堆排序算法的原理与应用
堆排序(Heap Sort)是一种基于堆数据结构的比较排序算法。它具有时间复杂度为 O(n log n) 的优点,并且空间复杂度为 O(1),是一种不稳定的排序算法。本文将详细介绍堆排序的工作原理、步骤以及它的应用场景。
一、堆排序的基本概念
堆是一种特殊的二叉树数据结构,具有以下两个重要特性:
- 完全二叉树:所有的层都是满的,除了最后一层,且最后一层的节点从左到右依次排列。
- 堆的性质:
- 最大堆:对于每个非叶子节点,父节点的值都大于或等于其子节点的值。
- 最小堆:对于每个非叶子节点,父节点的值都小于或等于其子节点的值。
堆排序的核心思想是:利用堆这种结构,每次将堆顶元素(最大或最小)取出,然后调整剩余的堆,直到所有元素都被排好序。
1. 堆排序的流程
堆排序的基本过程可以分为以下几个步骤:
- 构建最大堆:将无序数组调整为一个符合最大堆性质的结构。
- 取出堆顶元素:将最大堆的根节点(即最大值)与最后一个节点交换,并把最大值放在数组末尾。此时,最大值已在正确的位置。
- 重新调整堆:去掉已排好的元素,重新调整剩下的部分,使其再次成为一个最大堆。
- 重复步骤 2 和 3:直到堆中只剩下一个元素,排序完成。
二、堆排序的详细步骤
接下来,我们具体看看如何实现堆排序。以下是堆排序的步骤说明:
1. 构建最大堆
将一个无序数组变成一个最大堆的过程称为堆化。堆化的过程是从最后一个非叶子节点开始,自底向上依次调整每个节点,使其符合最大堆的性质。堆化的时间复杂度为 O(n)。
2. 取出堆顶元素
最大堆的堆顶元素是整个数组的最大值。将这个值与数组的最后一个元素交换,并缩小堆的范围(忽略已排好序的部分)。这时,堆顶可能不再是最大值,需要通过堆调整重新恢复最大堆的性质。
3. 堆调整
堆调整是保持堆的性质的核心操作。每次调整时,将新的堆顶元素下沉到合适的位置,确保每个父节点都大于等于它的子节点。堆调整的时间复杂度是 O(log n),因为树的高度是 log n。
4. 重复构建和调整
重复取出堆顶元素和堆调整,直到所有元素排序完毕。由于每次取出一个元素都需要堆调整,因此总的时间复杂度为 O(n log n)。
代码示例
为了让读者更直观理解堆排序的实现,下面是堆排序的伪代码描述:
# 堆排序主函数
def heap_sort(arr):n = len(arr)# 1. 构建最大堆for i in range(n // 2 - 1, -1, -1):heapify(arr, n, i)# 2. 取出堆顶元素并重新调整堆for i in range(n - 1, 0, -1):arr[i], arr[0] = arr[0], arr[i] # 交换堆顶与最后一个元素heapify(arr, i, 0) # 重新调整堆# 堆调整函数
def heapify(arr, n, i):largest = i # 初始化当前节点为最大left = 2 * i + 1 # 左子节点right = 2 * i + 2 # 右子节点# 如果左子节点存在且大于父节点if left < n and arr[left] > arr[largest]:largest = left# 如果右子节点存在且大于父节点if right < n and arr[right] > arr[largest]:largest = right# 如果最大值不是父节点,则进行交换,并继续调整if largest != i:arr[i], arr[largest] = arr[largest], arr[i]heapify(arr, n, largest)
在上面的代码中,heap_sort 函数是堆排序的主函数,而 heapify 函数负责维护最大堆的性质。每次调整完堆后,最大的元素会被移到数组的末尾,剩下的部分继续调整直到整个数组有序。
三、堆排序的优缺点
优点
- 时间复杂度稳定:堆排序的时间复杂度始终为 O(n log n),无论输入数据的有序程度如何。
- 空间复杂度为 O(1):堆排序是一种原地排序算法,不需要额外的辅助空间。
- 不受输入数据影响:堆排序的效率不依赖于输入数据是否有序,在最坏、最好和平均情况下的时间复杂度都为 O(n log n)。
缺点
- 不稳定:堆排序是一种不稳定排序算法,也就是说,相同的元素在排序前后可能会改变相对顺序。
- 常数开销大:尽管时间复杂度为 O(n log n),但由于堆的调整操作涉及较多次的交换,导致实际性能可能不如其他 O(n log n) 的排序算法(如归并排序和快速排序)。
四、堆排序的应用场景
堆排序由于其 O(n log n) 的时间复杂度和 O(1) 的空间复杂度,适合用于内存有限且需要稳定性能的场景。例如:
- 大数据量排序:在大数据量排序中,堆排序表现较为稳定,并且由于其空间复杂度低,适合在内存有限的设备上进行排序任务。
- 优先级队列:堆排序常用于实现优先级队列。通过最大堆或最小堆,可以快速找到队列中最大或最小的元素。
- 实时排序系统:堆排序适合在需要随时调整数据顺序的系统中,如实时交易系统、调度系统等。
五、总结与讨论
堆排序作为一种高效且节省空间的排序算法,在许多大数据和系统应用中都有其独特的优势。尽管它在实际应用中的普及程度不如快速排序,但在某些特殊场景下,它凭借稳定的时间复杂度和原地排序的特性,仍然是一个有力的选择。你在实际开发中有没有遇到过需要选择堆排序的情况?相比其他排序算法,你认为它在哪些应用场景下表现更好?欢迎分享你的经验和看法!
相关文章:

