【MySQL】深入浅出主从复制数据同步原理
【MySQL】深入浅出主从复制数据同步原理
参考资料:
全解MySQL之主从篇:死磕主从复制中数据同步原理与优化
MySQL 日志:undo log、redo log、binlog 有什么用?
文章目录
- 【MySQL】深入浅出主从复制数据同步原理
- 一、主从复制架构概述
- 二、MySQL中的主从复制技术
- MySQL数据同步的原理
- 从节点拉取的数据到底是什么格式?
- 三、基于主从模型的不同架构
- 一主一从/多从架构
- 双主/多主架构
- 多主一从架构
- 主从架构小结
- 四、主从数据一致性的解决方案
- 改变业务逻辑
- 更改复制方式
- 调整数据库架构
- 引入第三方中间件
一、主从复制架构概述
不论任何技术栈,但凡一提高可用、高性能、高稳定这些词汇,必然会牵扯到集群、主从架构的概念,如MQ、Redis、ES、MongoDB、Zookeeper.....任何技术栈中都会有,而MySQL中同样不例外,官方也提供了主从架构的支持,通过调整多个MySQL节点的配置信息,即可将一个节点的数据同步给另一个或多个节点,但这种方式同步的是所有数据!
主从架构中必须有一个主节点,以及一个或多个从节点,所有的数据都会先写入到主,接着其他从节点会复制主节点上的增量数据,从而保证数据的最终一致性,使用主从复制方案,可以进一步提升数据库的可用性和性能:
- ①在主节点宕机或故障的情况下,从节点能自动切换成主节点的身份,从而继续对外提供服务。
- ②提供数据备份的功能,当主节点的数据发生损坏时,从节点中依旧保存着完整数据。
- ③可以基于主从实现读写分离,主节点负责处理写请求,从节点处理读请求,进一步提升性能。
但无论任何技术栈的主从架构,都会存在致命硬伤,同时也会存在些许问题需要解决:
- ①硬伤:木桶效应,一个主从集群中所有节点的容量,受限于存储容量最低的哪台服务器。
- ②数据一致性问题:由于同步复制数据的过程是基于网络传输完成的,所以存储延迟性。
- ③脑裂问题:从节点会通过心跳机制,发送网络包来判断主机是否存活,网络故障情况下会产生多主。
上述提到的三个问题中,第一个问题只能靠加大服务器的硬件配置解决,第二个问题相对来说已经有了很好的解决方案(后续讲解),第三个问题则是部署方式决定的,如果将所有节点都部署在同一网段,基本上不会出现集群脑裂问题。
上面简单了解了主从复制架构的一些基本概念后,接着来聊一聊MySQL中的主从复制。
二、MySQL中的主从复制技术
MySQL数据同步的原理
MySQL是基于它自身的Bin-log日志来完成数据的异步复制,因为Bin-log日志中会记录所有对数据库产生变更的语句,包括DML数据变更和DDL结构变更语句,数据的同步过程如下:
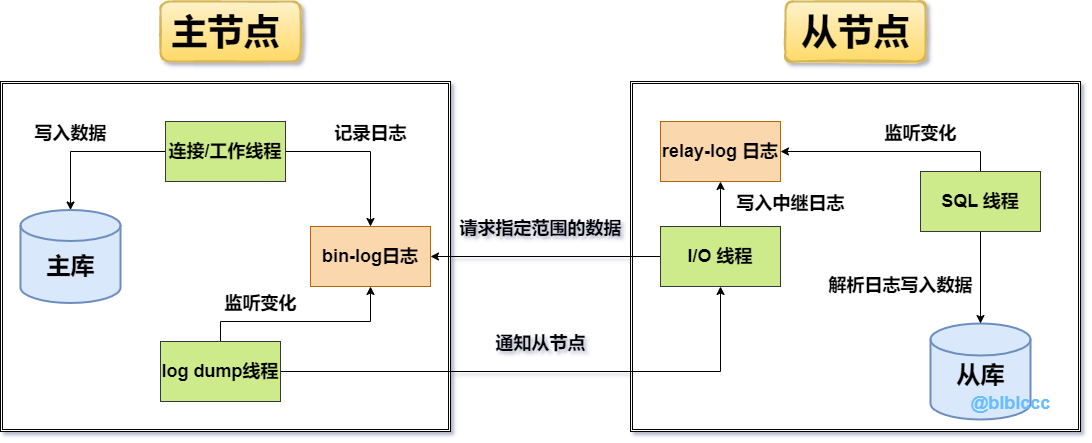
上述即是主从同步数据的原理图,但在讲解之前先来了解一下两种数据同步的方式:
- 主节点推送:当主节点出现数据变更时,主动向自身注册的所有从节点推送新数据写入。
- 从节点拉取:从节点定期去询问一次主节点是否有数据更新,有则拉取新数据写入。
那MySQL究竟采用的是什么方式呢?其实是「从拉」的方案,但对其稍微做了一些优化,传统的「从拉」方案是需要从节点一直与主节点保持长连接,从节点定时或持续性的对主节点做轮询,查看主机的数据是否发生了变更,而MySQL的数据同步原理如下:
- ①客户端将写入数据的需求交给主节点,主节点先向自身写入数据。
- ②数据写入完成后,紧接着会再去记录一份
Bin-log二进制日志。 - ③配置主从架构后,主节点上会创建一条专门监听
Bin-log日志的log dump线程。 - ④当
log dump线程监听到日志发生变更时,会通知从节点来拉取数据。 - ⑤从节点会有专门的
I/O线程用于等待主节点的通知,当收到通知时会去请求一定范围的数据。 - ⑥当从节点在主节点上请求到一定数据后,接着会将得到的数据写入到
relay-log中继日志。 - ⑦从节点上也会有专门负责监听
relay-log变更的SQL线程,当日志出现变更时会开始工作。 - ⑧中继日志出现变更后,接着会从中读取日志记录,然后解析日志并将数据写入到自身磁盘中。
阅读上述流程后,相信大家能感受出MySQL主从复制时做的优化,在主从数据同步的过程中,从节点并不会无限制的询问主机,这样实在太影响效率了,在MySQL中引入了惰性的思想,只有当主节点真正出现数据变更时,才会通知从节点拉取数据!
从节点拉取的数据到底是什么格式?
前面从整体角度出发,简单讲述了主从同步数据的过程,但从节点复制的数据到底是什么格式的呢?这里要根据主节点的Bin-log日志格式来决定,它会有三种格式,如下:
Statment:记录每一条会对数据库产生变更操作的SQL语句(默认格式)。Row:记录具体出现变更的数据(也会包含数据所在的分区以及所位于的数据页)。Mxed:Statment、Row的结合版,可复制的记录SQL语句,不可复制的记录具体数据。
一般在搭建主从架构时,最好将
Bin-log日志调整为Mixed格式,因为这种方式绝对不会出现数据不一致性,毕竟默认的Statment格式会导致主从节点间的数据出现不一致,例如:
-
insert into `zz_users` values(11,"blblccc","男","3333",now());当主节点插入数据时,使用了
sysdate()、now()....这类函数时,主节点会取自身的系统时间插入数据,而当从节点拉取SQL执行时,则会获取从节点的系统时间插入数据,因为主/从节点执行SQL语句绝对不可能发生在同一时间,因此就会导致主/从节点中,同一条数据的时间不一致。 -
有一个数据库表t1,表中有如下两条记录:
CREATE TABLE t1 (a int(11) DEFAULT NULL,b int(11) DEFAULT NULL,KEY a (a) ) ENGINE=InnoDB DEFAULT CHARSET=latin1; insert into t1 values(10,2),(20,1);接着开始执行两个事务的写操作:

