【数据结构】第六站:栈和队列
目录
一、栈
1.栈的概念和结构
2.栈的实现方案
3.栈的具体实现
4.栈的完整代码
5.有效的括号
二、队列
1.队列的概念及结构
2.队列的实现方案
3.队列的实现
4.队列实现的完整代码
一、栈
1.栈的概念和结构
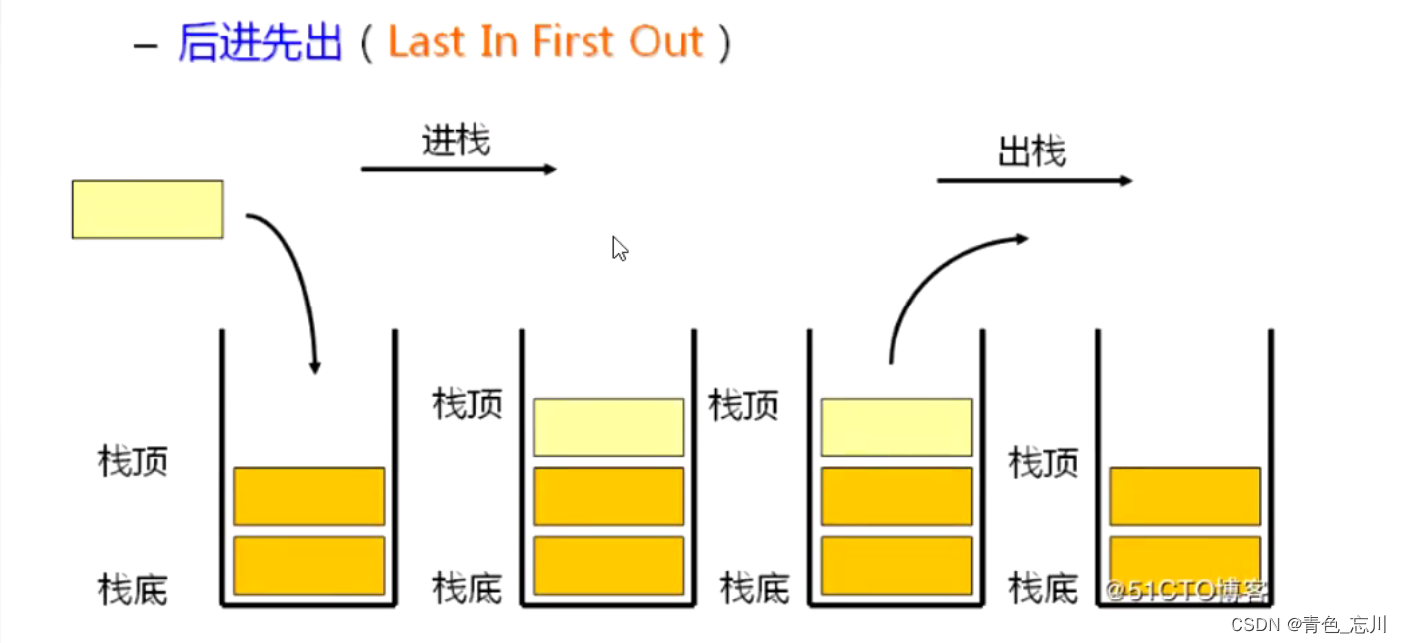
栈:一种特殊的线性表,其只允许在固定的一端进行插入和删除元素操作。进行数据插入和删除操作的一端称为栈顶,另一端称为栈底。栈中的数据元素遵守后进先出LIFO(Last In First Out)的原则
压栈:栈的插入操作叫做进栈/压栈/入栈,入数据在栈顶。
出栈:栈的删除操作叫做出栈。出数据也在栈顶。
2.栈的实现方案
对于这个栈,想必我们也不难想到他有两种实现的方案了,第一种方案是使用顺序表来实现,第二种方案是使用链表来实现
顺序表实现
如果采用顺序表来实现的话,由于只有在栈顶会出数据和入数据,所以栈顶就应该对应着数组的尾。
而这种方式,我们不难发现他是很优的,而且由于cpu的局部性原理,也是具有一定的优势的。因此我们发现栈是一种很适合使用顺序表实现的

