8个明显可以提升数据处理效率的 Python 神库
在进行数据科学时,可能会浪费大量时间编码并等待计算机运行某些东西。所以我选择了一些 Python 库,可以帮助你节省宝贵的时间
文章目录
- 1、Optuna
- 技术提升
- 2、ITMO\_FS
- 3、Shap-hypetune
- 4、PyCaret
- 5、floWeaver
- 6、Gradio
- 7、Terality
- 8、Torch-Handle
1、Optuna
Optuna 是一个开源的超参数优化框架,它可以自动为机器学习模型找到最佳超参数。
最基本的(也可能是众所周知的)替代方案是 sklearn 的 GridSearchCV,它将尝试多种超参数组合并根据交叉验证选择最佳组合。
GridSearchCV 将在先前定义的空间内尝试组合。例如,对于随机森林分类器,可能想要测试几个不同的树的最大深度。GridSearchCV 会提供每个超参数的所有可能值,并查看所有组合。
Optuna会在定义的搜索空间中使用自己尝试的历史来确定接下来要尝试的值。它使用的方法是一种称为“Tree-structured Parzen Estimator”的贝叶斯优化算法。
这种不同的方法意味着它不是无意义的地尝试每一个值,而是在尝试之前寻找最佳候选者,这样可以节省时间,否则这些时间会花在尝试没有希望的替代品上(并且可能也会产生更好的结果)。
最后,它与框架无关,这意味着您可以将它与 TensorFlow、Keras、PyTorch 或任何其他 ML 框架一起使用。
技术提升
技术要学会分享、交流,不建议闭门造车。一个人走的很快、一堆人可以走的更远。
完整代码、数据、技术交流提升, 均可加知识星球交流群获取,群友已超过2000人,添加时切记的备注方式为:来源+兴趣方向,方便找到志同道合的朋友。
方式①、添加微信号:pythoner666,备注:来自 CSDN + python
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
2、ITMO_FS
ITMO_FS 是一个特征选择库,它可以为 ML 模型进行特征选择。拥有的观察值越少,就越需要谨慎处理过多的特征,以避免过度拟合。所谓“谨慎”意思是应该规范你的模型。通常一个更简单的模型(更少的特征),更容易理解和解释。
ITMO_FS 算法分为 6 个不同的类别:监督过滤器、无监督过滤器、包装器、混合、嵌入式、集成(尽管它主要关注监督过滤器)。
“监督过滤器”算法的一个简单示例是根据特征与目标变量的相关性来选择特征。“backward selection”,可以尝试逐个删除特征,并确认这些特征如何影响模型预测能力。
这是一个关于如何使用 ITMO_FS 及其对模型分数的影响的普通示例:
>>> from sklearn.linear_model import SGDClassifier
>>> from ITMO_FS.embedded import MOS >>> X, y = make_classification(n_samples=300, n_features=10, random_state=0, n_informative=2)
>>> sel = MOS()
>>> trX = sel.fit_transform(X, y, smote=False) >>> cl1 = SGDClassifier()
>>> cl1.fit(X, y)
>>> cl1.score(X, y)
0.9033333333333333 >>> cl2 = SGDClassifier()
>>> cl2.fit(trX, y)
>>> cl2.score(trX, y)
0.9433333333333334
ITMO_FS是一个相对较新的库,因此它仍然有点不稳定,但我仍然建议尝试一下。
3、Shap-hypetune
到目前为止,我们已经看到了用于特征选择和超参数调整的库,但为什么不能同时使用两者呢?这就是 shap-hypetune 的作用。
让我们从了解什么是“SHAP”开始:
“SHAP(SHapley Additive exPlanations)是一种博弈论方法,用于解释任何机器学习模型的输出。”
SHAP 是用于解释模型的最广泛使用的库之一,它通过产生每个特征对模型最终预测的重要性来工作。
