Python用TOPSIS熵权法重构粮食系统及期刊指标权重多属性决策MCDM研究|附数据代码...
原文链接:https://tecdat.cn/?p=37724
在当今世界,粮食系统的稳定性至关重要。尽管现有的全球粮食系统在生产和分配方面表现出较高的效率,但仍存在大量人口遭受饥饿以及诸多粮食安全隐患。与此同时,在学术领域,准确评估情报学期刊的质量和影响力对于学术研究和信息传播意义重大(点击文末“阅读原文”获取完整代码数据)。
本研究旨在通过TOPSIS熵权法、多属性决策(MCDM)方法对全球粮食系统进行重构,以优化其效率、盈利能力、可持续性和公平性。
同时,结合python的代码和数据运用熵权法对情报学期刊的各项指标进行权重计算,为期刊评价提供科学方法。通过对粮食系统的四个程序 —— 生产、分配、加工和销售进行全面评估,我们致力于构建一个更加稳定、可持续且公平的粮食系统。而对于情报学期刊的研究,则有助于提升学术评价的准确性和科学性。
对于粮食系统的重构,我们提出了一系列模型。首先,建立模型 I 说明食物系统的效率和利润;其次,模型 II 衡量粮食系统的可持续性;第三,构建模型 III 证明食品系统中的公平问题。此外,我们还利用熵 topsis 方法评估食物系统的稳定性。对于情报学期刊指标权重的计算,结合python的代码和数据我们采用熵权法,通过对数据的处理和分析,得到了期刊学术质量、期刊影响力和期刊显示度等一级指标的权重。
对于重构粮食系统的建议Re-optimizing Food System
我们的全球粮食系统是不稳定的,即使是在世界上通常服务良好的地区。这些不稳定的部分原因是我们目前庞大的国家和国际粮食生产商和分销商的全球体系。这种粮食系统允许粮食以相对便宜和高效的方式生产和分配,因此表明当前的模式优先考虑效率和盈利能力。
尽管这个系统效率很高,但是全球依然大量人口遭受饥饿,同时存在很多粮食安全隐患
我们希望提出一个模型,重新构想和确定我们食品系统的优先级,以优化效率、盈利能力、可持续性和/或公平性。
解决方案
任务/目标
根据公开数据建立影响产量的原因,粮食生产对环境的影响即可持续性,食品运输过程的损耗和经济消耗,提出对于地区食品分配合理性的指标
问题重述
全球粮食系统由四个程序组成:粮食生产、分配、加工还有销售。我们对食物系统的效率进行了定量和充分的评估以及盈利能力、公平性、可持续性和稳定性,相应的变量侧重于每一个步骤。
•衡量效率和盈利能力
•衡量可持续性
•衡量公平
•变量的比较静态分析
•通过示例测量可伸缩性
模型简述
首先,我们建立模型I来说明食物系统的效率和利润,同时生产、加工和分销,并在ISM模型下进行计算确认。
第二,模型II是用来衡量粮食系统的可持续性,重点是食品系统的环境成本。我们计算出在给定条件下的显式和隐式成本用线性回归分析污染指数。我们可以定量地测量环境质量由食物系统引起的。
第三,我们构建了模型III,以证明食品系统中的公平问题主要与一个国家的食品支出有关。
此外,我们利用熵topsis方法来评估食物系统,并讨论现有系统在应对某些紧急情况时的稳定性。
部分模型展示如下
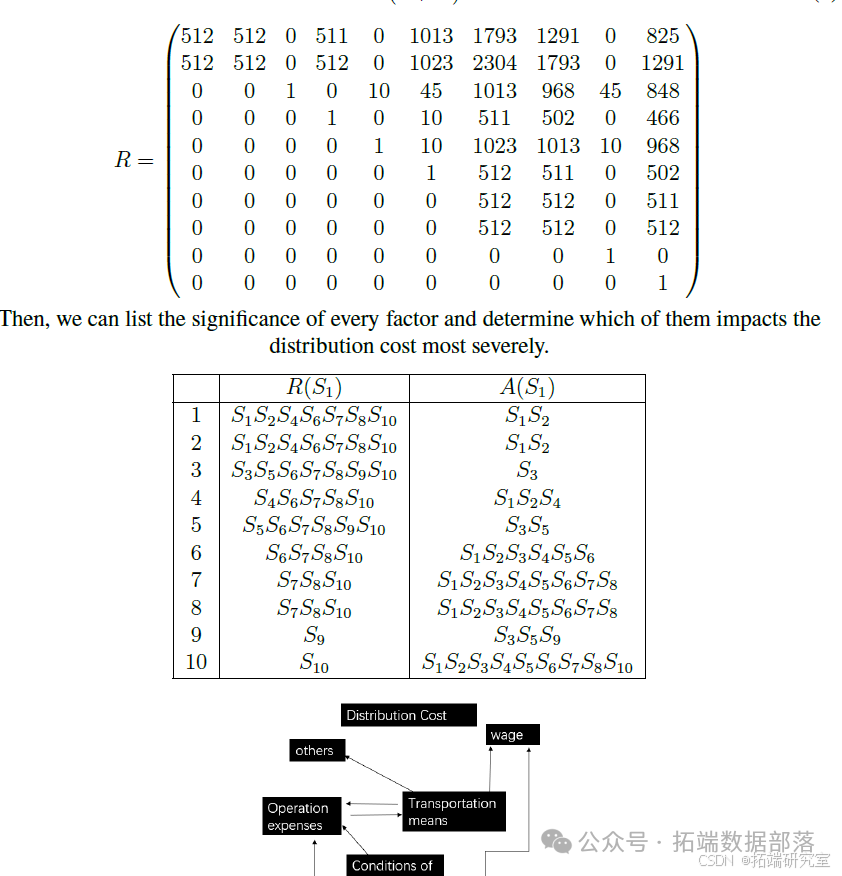
基本完成需要完成的任务,该系统可用于世界各地的许多国家,它还强调了利用宏观经济学研究粮食系统公平性和可持续性的意义。这些数据在大多数国家都很常见。如上所述,我们可以到达通过调整生产要素或政府政策进行优化。
提供了一种简化但仍然定量的方法来衡量权益通过收集一个国家内不同人群的数据来计算差异,我们成功地衡量了粮食系统内部的公平水平,并进行了比较静态分析。
但是也存在明显缺点,特别是对于运输方面,我们采用的ISM解释结构模型仅仅能够定性地分析主要影响原因而不能定量分析,而且由于数据的缺乏,仅仅对部分地区较为准确,整个模型比较粗糙。
点击标题查阅往期内容

