书生大模型实战营学习[7] InternLM + LlamaIndex RAG 实践

环境配置
选择30%A100做本次任务
conda create -n llamaindex python=3.10
conda activate llamaindex
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.7 -c pytorch -c nvidia
pip install einops
pip install protobuf安装Llamaindex
conda activate llamaindex
pip install llama-index==0.10.38 llama-index-llms-huggingface==0.2.0 "transformers[torch]==4.41.1" "huggingface_hub[inference]==0.23.1" huggingface_hub==0.23.1 sentence-transformers==2.7.0 sentencepiece==0.2.0下载 Sentence Transformer 模型
Sentence Transformer模型是一种用于句子嵌入(sentence embedding)技术的深度学习模型,旨在将句子或文本段落转换为固定长度的向量表示。这种表示可以用于多种自然语言处理任务,例如文本相似度计算、检索和分类等。
cd ~
mkdir llamaindex_demo
mkdir model
cd ~/llamaindex_demo
touch download_hf.py粘贴到download_hf.py
import os# 设置环境变量
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'# 下载模型
os.system('huggingface-cli download --resume-download sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2 --local-dir /root/model/sentence-transformer')执行该脚本
cd /root/llamaindex_demo
conda activate llamaindex
python download_hf.py下载 NLTK
cd /root
git clone https://gitee.com/yzy0612/nltk_data.git --branch gh-pages
cd nltk_data
mv packages/* ./
cd tokenizers
unzip punkt.zip
cd ../taggers
unzip averaged_perceptron_tagger.zip对原始internlm2-chat-1_8b进行测试
首先把InternLM2 1.8B 软连接出来
cd ~/model
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-1_8b/ ./创建一个python文件:
cd ~/llamaindex_demo
touch llamaindex_internlm.py将一下代码粘贴到llamaindex_internlm.py中
from llama_index.llms.huggingface import HuggingFaceLLM
from llama_index.core.llms import ChatMessage
llm = HuggingFaceLLM(model_name="/root/model/internlm2-chat-1_8b",tokenizer_name="/root/model/internlm2-chat-1_8b",model_kwargs={"trust_remote_code":True},tokenizer_kwargs={"trust_remote_code":True}
)rsp = llm.chat(messages=[ChatMessage(content="xtuner是什么?")])
print(rsp)运行查看结果:
conda activate llamaindex
cd ~/llamaindex_demo/
python llamaindex_internlm.py输出:
xtuner是一款用于播放音乐的软件,它支持多种音频格式,包括MP3、WAV、WMA、FLAC、AAC、APE、OGG、WMA、WAV、WMA
模型并不能很好的回答出正确答案。
RAG增强internlm2-chat-1_8b测试
首先安装词嵌入向量依赖:
conda activate llamaindex
pip install llama-index-embeddings-huggingface llama-index-embeddings-instructor然后获取知识库:
cd ~/llamaindex_demo
mkdir data
cd data
git clone https://github.com/InternLM/xtuner.git
mv xtuner/README_zh-CN.md ./创建一个pythonllamaindex_RAG.py文件:
cd ~/llamaindex_demo
touch llamaindex_RAG.py将以下代码粘贴到llamaindex_RAG.py中:
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settingsfrom llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLM#初始化一个HuggingFaceEmbedding对象,用于将文本转换为向量表示
embed_model = HuggingFaceEmbedding(
#指定了一个预训练的sentence-transformer模型的路径model_name="/root/model/sentence-transformer"
)
#将创建的嵌入模型赋值给全局设置的embed_model属性,
#这样在后续的索引构建过程中就会使用这个模型。
Settings.embed_model = embed_modelllm = HuggingFaceLLM(model_name="/root/model/internlm2-chat-1_8b",tokenizer_name="/root/model/internlm2-chat-1_8b",model_kwargs={"trust_remote_code":True},tokenizer_kwargs={"trust_remote_code":True}
)
#设置全局的llm属性,这样在索引查询时会使用这个模型。
Settings.llm = llm#从指定目录读取所有文档,并加载数据到内存中
documents = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()
#创建一个VectorStoreIndex,并使用之前加载的文档来构建索引。
# 此索引将文档转换为向量,并存储这些向量以便于快速检索。
index = VectorStoreIndex.from_documents(documents)
# 创建一个查询引擎,这个引擎可以接收查询并返回相关文档的响应。
query_engine = index.as_query_engine()
response = query_engine.query("xtuner是什么?")print(response)conda activate llamaindex
cd ~/llamaindex_demo/
python llamaindex_RAG.py输出:

LlamaIndex web
pip install streamlit==1.36.0
#创建py文件
cd ~/llamaindex_demo
touch app.py
粘贴
import streamlit as st
from llama_index.core import VectorStoreIndex, SimpleDirectoryReader, Settings
from llama_index.embeddings.huggingface import HuggingFaceEmbedding
from llama_index.llms.huggingface import HuggingFaceLLMst.set_page_config(page_title="llama_index_demo", page_icon="🦜🔗")
st.title("llama_index_demo")# 初始化模型
@st.cache_resource
def init_models():embed_model = HuggingFaceEmbedding(model_name="/root/model/sentence-transformer")Settings.embed_model = embed_modelllm = HuggingFaceLLM(model_name="/root/model/internlm2-chat-1_8b",tokenizer_name="/root/model/internlm2-chat-1_8b",model_kwargs={"trust_remote_code": True},tokenizer_kwargs={"trust_remote_code": True})Settings.llm = llmdocuments = SimpleDirectoryReader("/root/llamaindex_demo/data").load_data()index = VectorStoreIndex.from_documents(documents)query_engine = index.as_query_engine()return query_engine# 检查是否需要初始化模型
if 'query_engine' not in st.session_state:st.session_state['query_engine'] = init_models()def greet2(question):response = st.session_state['query_engine'].query(question)return response# Store LLM generated responses
if "messages" not in st.session_state.keys():st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}] # Display or clear chat messages
for message in st.session_state.messages:with st.chat_message(message["role"]):st.write(message["content"])def clear_chat_history():st.session_state.messages = [{"role": "assistant", "content": "你好,我是你的助手,有什么我可以帮助你的吗?"}]st.sidebar.button('Clear Chat History', on_click=clear_chat_history)# Function for generating LLaMA2 response
def generate_llama_index_response(prompt_input):return greet2(prompt_input)# User-provided prompt
if prompt := st.chat_input():st.session_state.messages.append({"role": "user", "content": prompt})with st.chat_message("user"):st.write(prompt)# Gegenerate_llama_index_response last message is not from assistant
if st.session_state.messages[-1]["role"] != "assistant":with st.chat_message("assistant"):with st.spinner("Thinking..."):response = generate_llama_index_response(prompt)placeholder = st.empty()placeholder.markdown(response)message = {"role": "assistant", "content": response}st.session_state.messages.append(message)运行
streamlit run app.py访问:
ssh -CNg -L 8501:127.0.0.1:8501 root@ssh.intern-ai.org.cn -p 48693(需要换成自己的端口号)
相关文章:
书生大模型实战营学习[7] InternLM + LlamaIndex RAG 实践
环境配置 选择30%A100做本次任务 conda create -n llamaindex python3.10 conda activate llamaindex conda install pytorch2.0.1 torchvision0.15.2 torchaudio2.0.2 pytorch-cuda11.7 -c pytorch -c nvidia pip install einops pip install protobuf安装Llamaindex cond…...

【MySQL】数据库--索引
索引 1.索引 在数据中索引最核心的作用就是:加速查找 1.1 索引原理 索引的底层是基于BTree的数据存储结构 如图所示: 很明显,如果有了索引结构的查询效率比表中逐行查询的速度要快很多且数据越大越明显。 数据库的索引是基于上述BTree的…...

[大语言模型-论文精读] ACL2024-长尾知识在检索增强型大型语言模型中的作用
ACL2024-长尾知识在检索增强型大型语言模型中的作用 On the Role of Long-tail Knowledge in Retrieval Augmented Large Language Models Authors: Dongyang Li, Junbing Yan, Taolin Zhang, Chengyu Wang, Xiaofeng He, Longtao Huang, Hui Xue, Jun Huang 1.概览 问题解决&…...

“迷茫野路子到AI大模型高手:一张图解产品经理晋升之路和能力构建“
前言 在探寻成功之路上,若你向20位业界顶尖的产品经理或运营专家请教,他们可能会向你展示一条条各异的路径,正如那句古老的格言:“条条大路通罗马”。但是,我们必须认识到,这些路径虽多,却并非…...
可看见车辆行人的高清实时视频第2辑
我们在《看见车辆行人的高清实时视频第2辑》分享了10处可看见车辆行人的实时动态高清视频。 现在我们又整理10处为你分享可看见车辆行人的实时动态高清视频,一共有30个摄像头数据,这些视频来自公开的高清摄像头实时直播画面。 我们在文末为你分享了这些…...

