如何基于Flink CDC与OceanBase构建实时数仓,实现简化链路,高效排查
本文作者:阿里云Flink SQL负责人,伍翀,Apache Flink PMC Member & Committer
众多数据领域的专业人士都很熟悉Apache Flink,它作为流式计算引擎,流批一体,其核心在于其强大的分布式流数据处理能力,同时巧妙地融合了流计算与批计算的能力,因此成为了众多企业在进行流式计算业务时的首选。
接下来,本文将探讨Flink CDC与Apache Flink之间的关联与差异。更重要的是,我们将如何巧妙地将Flink CDC与OceanBase数据库相结合,构建一个实时数据仓库系统。
Flink CDC和Apache Flink是什么关系?
从功能上来讲,Flink在批处理能力外,还能够实时读取数据源,进行数据加工,数据打宽和数据聚合,以及下游的存储、分析、服务。Flink CDC是基于Flink流式计算引擎构建的一个实时数据同步和处理的框架。目前,得益于日志变更技术(Change Data Capture),Flink CDC已经支持了十来种常见的数据库,比如MySQL、MongoDB、OceanBase等,在将数据实时同步至数据仓库或数据湖时,还能够实时进行数据加工、数据聚合、数据打宽等。
两个场景说明Flink CDC的由来
为什么会出现Flink CDC?下面以两个场景举例说明。
场景一:数据入仓。
传统的数据入仓方式,我们要通过数据同步工具将数据同步到数仓中分析,比如,使用DataX对业务数据库进行以天为单位的定时全量数据同步,但这种方式有几个比较明显的缺点。
首先,全量数据同步可能会对在线业务造成一定影响;其次,天级别的产出,可能无法满足下游业务的实时性需求。另外,随着数据量的不断增长,数据同步工具的性能瓶颈会越来越明显,比如同步的延时,以及对业务的影响。
很多应用方会在数据同步的基础上增设增量数据的同步,也就是我们常说的Lambda架构,常见的技术方案是采用Canal同步数据库增量数据到Kafka,再通过其他的处理框架将数据实时同步到新的数据库如OceanBase。这种架构虽然减少了对在线业务的影响,但引入了更多的组件,使同步链路变得更长。同时,手动管理全量和增量数据链路的切换也可能导致数据出现问题。
Flink CDC的出现很好地解决了上述问题,它能够一体化地支持全量数据和增量数据的读取,并且是在用户无感知的情况下自动发生的。在不影响业务稳定性的前提下,保证了实时流式传输与毫秒级数据更新。对于全量数据和增量数据的切换,Flink CDC能够保证数据的一致性,用户不用再担心数据丢失的问题。另外,从同步链路而言,需要维护的组件更少,降低了用户的维护成本与故障排查成本。
场景二:ETL数据分析
传统的数据分析链路是把业务数据,通过中间件同步到Canal,再使用Kafka对数据进行加工、计算。这种方案难以保证数据的一致性,其关键在于 Canal组件只支持同步增量数据,不支持同步历史数据。而数据的聚合统计等分析操作如果没有历史数据支撑,那么分析的结果也是有缺失的。
如果使用基于 Flink CDC 的 ETL 数据分析链路,就可以用Flink CDC简单替换如Canal和Kafka的组件。例如,我们现在需要将MySQL和 Postgres的表进行实时关联,再写入OceanBase。我们只需要用Flink CDC写三段SQL:一是定义MySQL实时订单表;二是定义Postgres实时产品表;三是定义Oceanbase结果表。然后用Flink的 Join 语法,实时关联订单和产品数据,并INSERT INTO 到OceanBase的结果表当中,就完成了两张表的实时打宽和关联。整个过程实时地将MySQL和 Postgres的全量数据和增量数据读出来,进行一致性关联后实时写入OceanBase。
Flink CDC的四个核心技术
上述两个场景中提到的功能,涉及FlinkCDC四个核心技术:
- 全增量一体化读取技术
- 动态表(Dynamic Table)
- 连续查询(Continuous Query)
- Changelog Mechanism
1. 全增量一体化的读取技术。
旧版本Flink CDC的数据库变更读取能力是基于 Debezium 实现的。Debezium 是一个类似于 Canal 的捕获数据库变更数据的类库,该类库提供了全量增量数据的一致性读取。但是该类库有两个核心问题。第一,Debezium使用了数据库的全局锁来保证全量数据和增量数据的一致性,但全局锁会导致数据无法写入,对在线业务造成影响。第二,Debezium只支持单并发读取,当海量数据要入仓时,耗时较长。如果全量数据同步失败,还需要进行重新读取,这会进一步拉长同步耗时。这非常影响系统的稳定性。
针对这些问题,我们在2.0版本迭代时提出了增量快照读取算法。第一,采用增量快照读取算法,无需加锁就能保证全量数据到增量数据的一致性,对业务影响降到最低。第二,将大表切片,切片之间可以并行读取,大幅提升海量数据入仓效率。最后,系统会追踪切片的读取进度,支持按照切片的粒度进行失败回滚,而无需全表重新读取,提升了大规模数据同步场景的稳定性。
2. 动态表(Dynamic Table)。
在读取端将CDC数据读取进来后,我们面对的问题是如何对它进行一致性的处理加工,此处就涉及Flink CDC的第二个核心技术——动态表。
一枚硬币有两面,数据库领域也是如此。动态表意味着数据会随着时间变化,我们在观测动态表时,表的所有变更都是数据流,流和动态表是同一事物的二象性。我们将变更流物化,就得到了一个动态表。我们去观测动态表上的变化,就得到了一个变更流。