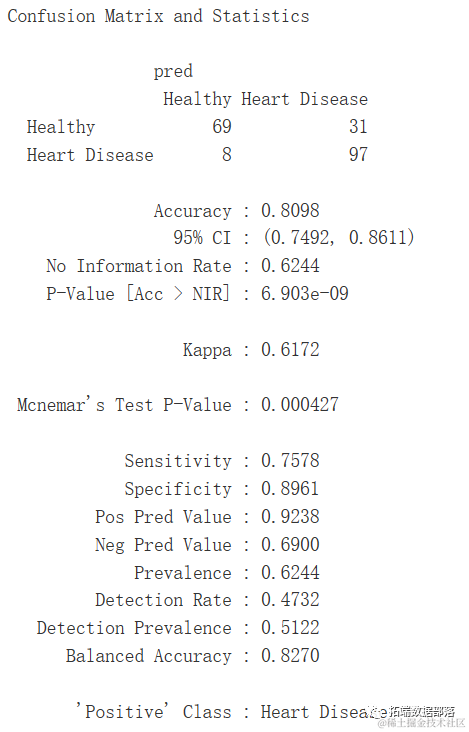
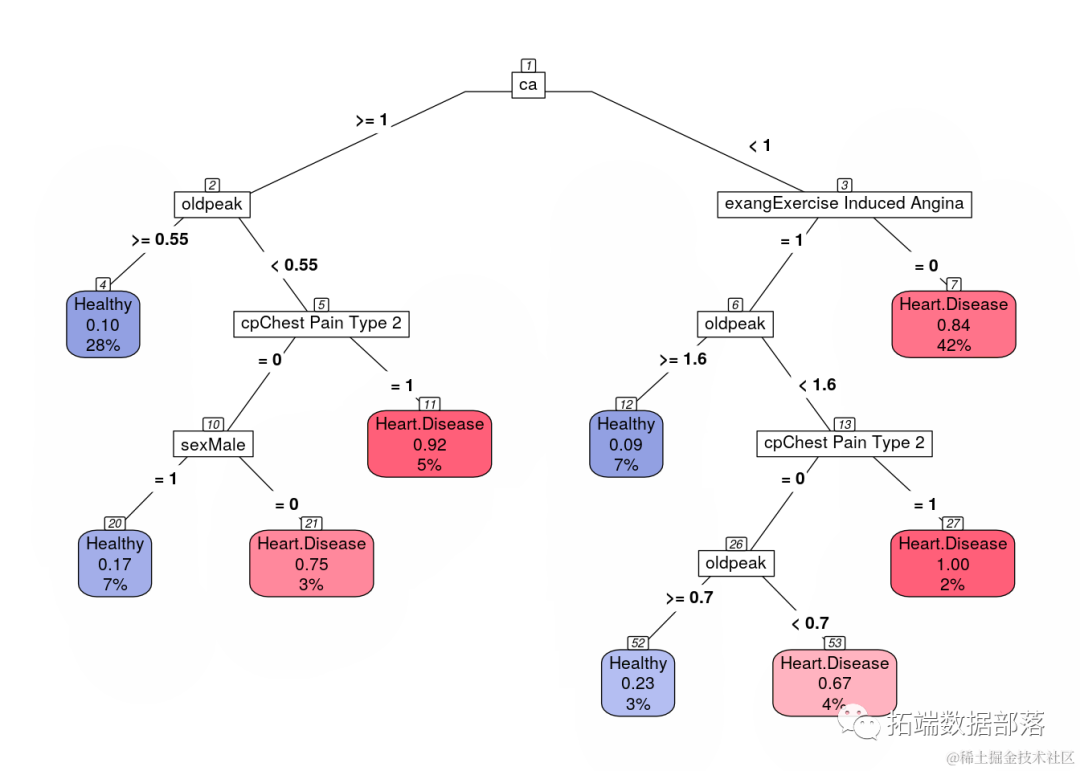
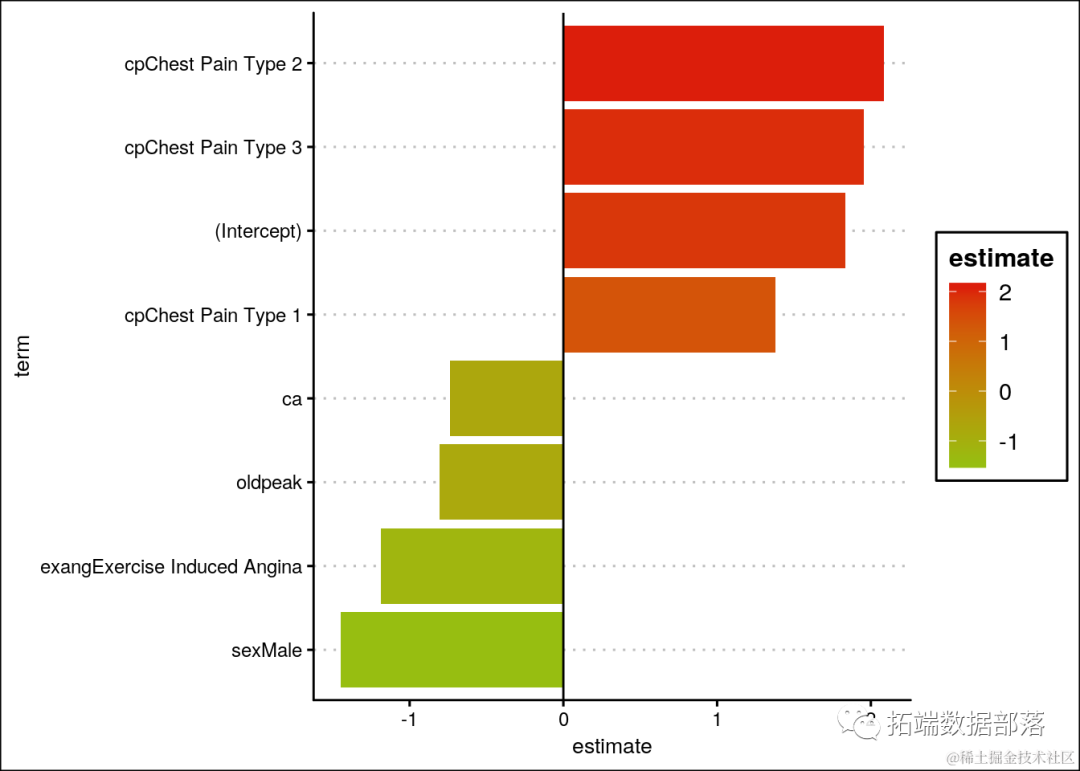
R语言逻辑回归、决策树、随机森林、神经网络预测患者心脏病数据混淆矩阵可视化

