【大数据之Hadoop】八、MapReduce之序列化
1 概述
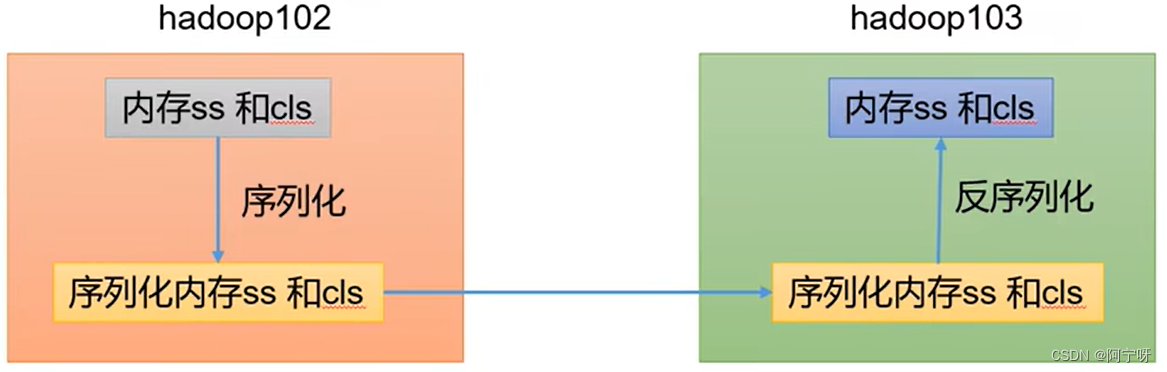
序列化:
把内存中的对象,转换成字节序列(或其他数据传输协议),以便于存储到磁盘(持久化)和网络传输。
反序列化:
将收到字节序列(或其他数据传输协议)或者是磁盘的持久化数据,转换成内存中的对象。
序列化原因:
服务器间不能传递内存中的对象,对象只能在本地的进程中使用;所以通过将内存中的对象序列化和反序列化的方式进行传递。
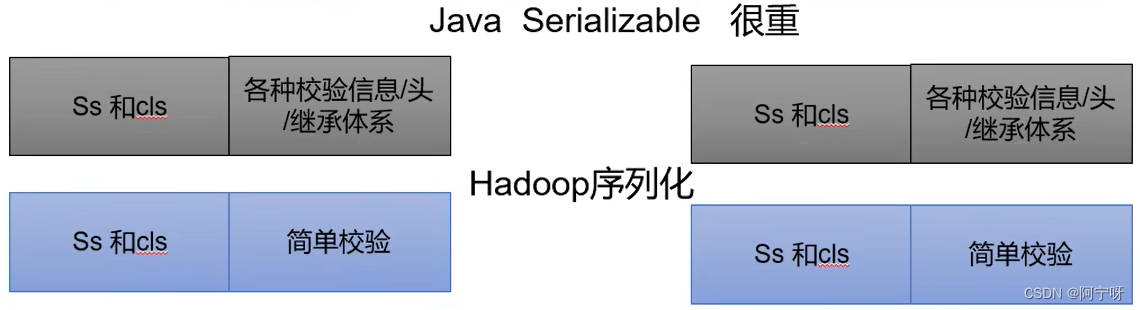
不用Java序列化的原因:
Java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,Header,继承体系等),不便于在网络中高效传输。
Hadoop序列化只附带了一些简单的校验信息。
优点:
(1)结构紧凑:高效利用存储空间。
(2)快速:读写额外开销小。
(3)互操作:支持多语言交互。
2 自定义bean对象实现序列化接口(Writable)
当基本序列化类型(第三章 1.4 部分)不能满足所有需求,比如在Hadoop框架内部传递一个bean对象,那么该对象就需要实现序列化接口。
步骤:
(1)必须实现Writable接口。
(2)反序列化时,需要反射调用空参构造函数,所以必须有空参构造。
public FlowBean() {super();
}
(3)重写序列化方法。
@Override
public void write(DataOutput out) throwsIOException {out.writeLong(upFlow);out.writeLong(downFlow);out.writeLong(sumFlow);
}
(4)重写反序列化方法。
@Override
public void readFields(DataInput in)throws IOException {upFlow= in.readLong();downFlow= in.readLong();sumFlow= in.readLong();
}
(5)反序列化的顺序和序列化的顺序完全一致(先进先出原则)。
(6)想把结果显示在文件中(因为默认传输的是地址值),需要重写toString(),可用"\t"分开,方便后续用。
(7)如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key必须能排序。
@Override
public int compareTo(FlowBean o) {//倒序排列,从大到小returnthis.sumFlow > o.getSumFlow() ? -1 : 1;
}
3 序列化案例

