排序学习笔记
目录
- 排序
- 排序的相关概念
- 冒泡排序
- 插入排序
- 选择排序
- 堆排序
- 快速排序
- 归并排序
- 内排序和外排序
- 非比较排序
- 稳定性
- 稳定性
- 完
排序
排序的相关概念
排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起来的操作。
稳定性:假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次
序保持不变,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序后的序列中,r[i]仍在r[j]之前,则称这种排
序算法是稳定的;否则称为不稳定的。
内部排序:数据元素全部放在内存中的排序。
外部排序:数据元素太多不能同时放在内存中,根据排序过程的要求不能在内外存之间移动数据的排序。
在接下来的学习过程中,我们将会遇到许多排序算法,这些排序算法各有各的优缺点,也因此应用于不同的场景。
冒泡排序
冒泡排序将数组分为两个部分:比较区和保护区。比较区负责存储将要比较的数据,保护区负责存储已经排完序的数据。比较区的每轮比较,将会从数组首元素开始,接着,将两两相邻元素进行比较,从而将比较区的极值移至比较区末尾;在比较区比完一轮后,比较区的最后一个元素就会并入保护区,随后进行下一轮比较。
如果某轮比较区的比较都是合法的(符合相对大小),则证明此时比较区已经有序,不需要再进行比较,比较区就会整体并入保护区。

思路明白之后,写代码就不难了:
typedef int SortData, * pSortData;bool compare(SortData val1, SortData val2)
{if (val1 > val2)return true;elsereturn false;
}void Swap(pSortData p1, pSortData p2)
{SortData transitory = *p1;*p1 = *p2;*p2 = transitory;
}
void Bubble_sort(pSortData pArray, int Size)
{int i = 0;int j = 0;for (i = 0; i < Size - 1; i++){bool falg = true;for (j = 0; j < Size - i - 1; j++){if (compare(pArray[j], pArray[j + 1])){Swap(&pArray[j], &pArray[j + 1]);falg = false;}}if (falg)break;}
}
为了提高排序算法对不同数据类型的适用性,我们使用compare来定义比较元素的相对大小关系,后续排序算法中,若涉及到对元素的比较,则全部通过调用该函数实现。另外,考虑到后续算法可能经常遇到数据交换问题,所以交换函数也专门写出。
为了对冒泡排序进行测试,还需要定义一些外围函数。
pSortData BulidArray(int Size)
{pSortData pArray = (pSortData)malloc(sizeof(SortData)* Size);if (pArray == NULL){perror("BulidArray malloc fail");return NULL;}int circuit = 0;for (; circuit < Size; circuit++){pArray[circuit] = rand();}return pArray;
}void pArrayPrintf(pSortData pArray, int Size)
{int circuit = 0;for (; circuit < Size; circuit++){printf("%d ",pArray[circuit]);}printf("\n");
}
测试(为了让程序以最优性能运行,请将版本改为Release)
void test1()
{int Size = 10;pSortData pArray = BulidArray(Size);int circuit = 0;printf("The contents of the original array:\n");pArrayPrintf(pArray, Size);Bubble_sort(pArray, Size);printf("\nThe contents of the sorted array:\n");pArrayPrintf(pArray, Size);free(pArray);pArray = NULL;
}int main()
{ srand((unsigned int)time(NULL));test1();return 0;
}
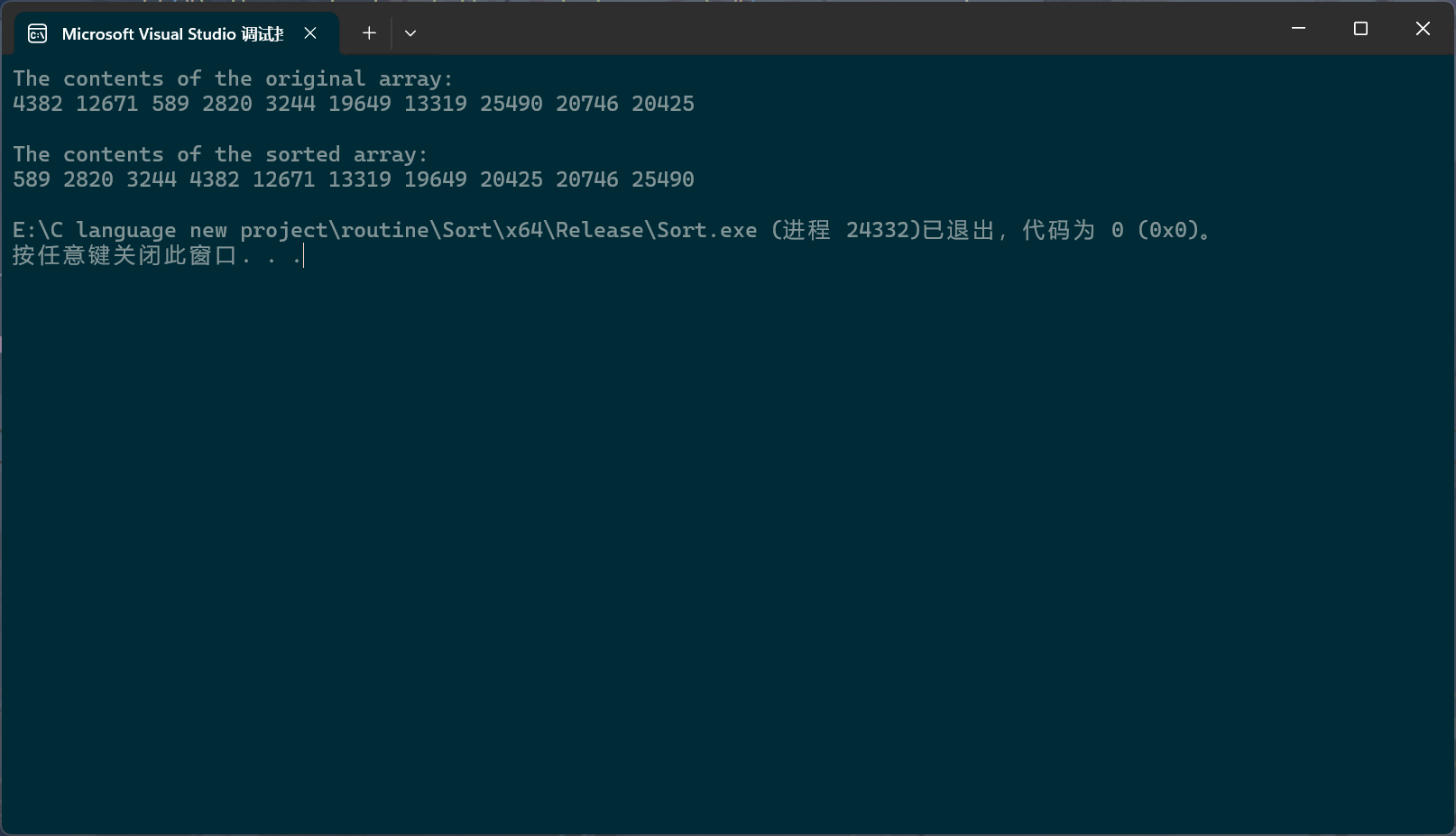
可以看到,测试是通过的。
后续还会对其它排序算法进行测试,测试的大致思路都和test1()相同,只不过调用的排序算法不同,这就会使得test系列函数过于重复冗余。为此,我们可以用宏定义的方式生成对应的排序算法测试函数。
#define PerformanceTesting(NumSize, Proceedings) \void test_##Proceedings() \{ \printf("The test begins.\n"); \printf("The subroutine tested is " #Proceedings ".\n"); \printf("The number of array members is " #NumSize ".\n"); \srand((unsigned int)time(NULL)); \int Size = NumSize; \pSortData pArray = BulidArray(Size); \int circuit = 0; \printf("\nThe contents of the original array:\n"); \pArrayPrintf(pArray, Size); \clock_t begin = clock(); \Proceedings(pArray, Size); \clock_t end = clock(); \printf("\nThe contents of the sorted array:\n"); \pArrayPrintf(pArray, Size); \free(pArray); \pArray = NULL; \printf("\nEnd of test.\n"); \printf("The " #Proceedings " runtime is %dms.\n", end-begin); \}
这个宏定义生成的测试函数将会打印测试的相关信息。clock()用于获取从程序启动到clock()执行的间隔时间,单位为毫秒;它的返回值为clock_t(long)类型,两个clock_t一减,就会粗略获得排序算法的运行时间。
PerformanceTesting(10, Bubble_sort)int main()
{ test_Bubble_sort();return 0;
}
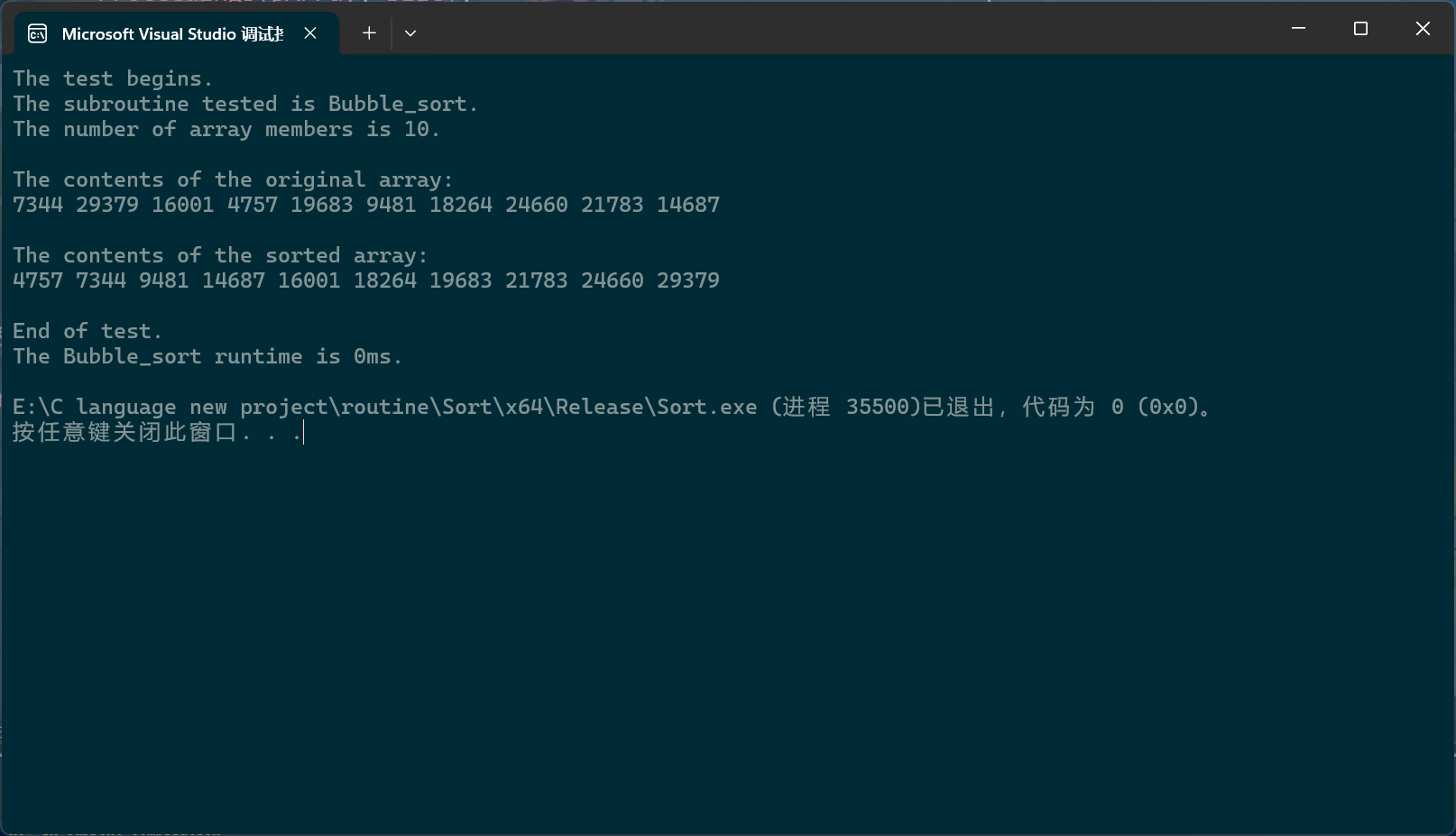
这里显示0毫秒是因为单位的精确度不够,数组成员的个数过少,可以换个数。
PerformanceTesting(10000, Bubble_sort)int main()
{ test_Bubble_sort();return 0;
}
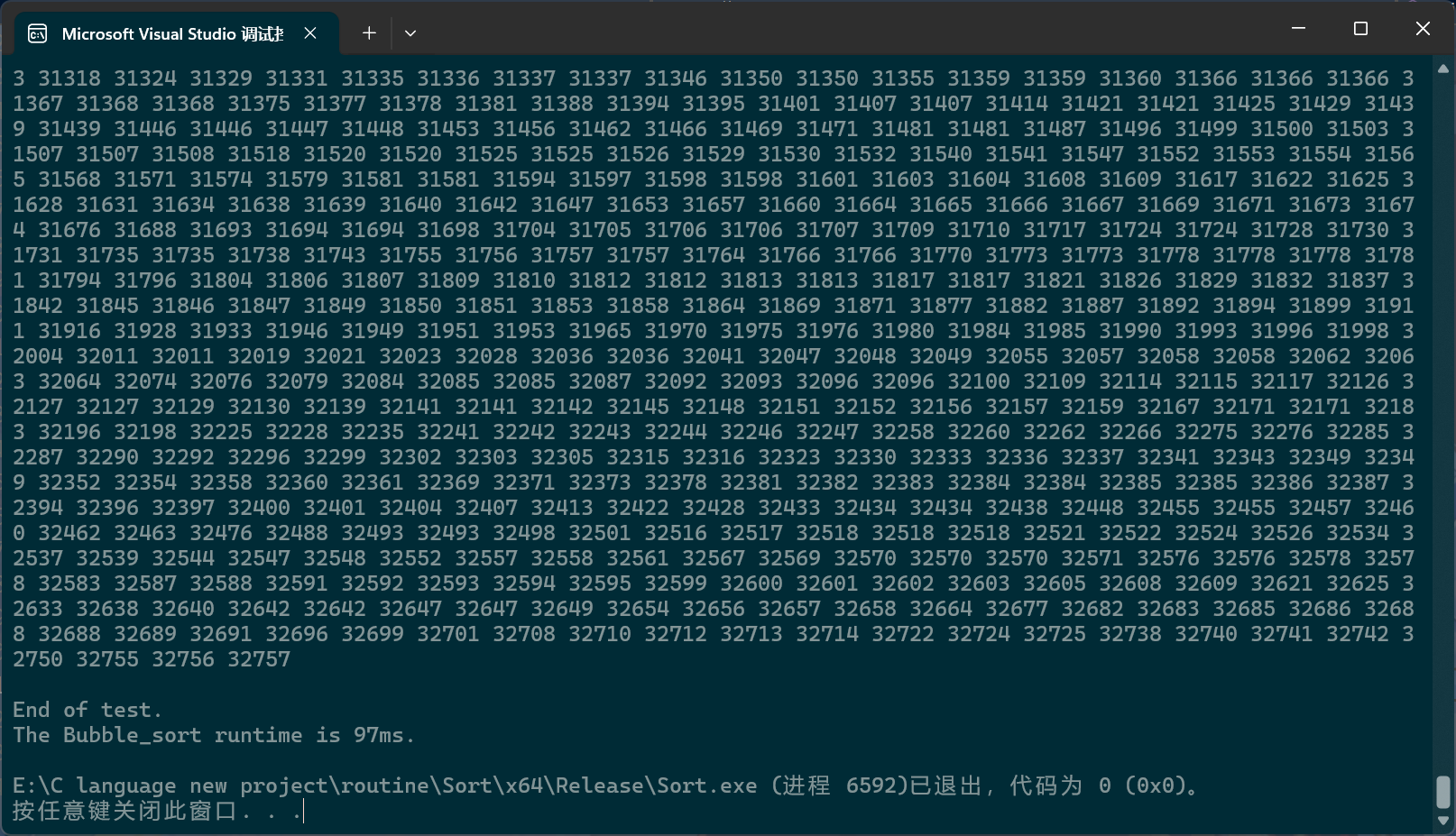
插入排序
插入排序的主题思想是将要排序的值依据相对大小关系插入到一个已经有序的结构中。由于单个元素是无法比较的,所以单个成员就可以视为有序的结构,所以插入排序最开始是将首元素作为那个有序结构,随后在此基础上,对剩余元素逐个插入。插入排序分为两种:连续型和离散型。
我们先说连续型,也叫直接插入排序。

实际代码与动图并不完全相同,实际代码是将对比区的首元素临时拷贝一份,这里的删除实际是覆写,但为了更好理解,动图忽略了这些细节。
当对比区首元素与保护区的元素逐个对比时,会出现三种情况:
- 符合排序规则,那就将拷贝数据写入保护区对比元素之后
- 不符合排序规则,那就将保护区对比元素向后挪一位
- 不符合排序规则,且保护区里的元素全部都比完了,就把拷贝数据写入保护区首元素
因此,最初的代码大概是这样的:
void Insert_sort(pSortData pArray, int Size)
{int compare_begin, protection_compare;SortData temporary_storage;for (compare_begin = 1; compare_begin < Size; compare_begin++){temporary_storage = pArray[compare_begin];for (protection_compare = compare_begin - 1; protection_compare >= 0; protection_compare--){if (compare(pArray[protection_compare], temporary_storage)){pArray[protection_compare + 1] = pArray[protection_compare];}else{pArray[protection_compare + 1] = temporary_storage;break;}}if(protection_compare == -1){pArray[protection_compare + 1] = temporary_storage;}}
}
当遇到第一种情况时,也就是符合规则的情况时,由于循环是break出的,所以protection_compare并不会改变,因此,后面的if(protection_compare == -1)其实也不用写,于是第一种和第三种情况就可以共用一份代码:
void Insert_sort(pSortData pArray, int Size)
{int compare_begin, protection_compare;SortData temporary_storage;for (compare_begin = 1; compare_begin < Size; compare_begin++){temporary_storage = pArray[compare_begin];for (protection_compare = compare_begin - 1; protection_compare >= 0; protection_compare--){if (compare(pArray[protection_compare], temporary_storage)){pArray[protection_compare + 1] = pArray[protection_compare];}else{break;}}pArray[protection_compare + 1] = temporary_storage;}
