Python内存管理与泄漏排查实战
Python内存管理与泄漏排查实战
Python作为一种高级编程语言,因其易读性和丰富的标准库而备受开发者青睐。然而,随着项目的复杂度增加,内存管理问题可能会影响程序的性能,甚至导致内存泄漏。为了构建健壮且高效的应用程序,了解Python的内存管理机制和如何排查内存泄漏至关重要。
在本篇博客中,我们将深入探讨Python的内存管理机制,分析内存泄漏的原因,介绍常用的工具和技术,并通过实际案例来演示如何排查内存泄漏问题。

Python的内存管理机制
Python的内存管理基于对象和引用计数的概念。每个对象都有一个引用计数,当对象的引用计数为0时,内存会被自动回收。Python还通过垃圾回收(Garbage Collection, GC)机制来处理循环引用的情况。
1. 引用计数
Python中每个对象都有一个引用计数器,记录了该对象被引用的次数。通过 sys.getrefcount() 方法可以查看对象的引用计数。例如:
import sysa = []
print(sys.getrefcount(a)) # 输出2
解释:这里引用计数为2,一个是我们自己创建的 a 引用,另一个是 getrefcount() 方法的参数引用。
2. 垃圾回收
当对象存在循环引用时,Python的引用计数机制无法处理这种情况。此时,Python会使用垃圾回收机制,通过标记-清除(Mark-and-Sweep)算法和分代回收(Generational Collection)来释放内存。
Python的GC模块可以通过 gc 库进行控制:
import gcgc.collect() # 手动触发垃圾回收
Python将内存分为0、1、2三代,垃圾回收器会频繁检查年轻代的对象并较少检查老年代的对象。

常见的内存泄漏原因
内存泄漏是指程序在执行过程中分配了内存,但不再需要时未能及时释放。以下是Python中常见的内存泄漏原因:
1. 循环引用
当两个或多个对象相互引用时,即使它们不再被其他对象引用,它们的引用计数也不会变为0,导致无法自动回收。
2. 全局变量
全局变量的生命周期贯穿程序的整个生命周期,如果不及时释放,可能导致内存持续占用。
3. 延迟的对象清理
某些对象如文件句柄或数据库连接没有及时关闭或释放资源,可能会占用大量内存。

内存泄漏排查工具
为了查找和解决内存泄漏问题,Python提供了多个内存分析工具:
1. tracemalloc
tracemalloc 是Python 3.4+引入的内存跟踪工具,它可以帮助开发者跟踪内存分配并确定内存使用的高峰时刻。
import tracemalloctracemalloc.start()# 执行你的代码
snapshot = tracemalloc.take_snapshot()
top_stats = snapshot.statistics('lineno')for stat in top_stats[:10]:print(stat)
2. objgraph
objgraph 是一个用于跟踪对象引用图的工具,能够帮助开发者查看对象间的引用关系,并找出循环引用。
import objgraphobjgraph.show_growth() # 查看内存中的对象增长情况
3. memory_profiler
memory_profiler 是用于分析Python程序内存使用情况的工具,可以逐行分析代码的内存消耗。
from memory_profiler import profile@profile
def my_function():a = [i for i in range(1000000)]return amy_function()

实战案例:排查内存泄漏
接下来,我们通过一个案例来演示如何使用上述工具排查内存泄漏问题。
问题描述:我们编写了一个处理大量数据的函数,该函数将数据保存在内存中处理完毕后应该释放内存,但程序运行一段时间后内存占用居高不下。
代码示例:
class DataProcessor:def __init__(self):self.cache = []def load_data(self, data):self.cache.append(data)def process_data(self):# 模拟数据处理for i in range(1000000):self.cache.append(i)def clear_cache(self):self.cache = [] # 尝试释放内存processor = DataProcessor()
processor.load_data([1, 2, 3])
processor.process_data()
processor.clear_cache()
排查步骤:
- 使用
tracemalloc进行内存跟踪
import tracemalloctracemalloc.start()processor = DataProcessor()
processor.load_data([1, 2, 3])
processor.process_data()snapshot = tracemalloc.take_snapshot()
top_stats = snapshot.statistics('lineno')for stat in top_stats[:10]:print(stat)
通过 tracemalloc,我们可以清楚地看到内存分配的位置,并找到是 process_data() 函数导致了内存泄漏。
- 使用
objgraph查看对象引用
import objgraphobjgraph.show_backrefs([processor], filename='refs.png')
生成的对象引用图显示 cache 仍然保留了对处理数据的引用,即使我们尝试清空它。
- 优化代码
我们发现问题在于 self.cache 使用了过多的内存,可以通过强制删除不必要的引用来解决问题。
class DataProcessor:def __init__(self):self.cache = []def load_data(self, data):self.cache.append(data)def process_data(self):self.cache = [i for i in range(1000000)] # 避免缓存大量数据def clear_cache(self):del self.cache[:] # 强制释放内存processor = DataProcessor()
processor.load_data([1, 2, 3])
processor.process_data()
processor.clear_cache()
通过以上修改,内存占用问题得到有效解决。

