关于数据同步工具DataX部署
1.DataX简介
1.1 DataX概述
DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。
源码地址:GitHub - alibaba/DataX: DataX是阿里云DataWorks数据集成的开源版本。
1.2 DataX支持的数据源
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图。
| 类型 | 数据源 | Reader(读) | Writer(写) |
| RDBMS 关系型数据库 | MySQL | √ | √ |
| Oracle | √ | √ | |
| OceanBase | √ | √ | |
| SQLServer | √ | √ | |
| PostgreSQL | √ | √ | |
| DRDS | √ | √ | |
| 通用RDBMS | √ | √ | |
| 阿里云数仓数据存储 | ODPS | √ | √ |
| ADS | √ | ||
| OSS | √ | √ | |
| OCS | √ | √ | |
| NoSQL数据存储 | OTS | √ | √ |
| Hbase0.94 | √ | √ | |
| Hbase1.1 | √ | √ | |
| Phoenix4.x | √ | √ | |
| Phoenix5.x | √ | √ | |
| MongoDB | √ | √ | |
| Hive | √ | √ | |
| Cassandra | √ | √ | |
| 无结构化数据存储 | TxtFile | √ | √ |
| FTP | √ | √ | |
| HDFS | √ | √ | |
| Elasticsearch | √ | ||
| 时间序列数据库 | OpenTSDB | √ | |
| TSDB | √ | √ |
2. DataX 架构原理
2.1 DataX设计理念
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。

2.2 DataX框架设计
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。
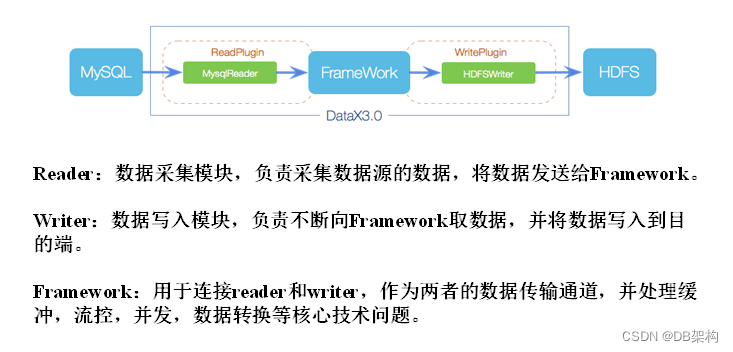
2.3 DataX运行流程
下面用一个DataX作业生命周期的时序图说明DataX的运行流程、核心概念以及每个概念之间的关系。

2.4 DataX调度决策思路
举例来说,用户提交了一个DataX作业,并且配置了总的并发度为20,目的是对一个有100张分表的mysql数据源进行同步。DataX的调度决策思路是:
1)DataX Job根据分库分表切分策略,将同步工作分成100个Task。
2)根据配置的总的并发度20,以及每个Task Group的并发度5,DataX计算共需要分配4个TaskGroup。
3)4个TaskGroup平分100个Task,每一个TaskGroup负责运行25个Task。
2.5 DataX与Sqoop对比
| 功能 | DataX | Sqoop |
| 运行模式 | 单进程多线程 | MR |
| 分布式 | 不支持,可以通过调度系统规避 | 支持 |
| 流控 | 有流控功能 | 需要定制 |
| 统计信息 | 已有一些统计,上报需定制 | 没有,分布式的数据收集不方便 |
| 数据校验 | 在core部分有校验功能 | 没有,分布式的数据收集不方便 |
| 监控 | 需要定制 | 需要定制 |
3. DataX 部署
1)下载DataX安装包并上传到hadoop102的/opt/software

下载地址:http://datax-opensource.oss-cn-hangzhou.aliyuncs.com/datax.tar.gz
2)解压datax.tar.gz到/opt/module
[maxwell@hadoop102 software]$ tar -zxvf datax.tar.gz -C /opt/module/
3)自检,执行如下命令
[maxwell@hadoop102 ~]$ python /opt/module/datax/bin/datax.py /opt/module/datax/job/job.jsonDataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.2023-03-28 12:56:58.652 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2023-03-28 12:56:58.669 [main] INFO Engine - the machine info => osInfo: Oracle Corporation 1.8 25.212-b10jvmInfo: Linux amd64 3.10.0-862.el7.x86_64cpu num: 2totalPhysicalMemory: -0.00GfreePhysicalMemory: -0.00GmaxFileDescriptorCount: -1currentOpenFileDescriptorCount: -1GC Names [PS MarkSweep, PS Scavenge]MEMORY_NAME | allocation_size | init_size PS Eden Space | 256.00MB | 256.00MB Code Cache | 240.00MB | 2.44MB Compressed Class Space | 1,024.00MB | 0.00MB PS Survivor Space | 42.50MB | 42.50MB PS Old Gen | 683.00MB | 683.00MB Metaspace | -0.00MB | 0.00MB 2023-03-28 12:56:58.712 [main] INFO Engine -
{"content":[{"reader":{"name":"streamreader","parameter":{"column":[{"type":"string","value":"DataX"},{"type":"long","value":19890604},{"type":"date","value":"1989-06-04 00:00:00"},{"type":"bool","value":true},{"type":"bytes","value":"test"}],"sliceRecordCount":100000}},"writer":{"name":"streamwriter","parameter":{"encoding":"UTF-8","print":false}}}],"setting":{"errorLimit":{"percentage":0.02,"record":0},"speed":{"byte":10485760}}
}2023-03-28 12:56:58.775 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2023-03-28 12:56:58.777 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2023-03-28 12:56:58.777 [main] INFO JobContainer - DataX jobContainer starts job.
