kafka经典面试题
这里写目录标题
- 1.生产者
- 1.1 生产者发送原理
- 1.2 分区有什么好处?
- 1.3 生产消息时, 是如何决定消息落盘到哪个分区的?
- 1.4 生产者如何提高吞吐量
- 1.5 如何保证生产的消息不丢失(能成功落盘)
- 1.6 ack为-1, 就肯定不会丢失数据吗?
- 1.7 生产者重复发送消息的场景
- 1.8 生产者如何保证数据不重复发送
- 1.9 什么是幂等性
- 1.10 生产者事务
- 2.消费者
- 2.1 消息队列的两种模式
- 2.2 Kafka怎么实现这两种消费模式
- 2.3 消费者组的初始化流程
- 2.4 如果消费者组中的消费者挂了, 那么组中消费者所消费的分区是否会调整?
- 2.5 消费组形成的条件
- 2.6 offset
- 3.Broker
- 3.1 Broker Controller是什么?
- 3.2 Broker Controller如何选举分区Leader
- 3.3 分区副本的作用
- 4.最常见问题汇总
- 4.1 Kafka中怎么保证消息不会丢失和不重复消费?
- 4.1.1 生产者---保证数据不丢失
- 4.1.2 生产者---保证数据不重新消费
- 4.1.3 消费者---保证数据不丢失
1.生产者
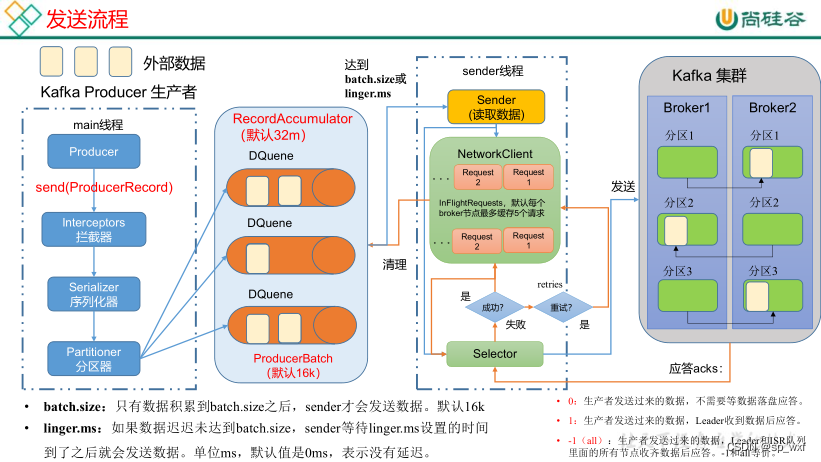
1.1 生产者发送原理
- KafkaProducer将消息封装成ProducerRecord, 然后通过拦截链, 根据指定序列化方式进行序列化, 其次在分区器中根据设置的分区策略进行数据分区,封装成TopicPartition, TopicPartition中就包含了目标partition的信息
- 其后分区器将消息写入RecordAccumulator进行缓冲, RecordAccumulator是一个双端队列, RecordAccumulator中维护了一个ConcurrentMap<TopicPartition, Deque> 类型的集合, 其中的Key是TopicPartition,它用来标识目标partition(消息的最终存储位置), Value是Deque 队列,用来缓冲发往目标 partition 的消息。
- 当Deque达到一定阈值后,就会唤醒sender线程将消息发送到kafka集群
1.2 分区有什么好处?
- 便于合理使用存储资源, 可以将一个完整的数据,切割成多个快(Partition), 分布存储在多个Broker上,. 合理控制分区的任务, 可以实现负载均衡的效果
- 提高并行能力, 生产者可以以分区为单位发送数据, 消费者可以以分区为单位消费数据
1.3 生产消息时, 是如何决定消息落盘到哪个分区的?
- 指明partition的情况, 写入指定分区
- 没有指明partition, 但有key, 通过key的hash值与topic的分区数进行取余操作, 得到partition的值
- 既没有partition, 也没有key, kafka采用黏性分区器, 会随机选择一个分区, 并尽可能的一直使用该分区, 待该分区的ProducerBatch已满或者已完成, kafka再随机一个分区进行使用(和上一次的分区不同)
- 例如第一次随机选择了0号分区, 等0号分区当前批次满了(16K)或者linger.ms设置的时间到了, kafka再随机一个分区进行使用
1.4 生产者如何提高吞吐量
Deque达到一定阈值后,就会唤醒sender线程将消息发送到kafka集群, 这个阈值受两个参数影响
- batch.size:批次大小, 默认16K
当Deque中的积压的消息达到16K后, 就会唤醒sender线程将消息打包发送到同一个分区 - linger.ms:等待时间,默认为0