另一方面,shap-hypertune 受益于这种方法来选择最佳特征,同时也选择最佳超参数。你为什么要合并在一起?因为没有考虑它们之间的相互作用,独立地选择特征和调整超参数可能会导致次优选择。同时执行这两项不仅考虑到了这一点,而且还节省了一些编码时间(尽管由于搜索空间的增加可能会增加运行时间)。
搜索可以通过 3 种方式完成:网格搜索、随机搜索或贝叶斯搜索(另外,它可以并行化)。但是,shap-hypertune 仅适用于梯度提升模型!
4、PyCaret
PyCaret 是一个开源、低代码的机器学习库,可自动执行机器学习工作流。它涵盖探索性数据分析、预处理、建模(包括可解释性)和 MLOps。
让我们看看他们网站上的一些实际示例,看看它是如何工作的:
# load dataset
from pycaret.datasets import get_data
diabetes = get_data('diabetes') # init setup
from pycaret.classification import *
clf1 = setup(data = diabetes, target = 'Class variable') # compare models
best = compare_models()
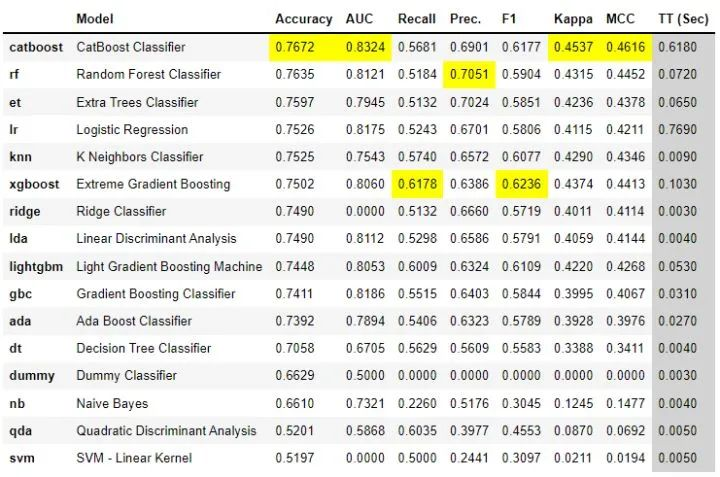
只需几行代码,就可以尝试多个模型,并在整个主要分类指标中对它们进行了比较。
它还允许创建一个基本的应用程序来与模型进行交互:
from pycaret.datasets import get_data
juice = get_data('juice')
from pycaret.classification import *
exp_name = setup(data = juice, target = 'Purchase')
lr = create_model('lr')
create_app(lr)
最后,可以轻松地为模型创建 API 和 Docker 文件:
from pycaret.datasets import get_data
juice = get_data('juice')
from pycaret.classification import *
exp_name = setup(data = juice, target = 'Purchase')
lr = create_model('lr')
create_api(lr, 'lr_api')
create_docker('lr_api')
没有比这更容易的了,对吧?
PyCaret是一个非常完整的库,在这里很难涵盖所有内容,建议你现在下载并开始使用它来了解一些 其在实践中的能力。
5、floWeaver
FloWeaver 可以从流数据集中生成桑基图。如果你不知道什么是桑基图,这里有一个例子: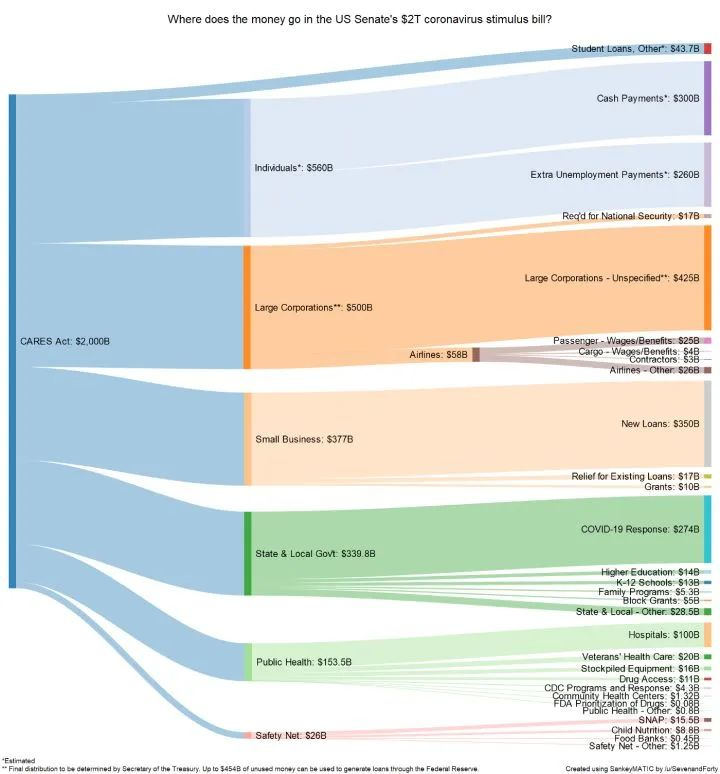
在显示转化漏斗、营销旅程或预算分配的数据时,它们非常有用(上例)。入口数据应采用以下格式:“源 x 目标 x 值”,只需一行代码即可创建此类图(非常具体,但也非常直观)。
6、Gradio
如果你阅读过敏捷数据科学,就会知道拥有一个让最终用户从项目开始就与数据进行交互的前端界面是多么有帮助。一般情况下在Python中最常用是 Flask,但它对初学者不太友好,它需要多个文件和一些 html、css 等知识。
Gradio 允许您通过设置输入类型(文本、复选框等)、功能和输出来创建简单的界面。尽管它似乎不如 Flask 可定制,但它更直观。
由于 Gradio 现在已经加入 Huggingface,可以在互联网上永久托管 Gradio 模型,而且是免费的!
7、Terality
理解 Terality 的最佳方式是将其视为“Pandas ,但速度更快”。这并不意味着完全替换 pandas 并且必须重新学习如何使用df:Terality 与 Pandas 具有完全相同的语法。实际上,他们甚至建议“import Terality as pd”,并继续按照以前的习惯的方式进行编码。它快多少?他们的网站有时会说它快 30 倍,有时快 10 到 100 倍。
另一个重要是 Terality 允许并行化并且它不在本地运行,这意味着您的 8GB RAM 笔记本电脑将不会再出现 MemoryErrors!
但它在背后是如何运作的呢?理解 Terality 的一个很好的比喻是可以认为他们在本地使用的 Pandas 兼容的语法并编译成 Spark 的计算操作,使用Spark进行后端的计算。所以计算不是在本地运行,而是将计算任务提交到了他们的平台上。
