MySQL --基本查询(上)
文章目录
- 1.Create
- 1.1单行数据+全列插入
- 1.2多行数据+指定列插入
- 1.3插入否则更新
- 1.4替换
- 2.Retrieve
- 2.1 select列
- 2.1.1全列查询
- 2.1.2指定列查询
- 2.1.3查询字段为表达式
- 2.1.4 为查询结果指定别名
- 2.1.5结果去重
- 2.2where 条件
- 2.2.1英语不及格的同学及英语成绩 ( < 60 )
- 2.2.2语文成绩在 [80, 90] 分的同学及语文成绩
- 2.2.3数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
- 2.2.4姓孙的同学 及 孙某同学
- 2.2.5语文成绩好于英语成绩的同学
- 2.2.6总分在 200 分以下的同学
- 2.2.7语文成绩 > 80 并且不姓孙的同学
- 2.2.8 孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
- 2.2.9 null的查询
- 2.3 结果排序
- 2.3.1同学及数学成绩,按数学成绩升序显示
- 2.3.2同学及 qq 号,按 qq 号排序显示
- 2.3.3 查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
- 2.3.4查询同学及总分,由高到低
- 2.3.5 查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
1.Create
语法:
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES (value_list) [, (value_list)] ...value_list: value, [, value] ...
示例:
创建一张学生表
CREATE TABLE students (
id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
sn INT NOT NULL UNIQUE COMMENT '学号',
name VARCHAR(20) NOT NULL,
qq VARCHAR(20)
);
1.1单行数据+全列插入
-- 插入两条记录,value_list 数量必须和定义表的列的数量及顺序一致
-- 注意,这里在插入的时候,也可以不用指定id(当然,那时候就需要明确插入数据到那些列了),那么mysql会使用默认的值进行自增。INSERT INTO students VALUES (100, 10000, '唐三藏', NULL);INSERT INTO students VALUES (101, 10001, '孙悟空', '11111');
-- 查看插入结果
SELECT * FROM students;

1.2多行数据+指定列插入
插入两条记录,value_list 数量必须和指定列数量及顺序一致
insert students (sn,name) values
(20001,'曹孟德'),
(20002,'孙仲谋');select * from students;

1.3插入否则更新
由于 主键 或者 唯一键 对应的值已经存在而导致插入失败
INSERT INTO students (id, sn, name) VALUES (100, 10010, '唐大师');INSERT INTO students (sn, name) VALUES (20001, '曹阿瞒');

可以选择性的进行同步更新操作
语法:
INSERT ... ON DUPLICATE KEY UPDATE
column = value [, column = value] ...
insert students (id,sn,name) values(100,10010,'唐大师')
on duplicate key update sn=10010,name='唐大师';

冲突数据被更新
– ON DUPLICATE KEY 当发生重复key的时候
1.4替换
– 主键 或者 唯一键 没有冲突,则直接插入;
– 主键 或者 唯一键 如果冲突,则删除后再插入
replace students (sn,name) values (20001,'曹阿瞒');
select * from students;

2.Retrieve
语法:
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...
示例:
创建表结构
create table exam_result(
id int unsigned primary key auto_increment,
name varchar(20) not null comment'姓名',
chinese float default 0.0 comment'语文成绩',
math float default 0.0 comment'数学成绩',
english float default 0.0 comment'英语成绩'
);
插入测试数据
insert exam_result(name,chinese,math,english)values
('唐三藏', 67, 98, 56),
('孙悟空', 87, 78, 77),
('猪悟能', 88, 98, 90),
('曹孟德', 82, 84, 67),
('刘玄德', 55, 85, 45),
('孙权', 70, 73, 78),
('宋公明', 75, 65, 30);

2.1 select列
2.1.1全列查询
– 通常情况下不建议使用 * 进行全列查询
– 1. 查询的列越多,意味着需要传输的数据量越大;
– 2. 可能会影响到索引的使用。
select * from exam_result;

2.1.2指定列查询
– 指定列的顺序不需要按定义表的顺序来
select id,name,english from exam_result;

2.1.3查询字段为表达式
– 表达式不包含字段
select id,name,5 from exam_result;
– 表达式包含一个字段
select id,name,english+5 from exam_result;