链表来实现
如果采用链表来实现的话,我们可以选择使用单链表和带头双向循环链表。
如果我们使用单链表
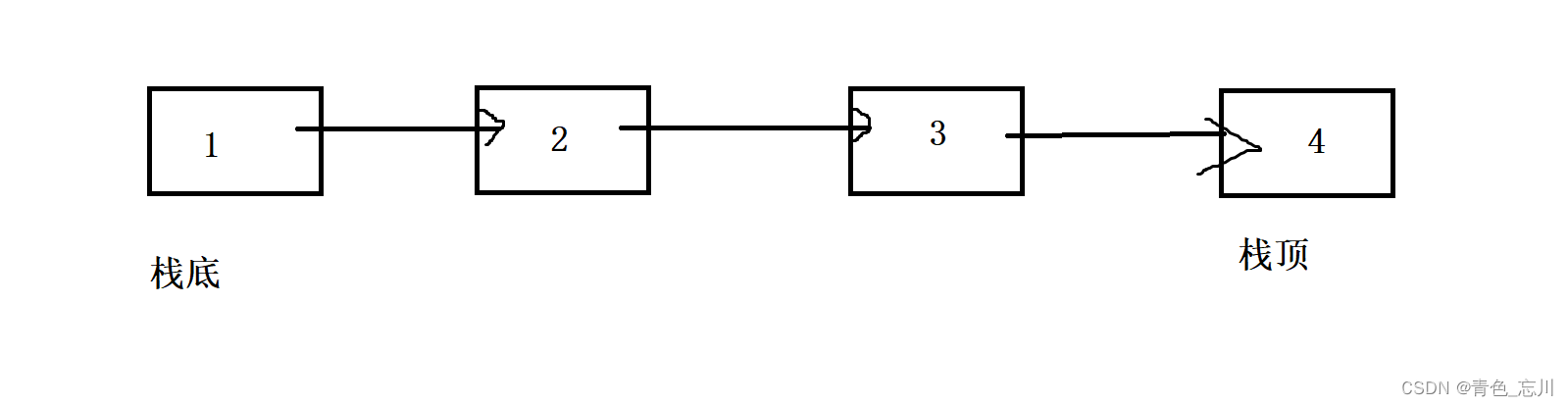
我们这里又可以细分为栈顶在链表头和在链表尾
如下图所示是栈顶在链表尾部,这样的话我们显然可以得知他的效率是很低的
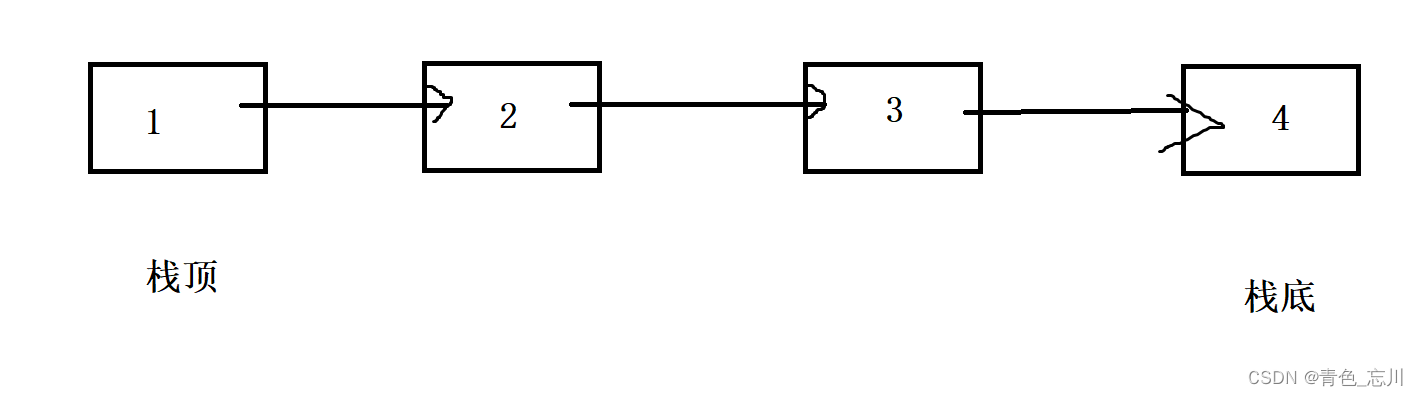
如果栈顶在链表头的话,这样就可以提升了效率,但是仍然没有顺序表更具有优势
而如果使用带头双向循环链表的话,确实也可以高效的实现栈,但是是没有顺序表具有优势的
3.栈的具体实现
栈的定义
根据上面的分析,我们决定采用顺序表来实现栈,使用顺序表又可以分为静态的和动态的。当然动态的性能是要优于静态的。我们使用动态顺序表
typedef int STDateType;typedef struct Stack {STDateType* a;int top;int capacity; }Stack;
栈的初始化
对于栈的初始化,与动态顺序表的初始化完全一样。初始为其分配四个数据的空间。然后让top和capacity分别置为0和4
//栈的初始化 void StackInit(Stack* ps) {assert(ps);ps->a = (STDateType*)malloc(sizeof(STDateType) * 4);if (ps->a == NULL){perror("malloc fail");return;}ps->top = 0;ps->capacity = 4; }
栈的销毁
由于这个栈的本质是一个顺序表,所以直接释放顺序表中指针所对应的那块空间即可
//栈的销毁 void StackDestroy(Stack* ps) {assert(ps);free(ps->a);ps->a = NULL;ps->top = 0;ps->capacity = 0; }
入栈
对于入栈,我们需要先检查容量,容量不够则扩容,然后直接尾插即可
//入栈 void StackPush(Stack* ps, STDateType x) {assert(ps);if (ps->top == ps->capacity){STDateType* tmp = (STDateType*)realloc(ps->a, ps->capacity * 2 * sizeof(STDateType));if (tmp == NULL){perror("realloc fail");return;}ps->a = tmp;ps->capacity *= 2;}ps->a[ps->top] = x;ps->top++; }
出栈
对于出栈,我们得先确定栈内元素不为空,然后我们直接让top--即可
//出栈 void StackPop(Stack* ps) {assert(ps);assert(!StackEmpty(ps));ps->top--; }
栈的个数
由于我们的top代表的就是栈的个数,所以直接返回即可
//栈的个数 int StackSize(Stack* ps) {assert(ps);return ps->top; }
栈是否为空
对于判断栈是否为空,我们直接根据top的值即可判断
//栈是否为空 bool StackEmpty(Stack* ps) {assert(ps);return ps->top == 0; }
取出栈顶的元素
我们先确定栈不为空,然后直接返回栈顶元素即可
//取出栈顶的数据 STDateType StackTop(Stack* ps) {assert(ps);assert(!StackEmpty(ps));return ps->a[ps->top - 1]; }
4.栈的完整代码
Stack.h
#pragma once #include<stdio.h> #include<malloc.h> #include<stdbool.h> #include<assert.h>typedef int STDateType;typedef struct Stack {STDateType* a;int top;int capacity; }Stack;//栈的初始化 void StackInit(Stack* ps); //栈的销毁 void StackDestroy(Stack* ps); //入栈 void StackPush(Stack* ps, STDateType x); //出栈 void StackPop(Stack* ps); //栈的个数 int StackSize(Stack* ps); //栈是否为空 bool StackEmpty(Stack* ps); //取出栈顶的数据 STDateType StackTop(Stack* ps);
Stack.c
#define _CRT_SECURE_NO_WARNINGS 1#include"Stack.h"//栈的初始化 void StackInit(Stack* ps) {assert(ps);ps->a = (STDateType*)malloc(sizeof(STDateType) * 4);if (ps->a == NULL){perror("malloc fail");return;}ps->top = 0;ps->capacity = 4; } //栈的销毁 void StackDestroy(Stack* ps) {assert(ps);free(ps->a);ps->a = NULL;ps->top = 0;ps->capacity = 0; } //入栈 void StackPush(Stack* ps, STDateType x) {assert(ps);if (ps->top == ps->capacity){STDateType* tmp = (STDateType*)realloc(ps->a, ps->capacity * 2 * sizeof(STDateType));if (tmp == NULL){perror("realloc fail");return;}ps->a = tmp;ps->capacity *= 2;}ps->a[ps->top] = x;ps->top++; } //出栈 void StackPop(Stack* ps) {assert(ps);assert(!StackEmpty(ps));ps->top--; } //栈的个数 int StackSize(Stack* ps) {assert(ps);return ps->top; } //栈是否为空 bool StackEmpty(Stack* ps) {assert(ps);return ps->top == 0; } //取出栈顶的数据 STDateType StackTop(Stack* ps) {assert(ps);assert(!StackEmpty(ps));return ps->a[ps->top - 1]; }
Test.c
#define _CRT_SECURE_NO_WARNINGS 1 #include"Stack.h" void TestStack1() {Stack s;StackInit(&s);StackPush(&s, 1);StackPush(&s, 2);StackPush(&s, 3);StackPush(&s, 4);StackPush(&s, 5);printf("%d\n", StackSize(&s));while (!StackEmpty(&s)){printf("%d ", StackTop(&s));StackPop(&s);}StackDestroy(&s); } int main() {TestStack1();return 0; }
