力扣题解2376
大家好,欢迎来到无限大的频道。
今日继续给大家带来力扣题解。
题目描述(困难):
统计特殊整数
如果一个正整数每一个数位都是 互不相同 的,我们称它是 特殊整数 。
给你一个 正 整数 n ,请你返回区间 [1, n] 之间特殊整数的数目。
解题思路:
要计算区间 ([1, n]) 之间的特殊整数数量,可以按以下步骤进行:
-
定义特殊整数:
-
一个特殊整数是指其每一个数位都是互不相同的,即没有重复的数字。
-
-
遍历和检查:
-
遍历每一个整数从 1 到 n,检查每个整数是否为特殊整数。
-
对于每个整数,可以将其分解为其各个数字,并检查这些数字是否有重复。
-
-
利用集合判断重复:
-
可以通过一个数组或集合来记录某个数字是否已经出现。
-
-
计数特殊整数:
-
如果当前数字是特殊整数,将计数器加一。遍历结束后,输出计数器的值。
-
参考代码如下:
bool is_special_integer(int num) {bool digit_seen[10] = {false}; // 标记每个数字是否出现过while (num > 0) {int digit = num % 10; // 取出当前的末尾数字if (digit_seen[digit]) { // 如果该数字已经出现过return false; // 不是特殊整数}digit_seen[digit] = true; // 标记该数字出现过num /= 10; // 去掉当前数字}return true; // 所有数字都互不相同
}
int countSpecialNumbers(int n) {int count = 0; // 特殊整数计数器for (int i = 1; i <= n; i++) {if (is_special_integer(i)) { // 判断是否为特殊整数count++; // 增加计数}}return count; // 返回特殊整数的数量
}代码解析:
-
is_special_integer 函数:
-
输入一个整数 num 并检查其每位数字是否互不相同。使用一个布尔数组 digit_seen 来记录 0-9 这 10 个数字的出现情况。
-
-
countSpecialNumbers 函数:
-
遍历 1 到 n 的所有整数,调用 is_special_integer 函数来判断该数字是否是特殊的,并更新计数器。
-
但是此代码的时间复杂度过高,测试用例超过了限定时间,所以要进行优化。
解题思路:
-
理解特殊整数:
-
特殊整数是在其每一位上没有重复的数字(例如,123、456是特殊整数,但 112、121、123 等不是)。
-
-
动态规划 + 记忆化搜索:
-
mask:用于表示当前已经使用的数字,采用位掩码。
-
prefixSmaller:表示当前构建的前缀数字是否小于目标数字的前缀。
-
nStr:将 ( n ) 转换成字符串形式,以便逐位处理各数字。
-
使用动态规划和哈希表来存储已经计算过的状态,以避免重复计算,提升效率。
-
状态定义:
-
-
递归函数 (DP):
-
通过递归函数 dp 实现动态规划,当当前使用的数字数量等于 ( n ) 的位数时返回 1。
-
对于每个数字,可以根据当前的状态,在允许的范围内选择下一个数字(既 [0,9] 中未被使用的数字)。
-
通过哈希表 memo 存储计算过的 mask 和 prefixSmaller 的组合,以加速后续计算。
-
-
计算统计:
-
首先计算位数小于 ( n ) 的所有特殊整数数量;
-
然后计算与 ( n ) 有相同位数的特殊整数数量。
-
参考代码如下:
typedef struct {int key;int val;UT_hash_handle hh;
} HashItem;
HashItem *hashFindItem(HashItem **obj, int key) {HashItem *pEntry = NULL;HASH_FIND_INT(*obj, &key, pEntry);return pEntry;
}
bool hashAddItem(HashItem **obj, int key, int val) {if (hashFindItem(obj, key)) {return false;}HashItem *pEntry = (HashItem *)malloc(sizeof(HashItem));pEntry->key = key;pEntry->val = val;HASH_ADD_INT(*obj, key, pEntry);return true;
}
bool hashSetItem(HashItem **obj, int key, int val) {HashItem *pEntry = hashFindItem(obj, key);if (!pEntry) {hashAddItem(obj, key, val);} else {pEntry->val = val;}return true;
}
int hashGetItem(HashItem **obj, int key, int defaultVal) {HashItem *pEntry = hashFindItem(obj, key);if (!pEntry) {return defaultVal;}return pEntry->val;
}
void hashFree(HashItem **obj) {HashItem *curr = NULL, *tmp = NULL;HASH_ITER(hh, *obj, curr, tmp) {HASH_DEL(*obj, curr); free(curr);}
}
int dp(int mask, bool prefixSmaller, const char *nStr, HashItem **memo) {if (__builtin_popcount(mask) == strlen(nStr)) {return 1;}int key = mask * 2 + (prefixSmaller ? 1 : 0);if (!hashFindItem(memo, key)) {int res = 0;int lowerBound = mask == 0 ? 1 : 0;int upperBound = prefixSmaller ? 9 : nStr[__builtin_popcount(mask)] - '0';for (int i = lowerBound; i <= upperBound; i++) {if (((mask >> i) & 1) == 0) {res += dp(mask | (1 << i), prefixSmaller || i < upperBound, nStr, memo);}}hashAddItem(memo, key, res);}return hashGetItem(memo, key, 0);