以上两个事务执行之后,数据库里面的记录会变成(11,2)和(20,2),这个发上在主库的数据变更大家都能理解。
假如事务的隔离级别是read committed,所以,事务1在更新时,只会对b=2这行加上行级锁,不会影响到事务2对b=1这行的写操作。
以上两个事务执行之后,会在bin log中记录两条记录,因为事务2先提交,所以
UPDATE t1 SET b=2 where b=1;会被优先记录,然后再记录UPDATE t1 SET a=11 where b=2;(再次提醒:statement格式的bin log记录的是SQL语句的原文)这样bin log同步到备库之后,SQL语句回放时,会先执行
UPDATE t1 SET b=2 where b=1;,再执行UPDATE t1 SET a=11 where b=2;。这时候,数据库中的数据就会变成(11,2)和(11,2)。这就导致主库和备库的数据不一致了!!!
而将Bin-log日志调整为Mixed格式后,就不会再出现这样的问题,因为对于这种不可复制的记录,会直接选择记录具体变更过的数据到日志中,当从节点读取数据写入时,则可以直接将数据放到磁盘对应的位置中即可。
那为什么不选择
Row格式来作为数据同步时的格式呢?
这种方式同步数据不需要经过SQL解析过程,只需直接将数据放到磁盘的具体位置即可,但这种方式会让主节点的I/O负载直线拉高,在传输时也会大量占用网络带宽,因此一般都不会选择Row作为同步复制时的格式。
三、基于主从模型的不同架构
前面将最基本的主从复制原理和细节讲清楚了,虽然MySQL官方只提供了最基本的主从复制技术的支持,但这并不妨碍咱们将其玩出花来,目前业内可以基于主从机制实现:一主一从/多从、双主/多主、多主一从、级联复制四种架构,下面详细聊一聊每种架构。
一主一从/多从架构
一主一从或一主多从,这是传统的主从复制模型,也就是多个主从节点组成的集群中,只有一个主节点,剩余的所有节点都为其附属关系,大致如下:
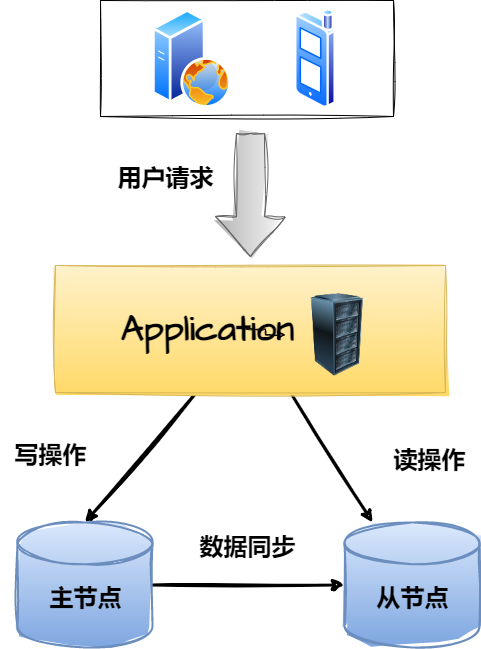
这种架构中,从节点的所有数据都源自于主节点,如上图所示,为了充分的利用好这种架构,一般都会基于它实现读写分离,也就是将客户端的写请求发给主节点处理,将客户端的读请求发给从节点处理。这种模式下,相较于单机节点而言,能够在性能上进一步提升,因为读写请求都被分发到了不同的节点处理,所以吞吐量至少会提升50%以上。
双主/多主架构
上述的一主一从/多从架构,更加适用于一些读大于写的场景,因为这类项目中,读请求的数量远超出写请求,因此将读操作分发到从库上,能够大大降低主库的访问压力,但如若你的项目中读写请求的比例对半开,同时整体的并发量也不算低,至少超出了单库的承载阈值,这时就可以选用双主/多主架构,如下:
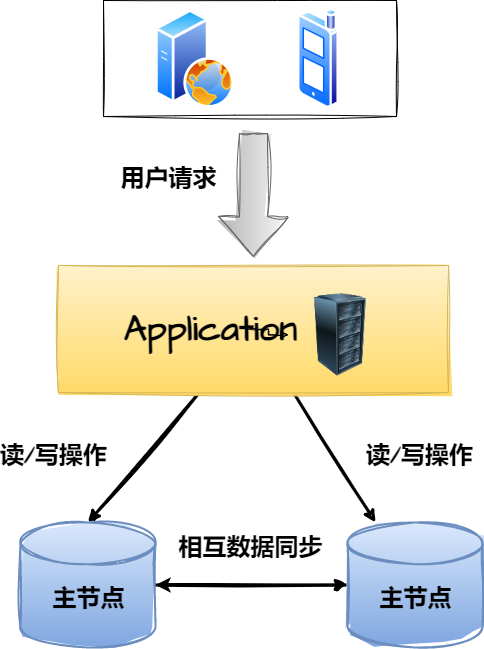
上图是一个典型的双主架构,这里有两个MySQL节点,它们都是主库,也都属于对方的从库,也就是两者之间会相互同步数据,这时为了防止主键出现冲突,一般都会通过设置数据库自增步长的方式来防重,通常会将两个节点的自增步长设为2,然后为两个节点分配自增初始值1、2,最终会出现如下效果:
DB1:1、3、5、7、9、11、13、15、17.......DB2:2、4、6、8、10、12、14、16、18......
在两个库上插入数据时,各自会以上述序列进行主键的递增,接着两个节点会各自同步对方的数据,这也就意味着双方都具备完整的数据,因此无论是:简单读、简单写、批量写、多表查…等任何类型的操作,都可以随便分发到任意节点上处理。
多主一从架构
除开上述两种主从架构的基本玩法外,面对于不同场景时也会有一些新奇玩法,比如面对于一些写大于读的场景,不管是一主多从、还是多主的方式,似乎都无法很好的解决这个问题,因此要处理这类问题时,可以选用多主一从架构,啥意思呢?如下图:
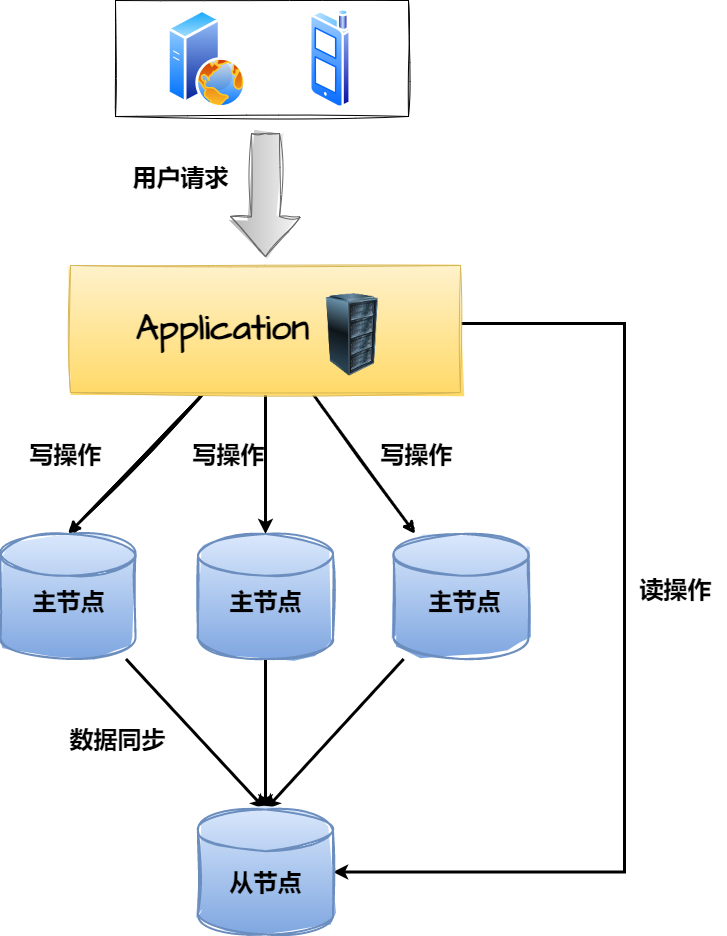
因为这种架构要解决写大于读造成的性能瓶颈,所以这里会采用多主来承载客户端的写请求,同时为了做好主键防重,也需要设置数据库自增步长和初始值,这里有三个主节点,因此自增步长为三,初始值分别为1、2、3,最终三个主节点中的数据如下:
DB1:1、4、7、10、13、16.....DB2:2、5、8、11、14、17.....DB3:3、6、9、12、15、18.....
而这三个主节点都会具备一个相同的从节点,也就是只有一个从库,它会负责同步所有主库的数据,这也就意味着从库中会具备三个主库的完整数据,这样做有什么好处呢?通过多个主节点解决了写请求导致压力过大的问题,同时从库中还有完整数据,因此也不会由于拆分了主库而影响读操作。
主从架构小结
下面做个简单的小总结:
- 一主多从架构:适用于读大于写的场景,采用多个从库来分担数据库系统的读压力。