5.有效的括号
题目链接:力扣
题目解析:对于这道题,最简单的方法就是使用一个栈来记录左括号,如果是左括号,则入栈,如果不是左括号,先取出栈顶的元素,并出栈。然后将栈顶元素与当前的字符进行比较。如果满足错误条件,则销毁栈后直接返回即可。
如果可以匹配,则直接让s++即可。最后当所有字符串遍历完成以后,然后根据栈是否为空,返回即可
typedef char STDateType;typedef struct Stack {STDateType* a;int top;int capacity; }Stack; //栈的初始化 void StackInit(Stack* ps) {assert(ps);ps->a = (STDateType*)malloc(sizeof(STDateType) * 4);if (ps->a == NULL){perror("malloc fail");return;}ps->top = 0;ps->capacity = 4; } //栈的销毁 void StackDestroy(Stack* ps) {assert(ps);free(ps->a);ps->a = NULL;ps->top = 0;ps->capacity = 0; } //入栈 void StackPush(Stack* ps, STDateType x) {assert(ps);if (ps->top == ps->capacity){STDateType* tmp = (STDateType*)realloc(ps->a, ps->capacity * 2 * sizeof(STDateType));if (tmp == NULL){perror("realloc fail");return;}ps->a = tmp;ps->capacity *= 2;}ps->a[ps->top] = x;ps->top++; } //栈是否为空 bool StackEmpty(Stack* ps) {assert(ps);return ps->top == 0; } //出栈 void StackPop(Stack* ps) {assert(ps);assert(!StackEmpty(ps));ps->top--; } //栈的个数 int StackSize(Stack* ps) {assert(ps);return ps->top; }//取出栈顶的数据 STDateType StackTop(Stack* ps) {assert(ps);assert(!StackEmpty(ps));return ps->a[ps->top - 1]; } bool isValid(char * s){Stack st;StackInit(&st);while(*s!='\0'){if( (*s=='(')||(*s=='[')||(*s=='{')){StackPush(&st,*s);}else{if(StackEmpty(&st)){StackDestroy(&st);return false;}char p=StackTop(&st);StackPop(&st);if( ((*s!=')')&&(p=='('))|| ((*s!=']')&&(p=='['))||((*s!='}')&&(p=='{'))){StackDestroy(&st);return false;}}s++;}bool ret =StackEmpty(&st);StackDestroy(&st);return ret; }
二、队列
1.队列的概念及结构
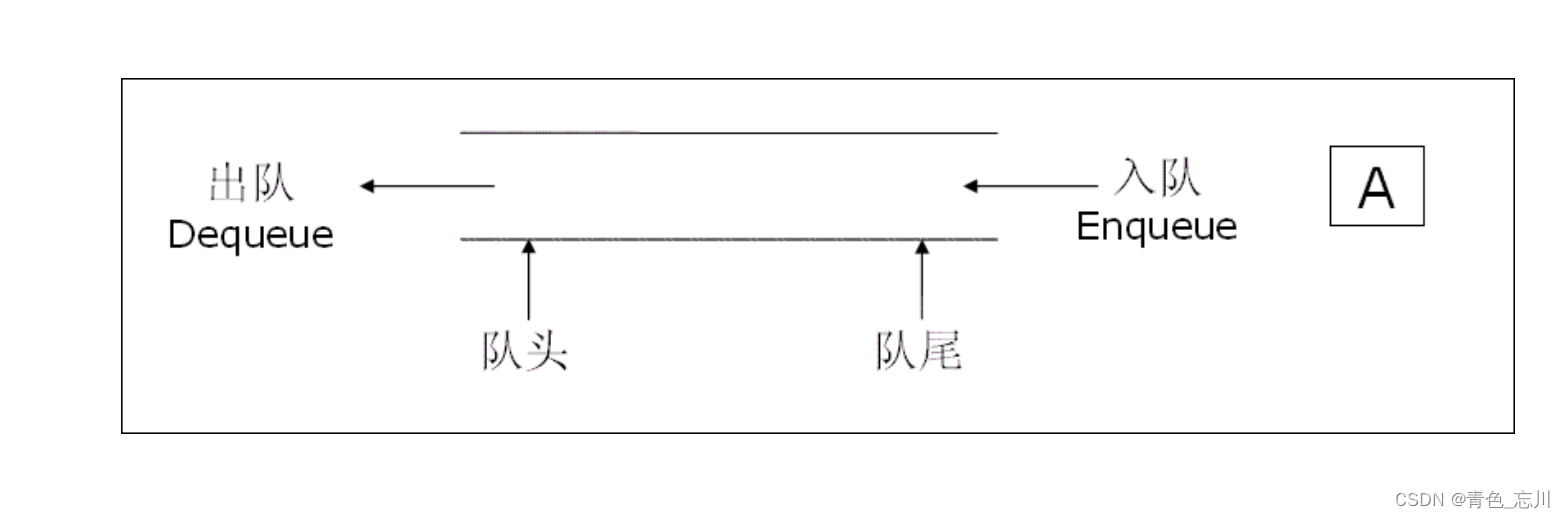
队列:只允许在一端进行插入数据操作,在另一端进行删除数据操作的特殊线性表,队列具有先进先出FIFO(First In First Out)入队列:进行插入操作的一端称为队尾出队列:进行删除操作的一端称为队头
2.队列的实现方案
对于队列的实现,我们仍然又两种方法可以选择,一种是链表形式,一种是顺序表形式
如果采用顺序表来实现的话,我们会发现头删操作时间复杂度较高。
如果采用链表来实现的话,我们发现找尾部结点的时间复杂度较高,但是我们可以多定义一个结点来随时知道尾部结点的地址。这样就可以优化掉找尾的时间复杂度。而且对于计算队列长度的话,我们也可以多定义一个变量size,我们在删除和插入数据的时候调整好size的大小。就可以优化掉计算队列长度的时间复杂度
这里我们也产生一个新的问题,对于单链表,能否多定义一个指针来控制尾部的地址,从而优化找尾的时间复杂度。
其实是不行的,对于尾插显然可以优化,但是对于尾删就不可以了。因为他需要找前一个结点的地址。
对于单链表我们也可以使用一个变量size,用来优化计算单链表长度的时间复杂度
综上所述,我们发现采用链表的结构是最优的。这个链表有一些不同的是,我们需要使用头尾两个指针以及一个size变量来进行优化,既然如此,那么我们就最好使用一个结构体来连接这些变量。否则传参的时候我们需要传三个以上的变量。
typedef int QDateType;typedef struct QNode {QDateType data;struct QNode* next; }QNode;typedef struct Queue {QNode* head;QNode* tail;int size; }Queue;
3.队列的实现
1.初始化队列
//初始化队列 void QueueInit(Queue* q) {assert(q);q->head = NULL;q->tail = NULL;q->size = 0; }如上代码所示,我们直接传结构体的地址就可以了。
2.队尾入数据
//申请一个结点 QNode* BuyQNode(QDateType x) {QNode* newnode = (QNode*)malloc(sizeof(QNode));if (newnode == NULL){perror("malloc fail");return NULL;}newnode->next = NULL;newnode->data = x;return newnode; } //队尾入队列 void QueuePush(Queue* q, QDateType x) {assert(q);QNode* newnode = BuyQNode(x);if (q->tail == NULL){q->head = q->tail = newnode;}else{q->tail->next = newnode;q->tail = q->tail->next;}q->size++; }队尾入数据的话,与单链表的入数据思路是一致的,我们先申请一个结点,然后判断这个链表是否为空,如果为空,则特殊处理,否则正常尾插即可
3.队头出数据
//队头出队列 void QueuePop(Queue* q) {assert(q);assert(q->head);QNode* first = q->head->next;free(q->head);q->head = first;q->size--;if (q->head == NULL){q->tail = NULL;} }对于出数据,与单链表是一样的,但是我们需要特别注意尾指针,如果删了队列最后一个结点后队列为空,那么需要将尾结点置为空
4.获取头部尾部数据