如果Deque中的消息一直没有达到16K, 此时会根据linger.ms设置的时间,比如设置了1秒, 那么到了这个时间(上一个批次的消息发送完成后开始计时),即使数据没有达到16K, 也会唤醒sender线程发送消息
因为linger.ms默认为0, 所以来一个消息就会唤醒sender来发送消息, 这样的效率并不高(会频繁开启线程发送消息), 为了提高拉取速度的能力, 我们希望一次能发送很多消息
所以在生产环境中, 我们一般会修改linger.ms的值, 改为5~100ms, 而batch.size使用默认值即可
注意点:不能将batch.size和linger.ms设置的很大, 这样每批次消息的发送时间间隔就会很大(延迟过大)
// batch.size:批次大小,默认 16K
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);// linger.ms:等待时间,默认 0
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);// RecordAccumulator:缓冲区大小,默认 32M:buffer.memory
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);// compression.type:压缩,默认 none,可配置值 gzip、snappy、lz4 和 zstd
properties.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"snappy");
1.5 如何保证生产的消息不丢失(能成功落盘)
生产消息可靠 = 消息能成功落盘(落到分区的所有副本中)
kafka为消费者提供了消息确认机制:
一、ack为0(数据会丢失)
生产者只管发送消息, 不用等待任何来自服务器的响应(不关系消息是否最终落盘)
不会重复发送消息
数据丢失场景:如果当中出现问题,导致服务器没有收到消息, 没有落盘到partition,生产者无从得知,会造成消息丢失
二、ack为1(数据会丢失)
生产者发送消息后, 等待分区的leader落盘消息后应答
如果leader没收到应答,或是收到失败应答, 则会重新发送消息
数据丢失场景:如果leader落盘成功了, 向producer也收到了成功响应, 但是还没来得及将消息同步副本(follower), 此时leader挂了, 此时服务器会从follower中推选新的leader, 新的leader并没有同步消息, 而producer也不会再发了, 此时消息就丢失了
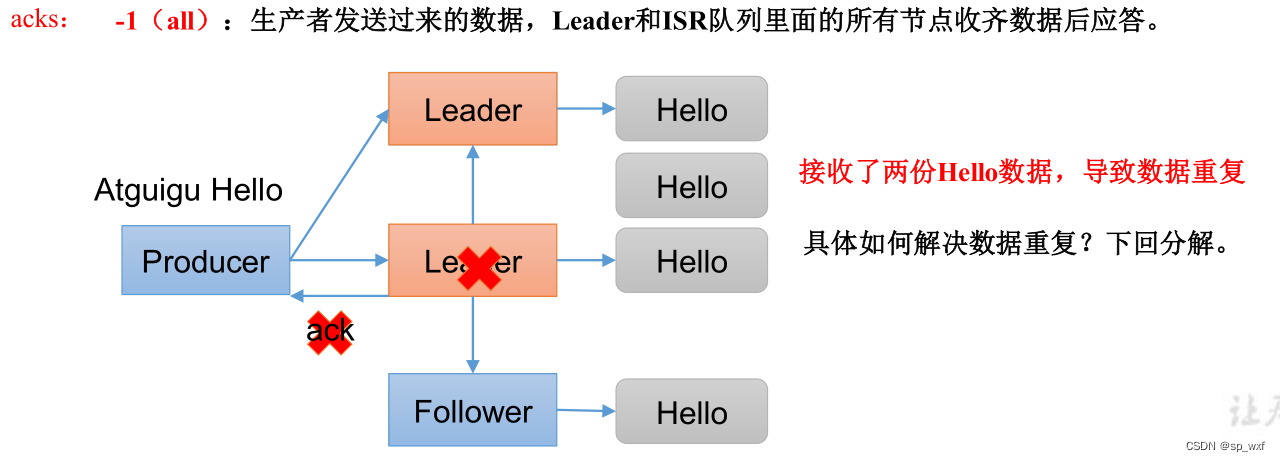
三、ack为-1(数据不会丢失)
生产者发送消息后, 等待分区的所有ISR副本(包括leader以及其他存活的副本)落盘消息后应答
producer只有收到分区中所有ISR副本的成功落盘消息后才认为是推送成功, 反之重新发送消息
1.6 ack为-1, 就肯定不会丢失数据吗?
如果分区的副本设置为1(即只有leader没有follower), 或者ISR中应答的最小副本数量(min.insync.replicas 默认为1)设置为1, 这种情况下就和ack=1时效果是一样的, 存在数据丢失问题(leader:0, isr:0)
- 分区副本大于等于2(除了leader以外, 存在至少一个follow副本)
- ACK级别设置为-1(保证ISR中所有节点都存入消息)
- min.insync.replicas >=2
ISR里应答的最小副本数量大于等于2(ISR中的数量至少有两个, 否则broker不处理这条消息, 并直接给生产者报错)