2023-03-28 12:56:58.780 [main] INFO JobContainer - Set jobId = 0
2023-03-28 12:56:58.860 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2023-03-28 12:56:58.861 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] do prepare work .
2023-03-28 12:56:58.861 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do prepare work .
2023-03-28 12:56:58.861 [job-0] INFO JobContainer - jobContainer starts to do split ...
2023-03-28 12:56:58.873 [job-0] INFO JobContainer - Job set Max-Byte-Speed to 10485760 bytes.
2023-03-28 12:56:58.874 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] splits to [1] tasks.
2023-03-28 12:56:58.874 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] splits to [1] tasks.
2023-03-28 12:56:58.908 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2023-03-28 12:56:58.911 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2023-03-28 12:56:58.919 [job-0] INFO JobContainer - Running by standalone Mode.
2023-03-28 12:56:58.969 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.
2023-03-28 12:56:59.015 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.
2023-03-28 12:56:59.015 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2023-03-28 12:56:59.051 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
2023-03-28 12:56:59.152 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[106]ms
2023-03-28 12:56:59.153 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2023-03-28 12:57:09.074 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.041s | All Task WaitReaderTime 0.060s | Percentage 100.00%
2023-03-28 12:57:09.074 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2023-03-28 12:57:09.074 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do post work.
2023-03-28 12:57:09.075 [job-0] INFO JobContainer - DataX Reader.Job [streamreader] do post work.
2023-03-28 12:57:09.075 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2023-03-28 12:57:09.079 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /opt/module/datax/hook
2023-03-28 12:57:09.080 [job-0] INFO JobContainer - [total cpu info] => averageCpu | maxDeltaCpu | minDeltaCpu -1.00% | -1.00% | -1.00%[total gc info] => NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime PS MarkSweep | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s PS Scavenge | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s 2023-03-28 12:57:09.081 [job-0] INFO JobContainer - PerfTrace not enable!