3. 连续查询(Continuous Query)。
连续查询和动态表是相辅相成的,当我们在动态表上定义连续查询,就会得到一个新的动态表。这从物理层面而言,产生了一段持续的CDC的流,这条流又可以通过下一个连续查询进行处理和加工,再产生新的动态表,从而编织起一个有分层的流式数仓。

4. Changelog Mechanism。
业界有很多支持流处理的框架,但大多不支持处理CDC的数据,关键原因在于缺乏完整的Changelog数据处理机制。
什么是Changelog数据处理机制?举个例子,现在有一个单词的数据源,我们要对每个单词进行聚合,并且对获取到的词频再进行聚合。比如单词是Hello和World,经统计,我们得到Hello出现一次,World也出现一次,那么词频为1的单词有两个(即[cnt=1, freq=2])。这时,数据源中又出现一个Hello,那么Hello就出现了两次,第一个聚合节点会输出一条Hello=2的更新,经过词频聚合后,会输出词频为2的单词有1个(即[cnt=2, freq=1])。但这是结果表中的[cnt=1, freq=2]是错误的。词频为1的单词少了一个(Hello词频从2变成了1),所以cnt=2对应的freq应该为1才对。

因此,我们引入数据处理机制修正错误结果,最终得到正确结果:[cnt=1,freq=1]。当Hello的出现次数从一次变成两次,我们会像传统数据库一样输出一个完整的更新前镜像和后镜像,也就是先输出旧数据的撤回消息-[Helo, 1],再输出新数据的新增消息+[Hello, 2]。撤回消息在到达聚合节点后,就会对cnt=1的 freq 做减一操作,得到[cnt=1, freq=1]。新增消息会对cnt=2的freq做加一操作,得到[cnt=2,freq=1]。可以看到该结果与批处理的结果一致。通过这种方式,能够保证CDC流处理语义的一致性。Changelog数据处理机制是保证 Streaming SQL 结果正确的关键机制,不需要用户感知,因为优化器会自动判断是否要输出和处理撤回消息(update_before)。

如何基于Flink CDC与OceanBase构建实时数仓?
基于上文Flink CDC的四个核心能力,结合OceanBase,可以构建一个实时的数据仓库,具体怎么做,我们不妨先来了解传统的实时数仓方案。
传统的实时数据仓库基于流式队列方案构建,我们称之为Streaming MQ方案,是目前业界最典型、应用最广泛的方案。将MySQL的数据源同步到Kafka,构建一个ODS数据层,再进行数据打宽、数据清洗,变为DWD的数据层,然后进行聚合,形成一个ADS数据层,最后做数据加工,放进KV层供下游进行消费查询。由于整个过程中数据不可被分析,所以还会将数据同步到分析型数仓。

