本地部署huggingface模型,建立自己的翻译应用
过去,我们使用翻译接口时,往往都是使用百度等的接口,每天有一定量的免费额度。今天为大家介绍一个可以进行翻译的模型,具备英译中、中译英的能力。并且在这个过程中,向大家介绍一个如何在本地部署模型。在之前的”五天入门RAG“中,我们介绍过如何线上运行,但这是需要网络条件的,当你不具备时,可以在本地安装使用。
这个模型就是Helsinki-NLP/opus-mt-zh-en和Helsinki-NLP/opus-mt-en-zh。在后面,我们会再带大家体验具备语音翻译,转录的模型SeamlessM4T。
首先进入:https://huggingface.co/
搜索:Helsinki-NLP/opus-mt-zh-en
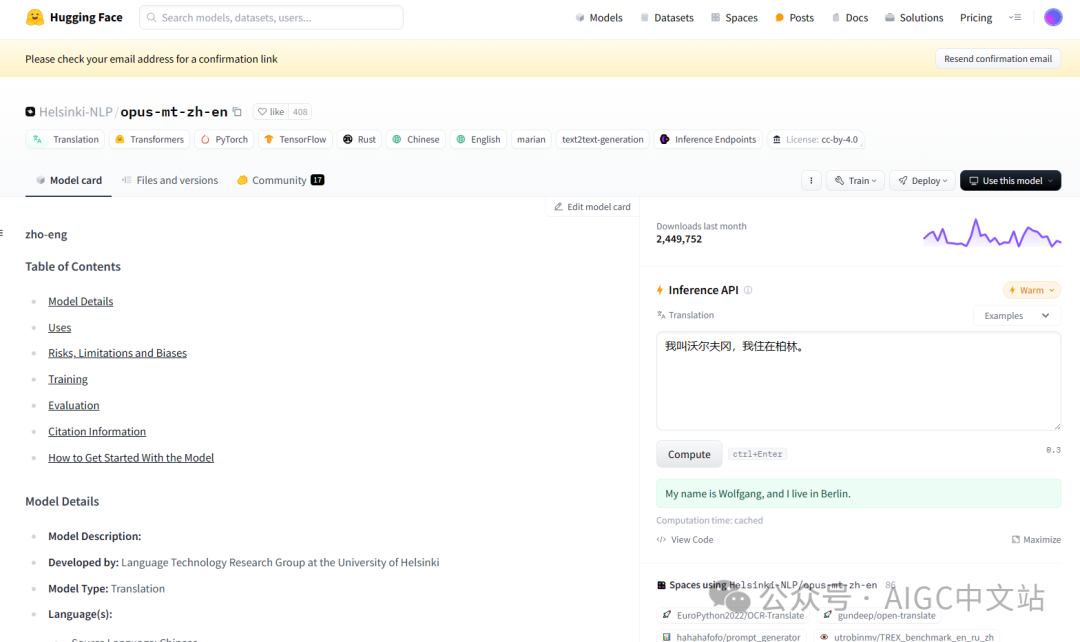
点击右边的compute试一下,翻译效果还不错。
然后点击files卡片。
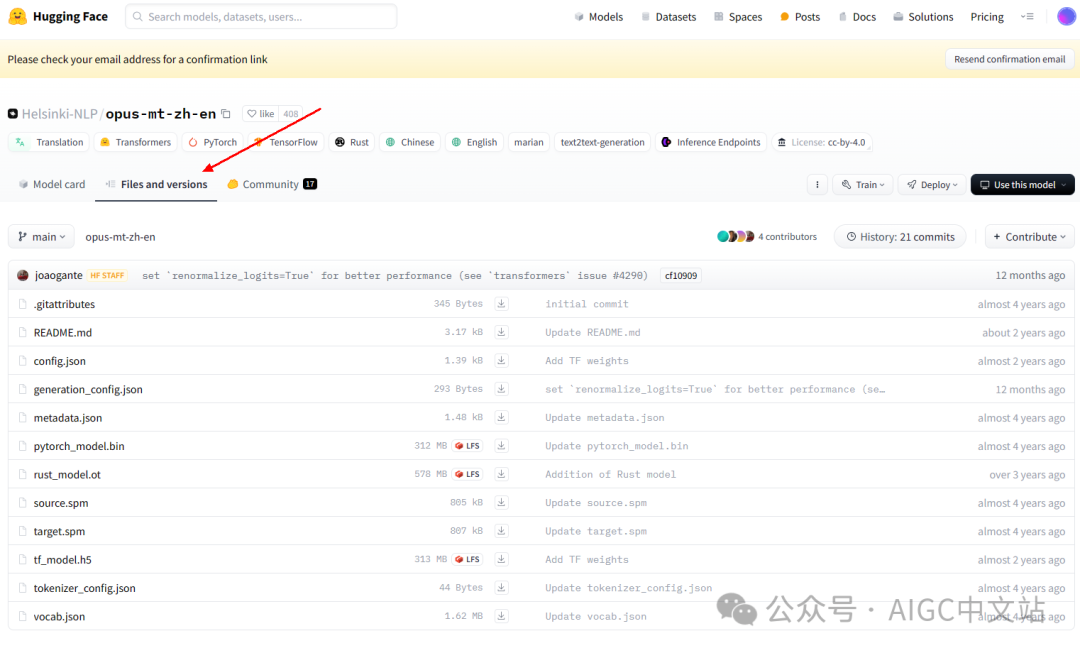
主要下载如下的几个文件。
放到自己本地目录下:
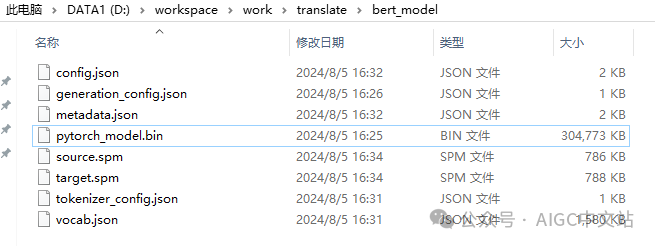
然后输入我们的翻译代码:
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM# 模型名称,如果模型已经下载到本地,可以直接指定路径