}
int countSpecialNumbers(int n) {char nStr[64];sprintf(nStr, "%d", n);int res = 0;int prod = 9;int len = strlen(nStr);HashItem *memo = NULL;for (int i = 0; i < len - 1; i++) {res += prod;prod *= 9 - i;}res += dp(0, false, nStr, &memo);hashFree(&memo);return res;
}代码分析:
1. 哈希表结构与操作
typedef struct {int key;int val;UT_hash_handle hh; // 哈希表的内部处理
} HashItem; -
定义了一个结构体 HashItem,用于存储键值对(key 和 val),并使用 UT_hash_handle 宏,以便利用 uthash 提供的哈希表功能。
-
哈希表相关操作如下:
HashItem *hashFindItem(HashItem **obj, int key);
bool hashAddItem(HashItem **obj, int key, int val);
bool hashSetItem(HashItem **obj, int key, int val);
int hashGetItem(HashItem **obj, int key, int defaultVal);
void hashFree(HashItem **obj);-
hashFindItem 查找哈希表的项。
-
hashAddItem 添加项到哈希表,如果已存在则返回 false。
-
hashSetItem 设置某项的值,如果不存在,则插入新项。
-
hashGetItem 获取项的值,若不存在则返回默认值。
-
hashFree 释放哈希表的内存。
2. 动态规划函数 dp
int dp(int mask, bool prefixSmaller, const char *nStr, HashItem **memo) {// 检查当前使用的数字数量是否等于目标字符串的数量if (__builtin_popcount(mask) == strlen(nStr)) {return 1; // 如果是,返回 1,表示成功构造了一个有效的特殊整数}// 生成一个唯一的键以访问缓存int key = mask * 2 + (prefixSmaller ? 1 : 0);// 如果当前状态没有被计算过if (!hashFindItem(memo, key)) {int res = 0;int lowerBound = (mask == 0) ? 1 : 0; // 第一个数字不能是 0// 确定当前可以选择的数字上限int upperBound = prefixSmaller ? 9 : nStr[__builtin_popcount(mask)] - '0';// 尝试选择每一个数字for (int i = lowerBound; i <= upperBound; i++) {if (((mask >> i) & 1) == 0) { // 检查当前数字是否未被使用// 递归调用,加入当前选择并更新状态res += dp(mask | (1 << i), prefixSmaller || (i < upperBound), nStr, memo);}}hashAddItem(memo, key, res); // 缓存当前状态的结果}return hashGetItem(memo, key, 0); // 返回缓存的结果或 0
}-
dp 函数中,使用 mask 来表示当前使用的数字,利用位运算避免重复。
-
使用 prefixSmaller 判断当前构造的数字是否小于对应的 ( n ) 的前缀。
-
计算当前状态下所能构造的特殊整数数量,并将其缓存到哈希表中。
3. 主函数 countSpecialNumbers
int countSpecialNumbers(int n) {char nStr[64];sprintf(nStr, "%d", n); // 将 n 转换为字符串形式int res = 0;int prod = 9; // 可能的数字引导初始值为 9int len = strlen(nStr); // 目标长度HashItem *memo = NULL; // 初始化缓存// 计算所有位数小于 n 的特殊整数的数量for (int i = 0; i < len - 1; i++) {res += prod; // 将当前的数量加入结果prod *= 9 - i; // 更新可能的选择数}res += dp(0, false, nStr, &memo); // 计算与 nStr 长度相同的特殊整数hashFree(&memo); // 释放内存return res; // 返回总结果
}-
主函数中,首先将 ( n ) 转为字符串以便逐位处理。
-
计算所有位数小于 ( n ) 的特殊整数数量。
-
通过 dp 函数计算与 ( n ) 有相同位数的特殊整数数量。
-
最后释放内存并返回结果。
总结:
整段代码结合了动态规划与哈希表的缓存机制,优雅地解决了问题:
-
通过位掩码有效记录已使用的数字。
-
通过记忆化搜索加速计算,避免重复递归。
-
提供了高效的方式来计算区间 ([1, n]) 中所有特殊整数的数量,可以适用于较大的数字范围。
这种方法的时间复杂度主要由位数 ( m ) 影响,且结合了组合的计算,通常在实际问题中能够高效运行。
相关文章:
力扣题解2376
大家好,欢迎来到无限大的频道。 今日继续给大家带来力扣题解。 题目描述(困难): 统计特殊整数 如果一个正整数每一个数位都是 互不相同 的,我们称它是 特殊整数 。 给你一个 正 整数 n ,请你返回区间 …...