Streaming MQ方案的优势在于实践经验非常丰富,层次分明,每一个组件的分工明确。但它的劣势也比较明显,比如链路复杂、数据冗余,由于涉及组件较多,排查问题时也非常困难。
因此,我们开始尝试新的构建方案——Streaming OLAP方案,既拥有流式队列的能力,又具备OLAP的处理、分析、查询能力。这一方面基于Flink CDC的核心技术,另一方面得益于OceanBase行列混存的HTAP特性,可以在一套系统中支持交易处理和复杂查询分析的能力。
举个例子,我们通过Flink CDC,把MySQL的全量数据和增量数据同步到OceanBase,形成一个ODS数据层供下游订阅。订阅的同时读取数据做加工和打宽,然后写入下游的OceanBase形成DWD数据层,通过聚合形成DWS数据层,此时就可以为用户提供查询服务和消费提供。

Streaming OLAP方案的优势显而易见,一是避免了Streaming MQ方案的数据冗余问题,不需要再维护一个实时数仓,数据可复用,模型统一,架构简单。二是简化了链路,OceanBase替代了KV服务、分析服务、Kafka等组件。三是解决了排查困难的问题,因为OceanBase每一层都是可查、可更新、可修正的,比如,某一层的数据出现问题,可以直接排查该层的表数据并进行修正,排查更高效。
该套实时数仓方案依赖于两项关键能力:OceanBase的CDC读取能力、OceanBase的CDC写入能力。
1.OceanBase CDC读取的实现机制。
对于全量数据的同步,因为OceanBase兼容MySQL,所以我们可以基于JDBC完成全量数据的读取;增量数据读取方面,基于oblogproxy捕获binlog数据,在数据源,可以通过logproxy-client 订阅 oblogproxy 获取增量数据。因为OceanBase暂时不支持表锁,也不支持行级的binlog位点,所以在全量和增量切换时,只能保证at-least-once读取。也就是说在切换的过程中会多读取数据,不过,Flink 会自动去重,保证最终数据不重复、不丢失。
2.OceanBase CDC写入的实现机制。
由于OceanBase 兼容 MySQL 协议,支持 MySQL 5.6和MySQL 5.7 的绝大多数语法,因此在许多场景下可以将其视作 MySQL 使用,比如,作为 Flink 的目的端数据库,可使用 flink-jdbc-connector 基于 MySQL 协议来写入,支持插入、更新和删除。
OceanBase CDC的读取和写入将整个实时数仓多层之间的数据进行了流式串联。举个例子,我们需要对订单明细表进行聚合,写入DWS层的统计表中。获取每个店铺每天的销售量。只需要三段SQL就可以完成。
第一段命令是定义一个OceanBase CDC的数据源,他是一个来自于orders的表,有这样的一些字段。

第二,使用FlinkCDC统计店铺销售额,将JDBC的表写入OceanBase的表中,形成了店铺指标的统计层。

第三段命令实时读取订单明细层(dwd_orders)的全量数据和增量数据,并进行实时聚合、加工,写入下游的OceanBase中(dws_shops)。该 dwd_shops 表又可以由另一个Flink进行读取,再加工,形成下一层的结果表。从而构建起整个流式数仓的分层概念。

Flink 与 Oceanbase 将全面集成
目前,Flink与数据源之间的集成,主要分成四个维度:源表、维表、结果表、元数据。
在与OceanBase的集成中:
- 源表支持全量数据的读取、增量数据的读取,以及全增量一体化的读取,下一步我们希望支持Exactly-Once 的读取。
- 数据处理和加工过程中最常见的动作是数据补全和数据打宽,在这方面,OceanBase下一步可以作为维表供Flink远程查询。
- 在结果表方面,目前支持数据的实时写入和更新,还有宽表Merge。下一步我们计划支持DDL的实时变更同步及整库的数据同步。
- 在元数据方面,OceanBase将对接Flink Catalog接口。用户填写OceanBase的地址及鉴权信息,OceanBase所有的库表都可以进行实时写入和查询,无需手动定义DDL。
通过这四个维度的集成,Flink结合OceanBase可以打造一站式的实时数仓体验,未来,Flink希望与OceanBase更进一步,进行全面集成。
相关文章:
如何基于Flink CDC与OceanBase构建实时数仓,实现简化链路,高效排查
本文作者:阿里云Flink SQL负责人,伍翀,Apache Flink PMC Member & Committer 众多数据领域的专业人士都很熟悉Apache Flink,它作为流式计算引擎,流批一体,其核心在于其强大的分布式流数据处理能力&…...