那有什么问题呢?每月最多只能免费处理 1TB 的数据。如果需要更多则必须每月至少支付 49 美元。1TB/月对于测试工具和个人项目可能绰绰有余,但如果你需要它来实际公司使用,肯定是要付费的。
8、Torch-Handle
如果你是Pytorch的使用者,可以试试这个库。
torchhandle是一个PyTorch的辅助框架。它将PyTorch繁琐和重复的训练代码抽象出来,使得数据科学家们能够将精力放在数据处理、创建模型和参数优化,而不是编写重复的训练循环代码。使用torchhandle,可以让你的代码更加简洁易读,让你的开发任务更加高效。
torchhandle将Pytorch的训练和推理过程进行了抽象整理和提取,只要使用几行代码就可以实现PyTorch的深度学习管道。并可以生成完整训练报告,还可以集成tensorboard进行可视化。
from collections import OrderedDict
import torch
from torchhandle.workflow import BaseConpython class Net(torch.nn.Module): def __init__(self, ): super().__init__() self.layer = torch.nn.Sequential(OrderedDict([ ('l1', torch.nn.Linear(10, 20)), ('a1', torch.nn.ReLU()), ('l2', torch.nn.Linear(20, 10)), ('a2', torch.nn.ReLU()), ('l3', torch.nn.Linear(10, 1)) ])) def forward(self, x): x = self.layer(x) return x num_samples, num_features = int(1e4), int(1e1)
X, Y = torch.rand(num_samples, num_features), torch.rand(num_samples)
dataset = torch.utils.data.TensorDataset(X, Y)
trn_loader = torch.utils.data.DataLoader(dataset, batch_size=64, num_workers=0, shuffle=True)
loaders = {"train": trn_loader, "valid": trn_loader}
device = 'cuda' if torch.cuda.is_available() else 'cpu' model = {"fn": Net}
criterion = {"fn": torch.nn.MSELoss}
optimizer = {"fn": torch.optim.Adam, "args": {"lr": 0.1}, "params": {"layer.l1.weight": {"lr": 0.01}, "layer.l1.bias": {"lr": 0.02}} }
scheduler = {"fn": torch.optim.lr_scheduler.StepLR, "args": {"step_size": 2, "gamma": 0.9} } c = BaseConpython(model=model, criterion=criterion, optimizer=optimizer, scheduler=scheduler, conpython_tag="ex01")
train = c.make_train_session(device, dataloader=loaders)
train.train(epochs=10)
定义一个模型,设置数据集,配置优化器、损失函数就可以自动训练了,是不是和TF差不多了。
相关文章:
8个明显可以提升数据处理效率的 Python 神库
在进行数据科学时,可能会浪费大量时间编码并等待计算机运行某些东西。所以我选择了一些 Python 库,可以帮助你节省宝贵的时间 文章目录1、Optuna技术提升2、ITMO\_FS3、Shap-hypetune4、PyCaret5、floWeaver6、Gradio7、Terality8、Torch-Handle1、Optun…...