浅谈计算机视觉的学习路径1
计算机视觉(Computer Vision, CV)是人工智能领域的一个重要分支,它的目标是使计算机能够像人类一样理解和处理图像和视频数据。 面向想要从事该方向的大学生,笔者这里给出以下是关于计算机视觉的学习路径建议: 简要了解…...

VScode C语言中文乱码问题解决
🎉 前言 省流:这不是正经的教学,纯属是作者弱智操作导致的乱码问题,绝不是是什么配置原因导致的。 🎉 问题描述 贴一下我写的C语言代码(太久没写了,最近学数据结构才拾起来) #in…...

安全基础学习-AES128加密算法
前言 AES(Advanced Encryption Standard)是对称加密算法的一个标准,主要用于保护电子数据的安全。AES 支持128、192、和256位密钥长度,其中AES-128是最常用的一种,它使用128位(16字节)的密钥进…...

Python 项目实践:文件批量处理
Python 项目实践:文件批量处理 文章目录 Python 项目实践:文件批量处理一 背景二 发现问题三 分析问题四 解决问题1 找到所有文件2 找到文件特定字段3 找出复杂的字符串4 替换目标字符串5 验证文件是否正确 五 总结六 完整代码示例七 源码地址 本项目旨在…...

jsonschema - 校验Json内容和格式
1、创建对象 from pydantic import BaseModel from typing import Listclass Person(BaseModel):name: strage: intclass Student(Person): level: int 16friends: List[Person] 2、生成 schema schema Student.model_json_schema()内容如下 {$defs: {Person: {propertie…...

浅谈计算机视觉新手的学习路径
浅谈计算机视觉新手的学习路径 计算机视觉是人工智能领域的一个重要分支,它的研究目标是使计算机能够理解和解释我们视觉可以看到的所有外界世界信息。对于一个计算机视觉领域的新人,学习计算机视觉大致可以分为几个步骤,包括理论基础、实际…...

SQL编程题复习(24/9/19)
练习题 x25 10-145 查询S001学生选修而S003学生未选修的课程(MSSQL)10-146 检索出 sc表中至少选修了’C001’与’C002’课程的学生学号10-147 查询平均分高于60分的课程(MSSQL)10-148 检索C002号课程的成绩最高的二人学号…...

提前解锁 Vue 3.5 的新特性
Vue 3.5 是 Vue.js 新发布的版本,虽然没有引入重大变更,但带来了许多实用的增强功能、内部优化和性能改进。 1. 响应式系统优化 Vue 3.5 进一步优化了响应式系统的性能,并且减少内存占用。尤其在处理大型或深度嵌套的响应式数组时ÿ…...
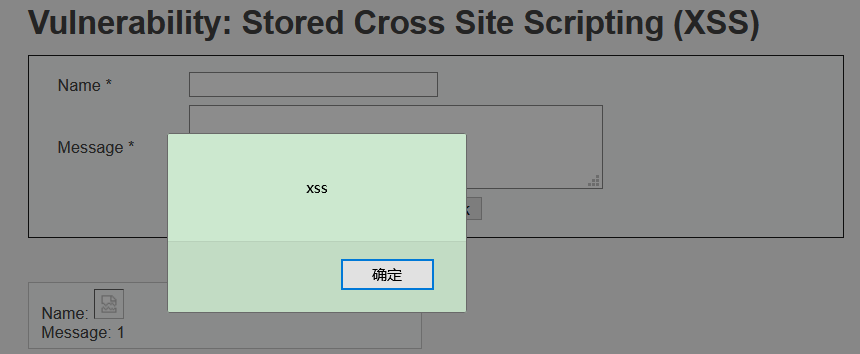
web基础—dvwa靶场(十)XSS
XSS(DOM) 跨站点脚本(XSS)攻击是一种注入攻击,恶意脚本会被注入到可信的网站中。当攻击者使用 web 应用程序将恶意代码(通常以浏览器端脚本的形式)发送给其他最终用户时,就会发生 XSS 攻击。允许这些攻击成…...

