【理论推导】变分自动编码器 Variational AutoEncoder(VAE)
变分推断 (Variational Inference)
变分推断属于对隐变量模型 (Latent Variable Model) 处理的一种技巧,其概率图如下所示

我们将 X={x1,...xN}X=\{ x_1,...x_N \}X={x1,...xN} 看作是每个样本可观测的一组数据,而将对应的 Z={z1,...,zN}Z=\{z_1,...,z_N\}Z={z1,...,zN} 看作是该组数据对应的高维空间下的对应样本点,例如使用 XXX 表示一个班同学的所有成绩,而将 ZZZ 看作是同学的学习能力。对于更复杂的一些情况,例如图像生成任务,使用 XXX 表示数据集中的每张图像,而使用 ZZZ 表示更高维的信息,例如基于类别/语义等控制信息。
对于生成任务,我们经常希望利用观测数据 XXX 建模随机变量 xxx 的真实分布 p(x)p(x)p(x),使用 zzz 来辅助概率推导,那么核心点在于计算两个条件概率分布 p(x∣z)p(x|z)p(x∣z) 与 p(z∣x)p(z|x)p(z∣x),通常可以使用一些先验知识假定 p(x∣z)p(x|z)p(x∣z) 服从某种概率分布(例如对于学习能力为 ggg 的同学成绩假定服从在 ggg 附近的高斯分布),但对于 p(z∣x)p(z|x)p(z∣x),注意到
p(z∣x)=p(z)p(x∣z)p(x)p(z|x) = \frac{p(z)p(x|z)}{p(x)} p(z∣x)=p(x)p(z)p(x∣z)
zzz 是辅助建模的变量,可以假定其服从某已知的分布,但对于归一化项 p(x)p(x)p(x),有
p(x)=∫zp(x,z)dz=∫zp(z)p(x∣z)dzp(x) = \int_z p(x,z)dz = \int_z p(z) p(x|z) dz p(x)=∫zp(x,z)dz=∫zp(z)p(x∣z)dz
由于 zzz 是一个非常高维的信息,p(x)p(x)p(x) 是很难直接计算积分进行处理的,所以 p(z∣x)p(z|x)p(z∣x) 也是很难处理的,我们通常使用优化的方法来拟合出概率分布 p(z∣x)p(z|x)p(z∣x)
首先,我们考虑随机变量 zzz 与 xxx 之间的关系,假定 p(x)p(x)p(x) 表示真实的数据分布,即我们观测到的数据 x∼p(x)x\sim p(x)x∼p(x),q(z∣x)q(z|x)q(z∣x) 为任一条件概率分布(通常是使用模型拟合出来的分布),有
logp(x)=logp(x,z)−logp(z∣x)=logp(x,z)q(z∣x)−logp(z∣x)q(z∣x)\begin{align} \log p(x) &= \log p(x,z) - \log p(z|x) \nonumber \\&=\log\frac{p(x,z)}{q(z|x)} - \log\frac{p(z|x)}{q(z|x)} \nonumber \end{align} logp(x)=logp(x,z)−logp(z∣x)=logq(z∣x)p(x,z)−logq(z∣x)p(z∣x)
对左右两式计算关于隐变量 zzz 的期望,有
left=Ez∼q(z∣x)[logp(x)]=logp(x)∫zq(z∣x)dz=logp(x)right=Ez∼q(z∣x)[logp(x,z)q(z∣x)−logp(z∣x)q(z∣x)]=∫zq(z∣x)logp(x,z)q(z∣x)dz+∫zq(z∣x)logq(z∣x)p(z∣x)dz=∫zq(z∣x)logp(x,z)q(z∣x)dz+KL(q(z∣x)∣∣p(z∣x))\begin{align} \text{left} &= \mathbb E_{z\sim q(z|x)}[\log p(x)] = \log p(x) \int_z q(z|x) dz = \log p(x) \nonumber \\\text{right} &= \mathbb E_{z\sim q(z|x)}[\log\frac{p(x,z)}{q(z|x)} - \log\frac{p(z|x)}{q(z|x)}] = \int_z q(z|x) \log\frac{p(x,z)}{q(z|x)} dz + \int_z q(z|x) \log\frac{q(z|x)}{p(z|x)} dz \nonumber \\ &= \int_z q(z|x) \log\frac{p(x,z)}{q(z|x)} dz + \text{KL}(q(z|x)||p(z|x)) \nonumber \end{align} leftright=Ez∼q(z∣x)[logp(x)]=logp(x)∫zq(z∣x)dz=logp(x)=Ez∼q(z∣x)[logq(z∣x)p(x,z)−logq(z∣x)p(z∣x)]=∫zq(z∣x)logq(z∣x)p(x,z)dz+∫zq(z∣x)logp(z∣x)q(z∣x)dz=∫zq(z∣x)logq(z∣x)p(x,z)dz+KL(q(z∣x)∣∣p(z∣x))
其中 ∫zq(z∣x)logp(x,z)q(z∣x)dz\int_z q(z|x) \log\frac{p(x,z)}{q(z|x)} dz∫zq(z∣x)logq(z∣x)p(x,z)dz 被称作是信心下界 (Evidence Lower Bound),简单记作 ELBO,名字来源是由于KL散度满足恒大于等于0的性质,因此有 logp(x)≥ELBO\log p(x)\geq \text{ELBO}logp(x)≥ELBO,当 q(z∣x)=p(z∣x)q(z|x) = p(z|x)q(z∣x)=p(z∣x) 时取等,因此我们有如下公式
