学习大数据DAY59 全量抽取和增量抽取实战
目录
需求流程:
需求分析与规范
作业
作业2
需求流程:
需求分析与规范
作业
#!/bin/python3
import pymysql
import sys
# 自动写 datax 的 json 文件
if len(sys.argv)!=3:
print("使用方法为:python3 full.py 数据库名 表名")
sys.exit()
sys_name=sys.argv[1]
table_name=sys.argv[2]
# datax_json=f"{sys_name}.{table_name}_full.json"
db=pymysql.connect(
host='zhiyun.pub',
port=23306,
user='zhiyun',
password='zhiyun',
database='information_schema'
)
cursor=db.cursor()
cursor.execute(f"select column_name,data_type from
information_schema.columns where table_schema='{sys_name}' and
table_name='{table_name}'")
data=cursor.fetchall()
fileds=[]for field in data:
field_name = field[0]
field_type = field[1]
#转换成 hive 类型
field_hive_type="string"
if field_type=="int" or field_type=="tinyint" or
field_type=="bigint":
field_hive_type="int"
if field_type=="float" or field_type=="double":
field_hive_type="float"
fileds.append([field_name,field_hive_type])
db.close()
print("=============== 配置 datax ===============")
file_path=f"/zhiyun/shihaihong/jobs/{sys_name}_{table_name}_fu
ll.json"
template_path="/zhiyun/shihaihong/jobs/template.json"
with open(template_path,"r",encoding="utf-8") as f:
template_content=f.read()
new_content=template_content.replace("#sys_name#",sys_name)
new_content=new_content.replace("#table_name#",table_name)
#列的替换
lines=[]
for filed in fileds:
line='
{"name":"'+filed[0]+'
","type":"'+filed[1]+'"},'
lines.append(line)
columns="\n".join(lines)
columns=columns.strip(",")
new_content=new_content.replace("\"#columns#\"",columns)
#写入到新的配置
with open(file_path,"w",encoding="utf-8") as ff:
ff.write(new_content)
ff.close()
f.close()
print("datax 文件配置成功")
print("=============== 配置 hive ===============")file_path=f"/zhiyun/shihaihong/sql/{sys_name}_{table_name}_ful
l.sql"
template_path="/zhiyun/shihaihong/sql/template.sql"
with open(template_path,"r",encoding="utf-8") as f:
template_content=f.read()
new_content=template_content.replace("#sys_name#",sys_name)
new_content=new_content.replace("#table_name#",table_name)
#列的替换
lines=[]
for filed in fileds:
line=f"
{filed[0]} {filed[1]},"
lines.append(line)
columns="\n".join(lines)
columns=columns.strip(",")
new_content=new_content.replace("#columns#",columns)
#写入到新的配置
with open(file_path,"w",encoding="utf-8") as ff:
ff.write(new_content)
ff.close()
print("hive 建表文件生成成功")json 模板:
template.json:
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": ["jdbc:mysql://zhiyun.pub:233
06/crm?useSSL=false"
],
"table": [
"#table_name#"
]
}
],
"password": "zhiyun",
"username": "zhiyun"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
"#column#"
],
"defaultFS": "hdfs://cdh02:8020",
"fieldDelimiter": "\t",
"fileName":
"#sys_name#_#table_name#_full.data",
"fileType": "orc",
"path":
"/zhiyun/shihaihong/ods/#sys_name#_#table_name#_full",
"writeMode": "truncate"
}
}
}
],
"setting": {
"speed": {
"channel": "3"
}
}
}
}create database if not exists ods_shihaihong location
"/zhiyun/shihaihong/ods";-- 增量表
create external table if not exists
ods_shihaihong.#table_name#_full(
#columns#
)
row format delimited fields terminated by "\t"
lines terminated by "\n"
stored as orc
location "/zhiyun/shihaihong/ods/#sys_name#_#table_name#_full";
#!/bin/bash
echo "生成全量配置文件"mkdir -p /zhiyun/shihaihong/jobs
echo '{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://zhiyun.pub:233
06/crm?useSSL=false"
],
"table": [
"user_base_info_his"
]
}
],
"password": "zhiyun",
"username": "zhiyun"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":
"id","type":"int"},
{"name":"user_id","type":"string"},
{"name":"user_type","type":"string"}
,
{"name":"source","type":"string"},
{"name":"erp_code","type":"string"}
,
{"name":"active_time","type":"strin
g"},
{"name":"name","type":"string"},
{"name":"sex","type":"string"},
{"name":"education","type":"string"}
,{"name":"job","type":"string"},
{"name":"email","type":"string"},
{"name":"wechat","type":"string"},
{"name":"webo","type":"string"},
{"name":"birthday","type":"string"}
,
{"name":"age","type":"int"},
{"name":"id_card_no","type":"string
"},
{"name":"social_insurance_no","type
":"string"},
{"name":"address","type":"string"},
{"name":"last_subscribe_time","type
":"int"}
],
"defaultFS": "hdfs://cdh02:8020",
"fieldDelimiter": "\t",
"fileName":
"crm_user_base_info_his_full.data",
"fileType": "orc",
"path":
"/zhiyun/shihaihong/ods/crm_user_base_info_his_full",
"writeMode": "truncate"
}
}
}
],
"setting": {
"speed": {
"channel": "3"
}
}
}
}' > /zhiyun/shihaihong/jobs/crm_user_base_info_his_full.json
echo "开始抽取"
hadoop fs -mkdir -p
/zhiyun/shihaihong/ods/crm_user_base_info_his_full
python /opt/datax/bin/datax.py
/zhiyun/shihaihong/jobs/crm_user_base_info_his_full.json
echo "hive 建表"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e 'create database if not exists ods_shihaihong location
"/zhiyun/shihaihong/ods";
-- 增量表
create external table if not exists
ods_shihaihong.user_base_info_his_full(
id int,
user_id string,
user_type string,
source string,
erp_code string,
active_time string,
name string,
sex string,
education string,
job string,
email string,
wechat string,
webo string,
birthday string,
age int,
id_card_no string,
social_insurance_no string,
address string,
last_subscribe_time int
)
row format delimited fields terminated by "\t"
lines terminated by "\n"
stored as orc
location "/zhiyun/shihaihong/ods/crm_user_base_info_his_full";
'
# echo "加载数据"
# beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
# load data inpath
\"/zhiyun/shihaihong/tmp/crm_user_base_info_his_full/*\"
overwrite into table ods_shihaihong.crm_user_base_info_his_full
partition(createtime='$day');
# "
echo "验证数据"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
select count(1) from ods_shihaihong.user_base_info_his_full;
"echo "抽取完成"



