Lucene Solr Elasticsearch三者之间的关系,怎么选?
Lucene简介:
Lucene主要用于构建文本搜索应用程序,包括Web搜索引擎、桌面搜索工具和商业应用程序。它提供了诸如单词分析、查询解析、搜索结果排序等功能,可以轻松地在大量文档中快速搜索和查找相关信息。
Lucene具有以下特点:
可扩展性:Lucene可以轻松处理大规模的数据集,支持分布式搜索,可轻松扩展以处理更多数据。
高性能:Lucene使用了许多高效的算法和数据结构,可以在大型文档集合中快速进行搜索。
全文搜索:Lucene支持全文搜索,可以搜索文档中的所有内容,包括文本、数字、日期等。
多语言支持:Lucene支持多种语言,可以轻松处理不同语言的文本。
易于使用:Lucene提供了简单易用的API,使开发人员可以轻松地构建搜索应用程序。
Lucene是一个强大的文本搜索引擎库,具有高性能、可扩展性和易用性,可以用于构建各种文本搜索应用程序。
Solr简介:
Solr是基于Apache Lucene搜索引擎库构建,提供了强大的全文检索和高级搜索功能,支持多种数据格式和多种查询方式。Solr使用Java语言编写,可以运行在任何支持Java虚拟机的操作系统上。
Solr主要用于构建大规模的搜索应用程序,如电子商务网站、新闻门户网站、社交媒体应用程序等。Solr具有高度可扩展性、高性能、高可用性和易于集成的特点,支持多种部署模式,如独立模式、云模式、集群模式等。
Solr提供了丰富的API和插件,可以轻松地集成到现有的应用程序中,还提供了强大的管理和监控工具,可用于管理索引、监控性能和进行故障排除。此外,Solr还支持多种数据格式和多种查询方式,包括基于文本、XML、JSON等格式的查询,以及支持复杂查询逻辑的查询方式。
Solr是一种强大的搜索平台,它提供了全面的搜索功能和易于集成的特点,适用于各种类型的应用程序。
Elasticsearch简介:
Elasticsearch是基于Lucene搜索引擎的分布式、开源的搜索和分析引擎。它能够快速地搜索、分析和存储大量的数据,并且可以轻松地水平扩展,以处理任何规模的数据。
Elasticsearch主要用于大规模应用程序的搜索、数据分析和数据可视化。它能够快速地搜索和分析大规模数据集,并提供实时的数据可视化。它也可以用于日志分析、安全分析、企业搜索等应用程序中。
Elasticsearch支持以下数据类型:
文本类型(Text):用于全文搜索的长文本,支持分析和索引。
关键字类型(Keyword):用于精确匹配的短文本,不支持分析和索引。
数值类型(Numeric):用于数值的存储和范围查询,支持整数、浮点数和双精度浮点数。
日期类型(Date):用于日期和时间的存储和范围查询。
布尔类型(Boolean):用于布尔值的存储和查询。
二进制类型(Binary):用于二进制数据的存储和查询。
地理位置类型(Geo):用于地理位置的存储和查询,支持点、线、多边形等多种类型的位置。
IP地址类型(IP):用于IP地址的存储和查询。
嵌套类型(Nested):用于嵌套的文档结构的存储和查询。
此外,Elasticsearch还支持自定义数据类型,可以通过插件或自定义分析器等方式进行扩展。
Elasticsearch的优点包括:
分布式架构:可以水平扩展,处理大量数据;
实时搜索和分析:能够快速地搜索和分析大规模数据集;
多种查询方式:支持全文搜索、短语搜索、模糊搜索、正则表达式搜索等;
多种数据类型支持:支持文本、数字、日期、地理位置等多种数据类型;
易于使用:提供简单的RESTful API和丰富的客户端库;
开源:遵循Apache 2.0许可证。
Elasticsearch是一个功能强大的搜索和分析引擎,具有广泛的应用领域,适用于各种规模和类型的应用程序。
Solr 和Elasticsearch怎么选
Solr和Elasticsearch都是流行的开源搜索引擎,具有许多相似之处,但也有一些不同之处。选择哪个搜索引擎取决于您的需求、技术能力和预算。
以下是一些可能帮助您选择的因素:
数据存储:Elasticsearch具有分布式数据存储的能力,可以处理大规模数据集。Solr则更适合小型或中型数据集,因为它使用单个节点存储数据。
查询功能:Elasticsearch在复杂查询方面表现更好。它使用lucene引擎,支持更多的查询类型,如嵌套查询、聚合查询等。Solr也具有强大的查询功能,但它没有像Elasticsearch那样的内置聚合。
可扩展性:Elasticsearch天生就具有水平扩展性,可以很容易地添加或删除节点。Solr也可以扩展,但需要手动配置和管理。
实时搜索:Elasticsearch是一个实时搜索引擎,能够在毫秒级别内返回查询结果。Solr也具有实时搜索功能,但查询速度可能较慢。
社区支持和文档:Elasticsearch在这方面的表现更好,拥有更广泛的社区和更完整的文档。Solr也有一个庞大的社区,但Elasticsearch的社区更加活跃。
如果您处理大型数据集,需要高级查询和实时搜索功能,并且具有足够的技术能力和预算,Elasticsearch可能是更好的选择。如果您处理的是小型或中型数据集,需要更简单的查询,并且预算较低,Solr可能更适合。
倒排索引和正排索引
倒排索引:
倒排索引(Inverted Index)是一种常见的文本索引技术,用于加快文本搜索的速度和效率。在倒排索引中,对于每个单词,记录它出现在哪些文档中以及出现的位置信息。
举个例子,假设有3个文档:
文档1:the quick brown fox jumps over the lazy dog
文档2:the quick brown fox jumps over the brown dog
文档3:the quick brown fox jumps over the brown dog again
对于每个单词,我们可以记录它出现在哪些文档中,以及在文档中出现的位置。例如,单词“quick”出现在文档1、文档2和文档3中,分别在第1个、第1个和第1个位置。因此,我们可以将它们记录在一个倒排索引表中:
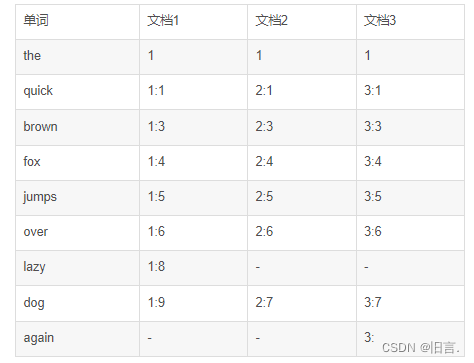
在这个倒排索引表中,每一行代表一个单词,每个单词出现在哪些文档中以及在文档中的位置都被记录下来。例如,“quick”的记录“1:1”表示它出现在文档1中,出现在文档1的第1个位置。通过这种方式,当我们需要搜索某个单词时,我们可以很快地找到包含该单词的所有文档和它们在文档中的位置,从而实现高效的文本搜索
正排索引:
正排索引(Forward Index)是指根据文本内容建立的索引,通常用于实现全文检索。正排索引将文本按照一定的格式(如文档、段落或句子等)分块存储,并为每个块分配一个唯一的标识符,以便后续检索和显示。在正排索引中,每个文本块还包含了该块的一些元信息,如文本的标题、作者、时间戳等等。
正排索引通常是由搜索引擎等系统在建立文本索引时所使用的一种索引结构,它将文本中的每个块(如单词、短语、句子等)都存储在索引结构中,并对每个块建立倒排索引,以支持快速的检索和排序。正排索引在搜索引擎等系统中扮演着非常重要的角色,它可以提高搜索的效率、准确性和可靠性,从而提高用户的搜索体验。
相关文章:
Lucene Solr Elasticsearch三者之间的关系,怎么选?
Lucene简介: Lucene主要用于构建文本搜索应用程序,包括Web搜索引擎、桌面搜索工具和商业应用程序。它提供了诸如单词分析、查询解析、搜索结果排序等功能,可以轻松地在大量文档中快速搜索和查找相关信息。 Lucene具有以下特点: …...