2023-03-28 12:57:09.081 [job-0] INFO StandAloneJobContainerCommunicator - Total 100000 records, 2600000 bytes | Speed 253.91KB/s, 10000 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.041s | All Task WaitReaderTime 0.060s | Percentage 100.00%
2023-03-28 12:57:09.082 [job-0] INFO JobContainer -
任务启动时刻 : 2023-03-28 12:56:58
任务结束时刻 : 2023-03-28 12:57:09
任务总计耗时 : 10s
任务平均流量 : 253.91KB/s
记录写入速度 : 10000rec/s
读出记录总数 : 100000
读写失败总数 : 0[maxwell@hadoop102 ~]$ 上述执行结果表明执行成功。
4. DataX使用
4.1 DataX使用概述
4.1.1 DataX任务提交命令
DataX的使用十分简单,用户只需根据自己同步数据的数据源和目的地选择相应的Reader和Writer,并将Reader和Writer的信息配置在一个json文件中,然后执行如下命令提交数据同步任务即可。
[maxwell@hadoop102 datax]$ python bin/datax.py path/to/your/job.json4.2.2 DataX配置文件格式
可以使用如下命名查看DataX配置文件模板。
[maxwell@hadoop102 datax]$ python bin/datax.py -r mysqlreader -w hdfswriterDataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.Please refer to the mysqlreader document:https://github.com/alibaba/DataX/blob/master/mysqlreader/doc/mysqlreader.md Please refer to the hdfswriter document:https://github.com/alibaba/DataX/blob/master/hdfswriter/doc/hdfswriter.md Please save the following configuration as a json file and usepython {DATAX_HOME}/bin/datax.py {JSON_FILE_NAME}.json
to run the job.{"job": {"content": [{"reader": {"name": "mysqlreader", "parameter": {"column": [], "connection": [{"jdbcUrl": [], "table": []}], "password": "", "username": "", "where": ""}}, "writer": {"name": "hdfswriter", "parameter": {"column": [], "compress": "", "defaultFS": "", "fieldDelimiter": "", "fileName": "", "fileType": "", "path": "", "writeMode": ""}}}], "setting": {"speed": {"channel": ""}}}
}
[maxwell@hadoop102 datax]$配置文件模板如下,json最外层是一个job,job包含setting和content两部分,其中setting用于对整个job进行配置,content用户配置数据源和目的地。

Reader和Writer的具体参数可参考官方文档,地址如下:
DataX/README.md at master · alibaba/DataX · GitHub
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| Kingbase | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADB | √ | 写 | ||
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | 写 | ||
| Hologres | √ | 写 | ||
| AnalyticDB For PostgreSQL | √ | 写 | ||
| 阿里云中间件 | datahub | √ | √ | 读 、写 |
| SLS | √ | √ | 读 、写 | |
| 阿里云图数据库 | GDB | √ | √ | 读 、写 |
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| Phoenix5.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Cassandra | √ | √ | 读 、写 | |
| 数仓数据存储 | StarRocks | √ | √ | 读 、写 |
| ApacheDoris | √ | 写 | ||
| ClickHouse | √ | 写 | ||
| Databend | √ | 写 | ||
| Hive | √ | √ | 读 、写 | |
| kudu | √ | 写 | ||
| selectdb | √ | 写 | ||
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| TSDB | √ | √ | 读 、写 | |
| TDengine | √ | √ | 读 、写 |
4.2 同步MySQL数据到HDFS案例
案例要求:同步gmall数据库中base_province表数据到HDFS的/base_province目录
需求分析:要实现该功能,需选用MySQLReader和HDFSWriter,MySQLReader具有两种模式分别是TableMode和QuerySQLMode,前者使用table,column,where等属性声明需要同步的数据;后者使用一条SQL查询语句声明需要同步的数据。
4.2.1 MySQLReader之TableMode
1)编写配置文件
(1)创建配置文件base_province.json
[maxwell@hadoop102 ~]$ vim /opt/module/datax/job/base_province.json(2)配置文件内容如下
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": ["id","name","region_id","area_code","iso_code","iso_3166_2"],"where": "id>=3","connection": [{"jdbcUrl": ["jdbc:mysql://hadoop102:3306/gmall"],"table": ["base_province"]}],"password": "XXXXXXX","splitPk": "","username": "root"}},"writer": {"name": "hdfswriter","parameter": {"column": [{"name": "id","type": "bigint"},{"name": "name","type": "string"},{"name": "region_id","type": "string"},{"name": "area_code","type": "string"},{"name": "iso_code","type": "string"},{"name": "iso_3166_2","type": "string"}],"compress": "gzip","defaultFS": "hdfs://hadoop102:8020","fieldDelimiter": "\t","fileName": "base_province","fileType": "text","path": "/base_province","writeMode": "append"}}}],"setting": {"speed": {"channel": 1}}}
}
2)配置文件说明
(1)Reader参数说明

(2)Writer参数说明

注意事项:
HFDS Writer并未提供nullFormat参数:也就是用户并不能自定义null值写到HFDS文件中的存储格式。默认情况下,HFDS Writer会将null值存储为空字符串(''),而Hive默认的null值存储格式为\N。所以后期将DataX同步的文件导入Hive表就会出现问题。