#!/bin/bash
echo "生成全量配置文件"
mkdir -p /zhiyun/shihaihong/jobs
echo '{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://zhiyun.pub:233
06/erp?useSSL=false"
],
"table": [
"u_memcard_reg"
]
}
],
"password": "zhiyun",
"username": "zhiyun"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":
"id","type":"int"},
{"name":"memcardno","type":"string"}
,
{"name":"busno","type":"string"},
{"name":"introducer","type":"string
"},
{"name":"cardtype","type":"int"},
{"name":"cardlevel","type":"int"},{"name":"cardpass","type":"string"}
,
{"name":"cardstatus","type":"int"},
{"name":"saleamount","type":"string
"},
{"name":"realamount","type":"string
"},
{"name":"puramount","type":"string"}
,
{"name":"integral","type":"string"}
,
{"name":"integrala","type":"string"}
,
{"name":"integralflag","type":"int"}
,
{"name":"cardholder","type":"string
"},
{"name":"cardaddress","type":"strin
g"},
{"name":"sex","type":"string"},
{"name":"tel","type":"string"},
{"name":"handset","type":"string"},
{"name":"fax","type":"string"},
{"name":"createuser","type":"string
"},
{"name":"createtime","type":"string
"},
{"name":"tstatus","type":"int"},
{"name":"notes","type":"string"},
{"name":"stamp","type":"string"},
{"name":"idcard","type":"string"},
{"name":"birthday","type":"string"}
,
{"name":"allowintegral","type":"int
"},
{"name":"apptype","type":"string"},
{"name":"applytime","type":"string"}
,
{"name":"invalidate","type":"string
"},
{"name":"lastdate","type":"string"}
,
{"name":"bak1","type":"string"},{"name":"scrm_userid","type":"strin
g"}
],
"defaultFS": "hdfs://cdh02:8020",
"fieldDelimiter": "\t",
"fileName":
"erp_u_memcard_reg_full.data",
"fileType": "orc",
"path":
"/zhiyun/shihaihong/ods/erp_u_memcard_reg_full",
"writeMode": "truncate"
}
}
}
],
"setting": {
"speed": {
"channel": "3"
}
}
}
}' > /zhiyun/shihaihong/jobs/erp_u_memcard_reg_full.json
echo "开始抽取"
hadoop fs -mkdir -p /zhiyun/shihaihong/ods/erp_u_memcard_reg_full
python /opt/datax/bin/datax.py
/zhiyun/shihaihong/jobs/erp_u_memcard_reg_full.json
echo "hive 建表"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e '
create database if not exists ods_shihaihong location
"/zhiyun/shihaihong/ods";
-- 增量表
create external table if not exists
ods_shihaihong.u_memcard_reg_full(
id int,
memcardno string,
busno string,
introducer string,
cardtype int,
cardlevel int,
cardpass string,
cardstatus int,saleamount string,
realamount string,
puramount string,
integral string,
integrala string,
integralflag int,
cardholder string,
cardaddress string,
sex string,
tel string,
handset string,
fax string,
createuser string,
createtime string,
tstatus int,
notes string,
stamp string,
idcard string,
birthday string,
allowintegral int,
apptype string,
applytime string,
invalidate string,
lastdate string,
bak1 string,
scrm_userid string
)
row format delimited fields terminated by "\t"
lines terminated by "\n"
stored as orc
location "/zhiyun/shihaihong/ods/erp_u_memcard_reg_full";
'
# echo "加载数据"
# beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
# load data inpath
\"/zhiyun/shihaihong/tmp/erp_u_memcard_reg_full/*\" overwrite
into table ods_shihaihong.erp_u_memcard_reg_full
partition(createtime='$day');
# "
echo "验证数据"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "select count(1) from ods_shihaihong.u_memcard_reg_full;
"
echo "抽取完成"#!/bin/bash
echo "生成全量配置文件"
mkdir -p /zhiyun/shihaihong/jobs
echo '{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://zhiyun.pub:233
06/erp?useSSL=false"
],
"table": [
"c_memcard_class_group"
]
}
],
"password": "zhiyun",
"username": "zhiyun"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":
"createtime","type":"string"},{"name":"createuser","type":"string
"},
{"name":"groupid","type":"int"},
{"name":"groupname","type":"string"}
,
{"name":"notes","type":"string"},
{"name":"stamp","type":"int"}
],
"defaultFS": "hdfs://cdh02:8020",
"fieldDelimiter": "\t",
"fileName":
"erp_c_memcard_class_group_full.data",
"fileType": "orc",
"path":
"/zhiyun/shihaihong/ods/erp_c_memcard_class_group_full",
"writeMode": "truncate"
}
}
}
],
"setting": {
"speed": {
"channel": "3"
}
}
}
}' > /zhiyun/shihaihong/jobs/erp_c_memcard_class_group_full.json
echo "开始抽取"
hadoop fs -mkdir -p
/zhiyun/shihaihong/ods/erp_c_memcard_class_group_full
python /opt/datax/bin/datax.py
/zhiyun/shihaihong/jobs/erp_c_memcard_class_group_full.json
echo "hive 建表"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e '
create database if not exists ods_shihaihong location
"/zhiyun/shihaihong/ods";
-- 增量表
create external table if not exists
ods_shihaihong.c_memcard_class_group_full(
createtime string,
createuser string,groupid int,
groupname string,
notes string,
stamp int
)
row format delimited fields terminated by "\t"
lines terminated by "\n"
stored as orc
location
"/zhiyun/shihaihong/ods/erp_c_memcard_class_group_full";
'
# echo "加载数据"
# beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
# load data inpath
\"/zhiyun/shihaihong/tmp/erp_c_memcard_class_group_full/*\"
overwrite into table
ods_shihaihong.erp_c_memcard_class_group_full
partition(createtime='$day');
# "
echo "验证数据"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
select count(1) from ods_shihaihong.c_memcard_class_group_full;
"
echo "抽取完成"
erp.u_memcard_reg_c:
#!/bin/bash
echo "生成全量配置文件"
mkdir -p /zhiyun/shihaihong/jobs
echo '{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader","parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://zhiyun.pub:233
06/erp?useSSL=false"
],
"table": [
"u_memcard_reg_c"
]
}
],
"password": "zhiyun",
"username": "zhiyun"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":
"id","type":"int"},
{"name":"memcardno","type":"string"}
,
{"name":"sickness","type":"string"}
,
{"name":"status","type":"string"}
],
"defaultFS": "hdfs://cdh02:8020",
"fieldDelimiter": "\t",
"fileName":
"erp_u_memcard_reg_c_full.data",
"fileType": "orc",
"path":
"/zhiyun/shihaihong/ods/erp_u_memcard_reg_c_full",
"writeMode": "truncate"
}
}
}
],
"setting": {
"speed": {"channel": "3"
}
}
}
}' > /zhiyun/shihaihong/jobs/erp_u_memcard_reg_c_full.json
echo "开始抽取"
hadoop fs -mkdir -p
/zhiyun/shihaihong/ods/erp_u_memcard_reg_c_full
python /opt/datax/bin/datax.py
/zhiyun/shihaihong/jobs/erp_u_memcard_reg_c_full.json
echo "hive 建表"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e '
create database if not exists ods_shihaihong location
"/zhiyun/shihaihong/ods";
-- 增量表
create external table if not exists
ods_shihaihong.u_memcard_reg_c_full(
id int,
memcardno string,
sickness string,
status string
)
row format delimited fields terminated by "\t"
lines terminated by "\n"
stored as orc
location "/zhiyun/shihaihong/ods/erp_u_memcard_reg_c_full";
'
# echo "加载数据"
# beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
# load data inpath
\"/zhiyun/shihaihong/tmp/erp_u_memcard_reg_c_full/*\" overwrite
into table ods_shihaihong.erp_u_memcard_reg_c_full
partition(createtime='$day');
# "
echo "验证数据"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
select count(1) from ods_shihaihong.u_memcard_reg_c_full;
"echo "抽取完成"#!/bin/bash
echo "生成全量配置文件"
mkdir -p /zhiyun/shihaihong/jobs
echo '{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://zhiyun.pub:233
06/his?useSSL=false"
],
"table": [
"chronic_patient_info_new"
]
}
],
"password": "zhiyun",
"username": "zhiyun"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":
"id","type":"int"},{"name":"member_id","type":"string"}
,
{"name":"erp_code","type":"string"}
,
{"name":"extend","type":"string"},
{"name":"detect_time","type":"strin
g"},
{"name":"bec_chr_mbr_date","type":"
string"}
],
"defaultFS": "hdfs://cdh02:8020",
"fieldDelimiter": "\t",
"fileName":
"his_chronic_patient_info_new_full.data",
"fileType": "orc",
"path":
"/zhiyun/shihaihong/ods/his_chronic_patient_info_new_full",
"writeMode": "truncate"
}
}
}
],
"setting": {
"speed": {
"channel": "3"
}
}
}
}' >
/zhiyun/shihaihong/jobs/his_chronic_patient_info_new_full.json
echo "开始抽取"
hadoop fs -mkdir -p
/zhiyun/shihaihong/ods/his_chronic_patient_info_new_full
python /opt/datax/bin/datax.py
/zhiyun/shihaihong/jobs/his_chronic_patient_info_new_full.json
echo "hive 建表"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e '
create database if not exists ods_shihaihong location
"/zhiyun/shihaihong/ods";
-- 增量表create external table if not exists
ods_shihaihong.chronic_patient_info_new_full(
id int,
member_id string,
erp_code string,
extend string,
detect_time string,
bec_chr_mbr_date string
)
row format delimited fields terminated by "\t"
lines terminated by "\n"
stored as orc
location
"/zhiyun/shihaihong/ods/his_chronic_patient_info_new_full";
'
# echo "加载数据"
# beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
# load data inpath
\"/zhiyun/shihaihong/tmp/his_chronic_patient_info_new_full/*\"
overwrite into table
ods_shihaihong.his_chronic_patient_info_new_full
partition(createtime='$day');
# "
echo "验证数据"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
select count(1) from
ods_shihaihong.chronic_patient_info_new_full;
"
echo "抽取完成"#!/bin/bash
echo "生成全量配置文件"
mkdir -p /zhiyun/shihaihong/jobsecho '{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://zhiyun.pub:233
06/erp?useSSL=false"
],
"table": [
"c_org_busi"
]
}
],
"password": "zhiyun",
"username": "zhiyun"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":
"id","type":"int"},
{"name":"busno","type":"string"},
{"name":"orgname","type":"string"},
{"name":"orgsubno","type":"string"}
,
{"name":"orgtype","type":"string"},
{"name":"salegroup","type":"string"}
,
{"name":"org_tran_code","type":"str
ing"},
{"name":"accno","type":"string"},
{"name":"sendtype","type":"string"}
,
{"name":"sendday","type":"string"},{"name":"maxday","type":"string"},
{"name":"minday","type":"string"},
{"name":"notes","type":"string"},
{"name":"stamp","type":"string"},
{"name":"status","type":"string"},
{"name":"customid","type":"string"}
,
{"name":"whl_vendorno","type":"stri
ng"},
{"name":"whlgroup","type":"string"}
,
{"name":"rate","type":"string"},
{"name":"creditamt","type":"string"}
,
{"name":"creditday","type":"string"}
,
{"name":"peoples","type":"string"},
{"name":"area","type":"string"},
{"name":"abc","type":"string"},
{"name":"address","type":"string"},
{"name":"tel","type":"string"},
{"name":"principal","type":"string"}
,
{"name":"identity_card","type":"str
ing"},
{"name":"mobil","type":"string"},
{"name":"corporation","type":"strin
g"},
{"name":"saler","type":"string"},
{"name":"createtime","type":"string
"},
{"name":"bank","type":"string"},
{"name":"bankno","type":"string"},
{"name":"bak1","type":"string"},
{"name":"bak2","type":"string"},
{"name":"a_bak1","type":"string"},
{"name":"aa_bak1","type":"string"},
{"name":"b_bak1","type":"string"},
{"name":"bb_bak1","type":"string"},
{"name":"y_bak1","type":"string"},
{"name":"t_bak1","type":"string"},
{"name":"ym_bak1","type":"string"},
{"name":"tm_bak1","type":"string"},{"name":"supervise_code","type":"st
ring"},
{"name":"monthrent","type":"string"}
,
{"name":"wms_warehid","type":"strin
g"},
{"name":"settlement_cycle","type":"
string"},
{"name":"apply_cycle","type":"strin
g"},
{"name":"applydate","type":"string"}
,
{"name":"accounttype","type":"strin
g"},
{"name":"applydate_last","type":"st
ring"},
{"name":"paymode","type":"string"},
{"name":"yaolian_flag","type":"stri
ng"},
{"name":"org_longitude","type":"str
ing"},
{"name":"org_latitude","type":"stri
ng"},
{"name":"org_province","type":"stri
ng"},
{"name":"org_city","type":"string"}
,
{"name":"org_area","type":"string"}
,
{"name":"business_time","type":"str
ing"},
{"name":"yaolian_group","type":"str
ing"},
{"name":"pacard_storeid","type":"st
ring"},
{"name":"opening_time","type":"stri
ng"},
{"name":"ret_ent_id","type":"string
"},
{"name":"ent_id","type":"string"}
],
"defaultFS": "hdfs://cdh02:8020",
"fieldDelimiter": "\t","fileName": "erp_c_org_busi_full.data",
"fileType": "orc",
"path":
"/zhiyun/shihaihong/ods/erp_c_org_busi_full",
"writeMode": "truncate"
}
}
}
],
"setting": {
"speed": {
"channel": "3"
}
}
}
}' > /zhiyun/shihaihong/jobs/erp_c_org_busi_full.json
echo "开始抽取"
hadoop fs -mkdir -p /zhiyun/shihaihong/ods/erp_c_org_busi_full
python /opt/datax/bin/datax.py
/zhiyun/shihaihong/jobs/erp_c_org_busi_full.json
echo "hive 建表"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e '
create database if not exists ods_shihaihong location
"/zhiyun/shihaihong/ods";
-- 增量表
create external table if not exists
ods_shihaihong.c_org_busi_full(
id int,
busno string,
orgname string,
orgsubno string,
orgtype string,
salegroup string,
org_tran_code string,
accno string,
sendtype string,
sendday string,
maxday string,
minday string,
notes string,
stamp string,status string,
customid string,
whl_vendorno string,
whlgroup string,
rate string,
creditamt string,
creditday string,
peoples string,
area string,
abc string,
address string,
tel string,
principal string,
identity_card string,
mobil string,
corporation string,
saler string,
createtime string,
bank string,
bankno string,
bak1 string,
bak2 string,
a_bak1 string,
aa_bak1 string,
b_bak1 string,
bb_bak1 string,
y_bak1 string,
t_bak1 string,
ym_bak1 string,
tm_bak1 string,
supervise_code string,
monthrent string,
wms_warehid string,
settlement_cycle string,
apply_cycle string,
applydate string,
accounttype string,
applydate_last string,
paymode string,
yaolian_flag string,
org_longitude string,
org_latitude string,
org_province string,org_city string,
org_area string,
business_time string,
yaolian_group string,
pacard_storeid string,
opening_time string,
ret_ent_id string,
ent_id string
)
row format delimited fields terminated by "\t"
lines terminated by "\n"
stored as orc
location "/zhiyun/shihaihong/ods/erp_c_org_busi_full";
'
# echo "加载数据"
# beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
# load data inpath
\"/zhiyun/shihaihong/tmp/erp_c_org_busi_full/*\" overwrite into
table ods_shihaihong.erp_c_org_busi_full
partition(createtime='$day');
# "
echo "验证数据"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
select count(1) from ods_shihaihong.c_org_busi_full;
"
echo "抽取完成"#!/bin/bash
echo "生成全量配置文件"
mkdir -p /zhiyun/shihaihong/jobs
echo '{
"job": {"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://zhiyun.pub:233
06/erp?useSSL=false"
],
"table": [
"c_code_value"
]
}
],
"password": "zhiyun",
"username": "zhiyun"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":
"id","type":"int"},
{"name":"cat_name","type":"string"}
,
{"name":"cat_code","type":"string"}
,
{"name":"val_name","type":"string"}
,
{"name":"var_desc","type":"string"}
],
"defaultFS": "hdfs://cdh02:8020",
"fieldDelimiter": "\t",
"fileName":
"erp_c_code_value_full.data",
"fileType": "orc",
"path":
"/zhiyun/shihaihong/ods/erp_c_code_value_full",
"writeMode": "truncate"}
}
}
],
"setting": {
"speed": {
"channel": "3"
}
}
}
}' > /zhiyun/shihaihong/jobs/erp_c_code_value_full.json
echo "开始抽取"
hadoop fs -mkdir -p /zhiyun/shihaihong/ods/erp_c_code_value_full
python /opt/datax/bin/datax.py
/zhiyun/shihaihong/jobs/erp_c_code_value_full.json
echo "hive 建表"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e '
create database if not exists ods_shihaihong location
"/zhiyun/shihaihong/ods";
-- 增量表
create external table if not exists
ods_shihaihong.c_code_value_full(
id int,
cat_name string,
cat_code string,
val_name string,
var_desc string
)
row format delimited fields terminated by "\t"
lines terminated by "\n"
stored as orc
location "/zhiyun/shihaihong/ods/erp_c_code_value_full";
'
# echo "加载数据"
# beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
# load data inpath
\"/zhiyun/shihaihong/tmp/erp_c_code_value_full/*\" overwrite
into table ods_shihaihong.erp_c_code_value_full
partition(createtime='$day');
# "echo "验证数据"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
select count(1) from ods_shihaihong.c_code_value_full;
"
echo "抽取完成"








