DAY17||654.最大二叉树 |617.合并二叉树 |700.二叉搜索树中的搜索 |
654.最大二叉树
题目:654. 最大二叉树 - 力扣(LeetCode)
给定一个不含重复元素的整数数组。一个以此数组构建的最大二叉树定义如下:
- 二叉树的根是数组中的最大元素。
- 左子树是通过数组中最大值左边部分构造出的最大二叉树。
- 右子树是通过数组中最大值右边部分构造出的最大二叉树。
通过给定的数组构建最大二叉树,并且输出这个树的根节点。
示例 :

构造二叉树一定要前序遍历,因为要先找到中,才能分割左右子树。
本题图解思路:

class Solution {
public:TreeNode* constructMaximumBinaryTree(vector<int>& nums) {TreeNode*node=new TreeNode(0);//如果数组只有一个元素的情况if(nums.size()==1){node->val=nums[0];return node;}//找到中int maxValue=0;int maxValueIndex=0;for(int i=0;i<nums.size();i++){if(nums[i]>maxValue){maxValueIndex=i;maxValue=nums[i];}}node->val=maxValue;//分割左右子树//递归构建左子树,新建一个数组if(maxValueIndex>0)//保证数组元素大于1,如果不写if的话就要另开一个函数,空的情况返回{vector<int>leftvec(nums.begin(),nums.begin()+maxValueIndex);//左开右闭写法node->left=constructMaximumBinaryTree(leftvec);}//递归构建右子树if(maxValueIndex<nums.size()-1){vector<int>rightvec(nums.begin()+maxValueIndex+1,nums.end());node->right=constructMaximumBinaryTree(rightvec);}return node;}
};本题做过上一题构建数组确实变得容易很多。代码优化方向有,不用每次找左右子树的时候构建新的数组的话效率就会高很多。(即直接用下标索引直接在原数组上操作)
关于加不加if的问题,如果允许空节点进入递归,就不加。
617.合并二叉树
题目:617. 合并二叉树 - 力扣(LeetCode)
给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠。
你需要将他们合并为一个新的二叉树。合并的规则是如果两个节点重叠,那么将他们的值相加作为节点合并后的新值,否则不为 NULL 的节点将直接作为新二叉树的节点。
示例 1:
注意: 合并必须从两个树的根节点开始