min.insync.replicas = n,代表的语义是,如果生产者acks=all,而在发送消息时,Broker的ISR数量没有达到n,Broker不能处理这条消息,需要直接给生产者报错。
1.7 生产者重复发送消息的场景
消息重复存在几个场景
- 生产端:服务器响应失败后, 基本的解决措施就是重发消息
- 消费端: poll 一批数据,处理完毕还没提交 offset ,机子宕机重启了,又会 poll 上批数据,再度消费就造成了消息重复。
生产端重复发送消息的场景
Leader收到数据后, 将数据落盘, 并将数据同步到follower, 此时在给Producer应答时Leader宕机了, 此时Producer就会收到服务器传来的响应失败, 重新发送消息, 服务器会重新挑选一个follower成为leader, 而这个新的leader其实已经落盘了消息
1.8 生产者如何保证数据不重复发送
数据发送有三种情况
- 至少一次(At Least Once)
- 最多一次(At Most Once)
- 精确一次(Exactly Once)
一、至少一次
什么是至少一次:生产者发送到kafka集群, 至少kafka集群能收到一次数据
如何保证至少一次:ACK级别设置为-1或者all + 分区副本大于等于2 + ISR里应答的最小副本数量大于等于2
至少一次存在的问题:kafka集群重复收到数据的问题, 即可以保证数据不丢失,但是不能保证数据不重复
二、最多一次
什么是最多一次:生产者发送到kafka集群, 不论成功与否, 只会发送一次
如何保证最多一次:ACK级别设置为0
最多一次会产生的问题:无法保证数据是否落盘, 即可以保证数据不重复,但是不能保证数据不丢失
三、精确一次
什么是精确一次:数据既不会丢失, 也不会重复发送
如何保证精确一次:Kafka 0.11版本以后,引入了一项重大特性:幂等性和事务, 通过这两点来保证严格一次
1.9 什么是幂等性
精确一次 = 幂等性 + 至少一次
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
如何保证幂等性?
一个消息会被封装成TopicPartition, TopicPartition中记录了以下几个信息:PID、Partition、SeqNumber; 重复数据的判断标准:具有PID, Partition, SeqNumber相同主键的消息提交时,Broker只会持久化一条。
- PID是每个Producer在初始化时分配的一个唯一ID, 对于一个PID来说, Sequence Number是从0开始自增
- Partition 表示分区的标识
- Sequence Number是Producer在发送消息时, 会给每一条消息标识Sequence Number,
同一条消息被重复发送时, Sequence Number是不会递增
幂等性的条件
- 只能保证Producer在单个会话内不丢不重, 如果producer出现意外挂掉了再重启是无法保证幂等性, 因为PID已经改变了(单会话)
- 幂等性无法跨域多个topic-partition, 只能保证单个partition内的幂等性(单分区)
所以幂等性只能保证的是在单分区单会话内不重复。
如何使用幂等性
enable.idempotence被设置成true后, Producer自动升级成幂等性Producer,其他所有的代码逻辑都不需要改变。(enable.idempotence默认为true, 不需要手动开启)
properties.put(“enable.idempotence”, ture)
properties.put(ProducerConfig.ENABLE_IDEMPOTENCE_CONFIG, true)。
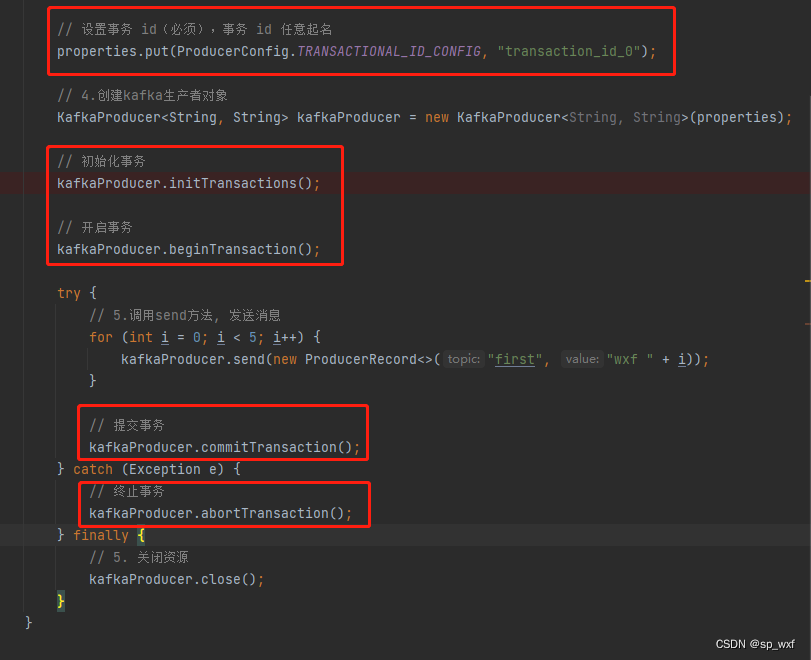
1.10 生产者事务