modelName = "D:/workspace/work/translate/bert_model/"
srcText = [
"大家好,我是一只来自中国的大熊猫",
"在这种方式下,我们的transformers才能发挥最大的作用",
"啊!华山,你可真是壮美",
]#---------------------------------tokenizer = AutoTokenizer.from_pretrained(modelName)
model = AutoModelForSeq2SeqLM.from_pretrained(modelName)
translated = model.generate(**tokenizer(srcText, return_tensors="pt", padding=True))
# 返回结果
r = [tokenizer.decode(t, skip_special_tokens=True) for t in translated]print(r)
代码可能会提示错误
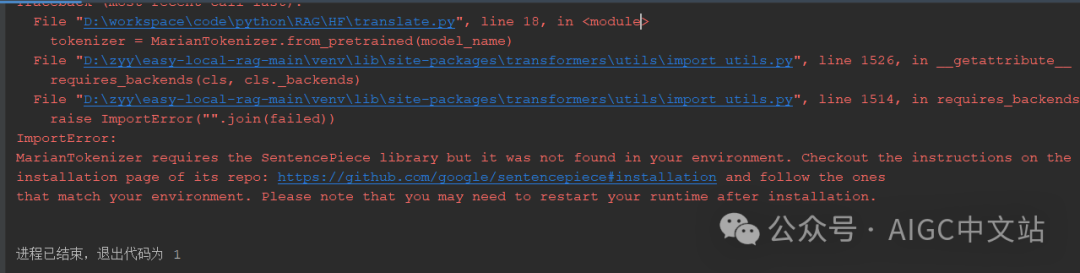
那么我们安装这个就是了,代码如下:
pip install SentencePiece
然后再运行:

["Hello. I'm a big panda from China.",
"In this way, our transformers will be most effective.",
"Oh, you're so beautiful, Wahshan."]
同样的,英译中使用另一个模型即可。
我们简单解释一下代码!
AutoTokenizer.from_pretrained
用于加载预训练的文本处理模型(Tokenizer),以便将文本数据转换为模型可以接受的输入格式。这个方法接受多个参数,以下是这些参数的详细说明:
1.pretrained_model_name_or_path (str):
-这是最重要的参数,指定要加载的预训练模型的名称或路径。可以是模型名称(例如 “bert-base-uncased”)或模型文件夹的路径。
\2. inputs (additional positional arguments, optional)
它表示额外的位置参数,这些参数会传递给标记器(Tokenizer)的__init__()方法。这允许你进一步自定义标记器的初始化。
\3. config ([PretrainedConfig], optional)
这个配置对象用于确定要实例化的分词器类。
4.cache_dir (str, optional):
用于缓存模型文件的目录路径
\5. force_download (bool, optional):
如果设置为 True,将强制重新下载模型配置,覆盖任何现有的缓存。
\6. resume_download (bool, optional):
-这是可选参数,如果设置为 True,则在下载过程中重新开始下载,即使部分文件已经存在。
\7. proxies (Dict[str, str], optional)
proxies(可选参数):这是一个字典,用于指定代理服务器的设置。代理服务器允许您在访问互联网资源时通过中继服务器进行请求,这对于在受限网络环境中使用 Transformers 库来加载模型配置信息非常有用。
proxies = { “http”: “http://your_http_proxy_url”, “https”: “https://your_https_proxy_url” }
\8. revision (str, optional):
指定要加载的模型的 Git 版本(通过提交哈希)。
\9. subfolder (str, optional)
如果相关文件位于 huggingface.co 模型仓库的子文件夹内(例如 facebook/rag-token-base),请在这里指定。
\10. use_fast (bool, optional, defaults to True)
这是一个布尔值,指示是否强制使用 fast tokenizer,即使其不支持特定模型的功能。默认为 True。
\11. tokenizer_type (str, optional)
参数用于指定要实例化的分词器的类型
\12. trust_remote_code (bool, optional, defaults to False)
trust_remote_code=True:
默认情况下,trust_remote_code 设置为 True。这意味着当您使用 from_pretrained() 方法加载模型配置文件时,它将下载来自 Hugging Face 模型中心或其他在线资源的配置文件。这是一个方便的默认行为,因为通常这些配置文件是由官方提供的,且是可信的。
trust_remote_code=False:
如果您将 trust_remote_code 设置为 False,则表示您不信任从远程下载的配置文件,希望加载本地的配置文件。这对于安全性或定制性要求较高的场景可能是有用的。
在这种情况下,您需要提供一个本地文件路径,以明确指定要加载的配置文件
总之,trust_remote_code 参数允许您在使用 Hugging Face Transformers 库时控制是否信任从远程下载的配置文件。默认情况下,它被设置为 True,以方便加载官方提供的配置文件,但您可以将其设置为 False 并提供本地配置文件的路径,以进行更精细的控制。
AutoModel.from_pretrained()
AutoModel.from_pretrained() 是 Hugging Face Transformers 库中的一个函数,用于加载预训练的深度学习模型。它允许你加载各种不同的模型,如BERT、GPT-2、RoBERTa 等,而无需为每个模型类型编写单独的加载代码。以下是 AutoModel.from_pretrained() 函数的主要参数:
\1. pretrained_model_name_or_path (str):
-这是一个字符串参数,用于指定要加载的预训练模型的名称或路径。可以是模型的名称(如 “bert-base-uncased”)或模型文件夹的路径。
\2. *model_args
直接传参的方式,传入配置项,例如,我们将编码器层数改为3层
model = AutoModel.from_pretrained(“./models/bert-base-chinese”, num_hidden_layers=3)
加载模型时,指定配置类实例
model = AutoModel.from_pretrained(“./models/bert-base-chinese”, config=config)
3.trust_remote_code (bool, optional, defaults to False)
trust_remote_code=True:
默认情况下,trust_remote_code 设置为 True。这意味着当您使用 from_pretrained() 方法加载模型配置文件时,它将下载来自 Hugging Face 模型中心或其他在线资源的配置文件。这是一个方便的默认行为,因为通常这些配置文件是由官方提供的,且是可信的。
trust_remote_code=False:
如果您将 trust_remote_code 设置为 False,则表示您不信任从远程下载的配置文件,希望加载本地的配置文件。这对于安全性或定制性要求较高的场景可能是有用的。
在这种情况下,您需要提供一个本地文件路径,以明确指定要加载的配置文件
总之,trust_remote_code 参数允许您在使用 Hugging Face Transformers 库时控制是否信任从远程下载的配置文件。默认情况下,它被设置为 True,以方便加载官方提供的配置文件,但您可以将其设置为 False 并提供本地配置文件的路径,以进行更精细的控制。
hub_kwargs_names = [
“cache_dir”, #同上面
“force_download”,#同上面
“local_files_only”,
“proxies”, #同上面
“resume_download”, #同上面
“revision”, #同上面
“subfolder”, #同上面
“use_auth_token”,
]
local_files_only:
如果设置为True,将只尝试从本地文件系统加载模型。如果本地文件不存在,它将不会尝试从Hugging Face模型存储库下载模型文件。如果本地存在模型文件,它将从本地加载。如果设置为False(默认值),它将首先尝试从本地加载,如果本地不存在模型文件,它将尝试从Hugging Face模型存储库下载模型文件并缓存到本地,然后加载。
from transformers import AutoModel
model = AutoModel.from_pretrained(“bert-base-uncased”, local_files_only=True)
详解 use_auth_token 参数:
默认值:use_auth_token 参数的默认值通常为 None,这意味着在默认情况下不使用身份验证令牌。
作用:Hugging Face Model Hub 上的一些模型可能需要身份验证令牌才能访问。这通常是因为模型的创建者希望对其进行访问控制,或者出于其他原因需要进行身份验证。如果模型需要身份验证令牌,你可以在 use_auth_token 参数中提供有效的令牌,以便在下载模型时使用。
获取身份验证令牌:要获得有效的身份验证令牌,你需要注册并登录到 Hugging Face Model Hub,然后访问你的个人配置文件(profile),那里会提供一个 API 令牌(API token),你可以将其用作 use_auth_token 的值。
from transformers import AutoModel
# 使用身份验证令牌来加载模型
model = AutoModel.from_pretrained(‘model_name’, use_auth_token=‘your_auth_token’)
大多数模型不需要身份验证令牌,并且可以在不提供 use_auth_token 参数的情况下加载。只有在你确实需要进行身份验证才需要使用此参数。
model.generate()
model()的使用场景:当你需要对输入数据执行一次完整的前向计算时使用,如分类任务、特征提取等。
model.generate()的使用场景:当你需要模型自动生成文本或序列,尤其是在语言模型中,如GPT、T5等。
return_tensors=‘pt’, 自动的将所有的结果都转化成二纬的tensor数据,因此,后面我们还需要将数据进行解码,完成编码解码。
如何学习大模型 AI ?
由于新岗位的生产效率,要优于被取代岗位的生产效率,所以实际上整个社会的生产效率是提升的。
但是具体到个人,只能说是:
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在人工智能学习中的很多困惑,所以在工作繁忙的情况下还是坚持各种整理和分享。但苦于知识传播途径有限,很多互联网行业朋友无法获得正确的资料得到学习提升,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。