堆排序算法的原理与应用
堆排序(Heap Sort)是一种基于堆数据结构的比较排序算法。它具有时间复杂度为 O(n log n) 的优点,并且空间复杂度为 O(1),是一种不稳定的排序算法。本文将详细介绍堆排序的工作原理、步骤以及它的应用场景。 一、堆排序的基本概念…...

【2024版本】Mac/Windows IDEA安装教程
IDEA 2024版本真的很强大,此外JDK发布了最新稳定版 JDK21 ,只有新版本支持JDK 21、JDK22。原来数据库插件不支持redis等一些NoSql的数据库的连接,如果要使用需要自己单独装收费的插件。直接打开idea就很吃内存了,再打开其他一大堆…...

Oracle bbed编译安装及配置
1. 什么是bbed ? Oracle Block Brower and EDitor Tool,是一个可以对oracle data block进行查看,编辑修改的内置工具。对于bbed,oracle本身是不提供支持的。 2. 如何编译bbed环境? 10g版本: 1) 编译bbed cd $ORACL…...

MindSearch 部署到Github Codespace 和 Hugging Face Space
conda init后需要重开终端,不然一键复制会导致后续pip install会安装错环境 还是报错 ImportError: cannot import name AutoRegister from class_registry (/opt/conda/envs/mindsearch/lib/python3.10/site-packages/class_registry/__init__.py)pip install --…...
【Maven】依赖管理,Maven仓库,Maven核心功能
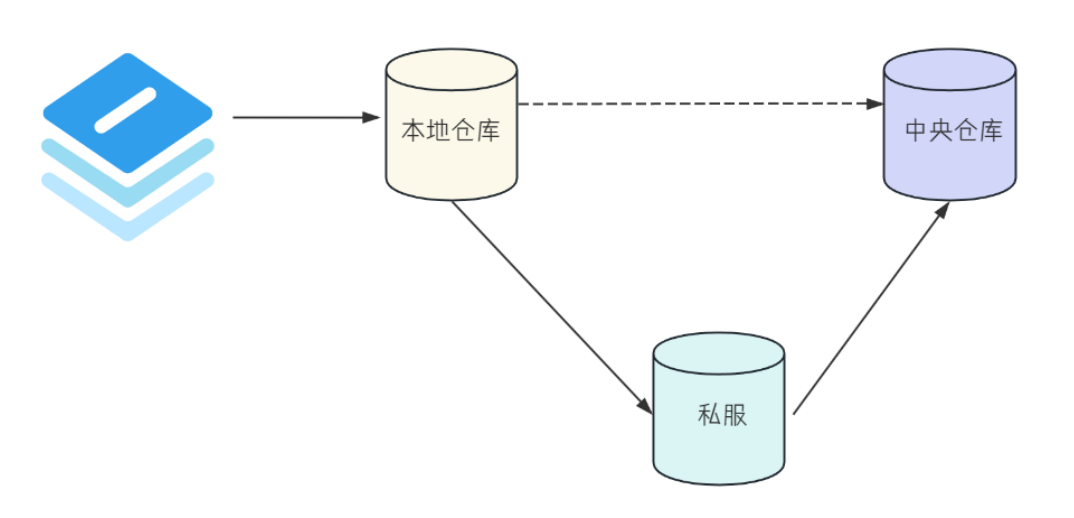
Maven 是一个项目管理工具,基于 POM(Project Object Model,项目对象模型)的概念,Maven 可以通过一小段描述信息来管理项目的构建,报告和文档的项目管理工具软件 大白话:Maven 是一个项目管理工…...