搜索引擎onesearch3实现解释和升级到Elasticsearch v8系列(五)-聚合
聚合 聚合基于Query结果的统计,执行过程是搜索的一部分,Onesearch支持0代码构建聚合,聚合目前完全在引擎层 0代码聚合 上图是聚合的配置,包括2个pdm文档聚合统计 termsOfExt term桶聚合,统计ext,如&…...

Pandas中df常用方法介绍
目录 常用方法df.columnsdf.indexdf.valuesdf.Tdf.sort_index()df.sort_values() 案例 常用方法 df.columns df.columns 是 Pandas 中 DataFrame 对象的一个属性,用于获取 DataFrame 中的列标签(列名)。 基本语法如下: df.col…...
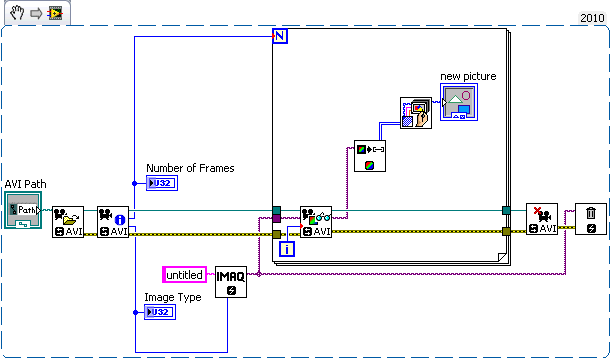
LabVIEW中AVI帧转图像数据
在LabVIEW中,有时需要将AVI视频文件的帧转换为图像数据进行进一步处理。下面详细讲解了如何从AVI视频提取单帧并将其转换为图像数据集群,以便与其他图像处理VI兼容。 问题背景: 用户已经拥有能够处理JPEG图像数据集群的VI,现在希…...

并发与并行的区别:深入理解Go语言中的核心概念
在编程中,并发与并行的区别往往被忽视或误解。很多开发者在谈论这两个概念时,常常把它们混为一谈,认为它们都指“多个任务同时运行”。但实际上,这种说法并不完全正确。如果我们深入探讨并发和并行的区别,会发现它不仅是词语上的不同,更是编程中非常重要的抽象层次,特别…...

小小扑克牌算法
1.定义一个扑克牌类Card: package democard; public class Card {public String suit;//表示花色public int rank;//表示牌点数Overridepublic String toString() {return "{"suit rank"}";}//实例方法,初始化牌的点数和花色public…...

【第34章】Spring Cloud之SkyWalking分布式日志
文章目录 前言一、准备1. 引入依赖 二、日志配置1. 打印追踪ID2. gRPC 导出 三、完整日志配置四、日志展示1. 前端2. 后端 总结 前言 前面已经完成了请求的链路追踪,这里我们通过SkyWalking来处理分布式日志; 场景描述:我们有三个服务消费者…...

easy-es动态索引支持
背景 很多项目目前都引入了es,由于es弥补了mysql存储及搜索查询的局限性,随着技术的不断迭代,原生的es客户端使用比较繁琐不直观,上手代价有点大,所以easy-es框架就面世了,学习成本很低,有空大…...
)
SWC(Speedy Web Compiler)
概述 SWC 由 Rust 编写, 既可用于编译,也可用于打包。 对于编译,它使用现代 JavaScript 功能获取 JavaScript / TypeScript 文件并输出所有主流浏览器支持的有效代码。 SWC在单线程上比 Babel 快 20 倍,在四核上快 70 倍。 简…...