– 表达式包含多个字段
SELECT id, name, chinese + math + english FROM exam_result;

2.1.4 为查询结果指定别名
语法:
SELECT column [AS] alias_name [...] FROM table_name;
SELECT id, name, chinese + math + english 总分 FROM exam_result;

2.1.5结果去重
SELECT math FROM exam_result;

– 98 分重复了
SELECT DISTINCT math FROM exam_result;
– 去重结果

2.2where 条件
比较运算符:
| 运算符 | 说明 |
|---|---|
| >,>=, <, <= | 大于,大于等于,小于,小于等于 |
| = | 等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
| <=> | 等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
| !=, <> | 不等于 |
| BETWEEN a0 AND a1 | 范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
| IN (option, …) | 如果是 option 中的任意一个,返回 TRUE(1) |
| IS NULL | 是 NULL |
| IS NOT NULL | 不是 NULL |
| LIKE | 模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算符:
| 运算符 | 说明 |
|---|---|
| AND | 多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
| OR | 任意一个条件为 TRUE(1), 结果为 TRUE(1) |
| NOT | 条件为 TRUE(1),结果为 FALSE(0) |
示例:
2.2.1英语不及格的同学及英语成绩 ( < 60 )
select name,english from exam_result where english<60;

2.2.2语文成绩在 [80, 90] 分的同学及语文成绩
SELECT name, chinese FROM exam_result WHERE chinese >= 80 AND chinese <= 90;

– 使用 BETWEEN … AND … 条件
SELECT name, chinese FROM exam_result WHERE chinese BETWEEN 80 AND 90;

2.2.3数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
select name,math from exam_result
where math=58
or math=59
or math=98
or math=99;

– 使用 IN 条件
SELECT name, math FROM exam_result WHERE math IN (58, 59, 98, 99);

2.2.4姓孙的同学 及 孙某同学
– % 匹配任意多个(包括 0 个)任意字符
select name from exam_result where name like '孙%';

– _ 匹配严格的一个任意字符
SELECT name FROM exam_result WHERE name LIKE '孙_';

2.2.5语文成绩好于英语成绩的同学
– WHERE 条件中比较运算符两侧都是字段
SELECT name, chinese, english FROM exam_result WHERE chinese > english;

2.2.6总分在 200 分以下的同学
– WHERE 条件中使用表达式
– 别名不能用在 WHERE 条件中
SELECT name, chinese + math + english 总分 FROM exam_resultWHERE chinese + math + english < 200;

2.2.7语文成绩 > 80 并且不姓孙的同学
SELECT name, chinese FROM exam_result
WHERE chinese > 80 AND name NOT LIKE '孙%';

2.2.8 孙某同学,否则要求总成绩 > 200 并且 语文成绩 < 数学成绩 并且 英语成绩 > 80
select name,chinese,math,english,chinese+math+english 总分 from exam_result where name like ' 孙_' or (chinese +math +english>200 and chinese < math and english>80);
2.2.9 null的查询
– 查询 students 表

– 查询 qq 号已知的同学姓名
SELECT name, qq FROM students WHERE qq IS NOT NULL;

– NULL 和 NULL 的比较,= 和 <=> 的区别
SELECT NULL = NULL, NULL = 1, NULL = 0;
SELECT NULL <=> NULL, NULL <=> 1, NULL <=> 0;

2.3 结果排序
语法:
– ASC 为升序(从小到大)
– DESC 为降序(从大到小)
– 默认为 ASC
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...];
注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
示例:
2.3.1同学及数学成绩,按数学成绩升序显示
SELECT name, math FROM exam_result ORDER BY math;

2.3.2同学及 qq 号,按 qq 号排序显示
– NULL 视为比任何值都小,升序出现在最上面
SELECT name, qq FROM students ORDER BY qq;

– NULL 视为比任何值都小,降序出现在最下面
SELECT name, qq FROM students ORDER BY qq DESC;

2.3.3 查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
– 多字段排序,排序优先级随书写顺序
SELECT name, math, english, chinese FROM exam_result
ORDER BY math DESC, english, chinese;