为你的网站加上Loading等待加载效果吧 | Loading页面加载添加教程
为你的网站加上Loading等待加载效果吧 | Loading页面加载添加教程 效果图 : 教程开始 新建一个loading样式css 将以下代码放进去 然后引用这个文件 code #Loadanimation{ background-color:#fff; height:100%; width:100%; position:fixed; z-index:1; ma…...
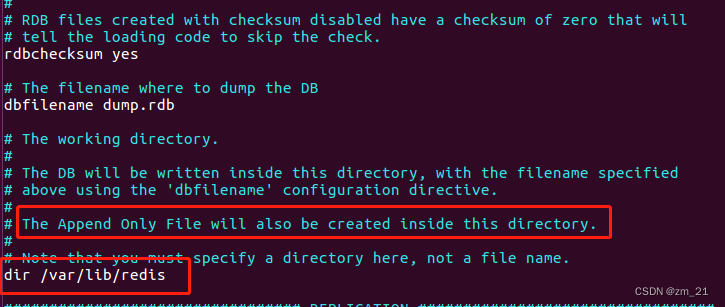
Redis安装和配置
网上有海量的Redis文章,写的都很详细。这里就是简单记录一下自己查aof问题过程中遇到的问题,主要是aof文件所在目录在redis.conf里的位置 1。在ubuntu16上安装Redis sudo apt-get install -y redis-server 2。修改redis配置 sudo vim /etc/redis/re…...