- 多主架构:适用于读写参半的场景,采用多个主库来承载数据库系统整体的读写压力。
- 多主一从架构:适用于写大于读的场景,采用多个主库分担写压力,单个从库承载读压力。
四、主从数据一致性的解决方案
到这里为止,对于主从复制架构中绝大多数知识点和细节技术,都已经做了全面概述,最后再来重点叙说一个点,则是主从节点之间的数据一致性问题。通常情况下,对MySQL搭建了主从集群,往往从节点不会只充当备库的角色,为了充分利用已有的资源,都会在主从热备的基础上,采用读写分离方案,将写请求分发给主库、读请求分发给从库处理。
这样的确能够充分发挥从库所在机器的性能,但随之而来的还有一些问题,由于从库需要处理读取数据的请求,但主从节点之间的数据绝对会有一定延时,那对于一些关键性的数据,在主库上修改之后,再去从库上读取,这时就很有可能读取到的是旧数据,即修改前的原数据。
但这种情况对于用户而言显然是无法接受的,比如一个用户将个人信息修改后,然后再次查看时,发现个人信息依旧是修改之前的原数据,这时用户就有可能再次修改,经过反反复复多次修改后,用户发现依旧未生效,大多数情况下都会心里骂一句:“去你*的,乐色系统”!
想要解决上述这种读写分离导致的数据不一致性,主要有四种解决方案:
- 业务逻辑做改变
- 复制方式做更改
- 数据库架构做调整
- 引入第三方中间件
改变业务逻辑
改变业务逻辑的潜在含义是:对业务做一定更改,比如当用户立即修改数据后,因为在从库读不到数据,所以先显示一个审核状态,这样能够给出用户的反馈,从而避免用户再次重复操作,如:
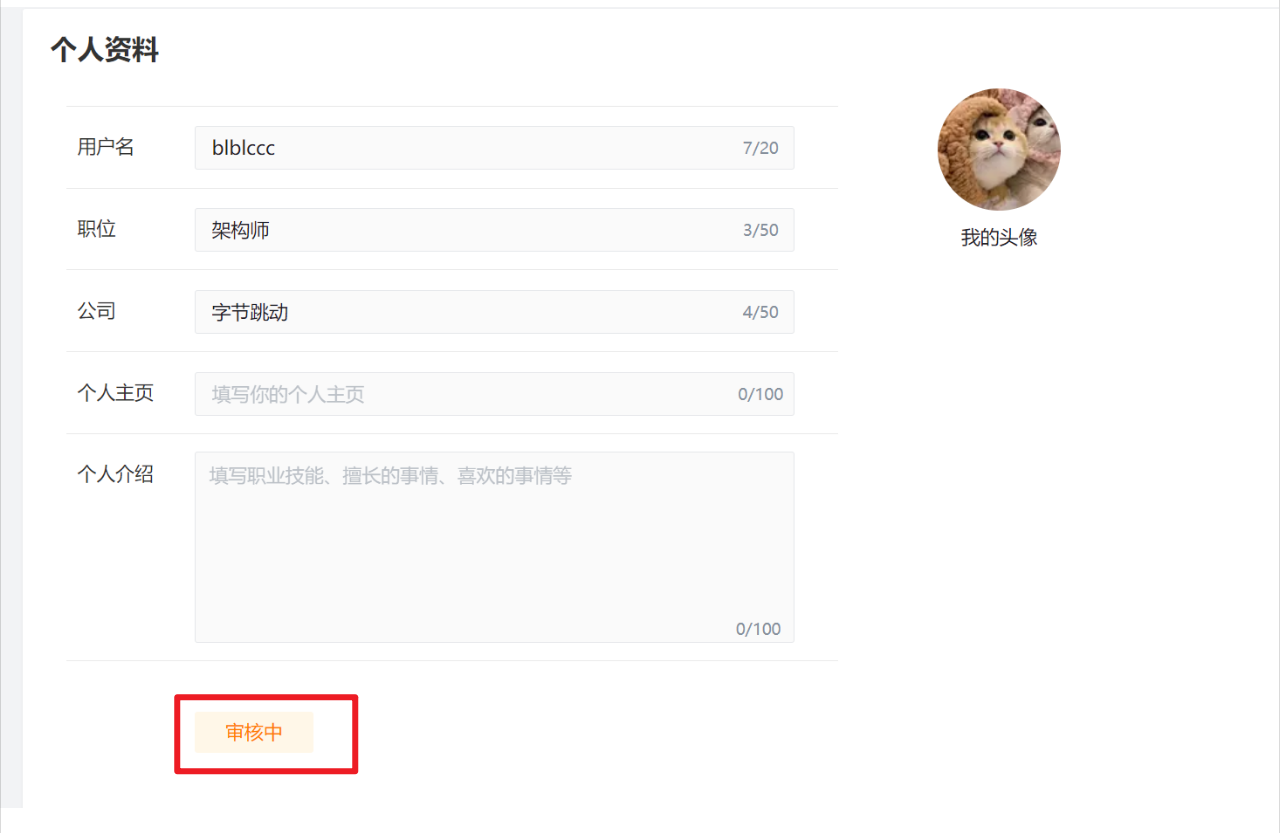
上述是掘金的个人资料,当用户手动更改后,会先显示一个「审核中」的状态,这种方式属于和数据不一致妥协的方案,接受一定的数据延迟,不过这种方式并不适用于一些对数据实时性要求较高的场景。
更改复制方式
在之前曾聊过MySQL四种数据同步复制的方式,即全同步、异步、半同步与无损复制,MySQL默认会是异步复制模式,即主节点写入数据后会立即返回成功的状态给客户端,这样能够确保性能达到最佳,但如果对实时性要求较高,可以将其改为全同步或半同步模式。
改成全同步的模式能够确保数据
100%不会存在延迟,但性能会因此严重下降,因此半同步是个不错的选择,但如果数据库仅仅是一主一从的架构,那么半同步模式和全同步模式没有任何区别,因为半同步是至少要求一个从库返回ACK,才向客户端返回写入成功,而一主一从架构中只有一个从节点~
不过就算是半同步(无损)复制模式,对比异步复制而言,依旧会导致性能下降较为严重。
调整数据库架构
如果无法接受主从架构带来的短期数据不一致,那可以升级服务器硬件,并将架构恢复成单库架构,所有读写操作都走单库完成,这就自然不会出现数据不一致问题。但如果升级硬件配置后,无法承载客户端的访问压力时,可将整体架构升级到分库分表架构,制定好合适的分片策略和路由键,每次读写数据都根据业务不同,操作不同的库。
引入第三方中间件
前面聊到的三种方案,多多少少都存在一些局限性,因为要么接受数据不一致、要么损失性能、要么使用更高规模的架构处理,但这些方案似乎都存在令人不能接受的后患,那有没有一种万全之策来解决这个问题呢?答案是有的,就是引入Canal中间件来监控主节点的Bin-log日志。
在之前讲主从同步数据原理时,曾讲到过,主节点上存在一个
log dump线程会监听Bin-log日志,当日志出现变更时会通知从节点来拉取数据,而Canal的思想也是一样的,会监控主节点的Bin-log日志,当发生变更时,就直接去拉取数据,然后直接推送给从节点写入。
Canal在主从集群的身份就类似于一个中间商,对于主节点而言,它是一个从库,因为Canal会去主库上拉取新增数据。而对于集群中真正的从节点而言,它是一个主库,因为Canal会给其他真正的从节点推送数据。但这种方式也无法做到真正的数据实时性,毕竟Canal监听变更、拉取数据、推送数据都需要时间,这部分的时间开销必然存在,只是它会比从库去主库上拉取,速度会更快一些罢了。
一般企业内部都会引入
Canal来解决数据不一致问题,因为它不仅仅只能解决主从延迟问题,还能解决MySQL-ES、MySQL-Redis.....等多种数据不一致的场景,Canal是由阿里巴巴开源的一项技术,也包括在阿里内部应用也较为广泛。
当然,也可以制定某些敏感数据走主库查询,这样能够确保数据的实时性,但容易模糊读写分离的界限,不过因为不需要引入额外的技术,所以在某些情况下也是个不错的方案。
相关文章:
【MySQL】深入浅出主从复制数据同步原理
【MySQL】深入浅出主从复制数据同步原理 参考资料: 全解MySQL之主从篇:死磕主从复制中数据同步原理与优化 MySQL 日志:undo log、redo log、binlog 有什么用? 文章目录【MySQL】深入浅出主从复制数据同步原理一、主从复制架构概述…...