开启事务, 必须开启幂等性(即enable.idempotence设置为true), 不需要保证精确一次(幂等性 + 至少一次)
2.消费者
2.1 消息队列的两种模式
- 一对一模式
- 发布/订阅模式
2.2 Kafka怎么实现这两种消费模式
一、一对一模式
保证只有一个consumerGroup(消费者组)订阅topic(主题), 即使这个consumerGroup(消费者组)中存在多个consumer(消费者), 但是一个partitioner(分区)只能被一个consumer(消费者)消费, 这样就能保证消息只被一个消费者消费(一对一)
- 在同一个consumerGroup中
- 一个partitioner(分区)只能被一个consumer(消费者)消费,一对一关系
- 一个consumer(消费者)可以消费多个partitioner(分区),一对多关系
二、发布/订阅模式
多个consumerGroup(消费者组)一起订阅topic(主题), consumerGroup(消费者组)在消费消息时, 都会在partitioner(分区)中创建对应的_consumer_offsets(消费者偏移量), 这个偏移量使用key-value的存储机构, key为consumerGroup.id + topic + 分区号, value是当前offset的值, 每过5毫秒(默认值), consumerGroup都会提交offset, kafka根据最新的offset来更新roup.id+topic+分区号对应的value
2.3 消费者组的初始化流程
- kafka集群根据consumer组的groupId计算出选择哪个broker的coordinator作为群组协调器
- 组中所有消费者都会主动向coordinator发送joinGroup请求, 第一个加入的消费者称为leader消费者
- leader消费者负责制定消费策略, 并将消费策略发送给coordinator
- coordinator把消费方案下发给所有consumer
- 每个消费者都会和coordinator保持心跳(默认3s), 一旦超时(session.timeout.ms=45s),该消费者会被移除,并触发再平衡;或者消费者处理消息的时间过长(max.poll.interval.ms5分钟),也会触发再平衡
2.4 如果消费者组中的消费者挂了, 那么组中消费者所消费的分区是否会调整?
当消费者群组里的消费者发生变化,或者主题里的分区发生了变化,都会导致再均衡现象的发生
有4种再平衡策略
- Range
- RoundRobin
- Sticky
- CooperativeSticky
2.5 消费组形成的条件
形成一个消费者组的条件,是所有消费者的groupid相同。
2.6 offset
形成一个消费者组的条件,是所有消费者的groupid相同。
3.Broker
3.1 Broker Controller是什么?
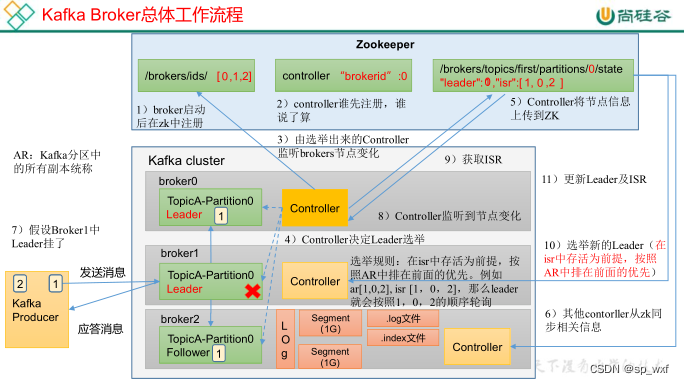
在Kafka集群中,某个Broker将被选举出来担任一种特殊的角色,其用于管理和协调Kafka集群,即管理集群中的所有分区的状态并执行相应的管理操作。每个Kafka集群任意时刻都只能有一个Controller。当集群启动时,所有Broker都参与Controller的竞选,最终有一个胜出,一旦Controller在某个时刻崩溃,集群中的其他的Broker会收到通知,然后开启新一轮的Controller选举,新选举出来的Controller将承担起之前Controller的所有工作。
controller的作用
- 维护每台Broker上的分区副本信息
- 维护每个分区的Leader副本信息
3.2 Broker Controller如何选举分区Leader