logp(x)=ELBO+KL(q(z∣x)∣∣p(z∣x))≥ELBO\begin{align} \log p(x) = \text{ELBO}+\text{KL}(q(z|x)||p(z|x)) \geq \text{ELBO} \end{align} logp(x)=ELBO+KL(q(z∣x)∣∣p(z∣x))≥ELBO
如果我们希望 q(z∣x)q(z|x)q(z∣x) 逼近真实条件概率分布 p(z∣x)p(z|x)p(z∣x),在观测数据 xxx 给定的情况下,最小化KL散度等价于最大化ELBO
假定 q(z∣x)q(z|x)q(z∣x) 表示的概率分布由参数 ϕ\phiϕ 决定(例如使用神经网络表示 qϕq_\phiqϕ,我们一般不改变网络结构,而只针对参数进行优化),那么该拟合问题的优化目标如下所示
ϕ^=argmaxϕELBO\hat{\phi} = \arg\max_\phi \text{ELBO} ϕ^=argϕmaxELBO
如果我们采用随机梯度下降法来进行优化 (Stochastic Gradient Varational Inference),首先要计算 ϕ\phiϕ 的导数
▽ϕELBO=▽ϕ∫zqϕ(z∣x)logp(x,z)qϕ(z∣x)dz=∫z▽ϕqϕ(z∣x)logp(x,z)qϕ(z∣x)dz+∫zqϕ(z∣x)▽ϕlogp(x,z)qϕ(z∣x)dz\begin{align} \triangledown_\phi \text{ELBO} &= \triangledown_\phi \int_z q_\phi(z|x) \log\frac{p(x,z)}{q_\phi(z|x)} dz \nonumber \\ &= \int_z \triangledown_\phi q_\phi(z|x) \log\frac{p(x,z)}{q_\phi(z|x)} dz + \int_z q_\phi(z|x) \triangledown_\phi \log\frac{p(x,z)}{q_\phi(z|x)} dz \nonumber \end{align} ▽ϕELBO=▽ϕ∫zqϕ(z∣x)logqϕ(z∣x)p(x,z)dz=∫z▽ϕqϕ(z∣x)logqϕ(z∣x)p(x,z)dz+∫zqϕ(z∣x)▽ϕlogqϕ(z∣x)p(x,z)dz
注意到,对于第二项,有
∫zqϕ(z∣x)▽ϕlogp(x,z)qϕ(z∣x)dz=−∫zqϕ(z∣x)▽ϕlogqϕ(z∣x)dz=−∫z▽ϕqϕ(z∣x)dz=−▽ϕ∫zqϕ(z∣x)dz=0\int_z q_\phi(z|x) \triangledown_\phi \log\frac{p(x,z)}{q_\phi(z|x)} dz = - \int_z q_\phi(z|x) \triangledown_\phi \log q_\phi(z|x) dz = - \int_z \triangledown_\phi q_\phi(z|x) dz = - \triangledown_\phi \int_z q_\phi(z|x) dz = 0 ∫zqϕ(z∣x)▽ϕlogqϕ(z∣x)p(x,z)dz=−∫zqϕ(z∣x)▽ϕlogqϕ(z∣x)dz=−∫z▽ϕqϕ(z∣x)dz=−▽ϕ∫zqϕ(z∣x)dz=0
因此,有如下等式
▽ϕELBO=∫zqϕ(z∣x)▽ϕlogqϕ(z∣x)logp(x,z)qϕ(z∣x)dz=Ez∼qϕ(z∣x)[▽ϕlogqϕ(z∣x)logp(x,z)qϕ(z∣x)]\begin{align} \triangledown_\phi \text{ELBO} &= \int_z q_\phi(z|x) \triangledown_\phi \log q_\phi(z|x) \log\frac{p(x,z)}{q_\phi(z|x)} dz \nonumber \\ &= \mathbb E_{z\sim q_\phi(z|x)}[\triangledown_\phi \log q_\phi(z|x) \log\frac{p(x,z)}{q_\phi(z|x)}] \end{align} \nonumber ▽ϕELBO=∫zqϕ(z∣x)▽ϕlogqϕ(z∣x)logqϕ(z∣x)p(x,z)dz=Ez∼qϕ(z∣x)[▽ϕlogqϕ(z∣x)logqϕ(z∣x)p(x,z)]
使用 Monto-Carlo 采样方法计算期望,即 zi∼qϕ(z∣x)(i=1...L)z_i \sim q_\phi(z|x) \;\;(i=1...L)zi∼qϕ(z∣x)(i=1...L)
▽ϕELBO≈1L∑i=1L▽ϕlogqϕ(zi∣x)logp(x,zi)qϕ(zi∣x)\triangledown_\phi \text{ELBO} \approx \frac{1}{L} \sum_{i=1}^L \triangledown_\phi \log q_\phi(z_i|x) \log\frac{p(x,z_i)}{q_\phi(z_i|x)} ▽ϕELBO≈L1i=1∑L▽ϕlogqϕ(zi∣x)logqϕ(zi∣x)p(x,zi)
注意到,式子中包含 ▽ϕlogqϕ(zi∣x)\triangledown_\phi \log q_\phi(z_i|x)▽ϕlogqϕ(zi∣x),以下为 y=log(x)y=\log(x)y=log(x) 的函数图像