基于饥饿游戏搜索优化随机森林的数据回归预测 MATLAB 程序 HGS-RF
1. 引言 随着人工智能和机器学习的飞速发展,回归预测在各个领域得到了广泛应用。回归模型用于预测连续变量的值,如金融市场的价格走势、气象预报中的温度变化等。本文提出了一种基于**饥饿游戏搜索(Hunger Games Search, HGS)优化…...

一天面了8个Java后端,他们竟然还在背5年前的八股文!
今天面了8个Java候选人,在面试中我发现他们还停留在面试背八股文的阶段,5年前面试背八股文没问题,随着市场竞争越来越激烈,再问普通的Java八股文已经没有意义了,因为考察不出来获选人的真实实力! 现在面试…...

python功能测试
文章目录 unnittest1. 基本结构2. 常用断言方法3. 测试生命周期方法4. 跳过测试5. 运行测试 pytest1. 基本测试用法2. 安装 pytest3. 运行测试4. 使用 assert 断言5. 异常测试6. 参数化测试7. 测试前后设置8. 跳过测试和标记失败9. 测试夹具 (Fixtures)10. 生成测试报告11. 插件…...
-三语言题解)
【秋招笔试】09.25华子秋招(已改编)-三语言题解
🍭 大家好这里是 春秋招笔试突围,一起备战大厂笔试 💻 ACM金牌团队🏅️ | 多次AK大厂笔试 | 大厂实习经历 ✨ 本系列打算持续跟新 春秋招笔试题 👏 感谢大家的订阅➕ 和 喜欢💗 和 手里的小花花🌸 ✨ 笔试合集传送们 -> 🧷春秋招笔试合集 🍒 本专栏已收集…...

【中级通信工程师】终端与业务(四):通信产品
【零基础3天通关中级通信工程师】 终端与业务(四):通信产品 本文是中级通信工程师考试《终端与业务》科目第四章《通信产品》的复习资料和真题汇总。终端与业务是通信考试里最简单的科目,有效复习通过率可达90%以上,本文结合了高频考点和近几…...

数据科学 - 字符文本处理
1. 字符串的基本操作 1.1 结构操作 1.1.1 拼接 • 字符串之间拼接 字符串之间的拼接使用进行字符串的拼接 a World b Hello print(b a) • 列表中的字符串拼接 将以分隔符‘,’为例子 str [apple,banana] print(,.join(str)); • 字符串中选择 通过索引进行切片操…...

python之装饰器、迭代器、生成器
装饰器 什么是装饰器? 用来装饰其他函数,即为其他函数添加特定功能的函数。 装饰器的两个基本原则: 装饰器不能修改被装饰函数的源码 装饰器不能修改被装饰函数的调用方式 什么是可迭代对象? 在python的任意对象中ÿ…...

Go语言实现后台管理系统如何根据角色来动态显示栏目
实现要点 根据不同的用户显示不同的栏目是后台管理的重要内容,那么如何实现这些功能呢? 栏目有很多分级这些需要递归查出来新增和删除也要满足层级规则且不影响其他层级各节点之间的关系因该明确,方便添加和删除数据库设置 存储栏目的数据库设计,要明确节点的关系最常用的…...

【深度学习】【TensorRT】【C++】模型转化、环境搭建以及模型部署的详细教程
【深度学习】【TensorRT】【C】模型转化、环境搭建以及模型部署的详细教程 提示:博主取舍了很多大佬的博文并亲测有效,分享笔记邀大家共同学习讨论 文章目录 【深度学习】【TensorRT】【C】模型转化、环境搭建以及模型部署的详细教程前言模型转换--pytorch转engineWindows平台搭…...

LeetCode(Python)-贪心算法
文章目录 买卖股票的最佳时机问题穷举解法贪心解法 物流站的选址(一)穷举算法贪心算法 物流站的选址(二)回合制游戏快速包装 买卖股票的最佳时机问题 给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。如果你…...

