common.RepNCSPELAN4 [512, 512, 512, 256, 1] 38[31, 34, 37, 16, 19, 22] 1 21542822 DualDDetect [1, [512, 512, 512, 256, 512, 512]]
yolov9-c-AKConv summary: 730 layers, 47795150 parameters, 47795118 gradients, 228.7 GFLOPs
yolov9-c-AKRepNCSPELAN4:
from n params module arguments 0 -1 1 0 models.common.Silence [] 1 -1 1 1856 models.common.Conv [3, 64, 3, 2] 2 -1 1 73984 models.common.Conv [64, 128, 3, 2] 3 -1 1 191636 models.common.AKRepNCSPELAN4 [128, 256, 128, 64, 1] 4 -1 1 164352 models.common.ADown [256, 256] 5 -1 1 739604 models.common.AKRepNCSPELAN4 [256, 512, 256, 128, 1] 6 -1 1 656384 models.common.ADown [512, 512] 7 -1 1 2379284 models.common.AKRepNCSPELAN4 [512, 512, 512, 256, 1] 8 -1 1 656384 models.common.ADown [512, 512] 9 -1 1 2379284 models.common.AKRepNCSPELAN4 [512, 512, 512, 256, 1] 10 -1 1 656896 models.common.SPPELAN [512, 512, 256] 11 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 12 [-1, 7] 1 0 models.common.Concat [1] 13 -1 1 3119616 models.common.RepNCSPELAN4 [1024, 512, 512, 256, 1] 14 -1 1 0 torch.nn.modules.upsampling.Upsample [None, 2, 'nearest'] 15 [-1, 5] 1 0 models.common.Concat [1] 16 -1 1 912640 models.common.RepNCSPELAN4 [1024, 256, 256, 128, 1] 17 -1 1 164352 models.common.ADown [256, 256] 18 [-1, 13] 1 0 models.common.Concat [1] 19 -1 1 2988544 models.common.RepNCSPELAN4 [768, 512, 512, 256, 1] 20 -1 1 656384 models.common.ADown [512, 512] 21 [-1, 10] 1 0 models.common.Concat [1] 22 -1 1 3119616 models.common.RepNCSPELAN4 [1024, 512, 512, 256, 1] 23 5 1 131328 models.common.CBLinear [512, [256]] 24 7 1 393984 models.common.CBLinear [512, [256, 512]] 25 9 1 656640 models.common.CBLinear [512, [256, 512, 512]] 26 0 1 1856 models.common.Conv [3, 64, 3, 2] 27 -1 1 73984 models.common.Conv [64, 128, 3, 2] 28 -1 1 212864 models.common.RepNCSPELAN4 [128, 256, 128, 64, 1] 29 -1 1 164352 models.common.ADown [256, 256] 30 [23, 24, 25, -1] 1 0 models.common.CBFuse [[0, 0, 0]] 31 -1 1 847616 models.common.RepNCSPELAN4 [256, 512, 256, 128, 1] 32 -1 1 656384 models.common.ADown [512, 512] 33 [24, 25, -1] 1 0 models.common.CBFuse [[1, 1]] 34 -1 1 2857472 models.common.RepNCSPELAN4 [512, 512, 512, 256, 1] 35 -1 1 656384 models.common.ADown [512, 512] 36 [25, -1] 1 0 models.common.CBFuse [[2]] 37 -1 1 2857472 models.common.RepNCSPELAN4 [512, 512, 512, 256, 1] 38[31, 34, 37, 16, 19, 22] 1 21542822 DualDDetect [1, [512, 512, 512, 256, 512, 512]]
yolov9-c-AKRepNCSPELAN4 summary: 978 layers, 49913974 parameters, 49913942 gradients, 234.5 GFLOPs
相关文章:
YOLOv9改进策略【卷积层】| AKConv: 具有任意采样形状和任意参数数量的卷积核
一、本文介绍 本文记录的是利用AKConv优化YOLOv9的目标检测网络模型。标准卷积操作的卷积运算局限于局部窗口,无法捕获其他位置的信息,且采样形状固定,无法适应不同数据集和位置中目标形状的变化。而AKConv旨在为卷积核提供任意数量的参数和…...