内存管理最佳实践
1. 避免循环引用
尽量避免使用循环引用。如果必须使用循环引用,记得及时解除引用,或者使用 weakref 模块管理对象。
2. 尽早释放资源
对于不再使用的对象,尽量及早释放其引用,特别是大数据结构。
3. 使用生成器处理大数据
当处理大数据时,优先使用生成器而非一次性将数据加载到内存中。生成器可以在迭代过程中动态生成数据,降低内存占用。
def data_generator():for i in range(1000000):yield i

深入分析内存泄漏场景
为了进一步了解内存泄漏的复杂性,我们可以考虑一个稍微复杂的案例,即多个类对象之间的相互引用可能导致内存泄漏。以下是一个具体的例子:
class Node:def __init__(self, value):self.value = valueself.next = Noneclass LinkedList:def __init__(self):self.head = Nonedef add_node(self, value):new_node = Node(value)if not self.head:self.head = new_nodeelse:current = self.headwhile current.next:current = current.nextcurrent.next = new_nodedef clear(self):self.head = None # 尝试释放链表节点
在这个简单的链表实现中,Node 对象通过 next 引用其他 Node 对象,而 LinkedList 则通过 head 引用链表的第一个节点。虽然调用 clear() 方法会将 head 设为 None,但如果节点间形成了循环引用,Python的引用计数机制无法自动释放内存。

使用垃圾回收器分析循环引用
虽然 gc 模块可以自动处理循环引用,但有时候我们希望手动检测循环引用以确保程序中的循环引用被正确处理。通过以下代码,我们可以使用 gc 模块来分析循环引用:
import gc# 强制进行垃圾回收
gc.collect()# 列出所有循环引用的对象
for obj in gc.garbage:print(f"循环引用对象: {obj}")
在复杂的应用程序中,可能存在更为隐蔽的循环引用问题。通过手动检查和处理这些对象,我们可以有效减少内存泄漏的风险。

优化内存管理的高级技巧
为了确保Python程序在内存管理方面表现优异,以下一些高级技巧可以帮助优化内存使用。
1. 使用 weakref 避免循环引用
对于那些必须保留引用但又不希望影响垃圾回收的对象,可以使用 weakref 模块。它允许创建不会增加引用计数的弱引用,从而避免循环引用导致的内存泄漏。
import weakrefclass Node:def __init__(self, value):self.value = valueself.next = Noneclass LinkedList:def __init__(self):self.head = Nonedef add_node(self, value):new_node = Node(value)if not self.head:self.head = weakref.ref(new_node) # 使用弱引用else:current = self.head()while current.next:current = current.nextcurrent.next = new_node
weakref 允许对象被回收,即便有其他对象引用它,也不会阻止垃圾回收器清除不再使用的对象。特别是在处理树、链表等复杂数据结构时,weakref 是避免内存泄漏的有力工具。
2. 尽量避免大量使用全局变量
全局变量在程序整个生命周期中一直存在,如果使用不当,可能导致内存持续占用。例如,可以将大型数据结构或者需要暂时保存的对象限制在函数或类方法中,避免滥用全局作用域。
# 避免使用全局变量
def process_data(data):cache = []for item in data:cache.append(item)return cache
通过将数据的生命周期限制在函数作用域内,Python可以在函数执行结束后自动回收内存,从而减少不必要的内存占用。
3. 使用生成器处理大规模数据
对于数据量巨大的场景(如处理大文件或批量数据),建议使用生成器,而不是将所有数据加载到内存中。生成器允许数据逐步生成,从而节省大量内存。
def read_large_file(file_path):with open(file_path) as file:for line in file:yield line.strip()# 使用生成器逐行处理大文件
for line in read_large_file('large_file.txt'):process(line)
生成器将数据处理分成一个个小步骤,避免一次性将所有数据加载到内存中的情况,有效减少内存占用。