在 xxx 较小时值的变化范围很大,因此直观上来看 ▽ϕlogqϕ(zi∣x)logp(x,zi)qϕ(zi∣x)\triangledown_\phi \log q_\phi(z_i|x) \log\frac{p(x,z_i)}{q_\phi(z_i|x)}▽ϕlogqϕ(zi∣x)logqϕ(zi∣x)p(x,zi) 方差较大,对于每个 xxx 都需要大量采样 zzz 才能得到一个较为准确的期望值,实际应用时存在较大困难,因此引入如下重参数化技巧 (Re-parameterization)
重参数化技巧:我们希望解耦随机变量 zzz 中的随机性与 ϕ\phiϕ 之间的关系,使得计算期望时随机变量服从的概率分布 z∼qϕ(z∣x)z\sim q_\phi(z|x)z∼qϕ(z∣x) 转变为某个已知的概率分布,我们假定存在某随机变量 ϵ∼pϵ(ϵ)\epsilon \sim p_\epsilon(\epsilon)ϵ∼pϵ(ϵ),满足 z=gϕ(ϵ,x)z = g_\phi(\epsilon, x)z=gϕ(ϵ,x),我们有 ∣qϕ(z∣x)dz∣=∣pϵ(ϵ)dϵ∣\left | q_{\phi }(z|x)dz \right |=\left | p_\epsilon(\epsilon )d\epsilon \right |∣qϕ(z∣x)dz∣=∣pϵ(ϵ)dϵ∣,因此,有下式
▽ϕELBO=▽ϕ∫zqϕ(z∣x)logp(x,z)qϕ(z∣x)dz=▽ϕ∫zlogp(x,z)qϕ(z∣x)pϵ(ϵ)dϵ=∫z▽ϕlogp(x,z)qϕ(z∣x)pϵ(ϵ)dϵ=Eϵ∼pϵ[▽ϕlogp(x,z)qϕ(z∣x)]=Eϵ∼pϵ[▽zlogp(x,z)qϕ(z∣x)▽ϕgϕ(ϵ,x)]\begin{align} \triangledown_\phi \text{ELBO} &= \triangledown_\phi \int_z q_\phi(z|x) \log\frac{p(x,z)}{q_\phi(z|x)} dz \nonumber \\ &= \triangledown_\phi \int_z \log\frac{p(x,z)}{q_\phi(z|x)} p_\epsilon(\epsilon) d\epsilon \nonumber \\ &= \int_z \triangledown_\phi \log\frac{p(x,z)}{q_\phi(z|x)} p_\epsilon(\epsilon) d\epsilon \nonumber \\ &= \mathbb E_{\epsilon\sim p_\epsilon}[ \triangledown_\phi\log\frac{p(x,z)}{q_\phi(z|x)}] \nonumber \\ &= \mathbb E_{\epsilon\sim p_\epsilon}[ \triangledown_z\log\frac{p(x,z)}{q_\phi(z|x)} \triangledown_\phi g_\phi(\epsilon,x)] \nonumber \end{align} ▽ϕELBO=▽ϕ∫zqϕ(z∣x)logqϕ(z∣x)p(x,z)dz=▽ϕ∫zlogqϕ(z∣x)p(x,z)pϵ(ϵ)dϵ=∫z▽ϕlogqϕ(z∣x)p(x,z)pϵ(ϵ)dϵ=Eϵ∼pϵ[▽ϕlogqϕ(z∣x)p(x,z)]=Eϵ∼pϵ[▽zlogqϕ(z∣x)p(x,z)▽ϕgϕ(ϵ,x)]
变分自动编码器 (Variational AutoEncoder)
变分自编码器是变分推断与自编码器的一种组合,首先来简单介绍一下自编码器,经验可知,对于图像 x∈RH×W×3x\in \R^{H\times W\times 3}x∈RH×W×3 等真实数据的高维数据,它们通常在空间中是稀疏分布的,大致分布在高维空间的某个流形上面,因此,我们希望将其投影到某个稠密分布的空间上,使其满足某些性质(例如,在该稠密空间上采样的任一一个点,投影回原始图像空间都能得到一个接近真实的图像),我们使用神经网络来执行不同表示空间的转换操作,如下所示

AE主要有encoder和decoder两个部分组成,其中encoder和decoder都是神经网络。其中encoder负责将高维输入转换为低维的隐变量,decoder负责将低维的隐变量转换为高维的图像输出,其中输出要跟输入尽可能的相似
通常情况下,网络的拟合能力要强于训练数据的多样性,假如 Autoencoders 中的 encoder 和 decoder 都具有无限的拟合能力,那么理论上我们就可以无损地把任何高维数据都压缩至维度为 1,无损的数据压缩往往会使得隐空间缺乏可解释性。在大多数情况下,空间转化不仅仅是为了降低数据维度,而是在降低数据维度的同时还能在隐空间中保留数据的主要结构信息。我们目前的损失函数只对每个样本点处进行约束,而并没有整个隐空间上给出约束信息,这使得该网络不能在样本点与样本点之间得到较好的插值结果

上图所示三种颜色表示三个样本点在隐空间上的位置,如果不引入额外的约束,只在样本点的某个小邻域内可以得到合理的图像结果,但大部分位置 Decoder 不能给出一个合理的图像生成结果。我们希望,对隐空间的样本点施加一个噪声的情况下,依旧约束 Decoder 重建出一张与原始图像相似的图片,整体流程如下所示