图神经网络池化方法
图神经网络池化方法 提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 图神经网络池化方法前言一、扁平图池化二、分层图池化1.节点聚类池化2.节点丢弃池化 参考文献 前言 图池化操作根据其池化策略的差异ÿ…...

小琳AI课堂:确保大语言模型安全的八大策略--从数据隐私到用户教育
大家好,这里是小琳AI课堂。今天我们深入探讨如何保证大语言模型的安全,这可是关系到我们每个人哦!🔐 首先,我们要明白,保证大语言模型的安全,需要从多个方面入手,确保模型在技术、法…...

Python 数学建模——高斯核密度估计
文章目录 前言原理代码实例scipy 实现seaborn 实现 前言 高斯核密度估计本是一种机器学习算法,在数学建模中也可以发挥作用。本文主要讨论用它来拟合变量的概率密度,获得概率密度函数 f ( x ) f(x) f(x)。 原理 已知一个连续型随机变量 X X X 的一系列…...

Flink+Spark相关记录
FlinkSpark相关记录 FlinkSQL Flink Streaming的一些点覆写RichSource、RichSink、RichMap 1.Source自动负载均衡,CDC源端加入一个全局调控的节点监控流量流速 2.Sink并发写入 3.Map与Iterator与增量迭代等用法关于Checkpoint几个用法 1.提交Commit至目的端数据库 2…...

2023 hnust 湖科大 毕业实习 报告+实习鉴定表
2023 hnust 湖科大 毕业实习 报告实习鉴定表 岗位 IT公司机房运维 实习报告 实习鉴定表 常见疑问 hnust 湖科大 毕业实习常见问题30问(2021 年7月,V0.9)-CSDN博客时间:大四开学第三四周毕业实习23年是企业(黑马&am…...

ConflictingBeanDefinitionException | 运行SpringBoot项目时报错bean定义冲突解决方案
具体报错: Caused by: org.springframework.context.annotation.ConflictingBeanDefinitionException: Annotation-specified bean name ‘CommissionMapperImpl’ for bean class [com.xxx.mapper.carrier.CommissionMapperImpl] conflicts with existing, non-co…...
【2024版】)
如何切换淘宝最新镜像源(npm)【2024版】
在使用 Node.js 和 npm 进行开发时,大家通常会遇到 npm 源速度较慢的问题。特别是当你需要安装大量依赖时,npm 官方源的速度可能不尽如人意。幸运的是,淘宝提供了一个更快速的 npm 镜像源,可以让你更快地下载和安装包。本文将介绍…...
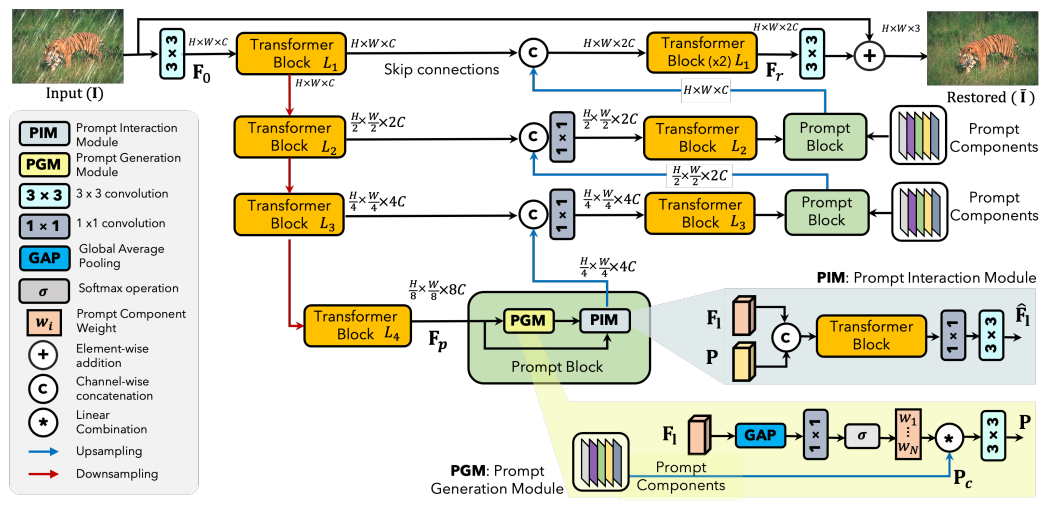
YoloV10改进策略:Block改进|PromptIR(NIPS‘2023)|轻量高效,即插即用|(适用于分类、分割、检测等多种场景)
文章目录 摘要代码详解如何在自己的论文中描述改进方法测试结果总结摘要 本文使用PromptIR框架中的PGM模块来改进YoloV10。PGM(Prompt Generation Module)模块是PromptIR框架中的一个重要组成部分,主要负责生成输入条件化的提示(prompts)。这些提示是一组可学习的参数,它…...