互联网公司吐槽养不起程序员,IT岗位的工资真是虚高有泡沫了?
说实话,看到这个话题的时候又被震惊到。 因为相比以往,程序员工资近年来已经够被压缩的了好嘛? 那些鼓吹泡沫论的,真就“何不食肉糜”了~~~ 而且这种逻辑就很奇怪, 程序员的薪资难道不是由行业水平决定么ÿ…...
Excel 进阶|只会 Excel 也能轻松搭建指标应用啦
现在,Kyligence Zen 用户可在 Excel 中对指标进行更进一步的探索和分析,能够实现对维度进行标签筛选、对维度基于指标值进行筛选和排序、下钻/上卷、多样化的透视表布局、本地 Excel 和云端 Excel 的双向支持等。业务人员和分析师基于现有分析习惯就可以…...
RabbitMQ中TTL
目录一、TTL1.控制后台演示消息过期2.代码实现2.1 队列统一过期2.2 消息过期一、TTL TTL 全称 Time To Live(存活时间/过期时间)。 当消息到达存活时间后,还没有被消费,会被自动清除。 RabbitMQ可以对消息设置过期时间࿰…...
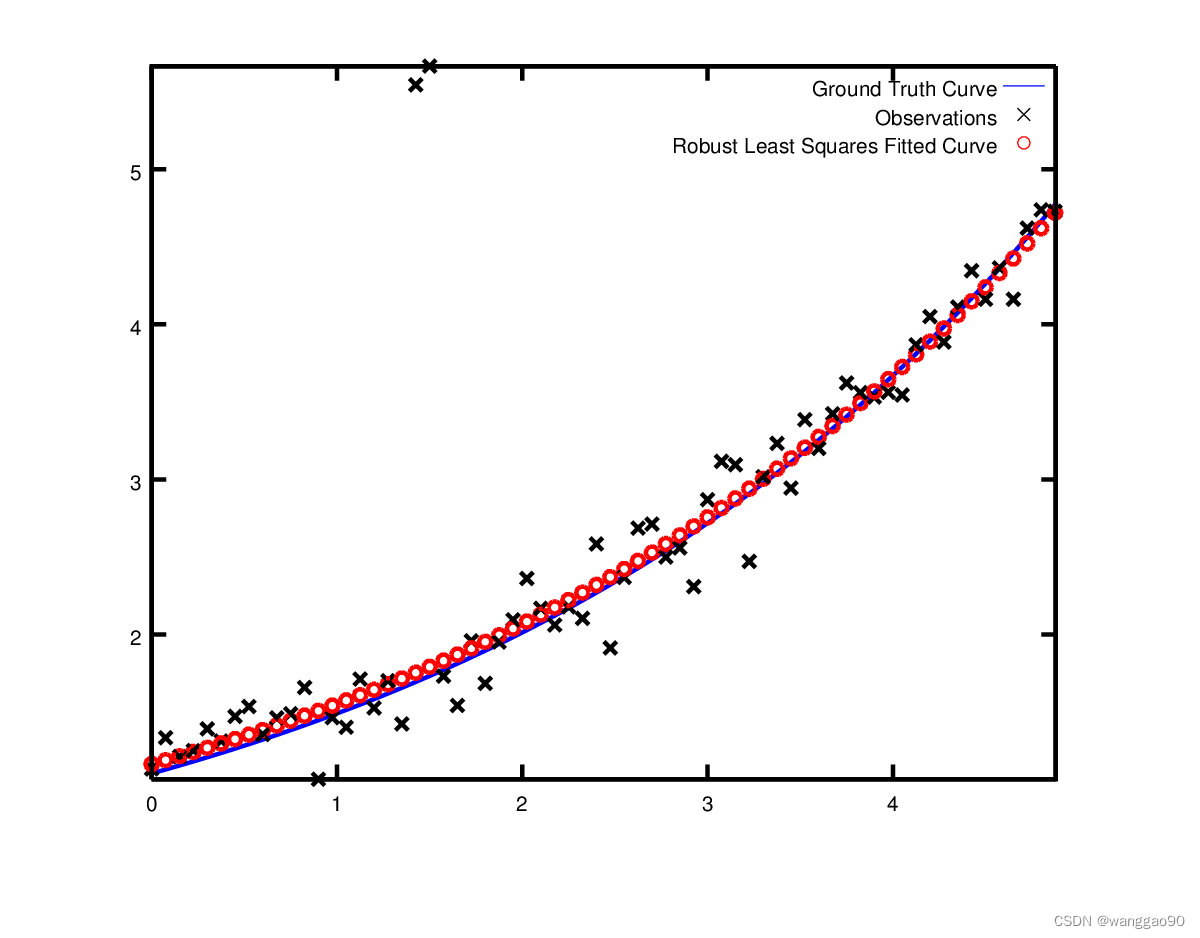
Ceres简介及示例(4)Curve Fitting(曲线拟合)
文章目录1、Curve Fitting1.1、残差定义1.2、 Problem问题构造1.3、完整代码1.4、运行结果2、Robust Curve Fitting1、Curve Fitting 到目前为止,我们看到的示例都是没有数据的简单优化问题。最小二乘和非线性最小二乘分析的原始目的是对数据进行曲线拟合。 以一个…...