 erp.c_code_value :
erp.c_code_value :
#!/bin/python3
import os
import pandas as pd
from openpyxl import load_workbook
ss=''
lst=[]#使用 pandas 的 read_excel 函数读取指定路径的 Excel 文件。
sheet_name=None 表示读取文件中的所有工作表,而 header=2 表示数据的表
头位于第 3 行(索引从 0 开始)
dfs = pd.read_excel('/zhiyun/shihaihong/data/12.码值
表.xlsx',sheet_name=None,header=2)
dir=list(dfs.keys())
#获取 xlsx 文件数据
for i in range(len(dir)):
if i>1:
#获取 A2 行数据
wb = load_workbook(filename='/zhiyun/shihaihong/data/12.
码值表.xlsx')
str_head = wb[dir[i]]['A2'].value
data=dfs[dir[i]]
#获取其它行数据
lst1=[]
for i in data.columns:
for j in range(len(data)):
if data[i][j] != 'NaN':
lst1.append(str(data[i][j]))
n=int(len(lst1)/2)
for i in range(n):
ss=f"{str_head.split('-')[0]}|{str_head.split('-')[
1]}|{lst1[i]}|{lst1[i+n]}"
lst.append(ss)
print("写入数据到 data")
template_path = "/zhiyun/shihaihong/data/code_value.txt"
with open(template_path,"w",encoding="utf-8") as f:
content="\n".join(lst)
f.write(content)
f.close
print("上传 data 文件 到 hdfs")
os.system(f"hdfs dfs -mkdir -p /zhiyun/shihaihong/filetxt/")
os.system(f"hdfs dfs -put {template_path}
/zhiyun/shihaihong/filetxt/")#!/bin/bash
# 作用: 完成从编写配置文件到验证数据的整个过程
# 需要在任何节点都可以执行
# 创建本人文件夹
mkdir -p /zhiyun/shihaihong/data /zhiyun/shihaihong/jobs
/zhiyun/shihaihong/python /zhiyun/shihaihong/shell
/zhiyun/shihaihong/sql
echo "hive 建表"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e'
create database if not exists ods_shihaihong location
"/zhiyun/shihaihong/ods";
create external table if not exists
ods_shihaihong.c_code_value_full(
cat_name string,
cat_code string,
val_name string,
var_desc string
)
row format delimited fields terminated by "|"
lines terminated by "\n"
stored as textfile
location "/zhiyun/shihaihong/filetxt";'
echo "hive 建表完成"
echo "验证数据"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
select count(1) from ods_shihaihong.c_code_value_full;
"
echo "验证完成"执行后,用 shell 脚本抽取