步骤:
(1)创建一个Bean实现Writable接口,创建构造函数getter和setter,重写序列化方法write(…)和反序列化方法readFields(…)以及输出函数toString()
package com.study.mapreduce.Flow;import org.apache.hadoop.io.Writable;import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;public class FlowBean implements Writable {private long upFlow; //上行流量private long downFlow; //下行流量private long sumFlow; //总流量public FlowBean() {}public long getUpFlow() {return upFlow;}public long getDownFlow() {return downFlow;}public long getSumFlow() {return sumFlow;}public void setUpFlow(long upFlow) {this.upFlow = upFlow;}public void setDownFlow(long downFlow) {this.downFlow = downFlow;}public void setSumFlow() {this.sumFlow = this.upFlow + this.downFlow;}// 反序列化的顺序和序列化的顺序完全一致(先进先出原则)。@Overridepublic void write(DataOutput dataOutput) throws IOException {dataOutput.writeLong(upFlow);dataOutput.writeLong(downFlow);dataOutput.writeLong(sumFlow);}@Overridepublic void readFields(DataInput dataInput) throws IOException {this.upFlow = dataInput.readLong();this.downFlow = dataInput.readLong();this.sumFlow = dataInput.readLong();}@Overridepublic String toString() {return " " + upFlow +" " + downFlow +" " + sumFlow ;}
}(2)创建Mapper类继承Mapper泛型,Mapper泛型<输入key,输入value,输出key,输出value>,重写map(…)函数,对数据进行切割封装。
输入key一般都是默认的类型LongWritable,输入value为一行数据则为Text;输出key为字符类型即Text,输出value为Bean,Bean中封装有别的内容。
package com.study.mapreduce.Flow;import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;//Mapper泛型<输入key,输入value,输出key,输出value>
//输入key一般都是默认的类型LongWritable,输入value为一行数据则为Text
//输出key为电话号码,为字符类型即Text,输出value为FlowBean,FlowBean中封装有别的内容
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {private Text outK = new Text();private FlowBean outV = new FlowBean();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//1 获取一行数据,转成字符串//1 13498787894 120.196.100.99 www.baidu.com 1116 954 200String line = value.toString();//2 切割数据//1,13498787894,120.196.100.99,www.baidu.com,1116,954,200String[] split = line.split(" ");//3 抓取我们需要的数据:手机号,上行流量,下行流量String phone = split[1];String up = split[split.length - 3];String down = split[split.length - 2];//4 封装outK outVoutK.set(phone);outV.setUpFlow(Long.parseLong(up)); //Long.parseLong():把string类型转为long型outV.setDownFlow(Long.parseLong(down));outV.setSumFlow();//5 写出outK outVcontext.write(outK, outV);}
}(3)创建Reducer类继续Reducer泛型,重写reduce(…)函数,对数据进行整合封装。reduce方法是相同的key调用一次
reduce的输入key,value为mapper的输出key,value;reduce的输出key,value为自己指定类型为Text,Bean。
package com.study.mapreduce.Flow;import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;//reducer的输入kv为mapper的输出kv
public class FlowReducer extends Reducer<Text, FlowBean, Text, FlowBean> {private FlowBean outV = new FlowBean();@Overrideprotected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {//reduce方法是相同的key调用一次long totalUp = 0;long totalDown = 0;//1 遍历values,将其中的上行流量,下行流量分别累加for (FlowBean flowBean : values) {totalUp += flowBean.getUpFlow();totalDown += flowBean.getDownFlow();}//2 封装outKVoutV.setUpFlow(totalUp);outV.setDownFlow(totalDown);outV.setSumFlow();//3 写出outK outVcontext.write(key,outV);}
}(4)创建Driver类,写法固定。
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {//1 获取job对象Configuration conf = new Configuration(true);Job job = Job.getInstance(conf);//2 关联本Driver类job.setJarByClass(FlowDriver.class);//3 关联Mapper和Reducerjob.setMapperClass(FlowMapper.class);job.setReducerClass(FlowReducer.class);//4 设置Map端输出KV类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(FlowBean.class);//5 设置程序最终输出的KV类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(FlowBean.class);//6 设置程序的输入输出路径FileInputFormat.setInputPaths(job, new Path("D:\\inputflow"));FileOutputFormat.setOutputPath(job, new Path("D:\\outputflow"));//7 提交Jobboolean b = job.waitForCompletion(true);System.exit(b ? 0 : 1);}
相关文章:
【大数据之Hadoop】八、MapReduce之序列化
1 概述 序列化: 把内存中的对象,转换成字节序列(或其他数据传输协议),以便于存储到磁盘(持久化)和网络传输。 反序列化: 将收到字节序列(或其他数据传输协议)…...
Python网络爬虫之Selenium详解
1、什么是selenium? Selenium是一个用于Web应用程序测试的工具。Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。支持通过各种driver(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)驱动真实浏览器…...