注意到对于上述流程中,采样这一步是无法进行反向传播的,采用重参数化技巧解耦 zzz 的随机性和与参数 ϕ\phiϕ 之间的关系。通常假定 z∣x∼N(μ(x),σ2(x)I)z|x \sim \mathcal N (\mu(x), \sigma^2(x)I)z∣x∼N(μ(x),σ2(x)I),那么有
z=μ(x)+σ(x)ϵz = \mu(x) + \sigma(x) \epsilon z=μ(x)+σ(x)ϵ
其中 ϵ∼N(0,I)\epsilon \sim \mathcal{N}(0,I)ϵ∼N(0,I),网络结构如下所示
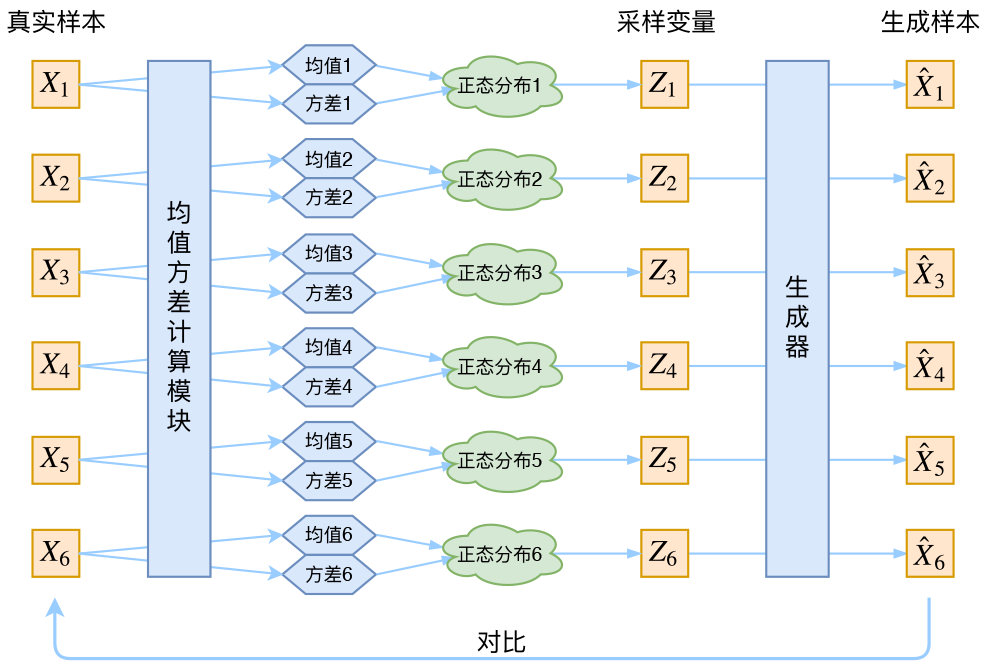
对于以上网络结构,显然噪声会增加重构的难度,其中噪声强度(方差)通过一个神经网络算出来的,如果不施加额外的约束,网络会倾向于让方差为0,模型会慢慢退化成普通的AutoEncoder,噪声不再起作用。
因此,为了避免模型退化,同时保证有意义的 p(z)p(z)p(z) 分布(方便图像的生成任务),VAE让所有的 p(z∣x)p(z|x)p(z∣x) 向标准正态分布看齐,如果所有的 p(z∣x)p(z|x)p(z∣x) 都很接近标准正态分布 N(0,1)\mathcal{N}(0,1)N(0,1),那么有
p(z)=∫xp(z∣x)p(x)dx=∫xN(0,1)p(x)dx=N(0,1)p(z) = \int_x p(z|x) p(x) dx = \int_x \mathcal{N}(0,1) p(x) dx = \mathcal{N}(0,1) p(z)=∫xp(z∣x)p(x)dx=∫xN(0,1)p(x)dx=N(0,1)
然后我们就可以从 N(0,1)\mathcal{N}(0,1)N(0,1) 中采样来生成图像
约束项由 KL 散度给出,有如下结论:对于一维高斯分布 p∼N(μ1,σ12)p~\sim \mathcal{N}(\mu_1,\sigma_1^2)p ∼N(μ1,σ12) 和 q∼N(μ2,σ22)q~\sim \mathcal{N}(\mu_2,\sigma_2^2)q ∼N(μ2,σ22),满足
KL(p∣∣q)=logσ2σ1+σ12+(μ1−μ2)22σ22−12\text{KL}(p||q) = \log\frac{\sigma_2}{\sigma_1} + \frac{\sigma_1^2+(\mu_1-\mu_2)^2}{2\sigma_2^2} - \frac{1}{2} KL(p∣∣q)=logσ1σ2+2σ22σ12+(μ1−μ2)2−21
具体细节可见 高斯分布的KL散度,进一步,假定隐变量各维度是相互独立的,可以给出如下损失函数约束项(对于第 i 个分量)
KL(N(μ(i)(x),σ(i)(x)),N(0,1))=12(μ(i)(x)2+σ(i)(x)2−2logσ(i)(x)−1)\text{KL}(\mathcal{N}(\mu^{(i)}(x),\sigma^{(i)}(x)), \mathcal{N}(0,1)) = \frac{1}{2}(\mu^{(i)}(x)^2+\sigma^{(i)}(x)^2−2\log\sigma^{(i)}(x)−1) KL(N(μ(i)(x),σ(i)(x)),N(0,1))=21(μ(i)(x)2+σ(i)(x)2−2logσ(i)(x)−1)
从数学角度来说,该优化问题可表示为
θ^,ϕ^=argminθ,ϕKL(qϕ(z∣x)∣∣pθ(z∣x))=argmaxθ,ϕELBO=argmaxθ,ϕEz∼qϕ(z∣x)[logpθ(x∣z)]−KL(qϕ(z∣x)∣∣pθ(z∣x))\begin{align} \hat{\theta}, \hat{\phi} &= \arg \min_{\theta,\phi} \text{KL}(q_\phi(z|x)||p_\theta(z|x)) \\&= \arg \max_{\theta,\phi} \text{ELBO} \\&= \arg \max_{\theta,\phi} \mathbb{E}_{z\sim q_\phi(z|x)} [\log p_\theta(x|z)] - \text{KL}(q_\phi(z|x)||p_\theta(z|x)) \end{align} θ^,ϕ^=argθ,ϕminKL(qϕ(z∣x)∣∣pθ(z∣x))=argθ,ϕmaxELBO=argθ,ϕmaxEz∼qϕ(z∣x)[logpθ(x∣z)]−KL(qϕ(z∣x)∣∣pθ(z∣x))
参考资料
白板推导机器学习
相关文章:
【理论推导】变分自动编码器 Variational AutoEncoder(VAE)
变分推断 (Variational Inference) 变分推断属于对隐变量模型 (Latent Variable Model) 处理的一种技巧,其概率图如下所示 我们将 X{x1,...xN}X\{ x_1,...x_N \}X{x1,...xN} 看作是每个样本可观测的一组数据,而将对应的 Z{z1,...,zN}Z\{z_1,...,z_N…...