2.3.4查询同学及总分,由高到低
– ORDER BY 中可以使用表达式
SELECT name, chinese + english + math FROM exam_result
ORDER BY chinese + english + math DESC;

– ORDER BY 子句中可以使用列别名
SELECT name, chinese + english + math 总分 FROM exam_result ORDER BY 总分 DESC;

2.3.5 查询姓孙的同学或者姓曹的同学数学成绩,结果按数学成绩由高到低显示
– 结合 WHERE 子句 和 ORDER BY 子句
SELECT name, math FROM exam_result
WHERE name LIKE '孙%' OR name LIKE '曹%'
ORDER BY math DESC;

相关文章:
MySQL --基本查询(上)
文章目录 1.Create1.1单行数据全列插入1.2多行数据指定列插入1.3插入否则更新1.4替换 2.Retrieve2.1 select列2.1.1全列查询2.1.2指定列查询2.1.3查询字段为表达式2.1.4 为查询结果指定别名2.1.5结果去重 2.2where 条件2.2.1英语不及格的同学及英语成绩 ( < 60 )2.2.2语文成…...
(19))
mysql学习教程,从入门到精通,SQL 删除数据(DELETE 语句)(19)
1、SQL 删除数据(DELETE 语句) 在SQL中,TRUNCATE TABLE 语句用于删除表中的所有行,但不删除表本身。这个操作通常比使用 DELETE 语句删除所有行要快,因为它不记录每一行的删除操作到事务日志中,而是直接重…...

RoguelikeGenerator Pro - Procedural Level Generator
这是怎么一回事? Roguelike Generator Pro:简单与力量的结合。使用GameObjects、Tilemaps或自定义解决方案轻松制作3D/2D/2.5D关卡。享受内置功能,如碰撞处理、高度变化、基本控制器和子随机化器,所有这些都由Drunkard Wlak程序生成算法提供支持。 我该如何使用它? 简单:…...
)
反病毒技术和反病毒软件(网络安全小知识)
一、反病毒技术的难点 病毒变异与多态性:病毒开发者不断利用新技术和漏洞,创造出新的病毒变种和多态病毒。这些病毒能够自我变异,从而避开传统的基于特征码的检测方法,使得反病毒软件难以识别和清除。 未知病毒检测:在…...

位图与布隆过滤器
引例 给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。 思路1:排序二分查找 思路2:哈希或红黑树 因为40亿个整数要占用16GB 102410241024Byte 约等于10亿Byte1GB 40亿*4Byte 16G…...

【题解】—— LeetCode一周小结38
🌟欢迎来到 我的博客 —— 探索技术的无限可能! 🌟博客的简介(文章目录) 【题解】—— 每日一道题目栏 上接:【题解】—— LeetCode一周小结37 16.公交站间的距离 题目链接:1184. 公交站间的距…...
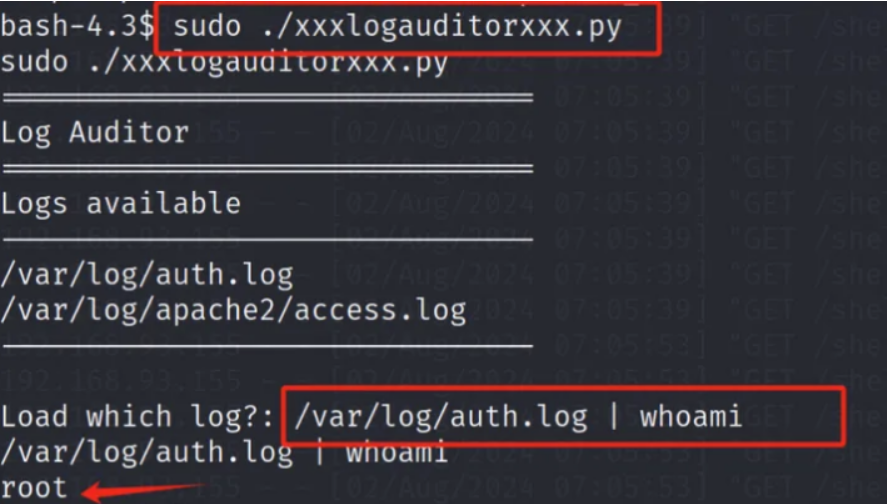
EvilScience靶机详解
主机发现 arp-scan -l 得到靶机ip 192.168.229.152 端口扫描 nmap -sV -A -T4 192.168.1.20 这段代码使用 nmap 命令来扫描目标主机 192.168.1.20,并执行以下操作:-sV:探测开放的端口,以确定服务/版本信息。-A:启…...

