面试系列-携程暑期实习一面
Java 基础
1、Java 中有哪些常见的数据结构?
图片来源于:JavaGuide
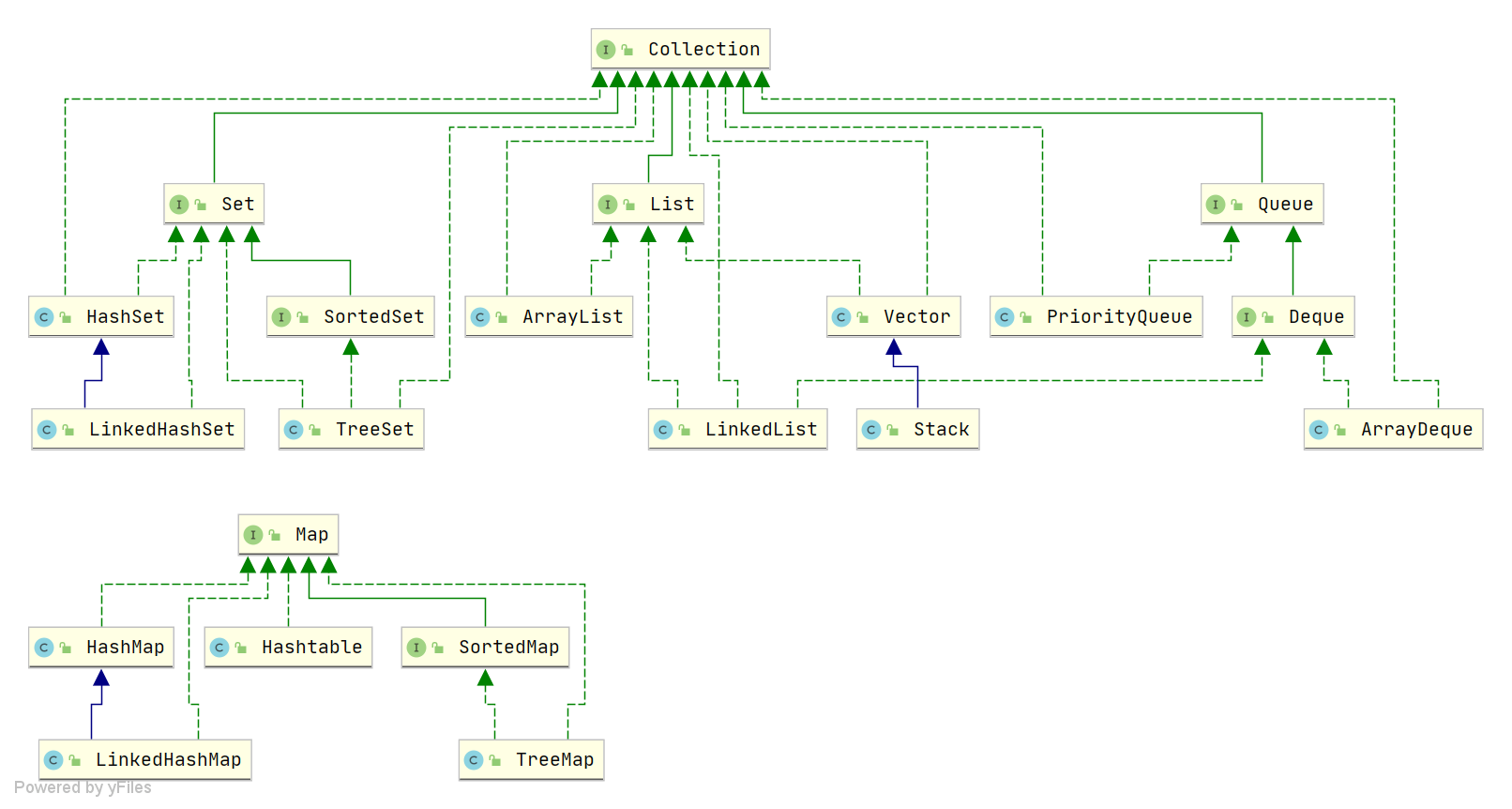
Java 中常见的数据结构包含了 List、Set、Map、Queue,在回答的时候,只要把经常使用的数据结构给说出来即可,不需要全部记住
如下:
List 列表: 有 ArrayList、LinkedList
1、ArrayList 是动态数组
2、LinkedList 是双向链表
Set 集合: 有 HashSet、LinkedHashSet、TreeSet
1、HashSet 基于 HashMap 实现,不保证元素的顺序,利用 Map 的 key 不能重复保证元素的唯一性
2、LinkedHashSet 继承自 HashSet,基于 LinkedHashMap 实现,通过链表维护元素的插入顺序
3、TreeSet 基于红黑树实现,元素自然排序或指定排序器排序
Map 哈希映射: 有 HashMap、LinkedHashMap、TreeMap、ConcurrentHashMap
1、HashMap 基于数组+链表+红黑树实现
2、LinkedHashMap 继承自 HashMap,通过链表维护元素插入顺序
3、TreeMap 基于红黑树实现,会对元素的 key 进行自然排序或指定排序器排序
4、ConcurrentHashMap 并发安全的 HashMap,在 JDK1.8 及以后通过 CAS + synchronized 实现线程安全
Queue 队列: 有 PriorityQueue、ArrayDeque
1、PriorityQueue 基于优先级堆的优先队列实现,元素自然排序或指定排序器排序
2、ArrayDeque 基于数组的双端队列
2、HashMap 介绍一下,key 可以设置为 null 吗?
HashMap 是哈希结构,存储 k-v 键值对,底层实现的话由数组+链表+红黑树进行实现
HashMap 中是可以存储 null 的 key 或 value 的,在 HashMap 中,为 null 的 key 只有一个,当传入 key 为 null 的时候,就会返回数组中索引为 0 的位置
3、ConcurrentHashMap 的 key 可以为 null 吗?
在 ConcurrentHashMap 中的 key 和 value 是不可以为 null 的
大家可以思考一下,为什么 HashMap 中 key 可以为 null,ConcurrentHashMap 中不可以呢?
ConcurrentHashMap 是并发安全的,因此是在多线程环境中使用的,如果 key 或者 value 可以为 null 的话,那么就会存在 二义性
因为一个线程在操作 ConcurrentHashMap 的时候,其他线程也有可能同时来进行修改,因此会存在 二义性 的问题:
如果 key 为 null,就无法区分这个 key 是否存在于 ConcurrentHashMap 中;如果 value 为 null,就无法区分这个 value 是不存在 ConcurrentHashMap 中还是该 value 被置为了 null
HashMap 中的 key 和 value 为什么可以为 null?