Redis持久化和高可用
Redis持久化和高可用一、Redis持久化1、Redis持久化的功能2、Redis提供两种方式进行持久化二、RDB持久化1、触发条件2、bgsave执行流程3、启动时加载三、Redis高可用1、什么是高可用2、Redis高可用技术四、AOF持久化(支持秒级写入)1、开启AOF2、执行流程…...
【数据结构】第六站:栈和队列
目录 一、栈 1.栈的概念和结构 2.栈的实现方案 3.栈的具体实现 4.栈的完整代码 5.有效的括号 二、队列 1.队列的概念及结构 2.队列的实现方案 3.队列的实现 4.队列实现的完整代码 一、栈 1.栈的概念和结构 栈:一种特殊的线性表,其只允许在固定…...
python matplotlib 绘制训练曲线 综合示例——平滑处理、图题设置、图例设置、字体大小、线条样式、颜色设置
文章目录1 导出曲线数据2 python简单的 绘制曲线3 Savitzky-Golay 滤波器--平滑曲线4 对y轴数值缩放处理5 设置图题、图例、字体、网格、保存曲线图6 补充6.1 python 曲线平滑处理——方法总结-详解6.2 Tensorboard可视化训练曲线导出数据用Python绘制6.3 PyTorch可视化工具-Te…...