}
让我们来测试一下:
PerformanceTesting(10, Insert_sort)int main()
{ test_Insert_sort();return 0;
}
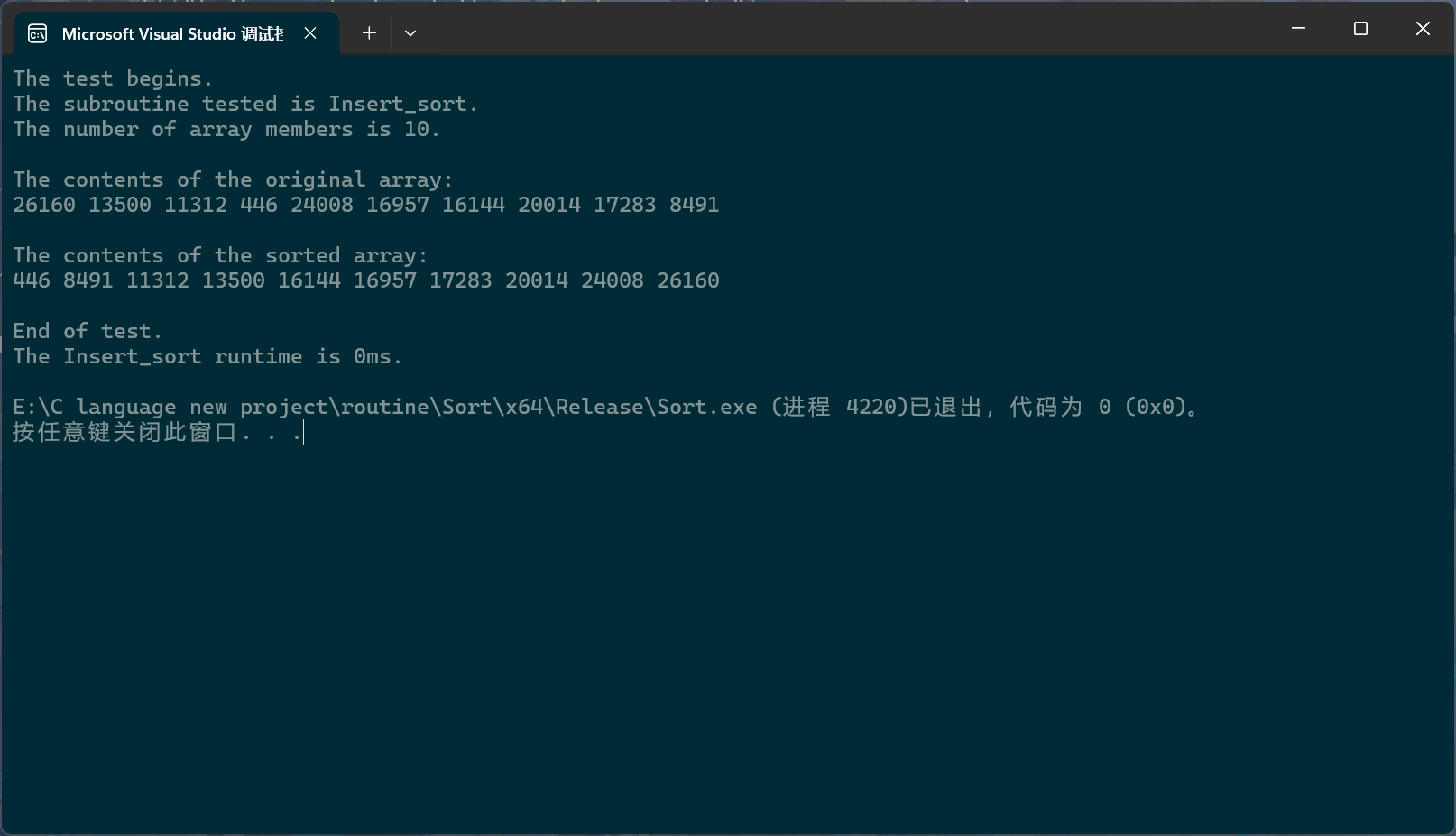
直接插入排序的时间复杂度是标准的等差数列,所以时间复杂度就不细说了,就是 0 ( N 2 ) 0(N^2) 0(N2)。不过对于直接插入排序来说,不太容易真的出现 N 2 N^2 N2级别的时间复杂度;出现 N 2 N^2 N2级别的时间复杂度意味着每次比较都是第三种情况,此时的数据其实就是逆序结构。比如在上面的例子中,直接排序会把输入的数组转化为升序数组,如果出现 N 2 N^2 N2级别的时间复杂度,那就意味着输入的数组就是降序数组。
所以对于直接插入排序来说,除了要知道我们通常说的最坏情况的时间复杂度之外,还要知道最好情况的复杂度,什么时候复杂度最好呢?观看上面的动图你可以发现,有些首元素被拷贝之后,直接就被放回了原位,如果每次比较都是这种情况,那就是最好情况。此时直接插入排序的时间复杂度就为 O ( N ) O(N) O(N),和最坏情况一样,这种级别的复杂度也很难遇到,遇到这种级别的复杂度,意味着,输入的数组就是顺序数组。
虽然冒泡排序和直接插入排序的时间复杂度(通常说的那个时间复杂度)都是 O ( N 2 ) O(N^2) O(N2),但直接插入排序优于冒泡排序。设想这样一种场景:现在需要将输入的数组转化为升序数组,但恰巧数组第一个元素就是最大值,很明显要把这个最大的元素移到最后一位。对于这种数组,直接插入每轮比较都顺手把这个最大的值向后移动一位,每轮比较都是有配合的;而对于冒泡排序来说,各轮比较像是各干各的,每轮比较只负责把极值推到最后。
接下来我们学习离散式插入排序,更多人将其称为希尔排序。
从前面的过程中,我们可以看到,无论是冒泡排序还是直接插入排序,某个数据到达它应有的位置都必须一步一步地移动,最起码在逻辑层面上,数据都是连续移动的,这正是“连续”的一种体现;
有没有少走两步的方法呢?当然是有的,这就引申出了“预排序”的概念。预排序的目的是让数组接近有序,大体上有序,之后再进行一次直接插入排序,从而减少直接插入排序的移动次数。
预排序的具体做法是将原先排序的数组,分为独立的几个部分,这几个独立数组中的成员在原先数组中并不是连续的,而是相隔一定单位的,随后在对这些独立的数组分别进行直接插入。
这里我们暂且将“一定单位”设为3。

经过预排序的数组相比未经过预排序的数组相比,在进行直接插入排序时,会出现更多每轮比较只进行一次的情况,算法的时间复杂度将更加靠近 O ( N ) O(N) O(N)。
不过在实际代码中,并不是真的把这一个数组分成独立的几个小数组。而是让下标由每次加一变成每次加一定单位。
void Shell_sort(pSortData pArray, int Size)
{//preorderint intervals = 3;int initial, compare_begin, protection_compare;SortData replica;for (initial = 0; initial < intervals; initial++){for (compare_begin = initial + intervals; compare_begin < Size; compare_begin += intervals){replica = pArray[compare_begin];for (protection_compare = compare_begin - intervals; protection_compare >= 0; protection_compare -= intervals){if (compare(pArray[protection_compare], replica)){pArray[protection_compare + intervals] = pArray[protection_compare];}else{break;}}pArray[protection_compare + intervals] = replica;}}//direct
}
不过更常用的是这种:
void Shell_sort(pSortData pArray, int Size)
{//preorderint intervals = 3;int initial, compare_begin, protection_compare;SortData replica;initial = 0;for (compare_begin = initial + intervals; compare_begin < Size; compare_begin++){replica = pArray[compare_begin];for (protection_compare = compare_begin - intervals; protection_compare >= 0; protection_compare -= intervals){if (compare(pArray[protection_compare], replica)){pArray[protection_compare + intervals] = pArray[protection_compare];}else{break;}}pArray[protection_compare + intervals] = replica;}//direct
}
只用两层循环,但实际还是一样的,不同的是,只有两层循环实际上是先把第一个独立数组比较一轮,再把第二个独立数组比较一轮,接着把第三个独立数组比较一轮,然后再让第一个独立数组比较一轮······
三层循环则是先把第一个独立数组完全比完,再去比较第二个独立数组和第三个独立数组。可以这样认为三层循环的代码是三个独立数组异步走,而只有二层循环的代码是三个独立数组同步走。
它们效率实际上是完全一样的,只不过两层循环看上去比三层循环更好看,所以常见的还是用两层循环。
好的,让我们先不写后续的直接插入,直接先测试一下:
PerformanceTesting(10, Shell_sort)int main()
{ test_Shell_sort();return 0;
}
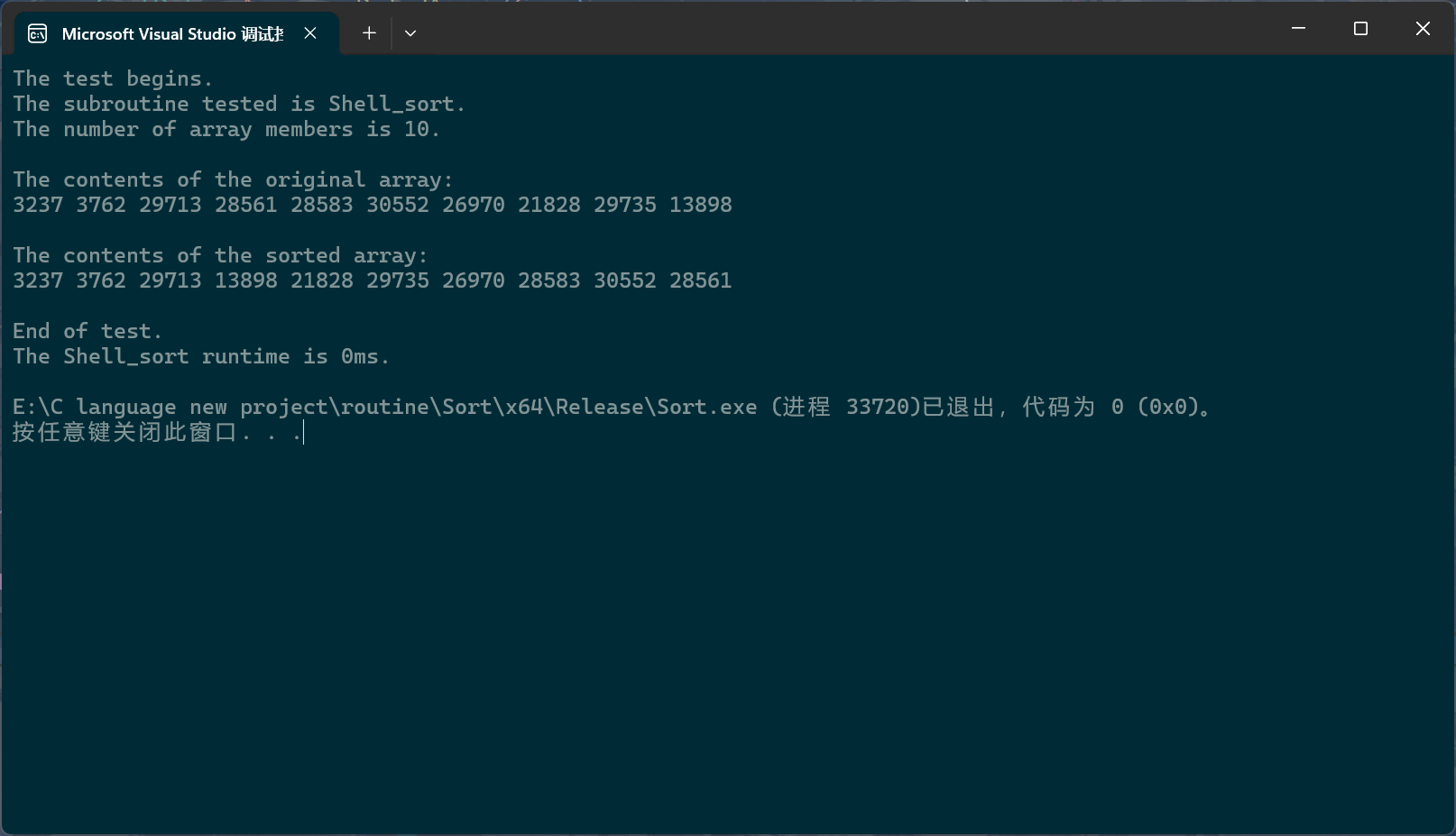
我们把intervals改成1试试
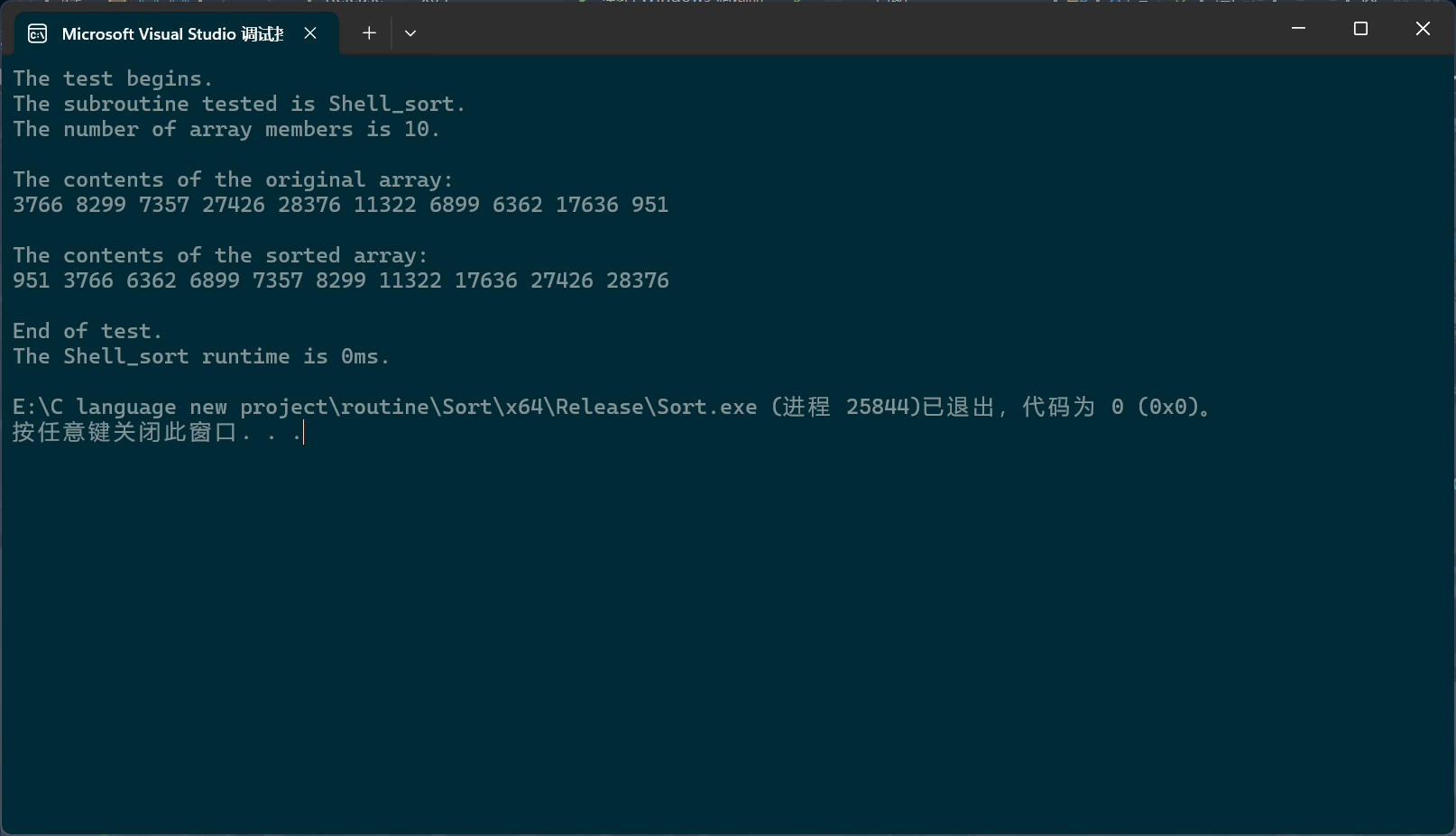
我们发现此时输出的数组就是有序的,为什么呢?因为间隔为1时,每个独立数组其实就只有一个成员,或者说,间隔为1的时候,独立数组只有一个,那就是输入数组本身。也就是说,直接插入排序,或者说连续式插入排序其实就是希尔排序,或者说离散式排序的一种特例,它们之间是被包含与包含的关系。
或者,也可以说,间隔intervals决定了输出数组的有序度。intervals越大(当然是合法的越大),输出数组的有序度就越小;而当intervals为1时,输出数组就是完全有序的。
于是,我们就可以改变intervals的值,让数组进行多次希尔排序,每次排序都可以被视为后一个排序的预排序,最后让intervals等于1即可。intervals就用数组成员个数来初始化。
void Shell_sort(pSortData pArray, int Size)
{int intervals = Size;int compare_begin, protection_compare, initial = 0;SortData replica;while (intervals > 1){intervals = intervals / 3 + 1;for (compare_begin = initial + intervals; compare_begin < Size; compare_begin++){replica = pArray[compare_begin];for (protection_compare = compare_begin - intervals; protection_compare >= 0; protection_compare -= intervals){if (compare(pArray[protection_compare], replica)){pArray[protection_compare + intervals] = pArray[protection_compare];}else{break;}}pArray[protection_compare + intervals] = replica;}}
}
intervals在其中的迭代公式为intervals = intervals / 3 + 1;它的思路是通过不断地整除三让intervals变小,最终让intervals小于三,此时加一就发挥了作用,它会使得intervals最终变成一,在执行完间隔为1的希尔排序后,借由while (intervals > 1)跳出循环,完成排序。
有人可能会问while (intervals > 1)能不能带等于号,答案是不行的。
第一个原因,不算致命问题。从代码中可以看出,它的逻辑是,先判断intervals,再调整intervals,然后再进行一次希尔排序。如果intervals已经为1了,则意味着上一次希尔排序间隔就为1,为什么还要再排一次呢?
第二个原因,是致命问题。当intervals为1之后,它的值就永远为1了,如果加上等号,程序就会陷入死循环。
除此之外,另一种主流的迭代公式为intervals = intervals / 2;。这是什么思路呢?数可以被分为奇数偶数,如果intervals最初是偶数,那intervals最终必会等于1,然后由while (intervals > 1)跳出循环;如果intervals最初是奇数,由于这里是整除,所以和偶数是一样的。
希尔排序的间隔公式还有其它版本。只要你数学好,能推导出满足要求的公式,那就可以用。
PerformanceTesting(10, Shell_sort)int main()
{ test_Shell_sort();return 0;
}
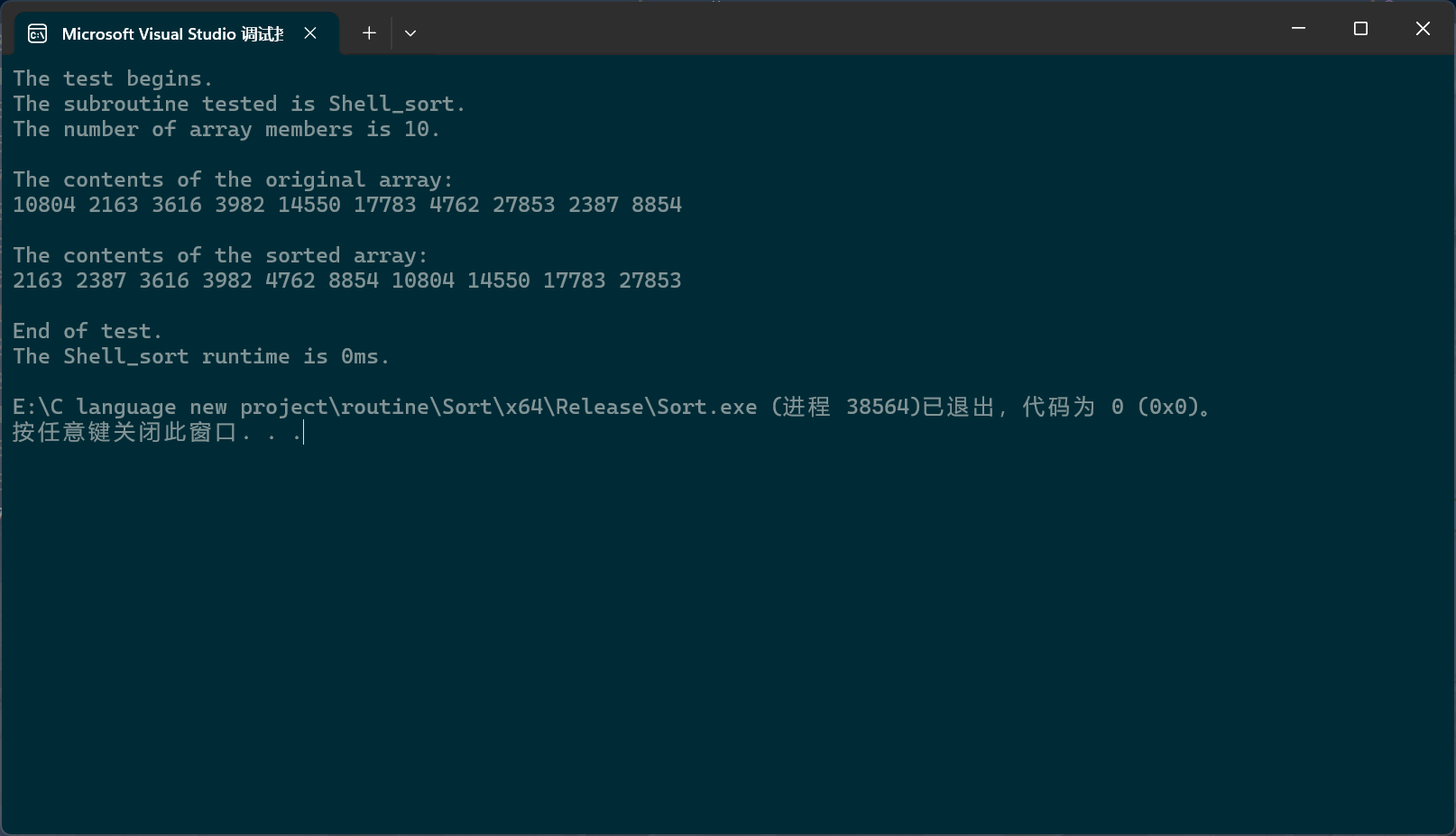
希尔排序的效率远高于直接插入排序。甚至可以直接与快排和堆排序一较高下。
下面我们来浅谈一下希尔排序的时间复杂度。为什么是浅谈呢?因为我数学不好,希尔排序的时间复杂度推导超出了我的数学知识水平。等我学了相关数学知识后再把没说的细节补上。
好的,让我们先看最外层的循环,也就是while (intervals > 1);如果以intervals = intervals / 3 + 1;来看的话,复杂度就为 l o g 3 N log_3N log3N,(由于时间复杂度是粗略计算,所以后面的那个“1”就忽略了。)
从第二层循环开始,这就超出了我的知识水平。由于intervals是在变化的,所以非常难计算。我们只能粗略算一下,怎么算呢?