MobTech|如何使用秒验
什么是秒验? 秒验是MobTech公司提供的一款实现一键验证功能的产品,从根源上降低企业验证成本,有效提高拉新转化率,降低因验证带来的流失率,3秒完成手机号验证(一键登录)。 秒验主要整合了三大…...

CSS实现自动分页打印同时每页保留重复的自定义内容
当需要打印的内容过长时系统会产生自动分割页面,造成样式不太美观。使用CSS的 media print 结合 <table> 可以实现对分页样式的可控。效果如下: 假设有50条数据,打印时系统会自动分成两页,同时每页保留自定义的header和foo…...

基于prometheus的监控告警怎么实现?
基于 Prometheus 的监控告警实现一般需要以下几个步骤: 安装和配置 Prometheus:安装 Prometheus 并配置好需要监控的目标。可以使用 Prometheus 的配置文件(prometheus.yml)来指定需要监控的目标,例如服务、主机、容器…...

2007年4月全国计算机等级考试二级JAVA笔试试题及答案
2007年4月全国计算机等级考试二级JAVA笔试试题及答案 一、选择题 (1)已知一棵二叉树前序遍历和中序遍历分别为ABDEGCFH和DBGEACHF,则该二叉树的后序遍历为 A.GEDHFBCA B.DGEBHFCA C.ABCDEFGH D.…...
)
灌水玩玩 ChatGPT AIGC生成的有栈协同程序实现(例子)
CO: 你是一名 C/C 高级软件工程师。 请使用 stackful 协程,实现一个 Sleep 随眠的协同程序,注意并非 stackless 协程,不允许使用 C/C 17 以上的语言标准实现,允许使用 boost 基础框架类库。 ChatGPT: 好的…...

【砝码称重】暴力DFS(一半分)+ dp(可AC)
题目描述: 题目分析: 我也没有完全搞太明白,简单说说我的理解 1.dp【i】【j】表示前 i 个砝码,是否可以称出来重量为 j 的物品,如果可以的话,值为1,不可以 为0; 2.针对当前第 i 个…...
科大奥瑞物理实验——霍尔效应实验
实验名称:霍尔效应实验 1. 实验目的: 了解霍尔效应测量磁场的原理和方法;观察磁电效应现象;学会用霍尔元件测量磁场及元件参数的基本方法。 2. 实验器材: QS-H型霍尔效应实验仪 磁针 QS-H型霍尔效应测试仪 双刀开关…...
2023_深入学习HTML5
H5 基于html5和 css3和一部分JS API 结合的开发平台(环境) 语义化标签 header : 表示头部,块级元素 footer : 表示底部,块级元素 section :区块 nav : 表示导航链接 aside : 表示侧边栏 output &am…...
Apache iotdb-web-workbench 认证绕过漏洞(CVE-2023-24829)
漏洞简介 影响版本 0.13.0 < 漏洞版本 < 0.13.3 漏洞主要来自于 iotdb-web-workbench IoTDB-Workbench是IoTDB的可视化管理工具,可对IoTDB的数据进行增删改查、权限控制等,简化IoTDB的使用及学习成本。iotdb-web-workbench 中存在不正…...

