Selenium with Python学习笔记整理(网课+网站持续更新)
本篇是根据学习网站和网课结合自己做的学习笔记,后续会一边学习一边补齐和整理笔记
非常推荐白月黑羽的学习网站:
白月黑羽 (byhy.net)
https://selenium-python.readthedocs.io/getting-started.html#simple-usage
WEB UI自动化环境配置
(推荐靠谱的博客文章来进行环境配置,具体的我就不写了)
下载和安装 Python+下载和安装 PyCharm+安装 Selenium 库+下载浏览器驱动程序:
具体操作还得是看这两篇文章:
Selenium web UI自动化测试简介与环境搭建_selenium webui-CSDN博客
PyCharm 搭建 Selenium + Python 的自动化测试环境_pycharm自动化测试-CSDN博客
然后安装selenium的时候出现了安装不成功的问题,那就参考这篇文章:
安装selenium(超级详细)_selenium安装-CSDN博客
Chorme Driver安装链接在这,非常全了:
Chrome for Testing availability (googlechromelabs.github.io)
Anaconda安装教程参考这篇很实用:
Anaconda安装教程傻瓜教程_anaconda下没有usr目录-CSDN博客
遇到的问题及解决方法:
下载的谷歌浏览器驱动版本和selenium版本一致,但新版本selenium浏览器总是会退,解决方法:
在最后加个input()等待
选择元素的基本方法
find_element 和 find_elements 的区别
使用 find_elements 选择的是符合条件的 所有 元素, 如果没有符合条件的元素, 返回空列表
使用 find_element 选择的是符合条件的 第一个 元素, 如果没有符合条件的元素, 抛出 NoSuchElementException 异常
通过WebElement对象选择元素
WebDriver 对象 选择元素的范围是 整个 web页面
WebElement 对象 选择元素的范围是 该元素的内部
定位元素
eg:拿测试百度网页来看:
通过ID定位
在网页上通过 ID 定位一个元素(通常是一个输入框),然后向这个输入框中输入 "Selenium",最后打印出这个输入框的当前值。
# 1. By ID - 定位搜索输入框search_box_by_id = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "kw")))search_box_by_id.send_keys("Selenium") # 在输入框中输入"Selenium"print("Located by ID:", search_box_by_id.get_attribute("value"))-
WebDriverWait(driver, 10):- 这个部分表示对
driver(Selenium 的浏览器控制对象)进行最多 10秒 的等待时间。Selenium 中有隐式和显式等待,此处使用的是显式等待,即在指定时间内等待某个条件满足。
- 这个部分表示对
-
until(EC.presence_of_element_located((By.ID, "kw"))):until方法的作用是在指定的条件被满足前一直等待,或者直到超时。这里的条件是EC.presence_of_element_located,它会等待页面上某个元素(通过指定的定位方法,如ID)被找到并存在。(By.ID, "kw")表示通过 ID 属性定位页面上的元素,ID 的值是"kw"。这个ID通常用于唯一标识页面中的某个元素。
-
search_box_by_id.send_keys("Selenium"):send_keys方法用于在找到的输入框中模拟键盘输入。这里它向页面上的搜索框输入了 "Selenium" 这个字符串。
-
print("Located by ID:", search_box_by_id.get_attribute("value")):get_attribute("value")是获取输入框当前的值。它会打印出输入框中已经填入的内容,以确认"Selenium"已经正确输入。
按名称定位
通过 Name 或 ID 属性定位页面上的搜索按钮(最终是通过 ID "su" 定位),并模拟点击操作。
# 2. By Name - 定位搜索按钮# 定位搜索按钮(名称为wd),并点击按钮(百度按钮的ID实际为su,所以切换成用ID定位)。search_button_by_name = driver.find_element(By.NAME, "wd")search_button_by_name = driver.find_element(By.ID, "su") # 百度搜索按钮的ID为 "su"search_button_by_name.click()print("Located by Name: 搜索按钮点击成功")-
search_button_by_name = driver.find_element(By.NAME, "wd"):- 尝试通过按钮的 Name 属性来定位搜索按钮。
find_element(By.NAME, "wd")意思是寻找网页中name属性为"wd"的元素。但百度的搜索按钮并没有这个 name 属性,因此这段代码应该是示例中的注释部分,可能是最初的尝试。
- 尝试通过按钮的 Name 属性来定位搜索按钮。
-
search_button_by_name = driver.find_element(By.ID, "su"):- 由于百度的搜索按钮的实际ID为
"su",所以在这里使用 ID 来重新定位元素。find_element(By.ID, "su")表示通过元素的 ID(即"su")来找到这个元素。
- 由于百度的搜索按钮的实际ID为
-
search_button_by_name.click():click()方法用于模拟用户点击该按钮。这意味着一旦找到搜索按钮,Selenium 将自动执行点击操作,触发搜索功能。
按类名查找元素
输出该元素的 class 属性值,以确认定位是否正确。
# 3. By Class Name - 定位搜索输入框的父级容器parent_div_by_class_name = driver.find_element(By.CLASS_NAME, "s_form")print("Located by Class Name:", parent_div_by_class_name.get_attribute("class"))Class Name 是 HTML 元素的一个属性,用于标识多个元素共享的样式或功能,因此使用 Class Name 可以选择某些具有相同特征的元素。
按标签名称定位元素
输出找到的链接数量,方便确认是否正确定位了页面上的所有链接。
# 4. By Tag Name - 定位所有链接all_links_by_tag_name = driver.find_elements(By.TAG_NAME, "a")print(f"Located by Tag Name: 找到 {len(all_links_by_tag_name)} 个链接")-
all_links_by_tag_name = driver.find_elements(By.TAG_NAME, "a"):- 这行代码通过
TAG_NAME定位页面中的所有<a>标签。find_elements(By.TAG_NAME, "a")方法会返回一个包含所有链接元素的列表(每个链接都是由<a>标签定义的)。 - 这里的
find_elements返回多个元素,因此用find_elements而不是find_element。即使页面上有多个<a>标签,它也可以找到并返回所有的链接元素。
- 这行代码通过
-
print(f"Located by Tag Name: 找到 {len(all_links_by_tag_name)} 个链接"):len(all_links_by_tag_name)获取all_links_by_tag_name列表的长度,也就是找到的<a>标签的数量。- 使用
f-string格式化输出信息,将找到的链接数量插入到打印语句中,向用户反馈已经定位到多少个链接。
通过 XPath 定位
- 通过 XPath 精确定位页面中的百度新闻链接,确保链接的
href和class属性满足指定条件。 - 使用 显式等待 确保在指定的时间内,等待元素的加载,适应动态网页。
# 5.使用XPath来进行定位元素 定位新闻# CSSSelector中的href属性值需要使用引号包围news_link_by_xpath = WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.XPATH, "//a[@href='http://news.baidu.com' and @class='mnav c-font-normal c-color-t']")))-
WebDriverWait(driver, 20).until(...):WebDriverWait是 Selenium 提供的显式等待方法,用于等待某个条件成立。在这里,我们告诉 Selenium 最多等待 20 秒,直到元素被定位并可用为止。- 显式等待 是在特定条件下使用的,它可以等待某个元素出现或某个状态完成,适用于动态加载的页面。