音质最好的骨传导蓝牙耳机有哪些,推荐几款不错的骨传导耳机
骨传导耳机也称为“不入耳式”耳机,是一种通过颅骨、骨迷路、内耳淋巴液和听神经之间的信号传导,来达到听力保护目的的一种技术。由于它可以开放双耳,所以在跑步、骑行等运动时使用十分安全,可以避免外界的干扰。这种耳机在佩戴…...

计算机操作系统安全
操作系统安全是计算机系统安全的重要组成部分,目的是保护操作系统的机密性、完整性和可用性。在当前的网络环境下,操作系统面临着许多威胁,如病毒、木马、蠕虫、黑客攻击等等。为了保护操作系统的安全,需要采取各种措施来防范这些…...
超详细从入门到精通,pytest自动化测试框架实战教程-用例标记/执行(三)
目录:导读前言一、Python编程入门到精通二、接口自动化项目实战三、Web自动化项目实战四、App自动化项目实战五、一线大厂简历六、测试开发DevOps体系七、常用自动化测试工具八、JMeter性能测试九、总结(尾部小惊喜)前言 pytest可以通过标记…...

Java SE 基础(5) Java 环境的搭建
Java 虚拟机——JVM JVM (Java Virtual Machine ):Java虚拟机,简称JVM,是运行所有Java程序的假想计算机,是Java程序的运行环境,是Java 最具吸引力的特性之一。我们编写的Java代码,都…...