【7-1】Redis急速入门与复习
文章目录1、分布式架构概述本阶段规划什么是分布式架构单体架构与分布式架构 对比分布式架构优点分布式架构缺点设计原则2、为何引入Redis现有架构的弊端3、什么是NoSql?NoSqlNoSql优点NoSql常见分类4、什么是分布式缓存,什么是Redis?什么是分…...
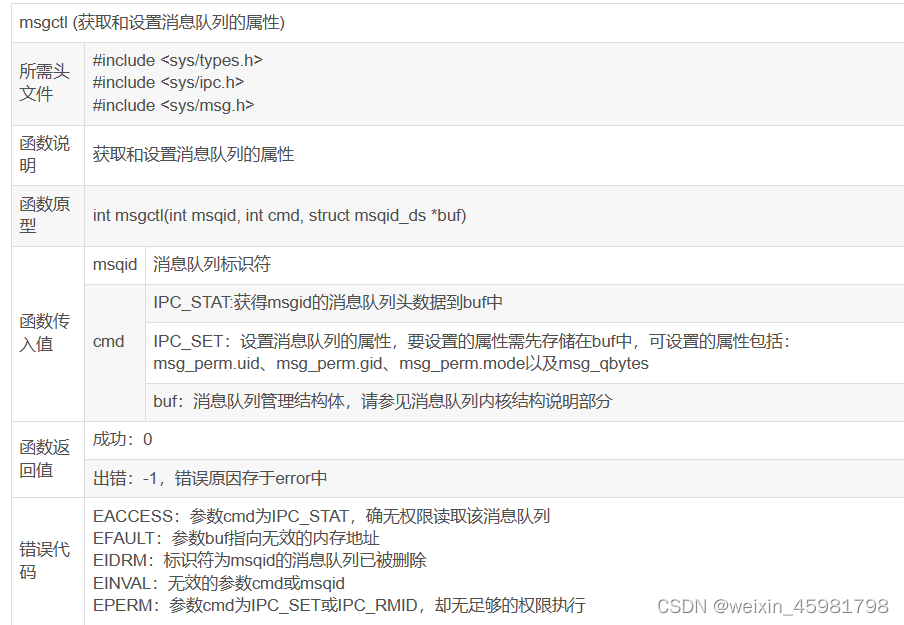
5、操作系统——进程间通信(3)(system V-IPC:消息队列)
目录 1、管道的缺点 2、消息队列 3、消息队列的API (1)获取消息队列的ID(类似文件的描述符)(msgget) (2)发送、接收消息(msgrcv) (3)获取和设置消息队列的属性(msgctl) 4、消息队…...
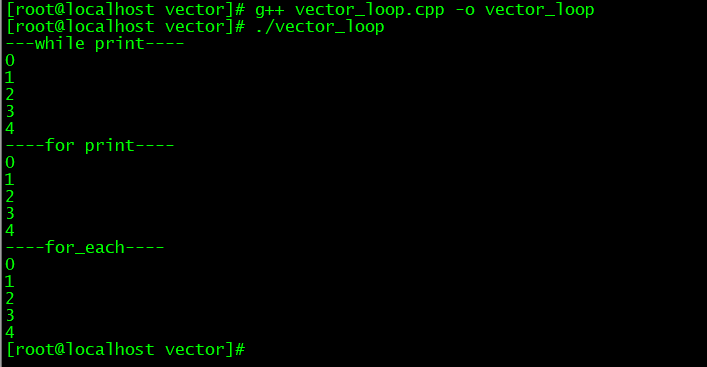
C++vector容器用法详解
一、前言vector 是封装动态数组的顺序容器,连续存储数据,所以我们不仅可以通过迭代器访问存储在 vector 容器中的数据,还能用指向 vector 容器中的数据的常规指针访问数据。这意味着指向 vector 容器中的数据的指针能传递给任何期待指向数组元…...