中睿天下受邀出席电促会第五次会员代表大会
3月21日,中国电力发展促进会(以下简称“电促会”)第五次会员代表大会暨第五届理事会第一次会议在京召开,中睿天下作为网络安全专业委员会会员单位受邀出席。 会议表决通过了第五次会员代表大会工作报告、第四届理事会财务报告、《…...

Chat GPT:软件测试人员的危机?
Chat GPT,作为一个引起科技巨头“红色警报”的人工智能语言模型,短期内便席卷全球,上线仅两个月活跃用户破亿。比尔盖茨更是如此评价“这种AI技术出现的重大历史意义,不亚于互联网和个人电脑的诞生。” 在各个行业备受关注的Chat …...
【Redis】高可用:Redis的主从复制是怎么实现的?
【Redis】高可用:主从复制详解 我们知道要避免单点故障,即保证高可用,便需要冗余(副本)方式提供集群服务。而Redis 提供了主从库模式,以保证数据副本的一致,主从库之间采用的是读写分离的方式。…...
WLAN速度突然变慢
目录 一、问题 二、在设置中重置网络 1. 按下组合键“WinI”打开设置,在设置窗口中点击“网络和Internet”。 2、点击左侧的“状态”,在右侧选择“网络重置”。 3、然后会进入“网络重置”页面,点击“立即重置”后点击“是”等待完成即可…...
GDAL和 Pillow 的互操作)
GDAL python教程基础篇(12)GDAL和 Pillow 的互操作
GDAL和 Pillow GDAL和PIL处理和操作的对象都是栅格图像。 但它们又不一样。 GDAL主要重点放在地理或遥感数据的读写和数据建模以及地理定位和转换, 但是PIL的重点是放在图像本身处理上的。 至于在底层数据处理上,两者都可以用 numpy 转化的二进制作为数…...

快速学习java路线建议
还有2 ,3个月就要毕业了,啥都不会的你是不是很慌呢,是不是想知道怎么样快速学习java呢。嘿嘿!它来了。 首先是java的学习 ,推荐 【尚硅谷】7天搞定Java基础,Java零…...
【MySQL】深入浅出主从复制数据同步原理
【MySQL】深入浅出主从复制数据同步原理 参考资料: 全解MySQL之主从篇:死磕主从复制中数据同步原理与优化 MySQL 日志:undo log、redo log、binlog 有什么用? 文章目录【MySQL】深入浅出主从复制数据同步原理一、主从复制架构概述…...