ActiveMQ、RabbitMQ 和 Kafka 在 Spring Boot 中的实战
在现代的微服务架构和分布式系统中,消息队列 是一种常见的异步通信工具。消息队列允许应用程序之间通过 生产者-消费者模型 进行松耦合、异步交互。在 Spring Boot 中,我们可以通过简单的配置来集成不同的消息队列系统,包括 ActiveMQ、Rabbit…...
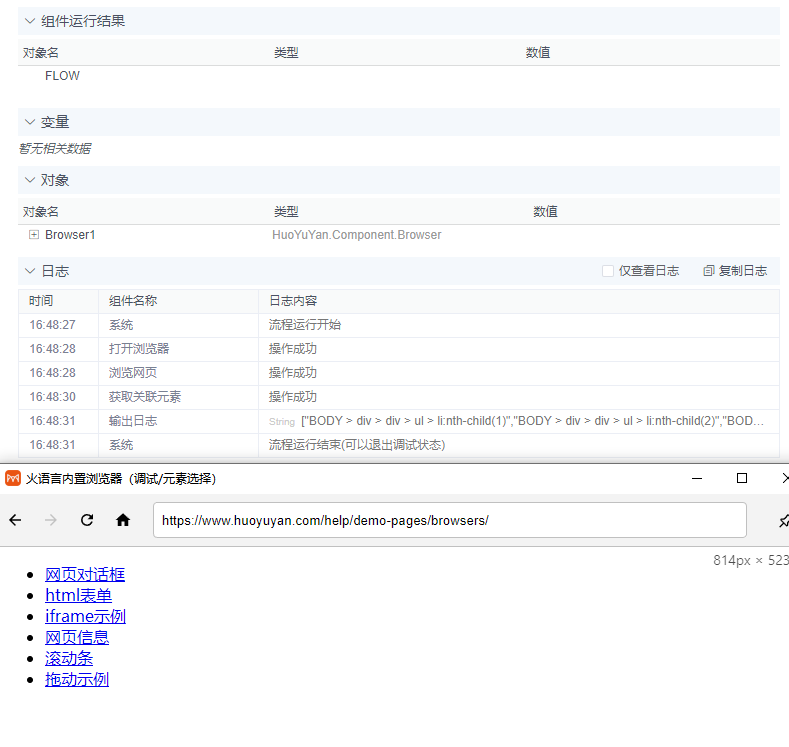
火语言RPA流程组件介绍--获取关联元素
🚩【组件功能】:获取指定元素的父元素、子元素、相邻元素等关联信息 配置预览 配置说明 目标元素 支持T或# 默认FLOW输入项 通过自动捕获工具捕获(选择元素工具使用方法)或手动填写网页元素的css,xpath,指定对应网页元素作为操作目标 关联…...

【2024研赛】【华为杯E题】2024 年研究生数学建模比赛思路、代码、论文助攻
思路将在名片下群聊分享 高速公路应急车道紧急启用模型 高速公路拥堵现象的原因众多,除了交通事故外,最典型的就是部分路段出现瓶颈现象,主要原因是车辆汇聚,而拥堵后又容易蔓延。高速公路一些特定的路段容易形成堵点࿰…...

Linux——K8s集群部署过程
1、环境准备 (1)配置好网络ip和主机名 control: node1: node2: 配置ip 主机名的过程省略 配置一个简单的基于hosts文件的名称解析 [rootnode1 ~]# vim /etc/hosts // 文件中新增以下三行 192.168.110.10 control 192.168.110.11 node1 1…...

二.Unity中使用虚拟摇杆来控制角色移动
上一篇中我们完成了不借助第三方插件实现手游的虚拟摇杆,现在借助这个虚拟摇杆来实现控制角色的移动。 虚拟摇杆实际上就给角色输出方向,类似于键盘的WSAD,也是一个二维坐标,也就是(-1,1)的范围,将摇杆的方向进行归一化…...