【C/C++】【基础数论】33、算数基本定理
算术基本定理,又称正整数的唯一分解定理。 说起来比较复杂,但是看一下案例就非常清楚了 任何一个大于 1 的正整数都可以唯一地分解成有限个质数的乘积形式,且这些质数按照从小到大的顺序排列,其指数也是唯一确定的。 例如&#…...
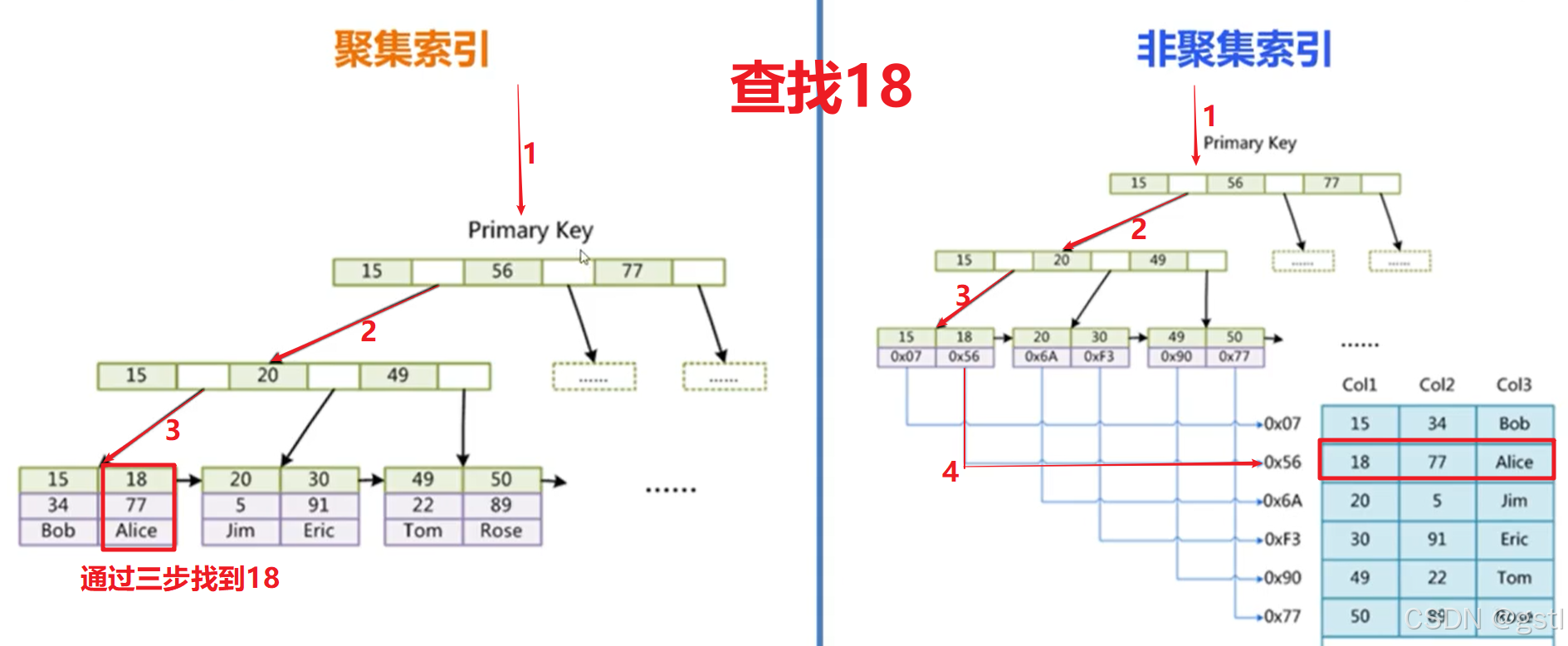
聚簇索引与非聚簇索引
物理存储方式不同: 1. InnoDb默认数据结构是聚簇索引;MyISAM 是非聚簇索引 2. 聚簇索引 中表索引与数据是在一个文件中 .ibd;非聚簇索引中表索引(.MYI)与数据(.MYD)是在两个文件中 3. 聚簇索引中表数据行都存放在索引树…...