Redis持久化和高可用
Redis持久化和高可用一、Redis持久化1、Redis持久化的功能2、Redis提供两种方式进行持久化二、RDB持久化1、触发条件2、bgsave执行流程3、启动时加载三、Redis高可用1、什么是高可用2、Redis高可用技术四、AOF持久化(支持秒级写入)1、开启AOF2、执行流程…...
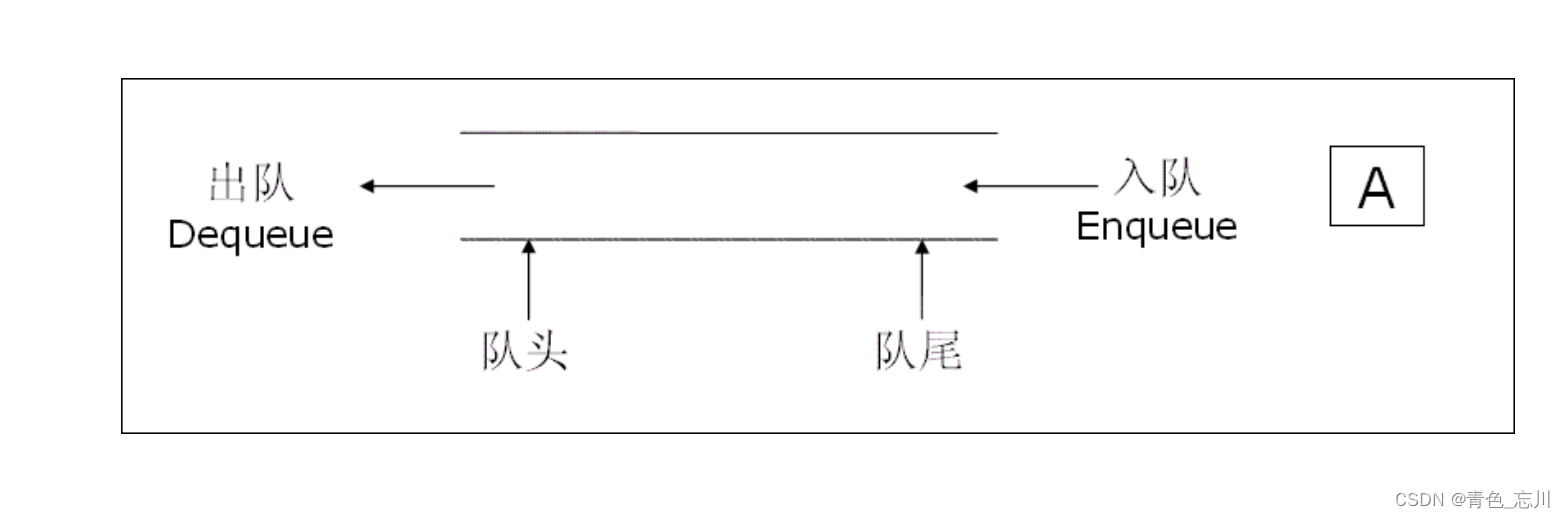
【数据结构】第六站:栈和队列
目录 一、栈 1.栈的概念和结构 2.栈的实现方案 3.栈的具体实现 4.栈的完整代码 5.有效的括号 二、队列 1.队列的概念及结构 2.队列的实现方案 3.队列的实现 4.队列实现的完整代码 一、栈 1.栈的概念和结构 栈:一种特殊的线性表,其只允许在固定…...