第一阶段(10天):初阶应用
该阶段让大家对大模型 AI有一个最前沿的认识,对大模型 AI 的理解超过 95% 的人,可以在相关讨论时发表高级、不跟风、又接地气的见解,别人只会和 AI 聊天,而你能调教 AI,并能用代码将大模型和业务衔接。
- 大模型 AI 能干什么?
- 大模型是怎样获得「智能」的?
- 用好 AI 的核心心法
- 大模型应用业务架构
- 大模型应用技术架构
- 代码示例:向 GPT-3.5 灌入新知识
- 提示工程的意义和核心思想
- Prompt 典型构成
- 指令调优方法论
- 思维链和思维树
- Prompt 攻击和防范
- …
第二阶段(30天):高阶应用
该阶段我们正式进入大模型 AI 进阶实战学习,学会构造私有知识库,扩展 AI 的能力。快速开发一个完整的基于 agent 对话机器人。掌握功能最强的大模型开发框架,抓住最新的技术进展,适合 Python 和 JavaScript 程序员。
- 为什么要做 RAG
- 搭建一个简单的 ChatPDF
- 检索的基础概念
- 什么是向量表示(Embeddings)
- 向量数据库与向量检索
- 基于向量检索的 RAG
- 搭建 RAG 系统的扩展知识
- 混合检索与 RAG-Fusion 简介
- 向量模型本地部署
- …
第三阶段(30天):模型训练
恭喜你,如果学到这里,你基本可以找到一份大模型 AI相关的工作,自己也能训练 GPT 了!通过微调,训练自己的垂直大模型,能独立训练开源多模态大模型,掌握更多技术方案。
到此为止,大概2个月的时间。你已经成为了一名“AI小子”。那么你还想往下探索吗?
- 为什么要做 RAG
- 什么是模型
- 什么是模型训练
- 求解器 & 损失函数简介
- 小实验2:手写一个简单的神经网络并训练它
- 什么是训练/预训练/微调/轻量化微调
- Transformer结构简介
- 轻量化微调
- 实验数据集的构建
- …
第四阶段(20天):商业闭环
对全球大模型从性能、吞吐量、成本等方面有一定的认知,可以在云端和本地等多种环境下部署大模型,找到适合自己的项目/创业方向,做一名被 AI 武装的产品经理。
- 硬件选型
- 带你了解全球大模型
- 使用国产大模型服务
- 搭建 OpenAI 代理
- 热身:基于阿里云 PAI 部署 Stable Diffusion
- 在本地计算机运行大模型
- 大模型的私有化部署
- 基于 vLLM 部署大模型
- 案例:如何优雅地在阿里云私有部署开源大模型
- 部署一套开源 LLM 项目
- 内容安全
- 互联网信息服务算法备案
- …
学习是一个过程,只要学习就会有挑战。天道酬勤,你越努力,就会成为越优秀的自己。
如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名大模型 AI 的正确特征了。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