哪种遍历方式都可以。其实就是同时遍历两颗二叉树,相同位置上的元素合并,如果一方有一方没有的情况,就把2的节点加到1中去就可以了。
前序遍历例子:
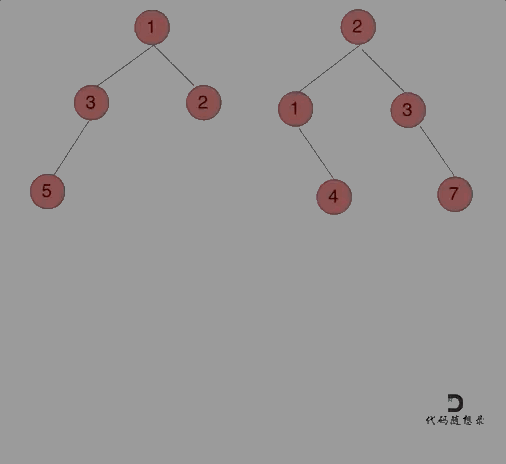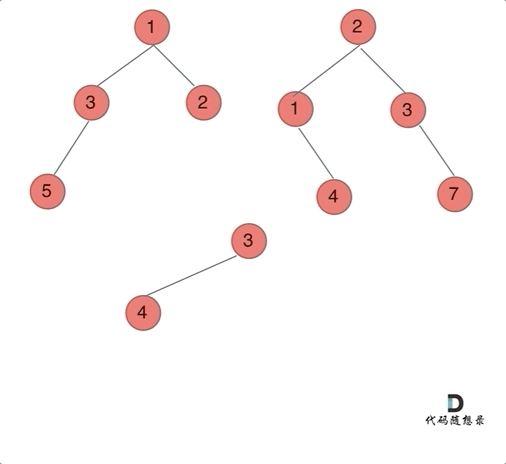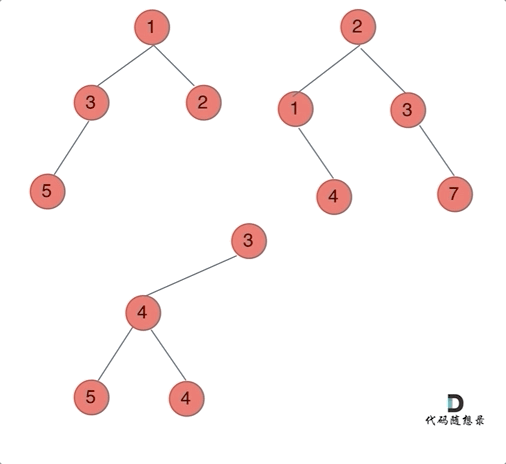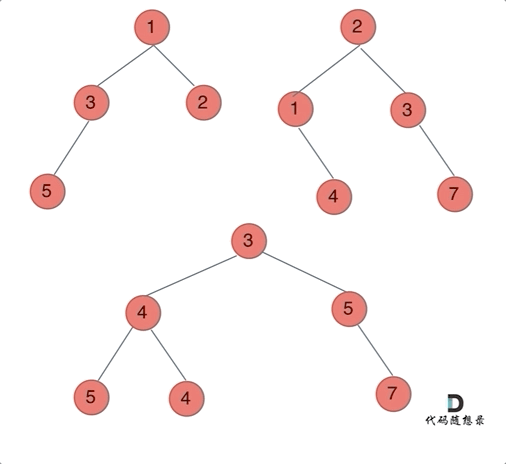
前中后序的区别只是左中右的顺序调换而已。
前序遍历(递归)
class Solution {
public:TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {if(root1==NULL)return root2;//如果t1为空,返回t2的值。如果两个都为空,那么其实返回的就是NULL了if(root2==NULL)return root1;root1->val+=root2->val;//合并root1->left=mergeTrees(root1->left,root2->left);root1->right=mergeTrees(root1->right,root2->right);return root1;}
};迭代法(层序遍历)
使用队列来其实这个写法最好理解思路。
同时遍历,入队列。
需要注意的是节点的左右子树入列的时候,当左子树不为空,右子树为空的情况其实已经被左子树的值加上右子树的值 处理过了
class Solution {
public:TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {if(root1==NULL)return root2;if(root2==NULL)return root1;queue<TreeNode*>que;//一定都不为空入列que.push(root1);que.push(root2);while(!que.empty()){TreeNode*node1=que.front();que.pop();TreeNode*node2=que.front();que.pop();node1->val+=node2->val;//合并步骤if(node1->left&&node2->left)//两棵树的左子树都在,入列{que.push(node1->left);que.push(node2->left);}if(node1->right&&node2->right)//两棵树的右子树都在,入列{que.push(node1->right);que.push(node2->right);}if(!node1->left&&node2->left)//如果1的左空,2的不空,就把2的赋值过去{node1->left=node2->left;}if(!node1->right&&node2->right)//如果1的左空,2的不空,就把2的赋值过去{node1->right=node2->right;}}return root1;//这里返回的是root1而不是node1的原因是,node1只是一个指针,它操作的对象是入了队列的root数}
};其实,定义的node1和node2是一个指针,它指向指针root1和root2.
700.二叉搜索树中的搜索
题目700. 二叉搜索树中的搜索 - 力扣(LeetCode)
给定二叉搜索树(BST)的根节点和一个值。 你需要在BST中找到节点值等于给定值的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 NULL。
例如,
在上述示例中,如果要找的值是 5,但因为没有节点值为 5,我们应该返回 NULL。
二叉搜索树是一个有序树:
- 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值;
- 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值;
- 它的左、右子树也分别为二叉搜索树
因为二叉搜索树的节点是有序的,所以可以有方向的去搜索。
如果root->val > val,搜索左子树,如果root->val < val,就搜索右子树,最后如果都没有搜索到,就返回NULL。
递归法
class Solution {
public:TreeNode* searchBST(TreeNode* root, int val) {if(root==NULL||root->val==val)return root;//如果为空或者找到了值,就返回//找左子树if(root->val>val)return searchBST(root->left,val);//找右子树if(root->val<val)return searchBST(root->right,val);return NULL;}
};迭代法
对于一般二叉树,递归过程中还有回溯的过程,例如走一个左方向的分支走到头了,那么要调头,在走右分支。
而对于二叉搜索树,不需要回溯的过程,因为节点的有序性就帮我们确定了搜索的方向。
class Solution {
public:TreeNode* searchBST(TreeNode* root, int val) {while(root){if(root->val>val)root=root->left;else if(root->val<val)root=root->right;else return root;}return NULL;}
};本题真的非常简单。因为二叉搜索树的有序性,所以不需要回溯写法。
98.验证二叉搜索树
题目:98. 验证二叉搜索树 - 力扣(LeetCode)
本题看似简单,陷阱挺多的。
我们要比较的是 左子树所有节点小于中间节点,右子树所有节点大于中间节点。
递归法
1.可以中序遍历,把所有节点元素放入一个数组,然后在逐个比较数组是否是递增的。(个人觉得好理解)
class Solution {private:vector<int>vec;void traversal(TreeNode*root){if(root==NULL)return;if(root->left)traversal(root->left);vec.push_back(root->val);if(root->right)traversal(root->right);}
public:bool isValidBST(TreeNode* root) {vec.clear();traversal(root);for(int i=1;i<vec.size();i++){if(vec[i]<=vec[i-1])return false;}return true;}
};2.当然也可以直接在递归遍历时比较节点大小
只有寻找某一条边(或者一个节点)的时候,递归函数会有bool类型的返回值。
其实本题是同样的道理,我们在寻找一个不符合条件的节点,如果没有找到这个节点就遍历了整个树,如果找到不符合的节点了,立刻返回。
class Solution {
public:long long maxVal = LONG_MIN; // 因为后台测试数据中有int最小值bool isValidBST(TreeNode* root) {if(root==NULL)return true;//空二叉树(即没有任何节点的二叉树)被认为是一个有效的二叉搜索树(BST)。bool right=isValidBST(root->left);//左//中。遍历整棵树,其实如果遇到不是递增的情况就返回false了。if(maxVal<root->val)maxVal=root->val;else return false;bool left=isValidBST(root->right);//右,不需要加if条件判断节点是否为空,因为空节点直接返回truereturn left&&right;}
};
maxVal是一个用于记录当前遍历到的节点值的变量。初始化为LONG_MIN是为了确保无论二叉树的节点值多小,它们最初都比这个值大。这是因为二叉搜索树的性质要求,左子树中的所有节点值都小于根节点值。最终返回值是左子树(
right)和右子树(left)验证结果的 逻辑与(&&),只有当左右子树都为 BST 时,整棵树才是 BST。
迭代法
使用栈模拟中序遍历。其实就是双指针法的。一个指针指向树节点,另一个指针指向NULL。当中序遍历走的过程,两指针同步移动,pre一定指向cur的上一个指向的节点。(好理解)
class Solution {
public:bool isValidBST(TreeNode* root) {stack<TreeNode*>st;TreeNode*cur=root;TreeNode*pre=NULL;while(cur!=NULL||!st.empty()){if(cur!=NULL){st.push(cur);cur=cur->left;//左子树入栈,按栈的存储结构和中序遍历特性,只要左树一直不为空,就入栈,反正出栈顺序就是中序遍历的顺序!}else//如果当前节点为空但栈不为空,就遍历右子树,并且比较是否符合二叉搜索树特性{cur=st.top();//中st.pop();//出栈if(pre!=NULL&&cur->val<=pre->val)return false;//错误情况pre=cur;//保存上一个数cur=cur->right;//右}}return true; }
};相关文章:

DAY17||654.最大二叉树 |617.合并二叉树 |700.二叉搜索树中的搜索 |
654.最大二叉树 题目:654. 最大二叉树 - 力扣(LeetCode) 给定一个不含重复元素的整数数组。一个以此数组构建的最大二叉树定义如下: 二叉树的根是数组中的最大元素。左子树是通过数组中最大值左边部分构造出的最大二叉树。右子树…...

读构建可扩展分布式系统:方法与实践16读后总结与感想兼导读
1. 基本信息 构建可扩展分布式系统:方法与实践 [美]伊恩戈顿(Ian Gorton)著 机械工业出版社,2024年5月出版 1.1. 读薄率 书籍总字数188千字,笔记总字数49688字。 读薄率49688188000≈26.4% 1.2. 读厚方向 设计模式:可复用面向对象软件的…...

Anaconda 安装
目录 - [简介](#简介) - [安装Anaconda](#安装anaconda) - [启动Anaconda Navigator](#启动anaconda-navigator) - [创建环境](#创建环境) - [管理包](#管理包) - [常用命令行操作](#常用命令行操作) - [Jupyter Notebook 快速入门](#jupyter-notebook-快速入门) - [结…...

优雅使用 MapStruct 进行类复制
前言 在项目中,常常会遇到从数据库读取数据后不能直接返回给前端展示的情况,因为还需要对字段进行加工,比如去除时间戳记录、隐藏敏感数据等。传统的处理方式是创建一个新类,然后编写大量的 get/set 方法进行赋值,若字…...