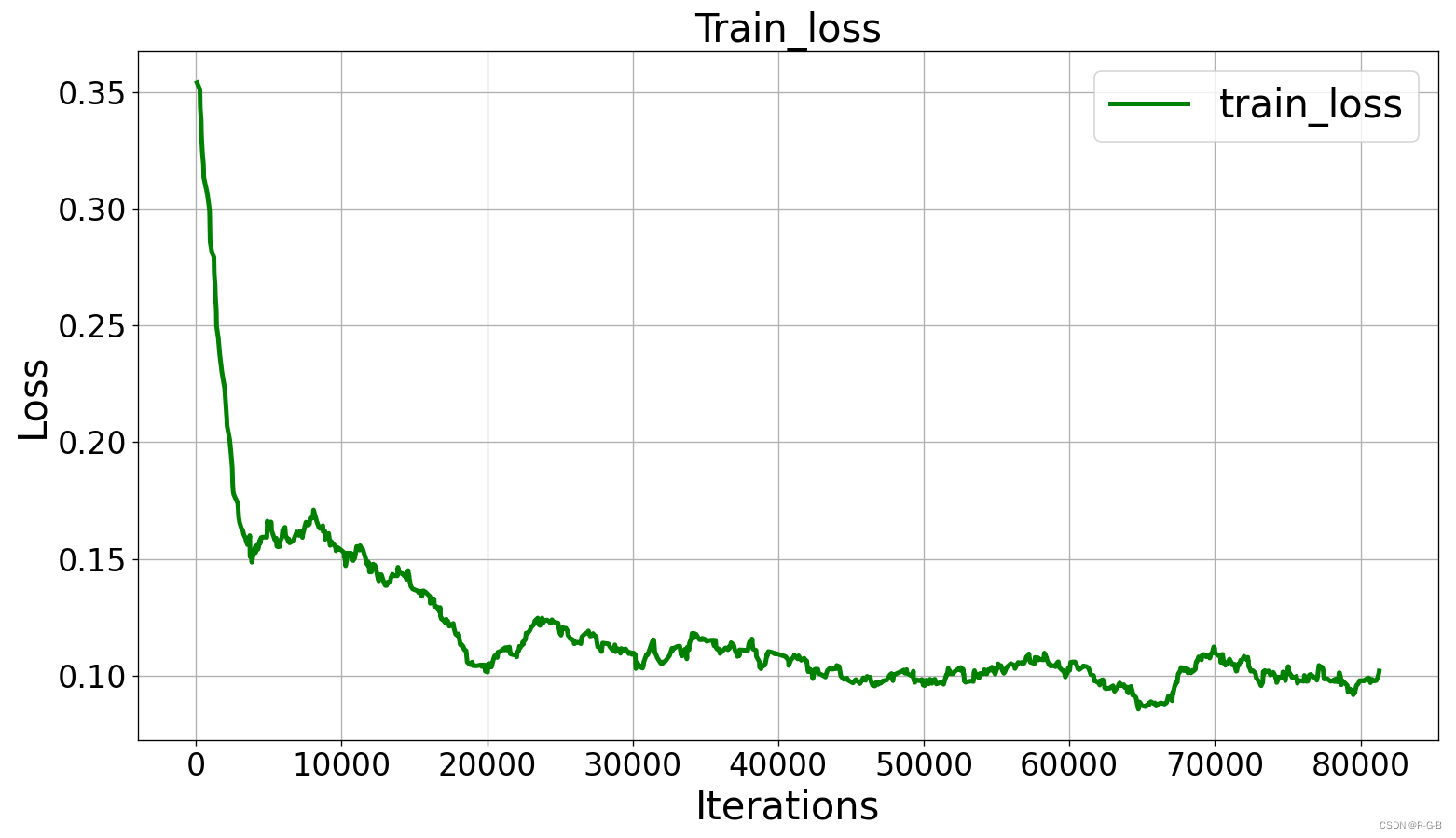
python matplotlib 绘制训练曲线 综合示例——平滑处理、图题设置、图例设置、字体大小、线条样式、颜色设置
文章目录1 导出曲线数据2 python简单的 绘制曲线3 Savitzky-Golay 滤波器--平滑曲线4 对y轴数值缩放处理5 设置图题、图例、字体、网格、保存曲线图6 补充6.1 python 曲线平滑处理——方法总结-详解6.2 Tensorboard可视化训练曲线导出数据用Python绘制6.3 PyTorch可视化工具-Te…...