【哈希表:哈希函数构造方法、哈希冲突的处理】
预测未来的最好方法就是创造它💦 目录 一、什么是Hash表 二、Hash冲突 三、Hash函数的构造方法 1. 直接定址法 2. 除余法 3. 基数转换法 4. 平方取中法 5. 折叠法 6. 移位法 7. 随机数法 四、处理冲突方法 1. 开放地址法 • 线性探测法 …...

HTML5 应用程序缓存
HTML5 应用程序缓存 使用 HTML5,通过创建 cache manifest 文件,可以轻松地创建 web 应用的离线版本。这意味着,你可以在没有网络连接的情况下进行访问。 什么是应用程序缓存(Application Cache)? HTML5 引…...

全国计算机等级考试三级网络技术选择题考点
目录 第一章 网络系统结构与设计的基本原则 第二章 中小型网络系统总体规划与设计方法 第三章 IP地址规划技术 第四章 路由设计基础 第五章 局域网技术基础应用 第六/七章 交换机/路由器及其配置 第八章 无线局域网技术 第九章 计算机网络信息服务系统的安装与…...

Python和VC代码实现希尔伯特变换(Hilbert transform)
文章目录前言一、希尔伯特变换是什么?二、VC中的实现原理及代码示例三、用Python代码实现总结前言 在数学和信号处理中,**希尔伯特变换(Hilbert transform)**是一个对函数产生定义域相同的函数的线性算子。 希尔伯特变换在信号处…...