而 HashMap 中的 key 和 value 可以为 null 就是因为 HashMap 是并发不安全的,因此使用 HashMap 的话,都是在单线程环境下使用,一个线程操作的时候,其他的线程不会同时操作,因此不会存在二义性问题
那么为什么 ConcurrentHashMap 源码不设计成可以判断是否存在 null 值的 key?
如果 key 为 null,那么就会带来很多不必要的麻烦和开销。比如,你需要用额外的数据结构或者标志位来记录哪些 key 是 null 的,而且在多线程环境下,还要保证对这些额外的数据结构或者标志位的操作也是线程安全的。而且,key 为 null 的意义也不大,因为它并不能表示任何有用的信息。
4、如果多线程同时操作一个数据,会有什么问题,怎么解决?
会存在线程安全的问题,只需要控制多个线程之间的操作同步,并且对该变量添加 volatile 关键字,保证该变量对多个线程的可见性即可
控制多个线程之间操作同步的话,通过 synchronized 或者 ReentrantLock 进行控制即可
5、线程池介绍一下,线程池的参数中最大线程数可以设得比核心线程数小吗?
介绍线程池的时候,说一下线程池的几个核心参数,以及线程池的工作流程
线程池中重要的参数如下:
-
corePoolSize:核心线程数量 -
maximumPoolSize:线程池最大线程数量 = 核心线程数+非核心线程数 -
keepAliveTime:非核心线程存活时间 -
unit:空闲线程存活时间单位(keepAliveTime单位) -
workQueue:工作队列(任务队列),存放等待执行的任务-
LinkedBlockingQueue:无界的阻塞队列,最大长度为 Integer.MAX_VALUE -
ArrayBlockingQueue:基于数组的有界阻塞队列,按FIFO排序 -
SynchronousQueue:同步队列,不存储元素,对于提交的任务,如果有空闲线程,则使用空闲线程来处理;否则新建一个线程来处理任务 -
PriorityBlockingQueue:具有优先级的无界阻塞队列,优先级通过参数Comparator实现。
-
-
threadFactory:线程工厂,创建一个新线程时使用的工厂,可以用来设定线程名、是否为daemon线程等等。 -
handler: 拒绝策略 ,有4种-
AbortPolicy :直接抛出异常,默认策略 -
CallerRunsPolicy:用调用者所在的线程来执行任务 -
DiscardOldestPolicy:丢弃阻塞队列里最老的任务,也就是队列里靠前的任务 -
DiscardPolicy :当前任务直接丢弃
-
新加入一个任务,线程池处理流程如下:
-
如果核心线程数量未达到,创建核心线程执行 -
如果当前运行线程数量已经达到核心线程数量,查看任务队列是否已满 -
如果任务队列未满,将任务放到任务队列 -
如果任务队列已满,看最大线程数是否达到,如果未达到,就新建非核心线程处理 -
如果当前运行线程数量未达到最大线程数,则创建非核心线程执行 -
如果当前运行线程数量达到最大线程数,根据拒绝策略处理
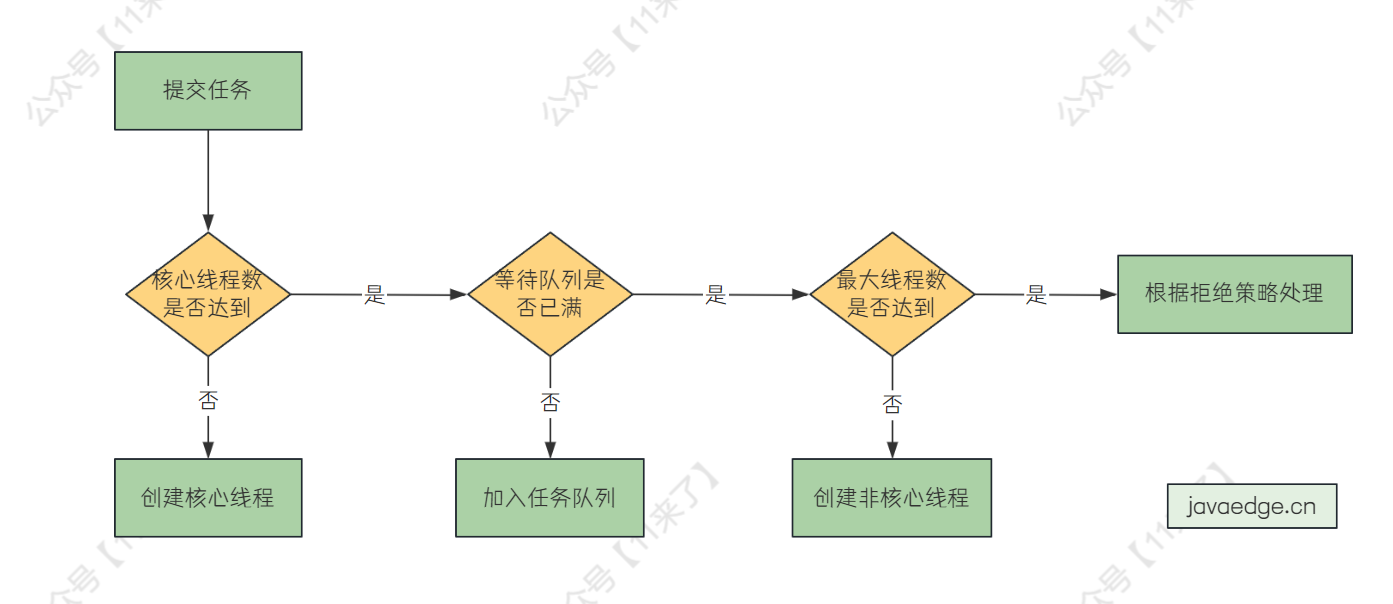
线程池的参数中最大线程数可以设得比核心线程数小吗?