vue-element-plus-admin整合后端实战——实现系统登录、缓存用户数据、实现动态路由
目标 整合vue-element-plus-admin前端框架,作为开发平台的前端。 准备工作 前端选用vue-element-plus-admin,地址 https://gitee.com/kailong110120130/vue-element-plus-admin。 首先clone项目,然后整合到开发平台中去。这是一个独立的前…...
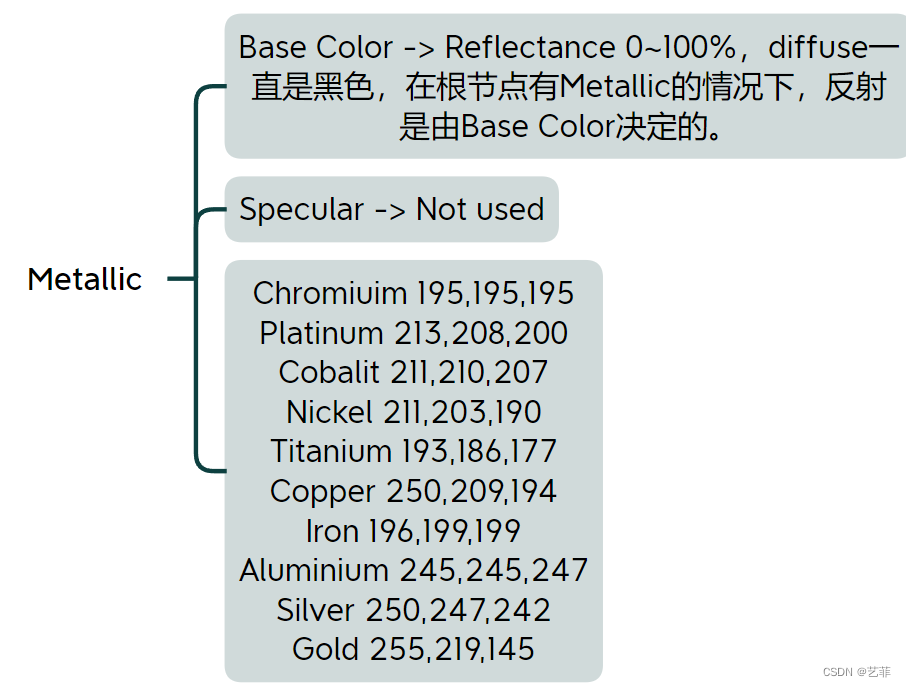
Shader Graph2-PBR介绍之表面属性(图解)
PBR的实现由光线和表面属性决定,下面我们介绍一下表面属性。这个5个属性在ShaderGraph的根节点是经常的看到,左侧是Unity中的,右侧是UE中的。 在没有Metallic金属的情况下,基础颜色值就决定了颜色的漫反射值,也就是说基…...
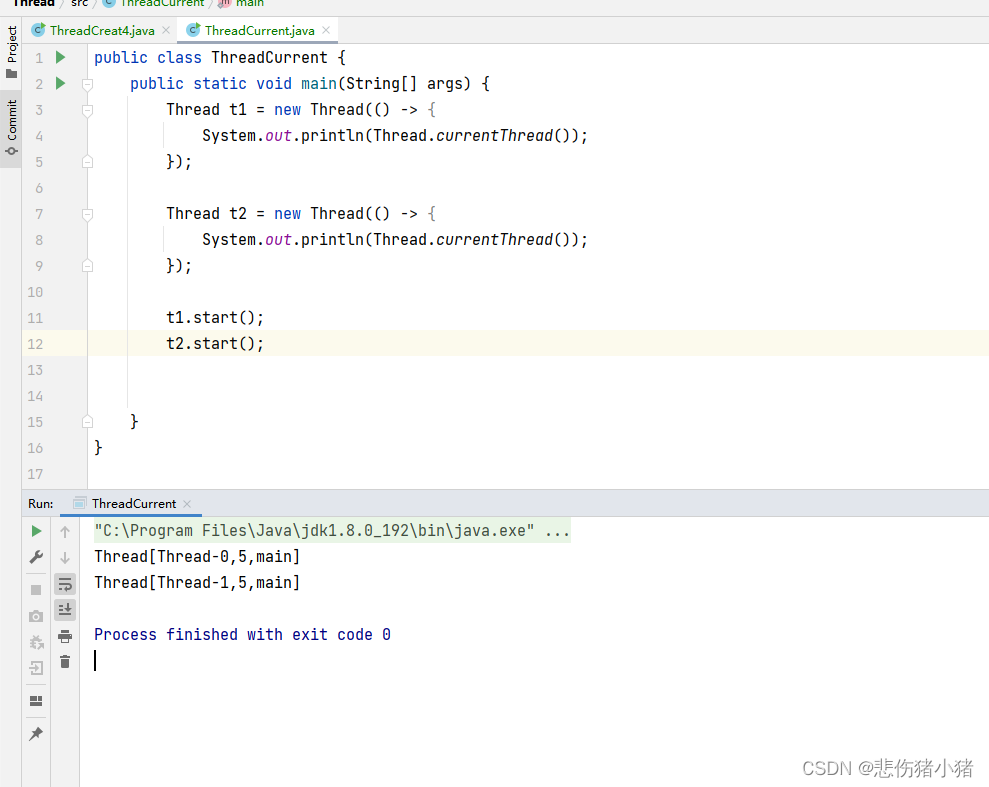
Java多线程编程,Thread类的基本用法讲解
文章目录如何创建一个线程start 与 run线程休眠线程中断线程等待获取线程实例如何创建一个线程 之前我们介绍了什么是进程与线程,那么我们如何使用代码去创建一个线程呢?线程操作是操作系统中的概念,操作系统内核实现了线程这样的机制&#…...
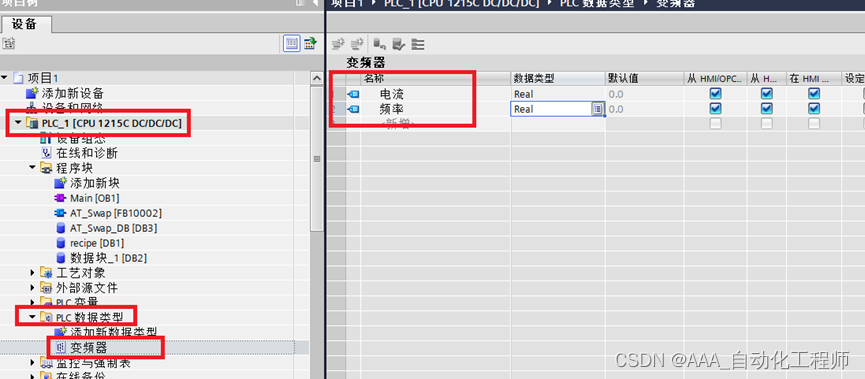
TIA博途Wincc_多路复用变量的使用方法示例(实现多台相同设备参数的画面精简)
TIA博途Wincc_多路复用变量的使用方法示例(实现多台相同设备参数的画面精简) 使用多路复用变量的好处: 当项目中存在多个相同的设备(例如:变频器、电机等),对这些设备在HMI上进行监控或修改参数时,不再需要逐个建立画面或IO域等,只需通过单个画面或IO域组合即可实现对…...