算法练习题24——leetcode3296移山所需的最小秒数(二分模拟)
【题目描述】 【代码示例(java)】 class Solution {// 计算让工人们将山的高度降到0所需的最少时间public long minNumberOfSeconds(int mountainHeight, int[] workerTimes) {long left 0; // 最少时间初始为0long right 0; // 最大时间初始化为0// …...

excel 单元格一直显示年月日
excel 单元格一直显示年月日,在单元格上右键选择单元格格式,选择日期时单元格会显示成日期格式...

【线程】线程的控制
本文重点:理解线程控制的接口 前言 内核中是没有很明确线程的概念的,只有轻量级进程的概念,不会提供直接给我们线程的系统调用,而会给我们提供轻量级进程的系统调用。我们用户是需要线程的接口的,在应用层࿰…...

掌握 Spring:从新手到高手的常见问题汇总
一提起Spring,总感觉有太多知识,无法详尽,有些基础理解就先不说了,相信大家都已经用过Spring了 下面简单针对常见Spring面试题做些回答 核心特性 IOC容器spring事件资源管理国际化校验数据绑定类型转换spirng表达式面向切面编程……...

机器学习——Bagging
Bagging: 方法:集成n个base learner模型,每个模型都对原始数据集进行有放回的随机采样获得随机数据集,然后并行训练。 回归问题:n个base模型进行预测,将得到的预测值取平均得到最终结果。 分类问题…...

日志体系结构与框架:历史、实现与如何在 Spring Cloud 中使用日志体系
文章目录 1. 引言2. 日志体系结构3. 日志框架的发展历程日志框架特点对比 4. 日志记录器的使用与管理使用 SLF4J 和 Logback 的日志记录示例 5. Spring Cloud 中的日志使用5.1 日志框架集成5.2 分布式追踪:Spring Cloud Sleuth 和 Zipkin添加 Sleuth 和 Zipkin 依赖…...

图文深入理解SQL语句的执行过程
List item 本文将深入介绍SQL语句的执行过程。 一.在RDBMS(关系型DB)中,看似很简单的一条已写入DB内存的SQL语句执行过程却非常复杂,也就是说,你执行了一条诸如select count(*) where id 001 from table_name的非常简…...

ubuntu安装StarQuant
安装boost 下面展示一些 内联代码片。 sudo apt install libboost-all-dev -y安装libmongoc-1.0 链接: link // An highlighted block sudo apt install libmongoc-1.0-0 sudo apt install libbson-1.0 sudo apt install cmake libssl-dev libsasl2-dev编译源码 $ git clone…...
)
学习篇 | Jupyter 使用(notebook hub)
1. JupyterHub 1.1 快速尝试 jupyterhub -f/path/jupyter_config.py --no-ssl1.2 长期后台运行 bash -c "nohup jupyterhub -f/path/jupyter_config.py --no-ssl" > ~/jupyterhub.log 2>&1 &1.3 帮助 jupyterhub --help2. Jupyter Notebook 2.1 快…...
-虚拟内存swap交换分区扩展)
【裸机装机系列】8.kali(ubuntu)-虚拟内存swap交换分区扩展
推荐阅读: 1.kali(ubuntu)-为什么弃用ubuntu,而选择基于debian的kali操作系统 linux swap交换分区,相当于win系统虚拟内存的概念。当linux系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前…...

异步请求的方法以及原理
异步请求是指在发送请求后,不会阻塞程序的执行,而是继续执行后续的代码,等待请求返回后再执行相应的回调函数。常见的异步请求方法包括使用XMLHttpRequest对象(XHR)和fetch API。 异步请求的方法 1. XMLHttpRequest (X…...