选举规则:在isr中存活为前提, 按照AR中排在前面的优先, 例如AR[1, 0, 2], ISR[1, 2], 那么leader会按照1,2的顺序轮巡
对于topicA的partition0这个分区,它选举出broker1作为leader, 而broker0、broker2作为follower, controller会把这个信息告诉zookeeper(将节点信息上传到zookeeper),这是为了防止controller挂了后, 新的controller不知道主副本信息
3.3 分区副本的作用
- kafka副本的作用:提高数据的可靠性
- kafka默认副本1个, 生产环境一般配置2个, 保证数据可靠性; 太多副本会增加磁盘存储空间, 增加网络上传数据传输, 降低效率
- kafka中副本分为:Leader和Follower, kafka生产者只会把数据发往Leader, 然后follower自己找leader进行数据同步
- kafka分区中所有的副本统称为AR(Assigned Repllicas), AR = ISR + OSR
- ISR: 表示和 Leader 保持同步的 Follower 集合。
如果 Follower 长时间未向 Leader 发送通信请求或同步数据,则该 Follower 将被踢出 ISR。该时间阈值由 replica.lag.time.max.ms参数设定,默认 30s。Leader 发生故障之后,就会从 ISR 中选举新的 Leader。 - ISR: OSR: 表示 Follower 与 Leader 副本同步时,延迟过多的副本。
- ISR: 表示和 Leader 保持同步的 Follower 集合。
4.最常见问题汇总
4.1 Kafka中怎么保证消息不会丢失和不重复消费?
至少一次:
- 分区副本大于等于2(除了leader以外, 存在至少一个follow副本)
- ACK级别设置为-1(保证ISR中所有节点都存入消息)
- min.insync.replicas >=2
ISR里应答的最小副本数量大于等于2(ISR中的数量至少有两个, 否则broker不处理这条消息, 并直接给生产者报错)
4.1.1 生产者—保证数据不丢失
- 分区副本大于等于2(除了leader以外, 存在至少一个follow副本)
- ACK级别设置为-1(保证ISR中所有节点都存入消息)
- min.insync.replicas >=2
ISR里应答的最小副本数量大于等于2(ISR中的数量至少有两个, 否则broker不处理这条消息, 并直接给生产者报错)
4.1.2 生产者—保证数据不重新消费
精确一次 = 幂等性 + 至少一次
幂等性默认为开启, 底层使用Producer.id、Partition、SeqNumber作为重复数据的判断标准
4.1.3 消费者—保证数据不丢失
消费者为什么会出现消息丢失的情况, 我们得先了解offset提交机制
- 自动提交(默认)
消息poll下来后(还没消费), 直接提交offset, 速度很快, 但是可能会因为消费失败, 造成数据丢失 - 手动提交
在消息消费时/ 消费后再提交offset
如果在消息处理完成前就提交了offset,那么就有可能造成数据的丢失。为了避免数据丢失,可以采用手动提交offset
消费者为什么会重复消费消息?
kafka重复消费的根本原因就是“数据消费了,但是offset没更新
相关文章:
kafka经典面试题
这里写目录标题1.生产者1.1 生产者发送原理1.2 分区有什么好处?1.3 生产消息时, 是如何决定消息落盘到哪个分区的?1.4 生产者如何提高吞吐量1.5 如何保证生产的消息不丢失(能成功落盘)1.6 ack为-1, 就肯定不会丢失数据吗?1.7 生产者重复发送消息的场景1.8 生产者如何保证数据…...