//获取队列头部元素 QDateType QueueFront(Queue* q) {assert(q);assert(q->head);return q->head->data; } //获取队列尾部元素 QDateType QueueBack(Queue* q) {assert(q);assert(q->head);return q->tail->data; }对于这两个函数,基本思路是一样的,我们先判断链表不为空,然后直接返回数据即可
5.获取队列中的有效元素的个数
//获取队列中的有效元素个数 int QueueSize(Queue* q) {assert(q);return q->size; }对于这段代码,我们直接返回size即可
6.检测队列是否为空
//检测队列是否为空 bool QueueEmpty(Queue* q) {assert(q);return q->head == NULL; }这段代码也很简单,直接返回这个判断条件即可
7.销毁队列
//销毁队列 void QueueDestroy(Queue* q) {assert(q);QNode* cur = q->head;while (cur){QNode* next = cur->next;free(cur);cur = next;}q->head = q->tail = NULL;q->size = 0; }销毁队列的方法与单链表的销毁是一样的,我们需要注意的是,别忘记置空head和tail以及size。
4.队列实现的完整代码
Queue.h
#pragma once #include<stdio.h> #include<stdlib.h> #include<malloc.h> #include<stdbool.h> #include<assert.h>typedef int QDateType;typedef struct QNode {QDateType data;struct QNode* next; }QNode;typedef struct Queue {QNode* head;QNode* tail;int size; }Queue;//初始化队列 void QueueInit(Queue* q); //队尾入队列 void QueuePush(Queue* q, QDateType x); //队头出队列 void QueuePop(Queue* q); //获取队列头部元素 QDateType QueueFront(Queue* q); //获取队列尾部元素 QDateType QueueBack(Queue* q); //获取队列中的有效元素个数 int QueueSize(Queue* q); //检测队列是否为空 bool QueueEmpty(Queue* q); //销毁队列 void QueueDestroy(Queue* q);
Queue.c
#define _CRT_SECURE_NO_WARNINGS 1 #include"Queue.h"//初始化队列 void QueueInit(Queue* q) {assert(q);q->head = NULL;q->tail = NULL;q->size = 0; } //申请一个结点 QNode* BuyQNode(QDateType x) {QNode* newnode = (QNode*)malloc(sizeof(QNode));if (newnode == NULL){perror("malloc fail");return NULL;}newnode->next = NULL;newnode->data = x;return newnode; } //队尾入队列 void QueuePush(Queue* q, QDateType x) {assert(q);QNode* newnode = BuyQNode(x);if (q->tail == NULL){q->head = q->tail = newnode;}else{q->tail->next = newnode;q->tail = q->tail->next;}q->size++; } //队头出队列 void QueuePop(Queue* q) {assert(q);assert(q->head);QNode* first = q->head->next;free(q->head);q->head = first;q->size--;if (q->head == NULL){q->tail = NULL;} } //获取队列头部元素 QDateType QueueFront(Queue* q) {assert(q);assert(q->head);return q->head->data; } //获取队列尾部元素 QDateType QueueBack(Queue* q) {assert(q);assert(q->head);return q->tail->data; } //获取队列中的有效元素个数 int QueueSize(Queue* q) {assert(q);return q->size; } //检测队列是否为空 bool QueueEmpty(Queue* q) {assert(q);return q->head == NULL; } //销毁队列 void QueueDestroy(Queue* q) {assert(q);QNode* cur = q->head;while (cur){QNode* next = cur->next;free(cur);cur = next;}q->head = q->tail = NULL;q->size = 0; }
Test.c
#define _CRT_SECURE_NO_WARNINGS 1 #include"Queue.h"void TestQueue1() {Queue pq;QueueInit(&pq);QueuePush(&pq, 1);QueuePush(&pq, 2);QueuePush(&pq, 3);QueuePush(&pq, 4);QueuePush(&pq, 5);printf("%d \n", QueueSize(&pq));while (!QueueEmpty(&pq)){printf("%d ", QueueFront(&pq));QueuePop(&pq);}QueueDestroy(&pq); } int main() {TestQueue1();return 0; }
本期内容就到这里了
如果对你有帮助的话,不要忘记点赞加收藏哦!!!
相关文章:
【数据结构】第六站:栈和队列
目录 一、栈 1.栈的概念和结构 2.栈的实现方案 3.栈的具体实现 4.栈的完整代码 5.有效的括号 二、队列 1.队列的概念及结构 2.队列的实现方案 3.队列的实现 4.队列实现的完整代码 一、栈 1.栈的概念和结构 栈:一种特殊的线性表,其只允许在固定…...
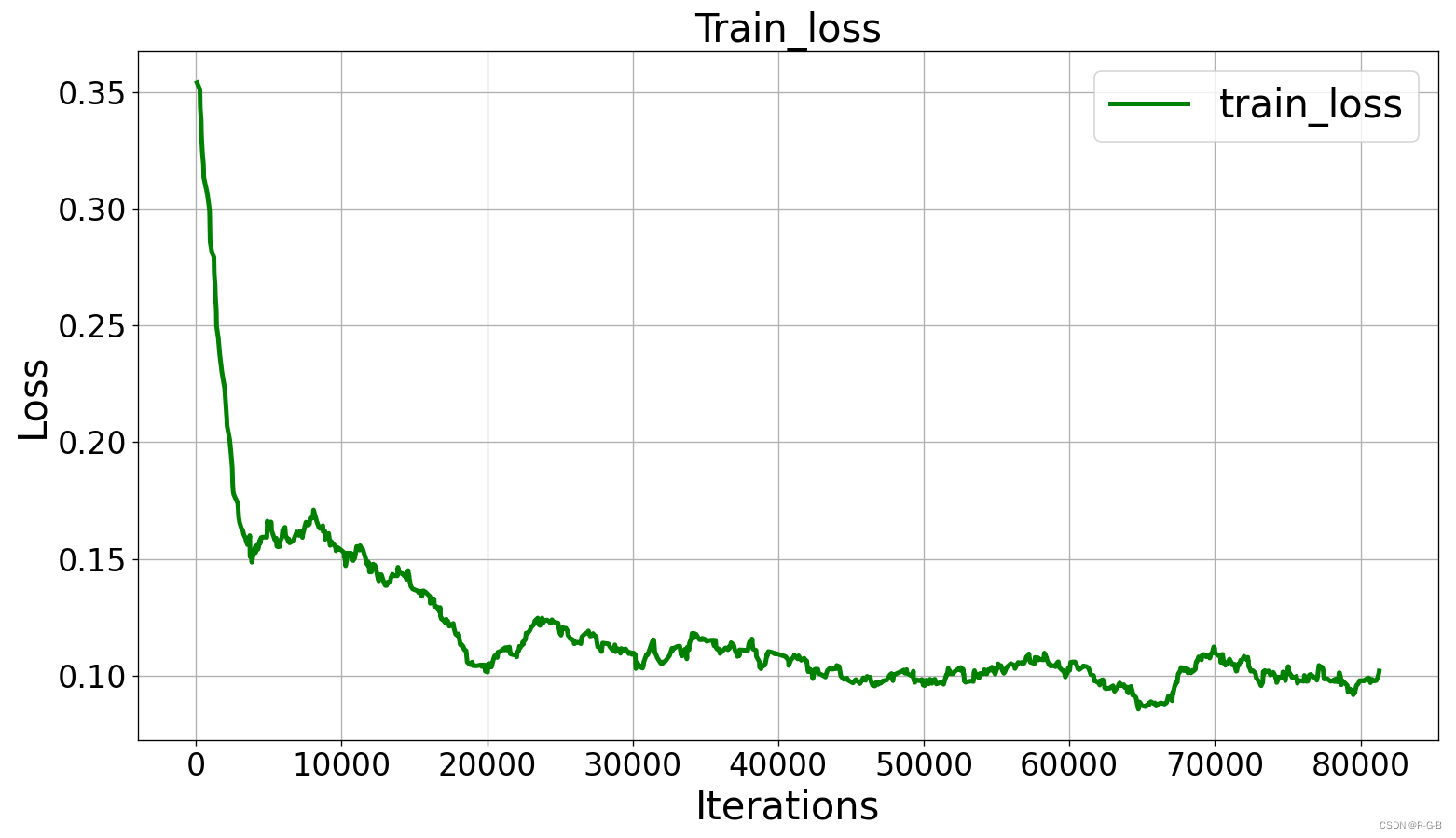
python matplotlib 绘制训练曲线 综合示例——平滑处理、图题设置、图例设置、字体大小、线条样式、颜色设置
文章目录1 导出曲线数据2 python简单的 绘制曲线3 Savitzky-Golay 滤波器--平滑曲线4 对y轴数值缩放处理5 设置图题、图例、字体、网格、保存曲线图6 补充6.1 python 曲线平滑处理——方法总结-详解6.2 Tensorboard可视化训练曲线导出数据用Python绘制6.3 PyTorch可视化工具-Te…...

