【Transformers基础入门篇2】基础组件之Pipeline
文章目录
- 一、什么是Pipeline
- 二、查看PipeLine支持的任务类型
- 三、Pipeline的创建和使用
- 3.1 根据任务类型,直接创建Pipeline,默认是英文模型
- 3.2 指定任务类型,再指定模型,创建基于指定模型的Pipeline
- 3.3 预先加载模型,再创建Pipeline
- 3.4 使用Gpu进行推理
- 3.5 查看Device
- 3.6 测试一下耗时
- 3.7 确定的Pipeline的参数
- 四、Pipeline的背后实现
本文为 https://space.bilibili.com/21060026/channel/collectiondetail?sid=1357748的视频学习笔记
项目地址为:https://github.com/zyds/transformers-code
一、什么是Pipeline
- 将数据预处理、模型调用、结果后处理三部分组装成的流水线,如下流程图
- 使我们能够直接输入文本便获得最终的答案,不需要我们关注细节
二、查看PipeLine支持的任务类型
from transformers.pipelines import SUPPORTED_TASKS
from pprint import pprint
for k, v in SUPPORTED_TASKS.items():print(k, v)
输出但其概念PipeLine支持的任务类型以及可以调用的
举例输出:
audio-classification {'impl': <class 'transformers.pipelines.audio_classification.AudioClassificationPipeline'>, 'tf': (), 'pt': (<class 'transformers.models.auto.modeling_auto.AutoModelForAudioClassification'>,), 'default': {'model': {'pt': ('superb/wav2vec2-base-superb-ks', '372e048')}}, 'type': 'audio'}
- key: 任务的名称,如音频分类
- v:关于任务的实现,如具体哪个Pipeline,有没有TF模型,有没有pytorch模型, 模型具体是哪一个

三、Pipeline的创建和使用
3.1 根据任务类型,直接创建Pipeline,默认是英文模型
from transformers import pipeline
pipe = pipeline("text-classification") # 根据pipeline直接创建一个任务类
pipe("very good") # 测试一个句子,输出结果
3.2 指定任务类型,再指定模型,创建基于指定模型的Pipeline
注,这里我已经将模型离线下载到本地了
# https://huggingface.co/models
pipe = pipeline("text-classification", model="./models/roberta-base-finetuned-dianping-chinese")
3.3 预先加载模型,再创建Pipeline
rom transformers import AutoModelForSequenceClassification, AutoTokenizer# 这种方式,必须同时指定model和tokenizer
model = AutoModelForSequenceClassification.from_pretrained("./models_roberta-base-finetuned-dianping-chinese")
tokenizer = AutoTokenizer.from_pretrained("./models_roberta-base-finetuned-dianping-chinese")
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer)
3.4 使用Gpu进行推理
pipe = pipeline("text-classification", model="./models_roberta-base-finetuned-dianping-chinese", device=0)
3.5 查看Device
pipe.model.device
3.6 测试一下耗时
import torch
import time
times = []
for i in range(100):torch.cuda.synchronize()start = time.time()pipe("我觉得不太行!")torch.cuda.synchronize()end = time.time()times.append(end - start)
print(sum(times) / 100)
3.7 确定的Pipeline的参数
# 先创建一个pipeline
qa_pipe = pipeline("question-answering", model="../../models/models")
qa_pipe
输出