我们从intervals的两个极端入手。
当intervals很大时,比如说 S i z e 3 \frac{Size}{3} 3Size,此时粗略来讲,将会有 S i z e 3 \frac{Size}{3} 3Size个独立数组,每个数组有三个成员,前面说过,直接插入排序的时间复杂度是个标准的等差数列,所以对于单个独立数组来说,它的具体复杂度就是1+2+3等于6,那有多少个独立数组呢?一共有 S i z e 3 \frac{Size}{3} 3Size个独立数组,所以此时的时间复杂度就为 S i z e 3 ∗ 6 = 2 S i z e \frac{Size}{3}*6=2Size 3Size∗6=2Size,也就是说,这是 O ( N ) O(N) O(N)级别的。
当intervals很小时,经过前面的预排序之后,此时原数组已经几乎是有序了。所以此时的复杂度就是前面说的最好情况O(N)。
所以说,单从intervals的两个极端来说,它的复杂度都是 O ( N ) O(N) O(N)。
据说,当intervals又不大又不小的时候,时间复杂度会增加。所以intervals从大到小,其复杂度的变化过程应该是先上升再下降。
上面说的这些,是让大家明白,非常粗略地来讲(即使是对复杂度来说,也是过于粗略的,不能真的作为复杂度的。)它的复杂度是 O ( N ∗ l o g 2 N ) O(N*log_2N) O(N∗log2N),这个级别的复杂度差不多能赶上堆排序和快排了。所以说希尔排序的效率远远高于直接插入排序。
至于希尔排序的具体时间复杂度就不说了,一方面是,这和intervals的迭代公式有关;另一方面,这真的很难算。
那到底多少呢?我也是听别人说的,大概是 O ( N 1.25 ) O(N^{1.25}) O(N1.25)到 O ( 1.6 N 1.25 ) O(1.6N^{1.25}) O(1.6N1.25)。非要给具体值就是 O ( N 1.3 ) O(N^{1.3}) O(N1.3)。
选择排序
选择排序非常简单。但效率太低了。它的思想是从数组中找出一个极值,把它放到应有的位置上,然后从剩余部分再找极值,依次类推。
我们稍微优化一下,每轮比较把最大值和最小值都找出来。我们通过交换把这两个极值放在合适的位置上:

大概是这个意思,不得不说,选择排序效率太低了,我画图都画了很长时间,画完没有细看是不是完全对的。
不过若是还这样写,还不行
void Select_sort(pSortData pArray, int Size)
{int pend_begin, pend_end;int max, min, current;for (pend_begin = 0, pend_end = Size - 1; pend_begin < pend_end; pend_begin++, pend_end--){max = pend_end;min = pend_begin;for (current = pend_begin; current < pend_end + 1; current++){if (compare(pArray[current], pArray[max])){max = current;}if (compare(pArray[min], pArray[current])){min = current;}}Swap(&(pArray[pend_begin]), &(pArray[min]));Swap(&(pArray[pend_end]), &(pArray[max]));}
}
在交换成员时,有时会出现一种情况,这种情况在动画中并没有体现出来。如果pend_begin恰好就和max相同时,在进行第一次交换后,原先选出的最大数就会跑到min的位置上,从而出现问题。所以还要略微修改。
void Select_sort(pSortData pArray, int Size)
{int pend_begin, pend_end;int max, min, current;for (pend_begin = 0, pend_end = Size - 1; pend_begin < pend_end; pend_begin++, pend_end--){max = pend_end;min = pend_begin;for (current = pend_begin; current < pend_end + 1; current++){if (compare(pArray[current], pArray[max])){max = current;}if (compare(pArray[min], pArray[current])){min = current;}}Swap(&(pArray[pend_begin]), &(pArray[min]));if (pend_begin == max){max = min;}Swap(&(pArray[pend_end]), &(pArray[max]));}
}
PerformanceTesting(10, Select_sort)int main()
{ test_Select_sort();return 0;
}
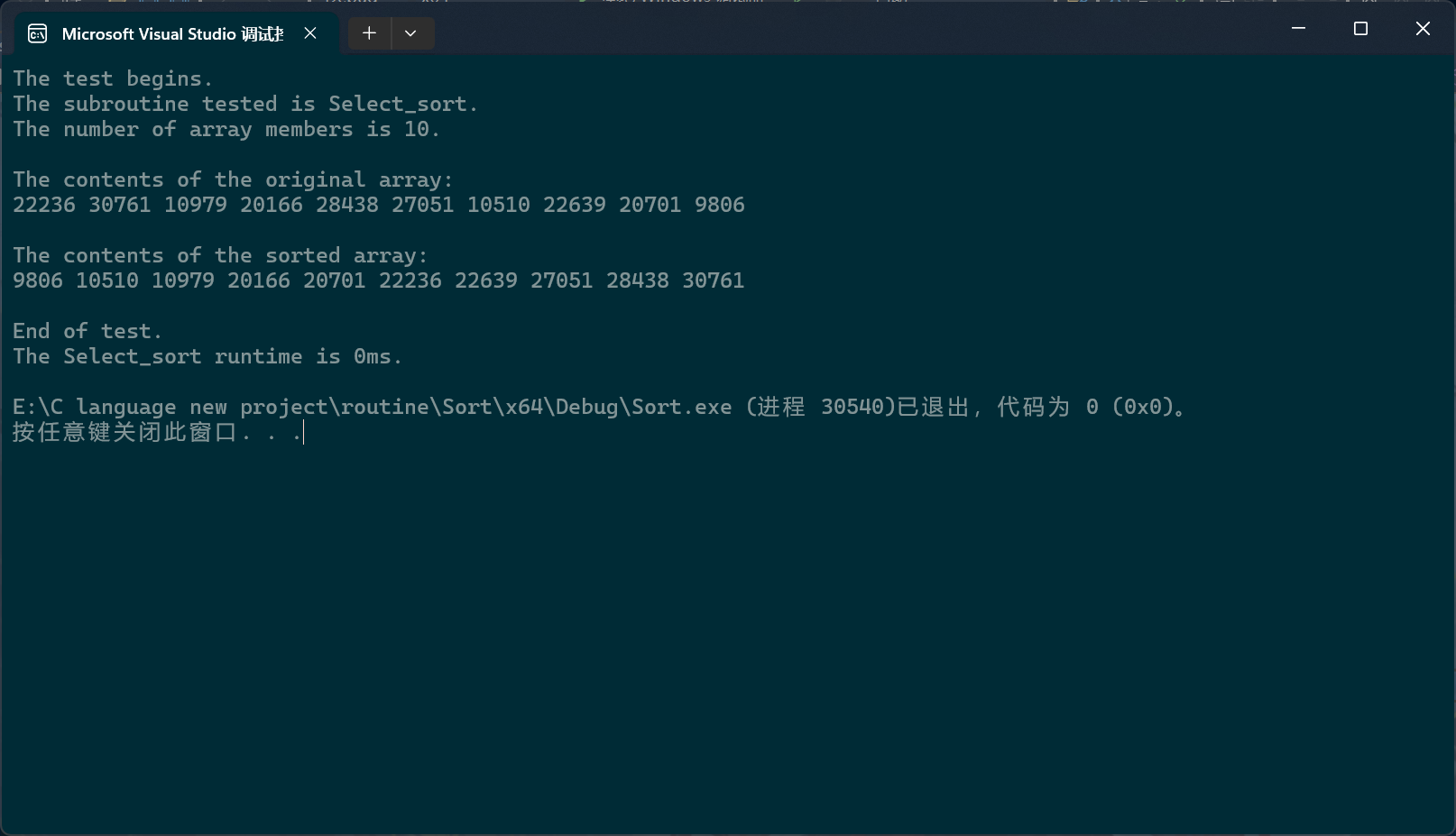
堆排序
之前说过堆排序,就在《二叉树和堆》那个项目下,这里再简单地回顾一下。
堆排序利用的是堆根节点是堆中成员极值的性质。先将输入的数组通过调整算法调整为堆,再把根节点数值与数组尾元素数值进行交换,接着再把剩余部分调整为堆;不断循环,最后得出有序数组。
示意图在《二叉树和堆》文档中已经给出,在此不做赘述。
static int FindFristChild(int parent, int Size)
{int child = parent * 2 + 1;if (child < Size){return child;}else{return -1;}
}static int FindSecondChild(int parent, int Size)
{int child = parent * 2 + 2;if (child < Size){return child;}else{return -1;}
}static void DownwardAdjustment(pSortData pArray, int Size, int start)
{int parent = start;int child;while (parent < Size){int first_child = FindFristChild(parent, Size);int second_child = FindSecondChild(parent, Size);if (first_child == -1 && second_child == -1){break;}else{child = first_child;if (second_child != -1){if (compare(pArray[second_child], pArray[first_child])){child = second_child;}}}if (compare(pArray[child], pArray[parent])){Swap(&(pArray[child]), &(pArray[parent]));}parent = child;}
}void Heap_sort(pSortData pArray, int Size)
{int parent = ((Size - 1) - 1) / 2;for (; parent >= 0; parent--){DownwardAdjustment(pArray, Size, parent);}int end;for (end = Size - 1; end > 0; end--){Swap(&(pArray[0]), &(pArray[end]));DownwardAdjustment(pArray, end, 0);}
}
PerformanceTesting(10, Heap_sort)int main()
{ test_Heap_sort();return 0;
}

快速排序
快速排序采用分治的思想。它先在待排数组中任取一成员作为基准值,随后依据该值将数组分为两个子部分,分别存放大于和小于基准值的成员,随后再将这两个子部分视为新的待排数组,重复上述步骤。
因为快速排序使用递归结构,所以要先实现单轮排序。单轮排序一共有三种实现方式。
第一种:Hoare法。Hoare正是快速排序的提出者,此种方法也是快速排序的原生思路。
在Hoare法中,默认选择待排序数组的第一个成员作为基准值;随后创建两个指针,最开始分别指向待排数组的第一个成员和最后一个成员;为了方便叙述,下面将这两个指针依据其相对方位分别命名为left和right;left的职责是寻找大于基准值的数,而right于此正好相反,这两个指针找到各自的目标后,会对所指向的数组成员进行数值交换,然后重复上述过程,直到两个指针指向同一个数组成员;这个成员所处的位置正是基准值应该处于的位置,此时,对该成员与数组第一个成员(也就是基准值)进行数值交换;单轮排序就结束了。
这两个指针采取“异步”的方式寻找目标,即某个指针(比如A)找到目标后,再让另一个指针(B)寻找自己的目标,在交换数值后,另一个指针(A)再寻找目标。指针最初的移动顺序也有讲究。当要生成升序数组时,由于基准值最后是通过与相遇位置成员进行数值交换才来到应有位置的,而基准值又默认为第一个成员的数值,所以必须要确保被基准值交换的成员数值是小于基准值的,为此,必须先让right指针先进行移动;当left与right相遇时,由于right先进行移动,所以绝大多数情况下,都是right先找到目标,然后left在寻找自己对应目标的过程中与right相遇,这意味这相遇位置的成员数值必然是小于基准值的。同理,若将基准值设置为最后一个成员,则必须先让left先走,以确保相遇位置的数值大于基准值。也就是说,两指针的移动顺序与基准值的位置有关。
除此之外,另一种特殊情况,先行指针在遍历完整个选中数组后仍没有找到目标,此时两指针直接在基准值相遇,但由于指针相遇位置与基准值位置相同,所以数值交换不会产生有效影响。
对于和基准值相同的数值成员,两指针不会进行任何响应(不视为目标),而是交由后续轮次排序处理。
以下动画展现的是基于Hoare法单轮排序的整体过程,而非单轮排序过程。
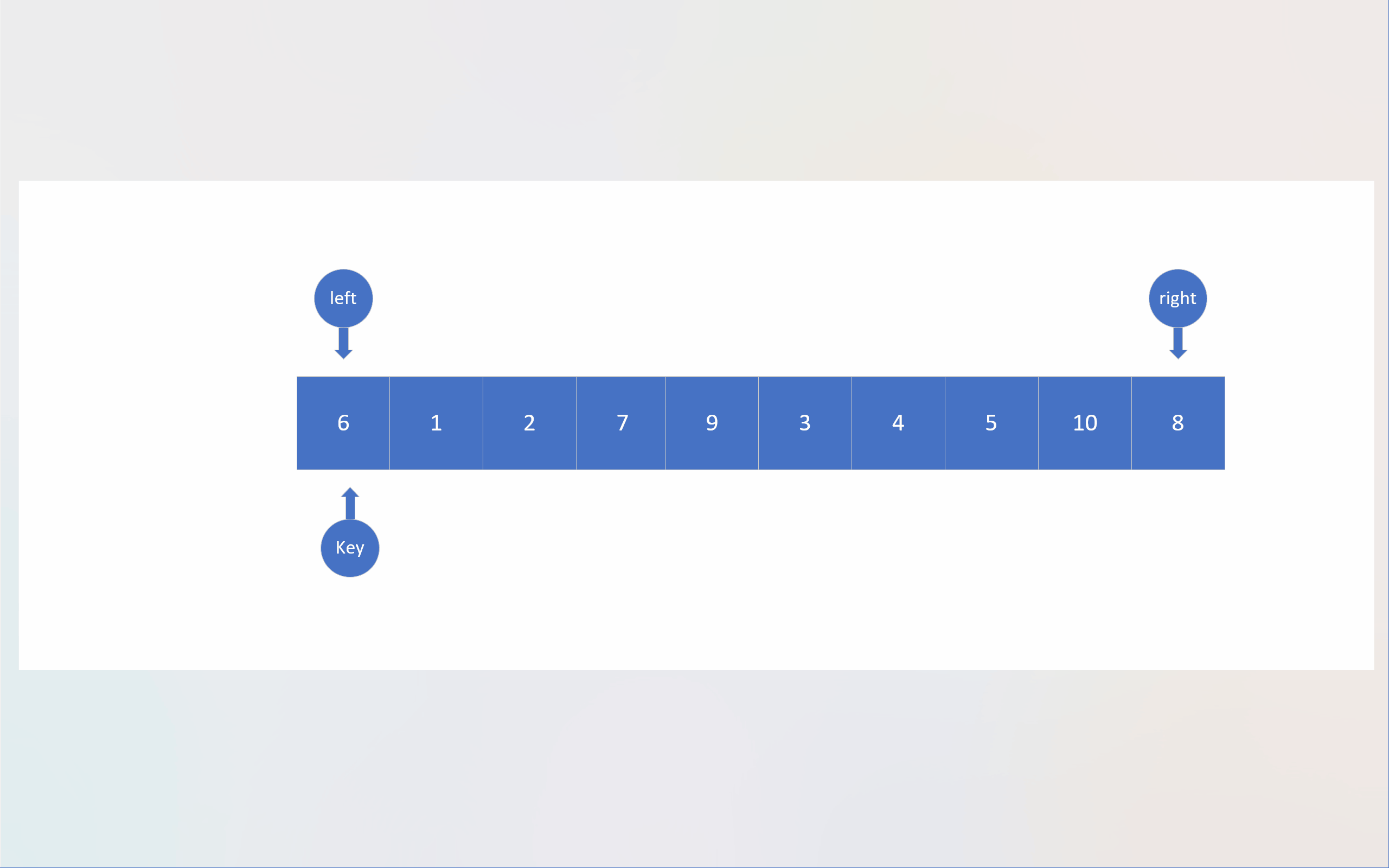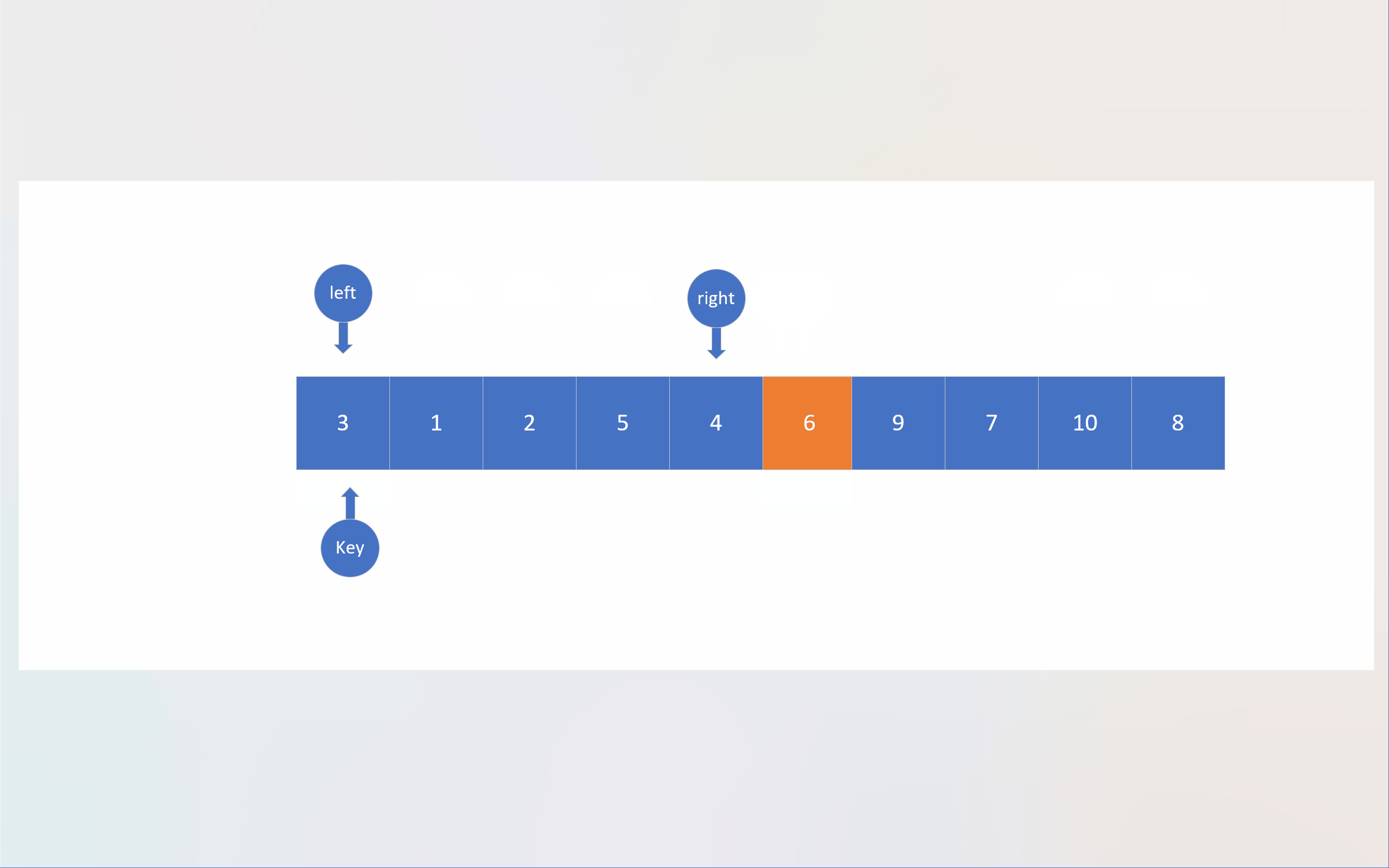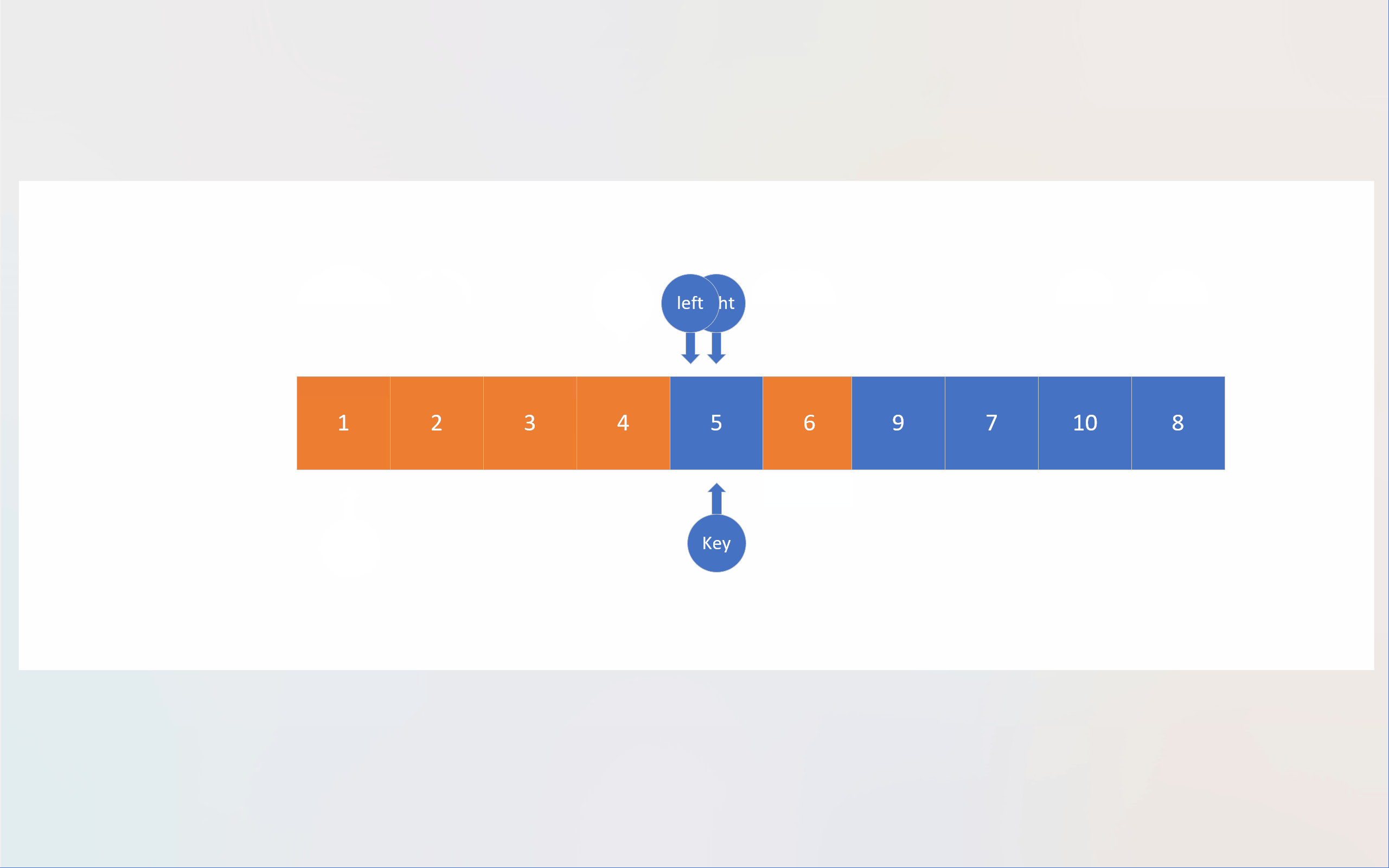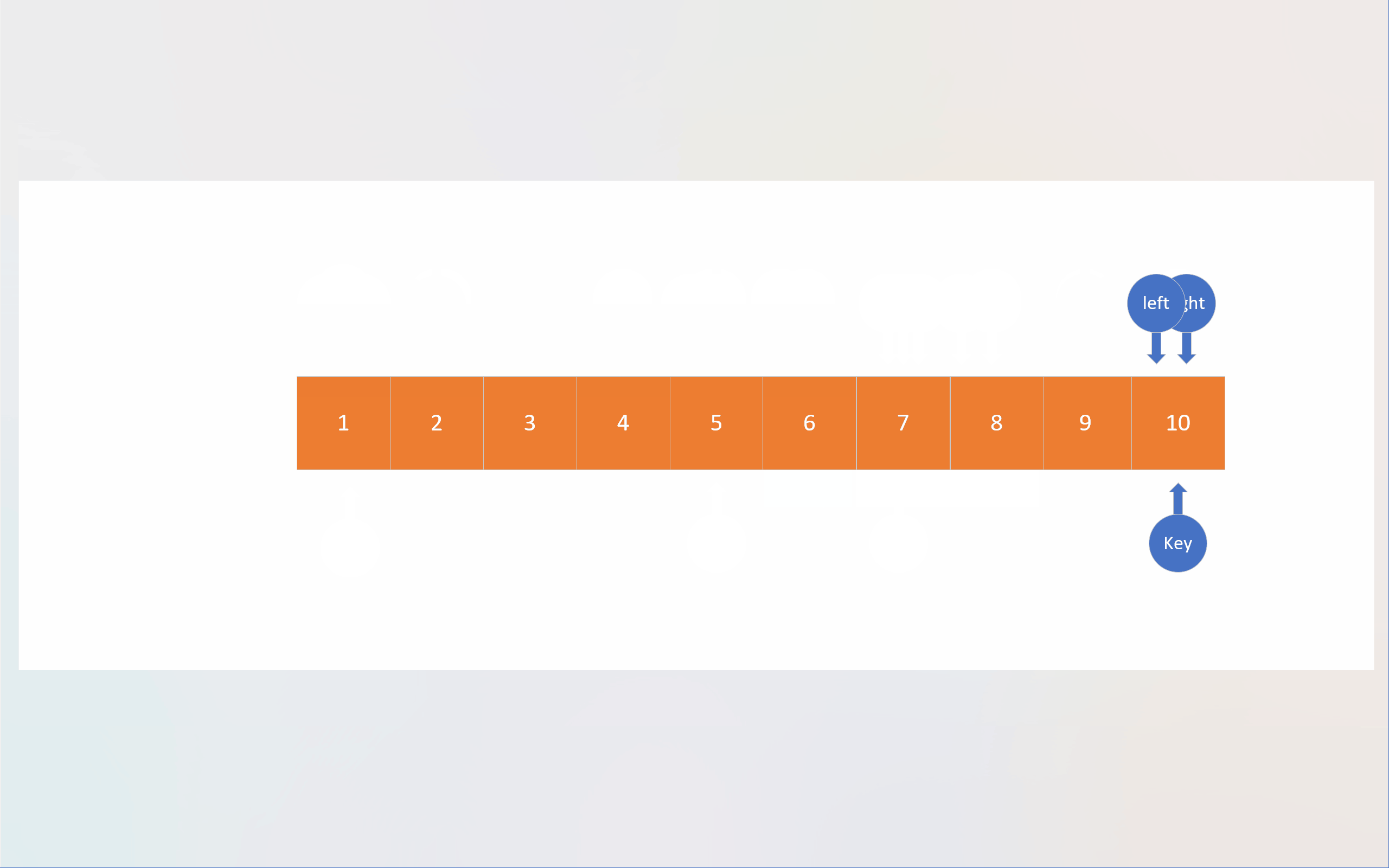
static int Hoare_mode(pSortData pArray, int left, int right)