基于SpringBoot的旅游管理系统
系统展示 用户前台界面 管理员后台界面 系统背景 近年来,随着社会经济的快速发展和人民生活水平的显著提高,旅游已成为人们休闲娱乐、增长见识的重要方式。国家积极倡导“全民旅游”,鼓励民众利用节假日外出旅行,探索各地自然与人…...

Linux套接字
目录标题 套接字套接字的基本概念套接字的功能与分类套接字的使用流程套接字的应用场景总结套接字在不同操作系统中的实现差异有哪些?如何优化套接字编程以提高网络通信的效率和安全性?原始套接字(SOCK_RAW)的具体应用场景和使用示…...
——二面(游戏测试))
软件测试面试题(5)——二面(游戏测试)
没想到测试题做完等了会儿就安排面试了,还以为自己会直接挂在测试题,这次面试很刺激。测试题总体来说不算太难,主要是实操写Bug那里真没经历过,所以写的很混乱。 我复盘一下这次面试的问题,这次面试是有两个面试官&…...

C#基于SkiaSharp实现印章管理(8)
上一章虽然增加了按路径绘制文本,支持按矩形、圆形、椭圆等路径,但测试时发现通过调整尺寸、偏移量等方式不是很好控制文本的位置。相对而言,使用弧线路径,通过弧线起始角度及弧线角度控制文本位置更简单。同时基于路径绘制文本时…...

信通院发布首个《大模型媒体生产与处理》标准,阿里云智能媒体服务作为业界首家“卓越级”通过
中国信通院近期正式发布《大模型驱动的媒体生产与处理》标准,阿里云智能媒体服务,以“首批首家”通过卓越级评估,并在9大模块50余项测评中表现为“满分”。 当下,AI大模型的快速发展带动了爆发式的海量AI运用,这其中&a…...

AI学习指南深度学习篇-Adam的Python实践
AI学习指南深度学习篇-Adam的Python实践 在深度学习领域,优化算法是影响模型性能的关键因素之一。Adam(Adaptive Moment Estimation)是一种广泛使用的优化算法,因其在多种问题上均表现优异而被广泛使用。本文将深入探讨Adam优化器…...

08_React redux
React redux 一、理解1、学习文档2、redux 是什么吗3、什么情况下需要使用 redux4、redux 工作流程5、react-redux 模型图 二、redux 的三个核心概念1、action2、reducer3、store 三、redux 的核心 API1、getState()2、dispatch() 四、使用 redux 编写应用1、求和案例\_redux 精…...

2024华为杯研究生数学建模竞赛(研赛)选题建议+初步分析
难度:DE<C<F,开放度:CDE>F。 华为专项的题目(A、B题)暂不进行选题分析,不太建议大多数同学选择,对自己专业技能有很大自信的可以选择华为专项的题目。后续会直接更新A、B题思路&#…...

001.从0开始实现线性回归(pytorch)
000动手从0实现线性回归 0. 背景介绍 我们构造一个简单的人工训练数据集,它可以使我们能够直观比较学到的参数和真实的模型参数的区别。 设训练数据集样本数为1000,输入个数(特征数)为2。给定随机生成的批量样本特征 X∈R10002 …...

Relations Prediction for Knowledge Graph Completion using Large Language Models
文章目录 题目摘要简介相关工作方法论实验结论局限性未来工作 题目 使用大型语言模型进行知识图谱补全的关系预测 论文地址:https://arxiv.org/pdf/2405.02738 项目地址: https://github.com/yao8839836/kg-llm 摘要 知识图谱已被广泛用于以结构化格式表…...

2024年中国研究生数学建模竞赛D题思路代码分析——大数据驱动的地理综合问题
地理系统是自然、人文多要素综合作用的复杂巨系统[1-2],地理学家常用地理综合的方式对地理系统进行主导特征的表达[3]。如以三大阶梯概括中国的地形特征,以秦岭—淮河一线和其它地理区划的方式揭示中国气温、降水、植被、土壤及生态环境在水平和垂直方向…...

全国31省对外开放程度、经济发展水平、政府干预程度指标数据(2000-2022年)
旨在分析2000-2022年间中国31个省份的对外开放程度、经济发展水平和政府干预程度,探讨其背后的动因与影响。 2000年-2022年 全国31省对外开放程度、经济发展水平、政府干预程度指标数据https://download.csdn.net/download/2401_84585615/89478612 数据概览 对外…...

