【计算机视觉 | 目标检测】DETR风格的目标检测框架解读
文章目录
- 一、前言
- 二、理解
- 2.1 DETR的理解
- 2.2 DETR的细致理解
- 2.2.1 Backbone
- 2.2.2 Transformer encoder
- 2.2.3 Transformer decoder
- 2.2.4 Prediction feed-forward networks (FFNs)
- 2.2.5 Auxiliary decoding losses
- 2.3 更具体的结构
- 2.4 编码器的原理和作用
- 2.5 解码器的原理和作用
- 三、注意力机制的理解
一、前言
在最近的论文阅读中,我遇到了一个新的框架—DETR风格的框架。

对此,感觉不是很了解,这里总结一下。
二、理解
2.1 DETR的理解
DETR(DEtection TRansformer)是一种基于Transformer的端到端目标检测模型,由Facebook AI Research团队提出。它使用Transformer将目标检测任务转换为一种集合预测问题(set prediction),即将输入的图像和目标集合编码为两个集合,然后通过匹配这两个集合来预测目标的类别、位置和数量。
没有NMS后处理步骤、没有anchor,结果在coco数据集上效果与Faster RCNN相当,且可以很容易地将DETR迁移到其他任务例如全景分割。
引用知乎大佬的话来说,这种做目标检测的方法更合理:
对于一个没接触过任何检测知识的人,去设计检测的方法,更容易想到的应该是DETR类似的方法,而不是RCNN系列的方法,因为它更直接更本质。所以这篇文章的主要意义也便是—将检测方法回归到了本质。
最初的检测方法,无法直接获取到检测结果,所以用proposal + classifier方法,是一种曲线救国的策略。无论RCNN系列还是YOLO系列,都无法像生物一样,直接指出哪个位置是什么物体,而是用密集的先验,覆盖整幅图可能出现物体的部分,然后预测该视野区域的实例类别以及该视野区域所应做出的调整。打一个比方,就像是刺激战场,开着八倍镜,找敌人一样。
判断视野里面的类别—调整视野—判断视野里面的类别—调整视野—…
而DETR方法则是,不开镜的情况下,确认那个地方有敌人,然后开着八倍镜去锁定目标。
确认整幅图实例情况—调整具体实例的视野。
DETR模型的整体结构分为编码器和解码器两部分。
- 编码器由一系列的Transformer编码层组成,用于提取图像中的特征信息。
- 解码器则将编码器提取的特征信息与目标集合中的先验信息进行结合,最终生成目标的类别、位置和数量等信息。
总体思路是把检测看成一个set prediction的问题,并且使用Transformer来预测box的set。DETR 利用标准 Transformer 架构来执行传统上特定于目标检测的操作,从而简化了检测 pipeline。
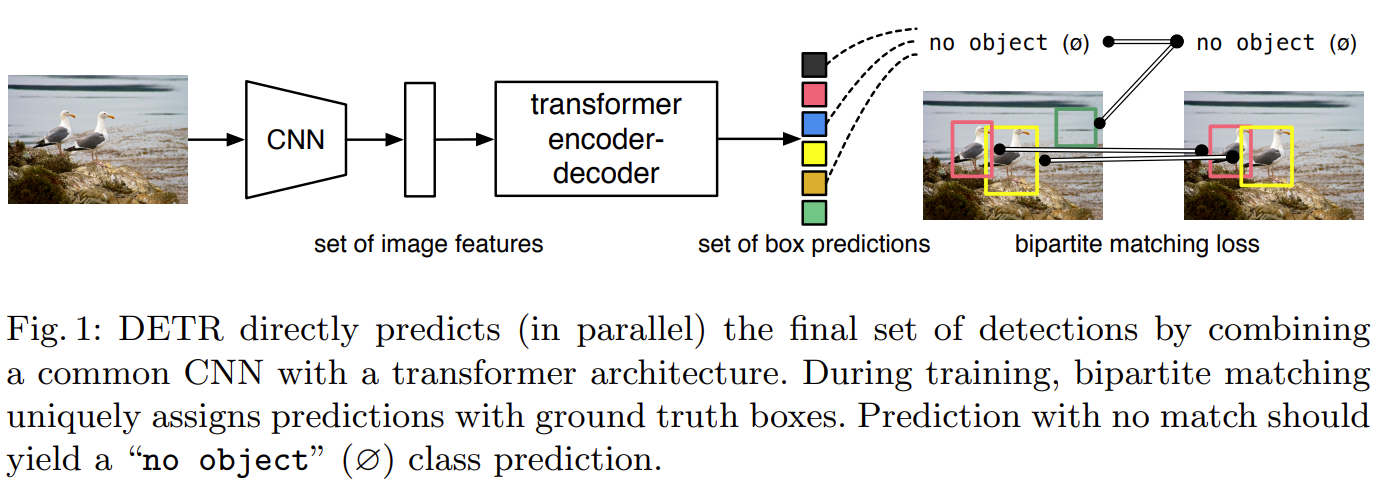
DETR包含三个主要组件:
- CNN骨干网
- 编码器-解码器transformer
- 一个简单的前馈网络
首先,CNN骨干网从输入图像生成特征图。
然后,将CNN骨干网的输出转换为一维特征图,并将其作为输入传递到Transformer编码器。该编码器的输出是N个固定长度的嵌入(向量),其中N是模型假设的图像中的对象数。