银行数字化转型导师坚鹏:银行对公客户数字化场景营销案例萃取
银行对公客户数字化场景营销案例萃取与行动落地课程背景: 很多银行存在以下问题:不清楚银行数字化营销与场景营销内涵?不知道如何开展对公客户数字化营销工作?不知道对公业务数字化场景营销成功案例? 学员收获&a…...

get和post的区别
1.用途上 get请求用来向服务器获取资源; post请求用来向服务器提交数据; 2.表单提交方式上 get请求直接将表单数据拼接到URL上,多个参数之间通过&符号连接; post请求将表单数据放到请求头或者请求体中; 3.传…...

Java调用Oracle存储过程
文章目录 Java调用Oracle存储过程Java调用Oracle存储过程 使用Java实现存储过程的步骤: 1、数据表、存储过程【已完成】 2、引入依赖包、数据源配置 3、Java实现【已完成】 – Oracle 创建数据表 CREATE TABLE STUDENT ( ID NUMBER (20) NOT NULL ENABLE PRIMARY KEY, NAME V…...

ubuntu如何设置qt环境变量
Qt 是一个1991年由Qt Company开发的跨平台C图形用户界面应用程序开发框架。它既可以开发GUI程序,也可用于开发非GUI程序,比如控制台工具和服务器。Qt是面向对象的框架,使用特殊的代码生成扩展(称为元对象编译器(Meta Object Compi…...

高管对谈|揭秘 NFT 技术背后的研发方法论
有人说,元宇宙是未来,NFT 则是通往这个可能的未来的数字通行证。 经过一度热炒之后,NFT 逐渐回归理性的「大浪淘沙」轨迹。NXTF_(廿四未来)正是一家将 NFT 向实体经济靠拢并与之结合的公司。 NXTF_利用区块链技术&am…...

是面试官放水,还是企业实在是缺人?这都没挂,字节原来这么容易进...
“字节是大企业,是不是很难进去啊?”“在字节做软件测试,能得到很好的发展吗?一进去就有9.5K,其实也没有想的那么难”直到现在,心情都还是无比激动! 本人211非科班,之前在字节和腾讯…...

JVM 本地方法栈
本地方法栈的作用 Java虚拟机栈于管理Java方法的调用,而本地方法栈用于管理本地方法的调用。本地方法栈,也是线程私有的。允许被实现成固定或者是可动态扩展的内存大小(在内存溢出方面和虚拟机栈相同) 如果线程请求分配的栈容量超…...

GPT-4老板:AI可能会杀死人类,已经出现我们无法解释的推理能力
来源: 量子位 微信号:QbitAI “AI确实可能杀死人类。” 这话并非危言耸听,而是OpenAI CEO奥特曼的最新观点。 而这番观点,是奥特曼在与MIT研究科学家Lex Fridman长达2小时的对话中透露。 不仅如此,奥特曼谈及了近期围绕ChatGPT…...

弹性盒布局
系列文章目录 前端系列文章——传送门 CSS系列文章——传送门 文章目录系列文章目录弹性盒模型(FlexibleBox 或 flexbox)什么是弹性盒?基本配置项给父元素添加给子元素添加弹性盒案例滚动条青蛙网页练习旧的弹性盒display:box 属性浏览器的兼…...

第13章_事务基础知识
第13章_事务基础知识 🏠个人主页:shark-Gao 🧑个人简介:大家好,我是shark-Gao,一个想要与大家共同进步的男人😉😉 🎉目前状况:23届毕业生,目前…...