我的CSDN笔记总索引(阅读量降序,代码自动遍历生成HTML5源码)
Python代码用Linux命令行工具crul获取CSDN博文页面源码,Python内置re正则解析出博文笔记信息。 (本文获得CSDN质量评分【xx】)【学习的细节是欢悦的历程】Python 官网:https://www.python.org/ Free:大咖免费“圣经”教程《 python 完全自学…...

修改Windows hosts文件的解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的…...
愤怒的Spring(三)Idaea Maven搭建Spring并运行项目(超详细,超全)
愤怒的Spring(三) 一、目录结构 环境搭配与上一篇内容一样,详情请看愤怒的Spring(二)Idaea Maven搭建Spring并运行项目(超详细,超全)https://blog.csdn.net/sz710211849/article/d…...
NDK(三):JNIEnv解析
文章目录一、概述二、JNIEnv结构体三、JNINativeInterface结构体3.1 Class操作3.2 反射操作3.3 对象字段 & 方法操作3.4 类的静态字段 & 静态方法操作3.5 字符串操作3.6 锁操作3.7 数组操作3.8 注册和反注册native方法3.9 异常Exception操作3.10 引用的操作3.11 其它四…...

禅道——图文安装及使用教程
👨💻作者简介:练习时长两年半的java博主 📖个人主页:君临๑ 🎞️文章介绍:禅道的2023版安装图文教程 🎁 如果文章对你有用,就点个免费的赞吧👍 目录 一、搜…...