嵌入式C语言语法概述
1.gcc概述 GCC全称是GUN C Compiler 随着时代的发展GCC支持的语言越来越多,它的名称变成了GNU Compiler Collection gcc的作用相当于翻译官,把程序设计语言翻译成计算机能理解的机器语言。 (1)gcc -o gcc -o (其…...
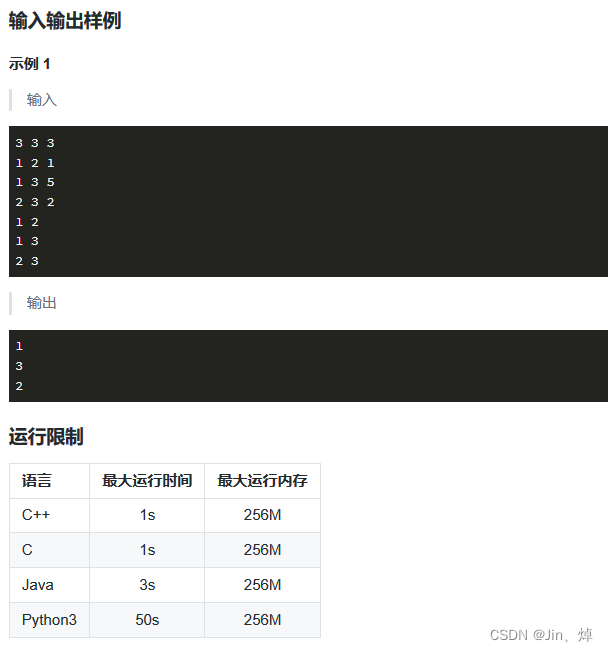
蓝桥杯第19天(Python)(疯狂刷题第3天)
题型: 1.思维题/杂题:数学公式,分析题意,找规律 2.BFS/DFS:广搜(递归实现),深搜(deque实现) 3.简单数论:模,素数(只需要…...
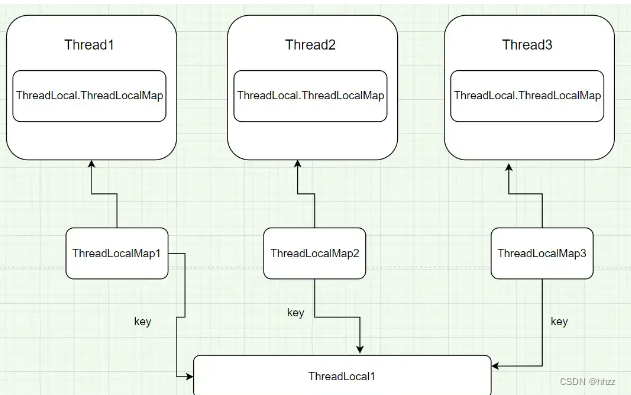
【数据库连接,线程,ThreadLocal三者之间的关系】
一、数据库连接与线程的关系 在实际项目中,数据库连接是很宝贵的资源,以MySQL为例,一台MySQL服务器最大连接数默认是100, 最大可以达到16384。但现实中最多是到200,再多MySQL服务器就承受不住了。因为mysql连接用的是tcp协议&…...
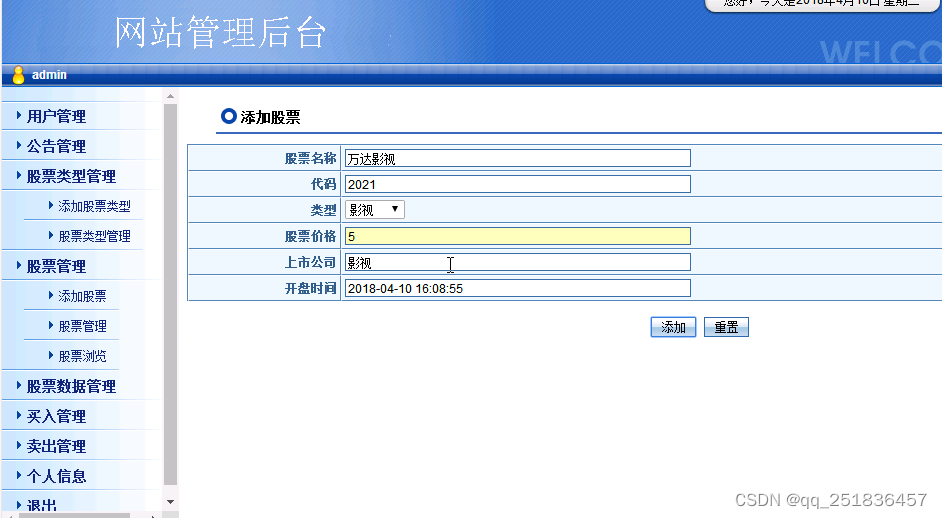
java 虚拟股票交易系统Myeclipse开发mysql数据库web结构jsp编程计算机网页项目
一、源码特点 JSP 虚拟股票交易系统是一套完善的java web信息管理系统,对理解JSP java编程开发语言有帮助,系统采用serlvetdaobean,系统具有完整的源代码和数据库,系统主要采用 B/S模式开发。 java 虚拟股票交易系统Myeclips…...