这个一般对于线程池有了解的都不会这么设置,最大线程数 = 核心线程数 +非核心线程数,所以最大线程数不可能比核心线程数还要小,这是错误的使用方式
JVM
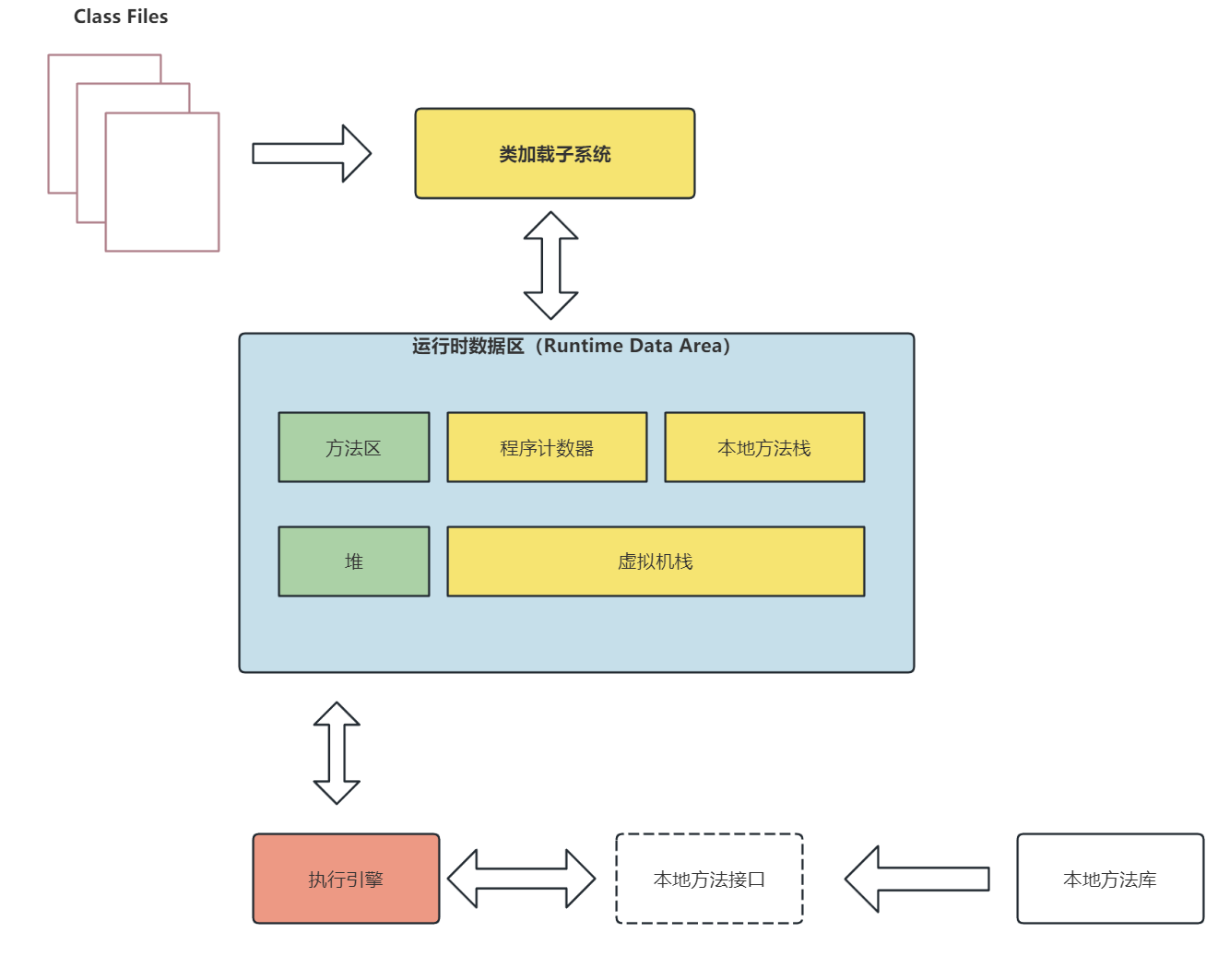
6、JVM 内存结构
JVM 的内存结构分为:堆、虚拟机栈、本地方法栈、方法区
堆 主要存储 JVM 中创建的对象,堆是多个线程共享的空间
方法区 主要存储编译后的 Java 代码,也就是 class 文件的信息
虚拟机栈 包括了一个个的栈帧,每执行一个方法,都会为该方法生成一个栈帧压入虚拟机栈中,当执行完该方法之后,就会将该栈帧弹出虚拟机栈,这个虚拟机栈是 线程私有 的,方法中的一些局部变量也会在该栈帧中进行存储
本地方法栈 类似于虚拟机栈,里边的栈帧就是使用到的本地方法,本地方法指的是底层的非 Java 代码,因为 Java是一门高级语言,我们不直接与操作系统资源、系统硬件打交道。如果想要直接与操作系统与硬件打交道,就需要使用到本地方法了
程序计数器 用于存储当前线程所执行的字节码指令的行号,让线程知道下一次要执行哪一个字节码指令,程序计数器是线程私有的
JVM 整体结构图如下:
7、垃圾回收算法和垃圾回收器都讲一下
垃圾回收算法有:标记-清除算法、复制算法、标记-压缩算法、分代回收算法
标记-清除算法 会从 GC Roots 开始遍历,将可到达的对象做标记,标记为存活对象,那么其他未标记的对象就是需要对象,将垃圾对象清除掉即可
缺点就是会产生内存碎片
复制算法 需要将内存区域分成大小相等的两块,当需要 GC 时,将其中一块内存区域中的存活对象复制到另外一块区域,再将原来的一块内存区域清空即可
优点是不会产生内存碎片,缺点是存在比较大的空间浪费
标记-压缩算法 是基于标记-清除算法的改进,先标记存活对象,之后将所有存活对象压缩到内存的一端,清除边界以外的垃圾对象即可
优点是既解决了标记-清除算法出现内存碎片的问题,又解决了复制算法中空间浪费的问题,但是效率低于复制算法
分代收集算法 是将 Java 堆分为新生代和老年代,这样就可以对不同生命周期的对象采取不同的收集方式,因为新生代中的对象生命周期短,存活率低,适合使用 复制算法 ,老年代生命周期长,存活率高,适合使用 标记-清除 或 标记-压缩 算法
垃圾收集器
有 8 种垃圾回收器,分别用于不同分代的垃圾回收:
-
新生代回收器:Serial、ParNew、Parallel Scavenge -
老年代回收器:Serial Old、Parallel Old、CMS -
整堆回收器:G1、ZGC
这里就不重复介绍了,可以参考 :JVM垃圾收集器
JDK1.8 中默认的垃圾收集器是 Parallel Scavenge(新生代)+Parallel Old(老年代)
公司中一般使用指定 G1 作为垃圾收集器的比较多 ,因为 G1 的特点就是天生适合用于大内存机器,无论内存多大,都可以指定期望的 GC 停顿时间,这样不至于停顿时间太长,导致用户体验卡顿
8、有看过 GC 日志吗
GC 日志的话可以通过 gceasy 工具进行分析,首先需要设置 VM Options 来开启 GC 日志打印:
# 开启 GC 日志创建更详细的 GC 日志
-XX:+PrintGCDetails
# 开启 GC 时间提示
-XX:+PrintGCTimeStamps,-XX:+PrintGCDateStamps