解决该问题的方案有两个:
一是修改DataX HDFS Writer的源码,增加自定义null值存储格式的逻辑,可参考记Datax3.0解决MySQL抽数到HDFSNULL变为空字符的问题_datax nullformat_谭正强的博客-CSDN博客。
二是在Hive中建表时指定null值存储格式为空字符串(''),例如:
DROP TABLE IF EXISTS base_province;
CREATE EXTERNAL TABLE base_province
(`id` STRING COMMENT '编号',`name` STRING COMMENT '省份名称',`region_id` STRING COMMENT '地区ID',`area_code` STRING COMMENT '地区编码',`iso_code` STRING COMMENT '旧版ISO-3166-2编码,供可视化使用',`iso_3166_2` STRING COMMENT '新版IOS-3166-2编码,供可视化使用'
) COMMENT '省份表'ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t'NULL DEFINED AS ''LOCATION '/base_province/';
(3)Setting参数说明

3)提交任务
(1)在HDFS创建/base_province目录
使用DataX向HDFS同步数据时,需确保目标路径已存在
[maxwell@hadoop102 datax]$ hadoop fs -mkdir /base_province
(2)进入DataX根目录
[maxwell@hadoop102 datax]$ cd /opt/module/datax (3)执行如下命令
[maxwell@hadoop102 datax]$ python bin/datax.py job/base_province.jsonDataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.2023-03-28 14:13:09.610 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2023-03-28 14:13:09.615 [main] INFO Engine - the machine info => osInfo: Oracle Corporation 1.8 25.212-b10jvmInfo: Linux amd64 3.10.0-862.el7.x86_64cpu num: 2totalPhysicalMemory: -0.00GfreePhysicalMemory: -0.00GmaxFileDescriptorCount: -1currentOpenFileDescriptorCount: -1GC Names [PS MarkSweep, PS Scavenge]MEMORY_NAME | allocation_size | init_size PS Eden Space | 256.00MB | 256.00MB Code Cache | 240.00MB | 2.44MB Compressed Class Space | 1,024.00MB | 0.00MB PS Survivor Space | 42.50MB | 42.50MB PS Old Gen | 683.00MB | 683.00MB Metaspace | -0.00MB | 0.00MB 2023-03-28 14:13:09.632 [main] INFO Engine -
{"content":[{"reader":{"name":"mysqlreader","parameter":{"column":["id","name","region_id","area_code","iso_code","iso_3166_2"],"connection":[{"jdbcUrl":["jdbc:mysql://hadoop102:3306/gmall"],"table":["base_province"]}],"password":"*********","splitPk":"","username":"root","where":"id>=3"}},"writer":{"name":"hdfswriter","parameter":{"column":[{"name":"id","type":"bigint"},{"name":"name","type":"string"},{"name":"region_id","type":"string"},{"name":"area_code","type":"string"},{"name":"iso_code","type":"string"},{"name":"iso_3166_2","type":"string"}],"compress":"gzip","defaultFS":"hdfs://hadoop102:8020","fieldDelimiter":"\t","fileName":"base_province","fileType":"text","path":"/base_province","writeMode":"append"}}}],"setting":{"speed":{"channel":1}}
}2023-03-28 14:13:09.650 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2023-03-28 14:13:09.652 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2023-03-28 14:13:09.652 [main] INFO JobContainer - DataX jobContainer starts job.
2023-03-28 14:13:09.654 [main] INFO JobContainer - Set jobId = 0
2023-03-28 14:13:09.978 [job-0] INFO OriginalConfPretreatmentUtil - Available jdbcUrl:jdbc:mysql://hadoop102:3306/gmall?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true.
2023-03-28 14:13:09.996 [job-0] INFO OriginalConfPretreatmentUtil - table:[base_province] has columns:[id,name,region_id,area_code,iso_code,iso_3166_2].
Mar 28, 2023 2:13:10 PM org.apache.hadoop.util.NativeCodeLoader <clinit>
WARNING: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2023-03-28 14:13:11.825 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2023-03-28 14:13:11.825 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do prepare work .
2023-03-28 14:13:11.825 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] do prepare work .
2023-03-28 14:13:12.047 [job-0] INFO HdfsWriter$Job - 由于您配置了writeMode append, 写入前不做清理工作, [/base_province] 目录下写入相应文件名前缀 [base_province] 的文件
2023-03-28 14:13:12.047 [job-0] INFO JobContainer - jobContainer starts to do split ...
2023-03-28 14:13:12.047 [job-0] INFO JobContainer - Job set Channel-Number to 1 channels.
2023-03-28 14:13:12.062 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] splits to [1] tasks.
2023-03-28 14:13:12.062 [job-0] INFO HdfsWriter$Job - begin do split...