SpringCloud入门(六)Nacos注册中心(下)
一、Nacos环境隔离 Nacos提供了namespace来实现环境隔离功能。 nacos中可以有多个namespace。namespace下可以有group、service等。不同namespace之间相互隔离,例如不同namespace的服务互相不可见。 使用Nacos Namespace 环境隔离 步骤: 1.在Nacos控制…...

【RDMA】mlxlink检查和调试连接状态及相关问题--驱动工具
简介 mlxlink工具用于检查和调试连接状态及相关问题。该工具可以用于不同的链路和电缆(包括被动、电动、收发器和背板)。 属于mft工具套件的一个工具,固件工具 Firmware Tools (MFT):https://blog.csdn.net/bandaoyu/article/details/14242…...

KaTrain终极指南:用AI围棋教练快速提升你的棋艺水平
KaTrain终极指南:用AI围棋教练快速提升你的棋艺水平 【免费下载链接】katrain Improve your Baduk skills by training with KataGo! 项目地址: https://gitcode.com/gh_mirrors/ka/katrain 你是否曾经在对局后感到困惑,不知道自己的失误究竟在哪…...

10个Tunasync配置技巧:从基础到高级应用
10个Tunasync配置技巧:从基础到高级应用 【免费下载链接】tunasync Mirror job management tool. 项目地址: https://gitcode.com/gh_mirrors/tu/tunasync Tunasync 是一款强大的镜像作业管理工具,能够帮助用户轻松配置和管理各种镜像同步任务。…...

OpCore-Simplify:开源系统硬件适配的自动化配置引擎
OpCore-Simplify:开源系统硬件适配的自动化配置引擎 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 在跨平台系统部署领域,硬件…...

Win11Debloat终极指南:快速清理Windows系统臃肿的完整教程
Win11Debloat终极指南:快速清理Windows系统臃肿的完整教程 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutter an…...

MulimgViewer 终极指南:高效图片对比与拼接的完整解决方案
MulimgViewer 终极指南:高效图片对比与拼接的完整解决方案 【免费下载链接】MulimgViewer MulimgViewer is a multi-image viewer that can open multiple images in one interface, which is convenient for image comparison and image stitching. 项目地址: ht…...

美国签证预约神器:3步告别熬夜抢号,智能锁定更早面试时间
美国签证预约神器:3步告别熬夜抢号,智能锁定更早面试时间 【免费下载链接】us-visa-bot US Visa Bot 项目地址: https://gitcode.com/gh_mirrors/us/us-visa-bot 还在为美国签证预约的漫长等待而焦虑吗?每天手动刷新页面却总是错过最佳…...

如何让普通PC也能运行macOS?OpCore-Simplify的智能解决方案
如何让普通PC也能运行macOS?OpCore-Simplify的智能解决方案 【免费下载链接】OpCore-Simplify A tool designed to simplify the creation of OpenCore EFI 项目地址: https://gitcode.com/GitHub_Trending/op/OpCore-Simplify 你是否曾经梦想过在自己的Wind…...

Jellyfin Android TV客户端:打造家庭影院的终极大屏解决方案
Jellyfin Android TV客户端:打造家庭影院的终极大屏解决方案 【免费下载链接】jellyfin-androidtv Android TV Client for Jellyfin 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-androidtv Jellyfin Android TV客户端是一款专为智能电视和流媒体设…...

Windows CE嵌入式开发:实时USB设备插拔监控与信息持久化实战
1. 项目概述与核心思路 在嵌入式开发,尤其是涉及数据采集、文件交换或外设管理的项目中,实时感知USB设备的插拔状态是一个高频且关键的需求。想象一下,你正在开发一个工业数据记录仪,需要自动将U盘中的数据导入系统,或…...

MPC Video Renderer:让你的Windows视频播放体验焕然一新的终极指南
MPC Video Renderer:让你的Windows视频播放体验焕然一新的终极指南 【免费下载链接】VideoRenderer Внешний видео-рендерер 项目地址: https://gitcode.com/gh_mirrors/vi/VideoRenderer 还在为Windows系统上的视频播放效果感到失望吗&…...