相关文章:
本地部署huggingface模型,建立自己的翻译应用
过去,我们使用翻译接口时,往往都是使用百度等的接口,每天有一定量的免费额度。今天为大家介绍一个可以进行翻译的模型,具备英译中、中译英的能力。并且在这个过程中,向大家介绍一个如何在本地部署模型。在之前的”五天…...

基于python+django+vue的在线学习资源推送系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、SSM项目源码 系统展示 【2025最新】基于协同过滤pythondjangovue…...

.Net Gacutil工具(全局程序集缓存工具)使用教程
GAC介绍: GAC(Global Assembly Cache)全局程序集缓存,是用于存放.Net应用程序共享的程序集。 像平常我们在Visual Studio中引用系统程序集时,这些程序集便来自于GAC。 GAC默认位置为:%windir%\Microsoft…...

安卓13修改设置设备型号和设备名称分析与更改-android13设置设备型号和设备名称更改
总纲 android13 rom 开发总纲说明 文章目录 1.前言2.问题分析3.代码分析4.代码修改5.编译6.彩蛋1.前言 用户要定制一些系统显示的设备型号和设备名称,这就需要我们分析设置里面的相关信息来找到对应的位置进行修改了。 2.问题分析 像这种信息要么是config.xml里面写死了,要…...

AI健身体能测试之基于paddlehub实现引体向上计数个数统计
【引体向上计数】 本项目使用PaddleHub中的骨骼检测模型human_pose_estimation_resnet50_mpii,进行人体运动分析,实现对引体向上的自动计数。 1. 项目介绍 人体运动分析是近几年许多领域研究的热点问题。在学科的交叉研究上,人体运动分析涉…...

Redis常见报错及解决方法总结
Redis常见报错及解决方法总结 Redis作为高效的内存数据库,在实际使用过程中不可避免会遇到一些问题和报错。为了帮助大家更好地应对这些问题,我将常见的Redis报错及其解决方法进行总结,并提供具体的操作步骤。 1. Connection Refused 错误…...