-
EC.presence_of_element_located(...):EC是expected_conditions的缩写。presence_of_element_located表示等待某个元素在 DOM 中存在,但不一定可见。这里通过 XPath 指定我们要寻找的元素。
-
By.XPATH和 XPath 表达式:By.XPATH指定使用 XPath 定位元素。XPath 是一种用于查找 XML 或 HTML 文档中特定元素的路径语言,特别适合用于复杂结构或需要多条件筛选的情况。"//a[@href='http://news.baidu.com' and @class='mnav c-font-normal c-color-t']"://a:表示在整个页面中查找<a>标签(链接元素)。[@href='http://news.baidu.com']:指定href属性值必须是"http://news.baidu.com",也就是指向百度新闻的链接。[@class='mnav c-font-normal c-color-t']:指定class属性必须为'mnav c-font-normal c-color-t',确保只选择特定样式的链接。
通过链接文本查找超链接
- 通过部分链接文本定位包含“视频”一词的链接,并打印出该链接的完整文本。
- 适合用于无法预知链接的完整文本,但知道部分文本的场景。
# 6. By Partial Link Text - 定位部分文本包含"视频"的链接video_link_by_partial_link_text = driver.find_element(By.PARTIAL_LINK_TEXT, "视频")print("Located by Partial Link Text:", video_link_by_partial_link_text.text)-
driver.find_element(By.PARTIAL_LINK_TEXT, "视频"):- 这个方法使用 Partial Link Text 定位页面中的链接。
By.PARTIAL_LINK_TEXT允许通过部分链接文本进行定位,而不要求完整匹配链接文本。 - 这里寻找的是文本部分包含 “视频” 的链接(
<a>标签)。它只需要链接文本中含有 “视频” 这两个字,就可以定位到对应的元素。 find_element方法返回页面中第一个匹配的元素对象。
- 这个方法使用 Partial Link Text 定位页面中的链接。
-
video_link_by_partial_link_text.text:text属性用于获取找到的链接元素的可见文本。在这个例子中,video_link_by_partial_link_text.text会返回链接的完整文本内容。
通过 CSS 选择器定位元素
# 7. By CSS Selector - 定位百度logologo_by_css_selector = driver.find_element(By.CSS_SELECTOR, "#lg > img")print("Located by CSS Selector: 百度Logo已找到")-
driver.find_element(By.CSS_SELECTOR, "#lg > img"):- 这行代码通过 CSS Selector 定位元素,使用的是
find_element方法,它会返回页面中第一个符合条件的元素。 - CSS Selector 是一种灵活且强大的方式,允许我们通过 CSS 规则定位元素。它支持多种选择器类型,包括 ID、类、标签、属性等。
- 在这个例子中,
#lg > img表示选择 ID 为lg的元素下的 img 标签:#lg:表示一个 ID 为lg的元素(ID 选择器)。>:表示选择其直接子元素。img:表示一个 img 标签(图像元素)。
- 结合起来,这个选择器用于选择 ID 为
lg的元素内的 img 元素(通常是百度主页上的 Logo 图片)。
- 这行代码通过 CSS Selector 定位元素,使用的是
总体代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC# 初始化 WebDriver
service = Service(executable_path="D:/Apython/chromedriver.exe")
driver = webdriver.Chrome(service=service)# 打开百度主页
driver.get('https://www.baidu.com')try:# 1. By ID - 定位搜索输入框search_box_by_id = WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "kw")))search_box_by_id.send_keys("Selenium") # 在输入框中输入"Selenium"print("Located by ID:", search_box_by_id.get_attribute("value"))# 2. By Name - 定位搜索按钮# 定位搜索按钮(名称为wd),并点击按钮(百度按钮的ID实际为su,所以切换成用ID定位)。search_button_by_name = driver.find_element(By.NAME, "wd")search_button_by_name = driver.find_element(By.ID, "su") # 百度搜索按钮的ID为 "su"search_button_by_name.click()print("Located by Name: 搜索按钮点击成功")# 3. By Class Name - 定位搜索输入框的父级容器parent_div_by_class_name = driver.find_element(By.CLASS_NAME, "s_form")print("Located by Class Name:", parent_div_by_class_name.get_attribute("class"))# 4. By Tag Name - 定位所有链接all_links_by_tag_name = driver.find_elements(By.TAG_NAME, "a")print(f"Located by Tag Name: 找到 {len(all_links_by_tag_name)} 个链接")# 5.使用XPath来进行定位元素 定位新闻# CSSSelector中的href属性值需要使用引号包围news_link_by_xpath = WebDriverWait(driver, 20).until(EC.presence_of_element_located((By.XPATH, "//a[@href='http://news.baidu.com' and @class='mnav c-font-normal c-color-t']")))# 6. By Partial Link Text - 定位部分文本包含"视频"的链接video_link_by_partial_link_text = driver.find_element(By.PARTIAL_LINK_TEXT, "视频")print("Located by Partial Link Text:", video_link_by_partial_link_text.text)# 7. By CSS Selector - 定位百度logologo_by_css_selector = driver.find_element(By.CSS_SELECTOR, "#lg > img")print("Located by CSS Selector: 百度Logo已找到")# 8. By XPath - 定位搜索输入框search_box_by_xpath = driver.find_element(By.XPATH, "//input[@id='kw']")search_box_by_xpath.clear() # 清空输入框内容search_box_by_xpath.send_keys("XPath 选择器") # 再次输入print("Located by XPath:", search_box_by_xpath.get_attribute("value"))except Exception as e:print("An error occurred:", str(e))finally:# 关闭浏览器driver.quit()