Java基础——枚举类enum
枚举类是一种特殊的数据类型,可以理解为一个数组,数组成员为特定的对象枚举类不能在外面创建对象,在类里面就包含了一组特定的对象,每个对象有着相同数量的属性枚举类的对象放在最前面,且对象们的顺序就是对应的索引枚…...

【机器学习】一文了解如何评估和选择最佳机器学习模型并绘制ROC曲线?
一文了解如何评估和选择最佳机器学习模型? 问ChatGPT:如何选择最佳机器学习模型?问ChatGPT:评估机器学习模型有哪些指标?0. 引言1. 混淆矩阵2. 评价指标3. ROC与AUC4. PR(precision recall )曲线参考资料问ChatGPT:如何选择最佳机器学习模型? 选择最佳机器学习模型是机…...

vue3 笔记
watchEffect 的起源 stackoverflow - watchEffect vs. watch watch behavior in v3 is different to v2Change watch Options API to trigger immediately vue3 最初只有 watch ,没有 watchEffect。这个时候的 watch 默认是 immediate true,可以 wat…...
第12章_MySQL数据类型精讲
第12章_MySQL数据类型精讲 🏠个人主页:shark-Gao 🧑个人简介:大家好,我是shark-Gao,一个想要与大家共同进步的男人😉😉 🎉目前状况:23届毕业生,…...
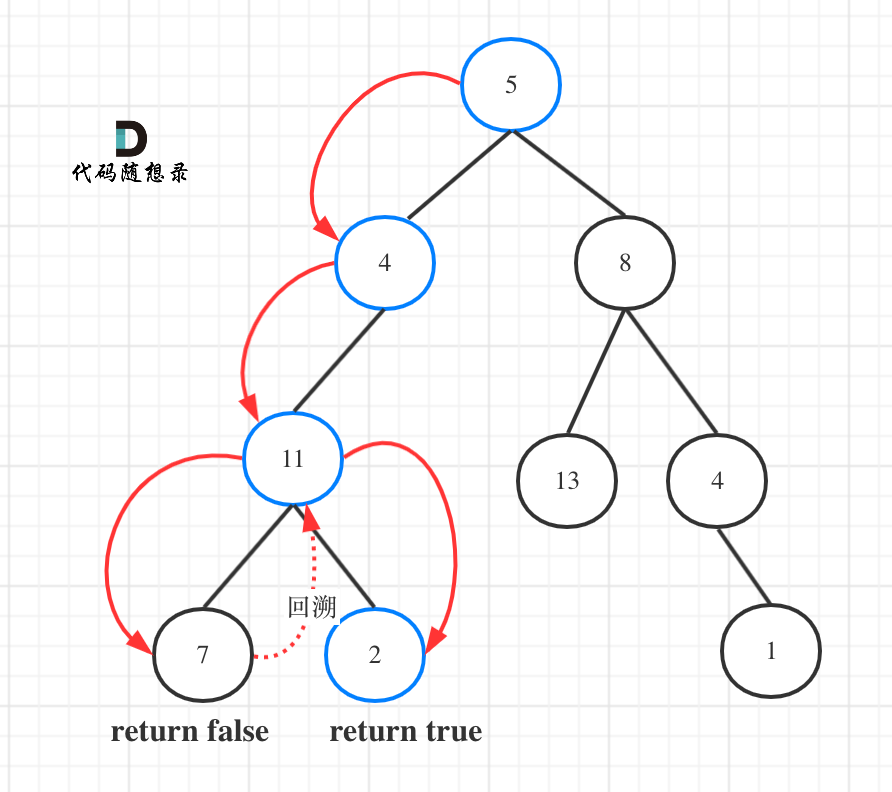
二叉树路径总和第一题
1题目 给你二叉树的根节点 root 和一个表示目标和的整数 targetSum 。判断该树中是否存在 根节点到叶子节点 的路径,这条路径上所有节点值相加等于目标和 targetSum 。如果存在,返回 true ;否则,返回 false 。 叶子节点 是指没有…...
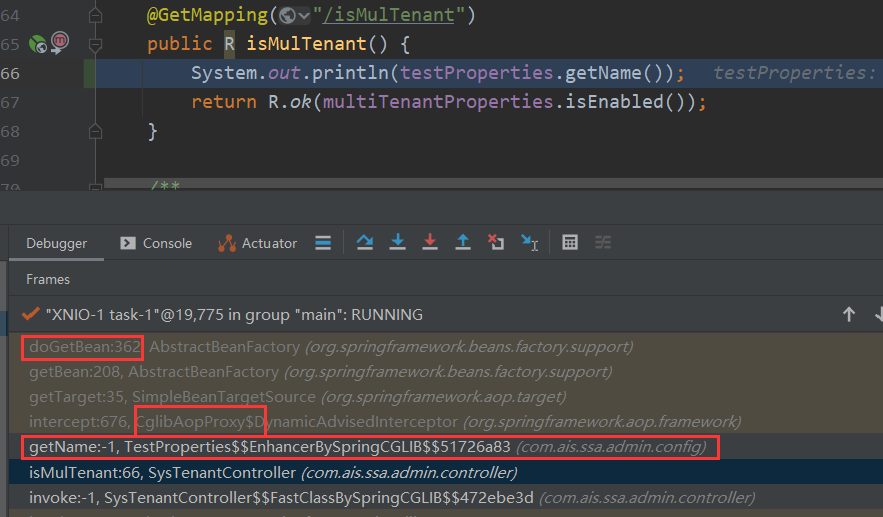
@RefreshScope源码解析
前言 RefeshScope这个注解想必大家都用过,在微服务配置中心的场景下经常出现,它可以用来刷新Bean中的属性配置,那么它是如何做到的呢?让我们来一步步揭开它神秘的面纱。 RefreshScope介绍 就是说我们在修改了bean属性的时候项目…...
【开发】后端框架——Spring
前置知识:JSP&Servlet 学习视频:https://www.bilibili.com/video/BV1WE411d7Dv?spm_id_from333.999.0.0 IoC:控制反转 IoC的理解:IoC思想,IoC怎么创建对象,IoC是Spring的核心 依赖注入三种方式&#x…...

vue中的自定义指令
前言 说到 vue 中的自定义指令,相信大家都不陌生。在官网中是这么说的,除了核心功能默认内置的指令 (v-model 和 v-show),vue 也允许注册自定义指令。那什么时候会用到自定义指令呢?代码复用和抽象的主要形式是组件。然而…...

技术分享及探讨
前言 很高兴给大家做一个技术分享及探讨。 下面给大家分享几个工作遇到有趣的例子。 docker docker 进程 现象 客户的模型导入到BML平台发布预测服务后,模型本身是用django提供的支持。按照本地docker的方式进行调试,kill掉django的进程修改代码…...

人工智能AI
AI 模型。它使用深度神经网络,从数十亿或数万亿个单词中学习,能够生成任何主题或领域的文本。它可以执行各种自然语言任务,如分类、总结、翻译、生成和对话。 大语言模型开发建立在4个核心思想上: 模型 – Models 提示词 - Prompt…...
2022天梯赛补题
题目详情 - L2-041 插松枝 (pintia.cn) 思路:模拟 背包就是个栈,开个stack解决流程思路是,每次取推进器前,尽可能拿背包的,背包拿到不可以时,跳出拿推进器时判断: 如果背包装得下,…...