性能分析与优化的工具
除了 tracemalloc、memory_profiler 和 objgraph,还有一些实用的工具能够帮助我们深入分析并优化程序的内存使用:
1. py-spy
py-spy 是一个Python性能分析器,主要用于检测应用程序的性能瓶颈,但它同样可以用来追踪内存的使用情况。它不会干扰正在运行的应用,可以直接分析生产环境中的应用性能。
py-spy top --pid <your-app-pid>
2. guppy3
guppy3 是一个Python内存分析工具,提供 Heapy 模块用于检测和分析内存的占用情况。它可以查看当前Python进程中的对象分布,找出内存泄漏的来源。
from guppy import hpyh = hpy()
heap = h.heap()
print(heap) # 打印内存使用情况
guppy3 还支持实时跟踪对象的创建和销毁,帮助开发者了解内存分配的动态变化。

总结与建议
Python的自动内存管理机制极大简化了开发者的工作,但在处理复杂数据结构、大规模数据以及长时间运行的程序时,内存泄漏问题仍然不可忽视。通过合理使用引用计数、垃圾回收以及相关工具,可以有效避免内存泄漏并优化内存使用。
以下是一些重要的建议,帮助你在实际项目中管理内存:
-
定期检测内存使用:使用
memory_profiler或tracemalloc等工具定期监测程序的内存占用情况,发现并解决潜在的内存泄漏问题。 -
避免循环引用:尽量避免复杂的数据结构之间的循环引用,或者通过
weakref来管理对象引用,防止不必要的内存占用。 -
及时释放资源:对于占用大量内存的对象,如文件句柄、大型数据结构等,应尽早释放其引用,避免不必要的内存占用。
-
使用生成器处理大数据:在处理大规模数据时,尽可能使用生成器和迭代器,以减少内存消耗。
通过对Python内存管理机制的深入理解,结合实际工具与优化技巧,可以有效地解决内存泄漏问题并优化程序性能。希望本篇博客能够为你在Python项目中处理内存管理和内存泄漏排查提供实用的参考与帮助。

相关文章:
Python内存管理与泄漏排查实战
Python内存管理与泄漏排查实战 Python作为一种高级编程语言,因其易读性和丰富的标准库而备受开发者青睐。然而,随着项目的复杂度增加,内存管理问题可能会影响程序的性能,甚至导致内存泄漏。为了构建健壮且高效的应用程序…...

828华为云征文|华为云Flexus云服务器X实例搭建部署H5美妆护肤分销商城、前端uniapp
准备国庆之际,客户要搭个 H5 商城系统,这系统好不容易开发好啦,就差选个合适的服务器上线。那可真是挑花了眼,不知道哪款性价比高呀!就像在琳琅满目的选择前。最终慧眼识珠,选择了华为云 Flexus X。至于为什…...

初学51单片机之I2C总线与E2PROM二
总结下上篇博文的结论: 1:ACK信号在SCL为高电平期间会一直保持。 2:在字节数据传输过程中如果发送电平跳变,那么电平信号就会变成重复起始或者结束的信号。(上篇博文的测试方法还是不能够明确证明这个结论࿰…...
Kafka学习笔记(一)Kafka基准测试、幂等性和事务、Java编程操作Kafka
文章目录 前言4 Kafka基准测试4.1 基于1个分区1个副本的基准测试4.2 基于3个分区1个副本的基准测试4.3 基于1个分区3个副本的基准测试 5 Java编程操作Kafka5.1 引入依赖5.2 向Kafka发送消息5.3 从Kafka消费消息5.4 异步使用带有回调函数的生产消息 6 幂等性6.1 幂等性介绍6.2 K…...