元素操作
清除文本输入框
clear(self)
点击元素
click(self)
提交表单
submit(self)
发送信息
send_keys(self, *value)
WebElement 中常见的元素属性
获取元素属性
get_attribute(self, name)
判断元素可见
is_displayed(self)
判断元素可用
is_enabled(self)
判断元素是否被选中
is_selected(self)
WebElement 中常见的属性方法
获取元素位置
location
获取元素大小
size
获取元素的文本
text
设计模式(封装)
Pom模式+关键字驱动模式
po模式:page object model 页面对象模式。
好处:
解决:线性脚本的问题
解决:代码不能重复利用的问题
解决:后期的维护问题
票子:看过他们的仓库?日用品放一起,电器放一起,文具放一起
..分类
分三层 :
1.基础层:base 主要放selenium原生的方法,
2.页面对象层:po 主要用于放页面的元素和页面的动作。
3.测试用例层:testcase 存放测试用例以及测试数据,
页面对象层调用基础层的方法,测试用例层调用页面对象层的方法。

浏览器导航操作
等待界面元素出现
等待页面加载完成
Selenium Webdriver 提供两种类型的waits - 隐式和显式。 显式等待会让WebDriver等待满足一定的条件以后再进一步的执行。 而隐式等待让Webdriver等待一定的时间后再才是查找某元素。
在我们进行网页操作的时候, 有的元素内容不是可以立即出现的, 可能会等待一段时间。
比如 我们的股票搜索示例页面, 搜索一个股票名称, 我们点击搜索后, 浏览器需要把这个搜索请求发送给服务器, 服务器进行处理后,再把搜索结果返回给我们。
所以,从点击搜索到得到结果,需要一定的时间,
只是通常 服务器的处理比较快,我们感觉好像是立即出现了搜索结果。
搜索的每个结果 对应的界面元素 其ID 分别是数字 1, 2 ,3, 4 。。。
我们可以先用如下代码 将 第一个搜索结果里面的文本内容 打印出来
为什么呢?
因为我们的代码执行的速度比 网站响应的速度 快。
网站还没有来得及 返回搜索结果,我们就执行了如下代码
element = wd.find_element(By.ID, '1')
在那短暂的瞬间, 网页上是没有用 id为1的元素的 (因为还没有搜索结果呢)。自然就会报告错误 id为1 的元素不存在了。
那么怎么解决这个问题呢?
from selenium import webdriver
from selenium.webdriver.common.by import By# 创建 WebDriver 对象
wd = webdriver.Chrome()
"""
后续所有的 find_element 或者 find_elements 之类的方法调用 都会采用上面的策略:
如果找不到元素, 每隔 半秒钟 再去界面上查看一次, 直到找到该元素, 或者 过了10秒 最大时长
"""
# 隐式等待 以后创建 WebDriver 对象之后,都要条件反射的加上这个隐式等待
wd.implicitly_wait(10)try:# 调用WebDriver 对象的get方法 可以让浏览器打开指定网址wd.get('https://www.byhy.net/cdn2/files/selenium/stock1.html')# 根据id选择元素,返回的就是该元素对应的WebElement对象element = wd.find_element(By.ID, 'kw')# 通过该 WebElement对象,就可以对页面元素进行操作了# 比如输入字符串到 这个 输入框里element.send_keys('通讯\n')# 等待用户输入,以便观察当前页面状态input("按下任意键继续...")element = wd.find_element(By.ID,'go')element.click()#让这个代码执行不要那么块 网站响应的速度相对较慢# import time#问题是这里设置多长时间合适呢"""解决方法:当发现元素没有找到的时候,并不立即返回 找不到的 元素的错误而是周期(每隔半秒)重新寻找元素 直到元素找到或者超出指定最大等待时长,这时才 抛出异常(如果是 find_elements 之类的方法, 则是返回空列表)。"""# while True:# try:# # 网站还没有来得及 返回搜索结果,我们就执行了如下代码# element = wd.find_element(By.ID, '1')# print(element.text)# break# except:# time.sleep(1)"""但这样会出现死循环,这里要用implicitly_wait ,隐式等待 ,或者 全局等待 。该方法接受一个参数,用来指定 最大等待 时长"""element = wd.find_element(By.ID, '1')print(element.text)finally:# 关闭浏览器wd.quit()
显式等待
在代码中定义等待一定条件发生后再进一步执行代码。
最糟糕的案例是使用time.sleep(),它将条件设置为等待一个确切的时间段。 这里有一些方便的方法让你只等待需要的时间。WebDriverWait结合ExpectedCondition 是实现的一种方式。
隐式等待
如果某些元素不是立即可用的,隐式等待是告诉WebDriver去等待一定的时间后去查找元素。 默认等待时间是0秒,一旦设置该值,隐式等待是设置该WebDriver的实例的生命周期。
eg,拿百度首页先在输入框输入Selenium之后,等待一会儿在跳转视频模块进行举例
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time# 自定义等待类:等待元素具有特定的CSS类
class element_has_css_class(object):def __init__(self, locator, css_class):self.locator = locatorself.css_class = css_classdef __call__(self, driver):element = driver.find_element(*self.locator)if self.css_class in element.get_attribute("class"):return elementelse:return False# 初始化Chrome WebDriver