“类型名称”在Go语言规范中的演变
Go语言规范(The Go Programming Language Specification)[1]是Go语言的核心文档,定义了该语言的语法、类型系统和运行时行为。Go语言规范的存在使得开发者在实现Go编译器时可以依赖一致的标准,它确保了语言的稳定性和一致性&#…...

c++----继承(初阶)
大家好呀,今天我们也是多久没有更新博客了,今天来讲讲我们c加加中的一个比较重要的知识点继承。首先关于继承呢,大家从字面意思看,是不是像我们平常日常生活中很容易出现的,比如说电视剧里面什么富豪啊,去了…...
常见的四种非关系型数据库(NoSQL))
数据库系列(1)常见的四种非关系型数据库(NoSQL)
非关系型数据库(NoSQL) 非关系型数据库适用于需要灵活数据模型和高可扩展性的场景。常见的非关系型数据库包括: MongoDB:文档数据库,以JSON-like格式存储数据,适合快速开发和迭代。Cassandra:…...

NCM解密终极指南:3步释放网易云音乐到任何播放器
NCM解密终极指南:3步释放网易云音乐到任何播放器 【免费下载链接】ncmdump 项目地址: https://gitcode.com/gh_mirrors/ncmd/ncmdump 你是否曾经在网易云音乐下载了心爱的歌曲,却发现只能在特定应用中播放?当你想要将音乐迁移到其他设…...

Flutter 测试完全指南
Flutter 测试完全指南 引言 测试是软件质量保障的关键环节。本文将深入探讨 Flutter 测试的各种类型和最佳实践。 基础概念回顾 测试类型 单元测试: 测试单个函数或方法Widget 测试: 测试单个 Widget集成测试: 测试多个组件的交互性能测试: 测试应用性能 测试工具 test:…...

Arm Neoverse CMN-700互连架构与协议寄存器配置指南
1. Arm Neoverse CMN-700一致性互连架构解析在现代多核处理器设计中,一致性互连网络如同城市交通系统般重要。Arm Neoverse CMN-700作为第二代Coherent Mesh Network解决方案,其架构设计充分考虑了数据中心和边缘计算的严苛需求。与传统的总线或环形拓扑…...

3个维度深度解析:UABEA如何重塑Unity资源处理生态
3个维度深度解析:UABEA如何重塑Unity资源处理生态 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 在Unity游戏开发和资源处理的复杂生态中,开发者常常面临一个核心挑战…...

Blitz.js全栈开发框架:零API理念与Next.js深度集成实战
1. 项目概述:一个颠覆性的全栈开发框架如果你和我一样,在过去的几年里,一直在React生态圈里打转,从Create React App到Next.js,再到尝试自己搭建一套包含身份验证、数据层、API路由的完整应用,那你一定对那…...

基于GitHub Pages与Jekyll的静态博客搭建与深度定制指南
1. 项目概述:一个静态博客的诞生与演进如果你对搭建个人博客感兴趣,或者正在寻找一个轻量、高效、完全可控的线上空间,那么“RyansGhost/RyansGhost.github.io”这个项目仓库,很可能就是你一直在寻找的答案。这不仅仅是一个托管在…...
)
别再让用户等上传!用@ffmpeg/ffmpeg在浏览器里直接压缩视频(附ThinkPHP项目实战)
浏览器端视频压缩实战:基于FFmpeg.wasm与ThinkPHP的高效集成方案 引言 在当今内容为王的互联网时代,视频已成为用户生成内容(UGC)的核心载体。然而,高清视频带来的大文件体积往往成为用户体验的瓶颈——上传等待时间长…...

从单一AI到智能体集群:构建模块化AI协作系统的核心原理与实践
1. 项目概述:当AI学会“开会”,一个开源智能体集群的诞生最近在GitHub上看到一个挺有意思的项目,叫daveshap/OpenAI_Agent_Swarm。光看名字,你可能会觉得这又是一个调用OpenAI API的简单封装库。但如果你点进去,花上十…...

终极ThinkPad风扇控制指南:告别噪音,拥抱静音高效
终极ThinkPad风扇控制指南:告别噪音,拥抱静音高效 【免费下载链接】TPFanCtrl2 ThinkPad Fan Control 2 (Dual Fan) for Windows 10 and 11 项目地址: https://gitcode.com/gh_mirrors/tp/TPFanCtrl2 你是否曾经因为ThinkPad风扇的"直升机起…...

AI项目脚手架:标准化与自动化提升工程效率
1. 项目概述:一个为AI项目量身定制的“脚手架”如果你和我一样,在AI领域摸爬滚打多年,从早期的机器学习模型到现在的深度学习、大语言模型应用,肯定经历过无数次从零开始搭建项目的“阵痛”。每次新建一个项目,都要重复…...