Transformer解码器借助自身和编码器-解码器注意机制将这些嵌入解码为边界框坐标。
最后,前馈神经网络预测边界框的标准化中心坐标,高度和宽度,而线性层使用softmax函数预测类别标签。
详细见下图:
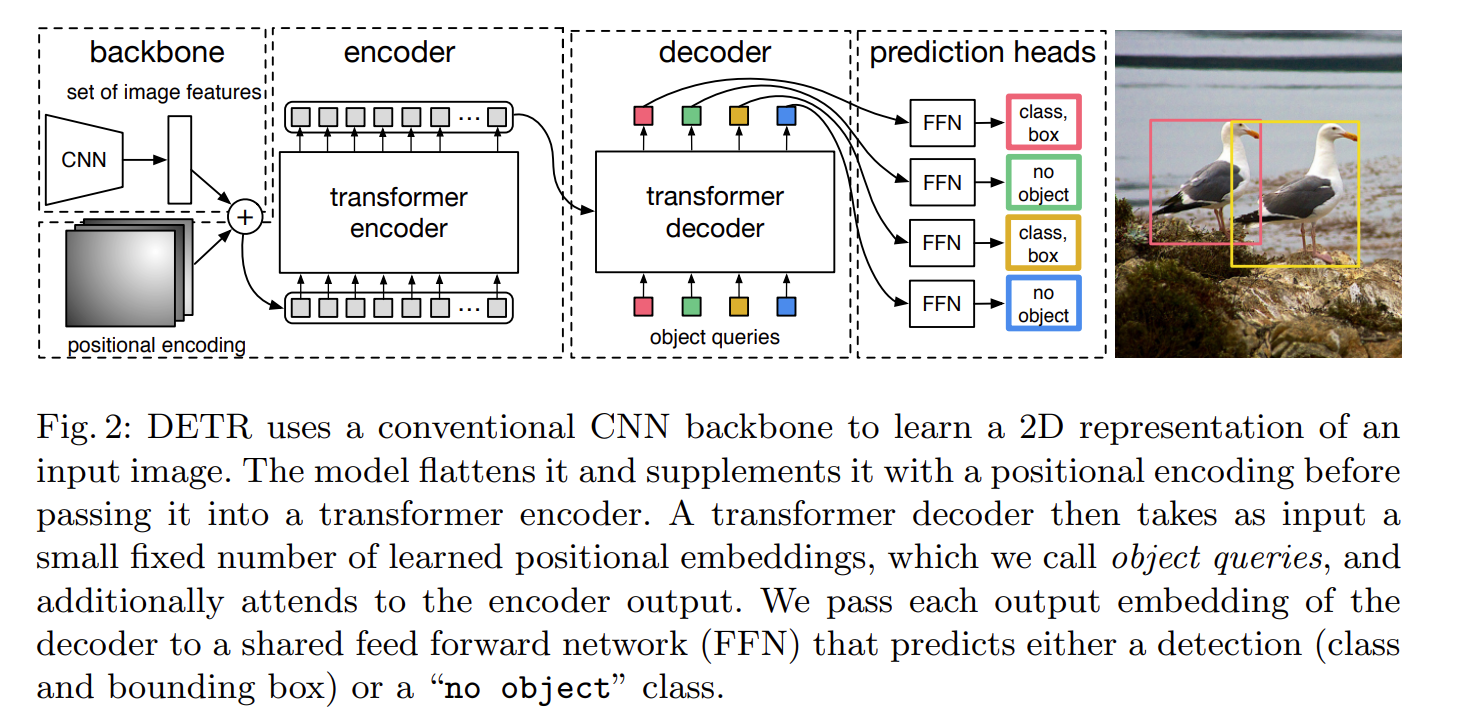
DETR采用Transformer的自注意力机制来对输入进行编码,而不是使用传统的卷积神经网络。
这样做的好处是可以充分考虑整张图像中不同位置之间的关系,提高了模型对目标的感知能力和准确率。此外,DETR还使用了一个新的位置编码方法,称为Sinusoidal Positional Encoding,用于对不同位置的特征进行区分和定位。
与传统目标检测方法相比,DETR具有以下优点:
- 高效性:DETR采用端到端的方式训练,无需使用繁琐的手工设计过程,因此模型训练和推理速度较快。
- 灵活性:DETR的目标检测过程可以看作是对集合进行预测,因此可以灵活地处理各种数量和种类的目标。
- 鲁棒性:DETR通过将目标检测问题转换为集合预测问题,避免了传统目标检测算法中的anchor设计等问题,从而具有更强的鲁棒性。
2.2 DETR的细致理解
2.2.1 Backbone
在DETR中,Backbone指的是在输入图片上提取特征的卷积神经网络(Convolutional Neural Network,CNN)。它负责将输入的图片经过一系列卷积、池化等操作,转换成特征图。这些特征图将作为编码器的输入,编码器再将其转换为定位和分类的对象特征。
DETR使用ResNet作为其Backbone,ResNet是一种非常深的卷积神经网络,能够学习到更加复杂的特征表示。DETR使用ResNet的前面几个卷积块(例如ResNet50中的前四个卷积块)来提取特征,并且通过一个降采样操作将特征图缩小到一定的尺寸。这样可以提高特征的表达能力,同时缩小特征图的尺寸,从而减少后续处理的计算量。
需要注意的是,DETR中的Backbone与传统的目标检测模型中的Backbone有所不同。在传统的目标检测模型中,Backbone通常指的是将输入图片经过卷积神经网络得到的特征图,而在DETR中,Backbone只是负责提取特征的卷积神经网络部分。特征图的生成则是通过Encoder和Decoder两个阶段完成的。
2.2.2 Transformer encoder
在DETR中,Transformer encoder被用作编码器(Encoder)模块,用于将图像编码为一组特征向量。
Transformer encoder由若干个Transformer block组成,每个Transformer block又由两个子层组成,分别是self-attention层和前向神经网络(feed-forward neural network)层。
Transformer encoder通过对输入特征进行多层处理,逐渐提取出特征的高级抽象表示,最终输出一组特征向量。在DETR中,这些特征向量被用于表示输入图像中的目标。
自注意力机制(self-attention)是Transformer encoder的关键组成部分,用于在特征向量之间建立全局上下文关系。在self-attention层中,每个特征向量都会与其它所有特征向量进行交互,以便在全局上下文中获取更准确的特征表示。