driver = webdriver.Chrome()try:# 访问百度首页driver.get("https://www.baidu.com")# 等待百度首页的搜索框加载并可点击search_box = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.ID, "kw")))print("搜索框已加载并可点击")# 在搜索框中输入关键词并提交search_box.send_keys("Selenium")search_box.submit()# 等待搜索结果页面加载,并等待搜索结果元素加载完成WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "content_left")))print("搜索结果页面已加载")# 通过CSS类检查搜索按钮是否加载完成并可点击# 使用自定的element_has_css_class 等待搜素按钮具备特定的CSS类 确保样式正确search_button = WebDriverWait(driver, 10).until(element_has_css_class((By.ID, "su"), "bg s_btn"))print("搜索按钮具备指定的CSS类")# 点击“新闻”链接,使用CSS Selector定位news_link = WebDriverWait(driver, 10).until(EC.element_to_be_clickable((By.LINK_TEXT,"视频")))news_link.click()print("已点击视频链接")# 等待新闻页面加载完成WebDriverWait(driver, 10).until(EC.title_contains("百度新闻"))print("百度新闻页面已加载")# 等待某个新闻板块可见news_section = WebDriverWait(driver, 10).until(EC.visibility_of_element_located((By.CSS_SELECTOR, ".news-nav-item")))print("新闻板块已加载")# 进一步操作,如点击具体的新闻标题等finally:# 等待几秒后关闭浏览器time.sleep(20)driver.quit()
eg,获取百度页面的 title 和 URL,并使用句柄方式切换窗口的例子:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import time# 创建一个 WebDriver 实例
driver = webdriver.Chrome()# 打开百度首页
driver.get("http://www.baidu.com")# 获取当前窗口的句柄
current_window_handle = driver.current_window_handle# 获取当前窗口的 title 和 URL
print("当前窗口的 title:", driver.title)
print("当前窗口的 URL:", driver.current_url)# 点击百度首页上的 "新闻" 链接,打开一个新窗口
driver.find_element(By.LINK_TEXT, "新闻").click()# 等待 2 秒,确保新窗口已经打开
time.sleep(2)# 获取所有窗口的句柄
all_window_handles = driver.window_handles# 遍历所有窗口的句柄
for window_handle in all_window_handles:# 如果当前窗口的句柄不是第一个窗口的句柄if window_handle != current_window_handle:# 切换到当前窗口driver.switch_to.window(window_handle)# 获取当前窗口的 title 和 URLprint("当前窗口的 title:", driver.title)print("当前窗口的 URL:", driver.current_url)# 关闭所有窗口
driver.quit()
页面对象
一个页面对象表示在你测试的WEB应用程序的用户界面上的区域。
使用页面对象模式的好处:
- 创建可复用的代码以便于在多个测试用例间共享
- 减少重复的代码量
- 如果用户界面变化,只需要修改一处
项目目录结构:
pythonProject/
├── po/
│ ├── __init__.py # 初始化文件
│ ├── element.py # 页面元素封装
│ └── page.py # 页面对象类定义
│
├── tests/
│ ├── __init__.py # 初始化文件
│ └── test_search.py # 测试用例
└── requirements.txt # 依赖文件
eg1:要自动化测试 Python 官方网站的搜索功能。具体步骤如下:
打开 Python 官网。
输入搜索关键字,例如 "pycon"。
点击搜索按钮。
验证搜索结果页面是否正确加载。
页面元素
po/element.py 中定义页面元素封装类
# 页面元素封装 包含基本的操作方法 例如查找元素、点击、发送文本等。
# 定位元素
from selenium.webdriver.common.by import By
# 处理页面加载时间不确定的情况,确保在操作元素之前它已经存在或可见。
from selenium.webdriver.support.ui import WebDriverWait
# expected_conditions (EC): 一个预定义的条件集,可以结合 WebDriverWait 使用。
# 例如,等待某个元素出现、可点击、页面标题包含某些内容等。
from selenium.webdriver.support import expected_conditions as EC# 封装了对页面元素的基本操作 查找 点击和输入文本
class BaseElement:def __init__(self, driver, by, value):# 与浏览器的交互self.driver = driver# 元素的定位方式self.by = by# 元素的定位值self.value = valuedef find_element(self):# 等待最多10秒钟,直到满足条件。如果 10# 秒内条件未满足,会抛出超时异常。return WebDriverWait(self.driver, 10).until(EC.presence_of_element_located((self.by, self.value)))# 通过find_element方法找到元素,然后执行点击操作。def click(self):self.find_element().click()# 向页面上的输入框元素发送文本(例如输入搜索关键词)def send_keys(self, text):# 先通过find_element方法找到元素,然后将文本text输入到该元素中。self.find_element().send_keys(text)页面对象类
po/page.py 中创建页面对象类
# 页面对象类定义 代表 Python 官网的首页以及搜索结果页面。
from po.element import BaseElement
from selenium.webdriver.common.by import By# 封装了主页上的操作:输入搜索关键词和点击搜索按钮。