【TabBar嵌套Navigation案例-JSON的简单使用 Objective-C语言】
一、JSON的简单使用 1.我们先来看一下示例程序里边,产品推荐页面, 在我们这个产品推荐页面里面, 它是一个CollectionViewController,注册的是一个xib的一个类型,xib显示这个cell,叫做item,然后,这个邮箱大师啊,包括这个图标,以及这些东西,都是从哪儿来的呢,都是从…...
)
通过鼠标移动来调整两个盒子的宽度(响应式)
DOM结构: <div class"courer"> // 外层盒子<div class"dividing-line" title"拖动"></div> // 拖动的那个线<div class"course-title-box"> // 第一个盒子<div class"course-content-…...

React Zustand状态管理库的使用
Zustand 是一个轻量级的状态管理库,适用于 React 和浏览器环境中的状态管理需求。它由 Vercel 开发并维护,旨在提供一种简单的方式来管理和共享状态。Zustand 的设计理念是尽可能简化状态管理,使其更加直观和易于使用。 Zustand 官网点击跳转…...

pyrosetta MoveMap介绍
在 PyRosetta 中,MoveMap 是一个非常重要的类,用来控制蛋白质分子中哪些部分可以在某些操作(如折叠、旋转、优化等)中被移动。MoveMap 允许你精确地指定哪些残基、键角或原子可以进行特定的运动,从而帮助你在蛋白质结构预测、优化和设计中进行灵活的控制。 MoveMap 的功能…...

在线安全干货|如何更改IP地址?
更改IP地址是一个常见的需求,无论是为了保护个人隐私、绕过地理限制还是进行商业数据分析。不同的IP更改方法适用于不同的需求和环境。但请注意,更改IP地址应在合法场景下进行,无论使用什么方法,都需要在符合当地网络安全法律法规…...

【C++】【网络】【Linux系统编程】单例模式,加锁封装TCP/IP协议套接字
目录 引言 获取套接字 绑定套接字 表明允许监听 单例模式设计 完整代码示例 个人主页:东洛的克莱斯韦克-CSDN博客 引言 有关套接字编程的细节和更多的系统调用课参考《UNIX环境高级编程》一书,可以在如下网站搜索电子版,该书在第16章详…...

Matplotlib在运维开发中的应用
在现代运维开发中,数据可视化扮演着越来越重要的角色。它能帮助我们更直观地理解系统状态,快速发现潜在问题,并辅助决策制定。Python的Matplotlib库作为一个强大而灵活的绘图工具,在运维领域有着广泛的应用。本文将探讨Matplotlib在运维开发中的常见应用场景,并提供实用的代码示…...

centos下nvme over rdma 环境配置
nvme over rdma 环境配置 本文主要介绍NVMe over RDMA的安装和配置。关于什么是NVMe over Fabrics,什么是NVMe over RDMA,本文就不做介绍了,网上资料一大堆。 可以看看什么是NVMe over Fabrics? RDMA(全称:Remote Dir…...

【C++】——多态详解
目录 1、什么是多态? 2、多态的定义及实现 2.1多态的构成条件 2.2多态语法细节处理 2.3协变 2.4析构函数的重写 2.5C11 override 和 final关键字 2.6重载—重写—隐藏的对比分析 3、纯虚函数和抽象类 4、多态的原理分析 4.1多态是如何实现的 4.2虚函数…...

STM32上实现FFT算法精准测量正弦波信号的幅值、频率和相位差(标准库)
在研究声音、电力或任何形式的波形时,我们常常需要穿过表面看本质。FFT(快速傅里叶变换)就是这样一种强大的工具,它能够揭示隐藏在复杂信号背后的频率成分。本文将带你走进FFT的世界,了解它是如何将时域信号转化为频域…...