Android wifi信号和漫游信号设置
1.wifi信号 /packages/modules/Wifi/framework/java/android/net/wifi/WifiManager.java Deprecated public static int calculateSignalLevel(int rssi, int numLevels) { if (rssi < MIN_RSSI) { //*/update wifi signal return 1;…...

检查cuda和显卡的可用性
检查cuda和显卡的可用性 import torch device_gpu torch.device(cuda if torch.cuda.is_available() else cpu) print(device_gpu) print(torch.cuda.is_available())...

Kotlin:2.0.20 的新特性
一、概述 Kotlin 2.0.20英文版官方文档 Kotlin 2.0.20发布了!这个版本包括对Kotlin 2.0.0的性能改进和bug修复,我们在其中宣布Kotlin K2编译器为Stable。以下是本次发布的一些亮点: 数据类复制函数将具有与构造函数相同的可见性来自默认目标层次结构的源集的静态访…...

Python内存管理与泄漏排查实战
Python内存管理与泄漏排查实战 Python作为一种高级编程语言,因其易读性和丰富的标准库而备受开发者青睐。然而,随着项目的复杂度增加,内存管理问题可能会影响程序的性能,甚至导致内存泄漏。为了构建健壮且高效的应用程序…...

828华为云征文|华为云Flexus云服务器X实例搭建部署H5美妆护肤分销商城、前端uniapp
准备国庆之际,客户要搭个 H5 商城系统,这系统好不容易开发好啦,就差选个合适的服务器上线。那可真是挑花了眼,不知道哪款性价比高呀!就像在琳琅满目的选择前。最终慧眼识珠,选择了华为云 Flexus X。至于为什…...

初学51单片机之I2C总线与E2PROM二
总结下上篇博文的结论: 1:ACK信号在SCL为高电平期间会一直保持。 2:在字节数据传输过程中如果发送电平跳变,那么电平信号就会变成重复起始或者结束的信号。(上篇博文的测试方法还是不能够明确证明这个结论࿰…...
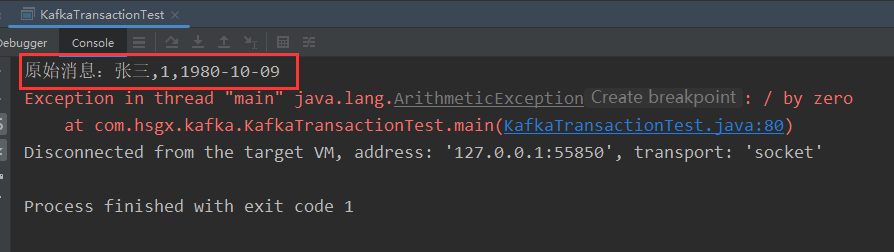
Kafka学习笔记(一)Kafka基准测试、幂等性和事务、Java编程操作Kafka
文章目录 前言4 Kafka基准测试4.1 基于1个分区1个副本的基准测试4.2 基于3个分区1个副本的基准测试4.3 基于1个分区3个副本的基准测试 5 Java编程操作Kafka5.1 引入依赖5.2 向Kafka发送消息5.3 从Kafka消费消息5.4 异步使用带有回调函数的生产消息 6 幂等性6.1 幂等性介绍6.2 K…...

结合vueuse实现图片懒加载
介绍 为什么要有懒加载? 在一个网页中如果有很多张图片,那么用户初进这个页面的时候不必一次性把所有图片都加载出来,否则容易造成卡顿和浪费。应该是,用户的视图页面滑到该图片的位置,然后再把该图片加载出来。 前置…...