vue-element-plus-admin整合后端实战——实现系统登录、缓存用户数据、实现动态路由
目标 整合vue-element-plus-admin前端框架,作为开发平台的前端。 准备工作 前端选用vue-element-plus-admin,地址 https://gitee.com/kailong110120130/vue-element-plus-admin。 首先clone项目,然后整合到开发平台中去。这是一个独立的前…...
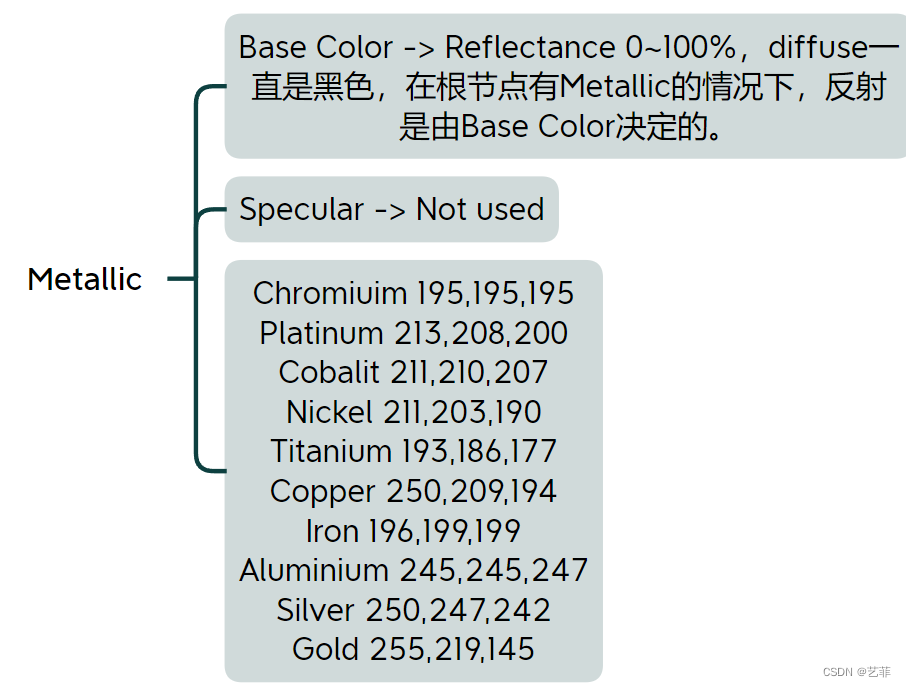
Shader Graph2-PBR介绍之表面属性(图解)
PBR的实现由光线和表面属性决定,下面我们介绍一下表面属性。这个5个属性在ShaderGraph的根节点是经常的看到,左侧是Unity中的,右侧是UE中的。 在没有Metallic金属的情况下,基础颜色值就决定了颜色的漫反射值,也就是说基…...
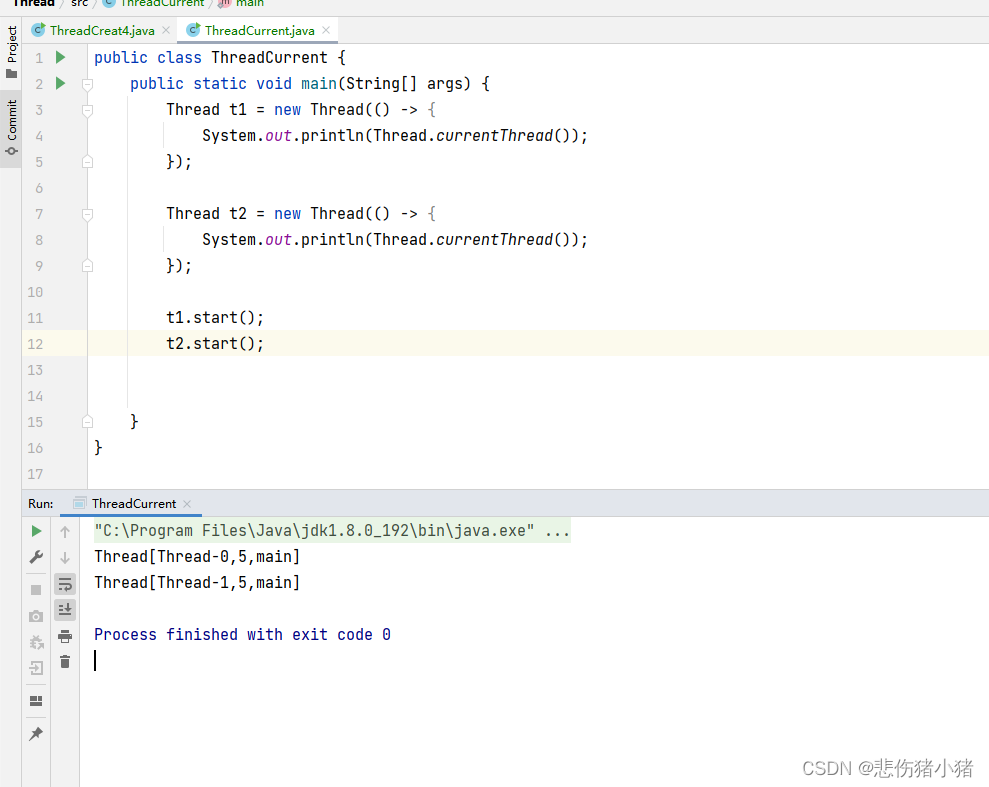
Java多线程编程,Thread类的基本用法讲解
文章目录如何创建一个线程start 与 run线程休眠线程中断线程等待获取线程实例如何创建一个线程 之前我们介绍了什么是进程与线程,那么我们如何使用代码去创建一个线程呢?线程操作是操作系统中的概念,操作系统内核实现了线程这样的机制&#…...
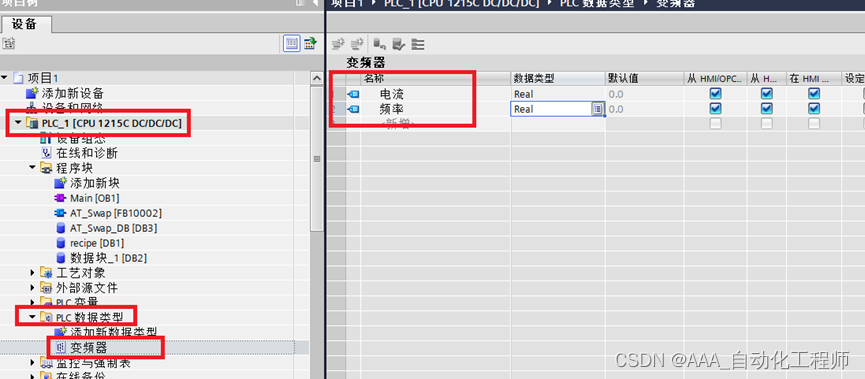
TIA博途Wincc_多路复用变量的使用方法示例(实现多台相同设备参数的画面精简)
TIA博途Wincc_多路复用变量的使用方法示例(实现多台相同设备参数的画面精简) 使用多路复用变量的好处: 当项目中存在多个相同的设备(例如:变频器、电机等),对这些设备在HMI上进行监控或修改参数时,不再需要逐个建立画面或IO域等,只需通过单个画面或IO域组合即可实现对…...