{int key = left;while (left < right){while (left < right && !compare(pArray[key], pArray[right])){right--;}while (left < right && !compare(pArray[left], pArray[key])){left++;}Swap(&(pArray[left]), &(pArray[right]));}Swap(&(pArray[right]), &(pArray[key]));return right;
}tatic void _Quick_sort_root(pSortData pArray, int left, int right)
{if (left >= right)return;int key = Hoare_mode(pArray, left, right);_Quick_sort_root(pArray, left, key - 1);_Quick_sort_root(pArray, key + 1, right);
}void Quick_sort(pSortData pArray, int Size)
{_Quick_sort_root(pArray, 0, Size - 1);
}
在实际写代码时,要特别注意两指针找目标的循环条件。前面的left < right,防止跑出数组;后面的大小比较一定要带等于号,试想一下这种情况,当数组中除基准值时还含有两个和基准值相同的成员,而指针循环条件没带等号时
while (left < right && pArray[right] > pArray[key])
{right--;
}
while (left < right && pArray[key] < pArray[left])
{left++;
}
这两个指针就会把与基准值相等的那两个值分别选为目标,交换之后,两个指针的指向内容依旧与基准值相等,所以依旧不会进入循环,两指针不会发生变化,于是它们就会再交换一下,于是,就死循环了。
erformanceTesting(10, Quick_sort)int main()
{ test_Quick_sort();return 0;
}

第二种,填坑法。
从上面的学习中,可以看到霍尔法有很多坑,于是就有人以霍尔法的思想为指导,创造出了填坑法。
填坑法与霍尔法的主要区别就是数据的传递方式的不同。霍尔法的数据传递方式是交换,而填坑法的数据传递是覆写。
和霍尔法类似,我们先默认基准值是数组第一个成员。在确定基准值之后,对基准值进行拷贝,由于拥有备份,所以基准值在数组中的原位置就可以随意处理了,此时它就变成了一个坑,可以写入数组中的其它数据。然后就要寻找填入坑的数据,由于坑最开始位于数组的第一个成员处,所以想要找数据自然是要从数组最后一个成员处开始寻找。于是right指针就登场了,它会寻找比基准值小的数,找到之后,就把自己指向的数据写入坑里,此时right指向的数据也有了拷贝,于是right就成为了新的坑,有新的坑,就要寻找新的数据,由于此时的坑在右侧,所以想要找新的数据自然是要从数组左侧开始找起,于是left就登场了,它会寻找大于基准值的数据,找到之后填入坑里,于是它指向的地方就成为了新坑,right就会找数据用来填入新坑,重复上述过程,当两指针相遇后,它们指向的位置就是基准值应处于的位置,于是把之前拷贝的基准值写入这个位置。

static int FillGap_mode(pSortData pArray, int left, int right)
{SortData key = pArray[left];int gap = left;while (left < right){while (left < right && !compare(key, pArray[right])){right--;}pArray[gap] = pArray[right];gap = right;while (left < right && !compare(pArray[left], key)){left++;}pArray[gap] = pArray[left];gap = left;}pArray[gap] = key;return gap;
}static void _Quick_sort_root(pSortData pArray, int left, int right)
{if (left >= right)return;int key = FillGap_mode(pArray, left, right);_Quick_sort_root(pArray, left, key - 1);_Quick_sort_root(pArray, key + 1, right);
}void Quick_sort(pSortData pArray, int Size)
{_Quick_sort_root(pArray, 0, Size - 1);
}
当然,此时仍需要注意循环变量的等于号。
PerformanceTesting(100000, Quick_sort)int main()
{ test_Quick_sort();return 0;
}
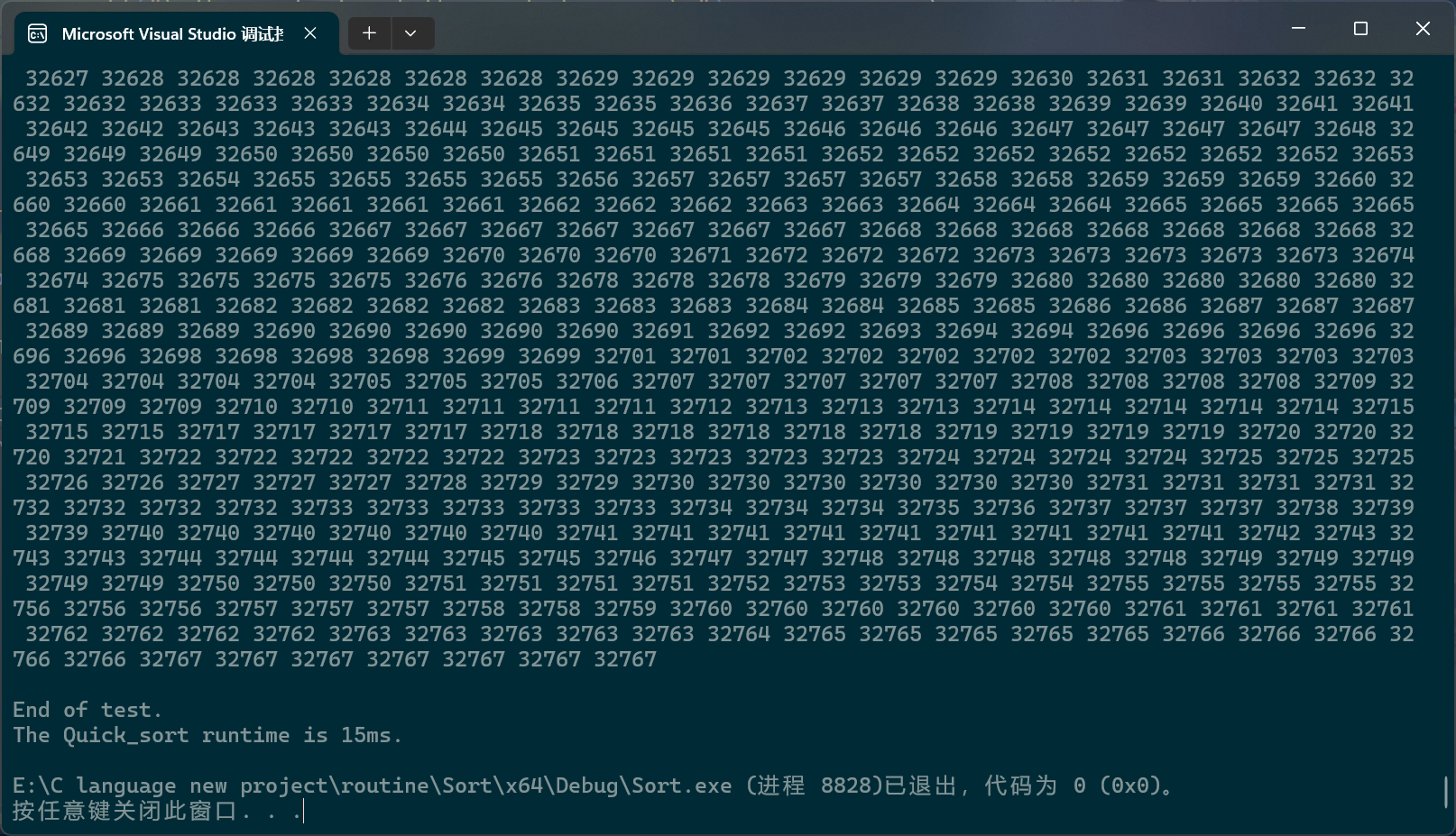
第三种方法,没有统一的命名,依据思路,要不叫它“跟屁虫法”或者“搜索法”?
在搜索法中,同样有两个指针,一个指针负责搜索目标,另一个指针负责尾随前一个指针。还是以数组首元素为基准值,搜索指针会寻找比基准值小的数据,找到一个,尾随指针就会向后移动一位,然后这两个指针指向的内存块就会交换数值,当搜索指针跑出数组后,尾随指针指向的内存块就会和基准值交换。
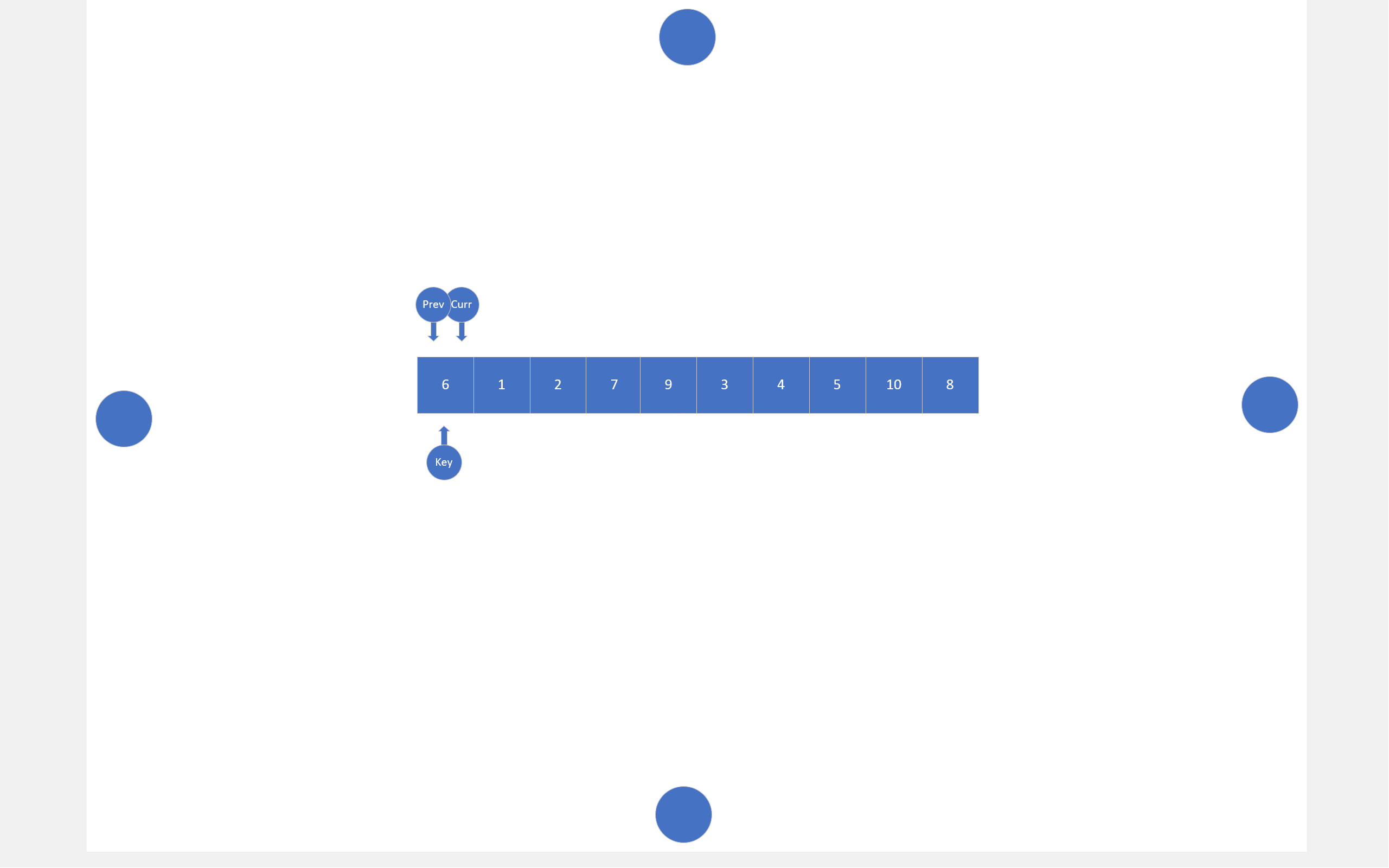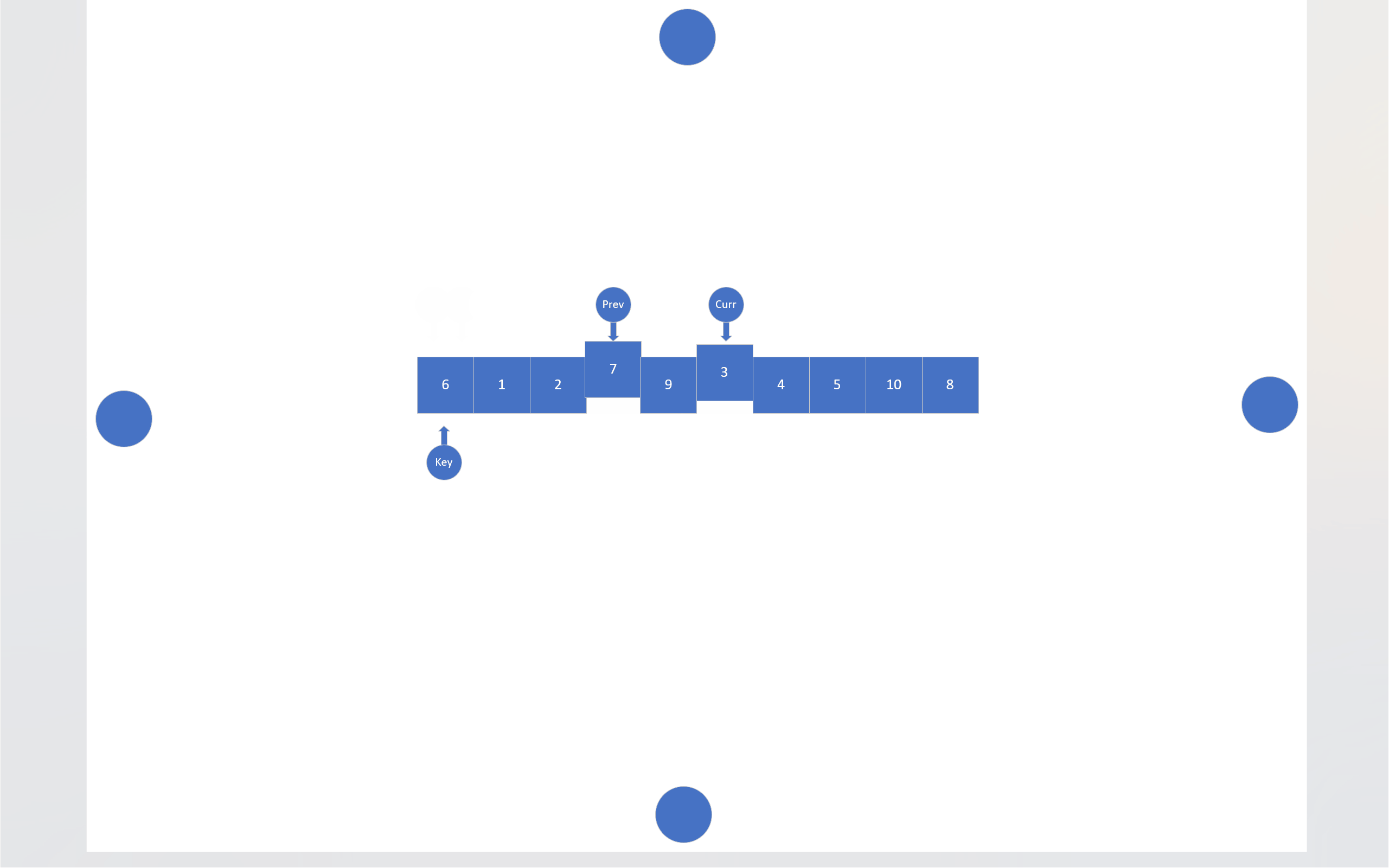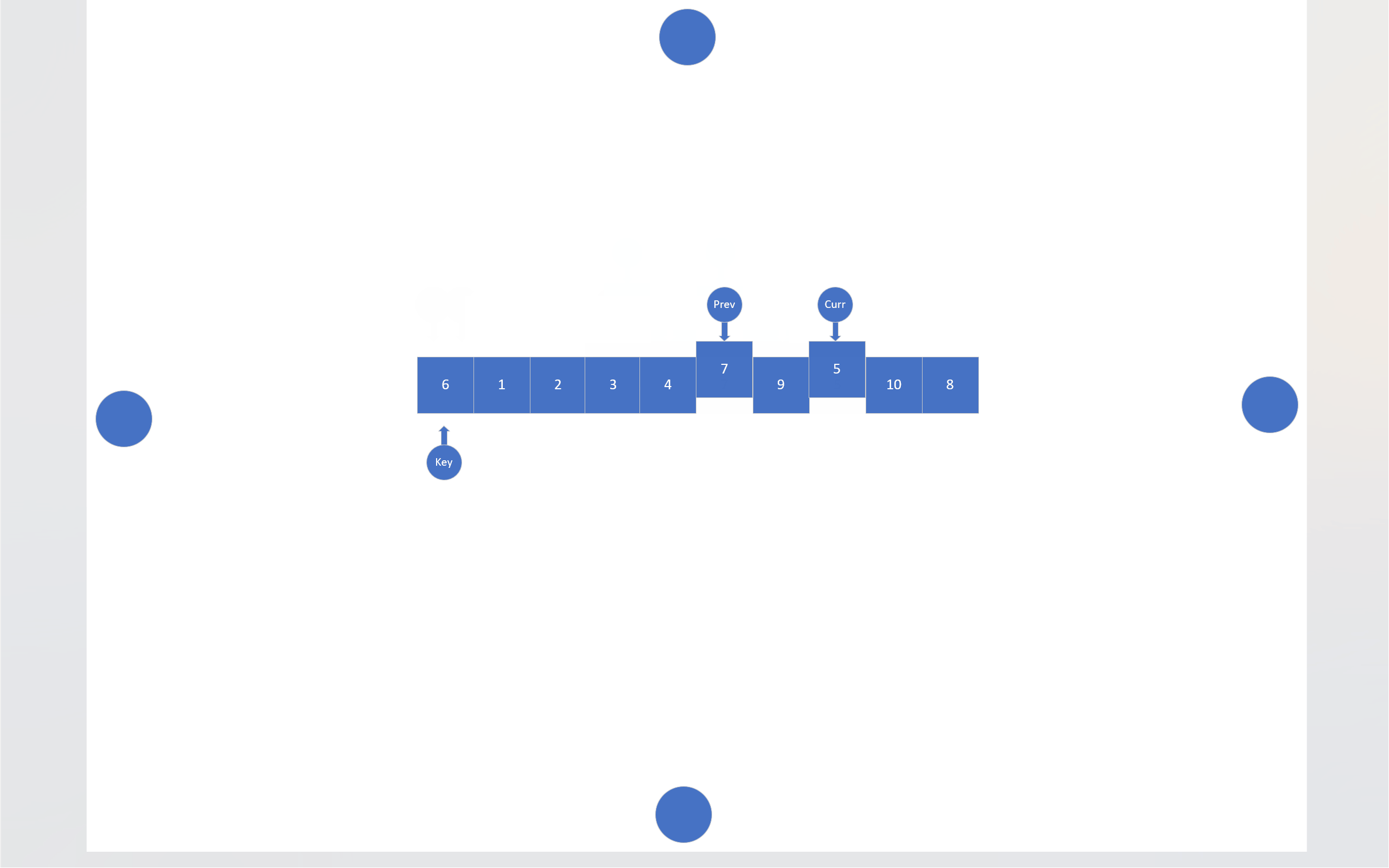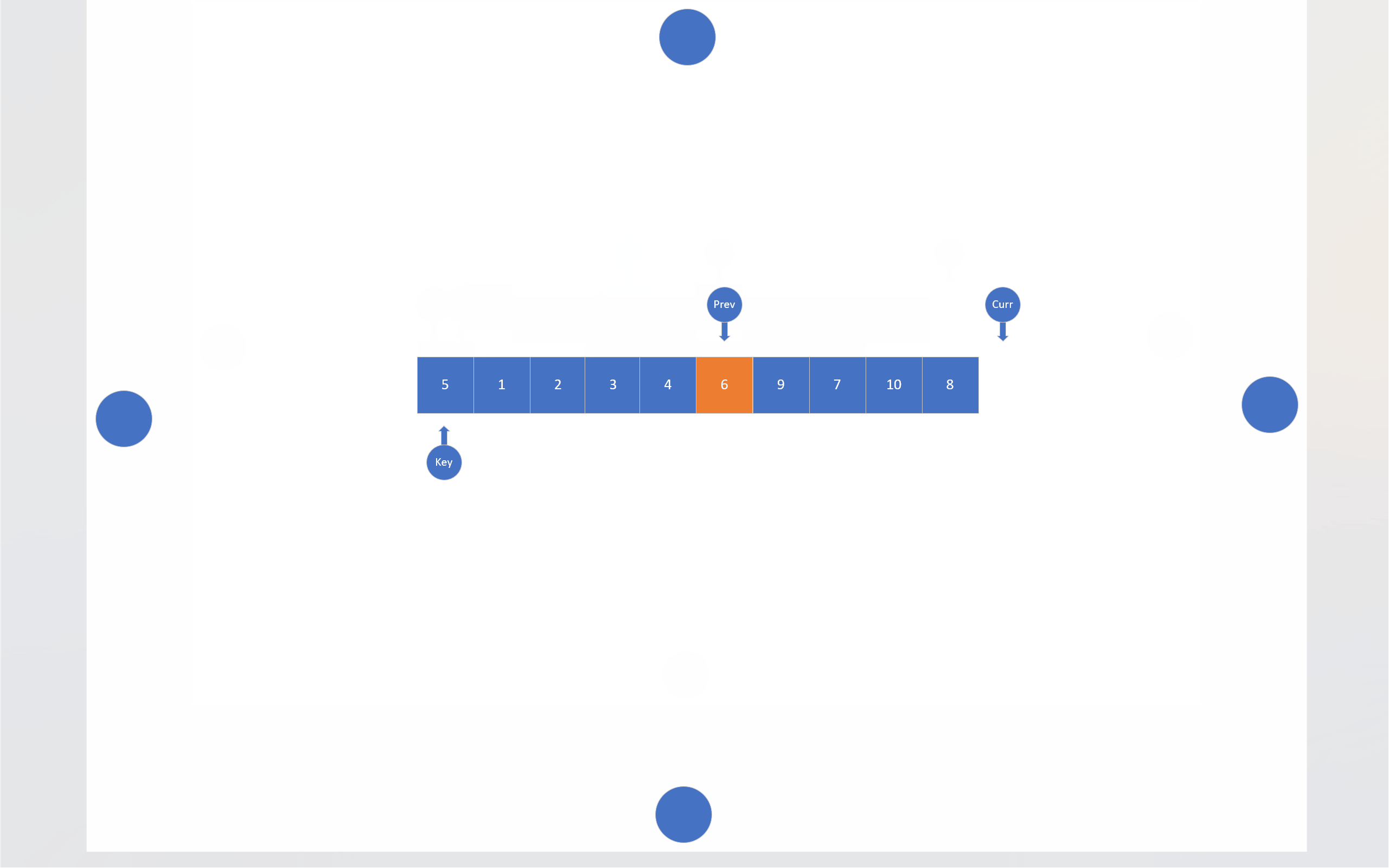
static int Search_mode(pSortData pArray, int left, int right)
{int key = left;int prev = left;int curr = left;while (curr <= right){if (compare(pArray[key], pArray[curr])){Swap(&(pArray[++prev]), &(pArray[curr]));}curr++;}Swap(&(pArray[prev]), &(pArray[key]));return prev;
}static void _Quick_sort_root(pSortData pArray, int left, int right)
{if (left >= right)return;int key = Search_mode(pArray, left, right);_Quick_sort_root(pArray, left, key - 1);_Quick_sort_root(pArray, key + 1, right);
}void Quick_sort(pSortData pArray, int Size)
{_Quick_sort_root(pArray, 0, Size - 1);
}
PerformanceTesting(100000, Quick_sort)int main()
{ test_Quick_sort();return 0;
}
也还可以优化优化:
static int Search_mode(pSortData pArray, int left, int right)
{int key = left;int prev = left;int curr = left;while (curr <= right){if (compare(pArray[key], pArray[curr]) && ++prev != cur){Swap(&(pArray[prev]), &(pArray[curr]));}curr++;}Swap(&(pArray[prev]), &(pArray[key]));return prev;
}
就是加加后还等于搜索指针就不交换了。其实优不化优化都行的。
接下来我们看看快速排序的时间复杂度,当基准值恰好为选中数组的中位数时,快速排序效率达到最高,此时快速排序的结构与二叉树类似
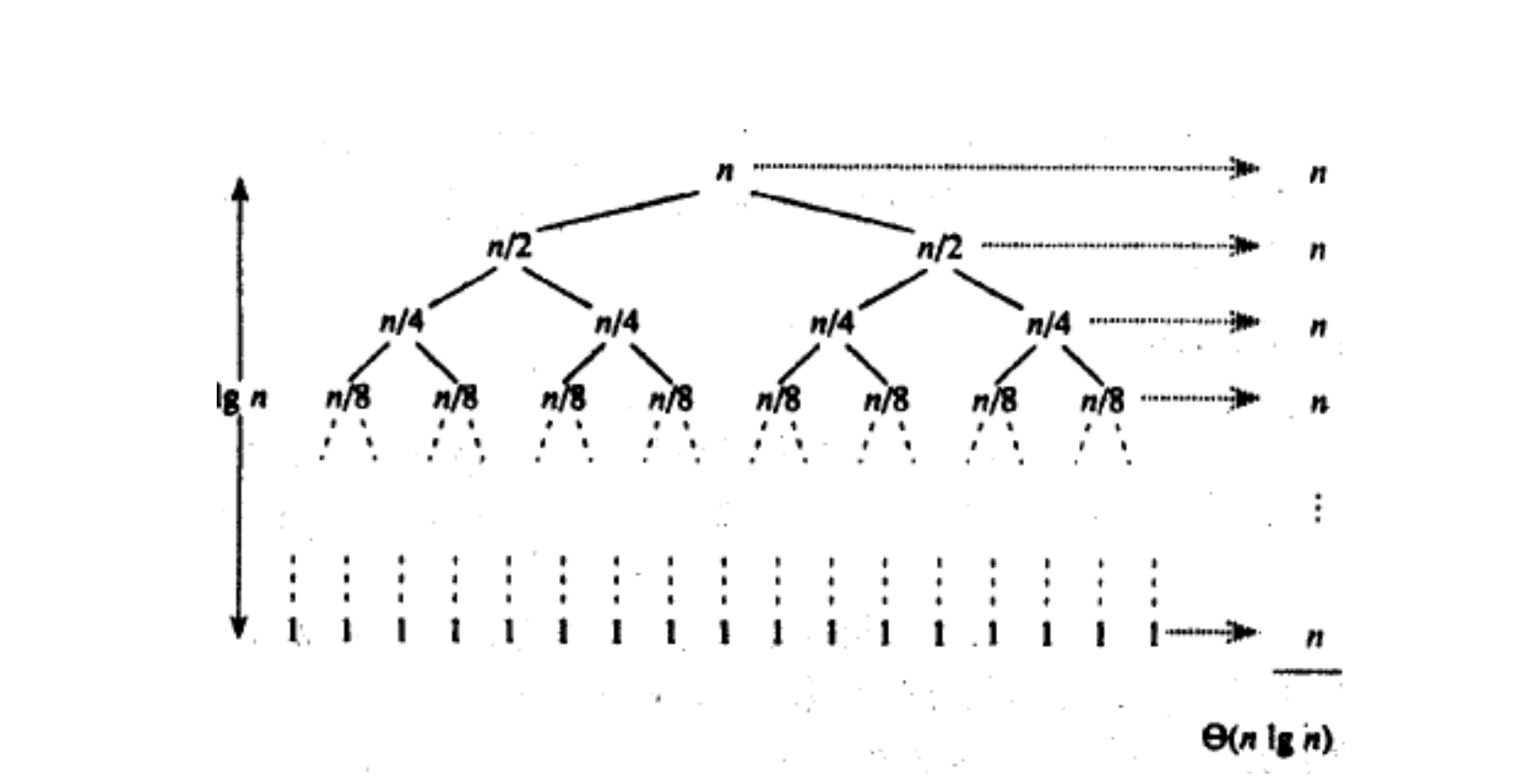
每个节点就可以被视为一个函数栈帧,一共有 l o g 2 N log_2N log2N层,每一层所选中数组部分合在一块就相等于整个数组,所以每层都是 N N N,再乘一下,于是就得到时间复杂度 O ( N ∗ l o g 2 N ) O(N*log_2N) O(N∗log2N)。
最坏情况是什么呢?那就是每次选中的基准值都恰好是极值,此时的函数栈帧更像是链表而非树,每层的复杂度仍是 N N N,但此时深度已经变成了 N N N,所以复杂度就变成了 O ( N 2 ) O(N^2) O(N2)。
前面说过,基准值实际是可以任意选择的,所以为了避免出现最坏情况,就可以对快速排序进一步优化:
我们先挑出三个预选值,分别是数组末尾,开头,中间,然后选择中间的那一个。但如果直接在单轮排序上修改就太麻烦了,所以我们的实际操作是先把三个数中间的那个数找出来,然后让它与数组首元素进行数值交换。
int middle_of_three(pSortData pArray, int left, int right)
{int mid = (left + right) / 2;if (compare(pArray[left], pArray[mid])){if (compare(pArray[mid], pArray[right])){return mid;}else{if (compare(pArray[left], pArray[right])){return right;}elsereturn left;}}else{if (compare(pArray[right], pArray[mid])){return mid;}else{if (compare(pArray[left], pArray[right])){return left;}elsereturn right;}}
}
为了观察三数选中的效果,我们先修改一下数组构建函数
pSortData BulidArray(int Size)
{pSortData pArray = (pSortData)malloc(sizeof(SortData) * Size);if (pArray == NULL){perror("BulidArray malloc fail");return NULL;}int circuit = 0;for (; circuit < Size; circuit++){pArray[circuit] = circuit;}return pArray;
}
现在单次排序没有三数选中,让我们看看效率:
PerformanceTesting(100000, Quick_sort)int main()
{ test_Quick_sort();return 0;
}
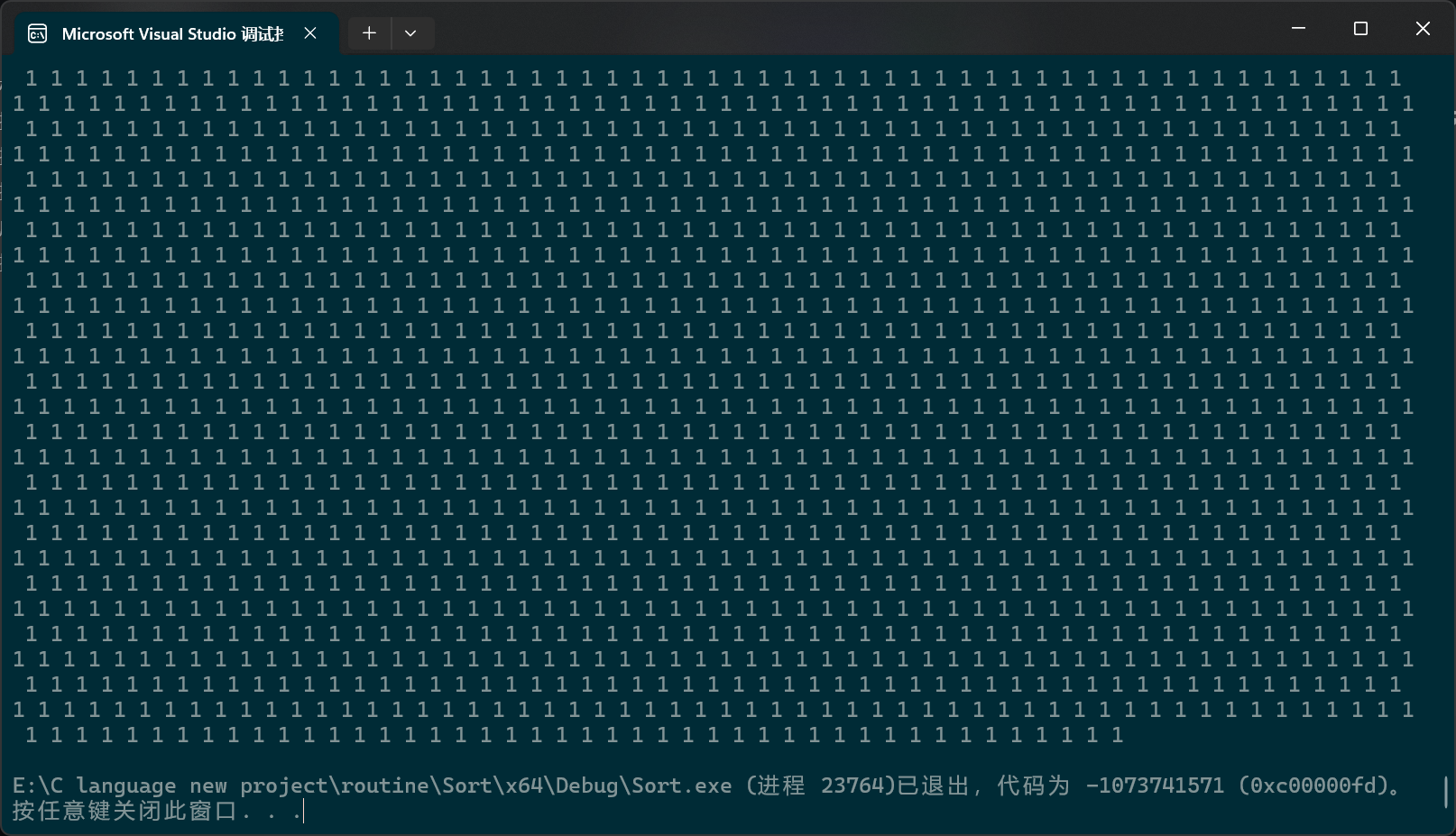