QuestionAnsweringPipeline

查看定义,会告诉我们这个pipeline该如何使用
class QuestionAnsweringPipeline(ChunkPipeline):"""Question Answering pipeline using any `ModelForQuestionAnswering`. See the [question answeringexamples](../task_summary#question-answering) for more information.Example:```python>>> from transformers import pipeline>>> oracle = pipeline(model="deepset/roberta-base-squad2")>>> oracle(question="Where do I live?", context="My name is Wolfgang and I live in Berlin"){'score': 0.9191, 'start': 34, 'end': 40, 'answer': 'Berlin'}```Learn more about the basics of using a pipeline in the [pipeline tutorial](../pipeline_tutorial)This question answering pipeline can currently be loaded from [`pipeline`] using the following task identifier:`"question-answering"`.The models that this pipeline can use are models that have been fine-tuned on a question answering task. See theup-to-date list of available models on[huggingface.co/models](https://huggingface.co/models?filter=question-answering)."""
进入pipeline,看__call__,查看可以支持的更多的参数
列出了更多的参数
def __call__(self, *args, **kwargs):"""Answer the question(s) given as inputs by using the context(s).Args:args ([`SquadExample`] or a list of [`SquadExample`]):One or several [`SquadExample`] containing the question and context.X ([`SquadExample`] or a list of [`SquadExample`], *optional*):One or several [`SquadExample`] containing the question and context (will be treated the same way as ifpassed as the first positional argument).data ([`SquadExample`] or a list of [`SquadExample`], *optional*):One or several [`SquadExample`] containing the question and context (will be treated the same way as ifpassed as the first positional argument).question (`str` or `List[str]`):One or several question(s) (must be used in conjunction with the `context` argument).context (`str` or `List[str]`):One or several context(s) associated with the question(s) (must be used in conjunction with the`question` argument).topk (`int`, *optional*, defaults to 1):The number of answers to return (will be chosen by order of likelihood). Note that we return less thantopk answers if there are not enough options available within the context.doc_stride (`int`, *optional*, defaults to 128):If the context is too long to fit with the question for the model, it will be split in several chunkswith some overlap. This argument controls the size of that overlap.max_answer_len (`int`, *optional*, defaults to 15):The maximum length of predicted answers (e.g., only answers with a shorter length are considered).max_seq_len (`int`, *optional*, defaults to 384):The maximum length of the total sentence (context + question) in tokens of each chunk passed to themodel. The context will be split in several chunks (using `doc_stride` as overlap) if needed.max_question_len (`int`, *optional*, defaults to 64):The maximum length of the question after tokenization. It will be truncated if needed.handle_impossible_answer (`bool`, *optional*, defaults to `False`):Whether or not we accept impossible as an answer.align_to_words (`bool`, *optional*, defaults to `True`):Attempts to align the answer to real words. Improves quality on space separated langages. Might hurt onnon-space-separated languages (like Japanese or Chinese)Return:A `dict` or a list of `dict`: Each result comes as a dictionary with the following keys:- **score** (`float`) -- The probability associated to the answer.- **start** (`int`) -- The character start index of the answer (in the tokenized version of the input).- **end** (`int`) -- The character end index of the answer (in the tokenized version of the input).- **answer** (`str`) -- The answer to the question."""
如下面的例子
我们输出问题:中国的首都是哪里? 给的上下文是:中国的首都是北京
qa_pipe(question="中国的首都是哪里?", context="中国的首都是北京")

如果通过 max_answer_len参数来限定输出的最大长度,会进行强行截断
qa_pipe(question="中国的首都是哪里?", context="中国的首都是北京", max_answer_len=1)

四、Pipeline的背后实现
- step1 初始化组件,Tokenizer,model
# step1 初始化tokenizer, model
tokenizer = AutoTokenizer.from_pretrained("../../models/models_roberta-base-finetuned-dianping-chinese")
model = AutoModelForSequenceClassification.from_pretrained("../../models/models_roberta-base-finetuned-dianping-chinese")
- step2 预处理
# 预处理,返回pytorch的tensor,是一个dict
input_text = "我觉得不太行!"
inputs = tokenizer(input_text, return_tensors="pt")
inputs

- step3 模型预测
res = model(**inputs)
res

预测的结果,包括的内容有点多,如loss,logits等
- step4 结果后处理
logits = res.logits
logits = torch.softmax(logits, dim=-1)
pred = torch.argmax(logits).item()
result = model.config.id2label.get(pred)
result

相关文章:
【Transformers基础入门篇2】基础组件之Pipeline
文章目录 一、什么是Pipeline二、查看PipeLine支持的任务类型三、Pipeline的创建和使用3.1 根据任务类型,直接创建Pipeline,默认是英文模型3.2 指定任务类型,再指定模型,创建基于指定模型的Pipeline3.3 预先加载模型,再…...

java反射学习总结
最近在项目上有一个内部的CR,运用到了反射。想起之前面试的时候被面试官追问有没有在项目中用过反射,以及反射的原理和对反射的了解。 于是借此机会,学习回顾一下反射,以及在项目中可能会用到的场景。 Java 中的反射概述 反射&…...