关于console你不知道的那些事
看到标题,大家会不会想,我都在前端岗位叱咤风云这么多年了, console 这个玩意用你讲 但是, 今天我将带你看到不一样的 console, 可以带来更多的帮助 了解 console 什么是 console ? console 其实是 JavaScript 内的一个原生对象。内部存储的方法大部…...
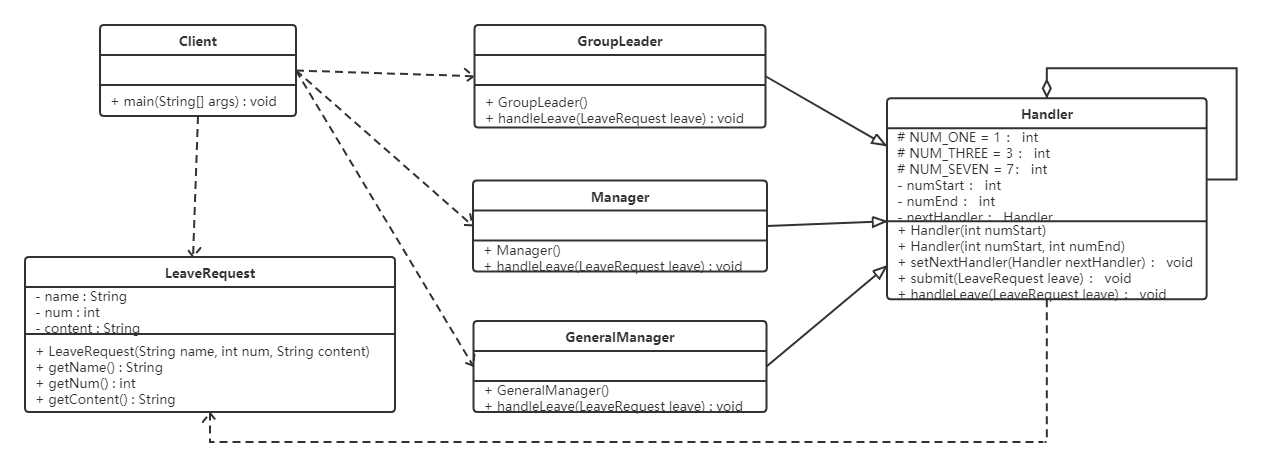
Java设计模式-责任链模式
1 概述 在现实生活中,常常会出现这样的事例:一个请求有多个对象可以处理,但每个对象的处理条件或权限不同。例如,公司员工请假,可批假的领导有部门负责人、副总经理、总经理等,但每个领导能批准的天数不同…...
顺序表设计循环队列
使用顺序表来设计队列的最大优势是顺序表有可以定位元素的下标。 并且可以以Mod来使数组下标循环 #include<stdio.h> #include<stdlib.h> #include<assert.h> #include<stdbool.h> typedef int CQDataType; typedef struct { int* array; in…...
 - 设置默认启动项为UEFI Shell)
UEFI 基础教程 (十四) - 设置默认启动项为UEFI Shell
一 编写源代码 OvmfPkg/Library/PlatformBootManagerLib/BdsPlatform.c UINTN BootOptionPriority ( CONST EFI_BOOT_MANAGER_LOAD_OPTION *BootOption ) { DEBUG ((EFI_D_ERROR," [CSDN] BootOptionPriority %S .\n", BootOption->Description)); if (StrCmp (…...