2023-03-28 14:13:12.075 [job-0] INFO HdfsWriter$Job - splited write file name:[hdfs://hadoop102:8020/base_province__599ea3d1_6d79_44aa_9f44_4148f782a4f8/base_province__564114a7_fd6b_4598_a234_460255d27677]
2023-03-28 14:13:12.075 [job-0] INFO HdfsWriter$Job - end do split.
2023-03-28 14:13:12.075 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] splits to [1] tasks.
2023-03-28 14:13:12.130 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2023-03-28 14:13:12.194 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2023-03-28 14:13:12.197 [job-0] INFO JobContainer - Running by standalone Mode.
2023-03-28 14:13:12.224 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.
2023-03-28 14:13:12.256 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.
2023-03-28 14:13:12.256 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2023-03-28 14:13:12.296 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
2023-03-28 14:13:12.335 [0-0-0-reader] INFO CommonRdbmsReader$Task - Begin to read record by Sql: [select id,name,region_id,area_code,iso_code,iso_3166_2 from base_province where (id>=3)
] jdbcUrl:[jdbc:mysql://hadoop102:3306/gmall?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].
2023-03-28 14:13:12.344 [0-0-0-writer] INFO HdfsWriter$Task - begin do write...
2023-03-28 14:13:12.344 [0-0-0-writer] INFO HdfsWriter$Task - write to file : [hdfs://hadoop102:8020/base_province__599ea3d1_6d79_44aa_9f44_4148f782a4f8/base_province__564114a7_fd6b_4598_a234_460255d27677]
2023-03-28 14:13:12.516 [0-0-0-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select id,name,region_id,area_code,iso_code,iso_3166_2 from base_province where (id>=3)
] jdbcUrl:[jdbc:mysql://hadoop102:3306/gmall?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].
2023-03-28 14:13:13.387 [0-0-0-writer] INFO HdfsWriter$Task - end do write
2023-03-28 14:13:13.461 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[1179]ms
2023-03-28 14:13:13.462 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2023-03-28 14:13:22.266 [job-0] INFO StandAloneJobContainerCommunicator - Total 32 records, 667 bytes | Speed 66B/s, 3 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-03-28 14:13:22.266 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2023-03-28 14:13:22.267 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] do post work.
2023-03-28 14:13:22.267 [job-0] INFO HdfsWriter$Job - start rename file [hdfs://hadoop102:8020/base_province__599ea3d1_6d79_44aa_9f44_4148f782a4f8/base_province__564114a7_fd6b_4598_a234_460255d27677.gz] to file [hdfs://hadoop102:8020/base_province/base_province__564114a7_fd6b_4598_a234_460255d27677.gz].
2023-03-28 14:13:22.317 [job-0] INFO HdfsWriter$Job - finish rename file [hdfs://hadoop102:8020/base_province__599ea3d1_6d79_44aa_9f44_4148f782a4f8/base_province__564114a7_fd6b_4598_a234_460255d27677.gz] to file [hdfs://hadoop102:8020/base_province/base_province__564114a7_fd6b_4598_a234_460255d27677.gz].
2023-03-28 14:13:22.318 [job-0] INFO HdfsWriter$Job - start delete tmp dir [hdfs://hadoop102:8020/base_province__599ea3d1_6d79_44aa_9f44_4148f782a4f8] .
2023-03-28 14:13:22.402 [job-0] INFO HdfsWriter$Job - finish delete tmp dir [hdfs://hadoop102:8020/base_province__599ea3d1_6d79_44aa_9f44_4148f782a4f8] .
2023-03-28 14:13:22.402 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do post work.
2023-03-28 14:13:22.402 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2023-03-28 14:13:22.403 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /opt/module/datax/hook
2023-03-28 14:13:22.505 [job-0] INFO JobContainer - [total cpu info] => averageCpu | maxDeltaCpu | minDeltaCpu -1.00% | -1.00% | -1.00%[total gc info] => NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime PS MarkSweep | 1 | 1 | 1 | 0.039s | 0.039s | 0.039s PS Scavenge | 1 | 1 | 1 | 0.021s | 0.021s | 0.021s 2023-03-28 14:13:22.505 [job-0] INFO JobContainer - PerfTrace not enable!