Mysql数据库--聚合查询、分组查询、联合查询(不同的连接方式)
文章目录 1.查询的进阶版1.1查询搭配插入进行使用1.2聚合查询1.3group by分组查询1.4联合查询之笛卡尔积1.5左外连接,右外连接介绍join on1.6自连表 1.查询的进阶版 1.1查询搭配插入进行使用 我们首先创建两张表,一个叫做student,一个叫做student2,两个…...
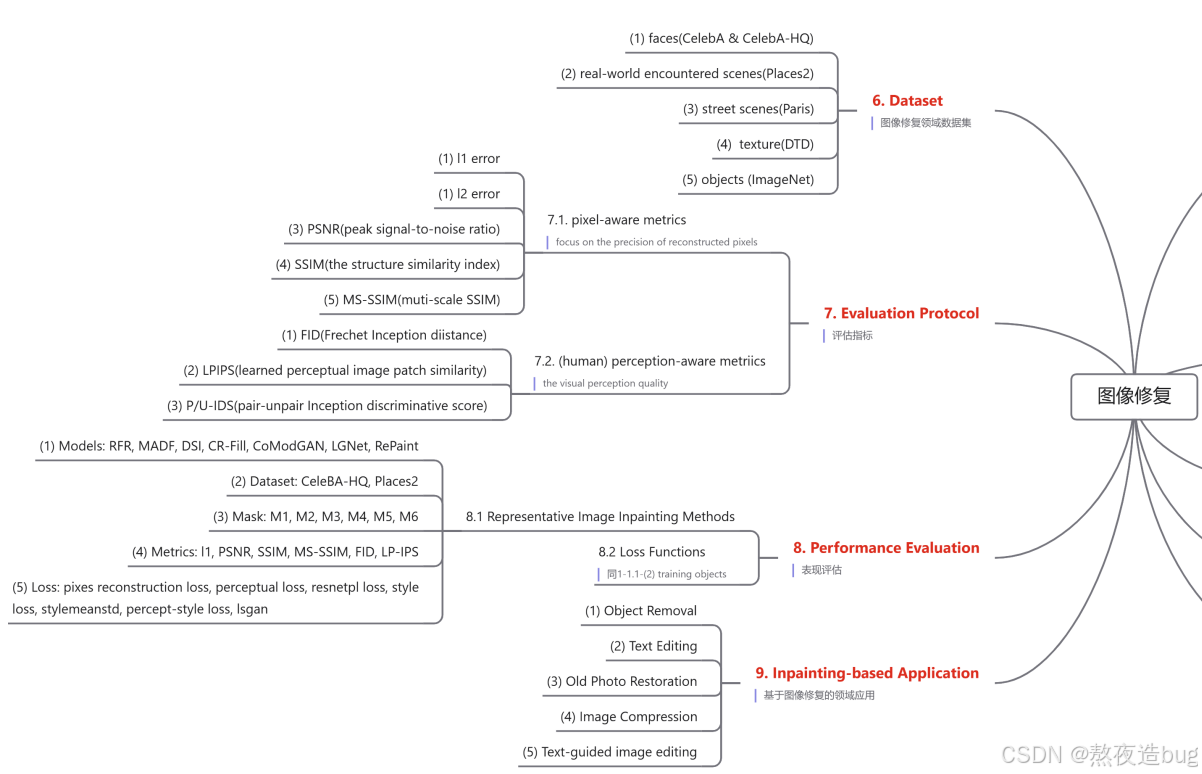
计算机视觉——图像修复综述篇
目录 1. Deterministic Image Inpainting 判别器图像修复 1.1. sigle-shot framework (1) Generators (2) training objects / Loss Functions 1.2. two-stage framework 2. Stochastic Image Inpainting 随机图像修复 2.1. VAE-based methods 2.2. GAN-based methods …...

集中式架构和分布式架构
数据是企业的核心资产和战略资源。面对爆炸性的数据增长,如何有效地组织、管理和利用数据成为企业的重大挑战。数据架构作为企业数据管理的蓝图和框架,发挥重要作用。本文就来详细说下当下主流的两种数据架构的类型。 首先明确数据架构定义:…...

Redis: 集群高可用之故障转移和集群迁移
故障转移 故障转移,包括自动故障转移和手动故障转移 1 )自动故障转移 Redis 集群,主节点挂了,从节点可以顶上来继续提供服务常用制造故障的两种方式 第一,对其中一个节点进行 SHUTDOWN 操作第二,kill 掉…...

记账软件在线、会计记账网站、财务记账官网、记账云、云记账、在线免费做账以及易舟云财务软件
记账软件在线、会计记账网站、财务记账官网、记账云、云记账、在线免费做账以及易舟云财务软件,以下是一些详细的介绍和推荐: 一、记账软件在线与会计记账网站 记账软件和会计记账网站是现代财务管理中不可或缺的工具,它们能够帮助企业或个人…...