另一方面,前向神经网络(feed-forward neural network)层是Transformer block的另一个组成部分。它是由全连接层和非线性激活函数组成的,用于在局部特征表示上进行非线性变换。这样可以更好地学习局部特征之间的关系,从而更好地对目标进行定位和分类。
总之,DETR中的Transformer encoder是用于从图像中提取特征的关键组件,通过多层的self-attention和前向神经网络层对特征进行处理,最终输出一组高级抽象的特征向量,用于目标检测和定位。
2.2.3 Transformer decoder
在DETR中,Transformer decoder主要用于解码器的实现,将编码器得到的信息和预测的位置、类别等信息进行解码,从而得到最终的目标检测结果。
在具体实现上,DETR使用了一个由若干个Transformer decoder堆叠而成的结构。每个Transformer decoder由若干个Multi-Head Attention和Feedforward网络组成,其中每个Multi-Head Attention和Feedforward网络都是一个Transformer decoder中的基本构建单元。Multi-Head Attention用于进行编码器和解码器信息的交互,Feedforward网络用于提取特征和信息的变换。
具体来说,DETR的解码器包括两个主要的部分:Transformer decoder和位置嵌入(position embedding)。位置嵌入是一种特殊的嵌入方式,用于将目标位置信息转换为可被神经网络学习的形式。在DETR中,位置嵌入的维度与编码器输出的特征维度相同,因此可以与特征向量进行拼接,作为解码器的输入。
在解码器中,每个Transformer decoder都负责处理编码器输出特征和目标位置信息的交互。具体来说,每个解码器包括三个主要的部分:Multi-Head Attention、Feedforward网络和LayerNorm。在Multi-Head Attention中,编码器输出的特征和目标位置信息作为查询向量和键值向量,分别用于计算注意力权重。计算出的注意力权重与编码器输出特征进行加权求和,得到解码器的输入特征。在Feedforward网络中,解码器的输入特征进行变换和非线性映射,从而得到更高层次的特征表示。最后,在LayerNorm中进行归一化,得到最终的解码器输出特征,供下一层解码器或最终的预测使用。
总的来说,DETR中的Transformer decoder主要用于解码器的实现,实现了目标检测任务中目标位置和编码器特征的有效融合。通过使用Transformer decoder,DETR可以在不需要使用先验框或区域提议的情况下,实现端到端的目标检测。
2.2.4 Prediction feed-forward networks (FFNs)
在DETR中,Prediction feed-forward networks (FFNs)是指在解码器中使用的两个全连接层,用于将编码器和解码器之间的注意力层输出进行处理,以生成最终的目标检测结果。这两个全连接层被称为class predictor和box predictor。