class PythonOrgHomePage:def __init__(self, driver):self.driver = driver# search_box和go_button:这两个是定位器,用于定位主页上的搜索框和搜索按钮。# BaseElement类封装了元素的查找和操作逻辑,By.NAME, "q"和By.ID, "submit"指定了如何定位这些元素。self.search_box = BaseElement(driver, By.NAME, "q")self.go_button = BaseElement(driver, By.ID, "submit")# 用于在搜索框中输入搜索词。 term: 要输入的搜索关键词。def enter_search_term(self, term):self.search_box.send_keys(term)# term: 要输入的搜索关键词。找到搜索按钮并执行点击操作。def click_go_button(self):self.go_button.click()# 封装了搜索结果页面的验证逻辑。通过检查页面标题,它可以确定搜索是否成功。
class SearchResultsPage:def __init__(self, driver):self.driver = driverdef is_result_found(self):print("Current page title:", self.driver.title)return "Search Python.org" in self.driver.title测试用例
tests/test_search.py 中编写测试用例
# 测试用例
import unittest
from selenium import webdriver
from po.page import PythonOrgHomePage, SearchResultsPageclass PythonOrgSearchTest(unittest.TestCase):# 在每个测试用例执行之前调用,用于初始化测试环境。def setUp(self):self.driver = webdriver.Chrome() # 使用 Chrome 浏览器self.driver.get("https://www.python.org")def test_search_in_python_org(self):# 创建一个 PythonOrgHomePage实例,封装了主页上的操作。home_page = PythonOrgHomePage(self.driver)# 在搜索框中输入"pycon"home_page.enter_search_term("pycon")# 点击搜索按钮home_page.click_go_button()# 封装了搜索结果页面的操作。search_results_page = SearchResultsPage(self.driver)self.assertTrue(search_results_page.is_result_found())# 每个测试用例执行之后调用,用于清理测试环境。def tearDown(self):self.driver.quit()if __name__ == "__main__":unittest.main()
eg2,使用 Selenium WebDriver 和 unittest 框架,测试百度搜索功能
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as ECclass BaiduHomePage:def __init__(self, driver):self.driver = driver# 元组,用于指定搜索框和搜索按钮的定位方式(ID)。self.search_box = (By.ID, "kw")self.search_button = (By.ID, "su")# 在搜索框中输入搜索词# 等待搜索框出现# 超时时间为10s# 向搜索框中输入搜索词def enter_search_term(self, term):WebDriverWait(self.driver, 10).until(EC.presence_of_element_located(self.search_box)).send_keys(term)# 点击搜索按钮# 等待搜索按钮可点击,超时时间为 10 秒# 等待条件,元素可点击# 点击搜索按钮def click_search_button(self):WebDriverWait(self.driver, 10).until(EC.element_to_be_clickable(self.search_button)).click()class BaiduSearchResultsPage:def __init__(self, driver):self.driver = driver# 用于检查搜索结果页面是否正确加载def is_result_found(self):return "百度一下,你就知道" in self.driver.title
test_baidu_search.py(测试用例)
import unittest
from selenium import webdriver
from page import BaiduHomePage, BaiduSearchResultsPageclass TestBaiduSearch(unittest.TestCase):# 在每个测试用例执行前执行一次,用于初始化测试环境。def setUp(self):self.driver = webdriver.Chrome()self.driver.get("https://www.baidu.com")def test_baidu_search(self):home_page = BaiduHomePage(self.driver)home_page.enter_search_term("Python")home_page.click_search_button()search_results_page = BaiduSearchResultsPage(self.driver)self.assertTrue(search_results_page.is_result_found())def tearDown(self):self.driver.quit()if __name__ == "__main__":unittest.main()
相关文章:
Selenium with Python学习笔记整理(网课+网站持续更新)
本篇是根据学习网站和网课结合自己做的学习笔记,后续会一边学习一边补齐和整理笔记 非常推荐白月黑羽的学习网站: 白月黑羽 (byhy.net) https://selenium-python.readthedocs.io/getting-started.html#simple-usage WEB UI自动化环境配置 (推荐靠谱…...