计算机网络传输层---课后综合题
线路:TCP报文下放到物理层传输。 TCP报文段中,“序号”长度为32bit,为了让序列号不会循环,则最多能传输2^32B的数据,则最多能传输:2^32/1500B个报文 结果: 吞吐率一个周期内传输的数据/周期时间…...

【homebrew安装】踩坑爬坑教程
homebrew官网,有安装教程提示,但是在实际安装时,由于待下载的包的尺寸过大,本地git缓存尺寸、超时时间的限制,会报如下错误: error: RPC failed; curl 92 HTTP/2 stream 5 was not closed cleanly…...

Unity安卓构建实战指南:解决APK真机安装闪退与构建失败
1. 这不是一本“从零开始”的书,而是一份你真正上手Unity安卓游戏开发前必须撕开的说明书我带过三届Unity实习工程师,也帮二十多个独立开发者把Demo打包进Google Play。每次看到新人在“安卓构建失败”报错里反复挣扎,或者对着“IL2CPP编译卡…...

SSE 基础知识
SSE 基础知识 一、概念定义 SSE 全称 Server-Sent Events,是基于HTTP协议的服务器单向数据推送技术。 建立一次长连接后,服务端可主动持续向前端推送数据,无需客户端反复轮询请求。 二、核心特点 单向通信:仅服务器 → 客户端发送…...

三步实现跨架构程序兼容:Box64高效架构转换指南
三步实现跨架构程序兼容:Box64高效架构转换指南 【免费下载链接】box64 Box64 - Linux Userspace x86_64 Emulator with a twist, targeted at ARM64, RV64 and LoongArch Linux devices 项目地址: https://gitcode.com/gh_mirrors/bo/box64 你是否曾在ARM64…...

厨房空调技术白皮书:从风冷到水冷,制冷系统在厨房场景中的工程化演进
厨房空调是暖通行业近三年技术迭代最密集的细分品类。从最初的"凉霸"(本质是风扇),到风冷分体式,再到水冷一体式,每代技术都在解决上一代没有覆盖的用户痛点。本文以工程技术视角,梳理四代厨房制…...

通过curl命令快速测试Taotoken大模型API的连通性与返回格式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken大模型API的连通性与返回格式 在集成大模型能力到应用时,开发者通常需要一种快速、轻量的…...

艾尔登法环存档迁移终极指南:3分钟解决角色转移难题
艾尔登法环存档迁移终极指南:3分钟解决角色转移难题 【免费下载链接】EldenRingSaveCopier 项目地址: https://gitcode.com/gh_mirrors/el/EldenRingSaveCopier 还在为《艾尔登法环》存档版本不兼容而烦恼吗?EldenRingSaveCopier 是你的终极解决…...

1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法
1688运营培训/询盘成本从500元降到63.9!1688运营培训还原1688真实玩法500块钱一个询盘,你敢信?做1688运营培训这么多年,这个数字我都觉得离谱。前阵子遇到一个老板,一上来就开始吐槽1688,说1688就是个垃圾平…...

终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生
终极指南:用D2DX让《暗黑破坏神2》在现代电脑上焕发新生 【免费下载链接】d2dx D2DX is a complete solution to make Diablo II run well on modern PCs, with high fps and better resolutions. 项目地址: https://gitcode.com/gh_mirrors/d2/d2dx 还在为经…...

深度解析:UI-TARS视觉语言模型驱动的自动化操作框架核心技术架构
深度解析:UI-TARS视觉语言模型驱动的自动化操作框架核心技术架构 【免费下载链接】UI-TARS-desktop The Open-Source Multimodal AI Agent Stack: Connecting Cutting-Edge AI Models and Agent Infra 项目地址: https://gitcode.com/GitHub_Trending/ui/UI-TARS-…...

3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南
3步快速上手Whisper-WebUI:轻松实现语音转字幕的完整指南 【免费下载链接】Whisper-WebUI A Web UI for easy subtitle using whisper model. 项目地址: https://gitcode.com/gh_mirrors/wh/Whisper-WebUI 还在为视频制作繁琐的字幕而烦恼吗?Whis…...