class predictor接收来自注意力层的输出,并为每个可能的目标类别输出一个分数,以表示其属于该类别的概率。在训练期间,模型使用交叉熵损失来最小化这些预测与真实类别之间的差异。
box predictor接收来自注意力层的输出,并对每个检测框的位置和大小进行预测。具体来说,它输出四个值,分别表示左上角和右下角坐标的偏移量。在训练期间,模型使用平滑L1损失来最小化这些预测与真实边界框之间的差异。
这两个预测器以并行的方式工作,并且在生成最终的目标检测结果时,它们的输出被合并起来,形成一个元组,其中包含预测的类别分数和边界框坐标。这些预测结果会经过一个非极大抑制算法以去除重叠的框,并保留最终的检测结果。
2.2.5 Auxiliary decoding losses
在DETR中,为了提高目标检测的性能,使用了一些辅助的解码损失。这些辅助损失的作用是在训练过程中提供更多的监督信号,以帮助网络更好地学习目标检测任务。
具体来说,DETR中使用了两个辅助损失:
- 位置损失(Position loss):在解码器中,每个位置都有一个预测的位置向量。该位置向量和真实位置之间的距离可以作为一个位置损失,用于指导模型更好地学习目标的位置信息。
- 类别损失(Class loss):DETR中使用了交叉熵损失来衡量预测类别和真实类别之间的距离。该损失可以促使模型更好地区分不同类别的目标。
这些辅助损失可以在模型训练中与主要的目标检测损失一起使用,以提高模型性能。
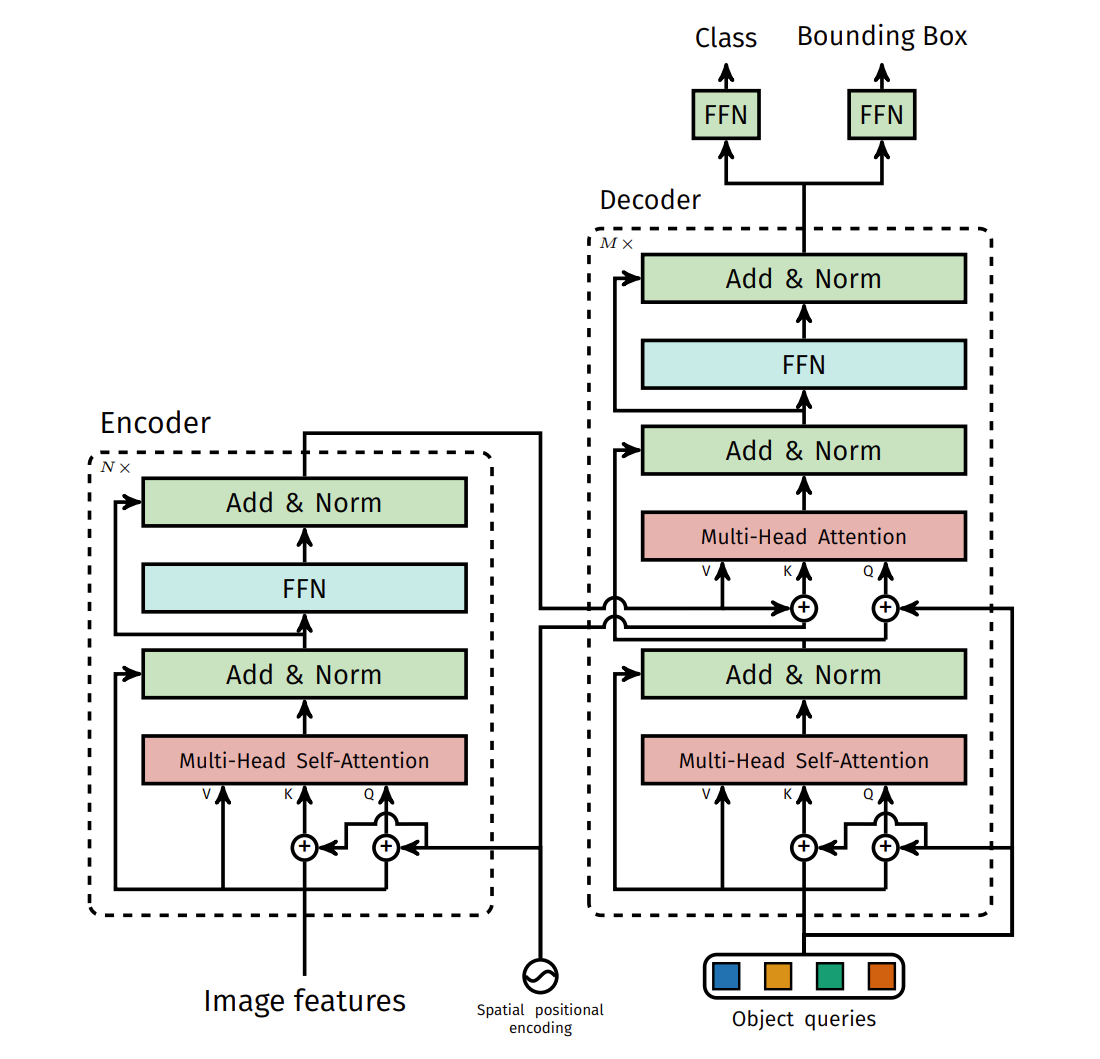
2.3 更具体的结构
2.4 编码器的原理和作用
在目标检测任务中,编码器是深度学习模型的一部分,主要负责将输入的图像特征提取并编码为一组向量表示,通常称为“特征向量”或“特征嵌入”。编码器的作用是将图像中的信息转换为一组有意义且易于处理的数字特征,以便用于后续的目标检测任务。
通常,编码器采用卷积神经网络(Convolutional Neural Networks,CNN)的结构进行设计,通过多层卷积和池化操作,逐步提取图像中的抽象特征。这些抽象特征能够代表图像中的局部和全局信息,包括纹理、形状、颜色等,同时具有一定的平移不变性和尺度不变性,使得它们适用于不同大小和位置的物体的检测。
在DETR(Detection Transformer)中,编码器是由Transformer编码器层组成的,这是一种基于自注意力机制(Self-Attention)的网络结构,能够捕获输入序列中的长程依赖关系,因此可以用于图像序列的编码。在DETR中,编码器将输入的图像划分为一系列图像块,对每个图像块进行特征提取和编码,生成一组图像块特征向量表示。
2.5 解码器的原理和作用
在目标检测任务中,解码器的作用是将编码器输出的特征图转换为目标框的位置和类别信息。具体来说,解码器接受编码器输出的特征图,并对其进行处理和解码,得到目标的位置和类别信息。
解码器通常包含一系列卷积层、池化层和全连接层,以及用于位置解码和类别预测的不同层。
- 对于位置解码,解码器通常使用回归器来预测目标框的位置和大小,例如使用四个参数来表示目标框的左上角坐标、宽度和高度。
- 对于类别预测,解码器使用分类器来预测每个目标框所属的类别。