LeetCode笔记:Biweekly Contest 101
LeetCode笔记:Biweekly Contest 101 1. 题目一 1. 解题思路2. 代码实现 2. 题目二 1. 解题思路2. 代码实现 3. 题目三 1. 解题思路2. 代码实现 4. 题目四 1. 解题思路2. 代码实现 比赛链接:https://leetcode.com/contest/biweekly-contest-101/ 1. 题…...

如何高效构建视频数据集:video2frame终极实战指南
如何高效构建视频数据集:video2frame终极实战指南 【免费下载链接】video2frame Yet another easy-to-use tool to extract frames from videos, for deep learning and computer vision. 项目地址: https://gitcode.com/gh_mirrors/vi/video2frame 在计算机…...

从日志到环境变量:根治 Android Studio AVD 启动报错“The emulator process has terminated”
1. 从错误弹窗到日志分析:定位问题的第一步 当你兴冲冲地打开Android Studio准备启动AVD(Android Virtual Device)时,突然弹出一个冰冷的提示框:"The emulator process has terminated",这感觉就…...
Translumo:5分钟掌握Windows实时屏幕翻译终极指南
Translumo:5分钟掌握Windows实时屏幕翻译终极指南 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否在玩外…...

ViGEmBus终极指南:Windows游戏手柄模拟驱动的完整解决方案
ViGEmBus终极指南:Windows游戏手柄模拟驱动的完整解决方案 【免费下载链接】ViGEmBus Windows kernel-mode driver emulating well-known USB game controllers. 项目地址: https://gitcode.com/gh_mirrors/vi/ViGEmBus 你是否曾经遇到过这样的情况ÿ…...

开源机械爪控制库:从PID算法到ROS集成的全栈开发指南
1. 项目概述:一个开源的机械爪设计与控制库最近在机器人硬件开发的圈子里,开源项目“MeyerZhou/openclaw”引起了不少创客和机器人爱好者的注意。简单来说,这是一个专注于机械爪(或称机械手、夹爪)设计与控制的代码库和…...
)
STM8硬件IIC驱动BNO055传感器避坑指南(附完整代码)
STM8硬件IIC驱动BNO055传感器实战解析与优化 BNO055作为一款集成了9轴传感器融合算法的智能芯片,能够直接输出姿态角数据,极大简化了嵌入式系统中姿态解算的复杂度。然而在实际应用中,许多开发者发现使用STM32等常见MCU的模拟IIC接口难以稳定…...

Rulebook-AI:用规则引擎为AI智能体构建可控决策框架
1. 项目概述:一个基于规则的AI智能体框架最近在探索如何让AI智能体(Agent)的行为更可控、更符合业务逻辑时,我遇到了一个挺有意思的开源项目:botingw/rulebook-ai。乍一看这个名字,可能会觉得它又是一个试图…...
,现在必须掌握的3种替代渲染方案)
像素艺术家紧急预警:Midjourney即将关闭--tile参数兼容性(倒计时14天),现在必须掌握的3种替代渲染方案
更多请点击: https://intelliparadigm.com 第一章:像素艺术家紧急预警:Midjourney即将关闭--tile参数兼容性(倒计时14天) Midjourney v6.5 已正式宣布将于 14 天后终止对 --tile 参数的原生支持,此举将直…...

基于GitHub Pages与Jekyll的静态博客搭建与深度定制指南
1. 项目概述:一个静态博客的诞生与演进如果你对搭建个人博客感兴趣,或者正在寻找一个轻量、高效、完全可控的线上空间,那么“RyansGhost/RyansGhost.github.io”这个项目仓库,很可能就是你一直在寻找的答案。这不仅仅是一个托管在…...

OpenAgentsControl:构建多智能体协同系统的开源框架解析
1. 项目概述:一个面向智能体控制的开放框架最近在折腾AI智能体(Agent)相关的项目,发现一个挺有意思的开源仓库:darrenhinde/OpenAgentsControl。这个项目名字直译过来就是“开放智能体控制”,听起来就很有搞…...