vue-element-plus-admin整合后端实战——实现系统登录、缓存用户数据、实现动态路由
目标 整合vue-element-plus-admin前端框架,作为开发平台的前端。 准备工作 前端选用vue-element-plus-admin,地址 https://gitee.com/kailong110120130/vue-element-plus-admin。 首先clone项目,然后整合到开发平台中去。这是一个独立的前…...
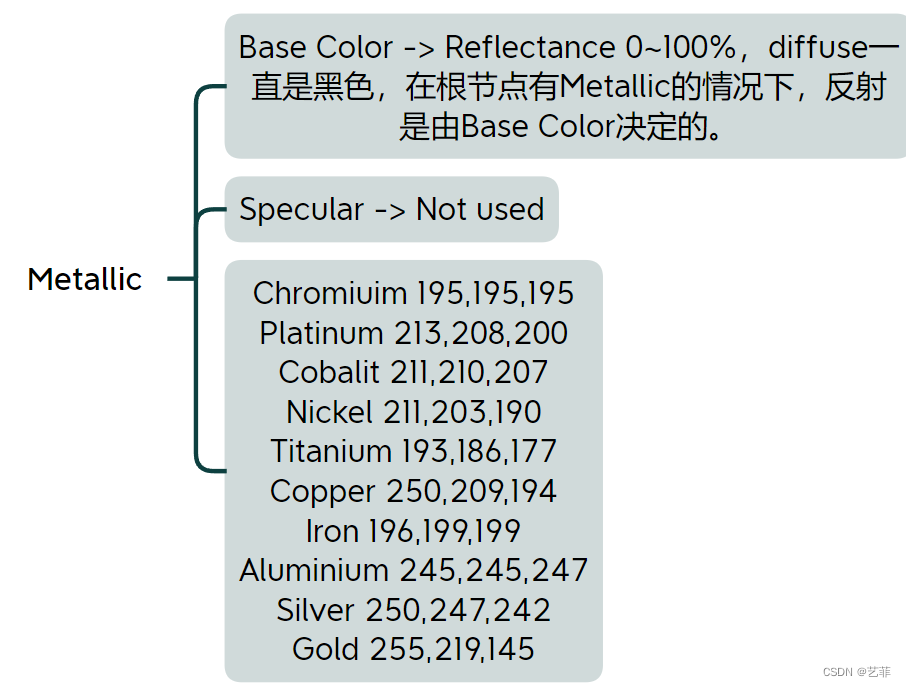
Shader Graph2-PBR介绍之表面属性(图解)
PBR的实现由光线和表面属性决定,下面我们介绍一下表面属性。这个5个属性在ShaderGraph的根节点是经常的看到,左侧是Unity中的,右侧是UE中的。 在没有Metallic金属的情况下,基础颜色值就决定了颜色的漫反射值,也就是说基…...
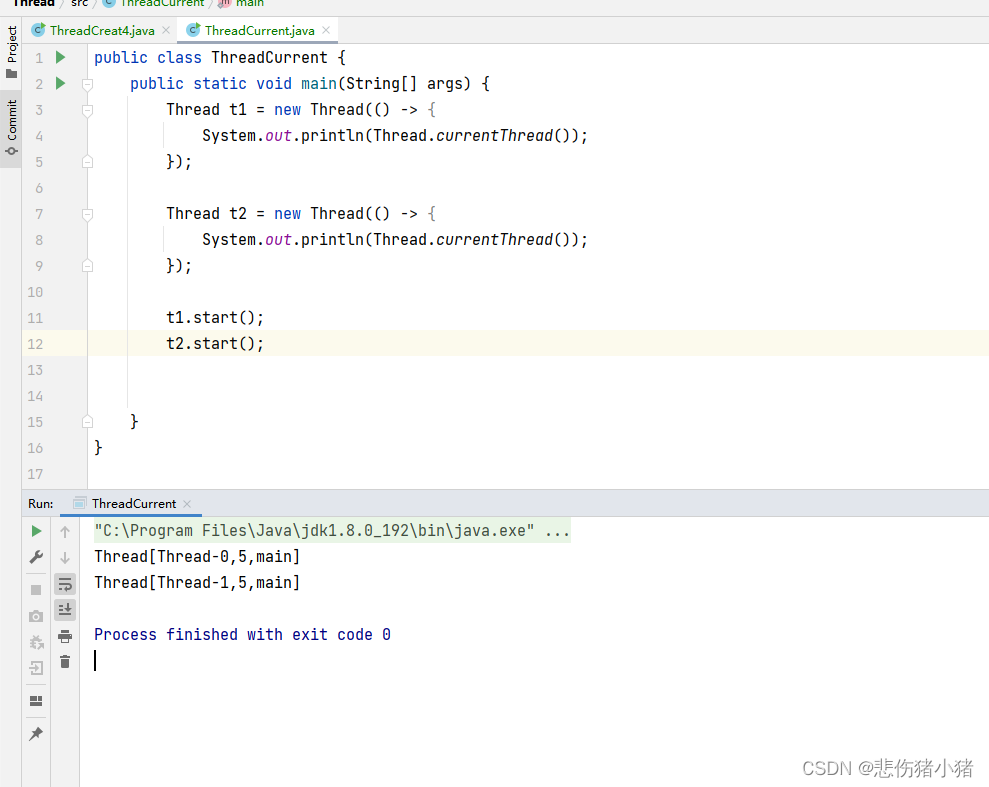
Java多线程编程,Thread类的基本用法讲解
文章目录如何创建一个线程start 与 run线程休眠线程中断线程等待获取线程实例如何创建一个线程 之前我们介绍了什么是进程与线程,那么我们如何使用代码去创建一个线程呢?线程操作是操作系统中的概念,操作系统内核实现了线程这样的机制&#…...
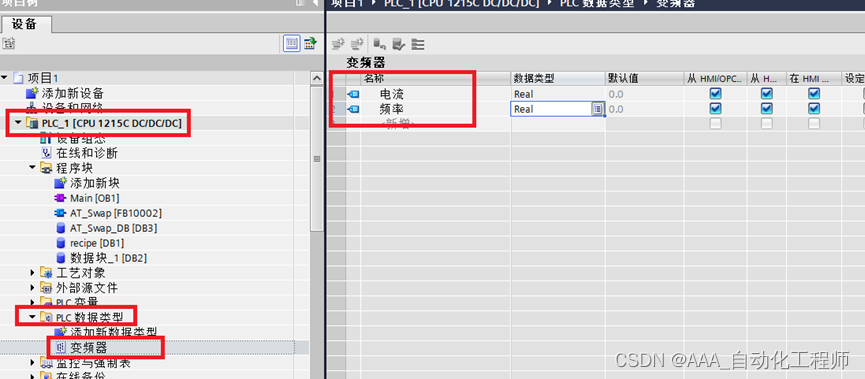
TIA博途Wincc_多路复用变量的使用方法示例(实现多台相同设备参数的画面精简)
TIA博途Wincc_多路复用变量的使用方法示例(实现多台相同设备参数的画面精简) 使用多路复用变量的好处: 当项目中存在多个相同的设备(例如:变频器、电机等),对这些设备在HMI上进行监控或修改参数时,不再需要逐个建立画面或IO域等,只需通过单个画面或IO域组合即可实现对…...