在DETR中,解码器使用Transformer结构,将编码器的特征图转换为一组对象嵌入向量,并将其输入到Transformer解码器中。解码器通过多层自注意力机制来将特征图中的对象嵌入向量与目标框的位置和类别信息相结合,从而得到最终的检测结果。
在DETR中,解码器主要通过注意力机制(self-attention)来实现对编码器输出特征图的解码,从而得到目标的位置和类别信息。
具体来说,解码器在每个解码步骤中:
-
首先使用一个自注意力模块来对编码器输出特征图进行注意力计算;
-
然后将自注意力计算结果和编码器输出特征图的信息融合,得到解码器当前的输入;
-
接下来,解码器使用一个多层感知机(MLP)来对当前输入进行处理,得到目标类别的概率分布和位置信息的偏移量,进而得到最终的目标位置和类别信息。
值得注意的是,在DETR中,解码器是通过自注意力机制来获取不同目标之间的交互信息,从而实现全局推理。这种方式相比于传统的基于区域提取的目标检测方法,可以减少手工设计的模块,同时还能更好地处理目标之间的遮挡和重叠等问题,因此具有更好的鲁棒性和泛化能力。
三、注意力机制的理解
注意力机制是一种计算机视觉和自然语言处理等领域常用的技术,用于指导模型在输入数据中聚焦于重要的部分。
其基本思想是,将输入数据映射到一个高维空间中,在这个空间中计算每个输入位置的重要性分数,并根据分数的大小分配不同的权重。这样,模型就可以聚焦于那些具有更高重要性分数的输入位置,从而提高模型的性能。
在注意力机制中,有多种不同的实现方式,比较常见的有以下两种:
- 自注意力机制(self-attention):自注意力机制是指在同一序列中的每个元素之间进行注意力计算。具体来说,对于输入序列 X=[x1,x2,...,xn]X=[x_1, x_2, ..., x_n]X=[x1,x2,...,xn],其中每个 xix_ixi 都表示一个向量,自注意力机制会对每个 xix_ixi 计算一个对应的权重向量 wiw_iwi,并根据权重向量对输入序列进行加权求和,得到表示整个序列的向量 vvv。自注意力机制的目的是在同一序列中学习不同位置之间的依赖关系。
- 注意力机制(attention):注意力机制是指将两个不同的序列之间的注意力计算。具体来说,假设有两个输入序列 X=[x1,x2,...,xn]X=[x_1, x_2, ..., x_n]X=[x1,x2,...,xn] 和 Y=[y1,y2,...,ym]Y=[y_1, y_2, ..., y_m]Y=[y1,y2,...,ym],其中每个 xix_ixi 和 yjy_jyj 都表示一个向量,注意力机制会对每个 xix_ixi 计算一个对应的权重向量 wiw_iwi,并将其与 YYY 进行加权求和,得到一个表示 XXX 中每个元素对 YYY 的贡献的向量 vvv。注意力机制的目的是在不同序列之间学习相关性。
相关文章:
【计算机视觉 | 目标检测】DETR风格的目标检测框架解读
文章目录一、前言二、理解2.1 DETR的理解2.2 DETR的细致理解2.2.1 Backbone2.2.2 Transformer encoder2.2.3 Transformer decoder2.2.4 Prediction feed-forward networks (FFNs)2.2.5 Auxiliary decoding losses2.3 更具体的结构2.4 编码器的原理和作用2.5 解码器的原理和作用…...