spring如何开启允许循环依赖
如何解决spring循环依赖 在Spring框架中,allowCircularReferences属性是用于控制Bean之间的循环依赖的。循环依赖是指两个或多个Bean之间相互依赖的情况,其中一个Bean依赖于另一个Bean,同时另一个Bean又依赖于第一个Bean。 allowCircularRe…...
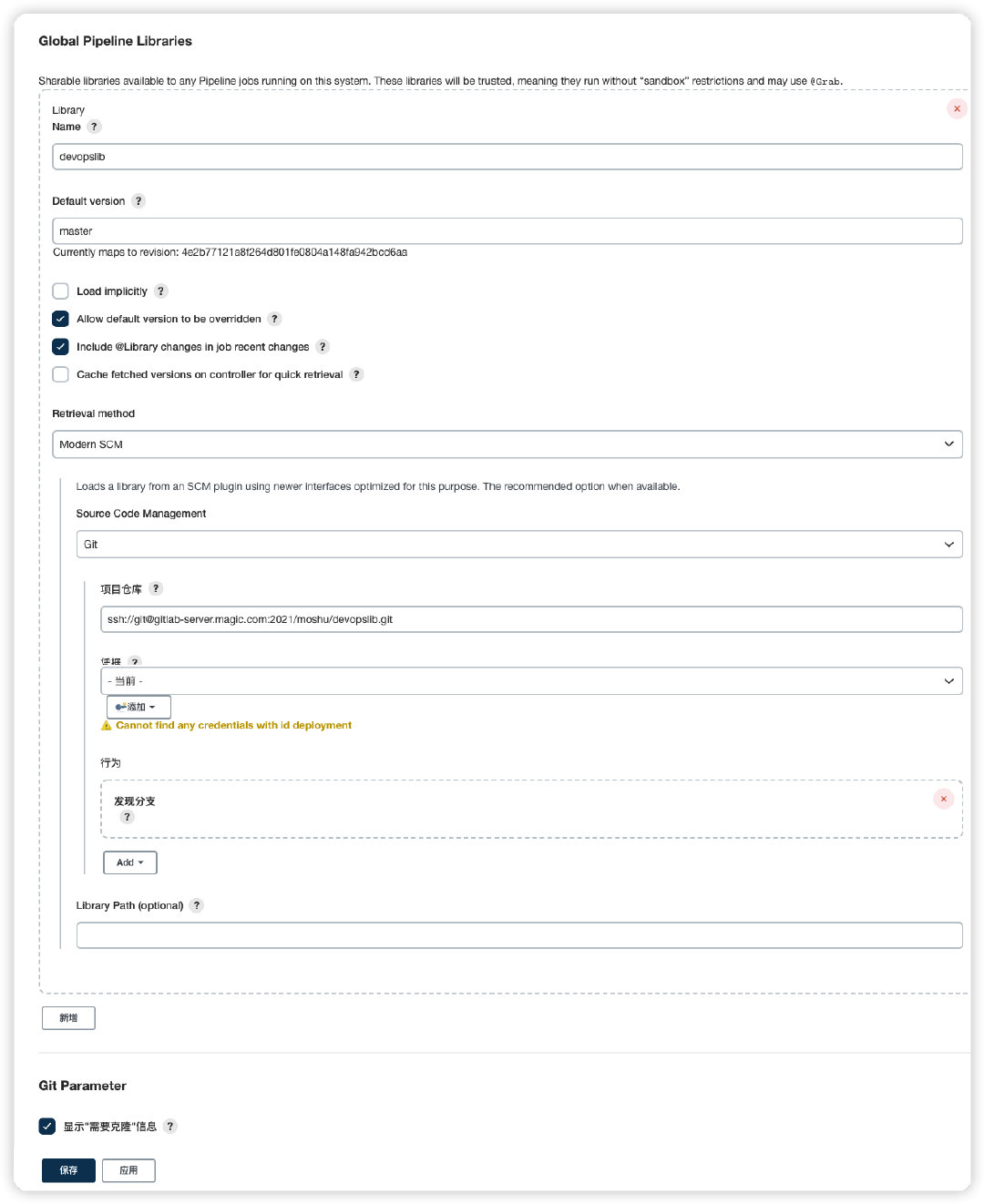
jenkins+sonarqube+自动部署服务
一、jenkins 配置Pipeline 二、新建共享库执行脚本 共享库可以是一个普通的gitlab项目,目录结构如下 三、添加到共享库 Jenkins Dashboard–>系统管理–>系统配置–>Global Pipeline Libraries Name: 共享库名称,自定义即可; Defa…...

【算法系列之动态规划III】背包问题
背包问题 01背包指的是物品只有1个,可以选也可以不选。完全背包是物品有无数个,可以选几个也可以不选。 二维数组01背包 有n件物品和一个最多能背重量为w 的背包。第i件物品的重量是weight[i],得到的价值是value[i] 。每件物品只能用一次&…...

MONAI-LayerFactory设计与实现
LayerFactory 用于创建图层的工厂对象,这使用给定的工厂函数来实际产生类型或构建可调用程序。这些函数是通过名称来参考的,可以在任何时候添加。 用到的关键技术点: 装饰器(Decorators), 例如:property装饰器,创建…...

Thinkphp 6.0路由的定义
本节课我们来了解一下路由方面的知识,然后简单的使用一下路由的功能。 一.路由简介 1. 路由的作用就是让 URL 地址更加的规范和优雅,或者说更加简洁; 2. 设置路由对 URL 的检测、验证等一系列操作提供了极大的便利性; …...

Kafka系列之:深入理解Kafka集群调优
Kafka系列之:深入理解Kafka集群调优 一、Kafka硬件配置选择二、Kafka内存选择三、CPU选择四、网络选择五、生产者调优六、broker调优七、消费者调优八、Kafka总体调优一、Kafka硬件配置选择 服务器台数选择: 2 * (生产者峰值生产速率 * 副本数 / 100) + 1磁盘选择: Kafka…...

creator-泄漏检测之资源篇
title: creator-泄漏检测之资源篇 categories: Cocos2dx tags: [creator, 优化, 泄漏, 内存] date: 2023-03-29 14:48:48 comments: false mathjax: true toc: true creator-泄漏检测之资源篇 前篇 资源释放 - https://docs.cocos.com/creator/manual/zh/asset/release-manager…...
)
【DevOps】Jenkins 运行任务时遇到 FATAL:Unable to produce a script file 报错(已解决)
文章目录一、问题描述二、定位原因三、解决方案四、其他方案五、总结关键词: Jenkins、Unable to produce a script file、UnmappableCharacterException、IOException: Failed to create a temp file on一、问题描述 由于使用的 Jenkins 存在安全漏洞(…...