使用rust自制操作系统内核
一、系统简介 本操作系统是一个使用rust语言实现,基于32位的x86CPU的分时操作系统。 项目地址(求star):GitHub - CaoGaorong/os-in-rust: 使用rust实现一个操作系统内核 详细文档:自制操作系统 语雀 1. 项目特性 …...

Flink难点和高阶面试题:Flink的状态管理机制如何保证数据处理的准确性和完整性
1 Flink状态管理机制核心要素 1.1 内置状态后端 在Apache Flink中,状态管理机制是确保数据处理准确性与完整性的关键环节。其核心在于灵活且高效的状态后端,这些后端负责在分布式环境中安全地存储和访问状态数据。Flink提供了多种内置状态后端,其中RocksDB和内存状态后端最…...

【激励广告带来的广告收入与用户留存率的双重提升】
激励广告带来的广告收入与用户留存率的双重提升 ) 随着移动应用市场的竞争加剧,如何通过广告变现成为众多开发者关注的焦点。其中,激励广告(Rewarded Ads)凭借其用户友好、互动性强等特点,逐渐成为开发者的首选。那些…...

指针和引用;内联函数和普通函数
1. 指针和引用 1.1 定义和性质区别 指针是一个变量,只不过这个变量存储的是一个地址,指向内存的一个存储单元;而引用跟原来的变量实质上是同一个东西,只不过是原变量的一个别名而已。可以有const指针,常量指针可以改…...

简单题67.二进制求和 (java)20240919
题目描述: Java: class Solution {public String addBinary(String a, String b) {StringBuilder result new StringBuilder();int i a.length()-1;int j b.length()-1;int carry 0; //记录进位信息while(i>0 || j>0 || carry!0){int sum ca…...

DDD的主要流程
DDD 开发流程分为模型的建立和模型的实现两大部分,接下来是具体的流程讲解以及流程图。 1. 模型的建立 捕获行为需求:在这一阶段,团队要识别系统中需要完成的任务、操作流程、功能需求以及每个功能由谁操作、会产生什么结果。我们可以通过 …...

linux驱动开发-设备树
设备树的历史背景 背景: 在早期的嵌入式系统中,硬件配置信息通常硬编码在内核源码中,这导致了内核代码的冗长和难以维护。 为了解决这个问题,设备树(Device Tree)被引入,使得硬件描述与内核代…...

数据结构——二叉树堆的专题
1.堆的概念及结构 如果有一个关键码的集合K {K0 ,K1 ,K2 ,K3…,K(N-1) },把它的所有元素按完全二叉树的顺序存储方式存储 在一个一维数组中,并满足:Ki < K2*i1且 Ki<K2*i2 ) i 0&#…...

【C语言零基础入门篇 - 7】:拆解函数的奥秘:定义、声明、变量,传递须知,嵌套玩转,递归惊艳
文章目录 函数函数的定义与声明局部变量和全局变量、静态变量静态变量和动态变量函数的值传递函数参数的地址传值 函数的嵌套使用函数的递归调用 函数 函数的定义与声明 函数的概念:函数是C语言项目的基本组成单位。实现一个功能可以封装一个函数来实现。定义函数的…...