关于console你不知道的那些事
看到标题,大家会不会想,我都在前端岗位叱咤风云这么多年了, console 这个玩意用你讲 但是, 今天我将带你看到不一样的 console, 可以带来更多的帮助 了解 console 什么是 console ? console 其实是 JavaScript 内的一个原生对象。内部存储的方法大部…...
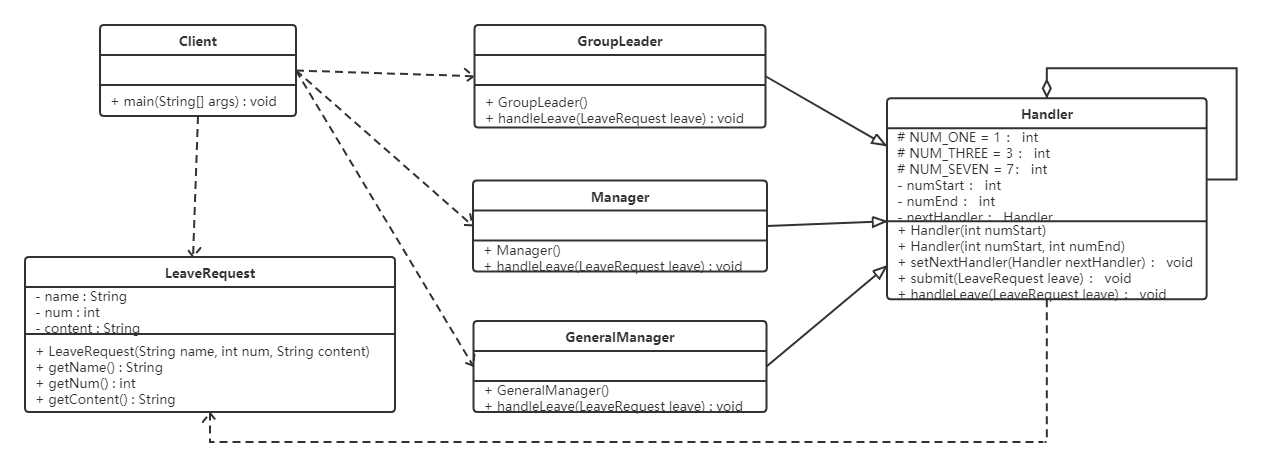
Java设计模式-责任链模式
1 概述 在现实生活中,常常会出现这样的事例:一个请求有多个对象可以处理,但每个对象的处理条件或权限不同。例如,公司员工请假,可批假的领导有部门负责人、副总经理、总经理等,但每个领导能批准的天数不同…...
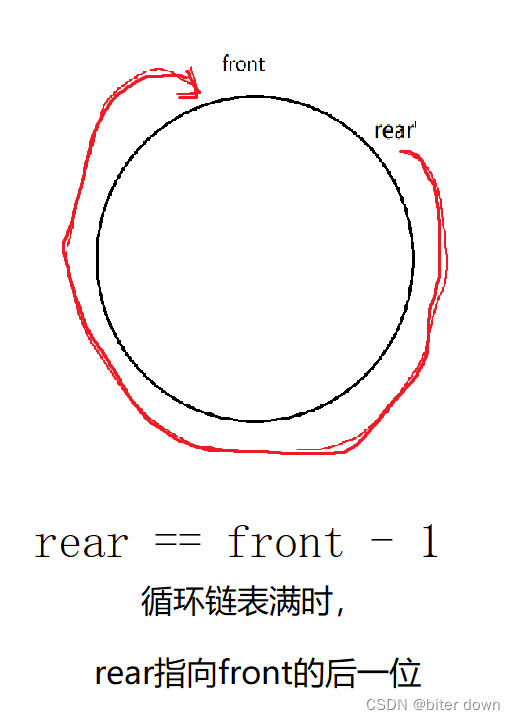
顺序表设计循环队列
使用顺序表来设计队列的最大优势是顺序表有可以定位元素的下标。 并且可以以Mod来使数组下标循环 #include<stdio.h> #include<stdlib.h> #include<assert.h> #include<stdbool.h> typedef int CQDataType; typedef struct { int* array; in…...
 - 设置默认启动项为UEFI Shell)
UEFI 基础教程 (十四) - 设置默认启动项为UEFI Shell
一 编写源代码 OvmfPkg/Library/PlatformBootManagerLib/BdsPlatform.c UINTN BootOptionPriority ( CONST EFI_BOOT_MANAGER_LOAD_OPTION *BootOption ) { DEBUG ((EFI_D_ERROR," [CSDN] BootOptionPriority %S .\n", BootOption->Description)); if (StrCmp (…...
python编程:判断一个数是否是超级素数
请定义一个函数,实现判断一个数是否是超级素数,并输出判断的结果。 一、编程题目 我们都知道,素数是除了1之外只能被自身整数的数,1除外。如果一个素数,去除一位、两位或多位后依然是素数,则我们称该素数为超级素数。…...