左右滑动查看更多
01
02
03
04
TOPSIS 方法在多属性决策(MCDM)中的应用|附数据代码
逼近理想解排序法(Technique for Order Preference by Similarity to Ideal Solution,TOPSIS)在 20 世纪 80 年代作为一种多准则决策方法出现。TOPSIS 选择与理想解的欧氏距离最短且与负理想解的距离最大的方案。
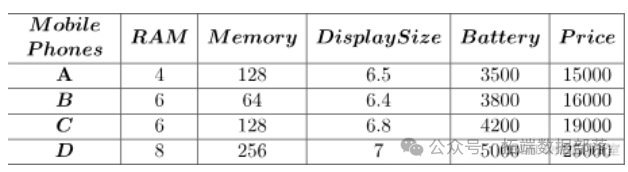
假设你要购买一部手机,去商店后根据 RAM、内存、屏幕尺寸、电池和价格等因素对 5 部手机进行分析。在考虑众多因素后感到困惑,不知如何决定购买哪部手机。TOPSIS 就是一种根据给定因素的权重和影响来分配排名的方法。
权重:表示给定因素应被考虑的程度(默认所有因素权重为 1)。例如,若希望 RAM 的权重高于其他因素,可以将 RAM 的权重设为 2,其他因素设为 1。
影响:指给定因素具有正面或负面的影响。例如,希望电池容量尽可能大,而手机价格尽可能低,所以给电池分配“+”权重,给价格分配“-”权重。
此方法可用于根据各种因素(如相关性、决定系数 $R^2$、准确率、均方根误差等)对机器学习模型进行排名。现在我们已经了解了 TOPSIS 是什么以及可以在哪里应用它。下面来看在给定的由多行(如不同的手机)和多列(如各种因素)组成的数据集上实施 TOPSIS 的步骤。
数据集示例:
给定数据集中特定因素的值被视为标准单位。始终对任何非数字数据类型进行标签编码。
步骤:
步骤 1:计算归一化矩阵和加权归一化矩阵。通过以下方式对每个值进行归一化,其中 $m$ 是数据集中的行数,$n$ 是列数。$i$ 沿行变化,$j$ 沿列变化。

对于上述给定的值,归一化矩阵将是:

然后,将每列中的每个值与相应的给定权重相乘。
def Normaze(dataset, nCol, weights):for i in range(1, nCol):temp = 0for j in range(len(dataset)):temp = temp + dataset.iloc\[j, i\]\*\*2temp = temp\*\*0.5for j in range(len(dataset)):dataset.iat\[j, i\] = (dataset.iloc\[j, i\] / temp)*weights\[i-1\]print(dataset)步骤 2:计算理想最优解和理想最劣解以及每行与理想最劣解和理想最优解的欧氏距离。首先,确定理想最优解和理想最劣解:这里需要考虑影响,即它是“+”影响还是“-”影响。如果是“+”影响,那么某一列的理想最优解是该列的最大值,理想最劣解是该列的最小值,反之对于“-”影响则相反。
现在需要计算所有行中的元素与理想最优解和理想最劣解的欧氏距离。这里 $diw$ 是第 $i$ 行的最劣距离计算值,其中 $ti,j$ 是元素值,$tw,j$ 是该列的理想最劣解。类似地,可以找到 $dib$,即第 $i$ 行的最佳距离计算值。