【LeetCode】剑指 Offer 41. 数据流中的中位数 p214 -- Java Version
题目链接:https://leetcode.cn/problems/shu-ju-liu-zhong-de-zhong-wei-shu-lcof 1. 题目介绍(41. 数据流中的中位数) 如何得到一个数据流中的中位数?如果从数据流中读出奇数个数值,那么中位数就是所有数值排序之后位…...

CSS3 知识总结
1,什么是CSS 用于定义网页的样式,包括不同设备和屏幕尺寸的设计、布局和显示变化。 2,CSS的作用优点 CSS 描述 HTML 元素如何在屏幕、纸张或其他媒体上显示 CSS 节省了大量工作。它可以一次控制多个网页的布局 3,css构成 CSS 规…...

回溯算法37:解数独
主要是我自己刷题的一些记录过程。如果有错可以指出哦,大家一起进步。 转载代码随想录 原文链接: 代码随想录 leetcode链接:37. 解数独 题目: 编写一个程序,通过填充空格来解决数独问题。 数独的解法需 遵循如下规则…...

【蓝桥杯-筑基篇】动态规划
🍓系列专栏:蓝桥杯 🍉个人主页:个人主页 目录 1.最大连续子段和 2.LCS 最大公共子序列 3.LIS 最长上升子序列 4.数塔 5.最大子矩阵和 6.背包问题 ①01背包问题 ②完全背包 1.最大连续子段和 这段代码是一个求最大子数组和的算法,使用…...

Unity利用Photon PUN2框架快速实现多人在线游戏实例分享
简介 Photon 是一个泛用性的 ScoketServer 套装软件,可用于多人在线游戏、聊天室、大厅游戏,并同时支持 Windows、Unity3D、iOS、Android、Flash 等平台。Photon 包含两个部分,一部分是 Socket 服务器,另一部分是其针对各个平台编写的 SDK,Unity3D 平台对应的 SDK 为 Pho…...

ChatGPT直出1.5w字论文查重率才30% - 基于物联网技术的智能家居控制系统设计与实现
文章目录ChatGPT直出1.5w字论文查重率才30% - 基于物联网技术的智能家居控制系统设计与实现一、绪论1.1 研究背景与意义1.2 国内外研究现状分析1.3 研究内容与目标1.4 研究方向和思路二、物联网技术与智能家居概述2.1 物联网技术原理与应用2.2 智能家居的概念与发展历程2.3 智能…...

特斯拉的操作系统是用什么语言编写的?
总目录链接>> AutoSAR入门和实战系列总目录 文章目录特斯拉车辆操作系统特斯拉GitHub中使用的语言Ruby和GoPythonSwift 和 Objective CQt我们知道操作系统至少需要一些非常低级的代码,这些代码在系统首次启动时运行,必须使用接近硬件的语言编写。…...

C++学习8-C++提高编程
文章目录前言一、模板1.1 模板的概念1.2 函数模板1.2.1 函数模板语法1.2.2 函数模板注意事项1.2.3 函数模板案例复习:计算数组长度1.2.4 普通函数与函数模板的区别1.2.5 普通函数与函数模板的调用规则1.2.6 模板的局限性1.3 类模板1.3.1 类模板语法1.3.2 类模板与函…...

ubuntu安装git server
一安装 要在Ubuntu上安装Git服务器,需要按照以下步骤进行操作: 安装Git: sudo apt-get update sudo apt-get install git 创建一个Git用户和一个Git仓库目录: sudo adduser git sudo mkdir /home/git/repo.git sudo chown git:git /home/git/repo.git 初始化Git仓库: c…...