Web前端
WEB前端 HTMLCSSJavaScriptjQuery(js框架)Bootstrap(CSS框架)AJAXJSON 文章目录 WEB前端WEB前端三大核心技术Web开发工具文本编辑器集成开发环境(IDE)浏览器选择HTML什么是 HTML?HTML版本变迁HTML-HelloWorldHTML 文档 = 网页HTML 标签属性(Attribute)HTML 常用标签...
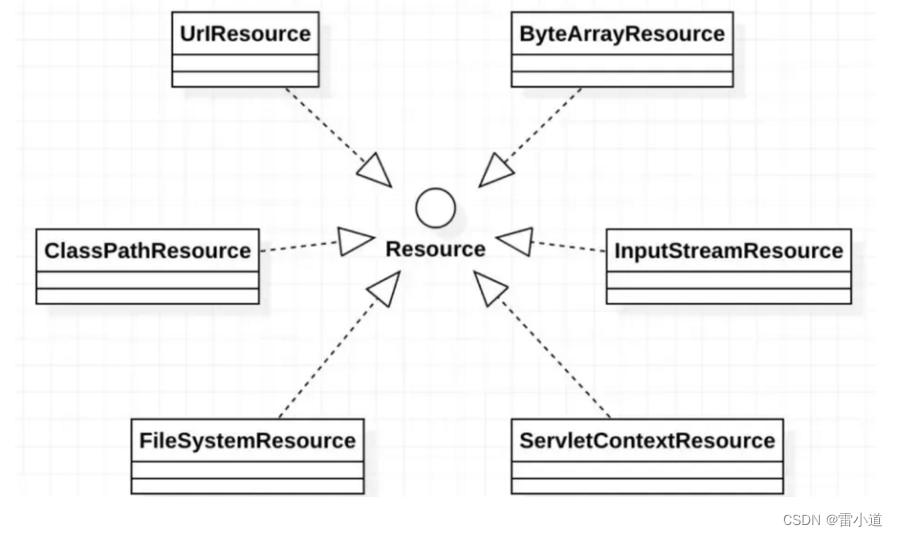
资源操作:Resources
文章目录1. Spring Resources概述1.2 Resource 接口1.3 Resource的实现类1.3.1 UrlResource访问网络资源1.3.2 ClassPathResource访问类路径下资源1.3.3 FileSystemResource访问文件系统资源1.3.4 ServletContextResource1.3.5、InputStreamResource1.3.6、ByteArrayResource1.…...
GDB调试的学习
很早就想在好好学一学gdb了,正好最近学算法(以前一直以为干硬件不需要什么特别厉害的算法,结果现在卷起来了。大厂面试题也有复杂一些的算法了) 下面的这些命令是别的博主总结的 GDB 调试过程_gdb调试过程_麷飞花的博客-CSDN博客…...

QuickCut视频剪辑软件:3分钟快速上手免费视频处理神器
QuickCut视频剪辑软件:3分钟快速上手免费视频处理神器 【免费下载链接】QuickCut Your most handy video processing software 项目地址: https://gitcode.com/gh_mirrors/qu/QuickCut 还在为复杂的专业视频编辑软件头疼吗?QuickCut作为一款轻量级…...

APK Installer终极指南:Windows平台Android应用部署完全手册
APK Installer终极指南:Windows平台Android应用部署完全手册 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 在跨平台应用生态日益融合的今天,开…...

AMD Ryzen SMU Debug Tool完全指南:揭秘硬件级调试的三大实战场景
AMD Ryzen SMU Debug Tool完全指南:揭秘硬件级调试的三大实战场景 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址:…...

半小时搞定C#开发
前言 此篇发出的原因有两点 致敬C#开篇 - 孤独战士,一篇包含雄心壮志的开篇,便无疾而终,时隔这么多年回关,内心莫名欣慰,感谢曾经的自己,就像文章标题所说,做一个无谓的孤独战士。笔者看到现在…...

蓝桥杯备赛别死磕理论!用DFS实战迷宫、八皇后,5分钟搞懂回溯模板
蓝桥杯算法实战:用DFS破解迷宫与八皇后问题的5个黄金法则 在算法竞赛的战场上,深度优先搜索(DFS)就像一把瑞士军刀——看似简单却能在关键时刻解决各类难题。许多选手在备战蓝桥杯时陷入理论泥潭,反复背诵模板却难以应…...

ARM Cortex-R中断处理与ECC机制详解
1. ARM Cortex-R中断处理机制深度解析在嵌入式实时系统中,中断处理机制的设计直接影响系统的响应速度和可靠性。ARM Cortex-R系列处理器作为面向实时控制应用的处理器架构,其中断处理系统经过精心设计,能够满足工业控制、汽车电子等领域的严苛…...

【紧急预警】传统文献管理正被淘汰!农科院最新评估:未集成NotebookLM的课题组结题延迟平均达4.8个月
更多请点击: https://codechina.net 第一章:NotebookLM农业科学研究的范式革命 传统农业科研长期依赖人工文献综述、田间数据手工录入与孤立模型验证,知识整合效率低、跨尺度分析能力弱。NotebookLM 以“文档即计算单元”的设计理念切入&…...

内容创作团队如何利用多模型API提升图文生成效率
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 内容创作团队如何利用多模型API提升图文生成效率 对于新媒体运营、电商内容或市场团队而言,持续产出高质量的图文内容是…...

【NotebookLM学术写作黄金法则】:20年科研老炮亲授5大避坑指南与3步合规提速法
更多请点击: https://intelliparadigm.com 第一章:NotebookLM学术写作规范的底层逻辑与认知革命 NotebookLM 并非传统意义上的文档编辑器,而是一个以“语义锚点”和“引用可追溯性”为基石的学术协作文本引擎。其底层逻辑颠覆了线性写作范式…...

从省级技术中心认证,看嵌入式企业如何以系统工程能力赋能开发者
1. 从“省级企业技术中心”认定,看一家嵌入式企业的硬核实力最近,在河北省发改委公布的2023年省级企业技术中心认定名单里,我看到了一个熟悉的名字——保定飞凌嵌入式技术有限公司。对于圈内人来说,“飞凌嵌入式”这个名字并不陌生…...