探索C语言与Linux编程:获取当前用户ID与进程ID
探索C语言与Linux编程:获取当前用户ID与进程ID 一、Linux系统概述与用户、进程概念二、C语言与系统调用三、获取当前用户ID四、获取当前进程ID五、综合应用:同时获取用户ID和进程ID六、深入理解与扩展七、结语在操作系统与编程语言的交汇点,Linux作为开源操作系统的典范,为…...

1.4 边界值分析法
欢迎大家订阅【软件测试】 专栏,开启你的软件测试学习之旅! 文章目录 前言1 定义2 选取3 具体步骤4 案例分析 本篇文章参考黑马程序员 前言 边界值分析法是一种广泛应用于软件测试中的技术,旨在识别输入值范围内的潜在缺陷。本文将详细探讨…...

Spring IOC容器Bean对象管理-注解方式
目录 1、Bean对象常用注解介绍 2、注解示例说明 1、Bean对象常用注解介绍 Component 通用类组件注解,该类被注解,IOC容器启动时实例化此类对象Controller 注解控制器类Service 注解业务逻辑类Respository 注解和数据库操作的类,如DAO类Reso…...

OpenAI API: How to catch all 5xx errors in Python?
题意:OpenAI API:如何在 Python 中捕获所有 5xx 错误? 问题背景: I want to catch all 5xx errors (e.g., 500) that OpenAI API sends so that I can retry before giving up and reporting an exception. 我想捕获 OpenAI API…...

C++初阶学习——探索STL奥秘——标准库中的priority_queue与模拟实现
1.priority_queque的介绍 1.priority_queue中文叫优先级队列。优先队列是一种容器适配器,根据严格的弱排序标准,它的第一个元素总是它所包含的元素中最大的。 2. 此上下文类似于堆,在堆中可以随时插入元素,并且只能检索最大堆元…...

PyTorch经典模型
PyTorch 经典模型教程 1. PyTorch 库架构概述 PyTorch 是一个广泛使用的深度学习框架,具有高度的灵活性和动态计算图的特性。它支持自动求导功能,并且拥有强大的 GPU 加速能力,适用于各种神经网络模型的训练与部署。 PyTorch 的核心架构包…...

C++ STL容器(三) —— 迭代器底层剖析
本篇聚焦于STL中的迭代器,同样基于MSVC源码。 文章目录 迭代器模式应用场景实现方式优缺点 UML类图代码解析list 迭代器const 迭代器非 const 迭代器 vector 迭代器const 迭代器非const迭代器 反向迭代器 迭代器失效参考资料 迭代器模式 首先迭代器模式是设计模式中…...

力扣416周赛
举报垃圾信息 题目 3295. 举报垃圾信息 - 力扣(LeetCode) 思路 直接模拟就好了,这题居然是中等难度 代码 public boolean reportSpam(String[] message, String[] bannedWords) {Map<String,Integer> map new HashMap<>()…...

vue 页面常用图表框架
在 Vue.js 页面中,常见的用于制作图表的框架或库有以下几种: ECharts: 官方网站: EChartsECharts 是一个功能强大、可扩展的图表库,支持多种图表类型,如柱状图、折线图、饼图等。Vue 集成: 可以使用 vue-echarts 插件,…...