物流云数据分析平台
物流云数据分析服务平台 http://project.webcats.cn/bx/36569/2455/index.html 本次系统模拟的是湖南省数据,解释权归杭氏集团所有! 1、系统简介: 物流大数据集成展示系统旨在通过大屏幕全面显示指定地区的物流运营车辆、物流公司和货主的相关信息和…...
配置OBS存储功能、新搭建obs
通过应用开发环境与OBS(Object-based Storage Service)对接,实现对象或者Widget资产存储功能。 背景信息 对象存储服务(Object-based Storage Service,OBS)是一个基于对象的海量存储服务,为客…...
基于DPDK收包的suricata的安装和运行
操作系统版本:Ubuntu 20.04.5 suricata版本: suricata-7.0.0-rc1 suricata是一个基于规则的入侵检测和防御引擎,功能强大,但性能可能 差强人意,不过目前最新的7版本已经支持DPDK收包了,DPDK是Intel提供的高…...
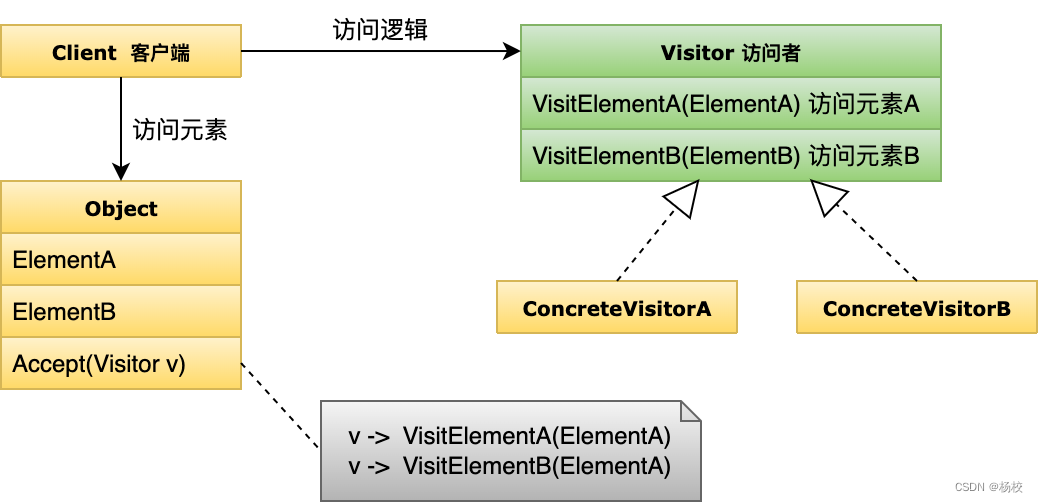
浅谈23种设计模式
创建型模式 有5种设计模式 抽象工厂(Abstract Factory):多套方案 抽象工厂模式是对创建不同的产品类型的抽象。对应到工作中,我们的确应该具备提供多套方案的能力,这也是我们常说的,要提供选择题。当你有这…...
JetBrains Rider 2022.3.3 Crack
具有 ReSharper 强大功能的令人难以置信的 .NET IDE!Rider 在我们使用 Windows 和 macOS 的整个开发团队中使用。 什么是骑士? JetBrains Rider 是一个基于 IntelliJ 平台和 ReSharper 的跨平台 .NET IDE。 支持许多 .NET 项目类型 JetBrains Rider 支持…...

浅理解扁平数据结构转Tree(树形结构)
文章目录📋前言🎯扁平数据结构🎯树形数据结构🎯使用递归将扁平数据转换为树形数据📝最后📋前言 在前端开发中,我们经常需要将扁平数据结构转换为树形结构(Tree)。比如在…...

前端开发——JavaScript的条件语句
世界不仅有黑,又或者白 世界而是一道精致的灰 ——Lungcen 目录 条件判断语句 if 语句 if else 语句 if else if else 语句 switch语句 break 关键字 case 子句 default语句 while循环语句 do while循环语句 for循环语句 for 循环中的三个表达式 for 循环嵌套 for …...

2.11 循环赛日程表
博主简介:一个爱打游戏的计算机专业学生博主主页: 夏驰和徐策所属专栏:算法设计与分析 目录 书本内容: 我的理解: 更优化的算法: 总结 1.注意实现问题 2.当用C语言和C实现循环赛日程表算法时ÿ…...

SpringBoot——SB整合mybatis案例(残缺版本)第三集
了解完使用阿里云存储的操作后,现在需要在案例里面集成阿里云进行开发。云服务——阿里云OSS的入门使用_北岭山脚鼠鼠的博客-CSDN博客 阿里云OSS——集成 对于前端传过来的图片要先上传到OSS,然后获取图片在云端的访问地址,存储到数据库里面…...
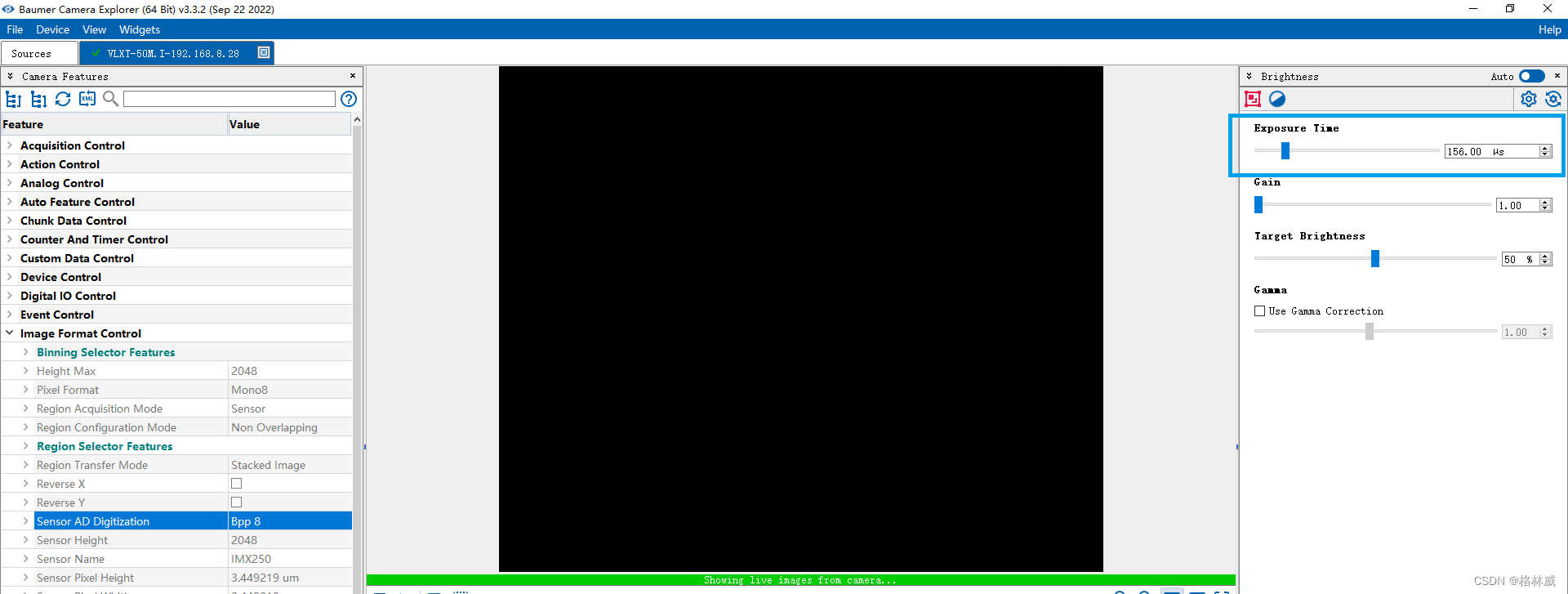
Baumer工业相机堡盟相机不满帧如何使用CameraExplorer设置相机参数让它的帧率达到满帧
项目场景 Baumer工业相机堡盟相机是一种高性能、高质量的工业相机,可用于各种应用场景,如物体检测、计数和识别、运动分析和图像处理。 Baumer的万兆网相机拥有出色的图像处理性能,可以实时传输高分辨率图像。此外,该相机还具…...