# 打印堆的GC日志
-XX:+PrintHeapAtGC
# 指定GC日志路径
-Xloggc:./logs/gc.log
分析 GC 日志的话,就是将生成的 gc.log 日志文件放入 gceasy 工具进行分析,分析的话主要看以下这几个重要的参数:
1、新生代、老年代、元空间占用情况: 看一下分配的空间大小以及峰值空间大小,来判断是否空间分配不合理,在 JDK1.8 中,如果不指定元空间大小,默认的初始值为 21MB,最大值为系统内存大小,元空间太小会导致频繁 Full GC 来提升元空间大小,因此这一点要注意
2、平均/最大 GC 暂停时间: 看一下暂停时间有没有特别长,如果特别长,说明是存在问题的
3、GC 持续时间/GC 次数: 判断 GC 持续时间是否过长、GC 次数是否频繁,如果 Full GC 较为频繁,也是存在问题的(因为 Full GC 比较慢,要减少 Full GC 次数),之后就要分析 Full GC 原因,看看是有大对象、还是产生非常多的对象、还是元空间初始值太小了
详细 GC 日志分析可参考:通过 gceasy工具对生成的 GC 日志进行分析
MQ
9、项目中的 RocketMQ 怎么保证消息一定发出去且收到了?
这里问的就是 RocketMQ 如何保证消息的可靠性,避免消息在传输过程中丢失了
RocketMQ 作为分布式消息中间件,肯定是要尽可能保证消息传输的 可靠性 ,要保证消息的可靠性,先来思考一下从哪些方面保证呢?
这要看消息的生命周期,既然保证可靠性,那么就是要保证 A 发送给 B 的消息一定可以成功,那么首先要保证发送成功,其次要保证 B 接收成功,而在 RocketMQ 中,消息是先发送到 Broker 中了,那么还需要保证 MQ 在 Broker 中不会丢失
因此 RocketMQ 是从三方面保障了消息的可靠性:
-
保证 生产者发送消息 的可靠性 -
保证 Broker 存储消息 的可靠性 -
保证 消费者消费消息 的可靠性
发送消息的可靠性
RocketMQ 在发送端保证发送消息的可靠性主要就是通过 重试机制 来实现的
生产者发送消息分为了 同步发送 、 异步发送 、单向发送 三种方式:
-
同步发送 :发送消息后,阻塞线程等待消息发送结果 -
异步发送 :发送消息后,并不会阻塞等待,回调任务会在另一个线程中执行 -
单向发送 :发送消息后,立即返回,不返回消息发送是否成功,因此不可以保证发送消息的可靠性
只有单向发送没有消息可靠性的保证,在 同步 和 异步 发送中,都可以通过设置发送消息的 重试次数 来保证发送端的可靠性,默认重试次数为 2 次
并且还可以设置如果发送失败,尝试发送到其他 Broker 节点
// 同步设置重试次数
producer.setRetryTimesWhenSendFailed(3)
// 异步设置重试次数
producer.setRetryTimesWhenSendAsyncFailed(3);
// 如果发送失败,是否尝试发送到其他 Broker 节点
producer.setRetryAnotherBrokerWhenNotStoreOK(true);
存储消息的可靠性
可靠性保证一:消息落盘存储保证消息的可靠性
在消息发送到 Broker 之后,Broker 会将消息存储在磁盘中,这样如果 Broker 异常宕机之后,可以读取磁盘中的数据来保证消息的 可靠性