Log4j2的Loggers详解
引言 官方配置文档:https://logging.apache.org/log4j/2.x/manual/filters.html Loggers节点 Loggers节点常见的有两种:Root和Logger <Loggers><Logger name"org.apache.logging.log4j.core.appender.db" level"debug" additivity&qu…...

计算机视觉的应用1-OCR分栏识别:两栏识别三栏识别都可以,本地部署完美拼接
大家好,我是微学AI,今天给大家带来OCR的分栏识别。 一、文本分栏的问题 在OCR识别过程中,遇到文字是两个分栏的情况确实是一个比较常见的问题。通常情况下,OCR引擎会将文本按照从左到右,从上到下的顺序一行一行地识别…...

低代码平台如何选型, 43款国内外低代码平台一网打尽
目前,零代码技术和低代码技术越来越成熟,低代码平台也越来越被大家所接受,国内低代码平台厂商和产品层出不穷,到底哪家低代码平台好,企业如何选型,以下给出一些参考。 一、低代码平台如何选型 企业如何选…...
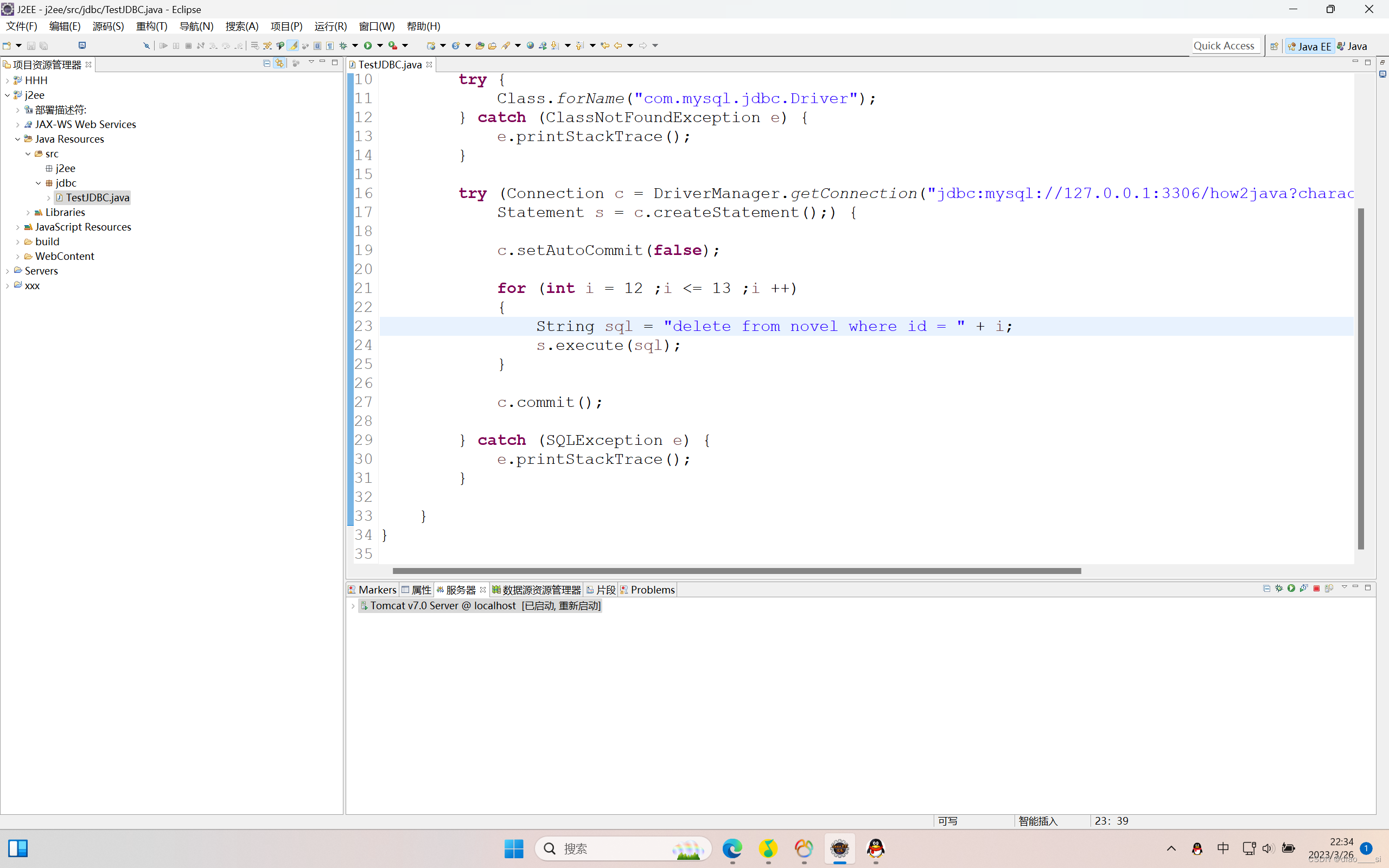
第六周作业(1.5小时)
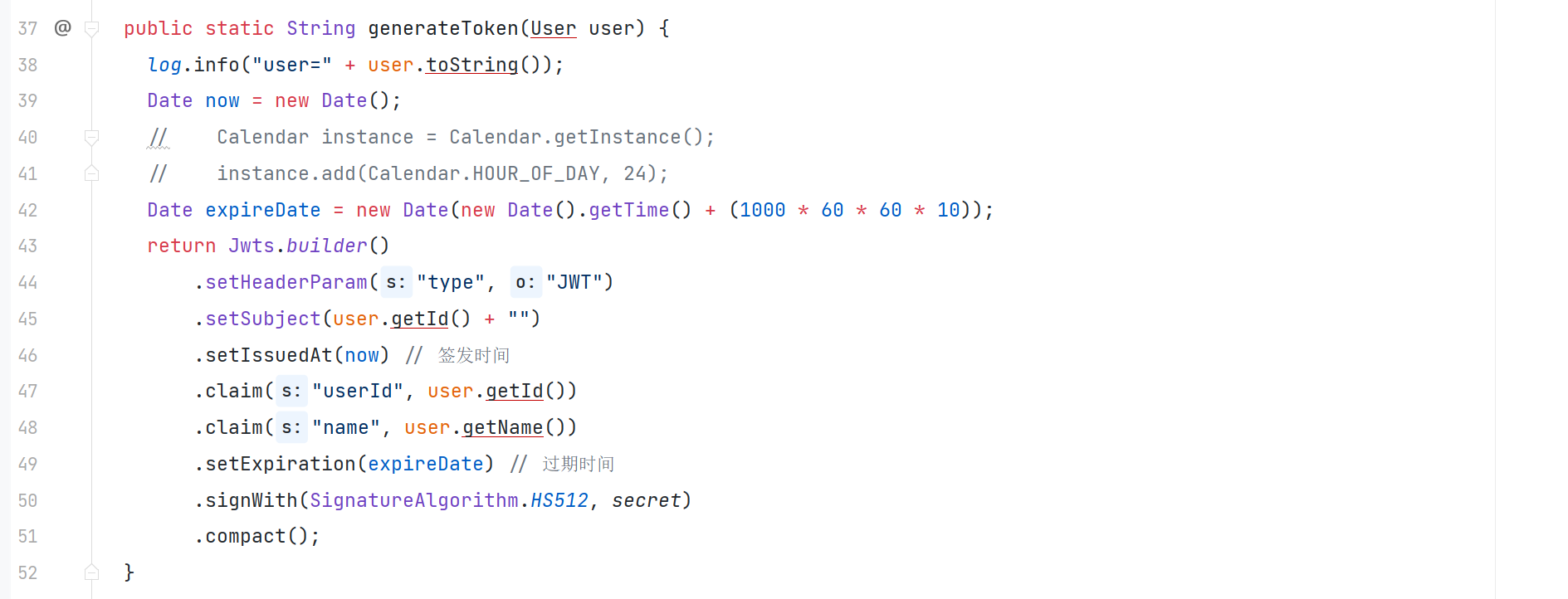
一、PreparedStatement PreparedStatement也可以用来执行sql语句,但是需要注意:它需要用sql创建好PreparedStatement,而Statement不需要用sql来创建。 优点: 1、具有较好的可维护性和可读性,参数的分别插入减少了错…...