如何用OpenCore Legacy Patcher让老旧Mac焕发新生:5分钟快速上手指南
如何用OpenCore Legacy Patcher让老旧Mac焕发新生:5分钟快速上手指南 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 还在为你的老旧Mac无法升级到…...

Wand-Enhancer:免费解锁WeMod专业版功能的终极本地增强工具
Wand-Enhancer:免费解锁WeMod专业版功能的终极本地增强工具 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的高昂订阅费用…...

基于Docker部署OpenOffice无头服务实现文档自动化处理
1. 项目概述与核心价值最近在折腾文档处理自动化流程,发现很多老项目或者特定场景下,对Office文档的兼容性要求极高,尤其是那些需要处理.doc、.xls、.ppt等老格式的场景。直接用现代办公套件(比如LibreOffice)去处理&a…...

ARM Neoverse-V3架构解析与性能优化实战
1. ARM Neoverse-V3架构概览作为Arm公司面向基础设施领域的最新处理器IP,Neoverse-V3代表了当前服务器级处理器的顶尖设计水平。我在实际芯片开发中多次接触该架构,其设计哲学可概括为:通过精细化微架构控制实现性能与能效的完美平衡。1.1 指…...
,现在必须掌握的3种替代渲染方案)
像素艺术家紧急预警:Midjourney即将关闭--tile参数兼容性(倒计时14天),现在必须掌握的3种替代渲染方案
更多请点击: https://intelliparadigm.com 第一章:像素艺术家紧急预警:Midjourney即将关闭--tile参数兼容性(倒计时14天) Midjourney v6.5 已正式宣布将于 14 天后终止对 --tile 参数的原生支持,此举将直…...

从零打造会“看”的电子眼:Teensy与OLED的嵌入式图形与传感器实践
1. 项目概述:打造一个会“看”的电子生命体几年前,我第一次在创客社区看到“Uncanny Eyes”项目时就被深深吸引了。一个微小的OLED屏幕,在代码驱动下,竟然能呈现出如此逼真、灵动的眼球运动,那种介于生命与机械之间的诡…...

Biomni项目解析:大语言模型与生物医学知识图谱融合实践
1. 项目概述:当大语言模型遇见生物医学知识图谱最近在探索如何让大语言模型(LLM)在专业领域,特别是生物医学这种信息密集、关系复杂的领域,变得更“靠谱”一点。相信很多同行都遇到过类似的问题:直接问Chat…...

Git安全增强实战:使用Ante实现策略即代码的版本控制防护
1. 项目概述:一个为开发者打造的“代码保险箱”如果你和我一样,在职业生涯中经历过几次“代码灾难”——比如不小心git push -f覆盖了同事的提交,或者手滑rm -rf删除了一个正在开发中的功能分支——那你一定会对“代码安全”这四个字有切肤之…...

基于RP2040的客制化宏键盘:从硬件设计到KMK固件开发全攻略
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫clawdpad,作者是kudretyilmazz。乍一看这个名字,可能有点摸不着头脑,但如果你对机械键盘、客制化输入设备或者桌面自动化感兴趣,那这个项目绝对值得你花时间…...

SoC片上系统:从架构原理到选型实战的深度解析
1. 项目概述:从“黑盒子”到“智慧核心”的认知跃迁在电子产品的世界里,我们常常惊叹于一部智能手机的纤薄与强大,它既能流畅播放高清视频,又能处理复杂的游戏画面,还能实时连接网络、定位导航。这一切的背后ÿ…...