RocketMQ 如何存储消息:
RocketMQ 会先将消息写入到操作系统的 page cache 中,之后消息刷入磁盘分为了 同步刷盘 和 异步刷盘 两种方式, 默认是异步刷盘方式
page cache 就是将文件映射到内存中,这样直接操作内存比较快,避免了频繁的磁盘 IO
Broker 通过 page cache 和 异步刷盘 在保证消息可靠性的前提下,还尽可能提升了消息写入的性能
在 Broker 端写入消息的流程如下:
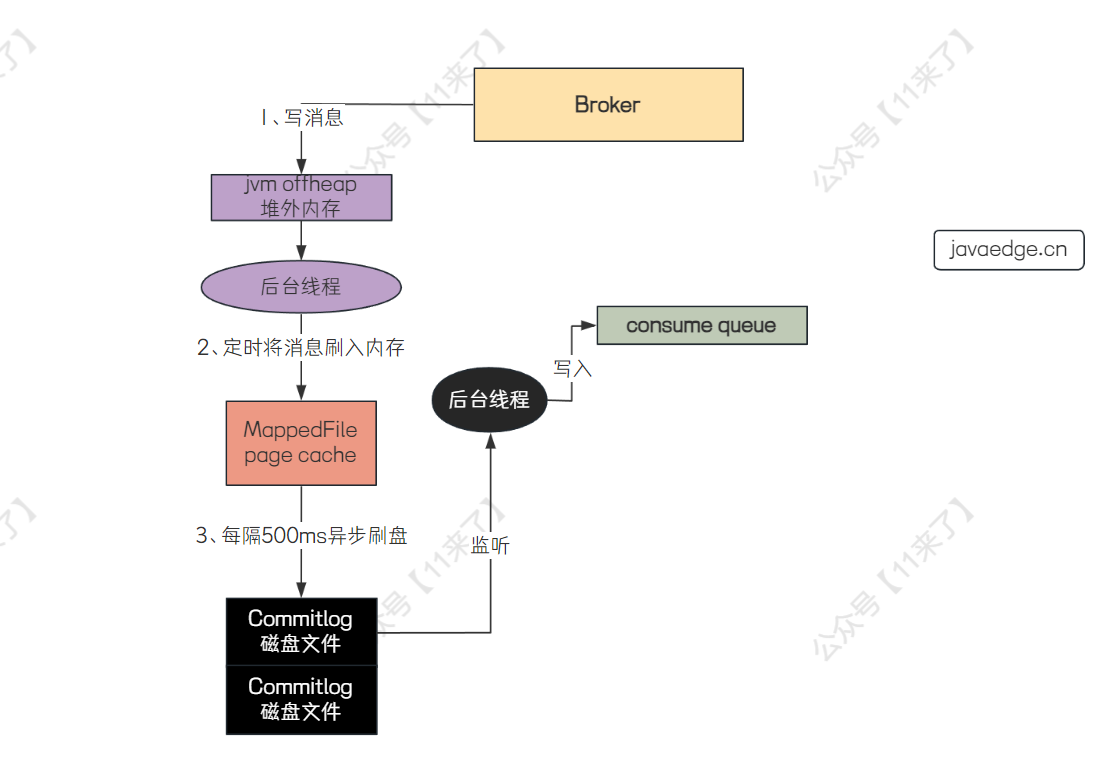
可以看到,这里写消息先写在了 JVM 的 堆外内存 中,而不是直接写在了 page cache 中,这是 RocketMQ 提供的 transientStorePoolEnabled(瞬时存储池启用)机制 来实现内存级别的读写分离(需要开启 transientStorePoolEnabled(瞬时存储池启用)机制 才会先写入 JVM 的堆外内存)
为什么要将消息先写在 堆外内存 呢?如果高并发的读写请求都直接落在 page cache 中的话,那么会导致对 page cache 的竞争太过于激烈,因此令写请求操作 堆外内存 ,读请求操作 page cache ,实现 读写分离 ,避免高并发情况下对 page cache 的激烈竞争
可靠性保证二:主从复制保证 Broker 的消息可靠性
上边是通过将消息写入磁盘来保证 Broker 存储端的消息可靠性,还有另一种方式:对 Broker 采用一主多从的方式部署,通过 主从复制 来保证消息的可靠性
在 Broker 主从复制时,会将 master 节点的消息同步到 slave 节点,slave 节点作为 master 节点的 热备份 存在,保证消息的可靠性
消费消息的可靠性
消费者为了保证消息的可靠性: 会先消费消息,再提交消息消费成功的状态 ,不过可能会出现 重复消费 的情况,因此需要业务方保证 幂等性 来解决重复消费的问题(可以建立一张消息消费表来避免重复消费)
可靠性保证一:消息重试保证可靠性
消费者只有返回 CONSUME_SUCCESS 才算消费完成,如果返回 CONSUME_LATER 则会按照不同的延迟时间再次消费,如果消费满 16 次之后还是未能消费成功,则会将消息发送到死信队列
可靠性保证二:死信队列保证可靠性
如果消息最终重试消费失败,并不会立即丢弃,而是将消息放入到了死信队列,之后还可以通过 MQ 提供的接口获取对应的消息, 保证消费消息的可靠性
本文由 mdnice 多平台发布
相关文章:
面试系列-携程暑期实习一面
Java 基础 1、Java 中有哪些常见的数据结构? 图片来源于:JavaGuide Java集合框架图 Java 中常见的数据结构包含了 List、Set、Map、Queue,在回答的时候,只要把经常使用的数据结构给说出来即可,不需要全部记住 如下&…...
你以为建站很复杂?Baklib 5分钟解决你的痛点
你以为建站很复杂?Baklib 5分钟解决你的痛点! 在这个“快节奏”的互联网时代,想要快速搭建一个网站是很多人的刚需。今天我要介绍的,就是如何利用Baklib的CMS/Wiki模板,五分钟内让你的网站“横空出世”。废话不多说&am…...