Elasticsearch基础_3.基础操作
文章目录 一、索引操作1.1、创建索引1.2、删除索引 二、映射操作2.1、查看映射2.2、扩展映射 三、文档操作3.1、单条写入文档3.2、更新单条文档3.3、查看单条文档3.4、删除单条文档3.5、根据条件删除文档 一、索引操作 1.1、创建索引 PUT /${index_name} {"settings&quo…...

PHP永久性Cookie的含义
PHP中的永久性Cookie(也称为持久性Cookie)是指在用户的计算机上存储的一种持久性的HTTP Cookie。与常规的临时Cookie不同,永久性Cookie在浏览器关闭后依然保留,并且可以在用户下次访问该网站时被读取和使用。 主要特点 持久存储…...

CANN/asc-devkit asc_any函数
asc_any 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/ca…...

CANN Triton排序选择算子优化
Sort/Select 算子优化 【免费下载链接】cannbot-skills CANNBot 是面向 CANN 开发的用于提升开发效率的系列智能体,本仓库为其提供可复用的 Skills 模块。 项目地址: https://gitcode.com/cann/cannbot-skills 适用于需要迭代选择元素的算子:NMS、…...

3步打造高效macOS菜单栏:Hidden Bar深度使用指南
3步打造高效macOS菜单栏:Hidden Bar深度使用指南 【免费下载链接】hidden An ultra-light MacOS utility that helps hide menu bar icons 项目地址: https://gitcode.com/gh_mirrors/hi/hidden 作为macOS用户,你是否曾为菜单栏图标拥挤不堪而烦恼…...

Python点云数据处理避坑指南:pypcd与pypcd4库在Ubuntu下的安装与实战对比
Python点云数据处理避坑指南:pypcd与pypcd4库在Ubuntu下的安装与实战对比 在3D视觉、自动驾驶和机器人开发领域,点云数据处理是基础而关键的环节。Ubuntu作为主流的开发环境,配合Python生态中的pypcd和pypcd4库,为工程师提供了高…...

形转化理论SYS方程组系数推导的现状:进展、成就与挑战
作者:温沛林日期:2026年5月20日摘要形转化理论(FTT)的核心动力学内核——形转化最小赋予系统(SYS)方程组——的系数完全确定,是从一个自洽的数学框架走向可计算、可检验物理模型的关键枢纽。本文…...

我做了一个仅有 1.3 MB 的 macOS 原生 AI 助手:AskNow
我就问个问题,怎么占用我一个多G的内存! 近半年以来,我们的信息流几乎被 Agent 刷屏。 Claude Code、Codex、OpenClaw,以及各种各样的 AI 应用都在快速出现。大家都在说:AI 已经不只是聊天机器人了,现在是 …...

智能手表核心升级:三星OLED与4nm处理器如何重塑用户体验
1. 项目概述:一次旗舰智能手表核心元件的深度迭代最近看到一条关于谷歌Pixel Watch 2的消息,核心信息点很明确:屏幕将由三星供应OLED面板,同时处理器将升级到4纳米制程。这看起来只是两个硬件参数的简单罗列,但对于我们…...

告别if/else地狱:从表驱动到设计模式的代码重构实战
1. 项目概述:从“屎山”到“优雅”的代码重构之旅“优雅地优化掉这些多余的if/else”,这几乎是每个有一定经验的开发者,在接手或维护一个项目时,内心最常响起的呐喊。我见过太多代码,它们最初可能只是几个简单的条件判…...

由C++速通Lua
一.变量声明1.与C不同Lua的变量声明不需要声明类型,我们创建了一个变量就相当于声明了它,如:a10,就相当于声明了变量a。2.同时Lua中声明的变量默认都是全局变量,如果想要声明局部变量需要在声明前加上local关键字3.在L…...

HDLbits奇偶校验坑点复盘:我如何被Fsm serialdp“折磨”到发邮件问作者?
HDLbits奇偶校验坑点复盘:从状态机类型差异到调试方法论 凌晨三点,显示器上的波形依然和预期不符。这是我第七次重写Fsm serialdp的状态机代码,仿真结果中done信号始终在错误的时间点跳变。作为HDLbits的终极挑战之一,这道串口接收…...