第19周JavaWeb编程实战-MyBatis实现OA系统 1-OA系统
办公OA系统项目开发 课程简介 本课程将通过慕课办公OA平台的开发,讲解实际项目开发中必须掌握的技能和设计技巧。课程分为三个主要阶段: 需求说明及环境准备: 基于RBAC的访问控制模块开发: 多级请假审批流程开发: …...
)
仿黑神话悟空跑动-脚下波纹特效(键盘wasd控制走动)
vue使用three.js实现仿黑神话悟空跑动-脚下波纹特效 玩家角色的正面始终朝向鼠标方向,且在按下 W 键时,玩家角色会朝着鼠标方向前进 空格建跳跃 <template><div ref"container" class"container" click"onClick"…...

`torch.utils.data`模块
在PyTorch中,torch.utils.data模块提供了许多有用的工具来处理和加载数据。以下是对您提到的DataLoader, Subset, BatchSampler, SubsetRandomSampler, 和 SequentialSampler的详细解释以及使用示例。 1. DataLoader DataLoader是PyTorch中用于加载数据的一个非常…...
` 函数:安全拼接字符串)
深入理解 `strncat()` 函数:安全拼接字符串
目录: 前言一、 strncat() 函数的基本用法二、 示例代码三、 strncat() 与 strcat() 的区别四、 注意事项五、 实际应用场景总结 前言 在C语言中,字符串操作是编程中非常常见的需求。strncat() 函数是标准库中用于字符串拼接的一个重要函数,…...

OpenCV_自定义线性滤波(filter2D)应用详解
OpenCV filter2D将图像与内核进行卷积,将任意线性滤波器应用于图像。支持就地操作。当孔径部分位于图像之外时,该函数根据指定的边界模式插值异常像素值。 卷积核本质上是一个固定大小的系数数组,数组中的某个元素被作为锚点(一般…...

设计模式之装饰模式(Decorator)
前言 这个模式带给我们有关组合跟继承非常多的思考 定义 “单一职责” 模式。动态(组合)的给一个对象增加一些额外的职责。就增加功能而言,Decorator模式比生成子类(继承)更为灵活(消除重复代码 & 减少…...

大数据-146 Apache Kudu 安装运行 Dockerfile 模拟集群 启动测试
点一下关注吧!!!非常感谢!!持续更新!!! 目前已经更新到了: Hadoop(已更完)HDFS(已更完)MapReduce(已更完&am…...

React入门准备
React是什么 React是一个用于构建用户界面的JavaScript框架,用于构建“可预期的”和“声明式的”Web用户界面,特别适合于构建那些数据会随时间改变的大型应用的用户界面。 它起源于Facebook的内部项目,因为对市场上所有JavaScript MVC框架都…...

robomimic基础教程(四)——开源数据集
robomimic开源了大量数据集及仿真环境,数据集标准格式为HDF5 目录 一、基础要求 二、使用步骤 1. 下载数据集 2. 后处理 3. 训练 4. 查看训练结果 三、HDF5数据集结构与可视化 1. 数据集结构 (1)根级别(data 组 group&a…...

胤娲科技:AI界的超级充电宝——忆阻器如何让LLM告别电量焦虑
当AI遇上“记忆橡皮擦”,电量不再是问题! 嘿,朋友们,你们是否曾经因为手机电量不足而焦虑得像个无头苍蝇?想象一下,如果这种“电量焦虑”也蔓延到了AI界, 特别是那些聪明绝顶但“耗电如喝水”的…...

前端大模型入门:使用Transformers.js手搓纯网页版RAG(二)- qwen1.5-0.5B - 纯前端不调接口
书接上文,本文完了RAG的后半部分,在浏览器运行qwen1.5-0.5B实现了增强搜索全流程。但受限于浏览器和模型性能,仅适合于研究、离线和高隐私场景,但对前端小伙伴来说大模型也不是那么遥不可及了,附带全部代码,…...

K-means聚类分析对比
K-means聚类分析,不同K值聚类对比,该内容是关于K-means聚类分析的,主要探讨了不同K值对聚类结果的影响。K-means聚类是一种常见的数据分析方法,用于将数据集划分为K个不同的类别。在这个过程中,选择合适的K值是非常关键…...

tar命令:压缩、解压的好工具
一、命令简介 用途: tar 命令用于创建归档文件(tarball),以及从归档文件中提取文件。 标签: 文件管理,归档。 特点: 归档文件可以保留原始文件和目录的层次结构,通常使用 .tar …...

Mac电脑上最简单安装Python的方式
背景 最近换了一台新的 MacBook Air 电脑,所有的开发软件都没有了,需要重新配环境,而我现在最常用的开发程序就是Python。这篇文章记录一下我新Mac电脑安装Python的全过程,也给大家一些思路上的提醒。 以下是我新电脑的配置&…...