ClickHouse在AI领域的结合应用
文章目录 引言1.1 人工智能与大数据的融合1.2 ClickHouse在大数据平台中的地位2.1 BI与AI的融合从传统BI到智能BIAI赋能BI融合的优势实际应用案例 2.2 异构数据处理的重要性数据多样性的挑战异构数据处理的需求技术实现实际应用案例 2.3 向量检索与AIOps技术向量检索的背景AIOp…...

git push出错Push cannot contain secrets
报错原因: 因为你的代码里面包含了github token明文信息,github担心你的token会泄漏,所以就不允许你推送这些内容。 解决办法: 需要先把代码里面的github token信息删除掉,并且删掉之前的历史提交,只要包…...

SwitchyOmega+Burp无感抓包实战:解决HTTPS拦截与流量路由难题
1. 为什么“无感抓包”是BurpSuite日常使用的分水岭刚接触Web安全测试的朋友常有个错觉:装上Burp Suite,配好代理,打开浏览器,点几下网页——流量就该自动进来了。结果现实是:首页打不开、登录态丢失、HTTPS报错满屏、…...

第3篇:系统透视——信息部门如何构建“税务友好型”IT架构
本篇导读:如果你是信息总监或IT负责人,请通读全文,尤其是“系统合规设计的三必须”和“现场检查SOP”;如果你是财税人员,请重点阅读“研产供销全链条的系统对接要求”和“与IT部门的协作要点”;如果你是老板…...

2026这6款神级降AIGC平台大公开,一键让AIGC率直逼绝对安全线!
步入 2026 年,学术圈的风向早已不是从前的模样。曾经大家还在为查重率发愁,如今却陷入了更棘手的困境——如何在不破坏论文专业性的前提下,彻底消除 AI 痕迹?随着 AIGC 检测技术不断进化,高校对论文的审核标准也愈发严…...

GEO优化可以覆盖哪些搜索平台
这是一个非常现实的问题。企业投放资源做GEO,当然希望覆盖面越广越好。那么GEO优化到底能覆盖哪些平台?覆盖到什么程度?不同平台的GEO逻辑有什么差异?GEO平台覆盖的三个层级第一层级:通用大模型AI平台(核心…...

猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧
猫抓浏览器扩展终极指南:5分钟掌握全网视频资源下载技巧 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 你是否经常遇到心仪的视频无法…...

如何快速无损转换B站m4s视频:完整工具使用指南
如何快速无损转换B站m4s视频:完整工具使用指南 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是否曾为B站缓存视频无法在其他设备…...

MPC Video Renderer终极指南:如何在Windows上实现专业级视频渲染体验
MPC Video Renderer终极指南:如何在Windows上实现专业级视频渲染体验 【免费下载链接】VideoRenderer Внешний видео-рендерер 项目地址: https://gitcode.com/gh_mirrors/vi/VideoRenderer MPC Video Renderer是一款专为Windows平台设计…...

3步掌握OpenSpeedy:免费开源游戏加速工具使用指南
3步掌握OpenSpeedy:免费开源游戏加速工具使用指南 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy 你是否曾为游戏卡顿而烦恼?是否希望在单机游戏中加快…...

终极免费解决方案:如何用Neat Bookmarks拯救你混乱的Chrome书签
终极免费解决方案:如何用Neat Bookmarks拯救你混乱的Chrome书签 【免费下载链接】neat-bookmarks A neat bookmarks tree popup extension for Chrome [DISCONTINUED] 项目地址: https://gitcode.com/gh_mirrors/ne/neat-bookmarks 还在为满屏混乱的Chrome书…...
)
别再乱用Bool和Enum了!用UE5的Gameplay Tags重构你的角色状态机(GAS避坑指南)
别再乱用Bool和Enum了!用UE5的Gameplay Tags重构你的角色状态机(GAS避坑指南)当你的ARPG角色同时陷入眩晕、灼烧和减速状态时,传统状态机往往会暴露出致命缺陷——布尔值互相覆盖、枚举组合爆炸、条件判断嵌套成灾。而UE5的Gamepl…...