雷迪RD8200管线探测仪参数/管线仪使用方法/管线仪说明书
预防损坏和工作效率是我们客户面临的最大挑战 全新的 RD8200可以解决这些问题。这是我们功能优秀的精密管线仪系列,设计时充分考虑了操作员的需要。 预防损坏的专业选择 速度、准确性和可靠的性能 易于设置和使用 阳光下可读的显示屏、高性能的音频系统和用于嘈杂…...

会话共享保存到redis
1. 安装redis服务 [rootdb01 ~]# yum -y install redis 2. 配置redis服务 修改配置文件可以让其他服务器远程连接 127.0.0.1:6379 # 默认只能本地连接 [rootdb01 ~]# vim /etc/redis.conf [rootdb01 ~]# grep 172.16.1.51 /etc/redis.conf bind 127.…...
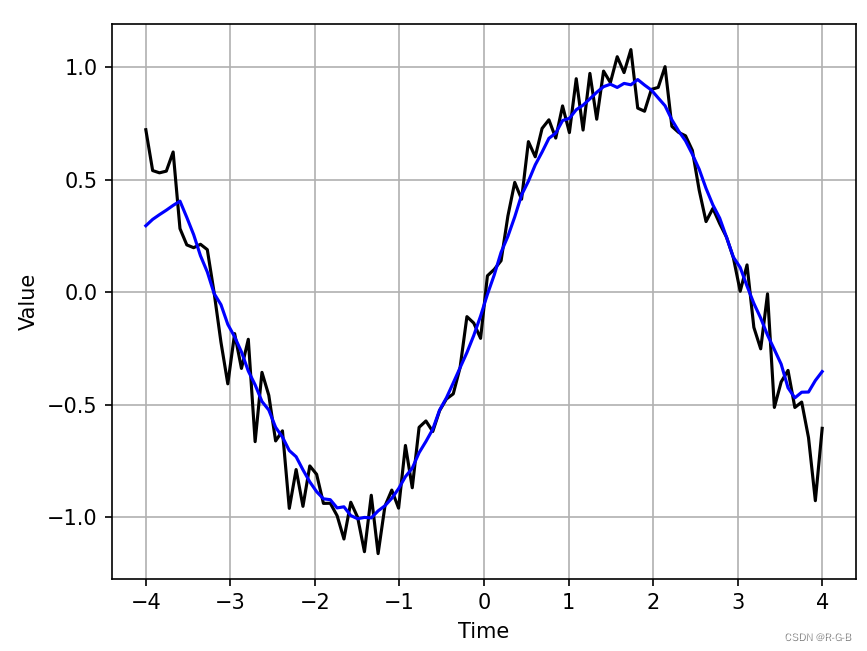
python 曲线平滑处理——方法总结(Savitzky-Golay 滤波器、make_interp_spline插值法和convolve滑动平均滤波)
文章目录1 插值法对曲线平滑处理1.1 插值法的常见实现方法1.2 拟合和插值的区别1.3 代码实例2 Savitzky-Golay 滤波器实现曲线平滑2.1 问题描述2.2 Savitzky-Golay 滤波器--调用讲解2.3 Savitzky-Golay 曲线平滑处理 示例2.4 Savitzky-Golay原理剖析3 基于Numpy.convolve实现滑…...

