Redis:原理+项目实战——Redis实战3(Redis缓存最佳实践(问题解析+高级实现))
👨🎓作者简介:一位大四、研0学生,正在努力准备大四暑假的实习
🌌上期文章:Redis:原理+项目实战——Redis实战2(Redis实现短信登录(原理剖析+代码优化))
📚订阅专栏:Redis:原理速成+项目实战
希望文章对你们有所帮助
Redis实现商铺查询缓存
- 什么是缓存
- 给商铺查询功能添加Redis缓存
- 基础业务逻辑
- 缓存作用模型与缓存流程
- 给商品类型添加缓存
- 缓存更新策略
- 主动更新策略
- 更新缓存 or 删除缓存
- 保证缓存与数据库操作同时成功或失败
- 线程安全问题(重要问题)
- 最佳实践方案
- 实现商铺缓存与数据库的双写一致性
- 双写一致性的验证
什么是缓存
缓存:数据交换的缓冲区(Cache),是存储数据的临时地方,读写性能高。
缓存的原理学过计算机组成原理、微机、计算机系统等课程的人都会很熟悉。
我们的浏览器有浏览器缓存,在浏览器未命中数据,就会在tomcat的应用层缓层中取数据,再没有命中的话就去数据库进行查询检索。
缓存的作用:
1、降低后端负载
2、提高读写效率,降低响应时间
缓存的成本:
1、数据的一致性成本
2、代码维护成本(解决一致性问题的时候带来的代码复杂)
3、运维的成本
给商铺查询功能添加Redis缓存
基础业务逻辑
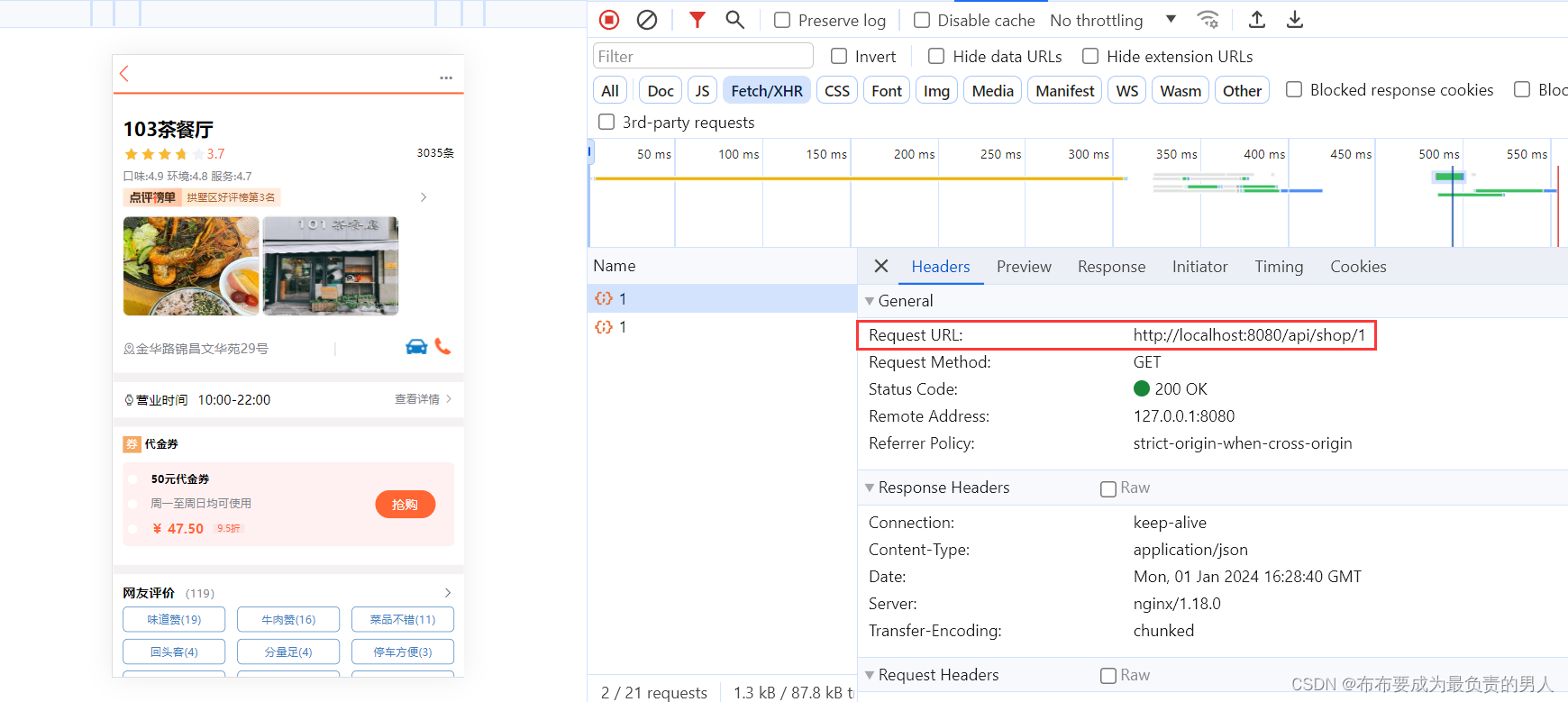
这里的网址就是根据ID查询商户信息的接口,可以看到信息还是很多的:

所以我们要做的事情就是给这个接口添加缓存,从而提高查询的性能。
我们找到查询商户的业务逻辑代码:
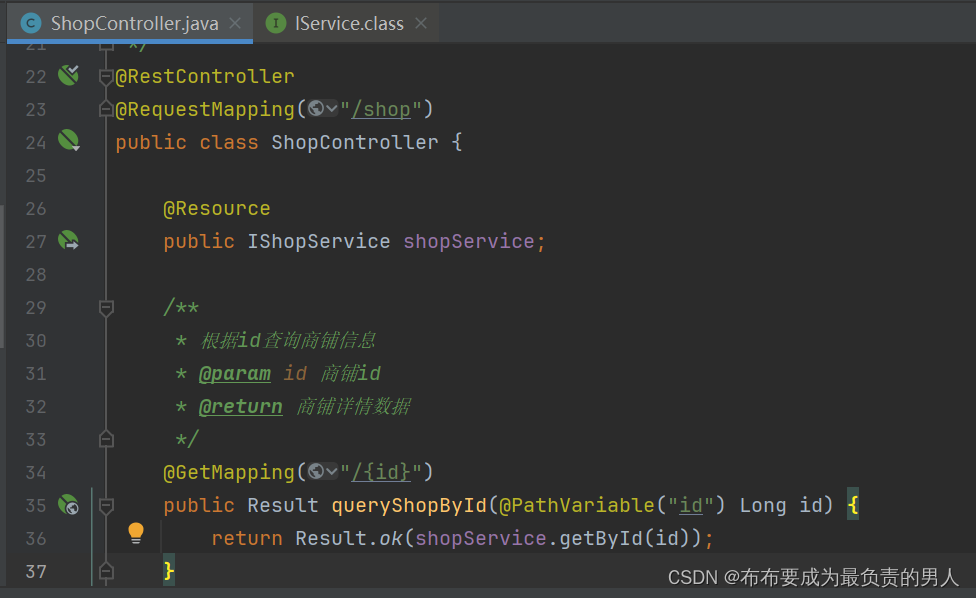

这里直接调用了mybatis-plus提供的接口,直接就能实现数据库的根据id查询的操作,我们就在这里进行Redis缓存的添加。
缓存作用模型与缓存流程
学过计算机系统结构,下面的内容还是很容易看懂的,最简单的缓存作用模型如图所示(当然这个模型实际上是有问题的,学过计算机系统结构的会明白,后续开发会优化这个模型):

知道原理,我们也很容易知道流程该如何进行:
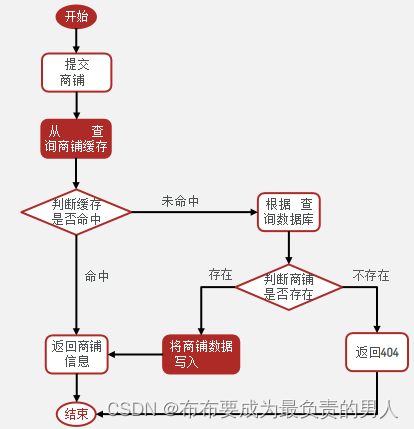
按照这个流程去实现代码,流程比较多我们就不在controller中去写了,直接让controller层中的方法去调用service层中的方法:

然后在service中实现相应的业务:
@Service
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {@Resourceprivate StringRedisTemplate stringRedisTemplate;@Overridepublic Result queryById(Long id) {String key = CACHE_SHOP_KEY + id;//从Redis中查询商铺缓存,存储对象可以用String或者Hash,这里用StringString shopJson = stringRedisTemplate.opsForValue().get(key);//判断是否存在if (StrUtil.isNotBlank(shopJson)) {//存在,直接返回Shop shop = JSONUtil.toBean(shopJson, Shop.class);return Result.ok(shop);}//不存在,根据id查询数据库Shop shop = getById(id);//不存在,返回错误if (shop == null){return Result.fail("店铺不存在");}//存在,写入RedisstringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(shop));//返回return Result.ok(shop);}
}
刷新页面,用了700多ms访问到该页面:
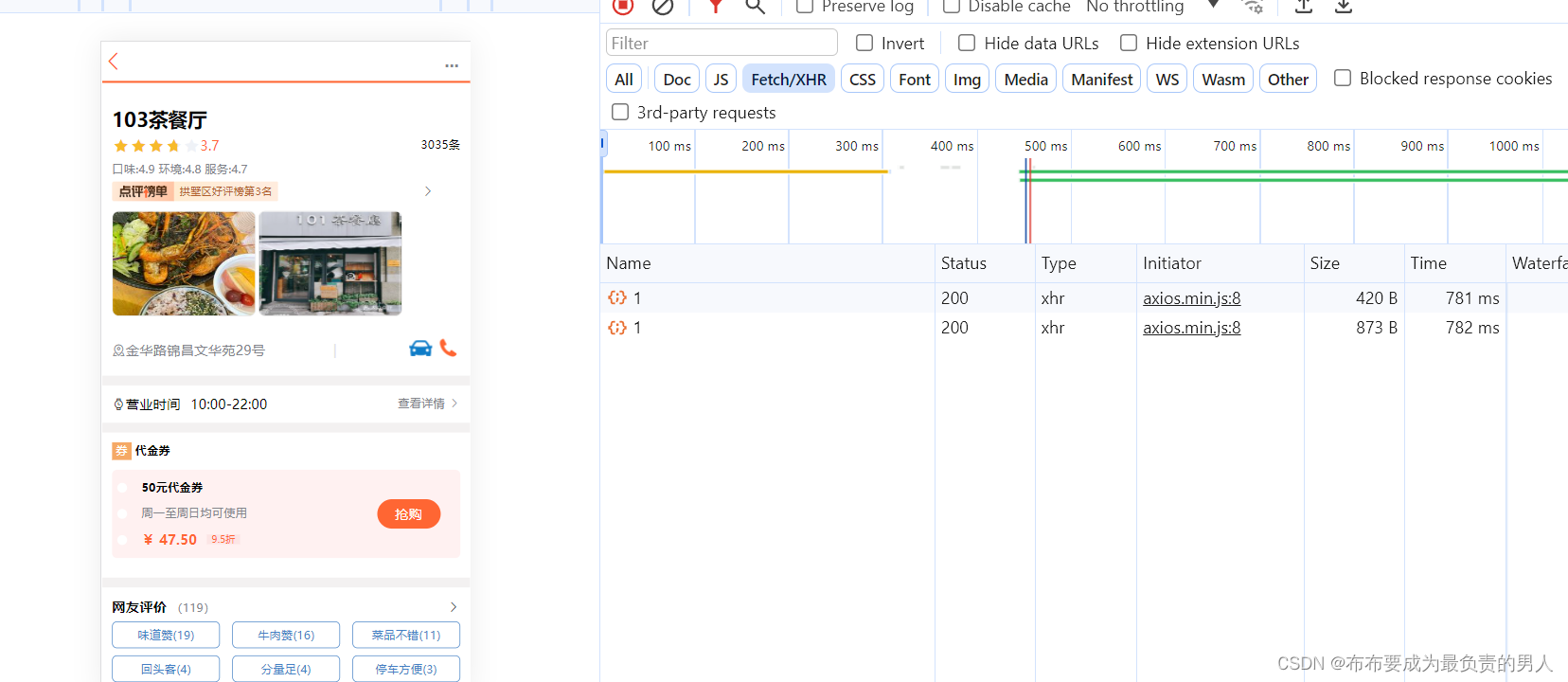
查询Redis数据库,发现成功存储:
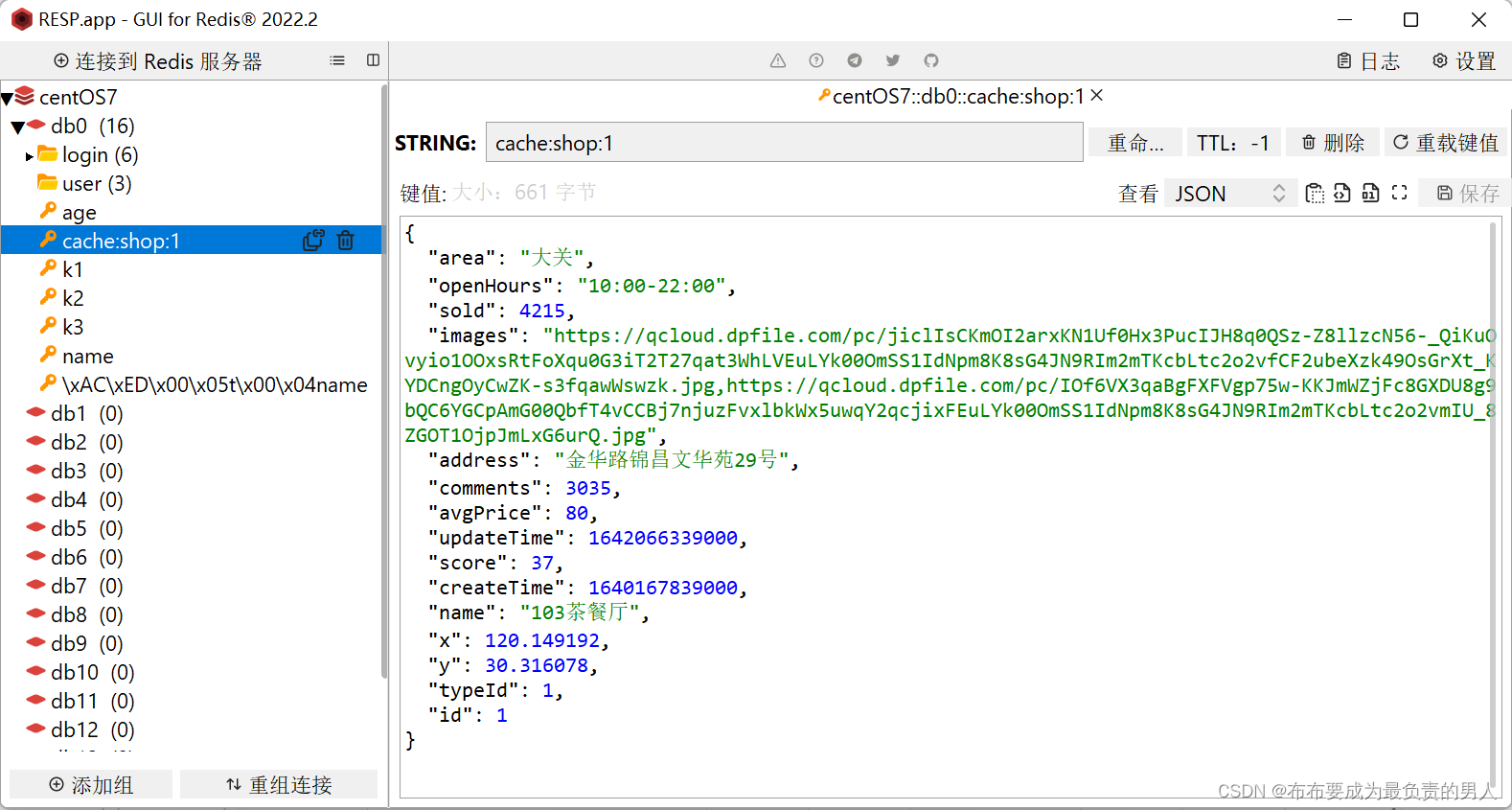
再次刷新页面,可以发现拥有缓存后速度快了很多:
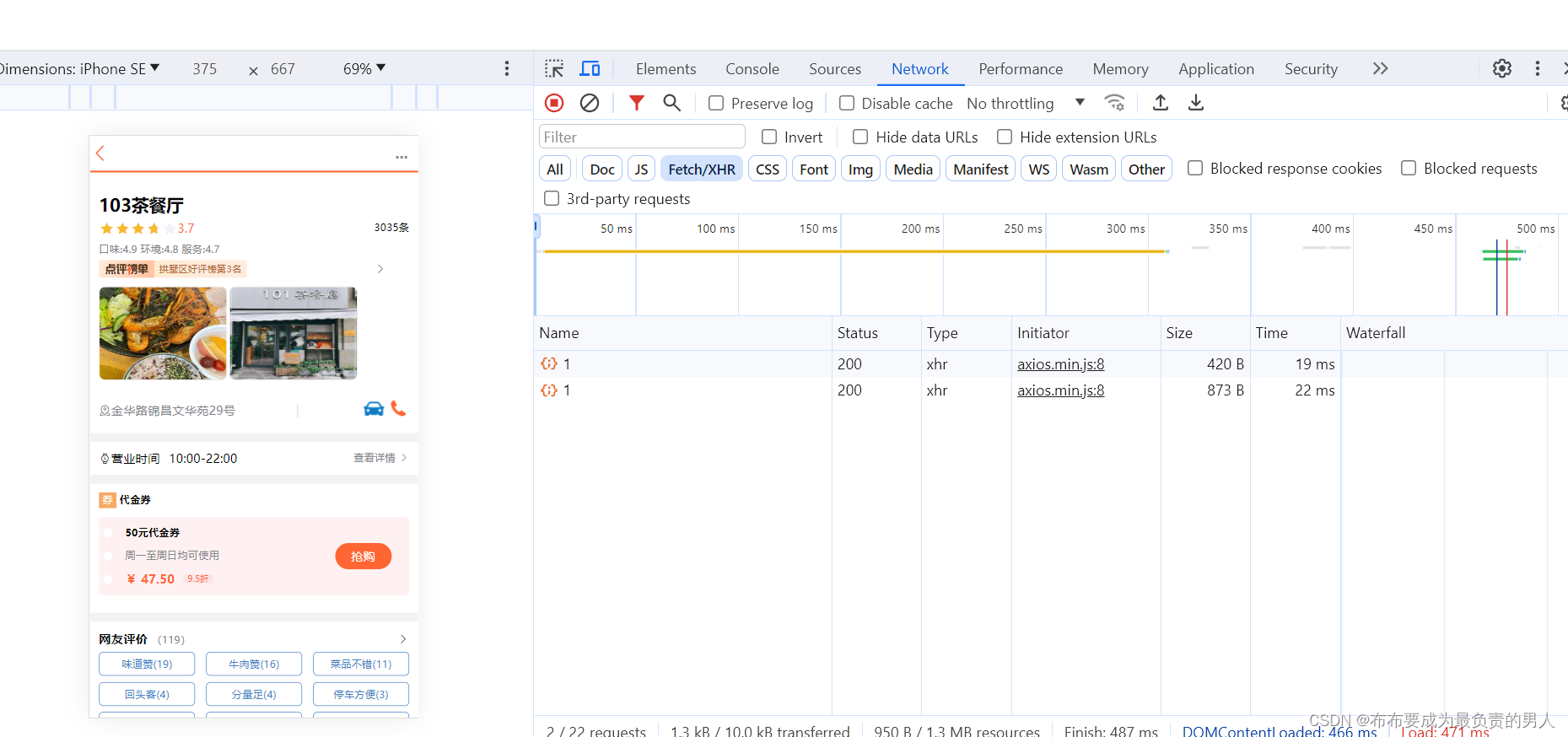
至此,我们已经成功给商户查询增添了Redis缓存。
给商品类型添加缓存
商品类型也就是Shop-List,在很多地方都会用到,比如首页:
这里的controller层代码逻辑:
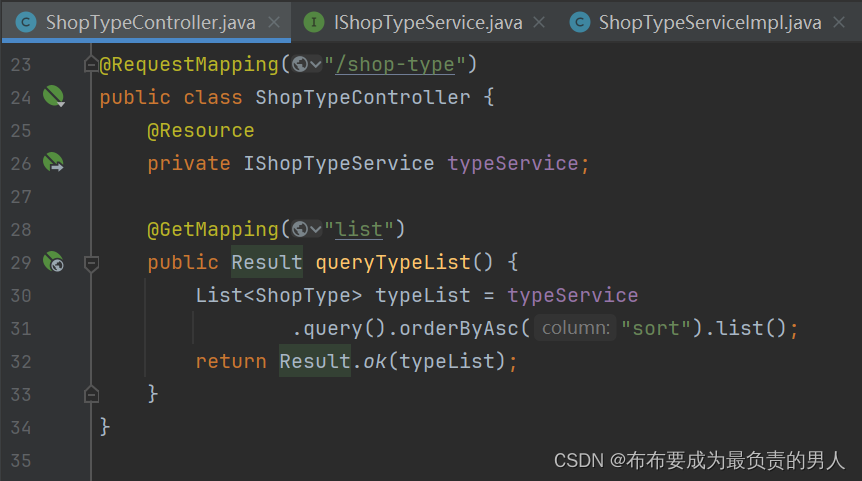
这个代码也是直接使用的mybatis-plus的查询功能,同时对“sort”这个优先级进行排序。
在这里添加Redis缓存,可以使用String也可以使用Hash,因为最终的返回值类型是List的,当然也可以使用List的数据结构。
这里最推荐使用的应该就是Hash了,因为List里面的内容都是对象,Hash是天然适配的。
但在这里我打算使用List来实现,用List实现的话,由于存储到Redis里面的List面向的是String类型的对象,所以我们从Redis取出后、在存入Redis的时候,都需要进行类型的转换。
这里的转换我用了比较高级一点的方式,先把List转换成Stream的形式,然后在map方法中进行转换。
controller层:
@GetMapping("list")public Result queryTypeList() {//List<ShopType> typeList = typeService// .query().orderByAsc("sort").list();//return Result.ok(typeList);if (typeService.queryTypeList() == null){return Result.fail("查询出错");}return Result.ok(typeService.queryTypeList());}
service层:
@Service