Linux基础命令cd详解
cd(change directory)命令是 Linux 中用于更改当前工作目录的基础命令。它没有很多复杂的参数,但它的使用非常频繁。以下是 cd 命令的详细说明及示例。 基本语法 cd [选项] [路径] 常用选项 -L : 使用逻辑路径(默认选项&…...

【大模型对话 的界面搭建-Open WebUI】
Open WebUI 前身就是 Ollama WebUI,为 Ollama 提供一个可视化界面,可以完全离线运行,支持 Ollama 和兼容 OpenAI 的 API。 github网址 https://github.com/open-webui/open-webui安装 第一种 docker安装 如果ollama 安装在同一台服务器上&…...

3种实战方法深度解析:如何高效使用TrollInstallerX安装TrollStore越狱工具
3种实战方法深度解析:如何高效使用TrollInstallerX安装TrollStore越狱工具 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX TrollInstallerX是一款专为iOS 14…...

AI技能白日梦:让大模型通过自主推演实现能力进化
1. 项目概述:当AI学会“白日做梦”最近在GitHub上看到一个挺有意思的项目,叫regiep4/skill-daydreaming。光看这个名字,就让人浮想联翩——“技能白日梦”?这听起来不像是一个传统的工具库或者框架,更像是一种对AI能力…...

机器人抓取仿真与数据分析:从PyBullet集成到抓取性能评估
1. 项目概述与核心价值最近在机器人控制与仿真领域,一个名为PyroMind-Dynamics/openclaw-tracer的项目引起了我的注意。乍一看这个标题,它像是一个典型的GitHub仓库名,由组织名“PyroMind-Dynamics”和项目名“openclaw-tracer”组成。作为一…...

别浪费了STM32F103C8T6的PA13和PA14!SWD下载后,教你一键解锁这两个GPIO
解锁STM32F103C8T6的PA13/PA14引脚:从SWD调试到GPIO复用的实战指南 刚拿到STM32F103C8T6核心板时,很多开发者会对着有限的引脚发愁——尤其是那些标着"SWDIO"和"SWCLK"的PA13/PA14引脚。难道这两个引脚只能永远被调试接口占用&#…...

自建个人知识管理系统Memex:从数据捕获到知识图谱的实践
1. 项目概述:一个私人数字记忆库的诞生几年前,我开始意识到一个严重的问题:我的数字生活正在变得支离破碎。一篇在浏览器里偶然看到的深度文章,一个在社交媒体上转瞬即逝的灵感火花,一段在播客里听到的精彩论述&#x…...

可视化大屏怎么做?可视化大屏工具你会用吗?
可视化大屏早已不只是技术人员的专属,越来越多的运营、产品和市场人也开始尝试,但是常常陷入各种问题:比如硬件效果一般、数据堆积没重点、动效杂乱干扰信息传达……其实归根结底,这些问题都指向一个核心:缺少一个专业…...

092、Python在芯片验证中的应用:从脚本小子到验证架构师
092、Python在芯片验证中的应用:从脚本小子到验证架构师 一、那个凌晨三点的调试现场 上周三凌晨三点,实验室的空调嗡嗡作响。面前的屏幕上,UVM验证环境跑了八小时,终于在随机测试第237次迭代时触发了那个诡异的时序违例。日志文件12GB,波形文件更是高达80GB。手动分析?…...

Vue 3 Composition API驱动下的企业级日期时间选择器架构演进与实践
Vue 3 Composition API驱动下的企业级日期时间选择器架构演进与实践 【免费下载链接】vue3-date-time-picker Datepicker component for Vue 3 项目地址: https://gitcode.com/gh_mirrors/vu/vue3-date-time-picker 在现代化Web应用开发中,日期时间选择器作为…...

从SRResNet到实战:基于Pytorch的图像超分辨率重建全流程解析
1. 图像超分辨率重建基础入门 第一次接触图像超分辨率技术时,我被它的魔法般的效果震撼到了。简单来说,这项技术就是让模糊的老照片变清晰,让低分辨率的监控画面呈现更多细节。在实际项目中,我经常遇到客户拿着十几年前的老照片希…...
)
手把手教你用rtsp-simple-server和FFmpeg在Windows上搭建个人视频流媒体服务器(保姆级教程)
手把手教你用rtsp-simple-server和FFmpeg在Windows上搭建个人视频流媒体服务器 在数字化生活日益普及的今天,个人视频流媒体服务器的需求正在快速增长。无论是想搭建家庭监控系统原型,还是为开发项目创建测试环境,亦或是单纯出于技术爱好探索…...