作业2
#!/bin/bash
echo "生成全量配置文件"
mkdir -p /zhiyun/shihaihong/jobs
echo '{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://zhiyun.pub:233
06/erp?useSSL=false"
],
"table": [
"u_sale_m"]
}
],
"password": "zhiyun",
"username": "zhiyun"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":"id","type":"int"},
{"name":"saleno","type":"string"},
{"name":"busno","type":"string"},
{"name":"posno","type":"string"},
{"name":"extno","type":"string"},
{"name":"extsource","type":"string"}
,
{"name":"o2o_trade_from","type":"st
ring"},
{"name":"channel","type":"int"},
{"name":"starttime","type":"string"}
,
{"name":"finaltime","type":"string"}
,
{"name":"payee","type":"string"},
{"name":"discounter","type":"string
"},
{"name":"crediter","type":"string"}
,
{"name":"returner","type":"string"}
,
{"name":"warranter1","type":"string
"},
{"name":"warranter2","type":"string
"},
{"name":"stdsum","type":"string"},
{"name":"netsum","type":"string"},
{"name":"loss","type":"string"},
{"name":"discount","type":"float"},
{"name":"member","type":"string"},
{"name":"precash","type":"string"},
{"name":"stamp","type":"string"},{"name":"shiftid","type":"string"},
{"name":"shiftdate","type":"string"}
,
{"name":"yb_saleno","type":"string"
}
],
"defaultFS": "hdfs://cdh02:8020",
"fieldDelimiter": "\t",
"fileName": "erp_u_sale_m_full.data",
"fileType": "orc",
"path":
"/zhiyun/shihaihong/ods/erp_u_sale_m_full",
"writeMode": "truncate"
}
}
}
],
"setting": {
"speed": {
"channel": "3"
}
}
}
}' > /zhiyun/shihaihong/jobs/erp_u_sale_m_full.json
echo "开始抽取"
hadoop fs -mkdir -p /zhiyun/shihaihong/ods/erp_u_sale_m_full
python /opt/datax/bin/datax.py
/zhiyun/shihaihong/jobs/erp_u_sale_m_full.json
echo "hive 建表"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e '
create database if not exists ods_shihaihong location
"/zhiyun/shihaihong/ods";
-- 增量表
create external table if not exists ods_shihaihong.u_sale_m_full(
id int,
saleno string,
busno string,
posno string,
extno string,
extsource string,
o2o_trade_from string,channel int,
starttime string,
finaltime string,
payee string,
discounter string,
crediter string,
returner string,
warranter1 string,
warranter2 string,
stdsum string,
netsum string,
loss string,
discount float,
member string,
precash string,
stamp string,
shiftid string,
shiftdate string,
yb_saleno string
)
row format delimited fields terminated by "\t"
lines terminated by "\n"
stored as orc
location "/zhiyun/shihaihong/ods/erp_u_sale_m_full";
'
# echo "加载数据"
# beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
# load data inpath \"/zhiyun/shihaihong/tmp/erp_u_sale_m_full/*\"
overwrite into table ods_shihaihong.erp_u_sale_m_full
partition(createtime='$day');
# "
echo "验证数据"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
select count(1) from ods_shihaihong.u_sale_m_full;
"
echo "抽取完成"写入任务调度平台:


#!/bin/bash
day=$(date -d "yesterday" +%Y-%m-%d)
if [ $1 != "" ]; thenday=$(date -d "$1 -1 day" +%Y-%m-%d);
fi;
echo "抽取的日期为 $day"
echo "生成增量配置文件"
mkdir -p /zhiyun/shihaihong/jobs
echo '
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://zhiyun.pub:233
06/erp?useSSL=false"
],
"querySql": [
"select * from u_sale_m where
stamp between '\'"$day" 00:00:00\'' and '\'"$day" 23:59:59\'' and
id>0"
]
}
],
"password": "zhiyun",
"username": "zhiyun"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":"id","type":"int"},
{"name":"saleno","type":"string"},
{"name":"busno","type":"string"},
{"name":"posno","type":"string"},
{"name":"extno","type":"string"},{"name":"extsource","type":"string"}
,
{"name":"o2o_trade_from","type":"str
ing"},
{"name":"channel","type":"int"},
{"name":"starttime","type":"string"}
,
{"name":"finaltime","type":"string"}
,
{"name":"payee","type":"string"},
{"name":"discounter","type":"string"}
,
{"name":"crediter","type":"string"},
{"name":"returner","type":"string"},
{"name":"warranter1","type":"string"}
,
{"name":"warranter2","type":"string"}
,
{"name":"stdsum","type":"string"},
{"name":"netsum","type":"string"},
{"name":"loss","type":"string"},
{"name":"discount","type":"float"},
{"name":"member","type":"string"},
{"name":"precash","type":"string"},
{"name":"stamp","type":"string"},
{"name":"shiftid","type":"string"},
{"name":"shiftdate","type":"string"}
,
{"name":"yb_saleno","type":"string"}
],
"defaultFS": "hdfs://cdh02:8020",
"fieldDelimiter": "\t",
"fileName": "erp_u_sale_m_inc.data",
"fileType": "orc",
"path":
"/zhiyun/shihaihong/tmp/erp_u_sale_m_inc",
"writeMode": "truncate"
}
}
}
],
"setting": {
"speed": {"channel": 2
}
}
}
}' > /zhiyun/shihaihong/jobs/erp_u_sale_m_inc.json
echo "开始抽取"
hadoop fs -mkdir -p /zhiyun/shihaihong/tmp/erp_u_sale_m_inc
python /opt/datax/bin/datax.py
/zhiyun/shihaihong/jobs/erp_u_sale_m_inc.json
echo "hive 建表"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e '
create database if not exists ods_shihaihong location
"/zhiyun/shihaihong/ods";
create external table if not exists
ods_shihaihong.erp_u_sale_m_inc(
id int,
saleno string,
busno string,
posno string,
extno string,
extsource string,
o2o_trade_from string,
channel int,
starttime string,
finaltime string,
payee string,
discounter string,
crediter string,
returner string,
warranter1 string,
warranter2 string,
stdsum string,
netsum string,
loss string,
discount float,
member string,
precash string,
shiftid string,
shiftdate string,
yb_saleno string) partitioned by (stamp string)
row format delimited fields terminated by "\t"
lines terminated by "\n"
stored as orc
location "/zhiyun/shihaihong/ods/erp_u_sale_m_inc";
'
echo "加载数据"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
load data inpath '/zhiyun/shihaihong/tmp/erp_u_sale_m_inc/*'
overwrite into table ods_shihaihong.erp_u_sale_m_inc
partition(stamp='"$day"');
"
echo "验证数据"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
show partitions ods_shihaihong.erp_u_sale_m_inc;
select count(1) from ods_shihaihong.erp_u_sale_m_inc where stamp
= '"$day"';
select * from ods_shihaihong.erp_u_sale_m_inc where stamp =
'"$day"' limit 5;
"
echo "抽取完成"