计算机毕业设计 农场投入品运营管理系统 Java+SpringBoot+Vue 前后端分离 文档报告 代码讲解 安装调试
🍊作者:计算机编程-吉哥 🍊简介:专业从事JavaWeb程序开发,微信小程序开发,定制化项目、 源码、代码讲解、文档撰写、ppt制作。做自己喜欢的事,生活就是快乐的。 🍊心愿:点…...
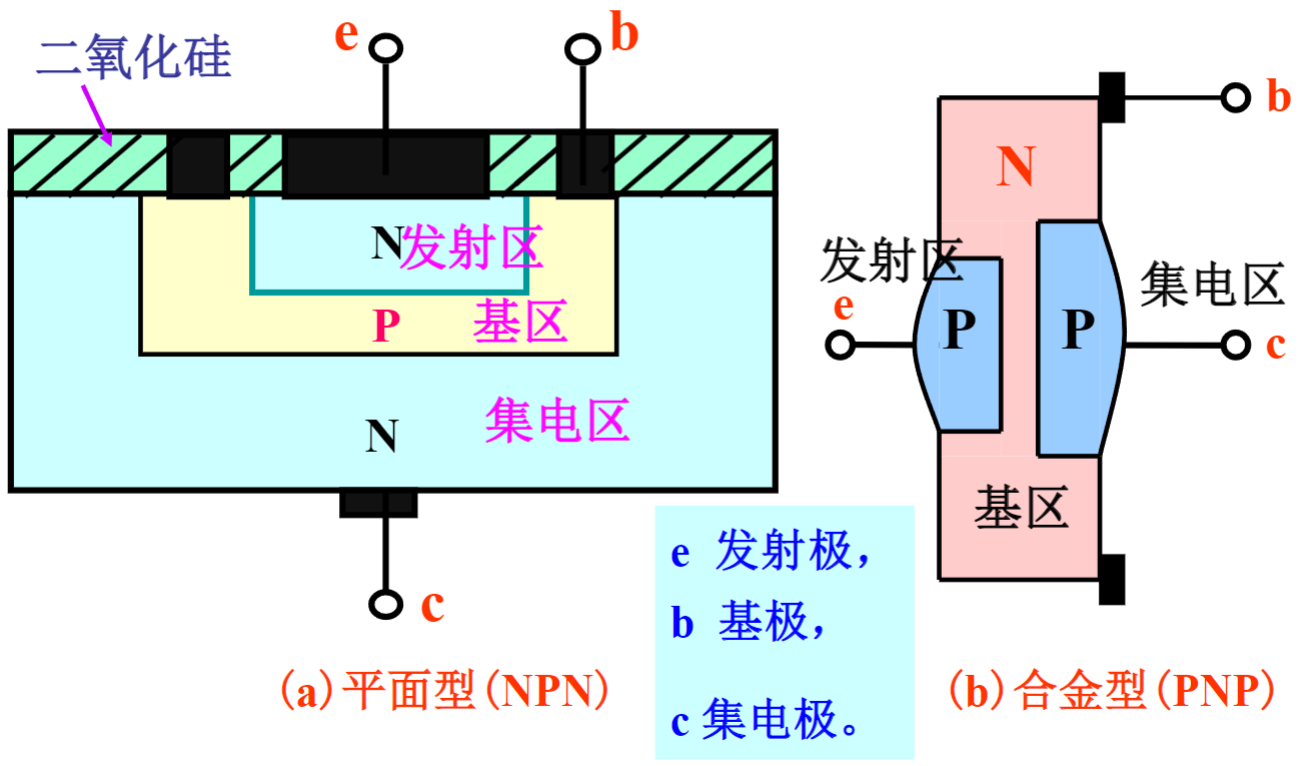
【笔记】2.1 半导体三极管(BJT,Bipolar Junction Transistor)
一、结构和符号 1. 三极管结构 常用的三极管的结构有硅平面管和锗合金管两种类型。各有PNP型和NPN型两种结构。 左图是NPN型硅平面三极管,右图是PNP型锗合金三极管。 从图中可见平面型三极管是先在一块大的金属板上注入杂质使之变成N型,然后再在中间注入杂质使之变成P型,…...