结合vueuse实现图片懒加载
介绍 为什么要有懒加载? 在一个网页中如果有很多张图片,那么用户初进这个页面的时候不必一次性把所有图片都加载出来,否则容易造成卡顿和浪费。应该是,用户的视图页面滑到该图片的位置,然后再把该图片加载出来。 前置…...

Mysql数据库--聚合查询、分组查询、联合查询(不同的连接方式)
文章目录 1.查询的进阶版1.1查询搭配插入进行使用1.2聚合查询1.3group by分组查询1.4联合查询之笛卡尔积1.5左外连接,右外连接介绍join on1.6自连表 1.查询的进阶版 1.1查询搭配插入进行使用 我们首先创建两张表,一个叫做student,一个叫做student2,两个…...
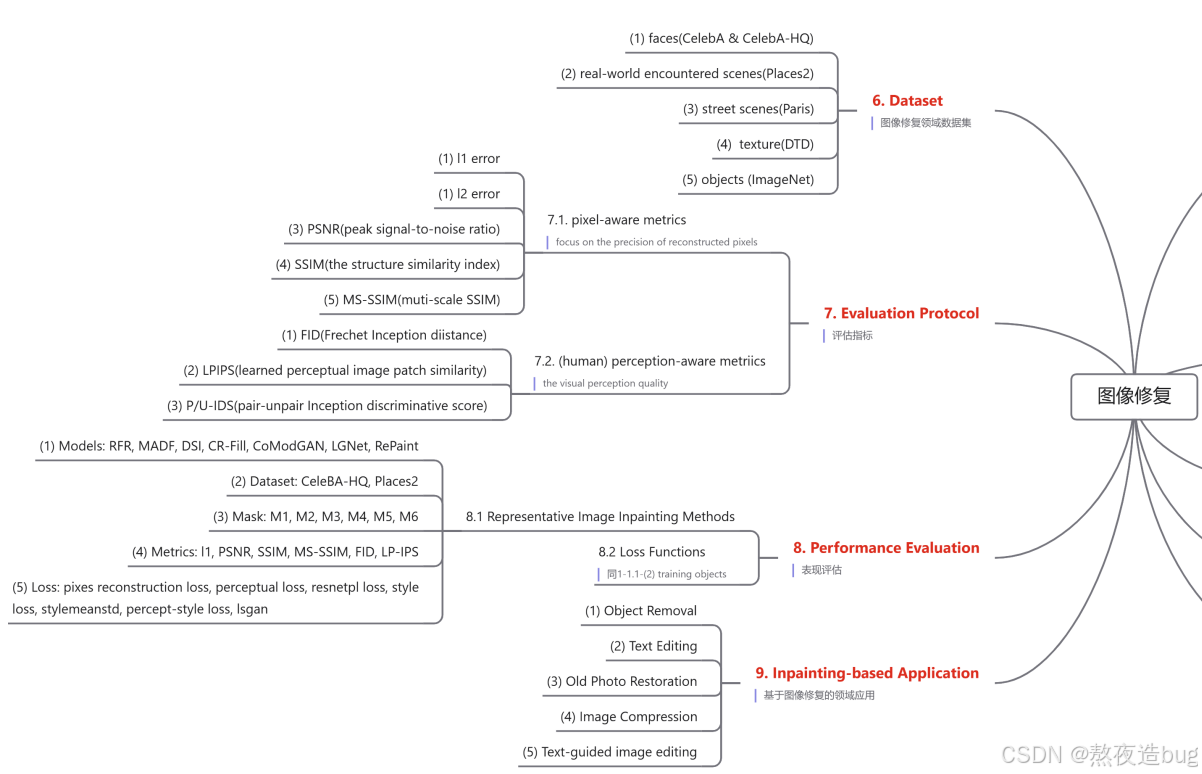
计算机视觉——图像修复综述篇
目录 1. Deterministic Image Inpainting 判别器图像修复 1.1. sigle-shot framework (1) Generators (2) training objects / Loss Functions 1.2. two-stage framework 2. Stochastic Image Inpainting 随机图像修复 2.1. VAE-based methods 2.2. GAN-based methods …...