#!/bin/bash
echo "生成全量配置文件"
mkdir -p /zhiyun/shihaihong/jobsecho '{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://zhiyun.pub:233
06/erp?useSSL=false"
],
"table": [
"u_sale_pay"
]
}
],
"password": "zhiyun",
"username": "zhiyun"
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":
"id","type":"int"},
{"name":"saleno","type":"string"},
{"name":"cardno","type":"string"},
{"name":"netsum","type":"string"},
{"name":"paytype","type":"string"},
{"name":"bak1","type":"string"}
],
"defaultFS": "hdfs://cdh02:8020",
"fieldDelimiter": "\t",
"fileName": "erp_u_sale_pay_full.data",
"fileType": "orc",
"path":
"/zhiyun/shihaihong/ods/erp_u_sale_pay_full",
"writeMode": "truncate"}
}
}
],
"setting": {
"speed": {
"channel": "3"
}
}
}
}' > /zhiyun/shihaihong/jobs/erp_u_sale_pay_full.json
echo "开始抽取"
hadoop fs -mkdir -p /zhiyun/shihaihong/ods/erp_u_sale_pay_full
python /opt/datax/bin/datax.py
/zhiyun/shihaihong/jobs/erp_u_sale_pay_full.json
echo "hive 建表"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e '
create database if not exists ods_shihaihong location
"/zhiyun/shihaihong/ods";
-- 增量表
create external table if not exists
ods_shihaihong.u_sale_pay_full(
id int,
saleno string,
cardno string,
netsum string,
paytype string,
bak1 string
)
row format delimited fields terminated by "\t"
lines terminated by "\n"
stored as orc
location "/zhiyun/shihaihong/ods/erp_u_sale_pay_full";
'
# echo "加载数据"
# beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
# load data inpath
\"/zhiyun/shihaihong/tmp/erp_u_sale_pay_full/*\" overwrite into
table ods_shihaihong.erp_u_sale_pay_full
partition(createtime='$day');# "
echo "验证数据"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
select count(1) from ods_shihaihong.u_sale_pay_full;
"
echo "抽取完成"

#!/bin/bash
day=$(date -d "yesterday" +%Y-%m-%d)
if [ $1 != "" ]; then
day=$(date -d "$1 -1 day" +%Y-%m-%d);
fi;
echo "抽取的日期为 $day"
echo "生成增量配置文件"
mkdir -p /zhiyun/shihaihong/jobs
echo '
{
"job": {
"content": [
{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"connection": [
{
"jdbcUrl": [
"jdbc:mysql://zhiyun.pub:233
06/erp?useSSL=false"
],
"table": [
"select u_sale_pay.*,stamp
from u_sale_pay left join u_sale_m on
u_sale_pay.saleno=u_sale_m.saleno where stamp between '\'"$day"
00:00:00\'' and '\'"$day" 23:59:59\'' and id>0 "
]
}
],
"password": "zhiyun",
"username": "zhiyun"
}},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [
{"name":
"id","type":"int"},
{"name":"saleno","type":"string"},
{"name":"cardno","type":"string"},
{"name":"netsum","type":"string"},
{"name":"paytype","type":"string"},
{"name":"bak1","type":"string"},
{"name":"stamp","type":"string"}
],
"defaultFS": "hdfs://cdh02:8020",
"fieldDelimiter": "\t",
"fileName": "erp_u_sale_pay_inc.data",
"fileType": "orc",
"path":
"/zhiyun/shihaihong/tmp/erp_u_sale_pay_inc",
"writeMode": "truncate"
}
}
}
],
"setting": {
"speed": {
"channel": "3"
}
}
}
}
' > /zhiyun/shihaihong/jobs/erp_u_sale_play_inc.json
echo "开始抽取"
hadoop fs -mkdir -p /zhiyun/shihaihong/tmp/erp_u_sale_play_inc
python /opt/datax/bin/datax.py
/zhiyun/shihaihong/jobs/erp_u_sale_play_inc.json
echo "hive 建表"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e 'create database if not exists ods_shihaihong location
"/zhiyun/shihaihong/ods";
create external table if not exists
ods_shihaihong.erp_u_sale_play_inc(
id int,
saleno string,
cardno string,
netsum string,
paytype string,
bak1 string
) partitioned by (stamp string)
row format delimited fields terminated by "\t"
lines terminated by "\n"
stored as orc
location "/zhiyun/shihaihong/ods/erp_u_sale_play_inc";
'
echo "加载数据"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
load data inpath '/zhiyun/shihaihong/tmp/erp_u_sale_play_inc/*'
overwrite into table ods_shihaihong.erp_u_sale_play_inc
partition(stamp='"$day"');
"
echo "验证数据"
beeline -u jdbc:hive2://localhost:10000 -n root -p 123 -e "
show partitions ods_shihaihong.erp_u_sale_play_inc;
select count(1) from ods_shihaihong.erp_u_sale_play_inc where
stamp = '"$day"';
select * from ods_shihaihong.erp_u_sale_play_inc where stamp =
'"$day"' limit 5;
"
echo "抽取完成"


相关文章:
学习大数据DAY59 全量抽取和增量抽取实战
目录 需求流程: 需求分析与规范 作业 作业2 需求流程: 全量抽取 增量抽取 - DataX Kettle Sqoop ... 场景: 业务部门同事或者甲方的工作人员给我们的部门经理和你提出了新的需 求 流程: 联系 > 开会讨论 > 确认需求 > 落地 需求文档( 具体…...