public class ShopTypeServiceImpl extends ServiceImpl<ShopTypeMapper, ShopType> implements IShopTypeService {@ResourceStringRedisTemplate stringRedisTemplate;@Overridepublic List<ShopType> queryTypeList() {//查询Redis是否有缓存Long size = stringRedisTemplate.opsForList().size(CACHE_SHOP_TYPE_KEY);//存储到Redis的——存储商品类型的ListList<String> typeList_String;//返还给前端的——存储商品类型的ListList<ShopType> typeList;//Redis里有数据,就转换成对象类型后直接返回数据if (size != 0){//CACHE_SHOP_TYPE_KEY="cache:shopType"typeList_String = stringRedisTemplate.opsForList().range(CACHE_SHOP_TYPE_KEY, 0, size);//将每个String都转换回ShopType类typeList = typeList_String.stream().map(s->{ShopType shopType = JSONUtil.toBean(s, ShopType.class);return shopType;}).collect(Collectors.toList());return typeList;}//Redis里面没有数据,就查询数据库typeList = this.query().orderByAsc("sort").list();if (typeList == null || typeList.isEmpty()){//数据库中不存在,返回nullreturn null;}//数据库里面有,就存入Redis缓存,并返回这个ListtypeList_String = typeList.stream().map(shopType -> {return JSONUtil.toJsonStr(shopType);}).collect(Collectors.toList());//存入Redis,注意插入的方式stringRedisTemplate.opsForList().rightPushAll(CACHE_SHOP_TYPE_KEY, typeList_String);//返回return typeList;}
}
刷新页面,响应时间接近600ms:
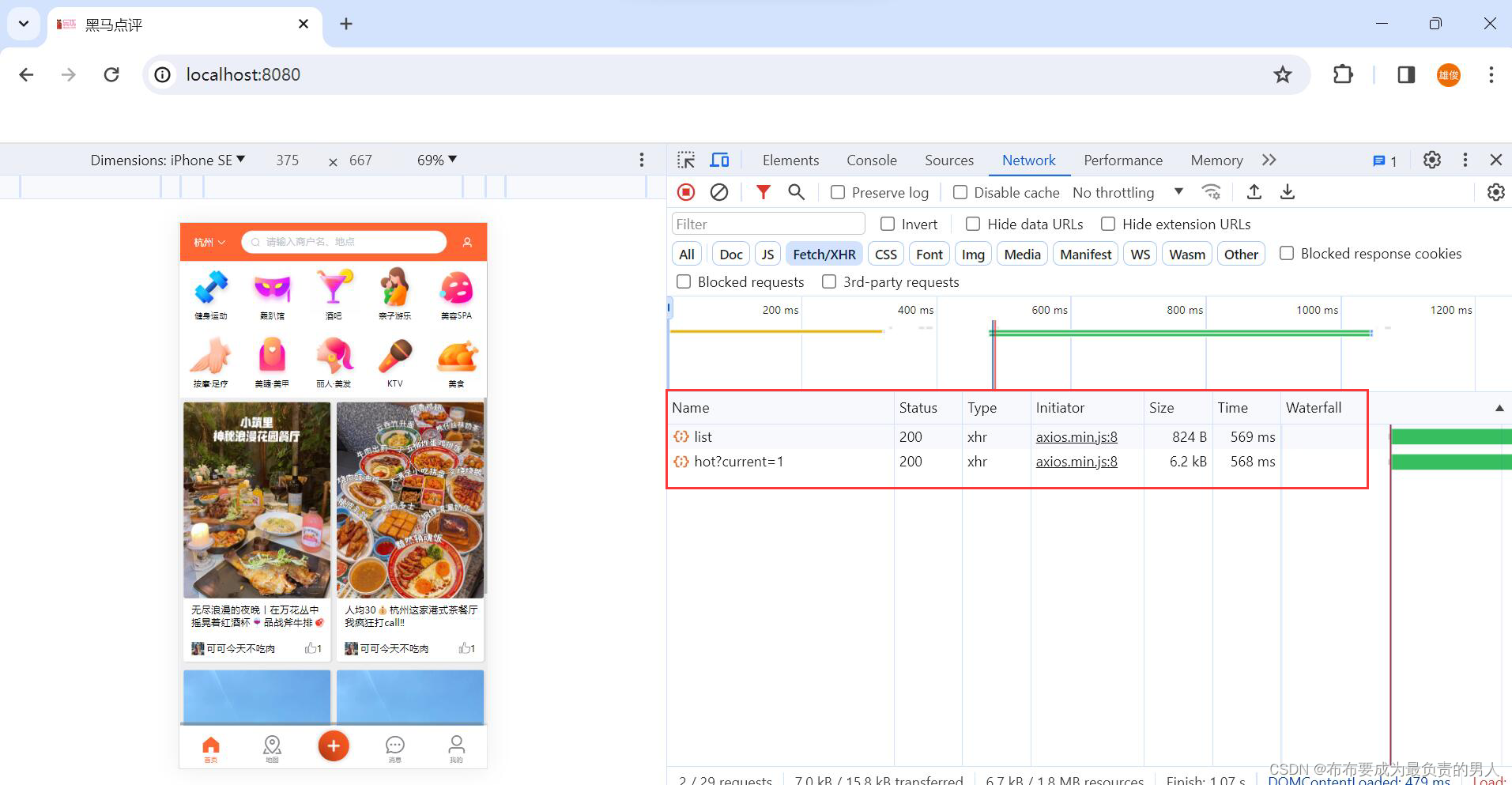
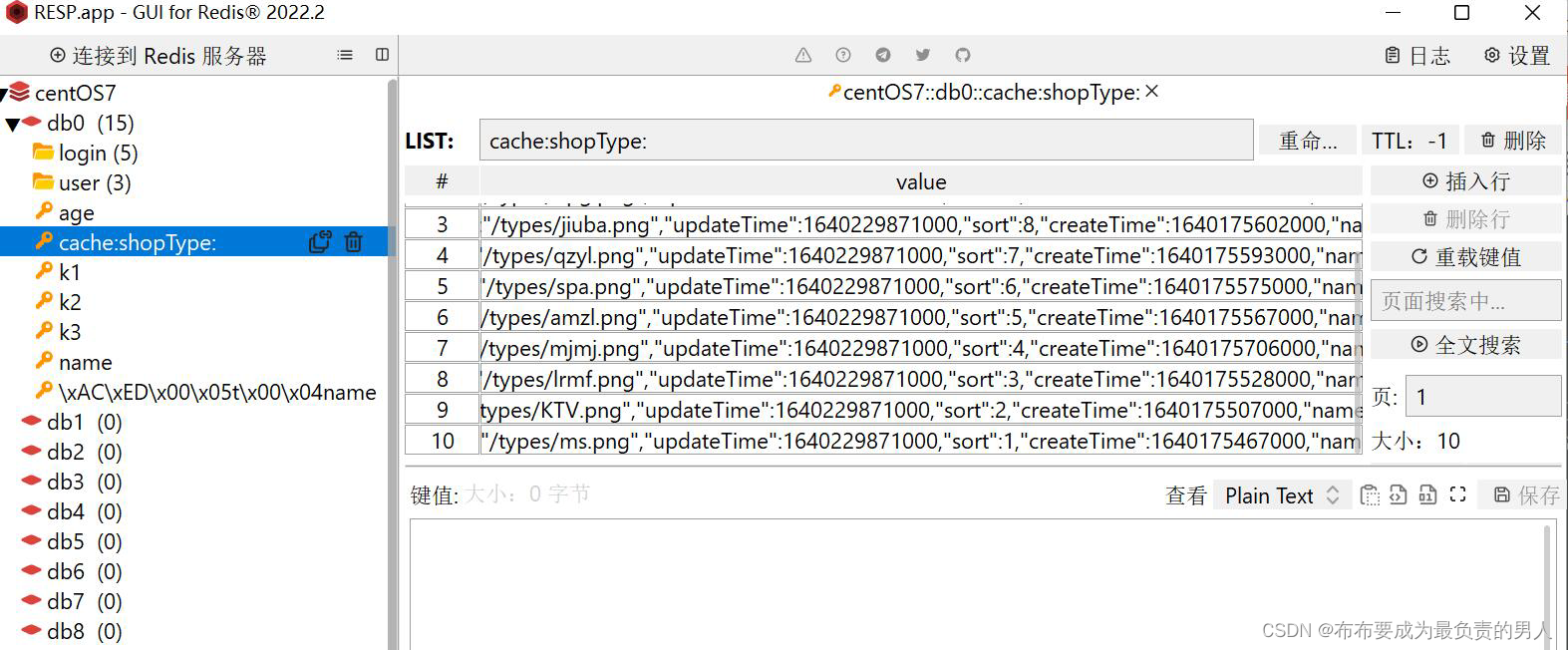
查看Redis,已经成功存储,且是按照sort来排序的:
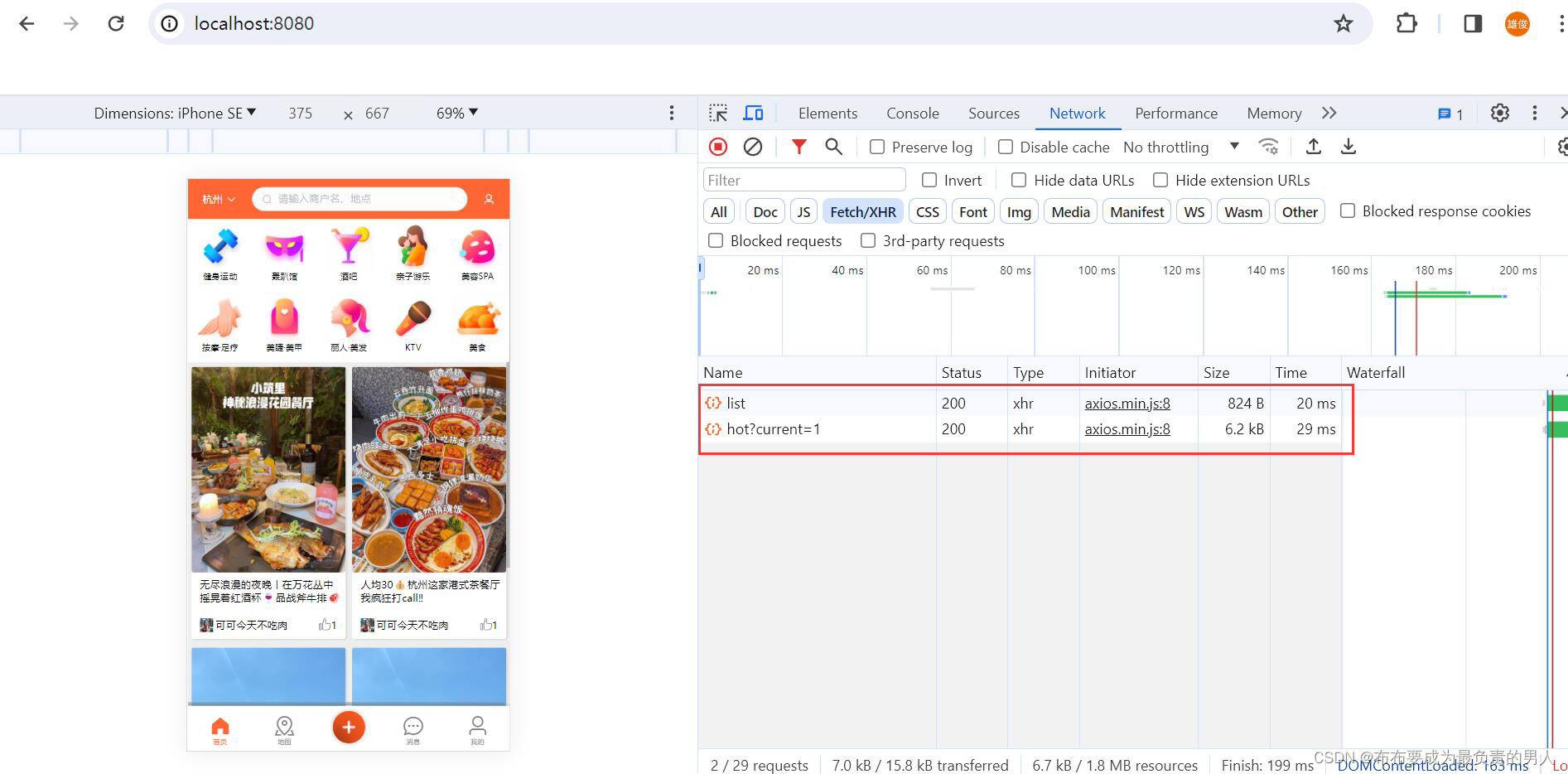
再次刷新,响应只花了20多ms:
缓存更新策略
学过计算机系统结构的同学应该知道,上面的作用模型可能会造成数据一致性问题,当我们对数据库进行修改的时候,缓存并没有同步进行修改,然后我们的页面在缓存中获取数据的时候,其实并不是最新的数据。这肯定是不允许的。
下面是缓存更新策略:
| 内存淘汰 | 超时剔除 | 主动更新 | |
|---|---|---|---|
| 说明 | 不用自己维护,利用Redis的内存淘汰机制,内存不足时自动淘汰部分数据,下次查询时更新缓存 | 给缓存数据添加TTL时间,到期后自动删除缓存。下次查询即可实现缓存的更新 | 自己编写业务逻辑,在修改数据库的同时,更新缓存 |