极狐GitLab 17.4 重点功能解读【二】
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 学习极狐GitLab 的相关资料: 极狐GitLab 官网极狐…...

LVS-DR实战案例,实现四层负载均衡
环境准备:三台虚拟机(NET模式或者桥接模式) 192.168.88.200 (web1)(安装nginx服务器作为测试) 192.168.88.201 (服务器)(用于部署lvs-dr) 192.168.88.202 (web2)…...

网游和3A类型游戏的CPU选择分析
目录 1. CPU性能基础 1.1 主频 1.2 三级缓存(L1、L2、L3缓存) 1.3 架构 1.4 单核与多核性能 2. 游戏类型分析 2.1 网游:以《永劫无间》为例 多核性能需求: 单核性能需求: CPU选择建议: 2.2 3A类…...

2024免费录屏软件的宝藏功能与实用技巧
在手机上操作很多时候为了记录方便都直接截图或者录屏,其实电脑也一样。现在面向电脑的录屏工具纷繁复杂,很容易让我们挑花了眼。今天这篇文章我将介绍几款免费的录屏软件为大家提供参考。 1.福昕录屏大师 链接达达:www.foxitsoftware.cn/R…...

linux---进程程序替换详解
提示:以下是本篇文章正文内容,下面案例可供参考 一、程序替换的原理 我们可以创建子进程通过程序替换,来执行不同的程序。程序替换不会重新创建子进程,我们通过程序替换函数,内核将磁盘中的可执行程序和数据加载到内存…...

笔试编程-百战成神——Day01
1.数字统计 题目来源:数字统计——牛客网 测试用例 算法原理 根据题目我们知道,首先要输出两个数字确定一个区间,寻找这个区间内数字中所有包含2的个数,比如12包含一个2,22包含两个2,以此类推,所以我们的…...

Qt+toml文件读写
Qttoml 使用 cpptoml 库示例Qt 项目中的代码示例 解释注意事项 在Qt中使用TOML(Tom’s Obvious, Minimal Language)格式的文件,可以通过第三方库来实现,例如 cpptoml。TOML是一种易于阅读和写入的配置文件格式,与JSON…...

浅谈C++之指针
一、基本介绍 在C中,指针是一种复杂的数据类型,它存储了另一个变量的内存地址。通过指针,程序可以直接访问和操作内存,这为编程提供了极大的灵活性和效率,但同时也增加了复杂性和潜在的错误风险。 二、指针的概念 指针…...

在虚幻引擎中实时显示帧率
引擎自带了显示帧率的功能 但是只能在编辑器中显示 , 在游戏发布后就没有了 , 所以我们要自己做一个 创建一个控件蓝图 创建画布和文本 , 修改文本 文本绑定函数 , 点击创建绑定 添加一个名为 FPS 的变量 格式化文本 用大括号把变量包起来 {FPS Int} FPS 然后转到事件图表…...