防火门安装与验收要点|闭门器、密封条、顺序器缺一不可
防火门安装与验收要点一、必备配件(缺一不可)闭门器:自动关门,火灾常态闭合防火密封条:遇火膨胀,隔烟阻火顺序器:双扇门专用,保证先后闭合二、安装要点门框墙体嵌实牢固,…...

怎样免费让老Mac重获新生:OpenCore Legacy Patcher专业教程
怎样免费让老Mac重获新生:OpenCore Legacy Patcher专业教程 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 想让你的旧Mac重新焕发活力吗…...

基于Fire2012算法与FastLED库的Arduino LED篝火制作全攻略
1. 项目概述:用代码点燃一场永不熄灭的数字篝火夏夜、星空、朋友围坐,篝火带来的温暖与氛围是露营的灵魂。但现实是,很多营地禁止明火,或者在城市阳台、室内空间,生一堆真正的火既不安全也不现实。作为一名玩了十多年A…...

构建轻量级LLM工具集:模块化设计、多模型集成与本地化部署实践
1. 项目概述:一个面向日常的轻量级LLM工具集最近在GitHub上闲逛,发现了一个挺有意思的项目,叫“Daily-LLM”。光看名字,你可能会觉得这又是一个庞大的、需要海量算力才能跑起来的“大模型”项目。但点进去仔细研究后,我…...

SyntaxUI:基于原子设计与Web组件的现代UI库开发实践
1. 项目概述:一个为开发者而生的现代UI组件库 如果你是一名前端开发者,或者正在构建一个需要用户界面的应用,那么你肯定经历过这样的场景:为了一个按钮的样式、一个表格的交互,或者一个模态框的动画,反复在…...

JetBrains IDE 30天试用重置:一键解决方案的完整实践指南
JetBrains IDE 30天试用重置:一键解决方案的完整实践指南 【免费下载链接】ide-eval-resetter 项目地址: https://gitcode.com/gh_mirrors/id/ide-eval-resetter 当您正专注于代码调试时,IDE突然弹出"评估期已结束"的红色警告…...

从零到一:基于GD32E230核心板的PCB设计实战与模块化解析
1. GD32E230核心板硬件设计基础 第一次拿到GD32E230这颗国产MCU时,说实话有点小激动。作为兆易创新基于Cortex-M23内核的拳头产品,它用55nm工艺把芯片面积压缩到了惊人的3x3mm,却集成了5个定时器、2个SPI、2个I2C这些实用外设。我在去年一个智…...

Godot游戏自动化构建与发布:基于GitHub Actions与Docker的CI/CD实践
1. 项目概述:当Godot遇上CI/CD如果你是一名独立游戏开发者,或者在一个小团队里负责Godot引擎的项目,那么“构建”和“部署”这两个词,大概率是你开发流程里最头疼的环节之一。手动导出项目到不同平台(Windows、Linux、…...

Claude-Code-KnowCraft:轻量级代码知识库构建与智能问答实践
1. 项目概述与核心价值最近在跟几个做AI应用开发的朋友聊天,大家普遍有个痛点:想把Claude这类大语言模型(LLM)的能力深度集成到自己的代码库分析工具里,但发现现有的方案要么太重,要么太浅。太重的是指那些…...

嵌入式动画优化:DMA驱动位图渲染在SAMD21上的实现
1. 项目概述与核心思路如果你玩过嵌入式开发,尤其是想在小小的微控制器屏幕上搞点流畅的动画,大概率会被“卡顿”和“闪屏”折磨过。传统的逐像素绘制,在需要全屏更新时,CPU时间几乎全耗在了等待屏幕刷新上,用户体验大…...