现在,数据集将包含正距离和负距离,如下所示:

步骤 3:计算 TOPSIS 得分并进行排名。现在我们有了距离正和距离负,让我们根据它们为每行计算 TOPSIS 得分。
TOPSIS 得分 = $diw$ / ($dib$ + $diw$) 对于每一行
现在根据 TOPSIS 得分进行排名,即得分越高,排名越好。
我们的数据集将如下进行排名:
基于熵权法的情报学期刊指标权重计算|附数据代码
本文旨在通过熵权法对情报学期刊的各项指标进行权重计算,以评估不同指标在期刊评价中的重要性。通过对数据的处理和分析,得到了期刊学术质量、期刊影响力和期刊显示度等一级指标的权重。
一、引言
在情报学领域,对期刊的评价是一个重要的研究课题。准确评估期刊的质量和影响力对于学术研究和信息传播具有重要意义。本文采用熵权法对情报学期刊的各项指标进行权重计算,为期刊评价提供一种科学的方法。
二、数据准备
首先,使用pandas库读取情报学期刊数据文件情报学期刊.xlsx。

import pandas as pd# 加载Excel文件file\_path = '/mnt/data/核心期刊数据.xlsx'df = pd.read\_excel(file\_path)# 显示数据的前几行以了解其结构df.head()import matplotlib.pyplot as pltimport seaborn as sns# 设置中文字体,以便在图表中显示中文plt.rcParams\['font.sans-serif'\] = \['SimHei'\]plt.rcParams\['axes.unicode\_minus'\] = False# 创建一个画布,包含多个子图fig, axes = plt.subplots(nrows=3, ncols=2, figsize=(15, 15))# 1. 条形图:展示各期刊的“出版文献量”sns.barplot(x='出版文献量', y='期刊名', data=df, ax=axes\[0, 0\])axes\[0, 0\].set\_title('各期刊的出版文献量')# 2. 饼图:展示不同“基金论文比”的分布df\['基金论文比分类'\] = pd.cut(df\['基金论文比'\], bins=\[0, 0.3, 0.6, 1\], labels=\['低', '中', '高'\])fund\_paper\_ratio\_distribution = df\['基金论文比分类'\].value\_counts()axes\[0, 1\].pie(fund\_paper\_ratio\_distribution, labels=fund\_paper\_ratio\_distribution.index, autopct='%1.1f%%')axes\[0, 1\].set\_title('基金论文比分布')# 3. 折线图:展示“综合影响因子”和“复合影响因子”的关系sns.lineplot(x='综合影响因子', y='复合影响因子', data=df, marker='o', ax=axes\[1, 0\])axes\[1, 0\].set\_title('综合影响因子与复合影响因子的关系')# 4. 箱线图:展示“篇均被引”的分布情况sns.boxplot(x=df\['篇均被引'\], ax=axes\[1, 1\])axes\[1, 1\].set\_title('篇均被引的分布情况')# 5. 散点图:展示“出版文献量”与“总被引频次”的关系sns.scatterplot(x='出版文献量', y='总被引频次', data=df, ax=axes\[2, 0\])axes\[2, 0\].set\_title('出版文献量与总被引频次的关系')# 调整布局plt.tight\_layout()plt.show()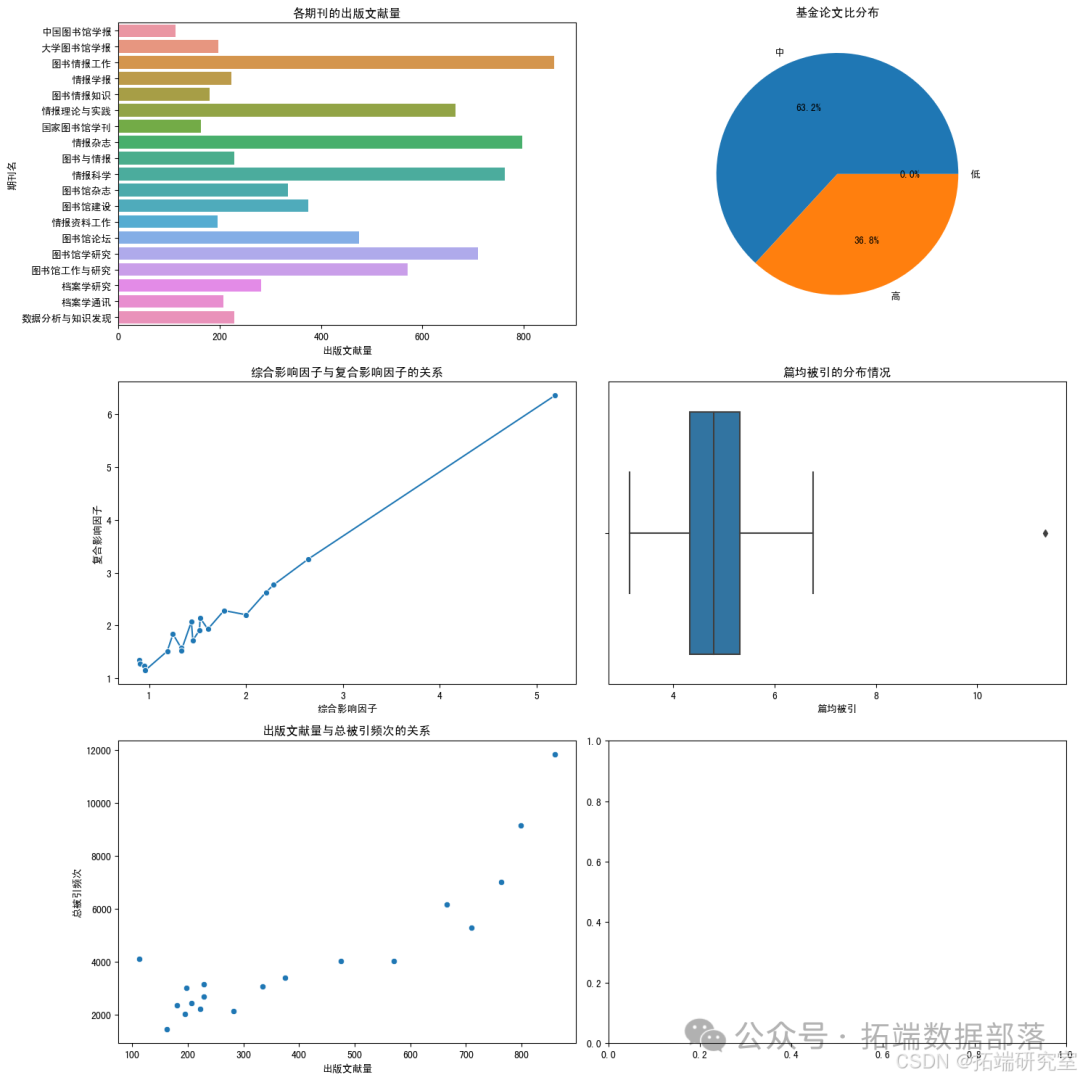
三、指标处理
获取正向指标列表:
# 在没有去掉网络指标的前提下 zhengxiang = data_qingbaoxue.columns.values.tolist() del zhengxiang\[0:2\] del zhengxiang\[1\] zhengxiang # 获得正向指标的列表获取负向指标列表:
index = data_qingbaoxue.columns.values.tolist() del index\[0:2\] fuxiang = \['零引论文率'\] # 获得负向指标列表 journal\_name = data\_qingbaoxue\['图书馆学、情报学类期刊18'\] # 包含了所有需要测量的期刊 indexs = data_qingbaoxue\[index\] # 包含了需要测量的指标的所有数据进行数据归一化等操作:
em = EntropyMethod(indexs, fuxiang, zhengxiang, journal_name) em.uniform() # 归一化后的数据
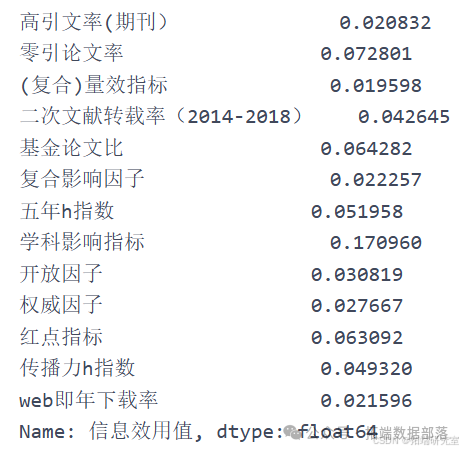
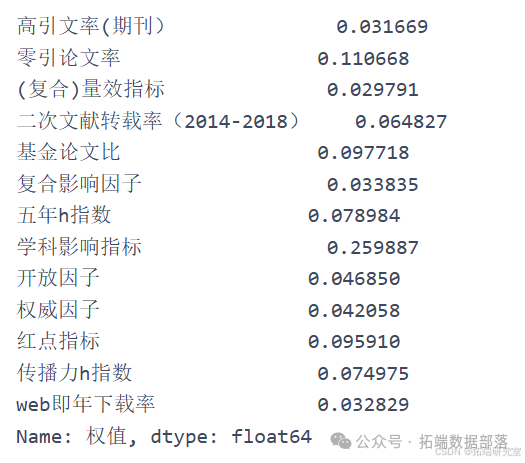
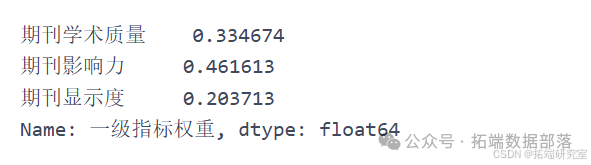
em.calc_probability() em.calc_entropy() em.calc\_entropy\_redundancy() # 尝试计算信息效用值 `````` em.calc_Weight() # 计算得单项指标最终权重 `````` weight = em.calc_Weight().tolist() yijizhibiao = \[\] yijizhibiao.append(sum(weight\[0:5\])) # 按照分类将单项指标权重相加得一级指标权重 yijizhibiao.append(sum(weight\[5:10\])) yijizhibiao.append(sum(weight\[10:\])) yijizhibiao = pd.Series(yijizhibiao, index=\['期刊学术质量', '期刊影响力', '期刊显示度'\], name='一级指标权重') yijizhibiao # 计算一级指标权重去除网络指标后再次计算:
# 在删除网络指标的前提下 zhengxiang.pop() zhengxiang.pop() # 删除位于尾部的两个网络指标 positive = zhengxiang `````` negative = fuxiang index.pop() index.pop() # 同样是删除位于尾部的两个网络指标 indexs = data_qingbaoxue\[index\] em = EntropyMethod(indexs, positive, negative, journal_name) `````` em.uniform()
em.calc_probability() em.calc_entropy() em.calc\_entropy\_redundancy() # 尝试计算信息效用值 `````` em.calc_Weight() # 计算得单项指标最终权重 `````` weight = em.calc_Weight().tolist() yijizhibiao = \[\] yijizhibiao.append(sum(weight\[0:5\])) yijizhibiao.append(sum(weight\[5:10\])) yijizhibiao.append(sum(weight\[10:\])) yijizhibiao = pd.Series(yijizhibiao, index=\['期刊学术质量', '期刊影响力', '期刊显示度'\], name='一级指标权重') yijizhibiao # 计算一级指标权重
四、结论
通过熵权法对情报学期刊数据进行处理和分析,成功计算出了不同指标下期刊学术质量、期刊影响力和期刊显示度等一级指标的权重,为情报学期刊的评价提供了一种有效的方法。
关于分析师