Apache Iceberg构建高性能数据湖
1. 概述 大数据时代的挑战 随着信息技术和互联网的迅猛发展,我们正处于一个数据爆炸的时代。企业和组织每天都在生成和收集海量的数据,这些数据来自于社交媒体、物联网设备、传感器、交易系统等各种来源。如何高效地存储、管理和分析这些庞大的数据集&…...

【图像压缩与重构】基于标准+改进BP神经网络
课题名称:基于标准改进BP神经网络的图像压缩与重构(带GUI) 代码获取方式(付费): 相关资料: 1. 代码注释 2.BP神经网络原理文档资料 3.图像压缩原理文档资料 程序实例截图: 1. 基于标准BP神经网络的图…...
介绍)
函数式编程(以Python编程语言为例)介绍
函数式编程(以Python编程语言为例)介绍 何为函数式编程? 函数式编程(Functional Programming),不要误以为就是用函数编程。函数式编程确实涉及使用函数,但它不仅仅是“用函数编程”那么简单。 …...

银河麒麟操作系统中查看动态库函数的方法
银河麒麟操作系统中查看动态库函数的方法 1、查看单个动态库中的函数2、查找特定函数位于哪个动态库中 💖The Begin💖点点关注,收藏不迷路💖 在Linux系统,包括银河麒麟操作系统中,动态库(.so文件…...

开放麒麟openkylin
开源社区: openKylin: openKylin 社区的愿景是:在开源、自愿、平等和协作的基础上,由基础软硬件企业、非营利性组织、社团组织、高等院校、科研机构和个人开发者共同创立的一个开源社区。 下载地址: openKylin开源操作系统 安…...

用Python与OpenCV的实践:实时面部对称性分析
目录 思路分析 整体代码 效果展示 总结 在当今计算机视觉领域,人脸识别和分析技术得到了广泛应用。无论是安全验证、社交媒体应用,还是美学研究,人脸特征的提取和分析都是关键技术之一。在这篇博客中,我们将深入探讨一个有趣的…...
)
第三十三章 使用派生密钥令牌进行加密和签名 - 使用 DerivedKeyToken _进行加密(一)
文章目录 第三十三章 使用派生密钥令牌进行加密和签名 - 使用 <DerivedKeyToken> 第三十三章 使用派生密钥令牌进行加密和签名 - 使用 进行加密(一) 如果加密了任何安全标头元素,请将它们添加到 WS-Security 标头元素中。为此&#…...

Structure-Aware Transformer for Graph Representation Learning
Structure-Aware Transformer for Graph Representation Learning(ICML22) 摘要 Transformer 架构最近在图表示学习中受到越来越多的关注,因为它通过避免严格的结构归纳偏差而仅通过位置编码对图结构进行编码,自然地克服了图神经…...
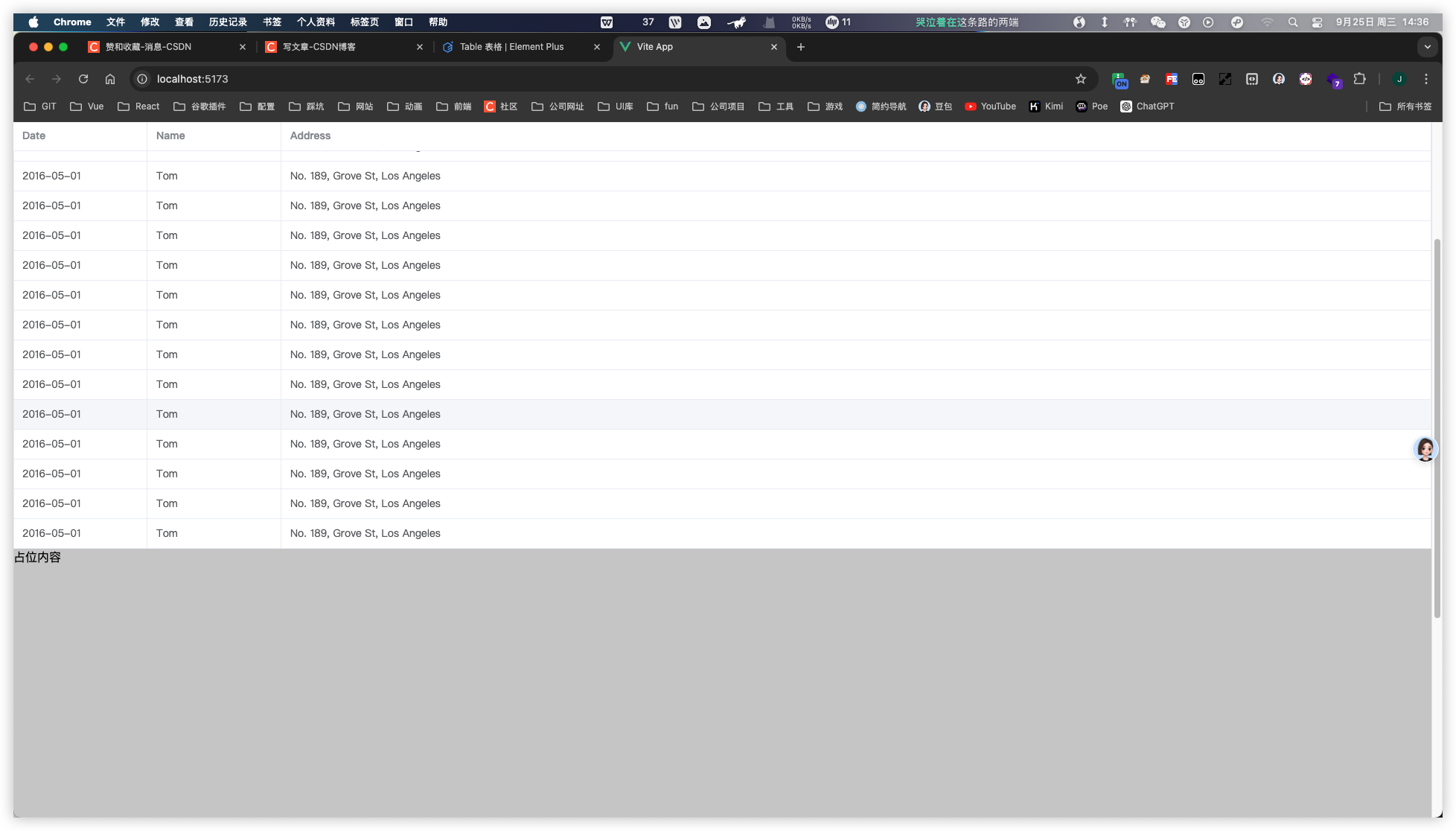
滚动页面,el-table表头始终置顶
效果如下: 起始状态: 滚动后: 代码地址:代码地址-面包多...