【计算机网络】传输层协议UDP
目录 一、端口号1.1 端口号范围划分1.2 认识知名端口号 二、UDP协议2.1 UDP协议端格式2.2 UDP的特点2.3 UDP的缓冲区2.4 UDP使用注意事项2.5 基于UDP的应用层协议 一、端口号 传输层协议负责数据的传输,从发送端到接收端。端口号标识一个主机上进行通信的不同的应用…...
Docker+PyCharm远程调试环境隔离解决方案
DockerPyCharmMiniconda实现深度学习代码远程调试和环境隔离 本文详细介绍了如何在局域网环境下,利用Docker、PyCharm和Miniconda构建一个高效的深度学习远程调试平台。首先在服务器(server)上,通过Docker构建包含不同CUDA环境的镜…...

告别虚拟机卡顿:在Windows 11的WSL2里搞定Lichee Nano交叉编译环境
告别虚拟机卡顿:在Windows 11的WSL2里搞定Lichee Nano交叉编译环境 对于嵌入式开发者来说,配置开发环境往往是个令人头疼的问题。传统虚拟机方案虽然能提供完整的Linux体验,但资源占用高、启动慢、与宿主系统交互不便等问题一直困扰着开发者。…...

智能手机相机光谱特性测量与多光谱成像技术
1. 智能手机相机光谱特性测量基础智能手机相机的光谱灵敏度函数(Spectral Sensitivity Function, SSF)和透射率函数是计算摄影领域的核心参数,它们决定了设备对光信号的响应特性。准确获取这些参数对色彩还原、光谱重建和白平衡校准等任务至关重要。1.1 光谱灵敏度函…...

DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染
更多请点击: https://codechina.net 第一章:DeepSeek基准测试避坑手册:92%开发者忽略的4大陷阱——硬件配置偏差、tokenizer不一致、batch size幻觉、温度值污染 硬件配置偏差:GPU显存与计算精度的隐性干扰 在A100(8…...
上午题回忆与解析(非标答版))
2026上半年数据库系统工程师(软考)上午题回忆与解析(非标答版)
本文为考后回忆整理,非官方标准答案,旨在为考后对答案及下半年备考的同学提供参考。题目顺序和表述可能与原卷有出入,欢迎在评论区指正、补充。📊 整体考情分析 刚结束的2026年上半年数据库系统工程师考试,上午题的风格…...

电信运营商每月处理海量工单,如何不再出错?基于AI Agent的端到端自动化解决方案
在2026年的电信行业,海量工单处理已不再仅仅是效率问题,而是合规与生存的底线。随着2026年5月20日《电信和互联网服务 基础电信企业网上营业厅服务规范》国家标准的正式实施,监管层对“信息透明、流程闭环、计费精准”的要求达到了前所未有的…...
适合全体毕业生)
口碑最好的AI论文写作工具推荐(从文献整理到论文成稿全流程)适合全体毕业生
还在为选题方向纠结、文献资料翻找耗时、开题报告无从下手、论文框架反复修改、查重率居高不下、降重过程痛苦不堪,甚至答辩PPT还要临时抱佛脚?作为学术新手、应届生或本科硕士毕业生,面对论文写作的重重关卡,流程复杂、操作门槛高…...

Qri高级功能:如何使用JSON Schema验证和描述数据集结构
Qri高级功能:如何使用JSON Schema验证和描述数据集结构 【免费下载链接】qri youre invited to a data party! 项目地址: https://gitcode.com/gh_mirrors/qr/qri Qri是一个强大的开源数据协作工具,它提供了丰富的功能来帮助用户管理、共享和验证…...

ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流
ModernWMS核心功能详解:从ASN入库到Dispatch出库的完整工作流 【免费下载链接】ModernWMS The open source simple and complete warehouse management system is derived from our many years of experience in implementing erp projects. We stripped the origin…...
)
Frida无Root Hook PC微信小程序源码(Electron+Chromium)
1. 这不是“破解”,而是一次对微信小程序运行机制的逆向观察 你有没有试过,在PC版微信里点开一个小程序,想看看它背后是怎么写的?比如某个电商小程序的优惠券逻辑、某个工具类小程序的数据渲染方式,甚至只是单纯好奇—…...

Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间
Driver Store Explorer终极指南:轻松管理Windows驱动存储区,释放宝贵磁盘空间 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾为Windows系统越来越慢而烦…...