排序 (蓝桥杯) JAVA
目录题目描述:冒泡排序算法(排序数字,字符):String与String buffer的区别:纯暴力破解(T到爆炸):暴力破解加思考(bingo):总结:题目描述: 小蓝最近学习了一些排序算法,其中冒泡排序让他…...

半导体测试数据分析难题?STDF Viewer提供一站式专业解决方案
半导体测试数据分析难题?STDF Viewer提供一站式专业解决方案 【免费下载链接】STDF-Viewer A free GUI tool to visualize STDF (semiconductor Standard Test Data Format) data files. 项目地址: https://gitcode.com/gh_mirrors/st/STDF-Viewer 半导体测试…...

利用Taotoken实现AI应用的高可用与容灾路由设计思路
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用Taotoken实现AI应用的高可用与容灾路由设计思路 应用场景类,探讨在构建对稳定性要求高的生产级AI应用时࿰…...

MATLAB许可排队严重?研发软件许可共享,不增购满足需求
我去年带着团队做自动驾驶算法验证,结果MATLAB许可证天天排队。每天早上团队成员像抢盲盒一样点开MATLAB,结果发现根本抢不到。我们项目组三人全用同一个许可证,项目延期三个月,研发效率直线下滑。这种乱象真的该结束了。问题本质…...

2026本地视频怎么去水印?5款免费去水印软件对比和实用方法指南
很多人都遇到过这个问题:辛辛苦苦保存下来的视频、素材库里的片段,上面都贴了水印,想要二次编辑或重新发布时,这些水印就成了"眼中钉"。本地视频怎么去水印?2026年有哪些靠谱的免费去水印方法?今…...

科研实战:三种高效获取ERA5再分析数据的路径解析
1. ERA5再分析数据基础认知 第一次接触ERA5数据时,我和大多数科研新手一样被各种专业术语搞得晕头转向。简单来说,ERA5就像给地球做CT扫描生成的全球气象体检报告,它能提供从1950年到现在,每小时更新的气温、降水、风速等上百种气…...

基于SpringBoot的共享汽车管理系统毕设源码
博主介绍:✌ 专注于Java,python,✌关注✌私信我✌具体的问题,我会尽力帮助你。一、研究目的本研究旨在构建一个基于Spring Boot与Vue框架的共享汽车管理系统以解决当前共享汽车行业在资源调度效率、用户服务体验以及数据安全等方面存在的核心问题。随着城…...

终极Fansly下载指南:5步快速掌握高效内容保存技巧
终极Fansly下载指南:5步快速掌握高效内容保存技巧 【免费下载链接】fansly-downloader Easy to use fansly.com content downloading tool. Written in python, but ships as a standalone Executable App for Windows too. Enjoy your Fansly content offline anyt…...

AVPlayer 卡顿、缓冲、加载失败问题根治与监控方案
在 iOS 音视频开发中,AVPlayer 作为系统原生播放器,凭借其稳定性、兼容性和低功耗优势,成为大多数 App 的首选。但在实际落地过程中,卡顿、缓冲异常、加载失败三大问题,却常常成为开发者的“拦路虎”——弱网环境下频繁…...

i.MX8M Plus开发板OV5640摄像头驱动配置与调试全攻略
1. 项目概述:为i.MX8M Plus开发板适配OV5640摄像头在嵌入式视觉项目里,无论是做安防监控、工业质检的“眼睛”,还是给机器人装上感知环境的“视觉”,第一步也是最基础的一步,就是把摄像头给跑起来。最近我在一个基于NX…...

2026春招AI人才争夺战白热化!小白程序员如何抓住13万高薪机遇?速收藏!
2026年春招显示AI领域岗位量同比增长8.7倍,成为职场新风口。具身智能岗位薪资暴增,AI科学家月薪高达13.2万元。高薪AI岗位紧缺,程序员需拥抱AI工具提升竞争力,否则面临被替代风险。AI能力已成为职场基础设施,不学AI可能…...