在此对 Sikun Chen 对本文所作的贡献表示诚挚感谢,他在复旦大学完成了数学与应用数学专业的学业,专注数理金融、数据采集等领域。擅长 Matlab。

本文中分析的数据、代码分享到会员群,扫描下面二维码即可加群!
资料获取
在公众号后台回复“领资料”,可免费获取数据分析、机器学习、深度学习等学习资料。

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《Python用TOPSIS熵权法重构粮食系统及期刊指标权重多属性决策MCDM研究》。
点击标题查阅往期内容
MATLAB改进模糊C均值聚类FCM在电子商务信用评价应用:分析淘宝网店铺数据|数据分享
R语言软件对房屋价格预测:回归、LASSO、决策树、随机森林、GBM、神经网络和SVM可视化|数据分享
数据分享|R语言逻辑回归、线性判别分析LDA、GAM、MARS、KNN、QDA、决策树、随机森林、SVM分类葡萄酒交叉验证ROC
R语言贝叶斯广义线性混合(多层次/水平/嵌套)模型GLMM、逻辑回归分析教育留级影响因素数据
逻辑回归Logistic模型原理R语言分类预测冠心病风险实例
数据分享|用加性多元线性回归、随机森林、弹性网络模型预测鲍鱼年龄和可视化
R语言高维数据惩罚回归方法:主成分回归PCR、岭回归、lasso、弹性网络elastic net分析基因数据(含练习题)
Python中LARS和Lasso回归之最小角算法Lars分析波士顿住房数据实例
R语言Bootstrap的岭回归和自适应LASSO回归可视化
R语言Lasso回归模型变量选择和糖尿病发展预测模型
R语言实现贝叶斯分位数回归、lasso和自适应lasso贝叶斯分位数回归分析
基于R语言实现LASSO回归分析
R语言用LASSO,adaptive LASSO预测通货膨胀时间序列
R语言自适应LASSO 多项式回归、二元逻辑回归和岭回归应用分析
R语言惩罚logistic逻辑回归(LASSO,岭回归)高维变量选择的分类模型案例
Python中的Lasso回归之最小角算法LARS
r语言中对LASSO回归,Ridge岭回归和弹性网络Elastic Net模型实现
r语言中对LASSO回归,Ridge岭回归和Elastic Net模型实现
R语言实现LASSO回归——自己编写LASSO回归算法
R使用LASSO回归预测股票收益
python使用LASSO回归预测股票收益



![]()

相关文章:
Python用TOPSIS熵权法重构粮食系统及期刊指标权重多属性决策MCDM研究|附数据代码...
原文链接:https://tecdat.cn/?p37724 在当今世界,粮食系统的稳定性至关重要。尽管现有的全球粮食系统在生产和分配方面表现出较高的效率,但仍存在大量人口遭受饥饿以及诸多粮食安全隐患。与此同时,在学术领域,准确评估…...

【例题】lanqiao4403 希尔排序模板题
插入排序每次只能将数据移动一位。 已知插入排序代码为: def insert_sort(a):for i in range(1,len(a)):ji-1while j>0 and a[j]>a[i]:a[j1]a[j]j-1a[j1]a[i]return a希尔排序在插入排序的基础上,将数据移动n/2,n/4,…,1位。 for i in range(ga…...

【C/C++】速通涉及string类的经典编程题
【C/C】速通涉及string类的经典编程题 一.字符串最后一个单词的长度代码实现:(含注释) 二.验证回文串解法一:代码实现:(含注释) 解法二:(推荐)1. 函数isalnum…...

MySQL:库表的基本操作
库操作 查看 查看存在哪些数据库: show databases;查看自己当前处于哪一个数据库: select database(); 由于我不处于任何一个数据库中,此处值为NULL 查看当前有哪些用户连接到了MySQL: show processlist; 创建 创建一个数据库 语…...