spring 注解 - @PostConstruct - 用于初始化工作
PostConstruct 是 Java EE 5 中引入的一个注解,用于标注在方法上,表示该方法应该在依赖注入完成之后执行。这个注解是 javax.annotation 包的一部分,通常用于初始化工作,比如初始化成员变量或者启动一些后台任务。 在 Spring 框架…...
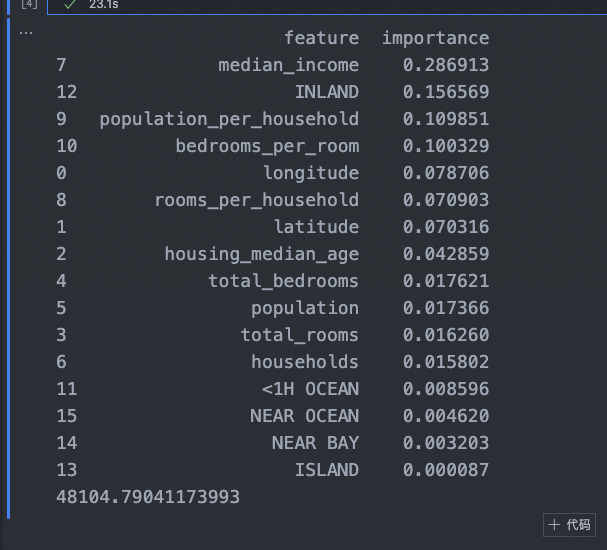
多机器学习模型学习
特征处理 import os import numpy as np import pandas as pd from sklearn.model_selection import train_test_split from sklearn.model_selection import StratifiedShuffleSplit from sklearn.impute import SimpleImputer from sklearn.pipeline import FeatureUnion fr…...

【网页设计】前言
本专栏主要记录 “网页设计” 这一课程的相关笔记。 参考资料: 黑马程序员:黑马程序员pink老师前端入门教程,零基础必看的h5(html5)css3移动端前端视频教程_哔哩哔哩_bilibili 教材:《Adobe创意大学 Dreamweaver CS6标准教材》《…...

STM32巡回研讨会总结(2024)
前言 本次ST公司可以说是推出了7大方面,几乎可以说是覆盖到了目前生活中的方方面面,下面总结下我的感受。无线类 支持多种调制模式(LoRa、(G)FSK、(G)MSK 和 BPSK)满足工业和消费物联网 (IoT) 中各种低功耗广域网 (LPWAN) 无线应…...

54 螺旋矩阵
解题思路: \qquad 这道题可以直接用模拟解决,顺时针螺旋可以分解为依次沿“右-下-左-上”四个方向的移动,每次碰到“边界”时改变方向,边界是不可到达或已经到达过的地方,会随着指针移动不断收缩。 vector<int>…...

基于STM32与OpenCV的物料搬运机械臂设计流程
一、项目概述 本文提出了一种新型的物流搬运机器人,旨在提高物流行业的物料搬运效率和准确性。该机器人结合了 PID 闭环控制算法与视觉识别技术,能够在复杂的环境中实现自主巡线与物料识别。 项目目标与用途 目标:设计一款能够自动搬运物流…...
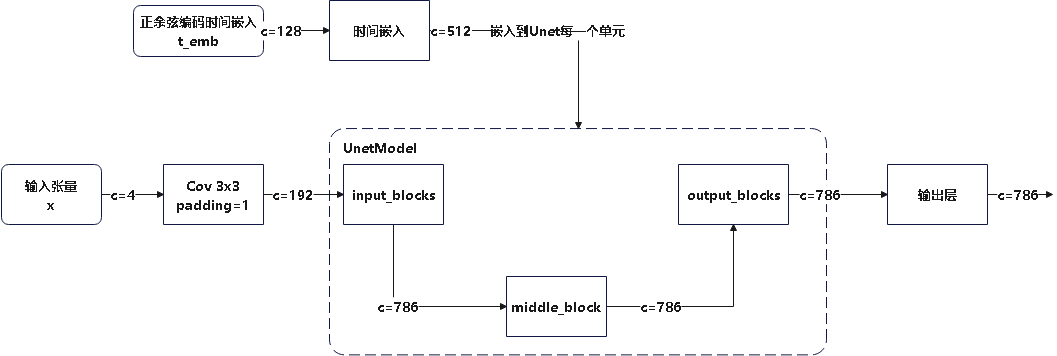
[万字长文]stable diffusion代码阅读笔记
stable diffusion代码阅读笔记 获得更好的阅读体验可以转到我的博客y0k1n0的小破站 本文参考的配置文件信息: AutoencoderKL:stable-diffusion\configs\autoencoder\autoencoder_kl_32x32x4.yaml latent-diffusion:stable-diffusion\configs\latent-diffusion\lsun_churches-ld…...

watchEffect工作原理
watchEffect工作原理 自动依赖收集:watchEffect不需要明确指定要观察的响应式数据,它会自动收集回调函数中用到的所有响应式数据作为依赖。即时执行:watchEffect的回调函数会在组件的setup()函数执行时立即执行一次,以便能够立即…...