| 一致性 | 差 | 一般 | 好 |
| 维护成本 | 无 | 低 | 高 |
上述的策略选择要根据具体的业务场景:
1、低一致性需求:使用内存淘汰机制。例如店铺类型的查询缓存。
2、高一致性需求:主动更新,以超时剔除作兜底方案。例如店铺详情查询的缓存。
主动更新策略
1、Cache Aside Pattern(最常用)
由缓存的调用者在更新数据库同时更新缓存
2、Read/Write Through Pattern
缓存与数据库整合为一个服务,由服务来维护一致性。调用者调用该服务无需关注一致性问题。但这种服务的成本肯定是很高的。
3、Write Behind Caching Pattern
调用者只操作缓存,由其它线程异步的将缓存数据持久化到数据库,保证最终一致。
比如我们一直对缓存进行更新,更新10次以后轮到这个线程工作,就维护一下数据库的数据为更新10次后的数据,中途的其他9次更新操作根本不重要,这样的性能显然是很高的。
这种方式当然也有很大问题,比如长期的数据不一致、缓存宕机造成的严重后果等。
之后的更新策略我们将会用第一种方式,操作缓存和数据库时有三个问题考虑:
更新缓存 or 删除缓存
更新缓存:每次更新数据库都更新缓存,中途无效写操作太多了
删除缓存:更新数据库时让缓存失效,查询时更新缓存
因此,我们会选择删除缓存
保证缓存与数据库操作同时成功或失败
单体系统:将缓存和数据库操作放到一个事务
分布式系统:利用TCC等分布式事务方案
总之我们要确保数据库与缓存操作的原子性
线程安全问题(重要问题)
我们到底要先删除缓存再操作数据库,还是先操作数据库再删除缓存呢?其实这两种方案都是会遇到问题的,我们可以先分析一下。
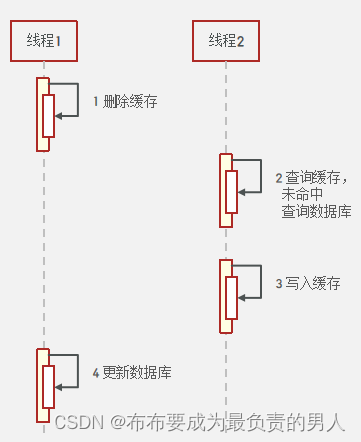
1、先删除缓存再操作数据库:
(1)正常情况
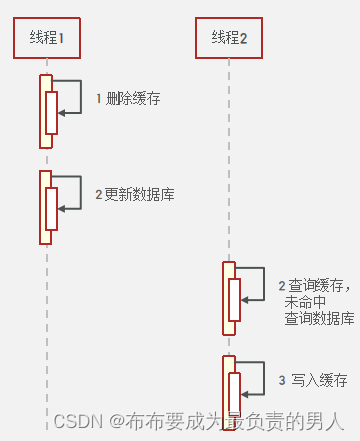
(2)异常情况
线程1工作的时候,线程2可能也要进行操作,就可能会造成数据不一致:
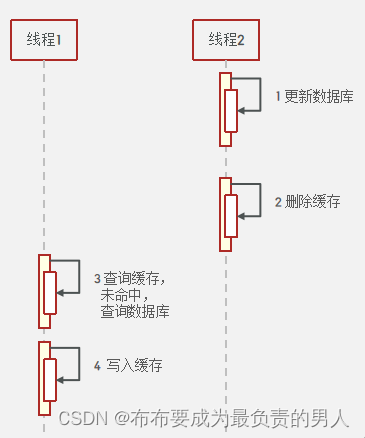
2、先操作数据库再删除缓存
(1)正常情况
(2)异常情况
查询缓存未命中,在查询数据库的过程中,数据库更新了,这时候也会造成数据不一致:
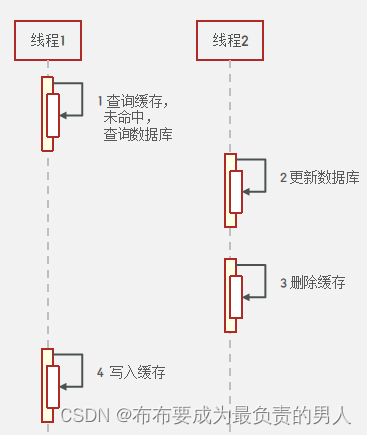
显然,第二种的异常条件是在查询数据库的过程中发生的不一致,相对是更难发生的,因此我们会选择先操作数据库,再删除缓存。
最佳实践方案
1、低一致性:使用Redis自带的内存淘汰机制
2、高一致性:主动更新,并以超时剔除作为兜底方案
(1)读操作:
①缓存命中直接返回
②缓存未命中则查询数据库,并写入缓存,设定超时时间(这是一个兜底,万一不一致,超时就剔除)
(2)写操作:
①先写数据库,再删除缓存
②确保数据库与缓存操作的原子性
实现商铺缓存与数据库的双写一致性
通过上面的讨论,现在我们要给查询商铺的缓存添加主动更新和超时剔除策略。
修改ShopController的业务逻辑满足:
(1)根据id查询店铺,没命中就查数据库,然后写入缓存,并设置超时时间
(2)根据id修改店铺,先操作数据库,再删除缓存
controller层:
@PutMappingpublic Result updateShop(@RequestBody Shop shop) {// 写入数据库//shopService.updateById(shop);return shopService.update(shop);}
service层:
1、在queryById函数的写入Redis环节加上时间限定:

2、根据id更新商铺逻辑:
@Override@Transactional //如果操作中有异常,我们用该注解实现事务回滚public Result update(Shop shop) {//我们要首先对id进行判断Long id = shop.getId();if (id == null) {return Result.fail("店铺id不能为空");}//更新数据库updateById(shop);//删除缓存 这里用了单事务,将删除缓存与更新数据库放在了一个事务里面stringRedisTemplate.delete(CACHE_SHOP_KEY + id);return Result.ok();}
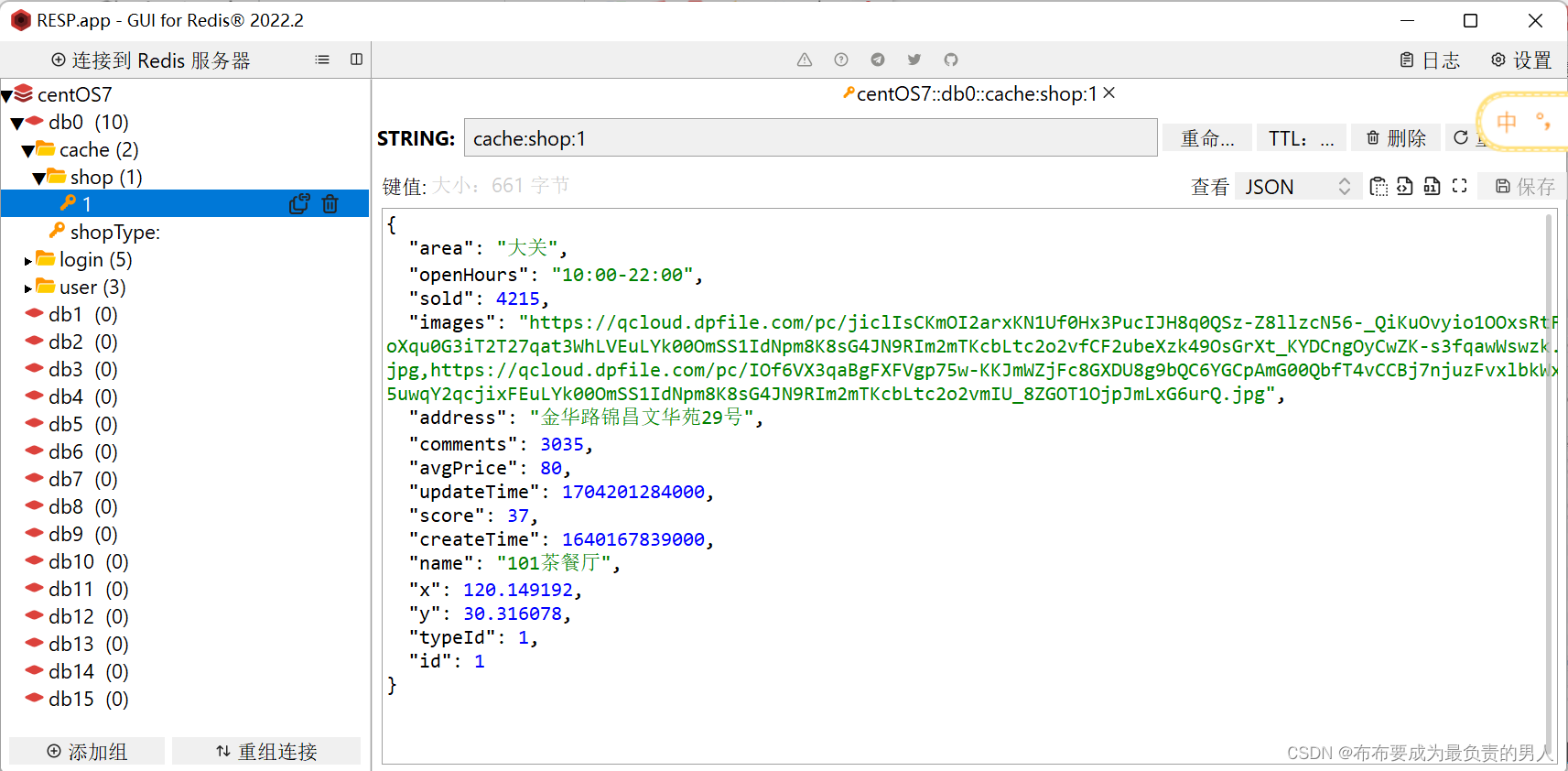
我们现在可以进行验证,首先进行查询的验证,当我们打开商铺页面以后,后端会进行数据库查询操作,接着我们打开Redis可以发现:
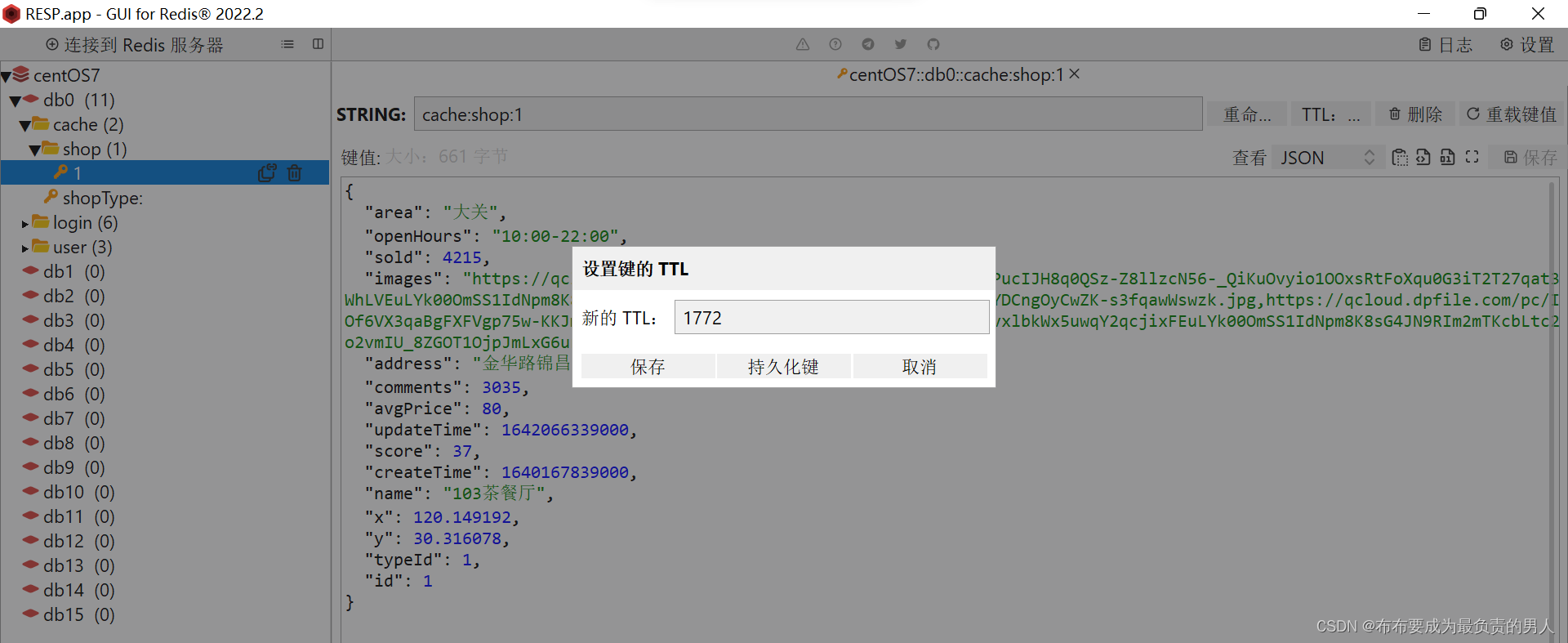
说明查询完毕了之后又写到了Redis,并且可以看到时限。
双写一致性的验证
对于修改店铺的验证,这种修改并不是使用前端的用户能进行的,因此我们需要Postman工具。
网页目前是103餐厅:

2、我们在postman中修改餐厅的名称,并点击send:
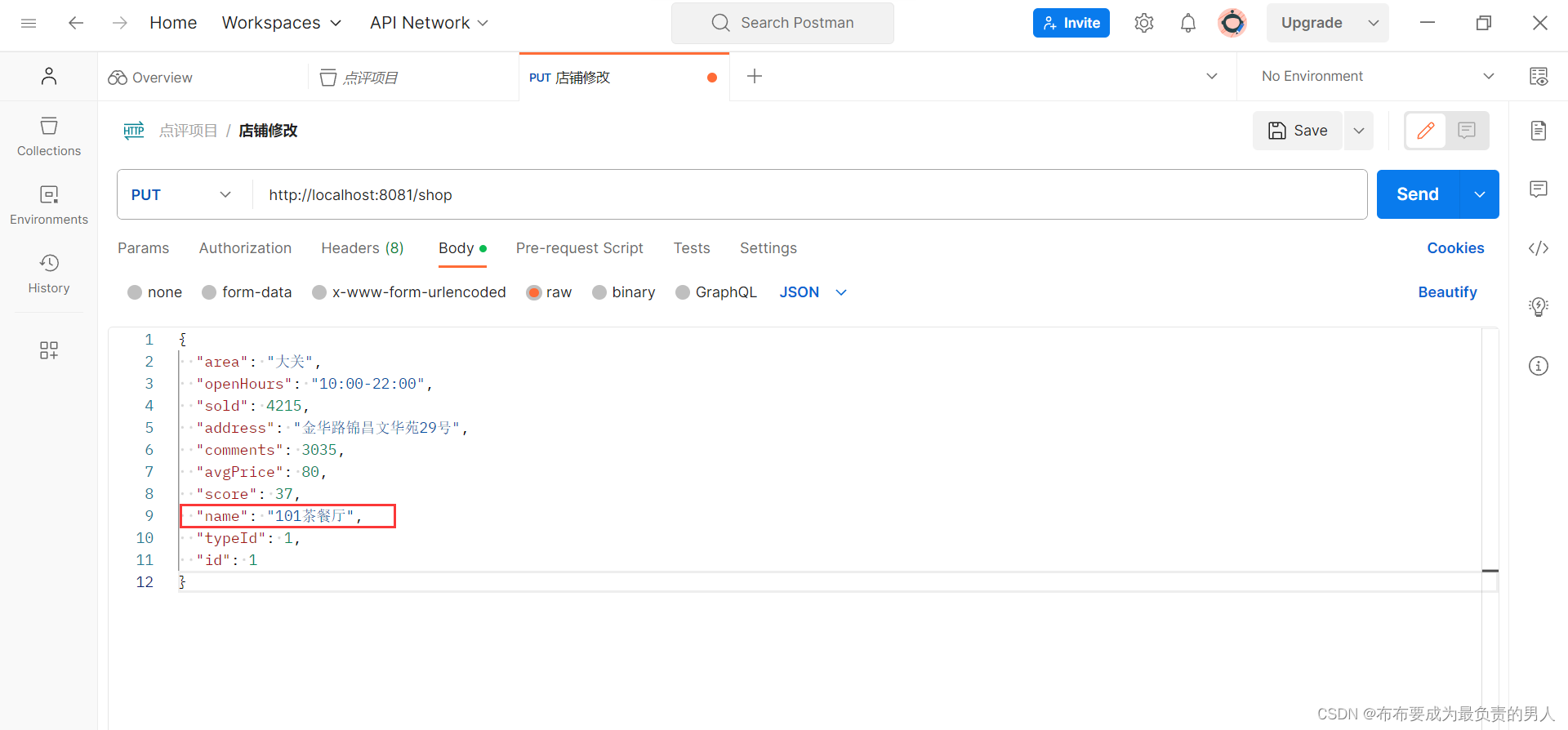
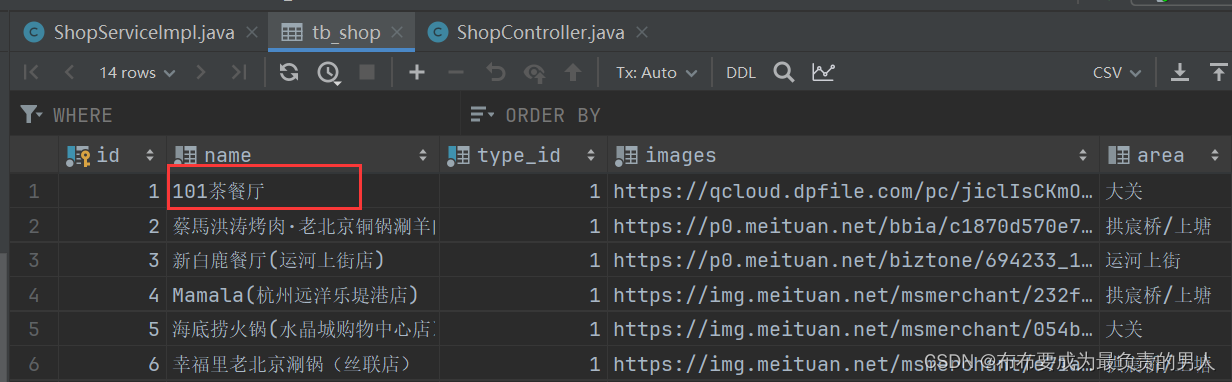
3、查询数据库是否成功修改:
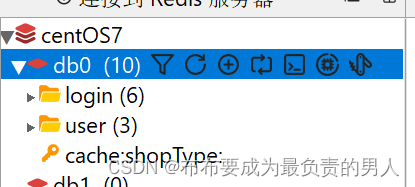
4、刷新一下Redis,可以发现已经没有了,说明成功进行了缓存删除:
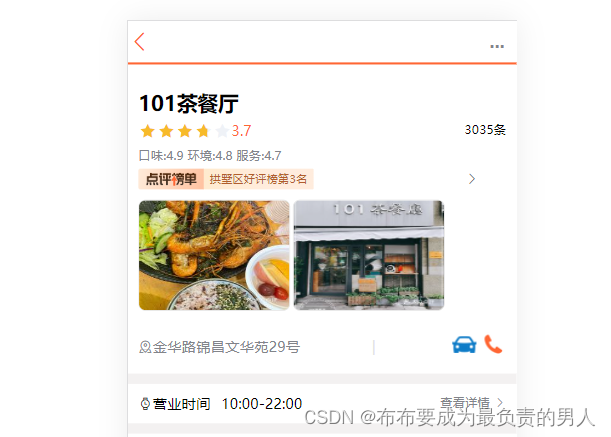
5、这时候去刷新浏览器,可以发现查询无误,说明确实是在缓存查询不到之后查询了数据库:
6、再次打开Redis,可以看见,查询完数据库以后,数据写回了Redis:
自此,流程完全调通!
上述是一些比较基础的内容和最佳实践,但是企业在使用Redis的时候,还会遇到其它难点和热点如缓存穿透、缓存雪崩、缓存击穿,在后续会慢慢解决这些问题。
相关文章:
Redis:原理+项目实战——Redis实战3(Redis缓存最佳实践(问题解析+高级实现))
👨🎓作者简介:一位大四、研0学生,正在努力准备大四暑假的实习 🌌上期文章:Redis:原理项目实战——Redis实战2(Redis实现短信登录(原理剖析代码优化)&#x…...