集中式架构和分布式架构
数据是企业的核心资产和战略资源。面对爆炸性的数据增长,如何有效地组织、管理和利用数据成为企业的重大挑战。数据架构作为企业数据管理的蓝图和框架,发挥重要作用。本文就来详细说下当下主流的两种数据架构的类型。 首先明确数据架构定义:…...

Redis: 集群高可用之故障转移和集群迁移
故障转移 故障转移,包括自动故障转移和手动故障转移 1 )自动故障转移 Redis 集群,主节点挂了,从节点可以顶上来继续提供服务常用制造故障的两种方式 第一,对其中一个节点进行 SHUTDOWN 操作第二,kill 掉…...

记账软件在线、会计记账网站、财务记账官网、记账云、云记账、在线免费做账以及易舟云财务软件
记账软件在线、会计记账网站、财务记账官网、记账云、云记账、在线免费做账以及易舟云财务软件,以下是一些详细的介绍和推荐: 一、记账软件在线与会计记账网站 记账软件和会计记账网站是现代财务管理中不可或缺的工具,它们能够帮助企业或个人…...

Elasticsearch基础_3.基础操作
文章目录 一、索引操作1.1、创建索引1.2、删除索引 二、映射操作2.1、查看映射2.2、扩展映射 三、文档操作3.1、单条写入文档3.2、更新单条文档3.3、查看单条文档3.4、删除单条文档3.5、根据条件删除文档 一、索引操作 1.1、创建索引 PUT /${index_name} {"settings&quo…...

PHP永久性Cookie的含义
PHP中的永久性Cookie(也称为持久性Cookie)是指在用户的计算机上存储的一种持久性的HTTP Cookie。与常规的临时Cookie不同,永久性Cookie在浏览器关闭后依然保留,并且可以在用户下次访问该网站时被读取和使用。 主要特点 持久存储…...

瑜伽培训行业为何要搭建自己的专属知识付费小程序平台?集师知识付费系统 集师知识付费小程序 集师知识服务系统 集师线上培训系统
在当今快节奏的生活中,瑜伽作为一种舒缓压力、增强体质的生活方式,受到了越来越多人的青睐。瑜伽培训行业也随之蓬勃发展,但如何在激烈的市场竞争中脱颖而出,成为众多瑜伽培训机构面临的一大挑战。搭建自己的专属知识付费小程序平…...

FFT 分析进阶-笔记
FFT 分析进阶 边界不连续与泄漏效应解决方法增加窗函数海宁窗与哈布什窗混叠效应频率高到什么程度会出现混叠现象呢?那我们有办法去应对这个混叠吗?经典平均指数平均关于结果的显示模式FFT计算的三个常见的范例计算FFT图谱中某一段的总值,图中…...
毕业设计_基于springboot+layui+mybatisPlus的中小型仓库物流管理系统源码+SQL+教程+可运行】41004
毕业设计_基于springbootlayuimybatisPlus的中小型仓库物流管理系统源码SQL教程可运行】41004 下载地址: https://download.csdn.net/download/qq_24428851/89843203 技术栈 后端:springboot、mybatis-plus、shiro 前端:layUI 存储&…...

ROS基础入门——实操教程
ROS基础入门——实操教程 前言 本教程实操为主,少说书。可供参考的文档中详细的记录了ROS的实操和理论,只是过于详细繁杂了,看得脑壳疼,于是做了这个笔记。 Ruby Rose,放在这里相当合理 本文初编辑于2024年10月4日 C…...

etcd 快速入门
简介 随着go与kubernetes的大热,etcd作为一个基于go编写的分布式键值存储,逐渐为开发者所熟知,尤其是其还作为kubernetes的数据存储仓库,更是引起广泛专注。 本文我们就来聊一聊etcd到底是什么及其工作机制。 首先,…...

Spring MVC__HttpMessageConverter、拦截器、异常处理器、注解配置SpringMVC、SpringMVC执行流程
目录 一、HttpMessageConverter1、RequestBody2、RequestEntity3、ResponseBody4、SpringMVC处理json5、SpringMVC处理ajax6、RestController注解7、ResponseEntity7.1、文件下载7.2、文件上传 二、拦截器1、拦截器的配置2、拦截器的三个抽象方法3、多个拦截器的执行顺序 三、异…...