企业中文档团队的三种组织形式
大家好!今天咱们来聊聊企业里文档团队都是怎么组织的。 企业中,常见的文档团队组织形式有三种。 首先,最常见的就是集中式的文档团队。就是说,公司里头有几个不同的部门,每个部门都需要做文档。于是呢,公…...

古诗词四首鉴赏
1、出自蓟北门行 唐李白 虏阵横北荒,胡星曜精芒。 羽书速惊电,烽火昼连光。 虎竹救边急,戎车森已行。 明主不安席,按剑心飞扬。 推毂出猛将,连旗登战场。 兵威冲绝漠,杀气凌穹苍。…...

Claude in Excel:原生集成的AI表格协作者
1. 项目概述:这不是插件,是Excel里长出来的AI同事“Claude in Excel”这个标题刚看到时,我下意识点开几个技术社区翻了一圈,发现多数人第一反应是:“又一个AI插件?”——其实完全不是。它根本没走传统Offic…...
)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南(附软件包)
从USB转TTL接线到手机热点配网:ESP8266无线通信保姆级避坑指南 当你第一次拿起ESP8266模块时,可能会被这个小巧的Wi-Fi模块惊艳到——它只有指甲盖大小,却蕴含着强大的无线通信能力。但很快,这种惊艳就会变成困惑:为什…...

Unity安卓打包实战指南:从环境配置到APK生成全链路排错
1. 这不是“入门教程”,而是一份写给真实开发现场的生存指南你打开Unity,新建一个3D项目,拖进一个Cube,点击Play——它动了。你松了口气,觉得“Unity好像也没那么难”。但当你把APK打包发给测试同事,对方回…...
叶绿素(CHL)数据,版本 2022.0)
Sentinel-3B OLCI 3 级全球分箱地球观测降分辨率(ERR)叶绿素(CHL)数据,版本 2022.0
Sentinel-3B OLCI Level-3 Global Binned Earth-observation Reduced Resolution (ERR) Chlorophyll (CHL) Data, version 2022.0 简介 叶绿素 a 数据集提供全球网格化的表层叶绿素 a 浓度(浮游植物生物量的替代指标)合成数据。CHL 支持时间序列和气候…...

Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度
Hitboxer:开源SOCD清理工具,3分钟提升游戏操作精准度 【免费下载链接】socd Key remapper for epic gamers 项目地址: https://gitcode.com/gh_mirrors/so/socd 你是否在激烈的游戏对抗中经历过这样的挫败:同时按下左右方向键时角色卡…...

本地柴油发电机组排行2023年最新榜单
柴油发电机是通过燃烧柴油驱动发动机,进而发电的设备,广泛应用于电力中断或无电网地区。1. 柴油发电机的核心工作原理是什么?柴油发电机是一种将化学能转化为电能的设备,其核心是柴油发动机与交流发电机的组合。当柴油在发动机内燃…...

METSO A413248自动化系统
METSO A413248 自动化系统模块产品特点: 品牌归属:芬兰METSO(美卓)工业自动化系统原装备件。 产品类型:工业级自动化控制模块/接口模块。 核心功能:用于控制信号处理、数据采集及系统集成。 系统兼容&am…...

FT231XQ USB串口桥接板设计解析与实战应用指南
1. 项目概述:从FT232R到FT231XQ的USB串口桥接板演进在嵌入式开发和硬件调试的日常工作中,一个可靠、小巧且功能清晰的USB转串口(UART)桥接板(Breakout Board, 简称BoB)几乎是工程师手边的标配工…...

GEO生成引擎优化:当AI成为信息分发的主角,品牌如何抢占对话窗口?
当用户不再"搜索-浏览",而是直接"AI提问-获取答案",传统SEO的逻辑正在被彻底改写。2026年,GEO(Generative Engine Optimization,生成式引擎优化)已经从概念走向规模化落地。本文从技术…...

Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取
Airtest Poco实战:5分钟搞定微信小程序自动化测试环境搭建与元素抓取微信小程序作为轻量级应用的代表,已经渗透到电商、社交、工具等各个领域。随着小程序功能的日益复杂,自动化测试成为保障产品质量的重要手段。本文将带你快速搭建微信小程序…...