JS领域的AI工程利器分享
JavaScript,这个在网页开发中广为人知的脚本语言,正逐渐在AI工程领域展现出其独特的魅力。对于那些希望将大语言模型(LLM)融入项目的开发者来说,以下五个JavaScript工具将是关键资源。 1. TensorFlow.js TensorFlow.…...

2024/9/20 使用QT实现扫雷游戏
有三种难度初级6x6 中级10x10 高级16x16 完成游戏 游戏失败后,无法再次完成游戏,只能重新开始一局 对Qpushbutton进行重写 mybutton.h #ifndef MYBUTTON_H #define MYBUTTON_H #include <QObject> #include <QWidget> #include <QPus…...

09.20 C++对C的扩充以及C++中的封装、SeqList
SeqList.h #ifndef SEQLIST_H #define SEQLIST_H#include <iostream> #include<memory.h> #include<stdlib.h> #include<string.h>using namespace std;//typedef int datatype; //类型重命名 using datatype int;//封装一个顺序表 class Seq…...

Git提交类型
说明:Git提交类型指的是代码commit时,写在comment前面的标志,表示此次commit的提交类型,如下: Git提交类型 常见的Git提交类型有: feat:新特性、新功能或优化; fix:修复…...

C++速通LeetCode简单第18题-杨辉三角(全网唯一递归法)
全网唯一递归法: vector<vector<int>> generate(int numRows) {vector<int> v;vector<vector<int>>vn;if (numRows 1){v.push_back(1);vn.push_back(v);v.clear();return vn;//递归记得return}if (numRows 2){v.push_back(1);vn.p…...

Redis作为单线程模型,为什么效率高、速度快呢?
前言: 效率高、速度快是相较于数据库来说的(MySQL、Orcale、SQL server) 文章目录 一、单线程模式的工作流程二、为什么快? 一、单线程模式的工作流程 这里我们所说的单线程是指:Redis只使用一个线程,来处…...

人工智能——猴子摘香蕉问题
一、实验目的 求解猴子摘香蕉问题,根据猴子不同的位置,求解猴子的移动范围,求解对应的过程,针对不同的目标状态进行求解。 二、实验内容 根据场景有猴子、箱子、香蕉,香蕉挂天花板上。定义多种谓词描述位置、状态等…...

对ViT 中Patch Embedding理解
借鉴了这个博主的ViT Patch Embedding理解-CSDN博客,再加了一些理解。 就通过代码来理解吧 假设输入图像的维度为HxWxC,分别表示高,宽和通道数。 PatchEmbed 的类,它继承了 nn.Module,实现了将输入的2维图像&#…...

Redis基本命令详解
1. 基本命令 命令不区分大小写,而key是区分大小写的 # select 数据库间的切换 数据库共计16个 127.0.0.1:6379> select 1# dbsize 返回当前数据库的 key 的数量 127.0.0.1:6379[1]> dbsize# keys * 查看数据库所有的key 127.0.0.1:6379[1]> keys *# fl…...

Java之线程篇四
目录 volatile关键字 volatile保证内存可见性 代码示例 代码示例2-(volatile) volatile不保证原子性 synchronized保证内存可见性 wait()和notify() wait()方法 notify() 理解notify()和notifyAll() wait和sleep的对比 volatile关键字 volati…...

计算机毕业设计之:基于微信小程序的校园流浪猫收养系统
博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台…...
)
SpringBoot:关于Redis的配置失效(版本问题)
我们使用redis时发现yaml配置中的redis相关配置不生效,后面发现将配置修改甚至删除所有相关redis的配置,springboot依然能使用redis里面默认的db0并且不报错。上网查阅了一些文章,也都没有解决今天分享下,我的处理方法, SpringBo…...

halcon 快速定义字典
定义一个名为params的字典 Params : dict{} 等价于用 create_dict (Params ) 为字典添加键值对,在halcon中箭只能是字符串,值可以是任何类型的obj或者tuple Params.remove_outer_edges : true Params.max_gap : 150 等价于用 set_dict_object (true,…...

Sublime text3怎么关闭提示更新
问题 sublime text 3有新版本后,会不停地在每次启动后弹窗提示更新版本 第一步 软件安装之前,切记是软件安装之前!!!需要在hosts中添加以下内容(屏蔽官网联网检测):hosts的位置一般在C:\Windows\System32\drivers\etc…...