1.随机事件与概率
第一章 随机时间与概率 1. 随机事件及其运算 1.1 随机现象 确定性现象:只有一个结果的现象 确定性现象:结果不止一个,且哪一个结果出现,人们事先并不知道 1.2 样本空间 样本空间:随机现象的一切可能基本…...

Redis结合Caffeine实现二级缓存:提高应用程序性能
本文将详细介绍如何使用CacheFrontend和Caffeine来实现二级缓存。 1. 简介 CacheFrontend: 是一种用于缓存的前端组件或服务。通俗的讲:该接口可以实现本地缓存与redis自动同步,如果本地缓存(JVM级)有数据,则直接从本…...

【LLM】Ollama:本地大模型 WebAPI 调用
Ollama 快速部署 安装 Docker:从 Docker 官网 下载并安装。 部署 Ollama: 使用以下命令进行部署: docker run -d -p 11434:11434 --name ollama --restart always ollama/ollama:latest进入容器并下载 qwen2.5:0.5b 模型: 进入 O…...
Excel监听以及常用工具类)
SpringBoot集成阿里easyexcel(二)Excel监听以及常用工具类
EasyExcel中非常重要的AnalysisEventListener类使用,继承该类并重写invoke、doAfterAllAnalysed,必要时重写onException方法。 Listener 中方法的执行顺序 首先先执行 invokeHeadMap() 读取表头,每一行都读完后,执行 invoke()方法…...

使用ELK Stack进行日志管理和分析:从入门到精通
在现代IT运维中,日志管理和分析是确保系统稳定性和性能的关键环节。ELK Stack(Elasticsearch, Logstash, Kibana)是一个强大的开源工具集,广泛用于日志收集、存储、分析和可视化。本文将详细介绍如何使用ELK Stack进行日志管理和分…...

前端框架对比与选择
🤖 作者简介:水煮白菜王 ,一位资深前端劝退师 👻 👀 文章专栏: 前端专栏 ,记录一下平时在博客写作中,总结出的一些开发技巧✍。 感谢支持💕💕💕 目…...
Springboot jPA+thymeleaf实现增删改查
项目结构 pom文件 配置相关依赖: 2.thymeleaf有点类似于jstlel th:href"{url}表示这是一个链接 th:each"user : ${users}"相当于foreach,对user进行循环遍历 th:if进行if条件判断 {变量} 与 ${变量}的区别: 4.配置好application.ym…...
【YashanDB知识库】yashandb执行包含带oracle dblink表的sql时性能差
本文内容来自YashanDB官网,具体内容请见https://www.yashandb.com/newsinfo/7396959.html?templateId1718516 问题现象 yashandb执行带oracle dblink表的sql性能差: 同样的语句,同样的数据,oracle通过dblink访问远端oracle执行…...