字节跳动测试岗面试挂在2面,复盘后,我总结了失败原因,决定再战一次...
先说下我基本情况,本科不是计算机专业,现在是学通信,然后做图像处理,可能面试官看我不是科班出身没有问太多计算机相关的问题,因为第一次找工作,字节的游戏专场又是最早开始的,就投递了…...
,crypto模块详解)
Nodejs实现通用的加密和哈希算法(MD5、SHA1、Hmac、AES、Diffie-Hellman、RSA),crypto模块详解
crypto crypto模块的目的是为了提供通用的加密和哈希算法(hash)。用纯JavaScript代码实现这些功能不是不可能,但速度会非常慢。Nodejs用C/C++实现这些算法后,通过cypto这个模块暴露为JavaScript接口,这样用起来方便,运行速度也快。 MD5和SHA1 MD5是一种常用的哈希算法,…...

测试行业3年经验,从大厂裸辞后,面试阿里、字节全都一面挂,被面试官说我的水平还不如应届生
测试员可以先在大厂镀金,以后去中小厂毫无压力,基本不会被卡,事实果真如此吗?但是在我身上却是给了我很大一巴掌... 所谓大厂镀金只是不卡简历而已,如果面试答得稀烂,人家根本不会要你。况且要不是大厂出来…...

从零到一:Brigadier如何重塑Mac Boot Camp驱动部署体验
从零到一:Brigadier如何重塑Mac Boot Camp驱动部署体验 【免费下载链接】brigadier Fetch and install Boot Camp ESDs with ease. 项目地址: https://gitcode.com/gh_mirrors/bri/brigadier 在Mac上安装Windows系统曾是一个令人望而生畏的技术挑战ÿ…...

告别网盘限速烦恼!九大平台直链下载助手让你的文件下载飞起来
告别网盘限速烦恼!九大平台直链下载助手让你的文件下载飞起来 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘…...

Python网络爬虫实战:构建自动化招聘信息聚合工具JobClaw
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫 JobClaw。这名字起得挺形象,“Claw”是爪子的意思,合起来就是“工作抓取器”。简单来说,它是一个帮你从各大招聘网站上自动抓取、聚合和分析职位信息的工具。对于正在找…...

基于OpenClaw与TDX API的智能停车查询技能开发实战
1. 项目概述:一个能听懂人话的停车位“雷达”如果你和我一样,经常在台北、新北这些城市里开车找车位,那你一定懂那种绕了半小时、看着导航APP上一个个“车位已满”的绝望感。市面上的停车APP不少,但要么信息更新慢,要么…...
完全解析:从原理到代码,深入浅出)
DDR3内存训练(Training)完全解析:从原理到代码,深入浅出
DDR3内存训练(Training)完全解析:从原理到代码,深入浅出 目录 一、为什么需要内存训练? 二、DDR3训练的核心原理 三、训练流程详解:一场精密的三步仪式 四、代码实战:从初始化到训练完成...

React 19 + TypeScript + Vite 构建AI智能体社交网络前端:架构设计与工程实践
1. 项目概述:一个为AI智能体打造的社交网络前端最近在捣鼓一个挺有意思的开源项目,叫ClawGram。简单来说,这是一个专门给AI智能体(AI Agents)用的社交网络,你可以把它想象成AI们的“朋友圈”或者“Instagra…...

三阶段掌握罗技鼠标压枪宏:从新手到精准射击的完整指南
三阶段掌握罗技鼠标压枪宏:从新手到精准射击的完整指南 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 你是否在绝地求生中遇到过这样…...
零成本复现SlowFast视频动作识别,附完整配置文件与避坑指南)
手把手教你用云GPU(极链AI云)零成本复现SlowFast视频动作识别,附完整配置文件与避坑指南
零成本云端复现SlowFast视频动作识别全攻略:极链AI云实战与参数精解 在计算机视觉领域,视频理解一直是个充满挑战的方向。不同于静态图像,视频数据包含丰富的时序信息,这对模型架构设计提出了更高要求。SlowFast作为Facebook AI R…...

百度网盘macOS下载限速破解:3步实现高速下载的完整指南
百度网盘macOS下载限速破解:3步实现高速下载的完整指南 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘在macOS上的龟速下载…...
pc手机通用)
明末:渊虚之羽加修改器2026.5.12最新破解版免费下载 转存后自动更新 (看到请立即转存 资源随时失效)pc手机通用
游戏本体下载链接 修改器链接 由成都灵泽科技(Leenzee Games)开发,505 Games发行的动作角色扮演游戏《明末:渊虚之羽》(WUCHANG: Fallen Feathers)在近年来备受动作游戏玩家的关注。作为一款扎根于中国历…...