生成式语言模型技术栈
生成式语言模型的最新技术栈正在快速发展,尤其是随着大规模预训练模型(LLMs)和生成式AI的应用不断扩展。以下是当今最前沿的生成式语言模型技术栈,涵盖从模型开发到优化、推理和部署的各个环节。 1. 基础模型开发 基础模型开发包…...
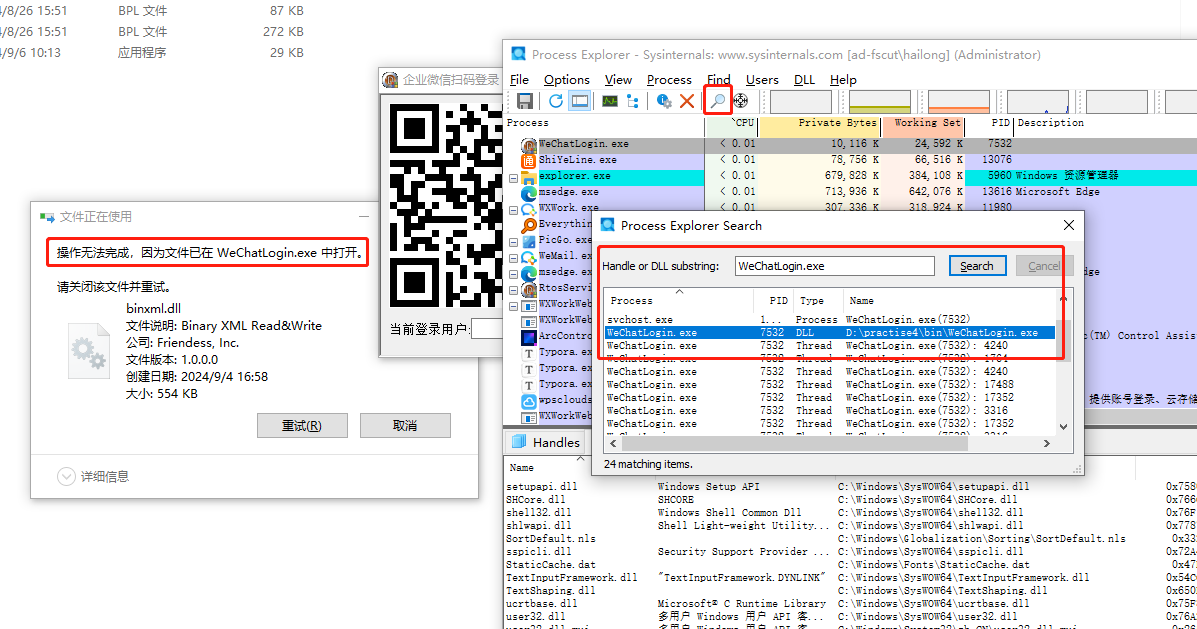
进程分析工具Process Explorer使用
进程分析工具Process Explorer使用 Process Explorer让使用者能了解看不到的在后台执行的处理程序,能显示目前已经载入哪些模块,分别是正在被哪些程序使用着,还可显示这些程序所调用的DLL进程,以及他们所打开的句柄。Process Expl…...

使用SEGGER Ozone调试nRF9160 Zephyr多线程应用:从HardFault到线程可视化
1. 项目概述:为什么选择Ozone调试nRF9160 Zephyr应用如果你正在用Nordic的nRF9160开发物联网设备,并且选用了Zephyr RTOS作为软件基础,那么调试环节很可能会成为你项目中的一个“痛点”。nRF9160本身集成了Cortex-M33内核、蜂窝调制解调器和丰…...

融合PlatformIO与CubeMX:打造跨平台STM32 HAL高效开发工作流
1. 为什么需要融合PlatformIO与CubeMX? 做STM32开发的朋友们应该都深有体会:CubeMX的图形化配置确实方便,但生成的代码往往需要手动移植到各种IDE里;PlatformIO支持跨平台开发,但直接用它配置STM32外设又不够直观。我过…...
详情页开发避坑指南:路由配置与参数传递详解)
告别弹窗!若依框架(Ruoyi)详情页开发避坑指南:路由配置与参数传递详解
若依框架详情页开发实战:从路由配置到参数传递的深度解析 在若依框架的实际开发中,详情页的实现往往成为开发者遇到的"拦路虎"。明明按照文档操作,却频繁遭遇页面空白、参数丢失或控制台报错等问题。本文将深入剖析若依框架中前端路…...

桌面级机械臂DIY全攻略:从运动学建模到PID控制实战
1. 项目概述:一个桌面级机械臂的诞生最近在逛GitHub的时候,发现了一个挺有意思的项目,叫“ClawPuter”。光看名字,你可能会有点摸不着头脑,Claw是爪子,Puter是计算机,合起来是“爪式计算机”&am…...

别再傻傻分不清了!全桥、半桥、推挽电源拓扑,到底哪个更适合你的项目?
全桥、半桥与推挽拓扑实战选型指南:从理论到工程落地的关键抉择 在电力电子设计领域,拓扑结构的选择往往决定着整个项目的成败。当我第一次面对500W工业电源设计需求时,曾天真地认为"功率越大拓扑越高级"——这个错误认知让我付出了…...

ROFL-Player:基于C的多版本英雄联盟回放文件解析技术实现
ROFL-Player:基于C#的多版本英雄联盟回放文件解析技术实现 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player ROFL-Player是一款…...

如何用KLOGG在5分钟内成为日志分析高手
如何用KLOGG在5分钟内成为日志分析高手 【免费下载链接】klogg Really fast log explorer based on glogg project 项目地址: https://gitcode.com/gh_mirrors/kl/klogg 你是否曾在海量日志文件中迷失方向?面对数十GB的日志数据,传统的grep命令显…...

基于Adafruit NeoTrellis M4打造自定义物理宏键盘:HID协议与CircuitPython实战
1. 项目概述:从通用键盘到专属启动台 如果你和我一样,每天要在电脑前处理大量任务,频繁地在不同应用间切换,或者需要执行一系列固定的快捷键操作,那么你肯定对“效率工具”有着执着的追求。我们习惯了通用键盘的“Ctrl…...

Python实战:从时序数据到ARIMA预测的完整建模指南
1. 时间序列分析与ARIMA模型入门 时间序列分析就像是一位经验丰富的老中医把脉——通过观察数据随时间变化的"脉搏",我们能诊断出背后的规律并预测未来走势。ARIMA模型正是其中最经典的"听诊器"之一,我在处理销售预测、库存管理等项…...

87456238
8637452...