GAMES101(19节,相机)
相机 synthesis合成成像:比如光栅化,光线追踪,相机是capture捕捉成像, 但是在合成渲染时,有时也会模拟捕捉成像方式(包括一些技术 动态模糊 / 景深等),这时会有涉及很多专有名词&a…...

Django Nginx+uwsgi 安装配置
Django Nginx+uwsgi 安装配置 本文将详细介绍如何在Linux环境下安装和配置Django应用程序,使用Nginx作为Web服务器和uwsgi作为应用程序服务器。我们将覆盖以下主题: 安装Python和相关库安装和配置Django安装Nginx安装和配置uwsgi配置Nginx以使用uwsgi测试和调试1. 安装Pytho…...

AI嵌入式系统测试:融合经典方法与数据驱动验证的工程实践
1. 项目概述:当嵌入式遇见AI,测试的“变”与“不变”干了十几年嵌入式,从8位单片机玩到多核异构处理器,从裸机编程干到复杂的RTOS,我原以为测试这件事,左不过就是单元测试、集成测试、系统测试那几板斧&…...

CANN/asc-devkit __hgtux2函数
__hgtux2 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://gitcode.com/c…...

TVBOX最新电视直播软件tv版下载与安装教程
如何安装最新版电视直播软件tv版TVBOX?先讲清楚:TVBox 是开源播放器,本身不带影视资源,装好后必须配置 “数据源 / 接口” 才能用。下面分「下载 → 安装 → 配置 → 常见问题」一步步来。(如果不会配置,可…...

2026年降AI工具万方检测专项测试:五款工具万方AIGC检测通过率完整横评
2026年降AI工具万方检测专项测试:五款工具万方AIGC检测通过率完整横评 选工具之前做了一周功课,试用了三款,最后定了嘎嘎降AI(www.aigcleaner.com)。 4.8元,知网AI率从61%降到了5.3%,达标率99…...
)
哨兵1号数据处理必备:如何搞定精密轨道文件和SRTM DEM数据(最新可用链接)
哨兵1号数据处理实战:精密轨道与SRTM DEM数据获取全指南 对于从事InSAR或时序分析的遥感研究者而言,数据预处理阶段的轨道校正和地形相位去除是决定成果精度的关键步骤。本文将聚焦哨兵1号SAR数据处理中最核心的两类辅助数据——精密轨道文件和SRTM DEM&…...

创业团队如何通过Taotoken统一管理AI开发资源与成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 创业团队如何通过Taotoken统一管理AI开发资源与成本 对于资源有限的创业团队而言,在早期产品原型开发与测试阶段&#…...

从RoPE到Retention:一文拆解RetNet如何用‘旋转’和‘衰减’重塑序列建模
RetNet技术解析:如何用旋转与衰减机制突破Transformer的局限 当ChatGPT掀起大语言模型浪潮时,Transformer架构已成为AI领域的基石。然而,其平方级计算复杂度带来的高推理成本,始终是工业界难以回避的痛点。微软与清华大学联合提出…...

RV1106开发板WiFi配置全攻略:从AP模式到STA模式,手把手教你搞定网络连接
RV1106开发板WiFi配置全攻略:从AP模式到STA模式,手把手教你搞定网络连接 刚拿到RV1106开发板时,最让人头疼的莫过于WiFi配置了。这块嵌入式开发板在网络连接上有着独特的配置逻辑,尤其是AP(接入点)和STA&am…...
)
别再只用BackgroundImage了!C# WinForm窗体背景图5种方法全解析(含PictureBox与资源文件实战)
别再只用BackgroundImage了!C# WinForm窗体背景图5种方法全解析 当我们需要为WinForm窗体添加背景图时,很多开发者会条件反射地使用BackgroundImage属性。这种习惯性选择虽然简单,但在实际项目中可能会遇到性能瓶颈、内存泄漏或适配问题。本文…...

10分钟打造专属AI歌手:Retrieval-based-Voice-Conversion-WebUI语音克隆终极指南
10分钟打造专属AI歌手:Retrieval-based-Voice-Conversion-WebUI语音克隆终极指南 【免费下载链接】Retrieval-based-Voice-Conversion-WebUI Easily train a good VC model with voice data < 10 mins! 项目地址: https://gitcode.com/GitHub_Trending/re/Retr…...