看样子是函数栈帧层数过多,栈溢出了。
换一下,
PerformanceTesting(3000, Quick_sort)int main()
{ test_Quick_sort();return 0;
}

现在加上三数选中,再来一次。
差别不是很明显,这应该是我电脑性能不行,参数设大一些就栈溢出了,理论上来说,参数越大,差别就应该越明显。等会以非递归实现快排之后,再试一试。
刚刚我们就看到了递归的缺点,当递归过深后,就容易出现栈溢出,所以接下来我们要以非递归的方式实现快速排序。
先让我们想一想当初为什么偏要用递归的方式去实现快排。其实很简单,就是利用递归把函数栈帧以树状的形式组织起来,然后用单轮排序返回的下标值把它们联系起来。
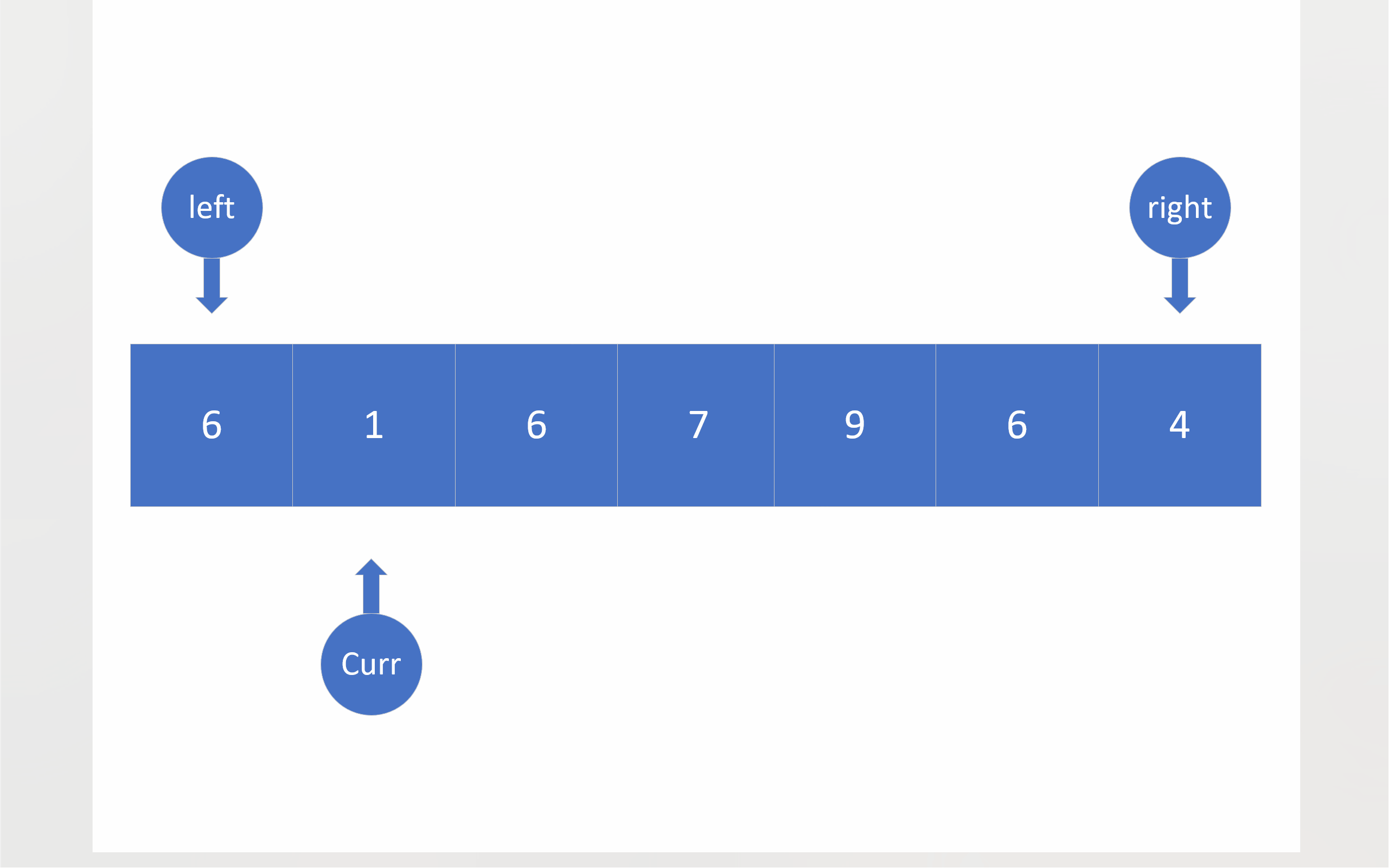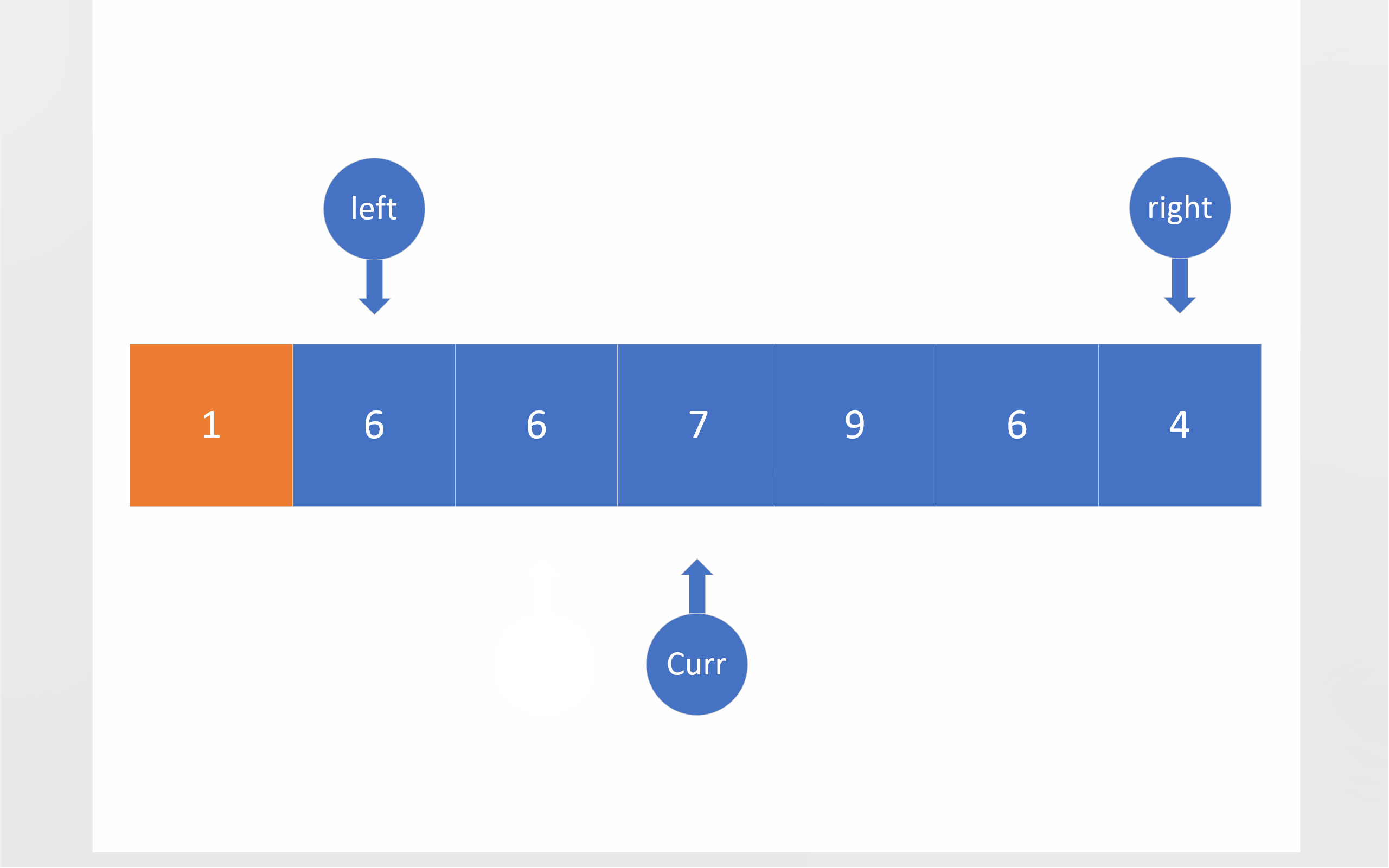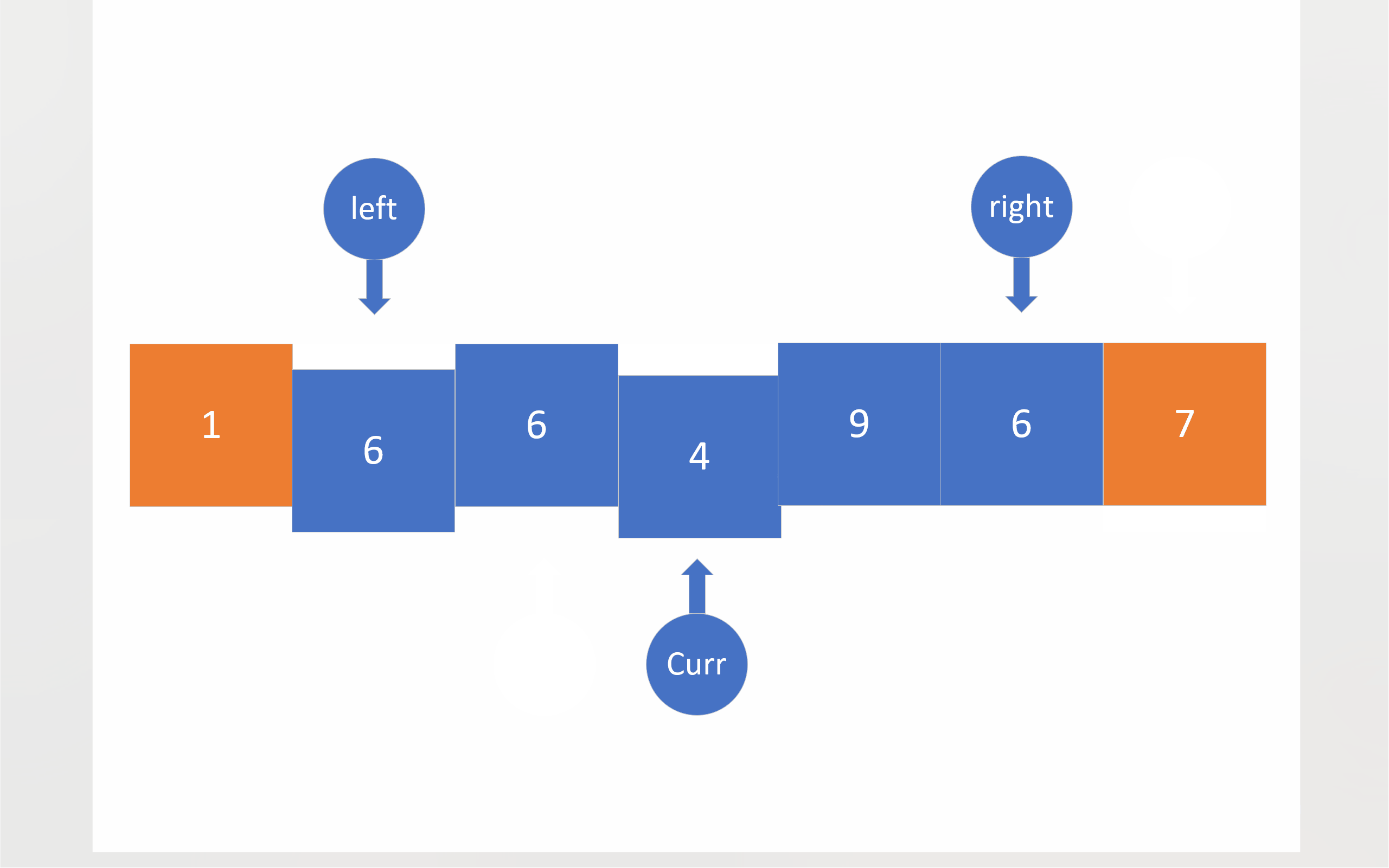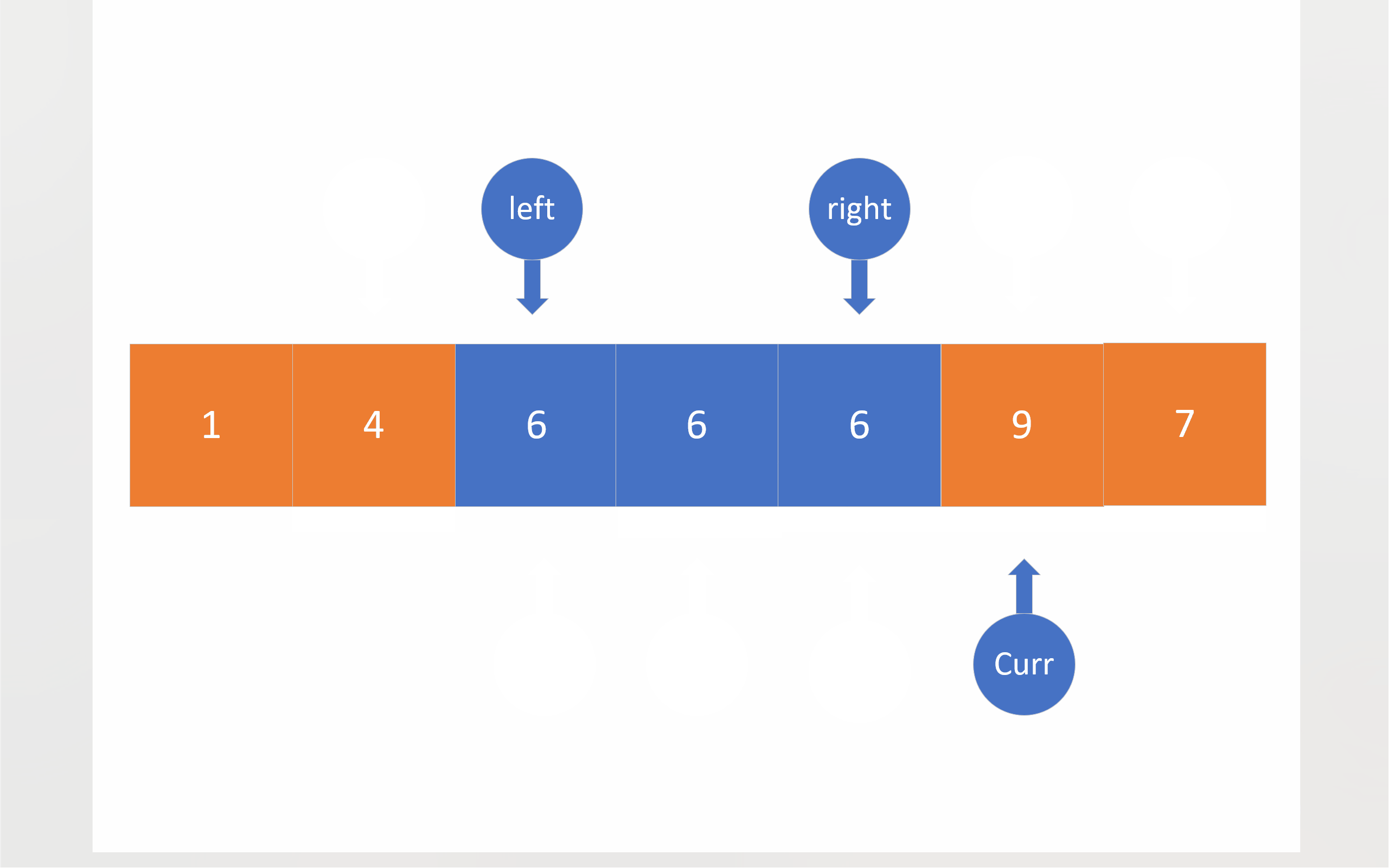
还是回到霍尔法,以动图中的数组[ 6,1,2,7,9,3,4,7,10,8 ]为例。图中,蓝色文本数字表示数组下标,蓝红色序列号表示先后顺序。
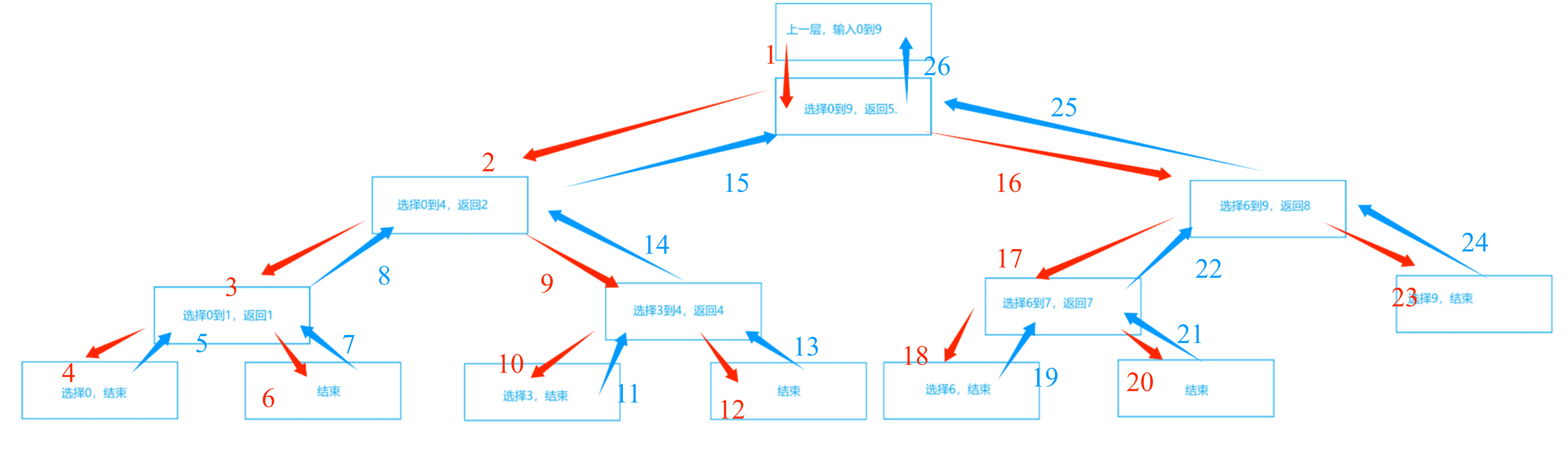
从这张图中,我们可以看到,下标数据遵循着“先进后出”的性质,哪种数据结构有“先进后出”的性质呢?那就是栈。注意这里说的“栈”是数据结构的栈,而不是内存的那个栈。我们自己开辟的栈是建立在内存的堆上的,堆的大小远大于栈(内存),所以就不会像递归那么容易出现栈溢出。
void Quick_sort_NonR(pSortData pArray, int Size)
{PST pStack = STInit();STPush(pStack, Size - 1);STPush(pStack, 0);while (!STEmpty(pStack)){int left = STPop(pStack);int right = STPop(pStack);int key = Hoare_mode(pArray, left, right);if (key + 1 < right){STPush(pStack, right);STPush(pStack, key + 1);}if (left < key - 1){STPush(pStack, key - 1);STPush(pStack, left);}}STDestroy(pStack);
}
注:栈的相关文件请参考《栈和队列》。
PerformanceTesting(100000, Quick_sort_NonR)int main()
{ test_Quick_sort_NonR();return 0;
}

看,即使是这样大的数据个数也不会栈溢出。
好的,上面的是带有三数选中的,让我们先把数组构造函数换成最坏情况的那种,然后再对比一下三数选中有无的效果。
PerformanceTesting(10000000, Quick_sort_NonR)int main()
{ test_Quick_sort_NonR();return 0;
}
含有三数选中时的结果:

现在我们把三数选中去掉,为了节约时间,就不打印了。
好的,最起码运行了15分钟,然后我受不了了,关掉了。
除了栈之外,队列也可以实现快速排序的非递归版本,只不过此时它的遍历次序已经和递归完全不同了。此时它应该先把0,9压入队列,再弹出0,9;随后压入0,4和6,9;然后弹出0,4;压入0,1和3,4;然后弹出6,9,压入6,7和9······也就是说,它是层序遍历树的。这里就不详细说了。
在某些极端情况下,上述三种的快速排序可能会全部失效。什么情况呢?那就是整个数组的所有成员的数值都相同。此时,比如说,right就会去寻找比基准值小的数,可是,很明显,它找不到,于是它就越界了。
为此,就有了“三路划分”。三路划分和以往的三套方法相比,有些根本上的不同。三路划分不像上述三套方法一样,对等于基准值的数值视而不见,而是想办法,把这些数值移到中间。于是在经过一轮排序之后,数组就可以被分成三个部分:左边的部分,存放着比基准值小的数值;中间的部分,存放着和基准值相同的数值;右边的部分,存放着比基准值大的值。
在三路划分中,将会有三个指针:left right curr。left和right的初始位置仍然在数组两端,依旧把数组首元素视为基准值,curr最开始将会位于第二个成员处。之后curr将会对数组成员进行遍历,对于小于基准值的成员,将会与left指向的成员进行数值交换,这样做有两个目的:一是把比基准值小的数移到左边,二是把比基准值相同的数值往中间移;在进行完数值交换之后,left和curr都会向下移动一位;对于等于基准值的数,curr会直接移到下一位,将这些与基准值相同的成员交给left日后处理;如果成员大于基准值,curr指向的成员就会与right指向的成员进行数值交换,这样比基准值大的数值就被移到了右边,不过,由于不知道从right那边移过来的数值到底是什么情况,所以curr不会向后移一位,当然right确实会向前移一位;当curr到达right的右边时,就意味着,整个数组的全部成员都已经被curr遍历,比较过了,于是,这轮比较就结束了。
为了方便起见,下面的动图没有考虑三数取中。
static void _Quick_sort_root_particularly(pSortData pArray, int left, int right)
{if (left >= right)return;SortData key = pArray[left];int begin = left;int current = begin + 1;int end = right;while (current <= end){if (pArray[current] < key){Swap(&(pArray[begin++]), &(pArray[current++]));}else if (pArray[current] == key){current++;}else if (pArray[current] > key){Swap(&(pArray[end--]), &(pArray[current]));}}_Quick_sort_root_particularly(pArray, left, begin - 1);_Quick_sort_root_particularly(pArray, end + 1, right);
}void Quick_sort_particularly(pSortData pArray, int Size)
{_Quick_sort_root_particularly(pArray, 0, Size - 1);
}
PerformanceTesting(10, Quick_sort_particularly)int main()
{ test_Quick_sort_particularly();return 0;
}
当然,可以看到,我们之前写的比较函数还不够好,应该用整型或者其它类型,布尔值只有两个选项,而大小有三种可能:大于,小于,等于。应该用整型,大于0的代表大于,等于0的代表等于,小于0的代表小于。比较函数的缺陷之后我们还会再说。
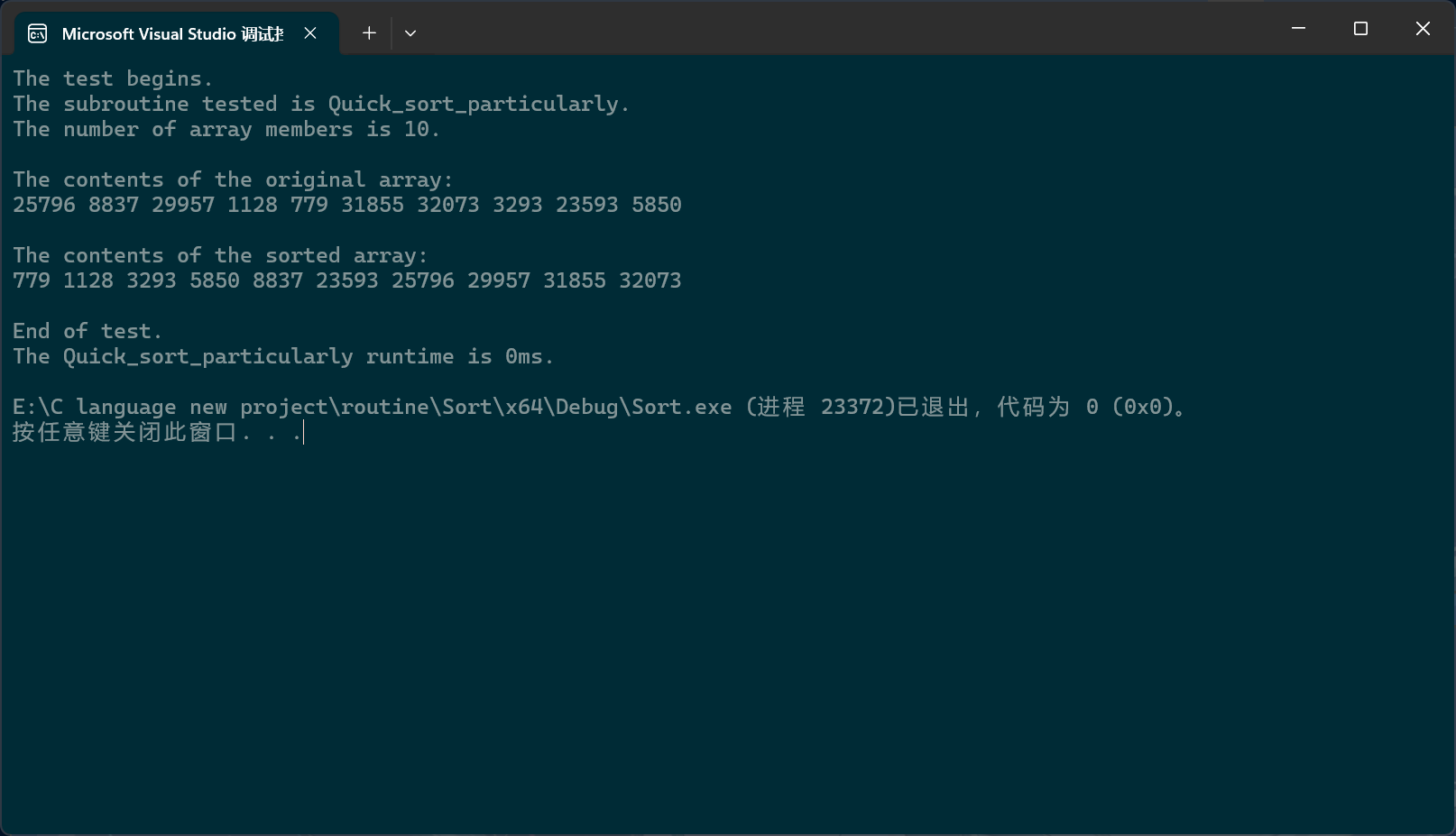
一般来说,这种级别的快排就没有什么问题了。但在某些在线编程测试平台上,即使是这种级别的快排依旧无法通过,无法通过的原因是因为上面的代码没有三数选中,所以效率有些低;但是,即使加上之前那三个方法的三数选中,依旧无法通过,因为,快排被这个平台恶意针对了,它的测试用例恰好是左中右就是极值,所以让三数选中失效了。
不过,我们也有对策。解决方案是不把选中数组中间的成员作为三数中中间的那个数,而是从选中数组中随机找一个成员作为中间的值。
int middle_of_three(pSortData pArray, int left, int right)
{srand((unsigned int)time(NULL));int mid = left + (rand() % (right - left));if (compare(pArray[left], pArray[mid])){if (compare(pArray[mid], pArray[right])){return mid;}else{if (compare(pArray[left], pArray[right])){return right;}elsereturn left;}}else{if (compare(pArray[right], pArray[mid])){return mid;}else{if (compare(pArray[left], pArray[right])){return left;}elsereturn right;}}
}
不过日常情况下用不着使用这种级别的快排,上面三种就够用了,当然,更可以直接使用标准库里的快排。
归并排序
归并排序使用的仍是分治的思想,它先将整个数组分成若干个子数组,然后再将这些子数组作进一步的拆分,直到拆分出的子数组一定是有序的。什么叫“一定有序”,很简单,拆的只剩一个成员它不就自然有序了。比如,对于一个有10个成员的数组来说,它先把这10个数组拆分成2个大小为5的子数组,下标分别是0到4, 5到9;然后再进一步拆分,拆成4个数组,下标分别是0到2, 3到4,5到7, 8到9,;随后再拆分,变成下标为0到1, 1到2, 3, 4, 5到6, 6到7, 8, 9········
拆成1个成员怎么办呢?比如现在已经有两个已经“被迫”(就一个成员吗)有序的数组了,第一个数组,有一个成员,是4;第二个数组,是1,;归并归并,就是归档,合并;于是我们先把这两个数组的首元素比较一下,我们发现,1是更小的,于是就把1拷贝到一个暂时的空间,然后第二个数组遍历完了,于是就把第一个数组剩下的部分,也就是那个6,拷贝到暂存空间中,然后再拷贝回去,这样,原数组的这两个子数组合并完了,于是,此时原数组的那个地方就变成了1,6;好的,现在已经有两个数组,这两个数组都有两个成员,第一个数组是1,6;第二个数组是3,8;然后呢,我们把这两个数组的首元素比较一下,我们发现,1更小是吧,就把1拷贝到暂存空间中,然后对比一下,第一个数组的第二成员和第二个数组的第一个成员,我们发现3更小,是吧,那就把3拷贝到暂存空间,然后再比较一下第一个数组和第二个成员的第二成员,我们发现6更小,于是拷贝到暂存空间,然后第一个数组没成员了,于是就把第二个数组的剩下部分再拷贝到暂存空间,此时暂存空间的这个地方就是1,3,6,8了,再把这地方拷贝会原数组的地方就行了。

因为某些不可抗拒因素,可能有些帧没有被成功录入。
void _Merge_sort_root(pSortData pArray, int left, int right, pSortData p_Temporary_Storage)