Flutter GetX实战:从Provider迁移到GetX,我的开发效率提升了多少?
Flutter GetX实战:从Provider迁移到GetX的效率革命 当Flutter开发团队面临状态管理方案的选择时,往往会陷入一种甜蜜的烦恼——官方推荐的Provider虽然稳定可靠,但第三方库GetX却以"全家桶"式的解决方案不断吸引开发者的目光。作为…...

ADXL335模拟传感器读数不稳?手把手教你用Arduino进行软件滤波与校准
ADXL335模拟传感器读数不稳?手把手教你用Arduino进行软件滤波与校准 当你把ADXL335加速度计接入Arduino,兴奋地跑起第一个测试程序时,那些跳动的数字可能很快会浇灭你的热情。原始读数像得了疟疾般颤抖,静止时本该稳定的1g重力加速…...

ncmdumpGUI:3分钟解锁网易云音乐ncm格式,让你的音乐无处不在
ncmdumpGUI:3分钟解锁网易云音乐ncm格式,让你的音乐无处不在 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 还在为网易云音乐下载的nc…...

JVM调优实战:让你的服务性能提升50%
一、背景 线上一个核心订单服务,QPS 3000左右,经常出现接口超时告警。监控显示: 平均RT: 180ms(要求<100ms)Full GC频率: 每天20次,每次STW 1.5sCPU使用率: 峰值85%服务规格: 8C16G,堆内存…...

OpenClaw实战教程:声明式配置驱动的高效数据抓取方案
1. 项目概述:一个关于“OpenClaw”的实战教程 最近在GitHub上看到一个挺有意思的项目,叫“OpenClawTuto”。光看名字,你可能会有点摸不着头脑,这“OpenClaw”到底是个啥?是某种开源机械爪?还是一个代号&…...

Legacy-iOS-Kit完整指南:如何让老旧iPhone和iPad重获新生
Legacy-iOS-Kit完整指南:如何让老旧iPhone和iPad重获新生 【免费下载链接】Legacy-iOS-Kit An all-in-one tool to restore/downgrade, save SHSH blobs, jailbreak legacy iOS devices, and more 项目地址: https://gitcode.com/gh_mirrors/le/Legacy-iOS-Kit …...

ITK-SNAP医学图像分割:破解三维解剖结构提取的工程难题
ITK-SNAP医学图像分割:破解三维解剖结构提取的工程难题 【免费下载链接】itksnap ITK-SNAP medical image segmentation tool 项目地址: https://gitcode.com/gh_mirrors/it/itksnap 当我们面对复杂的脑部MRI数据、肿瘤CT扫描或心血管影像时,最大…...

FPGA与GPU在OSOS-ELM算法中的性能对比与优化
1. 项目概述在边缘计算和实时信号处理领域,极端学习机(ELM)因其独特的训练机制和高效的计算性能而备受关注。OSOS-ELM作为ELM的一种变体,通过在线顺序学习机制进一步提升了算法的实用性。这项研究聚焦于FPGA和GPU两种硬件平台在执行OSOS-ELM算法时的性能…...

安得医疗冲刺港股:年营收9亿,利润1.5亿 上海亿瑞控制41%股权
雷递网 雷建平 5月16日山东安得医疗用品股份有限公司(简称:“安得医疗”)日前递交招股书,准备在港交所上市。截至2023年、2024年及2025年12月31日止年度,安得医疗分别宣派及派付股息6670万元、4670万元及4000万元。年营…...

保姆级教程:用STM8S207R6和FD6288T自制BLDC驱动板,从原理图到代码框架搭建
从零构建BLDC驱动板:STM8S207R6与FD6288T实战指南 在创客和嵌入式开发领域,无刷直流电机(BLDC)控制一直是兼具挑战性和实用性的热门方向。与有刷电机相比,BLDC电机具有高效率、长寿命和低噪音等优势,但驱动电路和控制系统也更为复…...