YOLOv8——测量高速公路上汽车的速度
引言 在人工神经网络和计算机视觉领域,目标识别和跟踪是非常重要的技术,它们可以应用于无数的项目中,其中许多可能不是很明显,比如使用这些算法来测量距离或对象的速度。 测量汽车速度基本步骤如下: 视频采集&#x…...

在线相亲交友系统:寻找另一半的新方式
在这个快节奏的时代里,越来越多的单身男女发现,传统意义上的相亲方式已经难以满足他们的需求。与此同时,互联网技术的迅猛发展为人们提供了新的社交渠道——在线相亲交友系统作者h17711347205。本文将探讨在线相亲交友系统如何成为一种寻找另…...

MySQL 中存储过程参数的设置与使用
《MySQL 中存储过程参数的设置与使用》 在 MySQL 数据库中,存储过程是一组预先编译好的 SQL 语句集合,可以接受参数并返回结果。使用存储过程可以提高数据库的性能和可维护性,同时也可以减少网络流量和代码重复。那么,如何在 MyS…...

2k1000LA 调试HDMI
问题: 客户需要使用HDMI 接口,1080p 的分辨率。 ---------------------------------------------------------------------------------------------------------------- 这里需要看看 龙芯派的 demo 版 的 硬件上的连接。 硬件上: 官方的demo 板 , dvo1 应该是 HDMI的…...

24年蓝桥杯及攻防世界赛题-MISC-1
2 What-is-this AZADI TOWER 3 Avatar 题目 一个恐怖份子上传了这张照片到社交网络。里面藏了什么信息?隐藏内容即flag 解题 ┌──(holyeyes㉿kali2023)-[~/Misc/tool-misc/outguess] └─$ outguess -r 035bfaa85410429495786d8ea6ecd296.jpg flag1.txt Reading 035bf…...

前端项目代码开发规范及工具配置
在项目开发中,良好的代码编写规范是项目组成的重要元素。本文将详细介绍在项目开发中如何集成相应的代码规范插件及使用方法。 项目规范及工具 集成 EditorConfig集成 Prettier1. 安装 Prettier2. 创建 Prettier 配置文件3. 配置 .prettierrc4. 使用 Prettier 集成 …...
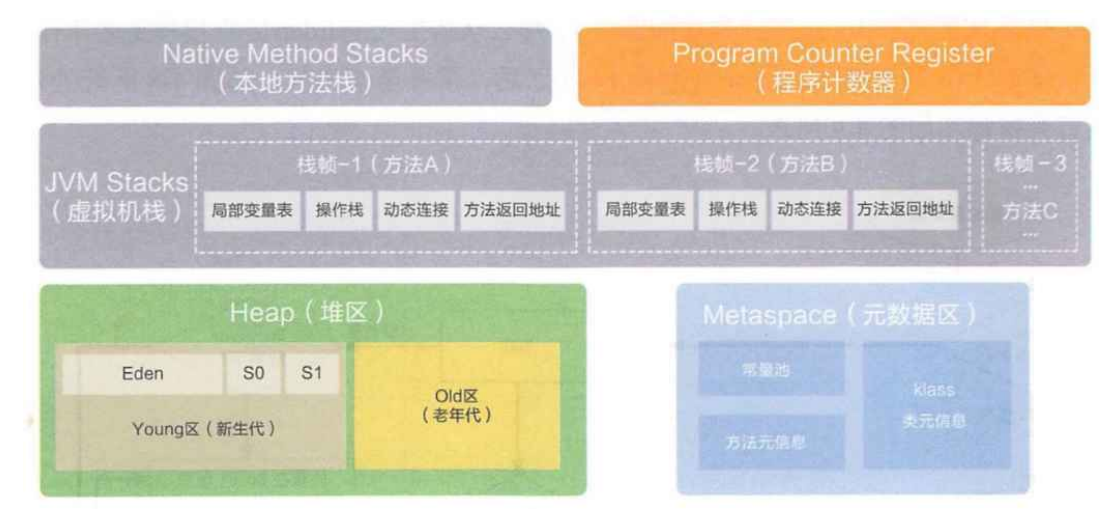
【JVM】JVM执行流程和内存区域划分
文章目录 是什么JVM 执行流程内存区域划分堆栈程序计数器元数据区经典笔试题 是什么 Java 虚拟机 JDK,Java 开发工具包JRE,Java 运行时环境JVM,Java 虚拟机 JVM 就是 Java 虚拟机,解释执行 Java 字节码 JVM 执行流程 编程语言…...
Python | 读取.dat 文件
写在前面 使用matlab可以输出为 .dat 或者 .mat 形式的文件,之前介绍过读取 .mat 后缀文件,今天正好把 .dat 的读取也记录一下。 读取方法 这里可以使用pandas库将其作为一个dataframe的形式读取进python,数据内容格式如下,根据…...

信息技术的变革与未来发展的思考
信息技术的变革与未来发展的思考 在21世纪,信息技术(IT)正在以前所未有的速度推动社会、经济、文化的深刻变革。无论是人工智能、大数据,还是云计算、物联网,信息技术的发展已经渗透到了各个行业,彻底改变…...

融会贯通记单词,绝对丝滑,一天轻松记几百
如果我将flower(花)、flat(公寓)、floor(地板)、plane(飞机)几个单词放在一起,你会怎么来记忆这样的一些单词呢? 我们会发现,我们首先可以将plane去掉,因为它看上去几乎就是一个异类。这样,我们首先就可以将…...

【计算机视觉】YoloV8-训练与测试教程
✨ Blog’s 主页: 白乐天_ξ( ✿>◡❛) 🌈 个人Motto:他强任他强,清风拂山冈! 💫 欢迎来到我的学习笔记! 制作数据集 Labelme 数据集 数据集选用自己标注的,可参考以下:…...

响应式布局-媒体查询父级布局容器
1.响应式布局容器 父局作为布局容器,配合自己元素实现变化效果,原理:在不通过屏幕下面吗,通过媒体查询来改变子元素的排列方式和大小,从而实现不同尺寸屏幕下看到不同的效果。 2.响应尺寸布局容器常见宽度划分 手机-…...

Android APN type 配置和问题
问题/疑问 如果APN配置了非法类型(代码没有定义的),则APN匹配加载的时候最终结果会是空类型。 那么到底是xml解析到数据库就是空type呢?还是Java代码匹配的时候映射是空的呢? Debug Log 尝试将原本的APN type加入ota或者新建一条ota type APN,检查log情况。 //Type有…...