关于console你不知道的那些事
看到标题,大家会不会想,我都在前端岗位叱咤风云这么多年了, console 这个玩意用你讲 但是, 今天我将带你看到不一样的 console, 可以带来更多的帮助 了解 console 什么是 console ? console 其实是 JavaScript 内的一个原生对象。内部存储的方法大部…...
Java设计模式-责任链模式
1 概述 在现实生活中,常常会出现这样的事例:一个请求有多个对象可以处理,但每个对象的处理条件或权限不同。例如,公司员工请假,可批假的领导有部门负责人、副总经理、总经理等,但每个领导能批准的天数不同…...
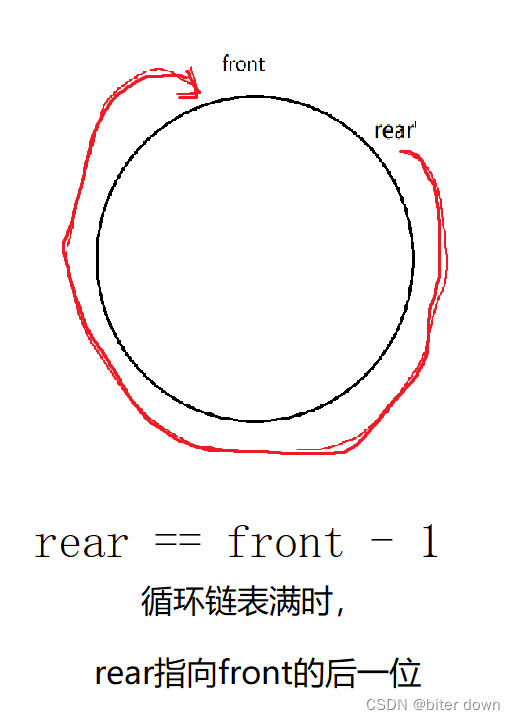
顺序表设计循环队列
使用顺序表来设计队列的最大优势是顺序表有可以定位元素的下标。 并且可以以Mod来使数组下标循环 #include<stdio.h> #include<stdlib.h> #include<assert.h> #include<stdbool.h> typedef int CQDataType; typedef struct { int* array; in…...
 - 设置默认启动项为UEFI Shell)
UEFI 基础教程 (十四) - 设置默认启动项为UEFI Shell
一 编写源代码 OvmfPkg/Library/PlatformBootManagerLib/BdsPlatform.c UINTN BootOptionPriority ( CONST EFI_BOOT_MANAGER_LOAD_OPTION *BootOption ) { DEBUG ((EFI_D_ERROR," [CSDN] BootOptionPriority %S .\n", BootOption->Description)); if (StrCmp (…...
python编程:判断一个数是否是超级素数
请定义一个函数,实现判断一个数是否是超级素数,并输出判断的结果。 一、编程题目 我们都知道,素数是除了1之外只能被自身整数的数,1除外。如果一个素数,去除一位、两位或多位后依然是素数,则我们称该素数为超级素数。…...