刚刚,Stable Diffusion 2024升级,最强Ai绘画整合包、部署教程(解压即用)
2024Ai技术大爆发的元年 目前两款Ai神器大火 一款是大名鼎鼎的Chat GPT 另外一款—Stable Diffusion 堪称全球最强Ai绘画工具 Stable Diffusion Ai绘画2024版本更新啦! 从4.8.7更新至**4.9版本!**更新优化和大模型增加,无需安装…...

【AIGC】ChatGPT提示词助力高效文献处理、公文撰写、会议纪要与视频总结
博客主页: [小ᶻZ࿆] 本文专栏: AIGC | ChatGPT 文章目录 💯前言💯高效英文文献阅读提示词使用方法 💯高效公文写作提示词使用方法 💯高效会议纪要提示词使用方法 💯高效视频内容分析提示词使用方法 &a…...

centos7更换国内下载源
📖centos7更换国内下载源 在CentOS 7上更换为国内源可以通过替换 /etc/yum.repos.d/CentOS-Base.repo文件来实现。以下是一些常用的国内源以及如何更换的示例: 阿里云源: mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Bas…...

【Linux】常用指令【更详细,带实操】
Linux全套讲解系列,参考视频-B站韩顺平,本文的讲解更为详细 目录 一、文件目录指令 1、cd【change directory】指令 2、mkdir【make dir..】指令 3、cp【copy】指令 4、rm【remove】指令 5、mv【move】指令 6、cat指令和more指令 7、less和…...

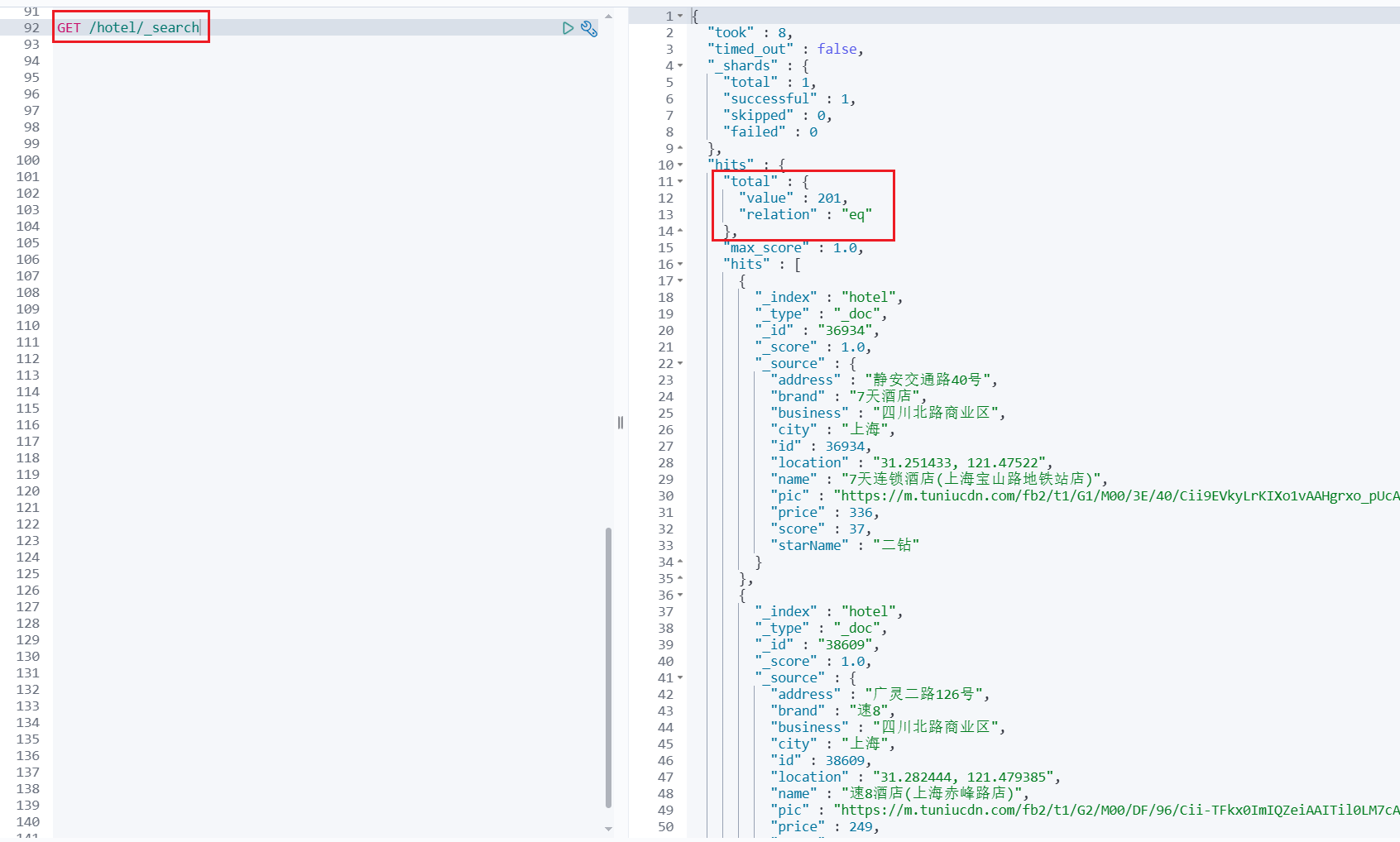
力扣3290.最高乘法得分
力扣3290.最高乘法得分 递归 记忆化搜索 对于b数组,从右往左考虑取不取,如果取则问题变成b[0] ~ b[i-1]间找j - 1个数 如果不取,则问题变成b[0] ~ b[i]间找j个数即dfs(i,j) max(dfs(i-1,j) , dfs(i-1,j-1) a[j] * b[i]) 边界:…...

Python | Leetcode Python题解之第413题等差数列划分
题目: 题解: class Solution:def numberOfArithmeticSlices(self, nums: List[int]) -> int:n len(nums)if n 1:return 0d, t nums[0] - nums[1], 0ans 0# 因为等差数列的长度至少为 3,所以可以从 i2 开始枚举for i in range(2, n):i…...

深入理解 ClickHouse 的性能调优与最佳实践
1. 介绍 ClickHouse 是一款由 Yandex 开发的开源列式数据库,专为在线分析处理(OLAP)场景设计。它以极高的查询性能著称,尤其适用于大规模数据的快速聚合和分析。自发布以来,ClickHouse 在多个行业中得到了广泛应用&am…...
Elasticsearch——介绍、安装与初步使用
目录 1.初识 Elasticsearch1.1.了解 ES1.1.1.Elasticsearch 的作用1.1.2.ELK技术栈1.1.3.Elasticsearch 和 Lucene1.1.4.为什么不是其他搜索技术?1.1.5.总结 1.2.倒排索引1.2.1.正向索引1.2.2.倒排索引1.2.3.正向和倒排 1.3.Elasticsearch 的一些概念1.3.1.文档和字…...
—任务创建和任务控制API说明)
FreeRTOS保姆级教程(以STM32为例)—任务创建和任务控制API说明
目录 一、任务创建: (1)TaskHandle_t 任务句柄 (2) xTaskCreate: 函数原型: 参数说明: 返回值: 示例: 注意事项: 用法示例:…...

Go语言现代web开发14 协程和管道
概述 Concurrency is a paradigm where different parts of the program can be executed in parallel without impact on the final result. Go programming supports several concurrency concepts related to concurrent execution and communication between concurrent e…...

Llama3.1的部署与使用
✨ Blog’s 主页: 白乐天_ξ( ✿>◡❛) 🌈 个人Motto:他强任他强,清风拂山冈! 💫 欢迎来到我的学习笔记! 什么是Llama3.1? Llama3.1 是 Meta(原 Facebook)公…...

Java/Spring项目的包开头为什么是com?
Java/Spring项目的包开头为什么是com? 下面是一个使用Maven构建的项目初始结构 src/main/java/ --> Java 源代码com.example/ --->为什么这里是com开头resources/ --> 资源文件 (配置、静态文件等)test/java/ --> 测试代码resourc…...

深度学习自编码器 - 随机编码器和解码器篇
序言 在深度学习领域,自编码器作为一种无监督学习技术,凭借其强大的特征表示能力,在数据压缩、去噪、异常检测及生成模型等多个方面展现出独特魅力。其中,随机编码器和解码器作为自编码器的一种创新形式,进一步拓宽了…...