{if (left >= right)return;int mid = (left + right) / 2;_Merge_sort_root(pArray, left, mid, p_Temporary_Storage);_Merge_sort_root(pArray, mid + 1, right, p_Temporary_Storage);int begin1 = left, end1 = mid;int begin2 = mid + 1, end2 = right;int begin = left;while (begin1 <= end1 && begin2 <= end2){if (compare(pArray[begin1], pArray[begin2])){p_Temporary_Storage[begin++] = pArray[begin2++];}else{p_Temporary_Storage[begin++] = pArray[begin1++];}}while (begin1 <= end1){p_Temporary_Storage[begin++] = pArray[begin1++];}while (begin2 <= end2){p_Temporary_Storage[begin++] = pArray[begin2++];}memcpy(pArray + left, p_Temporary_Storage + left, sizeof(SortData) * (right - left + 1));
}void Merge_sort(pSortData pArray, int Size)
{pSortData pTS = (pSortData)malloc(sizeof(SortData) * Size);if (pTS == NULL){perror("Merge_sort pTS fail");return; }_Merge_sort_root(pArray, 0, Size - 1, pTS);free(pTS);
}
PerformanceTesting(10, Merge_sort)int main()
{ test_Merge_sort();return 0;
}
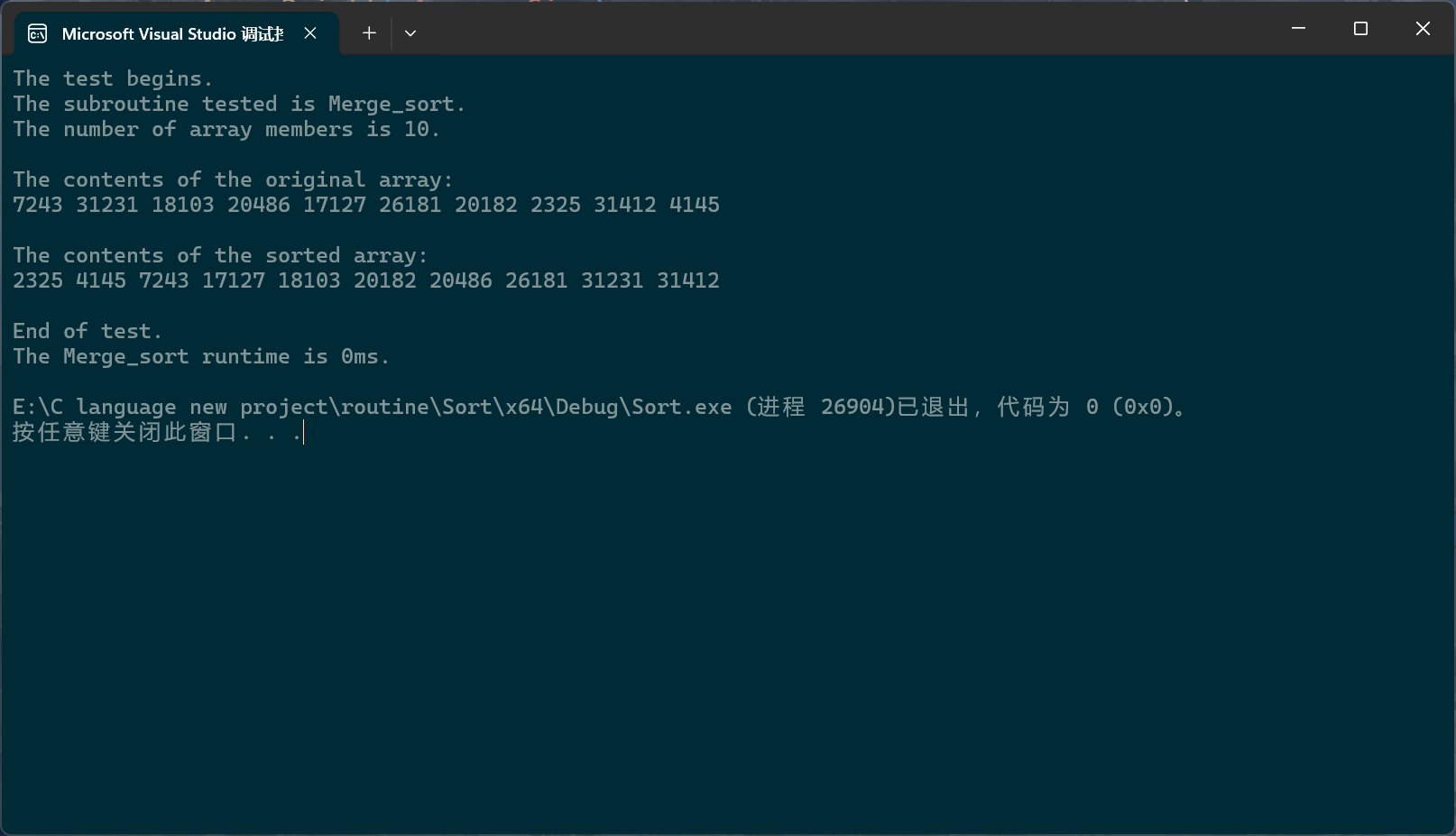
归并排序的递归写法还有一些地方可以再优化优化。我们知道,递归其实就是把函数栈帧以树的形式组织起来。当归并排序输入的数据量过大时,这棵树就会有太多的细小分支,这些细小分支中的数组个数都很小,没必要让它再继续分支下去。于是我们就可以设计一种机制,当数组的成员个数小到一定程度时,调用其他排序算法对这个小数组进行排序,这样的话,这个小数组其实也算是被迫有序了,就可以参与到后续的合并过程中。而且由于树结构的特点,比如,现在假设归并排序的递归版本所运行的栈帧树就是一棵标准的满二叉树,这样的话,每个栈帧都可以被视为一个节点;此时,这棵树一共有 2 H − 1 2^H-1 2H−1个节点,最后一层的节点数就是 2 H − 1 2^{H - 1} 2H−1,倒数第二层就是 2 H − 2 2^{H - 2} 2H−2,也就是说,最后一层大概占总结点数的50%,倒数第二层大概占总结点数的25.5%;而末端优化优化的正是这些更深处的层,于是,归并排序的总递归次数就少了不小。
那到底该选择什么排序呢?我这里用的是插入排序,毕竟这里要排的数组只是一个小数组罢了,用不着快排,堆排,希尔之类,再加上插入排序并不会破坏归并排序的稳定性(后面会说的),所以,还是用它。
具体改起来很简单
void _Merge_sort_root(pSortData pArray, int left, int right, pSortData p_Temporary_Storage)
{if (left >= right)return;if (right - left + 1 < 10){Insert_sort(pArray + left, right - left + 1);return;}int mid = (left + right) / 2;_Merge_sort_root(pArray, left, mid, p_Temporary_Storage);_Merge_sort_root(pArray, mid + 1, right, p_Temporary_Storage);int begin1 = left, end1 = mid;int begin2 = mid + 1, end2 = right;int begin = left;while (begin1 <= end1 && begin2 <= end2){if (compare(pArray[begin1], pArray[begin2])){p_Temporary_Storage[begin++] = pArray[begin2++];}else{p_Temporary_Storage[begin++] = pArray[begin1++];}}while (begin1 <= end1){p_Temporary_Storage[begin++] = pArray[begin1++];}while (begin2 <= end2){p_Temporary_Storage[begin++] = pArray[begin2++];}memcpy(pArray + left, p_Temporary_Storage + left, sizeof(SortData) * (right - left + 1));
}
接下来我们说一说归并排序的非递归。
上面我们说过,当数组只有一个成员时,它就自然而言地有序了,所以我们就先把数组中的相邻成员直接两两分组,每组排一下,然后每小组(两个成员)就有序了,然后,再把相邻的两个小组进行合并,以此类推,当然,可以预见到,这种方法肯定会有很多越界错误,所以我们要做的,就是把这些错误找出来,针对这些错误,对代码进行不断优化。
void Merge_sort_NonR(pSortData pArray, int Size)
{pSortData pTS = (pSortData)malloc(sizeof(SortData) * Size);if (pTS == NULL){perror("Merge_sort pTS fail");return;}int gap;for (gap = 1; gap < Size; gap *= 2){// The variable “begin” changes itself when it is written to the staging array, // eliminating the need to manually control the iteration.int begin = 0;while (begin < Size){// The variable “start” is used to control the starting position of the data copy.int start = begin;int begin1 = begin, end1 = begin1 + gap - 1;int begin2 = end1 + 1, end2 = begin2 + gap - 1;// The three conditional statements along with // the outer loop condition prevent the variable from going out of bounds.if (end1 >= Size){end1 = Size - 1;end2 = Size - 1;begin2 = end2 + 1;}if (begin2 >= Size){end2 = Size - 1;begin2 = end2 + 1;}if (end2 >= Size){end2 = Size - 1;}while (begin1 <= end1 && begin2 <= end2){if (compare(pArray[begin1], pArray[begin2])){pTS[begin++] = pArray[begin2++];}else{pTS[begin++] = pArray[begin1++];}}while (begin1 <= end1){pTS[begin++] = pArray[begin1++];}while (begin2 <= end2){pTS[begin++] = pArray[begin2++];}memcpy(pArray + start, pTS + start, sizeof(SortData) * (end2 - start + 1));}}free(pTS);
}
其中,条件语句的下标调整故意使得begin2>end2从而不进入下面的第一个循环。
PerformanceTesting(10, Merge_sort_NonR)int main()
{ test_Merge_sort_NonR();return 0;
}
还有一种方法实现归并排序的非递归,与上面的思想大致相同,主要区别是,这种写法的是一层一层地覆写回原数组的,而上面的写法是一对一对地覆写回原数组了。
为什么说是“一层一层”呢?这是从归并排序的递归角度来说的,很明显,在递归过程中,函数栈帧就像一棵树一样展开,这棵树的每一层都是把数组分成间隔不同的子数组,然后再逐个排序;
void Merge_sort_NonR1(pSortData pArray, int Size)
{pSortData pTS = (pSortData)malloc(sizeof(SortData) * Size);if (pTS == NULL){perror("Merge_sort pTS fail");return;}int gap;for (gap = 1; gap < Size; gap *= 2){int begin = 0;while (begin < Size){int begin1 = begin, end1 = begin1 + gap - 1;int begin2 = end1 + 1, end2 = begin2 + gap - 1;if (end1 >= Size){end1 = Size - 1;end2 = Size - 1;begin2 = end2 + 1;}if (begin2 >= Size){end2 = Size - 1;begin2 = end2 + 1;}if (end2 >= Size){end2 = Size - 1;}while (begin1 <= end1 && begin2 <= end2){if (compare(pArray[begin1], pArray[begin2])){pTS[begin++] = pArray[begin2++];}else{pTS[begin++] = pArray[begin1++];}}while (begin1 <= end1){pTS[begin++] = pArray[begin1++];}while (begin2 <= end2){pTS[begin++] = pArray[begin2++];}}memcpy(pArray, pTS, sizeof(SortData) * Size);}free(pTS);