雷迪RD8200管线探测仪参数/管线仪使用方法/管线仪说明书
预防损坏和工作效率是我们客户面临的最大挑战 全新的 RD8200可以解决这些问题。这是我们功能优秀的精密管线仪系列,设计时充分考虑了操作员的需要。 预防损坏的专业选择 速度、准确性和可靠的性能 易于设置和使用 阳光下可读的显示屏、高性能的音频系统和用于嘈杂…...

会话共享保存到redis
1. 安装redis服务 [rootdb01 ~]# yum -y install redis 2. 配置redis服务 修改配置文件可以让其他服务器远程连接 127.0.0.1:6379 # 默认只能本地连接 [rootdb01 ~]# vim /etc/redis.conf [rootdb01 ~]# grep 172.16.1.51 /etc/redis.conf bind 127.…...
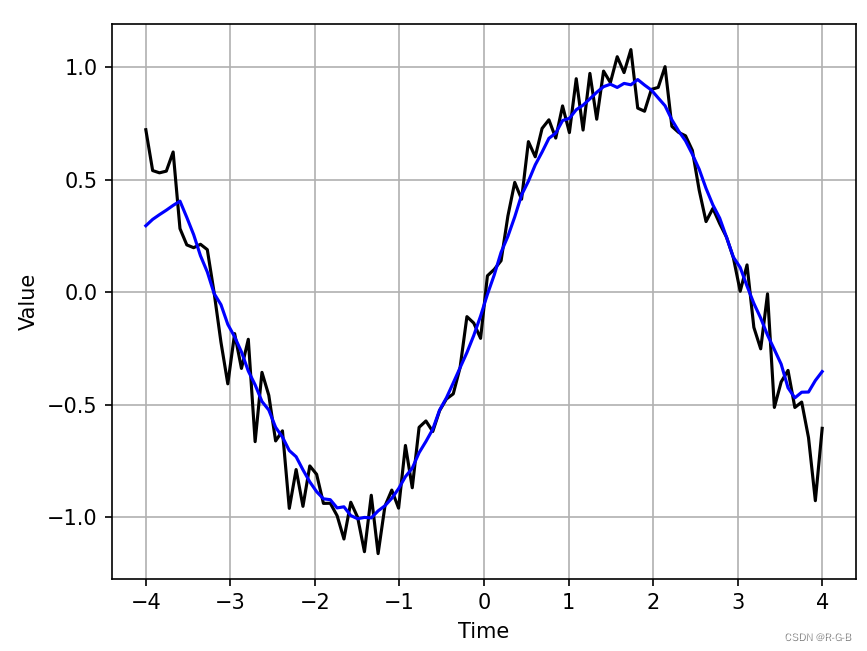
python 曲线平滑处理——方法总结(Savitzky-Golay 滤波器、make_interp_spline插值法和convolve滑动平均滤波)
文章目录1 插值法对曲线平滑处理1.1 插值法的常见实现方法1.2 拟合和插值的区别1.3 代码实例2 Savitzky-Golay 滤波器实现曲线平滑2.1 问题描述2.2 Savitzky-Golay 滤波器--调用讲解2.3 Savitzky-Golay 曲线平滑处理 示例2.4 Savitzky-Golay原理剖析3 基于Numpy.convolve实现滑…...