小驰私房菜_10_camx Otp Dump
#小驰私房菜# #camx# #Otp Dump# 本篇文章分下面几点展开: 1、otp dump的目的? 2、如何打开otp dump开关? 3、otp guide手册如何查看? 4、如何初步确认dump 出来的数据是否正确? 一、otp dump的目的 关于otp的一些概念,这里就不做过多的介绍了,不了解的同学,可以先去…...

priority_queue(堆)干货归纳+用法示例
10.priority_queue一.priority_queue(堆Heap)简介1.堆的特点:2.使用场景:二.成员函数1.构造函数:priority_queue构造函数方式:2.push()函数:向priority_queue中插入一个元素:3.pop()…...

miniprogram-to-uniapp使用指南(各种小程序项目转换为uni-app项目)
小程序分类:uni-app qq小程序 支付宝小程序 百度小程序 钉钉小程序 微信小程序 小程序转成uni_app 小程序转为uni_app 小程序转uni_app 小程序转换 工具现在支持npm全局库、HBuilderX插件两种方式使用,任君选择,HBuilderX插件地址:…...

BZOJ2720: [Violet 5]列队春游 【概率与期望】
题意自行理解,先讲一下概率和期望怎么算 概率 概率准确的定义自行百度,这里就不赘述了 概率的计算其实很简单,就是将符合条件的情况除以总共的情况 下面以掷骰子为例: 问题:将一个骰子掷出,666朝上的概率是多少 …...

如何3步免费解锁WeMod专业版:2026年终极增强工具使用指南
如何3步免费解锁WeMod专业版:2026年终极增强工具使用指南 【免费下载链接】Wand-Enhancer Advanced UX and interoperability extension for Wand (WeMod) app 项目地址: https://gitcode.com/gh_mirrors/we/Wand-Enhancer 还在为WeMod专业版的订阅费用而犹豫…...

终极指南:如何为PotPlayer配置百度翻译插件实现实时字幕翻译
终极指南:如何为PotPlayer配置百度翻译插件实现实时字幕翻译 【免费下载链接】PotPlayer_Subtitle_Translate_Baidu PotPlayer 字幕在线翻译插件 - 百度平台 项目地址: https://gitcode.com/gh_mirrors/po/PotPlayer_Subtitle_Translate_Baidu PotPlayer_Sub…...

All in Token,百度李彦宏指出:Token经济,阿里,百度,腾讯,字节,移动,电信,联通,华为,开启新的Token战争
当AI作为生产力已经成为确定性命题,我们当下应该如何衡量一家AI企业的价值?是看大模型跑分刷榜的能力,还是用户每天消耗的token数量?5月13日的Create2026大会上,百度创始人李彦宏提出了一个全新标准——DAA,…...

从零到一:基于GD32E230核心板的PCB设计实战与模块化解析
1. GD32E230核心板硬件设计基础 第一次拿到GD32E230这颗国产MCU时,说实话有点小激动。作为兆易创新基于Cortex-M23内核的拳头产品,它用55nm工艺把芯片面积压缩到了惊人的3x3mm,却集成了5个定时器、2个SPI、2个I2C这些实用外设。我在去年一个智…...

Qdrant客户端库实战:从向量数据库连接到生产级应用开发
1. 项目概述:从向量数据库到应用落地的桥梁如果你最近在折腾大模型应用,或者想给自己的产品加上一个“智能大脑”,那你大概率绕不开一个词:向量数据库。简单来说,它就像一个能理解“意思”的超级搜索引擎,不…...

Vircadia Native Core:开源虚拟世界服务器核心架构与部署实战
1. 项目概述:一个开源虚拟世界的“引擎心脏”如果你对构建一个属于自己的、去中心化的虚拟世界(Metaverse)感兴趣,或者你正在寻找一个能支撑起大规模、高自由度社交与协作应用的底层平台,那么Vircadia Native Core绝对…...

Iris API错误处理机制与嵌入式系统优化实践
1. Iris API错误处理机制解析在嵌入式系统开发中,API的健壮性直接影响整个系统的稳定性。Iris框架作为ARM架构下的核心组件,其错误处理机制基于JSON-RPC 2.0规范进行了深度定制,特别适合资源受限的嵌入式环境。与通用Web API不同,…...
,现在必须掌握的3种替代渲染方案)
像素艺术家紧急预警:Midjourney即将关闭--tile参数兼容性(倒计时14天),现在必须掌握的3种替代渲染方案
更多请点击: https://intelliparadigm.com 第一章:像素艺术家紧急预警:Midjourney即将关闭--tile参数兼容性(倒计时14天) Midjourney v6.5 已正式宣布将于 14 天后终止对 --tile 参数的原生支持,此举将直…...

基于Claude API构建AI代码生成工具:从API封装到工程化实践
1. 项目概述与核心价值最近在开发者社区里,一个名为ashish200729/claude-code-source-code的项目标题引起了不小的讨论。乍一看,这个标题很容易让人产生误解,以为这是某个知名AI模型的源代码被公开了。但作为一名在软件开发和开源领域摸爬滚打…...

C# AI开发实战:BotSharp框架构建企业级NLP应用指南
1. 项目概述:当C#开发者遇上AI应用开发如果你是一名长期深耕.NET生态的开发者,最近看着Python在AI领域风生水起,心里是不是有点痒,又有点不甘?总觉得为了跑个模型、搭个智能对话,就得切到另一个完全不同的技…...