}
差不多,这两种的关键都是控制下标不要越界。
PerformanceTesting(10, Merge_sort_NonR1)int main()
{ test_Merge_sort_NonR1();return 0;
}
内排序和外排序
之前我们在堆的章节说过,当数据量过大时,就无法将全部数据一次性压入内存。上面我们说的排序代码都是内排序,接下来我们将会学习外排序。所谓内排序就是在内存中对数据进行排序,外排序就是在外存(主要是硬盘)中对数据进行排序。
那外排序到底怎么排的呢?实际上,我们用的仍然是归并排序的思想,所以我在上文说,“排序代码”而不是“排序”;它的思想是把大文件分成一个个小文件,小到其中的数据已经放得下内存里了,然后,使用内排序对这些数据进行排序,然后再写回到文件的原位置处,之后以文件访问的方式打开这些子文件,使用文件指针对其中的成员逐个访问,依次类推。
由于时间关系,在此我们先只说思想。
非比较排序
上面我们说的排序都是比较排序,接下来我们说一说非比较排序,这种排序在日常生活中基本不会用到,主要是了解一下。
非比较排序分为基数排序和计数排序。基数排序用的就是学前班数学的思路:有两个数,怎么比较大小?先看一下,它们的位数都一样的,那就比一下最高位,谁最高位大谁就大,一样就比较下一位,它真的没什么用。
计数排序虽然在日常生活中也不会用到,但它具有很深的教育启蒙意义,往深了说,它是对哈希直接定址法的变形应用,这是C++里的,我就不深入讲了。
计数排序具体怎么做呢?
它首先会将要排序的数组遍历一遍,从而确定要排序数据的大致范围,然后依据这个范围开辟一个数组,接着再次遍历排序数组,对这些数据进行计数,遍历完后,对开辟数组的计数进行展开,就能得到有序数组,好吧,还是看动图吧。
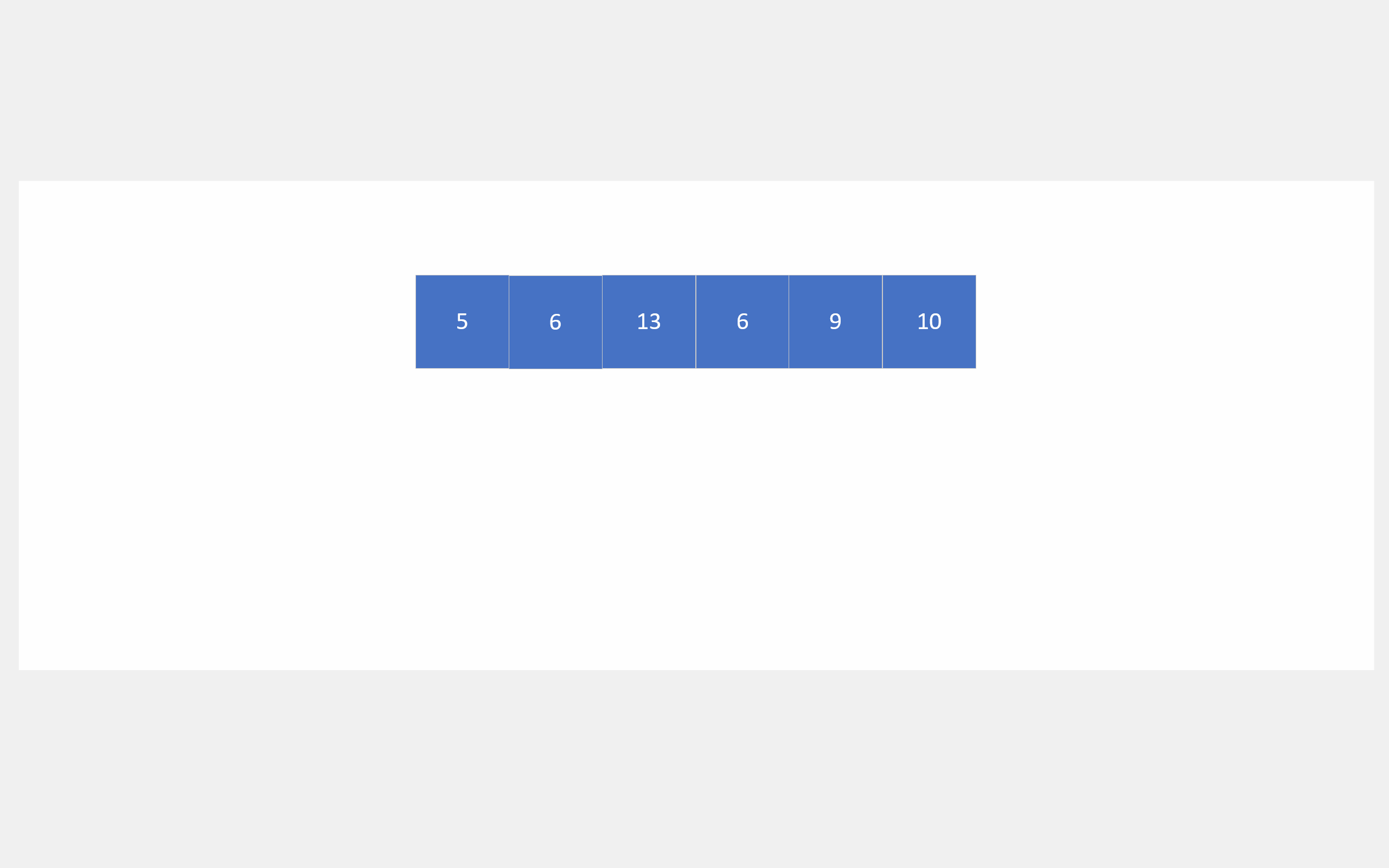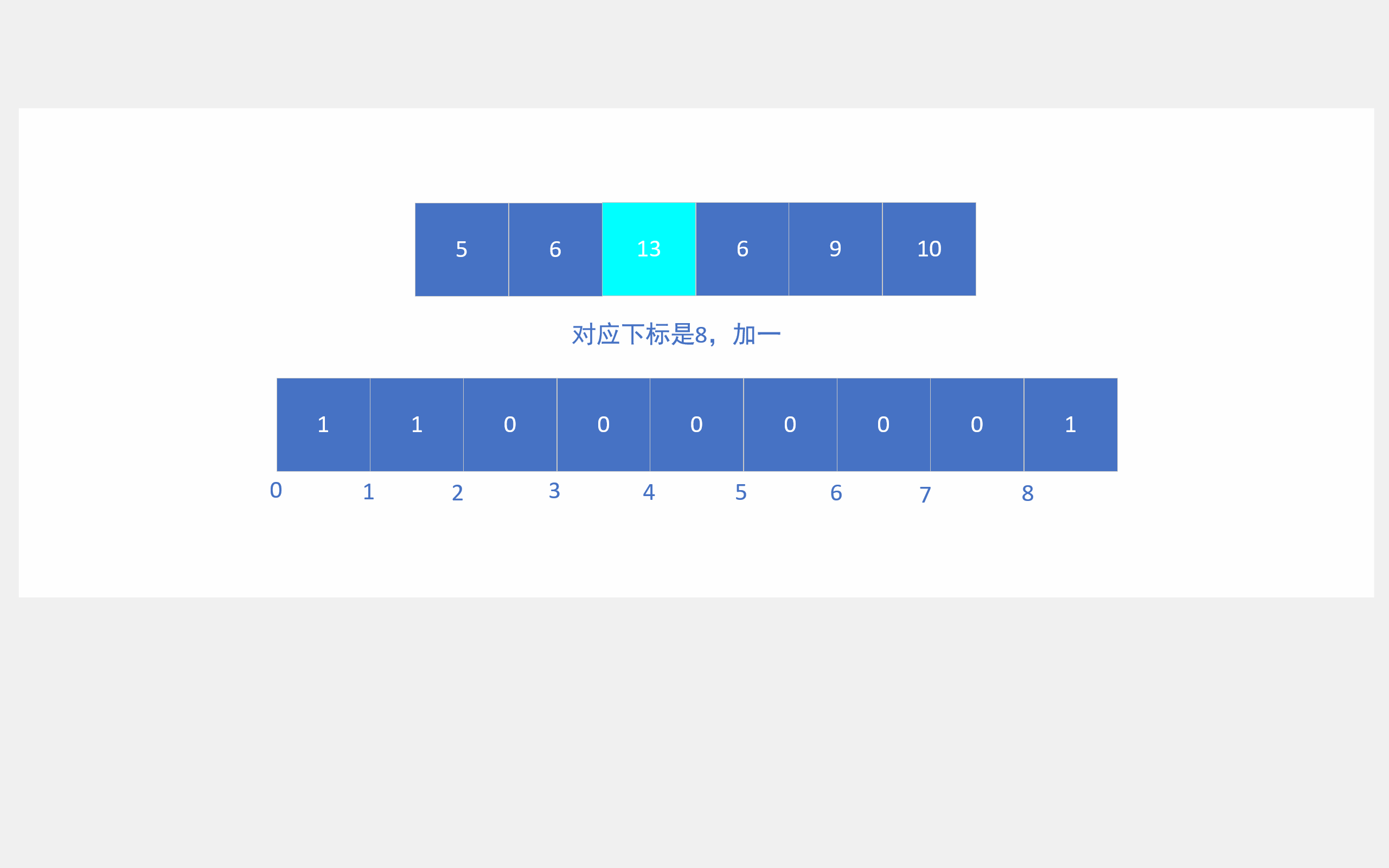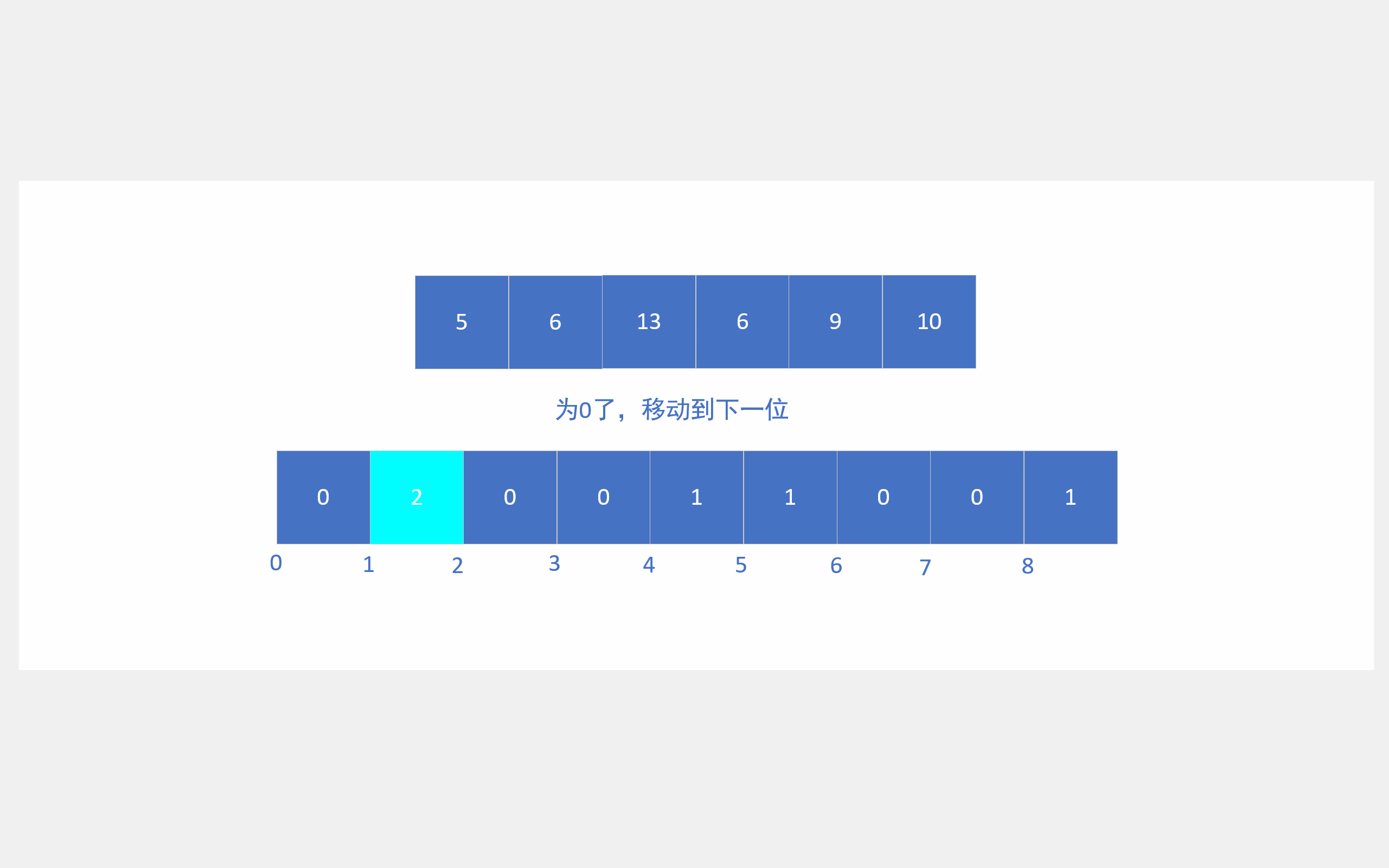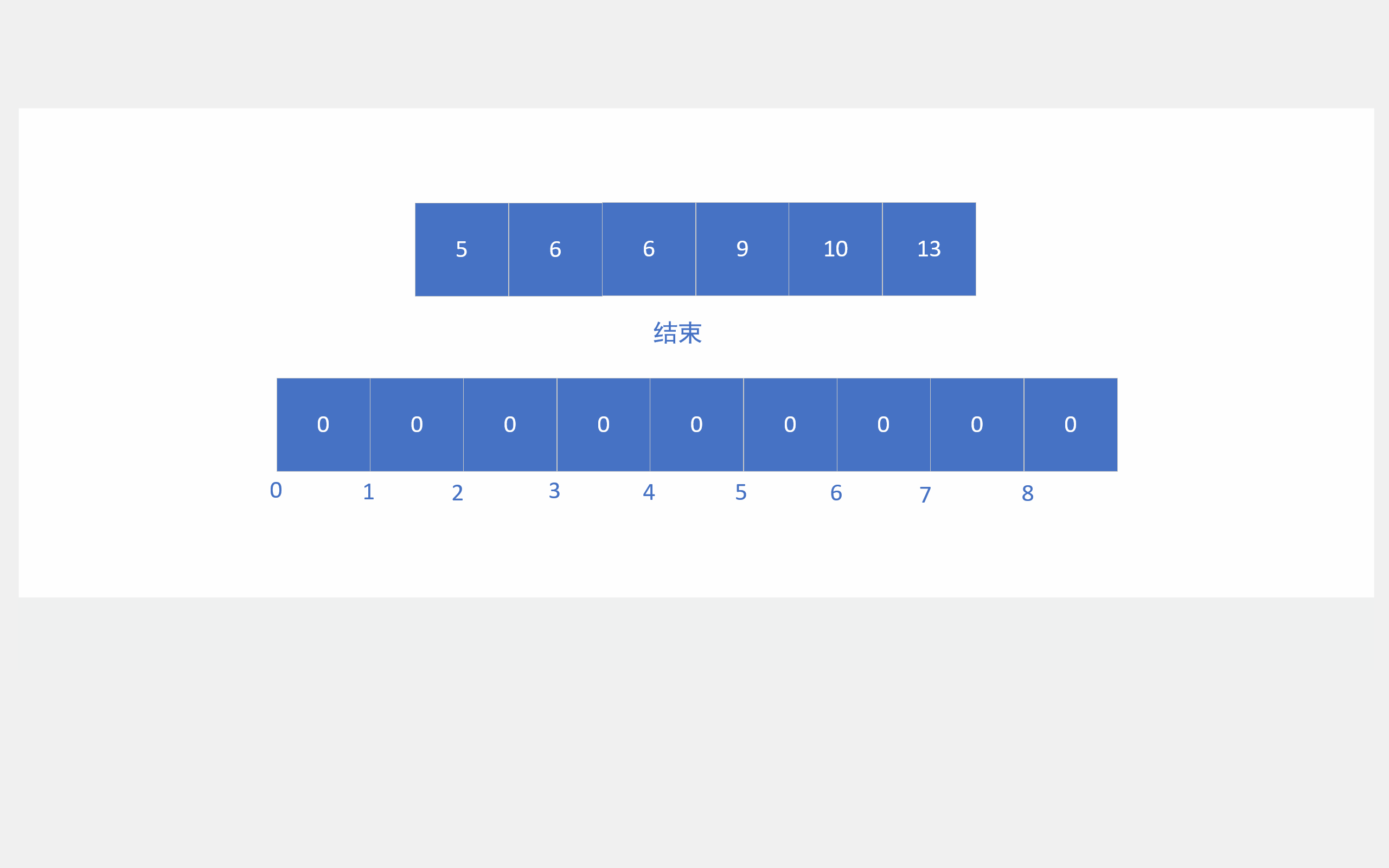
绝对映射就是1就对应下标1,2就对应下标2,3就对应下标3,100000就对应100000那种。如果这样映射,就要建13个成员的数组了。
void count_sort(int* pArray, int Size)
{int min = pArray[0], max = pArray[0];int current;for (current = 0; current < Size; current++){if (min > pArray[current]){min = pArray[current];}if (max < pArray[current]){max = pArray[current];}}int temSize = max - min + 1;int* p_tem = (int*)calloc(temSize, sizeof(int));if (p_tem == NULL){perror("count_sort malloc fail");return;}for (current = 0; current < Size; current++){p_tem[pArray[current] - min]++;}int i = 0;for (current = 0; current < temSize; current++){while (p_tem[current]){pArray[i++] = current + min;p_tem[current]--;}}free(p_tem);
}
int main()
{int arr[] = { 4,7,15,6,7,8,9,5,6,15,13 };int sz = sizeof(arr) / sizeof(arr[0]);count_sort(arr, sz);int i;for (i = 0; i < sz; i++){printf("%d ",arr[i]);}printf("\n");return 0;
}
很明显,计数排序很受数组数据范围的影响,所以不能使用通用测试模块,另外,你可能注意到,计数排序的数据类型用的全是原生类型,因为计数排序只能对整型,或者说整数进行排序,它的数据类型是被定死的。

稳定性
什么叫稳定性?可能有些人会将稳定性误以为是性能的稳定性,其实不是。在排序过程中,可能会有相同的数值成员,为了方便,我们就认为有两个相同的值, A 1 A_1 A1和 A 2 A_2 A2,如果在排序之前, A 1 A_1 A1在 A 2 A_2 A2的前面,排完序后, A 1 A_1 A1依旧在 A 2 A_2 A2的前面,那这种算法就是稳定的,否则就是不稳定的。
这是有实际应用价值的。描述某个事物,可能要不止一个数据,比如,它可能是个结构体,此时就要进行多次排序,优先级高的先排序,然后对于数值相同的,我们需要进行下一轮排序,此时的参考项就是优先级低一层的。
比如,对于某场考试,它可能由多场科目构成,比如说,有科目ABC,优先级依次降低,我先比一下总分,然后再比一下A科,再比一下B科,接着是C科,此时的排序算法就必须是稳定的才行。
冒泡是稳定的,对于相同的数值,不会进行交换;直接插入排序是稳定的,对于数值相同的项,我们是写在有序区后一位的;希尔排序只能保证子数组的稳定性,但整体稳定性就无法保证了;选择排序我就不分析了,直接举个反例:已知在数组中现有四个数: A 1 A 2 ; B 1 B 2 A_1 A_2; B_1 B_2 A1A2;B1B2,已知 A > B A>B A>B,其中 A 1 A_1 A1是数组首元素, A 2 A_2 A2夹在 B 1 B_1 B1和 A 1 A_1 A1之间; A 2 A_2 A2在 A 1 A_1 A1之后,为了方便考虑,我们每轮就找一个极值,最小值;现在假设, B B B恰好即使是最小的那个值,于是在第一轮寻找中, A 1 A_1 A1就会和 B 1 B_1 B1交换位置,这样, A 1 A_1 A1就会在 A 2 A_2 A2后了,换言之,稳定性被破坏了;堆排序也不稳定,比如,现在要建一个小堆,根节点和左节点数值相同,根节点大于右节点,这样一交换,稳定性就被破坏了;快排不稳定,即使不考虑三数取中,它也是不稳的,当有两个比基准值大的相同值时,就不稳定了;归并,要看具体代码,比如在上面的代码中,如果等于,先写入的确实是begin1,所以是稳定的,如果else分支里写的是begin2那就不稳了,此时若要稳定,就需要在条件判断里加个等于号,不过由于这里的比较函数设计有缺陷,所以要仿照霍尔排序的那种取反来写。
urrent = 0; current < Size; current++)
{
p_tem[pArray[current] - min]++;
}
int i = 0;
for (current = 0; current < temSize; current++)
{
while (p_tem[current])
{
pArray[i++] = current + min;
p_tem[current]–;
}
}
free(p_tem);
}
```c
int main()
{int arr[] = { 4,7,15,6,7,8,9,5,6,15,13 };int sz = sizeof(arr) / sizeof(arr[0]);count_sort(arr, sz);int i;for (i = 0; i < sz; i++){printf("%d ",arr[i]);}printf("\n");return 0;
}
很明显,计数排序很受数组数据范围的影响,所以不能使用通用测试模块,另外,你可能注意到,计数排序的数据类型用的全是原生类型,因为计数排序只能对整型,或者说整数进行排序,它的数据类型是被定死的。
[外链图片转存中…(img-Qzr03ymo-1726732666915)]
稳定性
什么叫稳定性?可能有些人会将稳定性误以为是性能的稳定性,其实不是。在排序过程中,可能会有相同的数值成员,为了方便,我们就认为有两个相同的值, A 1 A_1 A1和 A 2 A_2 A2,如果在排序之前, A 1 A_1 A1在 A 2 A_2 A2的前面,排完序后, A 1 A_1 A1依旧在 A 2 A_2 A2的前面,那这种算法就是稳定的,否则就是不稳定的。
这是有实际应用价值的。描述某个事物,可能要不止一个数据,比如,它可能是个结构体,此时就要进行多次排序,优先级高的先排序,然后对于数值相同的,我们需要进行下一轮排序,此时的参考项就是优先级低一层的。
比如,对于某场考试,它可能由多场科目构成,比如说,有科目ABC,优先级依次降低,我先比一下总分,然后再比一下A科,再比一下B科,接着是C科,此时的排序算法就必须是稳定的才行。
冒泡是稳定的,对于相同的数值,不会进行交换;直接插入排序是稳定的,对于数值相同的项,我们是写在有序区后一位的;希尔排序只能保证子数组的稳定性,但整体稳定性就无法保证了;选择排序我就不分析了,直接举个反例:已知在数组中现有四个数: A 1 A 2 ; B 1 B 2 A_1 A_2; B_1 B_2 A1A2;B1B2,已知 A > B A>B A>B,其中 A 1 A_1 A1是数组首元素, A 2 A_2 A2夹在 B 1 B_1 B1和 A 1 A_1 A1之间; A 2 A_2 A2在 A 1 A_1 A1之后,为了方便考虑,我们每轮就找一个极值,最小值;现在假设, B B B恰好即使是最小的那个值,于是在第一轮寻找中, A 1 A_1 A1就会和 B 1 B_1 B1交换位置,这样, A 1 A_1 A1就会在 A 2 A_2 A2后了,换言之,稳定性被破坏了;堆排序也不稳定,比如,现在要建一个小堆,根节点和左节点数值相同,根节点大于右节点,这样一交换,稳定性就被破坏了;快排不稳定,即使不考虑三数取中,它也是不稳的,当有两个比基准值大的相同值时,就不稳定了;归并,要看具体代码,比如在上面的代码中,如果等于,先写入的确实是begin1,所以是稳定的,如果else分支里写的是begin2那就不稳了,此时若要稳定,就需要在条件判断里加个等于号,不过由于这里的比较函数设计有缺陷,所以要仿照霍尔排序的那种取反来写。
完
相关文章:
排序学习笔记
目录 排序排序的相关概念冒泡排序插入排序选择排序堆排序快速排序归并排序 内排序和外排序非比较排序稳定性稳定性 完 排序 排序的相关概念 排序:所谓排序,就是使一串记录,按照其中的某个或某些关键字的大小,递增或递减的排列起…...

【nginx】缓存配置文件
http {# ... 其他配置 ...# 缓存目录配置proxy_cache_path /var/cache/nginx/proxy_cache levels1:2 keys_zonemy_cache:10m inactive60m use_temp_pathoff;# ... 其他配置 ... }server {listen 80;server_name www.example.com;location / {root /var/www/example.com/public;…...