前端mock了所有……
目录 一、背景描述 二、开发流程 1.引入Mock 2.创建文件 3.需求描述 4.Mock实现 三、总结 一、背景描述 前提: 事情是这样的,老板想要我们写一个demo拿去路演/拉项目,有一些数据,希望前端接一下,写几个表格&a…...
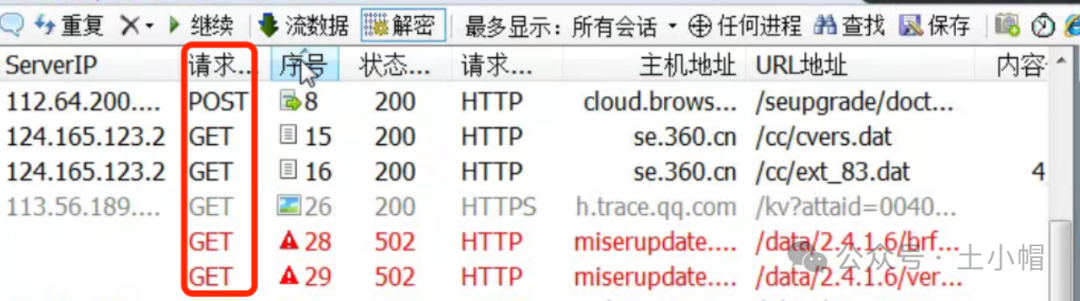
fiddler抓包10_列表显示请求方法
① 请求列表表头,鼠标悬停点击右键弹出选项菜单。 ② 点击“Customize columns”(定制列)。 ③ 弹窗中,“Collection”下拉列表选择“Miscellaneous”(更多字段)。 ④ “Field Name”选择“RequestMethod”…...
Win10系统复制、粘贴、新建、删除文件或文件夹后需要手动刷新的解决办法
有些win10系统可能会出现新建、粘贴、删除文件或文件夹后保持原来的状态不变,需要手动刷新,我这边新装的几个系统都有这个问题,已经困扰很久了,我从微软论坛和CSDN社区找了了很多方法都没解决,微软工程师给的建议包括重…...

BERT训练环节(代码实现)
1.代码实现 #导包 import torch from torch import nn import dltools #加载数据需要用到的声明变量 batch_size, max_len 1, 64 #获取训练数据迭代器、词汇表 train_iter, vocab dltools.load_data_wiki(batch_size, max_len) #其余都是二维数组 #tokens, segments, vali…...

必须执行该语句才能获得结果
UncategorizedSQLException: Error getting generated key or setting result to parameter object. Cause: com.microsoft.sqlserver.jdbc.SQLServerException: 必须执行该语句才能获得结果。 ; uncategorized SQLException; SQL state [null]; error code [0]; 必须执行该语句…...

AI论文写作可靠吗?分享5款论文写作助手ai免费网站
AI论文写作的可靠性是一个备受关注的话题。在当前的技术背景下,AI写作工具能够显著提高论文写作的效率和质量,但其可靠性和安全性仍需谨慎评估。 AI论文写作的可靠性 技术能力与限制 AI论文写作的质量很大程度上取决于用户提供的输入指令或素材的质量…...

单传感器肌电假肢:DTW算法实现92%识别准确率
1. 项目概述肌电假肢技术在过去几十年里取得了显著进展,但传统多传感器系统的高成本和复杂性仍然是阻碍其普及的主要障碍。作为一名从事生物医学工程研究多年的从业者,我一直在寻找更经济高效的解决方案。这项研究提出了一种创新方法:仅使用单…...

JLink V9.5 固件资源包
JLink V9.5 固件资源包 【下载地址】JLinkV9.5固件资源包 JLink V9.5 固件资源包欢迎使用JLink V9.5全套固件资源 项目地址: https://gitcode.com/open-source-toolkit/4bb56 欢迎使用JLink V9.5全套固件资源。本资源包专为那些需要对JLink调试器进行固件升级和自定义配…...

SillyTavern角色卡片系统:从图片到智能伙伴的魔法之旅
SillyTavern角色卡片系统:从图片到智能伙伴的魔法之旅 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 你是否曾想过,一张普通的图片如何能变成一个会思考、会对话、…...

SBA系列生物传感分析仪的工作原理是什么?
SBA系列生物传感分析仪利用酶促反应来进行定量分析,测定的关键传感器是固定化酶和过氧化氢电极复合传感器,分析过程基于以下生化反应:底物 固定化酶膜 → 产物谷氨酸 谷氨酸氧化酶 α-酮戊二酸葡萄糖 葡萄糖氧化…...

如何彻底解决macOS多设备滚动冲突:Scroll Reverser完全指南
如何彻底解决macOS多设备滚动冲突:Scroll Reverser完全指南 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是不是经常在MacBook触控板和鼠标之间切换时࿰…...

从美颜到卫星图:聊聊傅里叶变换在CV领域那些‘看不见’的应用
从美颜到卫星图:傅里叶变换在CV领域的隐形革命 当你用手机拍摄一张自拍,轻触"美颜"按钮时;当医生通过CT扫描诊断病情时;甚至当气象学家分析卫星云图预测台风路径时——这些看似毫不相关的场景背后,都藏着一个…...

从数据迷雾到精准洞察:Granblue Fantasy: Relink战斗分析工具深度解析
从数据迷雾到精准洞察:Granblue Fantasy: Relink战斗分析工具深度解析 【免费下载链接】gbfr-logs GBFR Logs lets you track damage statistics with a nice overlay DPS meter for Granblue Fantasy: Relink. 项目地址: https://gitcode.com/gh_mirrors/gb/gbfr…...
)
高校学生综合测评管理系统(10054)
有需要的同学,源代码和配套文档领取,加文章最下方的名片哦 一、项目演示 项目演示视频 二、资料介绍 完整源代码(前后端源代码SQL脚本)配套文档(LWPPT开题报告/任务书)远程调试控屏包运行一键启动项目&…...

【软考高级架构】论文范文19——论软件系统架构风格
论软件系统架构风格 摘要 软件系统架构风格是描述系统结构和行为的抽象模式,为不同应用领域提供了经过验证的设计方案。合理选择与组合架构风格能够有效指导系统分解、组件划分和交互设计,从而提升系统的可维护性、可扩展性和性能等质量属性。本文以笔者主导的某大型制造企…...

5分钟部署:开源网盘直链解析工具彻底解决下载限速问题
5分钟部署:开源网盘直链解析工具彻底解决下载限速问题 【免费下载链接】netdisk-fast-download 聚合多种主流网盘的直链解析下载服务, 一键解析下载,已支持夸克网盘/uc网盘/蓝奏云/蓝奏优享/小飞机盘/123云盘等. 支持文件夹分享解析. 体验地址: https://…...