效率工具推荐 | 高效管理客服中心知识库
人工智能AI的广泛应用,令AI知识库管理已成为优化客服中心运营的核心策略之一。一个高效、易用且持续更新的知识库不仅能显著提升客服代表的工作效率,还能极大提升客户的服务体验。而高效效率工具如HelpLook,能够轻松搭建AI客服帮助中心&#…...
综合实验1 利用OpenCV统计物体数量
一、实验简介 传统的计数方法常依赖于人眼目视计数,不仅计数效率低,且容易计数错误。通常现实中的对象不会完美地分开,需要通过进一步的图像处理将对象分开并计数。本实验巩固对OpenCV的基础操作的使用,适当的增加OpenCV在图像处…...
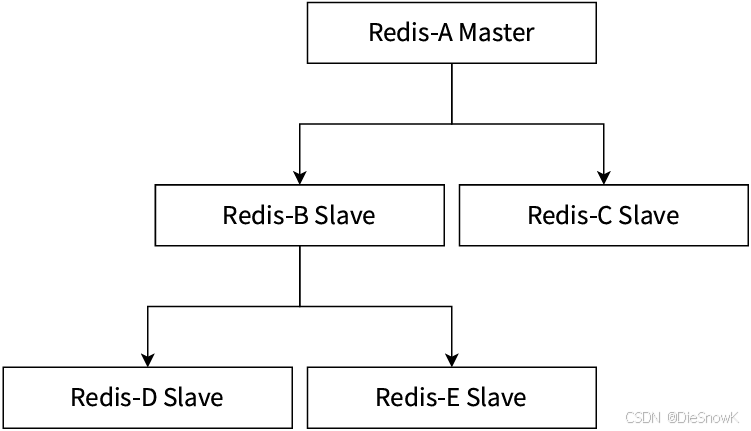
[Redis][主从复制][上]详细讲解
目录 0.前言1.配置1.建立复制2.断开复制3.安全性4.只读5.传输延迟 2.拓扑1.一主一从结构2.一主多从结构2.树形主从结构 0.前言 说明:该章节相关操作不需要记忆,理解流程和原理即可,用的时候能自主查到即可主从复制? 分布式系统中…...

【算法】leetcode热题100 146.LRU缓存. container/list用法
https://leetcode.cn/problems/lru-cache/description/?envTypestudy-plan-v2&envIdtop-100-liked 实现语言:go lang LRU 最近最少未使用,是一种淘汰策略,当缓存空间不够使用的时候,淘汰一个最久没有访问的存储单元。目前…...

[论文总结] 深度学习在农业领域应用论文笔记13
文章目录 1. Downscaling crop production data to fine scale estimates with geostatistics and remote sensing: a case study in mapping cotton fibre quality (Precision Agriculture ,2024, IF5.585)背景方法结果结论个人总…...
《Detection of Tea Leaf Blight in Low-Resolution UAV Remote Sensing Images》论文阅读
学习资料 论文题目:Detection of Tea Leaf Blight in Low-Resolution UAV Remote Sensing Images(低分辨率UAV遥感图像中茶叶枯萎病的检测)论文地址:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp&arnumber10345618 Abstr…...
低代码BPA(业务流程自动化)技术探讨
一、BPA流程设计平台的特点 可视化设计工具 大多数BPA流程设计平台提供直观的拖拽式界面,用户可以通过图形化方式设计、修改及优化业务流程。这种可视化的方式不仅降低了门槛,还便于非技术人员理解和参与流程设计。集成能力 现代BPA平台通常具备与其他系…...
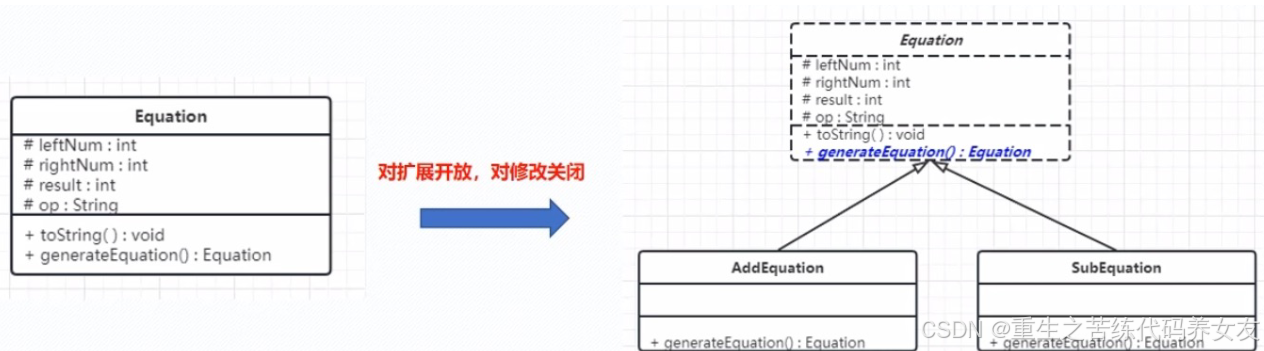
开闭原则(OCP)
开闭原则(OCP):Open Closed Princide:对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有代码,实现一个热插拔的效果。 简言之,是为了使程序的扩展性更好,…...