斐波那契数列
在 Python 3.11 中实现斐波那契数列的常见方式有多种,下面我将展示几种不同的实现方法,包括递归、迭代和使用缓存(动态规划)来优化递归版本。 1. 递归方式(最简单但效率较低) def fibonacci_recursive(n)…...

SISSO 终极指南:数据驱动建模的强大工具
SISSO 终极指南:数据驱动建模的强大工具 【免费下载链接】SISSO A data-driven method combining symbolic regression and compressed sensing for accurate & interpretable models. 项目地址: https://gitcode.com/gh_mirrors/si/SISSO SISSO…...

使用Taotoken后我们如何观测与优化大模型API调用成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用Taotoken后我们如何观测与优化大模型API调用成本 1. 从黑盒到透明:成本观测的第一步 在接入大模型API的初期&…...

claude code用户如何通过taotoken解决账号封禁与token不足难题
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Claude Code 用户如何通过 Taotoken 解决账号封禁与 Token 不足难题 对于深度依赖 Claude Code 作为编程助手的开发者而言…...

基于开源LLM构建私有化智能体:从意图解析到安全执行的工程实践
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫giocaizzi/ralph-copilot。乍一看这个名字,可能会让人联想到微软的 GitHub Copilot,但它的定位和实现方式其实非常不同。简单来说,这是一个基于开源大语言模型ÿ…...

霍夫曼编码:让计算机学会“断舍离“的无损压缩原理,为什么Zip文件能完美还原,而JPEG会失真?霍夫曼用一棵二叉树解决了50年的压缩难题
霍夫曼编码:让计算机学会"断舍离"的无损压缩原理 副标题: 为什么Zip文件能完美还原,而JPEG会失真?霍夫曼用一棵二叉树解决了50年的压缩难题痛点:为什么压缩文件能完美还原? 你用WinRAR压缩了一个Word文档&am…...

HoRain云--VS Code 创建与使用 Skill
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

ENVI 5.6 + COSI-Corr插件整合指南:搞定地表形变分析的第一步
ENVI 5.6 COSI-Corr插件整合指南:搞定地表形变分析的第一步 对于地质测绘领域的研究人员和工程师来说,地表形变监测是理解地质灾害、评估基础设施安全的重要技术手段。在众多遥感分析方法中,COSI-Corr(Co-registration of Optic…...

逆向分析效率翻倍:深度挖掘IDA Pro的‘隐藏’窗口——段视图、签名、类型库的实战价值
逆向分析效率翻倍:深度挖掘IDA Pro的‘隐藏’窗口实战指南 在逆向工程领域,IDA Pro无疑是众多安全研究员和分析师的首选工具。然而,许多中级用户往往只停留在反汇编窗口的基础操作上,忽视了那些隐藏在界面角落却能极大提升分析效率…...

RV1126 NPU部署ResNet50全流程:从PyTorch训练到嵌入式板端推理
1. 项目概述:从零到一,在RV1126上跑通ResNet50最近在折腾一块EASY-EAI-Nano开发板,核心是瑞芯微的RV1126芯片,这玩意儿带了个NPU,不拿来跑跑AI模型实在说不过去。手头正好有个车辆分类的需求,就想试试经典的…...

快速上手Highlighter:终极网页高亮工具完整指南
快速上手Highlighter:终极网页高亮工具完整指南 【免费下载链接】highlighter A Chrome extension to highlight text and keep it all saved 项目地址: https://gitcode.com/gh_mirrors/hig/highlighter 作为一名经常浏览网页的用户,你是否曾为无…...