Spring IoC DI
Spring 框架的核心是其控制反转(IoC,Inversion of Control)和依赖注入(DI,Dependency Injection)机制。这些概念是为了提高代码的模块化和灵活性,进而简化开发和测试过程。下面将详细介绍这两个…...
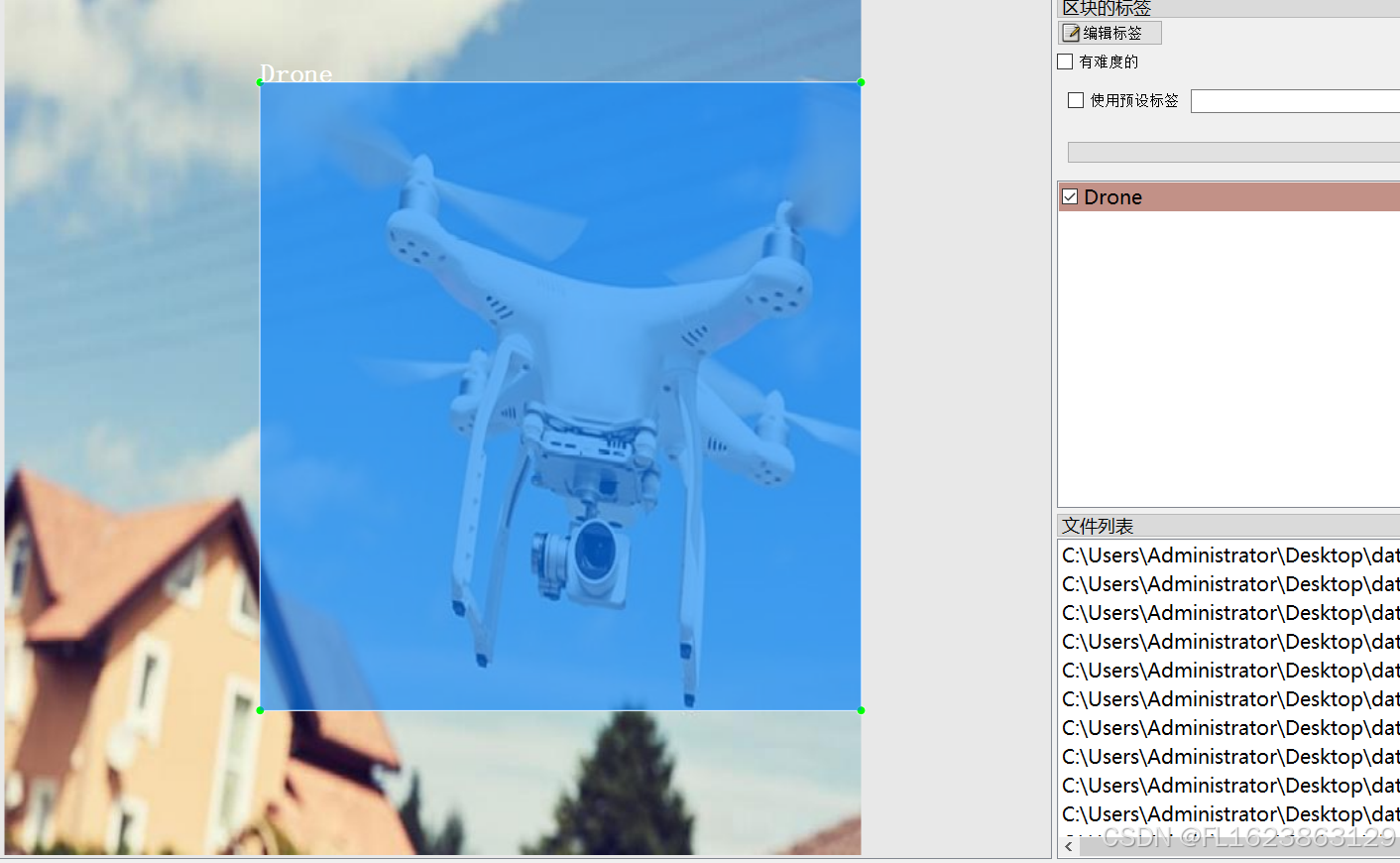
[数据集][目标检测]无人机飞鸟检测数据集VOC+YOLO格式6647张2类别
数据集格式:Pascal VOC格式YOLO格式(不包含分割路径的txt文件,仅仅包含jpg图片以及对应的VOC格式xml文件和yolo格式txt文件) 图片数量(jpg文件个数):6647 标注数量(xml文件个数):6647 标注数量(txt文件个数):6647 标注…...

Vue 中 watch 的使用方法及注意事项
前言 Vue 的 Watch 是一个非常有用的功能,它能够监听 Vue 实例数据的变化并执行相应的操作。本篇文章将详细介绍 Vue Watch 的使用方法和注意事项,让你能够充分利用 Watch 来解决 Vue 开发中的各种问题。 1. Watch 是什么? 1.1 Watch 的作…...
情指行一体化平台建设方案和必要性-———未来之窗行业应用跨平台架构
一、平台建设必要性 以下是情指行一体化平台搭建的一些必要性: 1. 提高响应速度 - 实现情报、指挥和行动的快速协同,大大缩短从信息获取到决策执行的时间,提高对紧急情况和突发事件的响应效率。 2. 优化资源配置 - 整合各类资源信…...

窗口框架frame(HTML前端)
一.窗口框架 作用:将网页分割为多个HTML页面,即将窗口分为多个小窗口,每个小窗口可以显示不同的页面,但是在浏览器中是一个完整的页面 基本语法 <frameset cols"" row""></frameset><frame…...
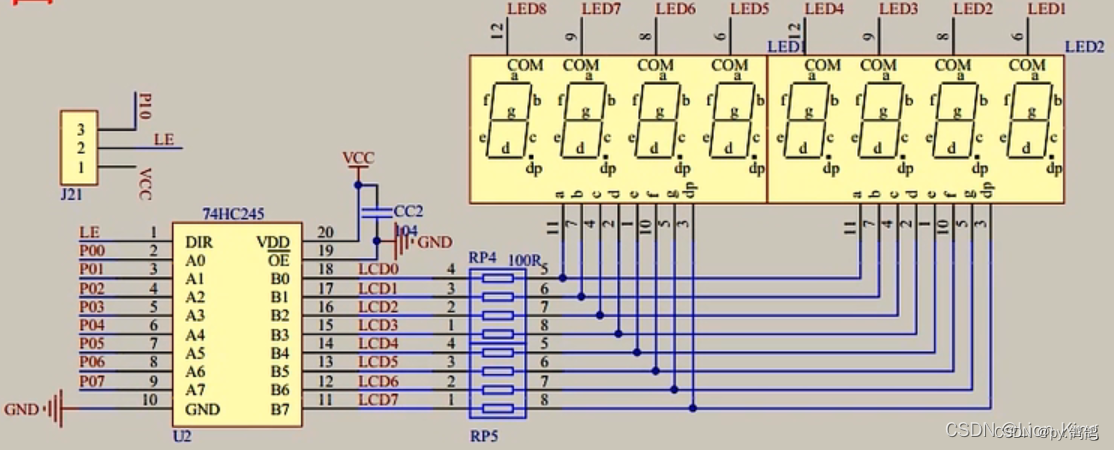
51单片机——数码管
一、数码管原理图 我们发现,总共有8个数码管。 它们的上面接8个LED,用来控制选择哪个数码管。例如要控制第三个数码管,就让LED6为0,其他为1,那LED又接到哪呢? 二、LED 由图可以看出,这个一个1…...

Windows 11系统优化终极指南:用Win11Debloat免费让你的电脑飞起来
Windows 11系统优化终极指南:用Win11Debloat免费让你的电脑飞起来 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declu…...

终极macOS Windows启动盘制作工具:WinDiskWriter完整指南
终极macOS Windows启动盘制作工具:WinDiskWriter完整指南 【免费下载链接】windiskwriter 🖥 Windows Bootable USB creator for macOS. 🛠 Patches Windows 11 to bypass TPM and Secure Boot requirements. 👾 UEFI & Legac…...

Co-IP/MS:蛋白免疫共沉淀质谱分析服务
免疫共沉淀质谱法(Co-IP/MS)是一种由免疫共沉淀技术联用质谱技术的蛋白互作研究技术,具备高分辨率鉴定和精确定量蛋白质复合物中每个组分的优势。Co-IP/MS使用靶向目标蛋白的特异性抗体,选择性地捕获目标蛋白质与其相互作用的分子…...

为什么你的Jellyfin需要MaxSubtitle:5分钟实现智能字幕匹配的终极指南
为什么你的Jellyfin需要MaxSubtitle:5分钟实现智能字幕匹配的终极指南 【免费下载链接】jellyfin-plugin-maxsubtitle 一个 Jellyfin 中文字幕插件(未来可以不局限中文) 项目地址: https://gitcode.com/gh_mirrors/je/jellyfin-plugin-maxs…...

N_m3u8DL-RE终极指南:如何高效下载加密流媒体视频
N_m3u8DL-RE终极指南:如何高效下载加密流媒体视频 【免费下载链接】N_m3u8DL-RE Cross-Platform, modern and powerful stream downloader for MPD/M3U8/ISM. English/简体中文/繁體中文. 项目地址: https://gitcode.com/GitHub_Trending/nm3/N_m3u8DL-RE 还…...

KVM网络配置踩坑记:从virt-install的`--network`参数到virsh管理虚拟网桥
KVM网络配置实战:从virt-install到virsh的深度解析 当你在本地环境搭建KVM虚拟机时,网络配置往往是第一个拦路虎。不同于物理机插上网线就能用的简单体验,虚拟化环境中的网络需要经过多层抽象和配置才能正常工作。本文将带你深入KVM网络配置的…...
)
告别实车测试!手把手教你用Vector VT平台搭建OBC/DCDC的HIL测试环境(附避坑指南)
新能源汽车OBC/DCDC控制器HIL测试环境搭建实战指南 在新能源汽车三电系统开发中,车载充电机(OBC)和DC/DC变换器的功能验证一直是工程师面临的挑战。传统实车测试不仅成本高昂,而且难以覆盖所有边界条件。硬件在环(HIL)测试技术通过将真实控制器接入虚拟车…...

PG数据库空间查询添加空间索引后提速10倍
以下语句直接在Navicat软件中链接PG数据库后实现 添加空间索引之前查询第一次要10几秒,添加空间索引之后不到1秒 -- 创建支持 UTM 32650 投影查询的空间索引 CREATE INDEX idx_fjdmdz_geom_32650 ON tablename USING GIST (ST_Transform(geom, 32650));SELECT * FROM tabl…...
一键Root)
保姆级教程:红米K70澎湃OS解锁BL后,如何用Delta面具(德尔塔面具)一键Root
红米K70澎湃OS深度Root指南:Delta面具全流程实战解析 在安卓玩机圈里,Root始终是释放设备潜力的终极钥匙。对于手持红米K70并已解锁Bootloader的进阶用户而言,Delta面具(Magisk Delta)无疑是当前最安全、最稳定的Root解…...

phpenv终极指南:5分钟掌握PHP多版本管理的完整解决方案
phpenv终极指南:5分钟掌握PHP多版本管理的完整解决方案 【免费下载链接】phpenv Simple PHP version management 项目地址: https://gitcode.com/gh_mirrors/ph/phpenv 还在为不同PHP项目间的版本冲突而烦恼吗?phpenv为您提供了一站式PHP版本管理…...