Unity之 TextMeshPro 介绍
TextMeshPro 是 Unity 中用于处理文本显示的高级插件,旨在替代 Unity 内置的 UI.Text 和 TextMesh 组件。与默认的文本组件相比,TextMeshPro 提供了更高的文本渲染质量和更多的文本样式选项,同时具备强大的优化能力。 TextMeshPro 的主要特点…...
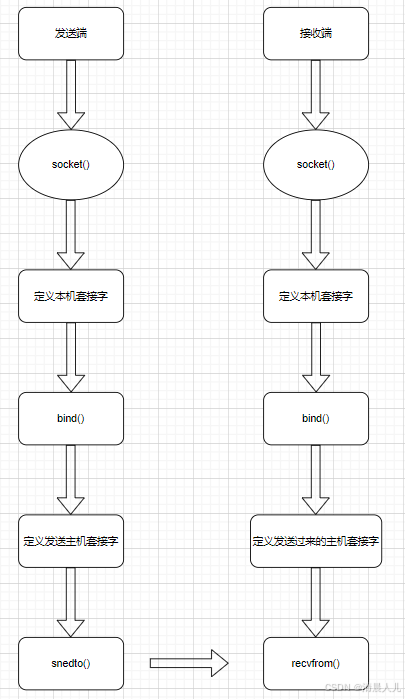
Linux套接字Socket
Linux套接字Socket 前提知识补充 为不同机器上的两个进程之间提供通信机制 主机字节序小端存储,网络字节序大端存储 特点TCPUDP连接类型面向连接无连接可靠性高低有序性保证数据包按顺序到达不保证数据包顺序流量控制有滑动窗口机制无拥塞控制有拥塞控制机制无复杂性较高较低…...
基于 Web 的工业设备监测系统:非功能性需求与标准化数据访问机制的架构设计
目录 案例 【说明】 【问题 1】(6 分) 【问题 2】(14 分) 【问题 3】(5 分) 【答案】 【问题 1】解析 【问题 2】解析 【问题 3】解析 相关推荐 案例 阅读以下关于 Web 系统架构设计的叙述,回答问题 1 至问题 3 。 【说明】 某公司拟开发一款基于 Web 的…...

国产碳化硅MOSFET在通讯电源PFC中的应用与实战解析
1. 项目概述:当通讯电源遇上国产碳化硅MOSFET最近在做一个通讯电源的PFC(功率因数校正)项目,客户对效率、功率密度和可靠性提出了近乎苛刻的要求。传统的硅基MOSFET方案,在追求更高开关频率以减小磁性元件体积时&#…...

MOOTDX:Python通达信数据接口的完整指南
MOOTDX:Python通达信数据接口的完整指南 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx MOOTDX是一个专为量化投资和股票数据分析设计的Python通达信数据接口封装库,它提供…...

3分钟搞定Windows安卓应用:APK安装器让你的电脑秒变安卓设备!
3分钟搞定Windows安卓应用:APK安装器让你的电脑秒变安卓设备! 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你知道吗?现在无需安装…...
)
告别安装报错!Windows 10/11 保姆级 MySQL 5.7.44 配置指南(含my.ini文件详解)
Windows 10/11 下 MySQL 5.7.44 终极安装指南:从避坑到精通配置 每次在Windows系统上安装MySQL,总会有那么几个"经典"错误让人抓狂——服务启动失败、初始化报错、环境变量配置无效... 作为一个经历过无数次安装折磨的老手,我决定…...

终极免费MGit:在手机上管理Git仓库的完整解决方案
终极免费MGit:在手机上管理Git仓库的完整解决方案 【免费下载链接】MGit A Git client for Android. 项目地址: https://gitcode.com/gh_mirrors/mg/MGit 你是否曾经在通勤路上灵感迸发,却苦于无法立即提交代码?或者需要在移动设备上快…...

内容创作团队如何利用多模型API提升图文生成效率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 内容创作团队如何利用多模型API提升图文生成效率 对于新媒体运营、电商内容或市场团队而言,持续产出高质量的图文内容是…...
)
手把手教你用逻辑分析仪抓取RF433遥控器信号(附我家窗帘遥控器完整解码过程)
手把手教你用逻辑分析仪抓取RF433遥控器信号(附我家窗帘遥控器完整解码过程) 无线遥控技术早已渗透进日常生活,从车库门到智能窗帘,这些设备背后的RF433MHz通信协议却像黑匣子般神秘。本文将用一台百元级的逻辑分析仪和常见的超外…...

HoRain云--VS Code 创建与使用 Skill
🎬 HoRain 云小助手:个人主页 ⛺️生活的理想,就是为了理想的生活! ⛳️ 推荐 前些天发现了一个超棒的服务器购买网站,性价比超高,大内存超划算!忍不住分享一下给大家。点击跳转到网站。 目录 ⛳️ 推荐 …...

DLSS Swapper终极指南:一键管理游戏超采样文件,免费提升显卡性能
DLSS Swapper终极指南:一键管理游戏超采样文件,免费提升显卡性能 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款专为NVIDIA、AMD和Intel显卡用户设计的智能超采样文件管理工…...
动态加载)
PyQt5开发避坑:别再手动编译.ui文件了,试试uic.loadUi()动态加载
PyQt5高效开发:uic.loadUi()动态加载技术深度解析 在快速迭代的GUI开发过程中,PyQt5开发者常陷入一个效率陷阱——每次修改界面后都需要手动执行pyuic编译命令。这种重复性操作不仅打断开发流状态,还会在频繁调整阶段浪费大量时间。本文将揭示…...