如何使用 maxwell 同步到 redis?
文章目录 1、MaxwellListener2、MxwObject1. 使用Maxwell捕获MySQL变更2. 将Maxwell的输出连接到消息系统3. 从消息系统读取数据并同步到Redis注意事项 1、MaxwellListener package com.atguigu.tingshu.album.listener;import com.alibaba.fastjson.JSON; import org.apache.…...

C++ 元编程
目录 C 元编程1. 术语2. 元函数1. 数值元函数示例:阶乘计算 2. 类型元函数示例:类型选择 3. 混合编程1. 常规的计算点积范例2. 混合元编程计算点积 4. typelist实现设计和基本操作接口(算法)完整代码 5. tuple 实现基础知识1. 左值…...

运行npm install 时,卡在sill idealTree buildDeps没有反应
一直停留在sill idealTree buildDeps 解决方法 npm config set registry https://registry.npm.taobao.org 配置后用下面命令看是否配置成功 npm config get registry 如果配置还不好使 就执行下行的ssl npm set strict-ssl false 然后执行 npm install 成功执行...

swc 编译 es6为commonjs
如果直接写es6后运行node index.js 报错:SyntaxError: Cannot use import statement outside a module js 我们这里使用swc来将es6编译成CommonJS。 以后可以作为一个简单的框架模版使用。 安装 pnpm add swc/cli swc/core 配置.swcrc {"$schema": &q…...

#nginx配置案例
示例配置 1:反向代理 负载均衡 缓存控制 http {# 定义后端服务器池,用于负载均衡upstream backend_servers {server backend1.example.com weight3; # 权重为3server backend2.example.com weight1; # 权重为1server backend3.example.com backup; …...

STM32—I2C通信外设
1.I2C外设简介 STM32内部集成了硬件I2C收发电路,可以由硬件自动执行时钟生成、起始终止条件生成、应答位收发、数据收发等功能,减轻CPU的负担支持多主机模型(可变多主机)支持7位/10位地址模式(11110......)支持不同的通…...

Java-测试-Mockito 入门篇
之前很长一段时间我都认为测试就是使用SpringBootTest类似下面的写法: SpringBootTest class SysAuthServiceTest {AutowiredSysRoleAuthMapper sysRoleAuthMapper;Testpublic void test() {QueryWrapper<SysRoleAuth> queryWrapper new QueryWrapper<&g…...

【jupyter notebook】环境部署及pycharm连接虚拟机和本地两种方式
Python数据处理分析简介 Python作为当下最为流行的编程语言之一 可以独立完成数据分析的各种任务数据分析领域里有海量开源库机器学习/深度学习领域最热门的编程语言在爬虫,Web开发等领域均有应用 与Excel,PowerBI,Tableau等软件比较 Excel有…...

TypeScript异常处理
1.异常的概念 程序运行中意外发生的情况就成为异常 例子: //除法运算function chu(num1:number,num2:number){if(num20){//throw 抛出异常throw new Error(除数不能为零)}let num:numbernum1/num2console.log(num) }//程序出现异常后会停止运行// 捕获异常try{ /…...

go的学习笔记
中文标准库文档:https://studygolang.com/pkgdoc 第一段代码 所有代码的主文件都是main.go,下面的代码直接在项目里面创建main.go运行 package main // 声明文件所在的包,每个go文件必须有归属的包import "fmt" // 引入程序需要的包,为了使用包下的函数,比如Print…...

卷积和转置卷积的输出尺寸计算
卷积和转置卷积的输出尺寸计算 卷积 h是输出的高,h是输入的高,k_h是卷积核的高 w类似stride1 h h - k_h padding*2 1通用公式 stride1就是上面的公式 h (h - k_w 2*padding stride)//stride 一些常见的卷积 高宽不变的卷积:kernel…...

vue3+ts 使用amCharts展示地图,1.点击左侧国家,可以高亮并放大右侧地图对应的国家。 2.展示数据球。
效果图展示: 1.点击左侧国家,可以高亮并放大右侧地图对应的国家。 2.展示数据球。 下载依赖 yarn add amcharts/amcharts5其中,props.countryData的数据格式为 [{ “country”: “加拿大”, “code”: “CA”, “deviceCount”: 1 },{ “c…...

汽车无钥匙启动功能工作原理
移动管家无钥匙启动是一种科技化的汽车启动方式,它允许车主在不使用传统钥匙的情况下启动车辆。这种技术通过智能感应系统实现,车主只需携带智能钥匙,当靠近车辆时,车辆能够自动解锁并准备启动。启动车辆时,车主无…...

C++标准的一些特性记录:C++11的auto和decltype
文章目录 auto容器遍历配合lambda表达式decltype两者对引用类型的处理是相同的decltype保留const,而auto不会保留const在C++11中,引入了两个新的关键字,auto和decltype两个关键字,都是用于做类型推断。但是使用的场景有些区别。 auto 容器遍历 auto这个关键字,我个人在编…...

【Elasticsearch系列四】ELK Stack
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...
【新手上路】衡石分析平台使用手册-认证方式
认证方式 用户登录衡石系统时,系统需要对输入的用户名和密码进行验证,保证系统的安全。衡石提供 CAS、SAML2、OAUTH2等多种单点登录认证方式。在 SSO 单点登录中,衡石是服务提供者 SP(Service Provider)为用户提供所…...

数字电路与逻辑设计-触发器功能测试及其应用
一、实验目的 1.验证基本RS、JK、D、T和T’触发器的逻辑功能及使用方法; 2.能进行触发器之间的相互转换; 3.学习触发器的一些应用。 二、实验原理 触发器具有两个能够自行保持的稳定状态,用以表示逻辑状…...

【网站架构部署与优化】web服务与http协议
文章目录 HTMLHTML 概述HTML 语法规则HTML 文件结构头标签中常用标签静态网页与动态网页1. 静态网页2. 动态网页3. 动态网页语言 HTTP协议概述主要的HTTP版本包括:HTTP方法GET与POST方法的比较 HTTP状态码分类及常见状态码HTTP常见状态码 HTTP 请求流程分析1. 请求报…...

AMLP:基于大语言模型的自动化机器学习势函数构建平台
1. 项目概述:当AI遇见原子模拟,AMLP如何重塑机器学习势函数构建在计算材料科学和化学物理领域,分子动力学模拟是我们窥探微观世界动态行为的“显微镜”。无论是研究新材料的相变过程,还是探索生物大分子的折叠机制,其核…...

从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器
从理论推导到代码实现:手把手教你用Python/Numpy写出守恒形式的NS方程求解器计算流体力学(CFD)的魅力在于它将抽象的数学方程转化为可执行的代码,让流体运动的奥秘在计算机中重现。对于已经掌握流体力学理论的中高级学习者来说&am…...

为什么视频代剪辑会影响你的内容传播效果
为什么你精心拍的视频,发出去却没人看? 你有没有过这样的经历:花了一整天拍Vlog,素材画质高清、内容真实,可一剪出来就显得平淡无奇,点赞寥寥?或者婚礼当天感动全场,回看成片却像流水…...
)
Windows 10/11系统下,SecureCRT 8.7.2保姆级安装与激活图文指南(含Keygen使用避坑点)
Windows平台SecureCRT 8.7.2全流程部署与安全配置指南在当今远程运维与网络管理的日常工作中,一款可靠的终端仿真工具如同工程师的瑞士军刀。作为行业标杆的SecureCRT,其8.7.2版本在Windows 10/11环境下的部署却常让新手陷入各种技术陷阱——从安装路径选…...

森优时铁锌维发根养黑用三个月真实效果实测:内服营养养黑的客观测评
"森优时铁锌维发根养黑用三个月真实效果实测显示,针对压力、熬夜引发的早白问题,通过内服补充毛囊所需营养的方式,多数使用者能感受到发根韧性提升、新生发色素沉淀改善,整体改善效果因人而异,合规的营养补充是目…...

skills CANN开源社区贡献技能包开发指南
前言 开源社区的健康运转,不仅依赖核心代码的贡献,还需要降低贡献门槛、提供清晰的指南和自动化工具。skills仓库是CANN开源社区的"贡献技能包",提供了一系列辅助脚本、代码模板、CI检查和文档生成工具,帮助新手快速上…...

通过curl命令快速测试Taotoken大模型API的连通性与返回格式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken大模型API的连通性与返回格式 在集成大模型能力到应用时,开发者通常需要一种快速、轻量的…...

告别枯燥理论!用Unity脚本生命周期与预制体玩转一个“会变身的敌人”
用Unity打造会变身的敌人:脚本生命周期与预制体的实战应用在游戏开发中,敌人AI的行为设计往往是新手开发者最感兴趣也最容易感到困惑的部分。Unity的脚本生命周期和预制体系统为这类需求提供了强大支持,但教科书式的讲解常常让学习者陷入枯燥…...

统信UOS浏览器书签同步难题?一招搞定所有新用户默认书签配置
统信UOS浏览器书签批量配置:系统管理员的高效部署指南在企业或教育机构的IT运维工作中,统信UOS作为国产操作系统的代表,其浏览器书签的统一管理常常成为系统管理员面临的挑战。想象一下,每当有新员工入职或学生入学,都…...

PrivacyGuard实战:基于实证差分隐私的机器学习模型隐私审计框架
1. 项目概述与核心价值在过去的几年里,我亲眼见证了机器学习模型从实验室走向银行、医疗、社交网络等各个敏感领域的全过程。模型性能的每一次飞跃都令人兴奋,但随之而来的隐私泄露事件也一次次为我们敲响警钟。一个在医疗数据上训练出的诊断模型&#x…...