小驰私房菜_10_camx Otp Dump
#小驰私房菜# #camx# #Otp Dump# 本篇文章分下面几点展开: 1、otp dump的目的? 2、如何打开otp dump开关? 3、otp guide手册如何查看? 4、如何初步确认dump 出来的数据是否正确? 一、otp dump的目的 关于otp的一些概念,这里就不做过多的介绍了,不了解的同学,可以先去…...

priority_queue(堆)干货归纳+用法示例
10.priority_queue一.priority_queue(堆Heap)简介1.堆的特点:2.使用场景:二.成员函数1.构造函数:priority_queue构造函数方式:2.push()函数:向priority_queue中插入一个元素:3.pop()…...

miniprogram-to-uniapp使用指南(各种小程序项目转换为uni-app项目)
小程序分类:uni-app qq小程序 支付宝小程序 百度小程序 钉钉小程序 微信小程序 小程序转成uni_app 小程序转为uni_app 小程序转uni_app 小程序转换 工具现在支持npm全局库、HBuilderX插件两种方式使用,任君选择,HBuilderX插件地址:…...

BZOJ2720: [Violet 5]列队春游 【概率与期望】
题意自行理解,先讲一下概率和期望怎么算 概率 概率准确的定义自行百度,这里就不赘述了 概率的计算其实很简单,就是将符合条件的情况除以总共的情况 下面以掷骰子为例: 问题:将一个骰子掷出,666朝上的概率是多少 …...

脉诊之脉象——平脉,常见病脉,七绝脉
平脉与病脉诊脉纲领平人脉象常见病脉浮脉沉脉迟脉数脉虚脉实脉涩脉洪脉细脉滑脉弦脉紧脉长脉短脉弱脉芤脉结脉代脉七绝脉釜沸脉鱼翔脉虾游脉屋漏脉雀啄脉解索脉弹石脉预后诊脉纲领 脉跳动的力度:有力者,气足也。无力者,气不足也。 脉…...
第05章_存储引擎
第05章_存储引擎 🏠个人主页:shark-Gao 🧑个人简介:大家好,我是shark-Gao,一个想要与大家共同进步的男人😉😉 🎉目前状况:23届毕业生,目前在某…...

3分钟掌握:163MusicLyrics终极免费歌词解决方案全攻略
3分钟掌握:163MusicLyrics终极免费歌词解决方案全攻略 【免费下载链接】163MusicLyrics 云音乐歌词获取处理工具【网易云、QQ音乐】 项目地址: https://gitcode.com/GitHub_Trending/16/163MusicLyrics 想要快速获取网易云音乐和QQ音乐的歌词吗?1…...

JVM调优实战:让你的服务性能提升50%
一、背景 线上一个核心订单服务,QPS 3000左右,经常出现接口超时告警。监控显示: 平均RT: 180ms(要求<100ms)Full GC频率: 每天20次,每次STW 1.5sCPU使用率: 峰值85%服务规格: 8C16G,堆内存…...

5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南
5分钟快速上手:使用res-downloader实现视频号批量下载的终极指南 【免费下载链接】res-downloader 视频号、小程序、抖音、快手、小红书、直播流、m3u8、酷狗、QQ音乐等常见网络资源下载! 项目地址: https://gitcode.com/GitHub_Trending/re/res-downloader …...

Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南
Unlock Music Electron:3步解锁你的加密音乐文件,重获音乐自由终极指南 【免费下载链接】unlock-music-electron Unlock Music Project - Electron Edition 在Electron构建的桌面应用中解锁各种加密的音乐文件 项目地址: https://gitcode.com/gh_mirro…...

告别标题栏!在RK3568 Buildroot固件上,让你的Qt应用开机全屏显示的保姆级教程
RK3568嵌入式全屏实战:从Weston配置到Qt应用独占显示的完整指南 在嵌入式Linux系统开发中,GUI应用的全屏显示往往成为工程师面临的第一个"拦路虎"。当你在RK3568平台上精心开发的Qt应用启动后,却发现屏幕顶部顽固地挂着Weston窗口管…...
,现在必须掌握的3种替代渲染方案)
像素艺术家紧急预警:Midjourney即将关闭--tile参数兼容性(倒计时14天),现在必须掌握的3种替代渲染方案
更多请点击: https://intelliparadigm.com 第一章:像素艺术家紧急预警:Midjourney即将关闭--tile参数兼容性(倒计时14天) Midjourney v6.5 已正式宣布将于 14 天后终止对 --tile 参数的原生支持,此举将直…...

基于LLM与视觉模型融合的智能体框架:从原理到工业质检实践
1. 项目概述:当AI学会“看”与“想”最近在探索AI与视觉结合的落地场景时,我深度体验了landing-ai/vision-agent这个项目。它不是一个简单的图像识别工具,而是一个试图让AI具备“视觉推理”能力的智能体框架。简单来说,它让AI不仅…...

Navis:开源项目标准化开发环境与工具链配置框架实践
1. 项目概述:一个为开发者打造的“导航星图”如果你和我一样,常年混迹在开源项目的海洋里,那么你一定对这种感觉不陌生:面对一个全新的、功能强大的开源工具,兴奋地克隆了仓库,然后……就卡在了第一步。REA…...

C# AI开发实战:BotSharp框架构建企业级NLP应用指南
1. 项目概述:当C#开发者遇上AI应用开发如果你是一名长期深耕.NET生态的开发者,最近看着Python在AI领域风生水起,心里是不是有点痒,又有点不甘?总觉得为了跑个模型、搭个智能对话,就得切到另一个完全不同的技…...

基于MCP与Apify构建AI驱动的投资另类数据研究工具
1. 项目概述:当投资研究遇上AI代理如果你是一名量化研究员、对冲基金分析师,或者只是一个对金融市场充满好奇、希望用数据驱动决策的独立投资者,那么你肯定对“另类数据”这个词不陌生。传统的财报、股价、宏观经济指标,这些“传统…...