2023-03-28 14:13:22.506 [job-0] INFO StandAloneJobContainerCommunicator - Total 32 records, 667 bytes | Speed 66B/s, 3 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-03-28 14:13:22.507 [job-0] INFO JobContainer -
任务启动时刻 : 2023-03-28 14:13:09
任务结束时刻 : 2023-03-28 14:13:22
任务总计耗时 : 12s
任务平均流量 : 66B/s
记录写入速度 : 3rec/s
读出记录总数 : 32
读写失败总数 : 0[maxwell@hadoop102 datax]$ 4)查看结果
(1)DataX打印日志

(2)查看HDFS文件
[maxwell@hadoop102 datax]$ hadoop fs -cat /base_province/* | zcat
2023-03-28 14:15:50,686 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
3 山西 1 140000 CN-14 CN-SX
4 内蒙古 1 150000 CN-15 CN-NM
5 河北 1 130000 CN-13 CN-HE
6 上海 2 310000 CN-31 CN-SH
7 江苏 2 320000 CN-32 CN-JS
8 浙江 2 330000 CN-33 CN-ZJ
9 安徽 2 340000 CN-34 CN-AH
10 福建 2 350000 CN-35 CN-FJ
11 江西 2 360000 CN-36 CN-JX
12 山东 2 370000 CN-37 CN-SD
14 台湾 2 710000 CN-71 CN-TW
15 黑龙江 3 230000 CN-23 CN-HL
16 吉林 3 220000 CN-22 CN-JL
17 辽宁 3 210000 CN-21 CN-LN
18 陕西 7 610000 CN-61 CN-SN
19 甘肃 7 620000 CN-62 CN-GS
20 青海 7 630000 CN-63 CN-QH
21 宁夏 7 640000 CN-64 CN-NX
22 新疆 7 650000 CN-65 CN-XJ
23 河南 4 410000 CN-41 CN-HA
24 湖北 4 420000 CN-42 CN-HB
25 湖南 4 430000 CN-43 CN-HN
26 广东 5 440000 CN-44 CN-GD
27 广西 5 450000 CN-45 CN-GX
28 海南 5 460000 CN-46 CN-HI
29 香港 5 810000 CN-91 CN-HK
30 澳门 5 820000 CN-92 CN-MO
31 四川 6 510000 CN-51 CN-SC
32 贵州 6 520000 CN-52 CN-GZ
33 云南 6 530000 CN-53 CN-YN
13 重庆 6 500000 CN-50 CN-CQ
34 西藏 6 540000 CN-54 CN-XZ
[maxwell@hadoop102 datax]$ 4.2.2 MySQLReader之QuerySQLMode
1)编写配置文件
(1)修改配置文件base_province.json
[maxwell@hadoop102 ~]$ vim /opt/module/datax/job/base_province_sql.json(2)配置文件内容如下
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"connection": [{"jdbcUrl": ["jdbc:mysql://hadoop102:3306/gmall"],"querySql": ["select id,name,region_id,area_code,iso_code,iso_3166_2 from base_province where id>=3"]}],"password": "XXXXXXXX","username": "root"}},"writer": {"name": "hdfswriter","parameter": {"column": [{"name": "id","type": "bigint"},{"name": "name","type": "string"},{"name": "region_id","type": "string"},{"name": "area_code","type": "string"},{"name": "iso_code","type": "string"},{"name": "iso_3166_2","type": "string"}],"compress": "gzip","defaultFS": "hdfs://hadoop102:8020","fieldDelimiter": "\t","fileName": "base_province","fileType": "text","path": "/base_province","writeMode": "append"}}}],"setting": {"speed": {"channel": 1}}}
}2)配置文件说明
(1)Reader参数说明

3)提交任务
(1)清空历史数据
[maxwell@hadoop102 datax]$ hadoop fs -rm -r -f /base_province/*(2)进入DataX根目录
[maxwell@hadoop102 datax]$ cd /opt/module/datax (3)执行如下命令
[maxwell@hadoop102 datax]$ python bin/datax.py job/base_province_sql.jsonDataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.2023-03-28 14:57:22.029 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2023-03-28 14:57:22.040 [main] INFO Engine - the machine info => osInfo: Oracle Corporation 1.8 25.212-b10jvmInfo: Linux amd64 3.10.0-862.el7.x86_64cpu num: 2totalPhysicalMemory: -0.00GfreePhysicalMemory: -0.00GmaxFileDescriptorCount: -1currentOpenFileDescriptorCount: -1GC Names [PS MarkSweep, PS Scavenge]MEMORY_NAME | allocation_size | init_size PS Eden Space | 256.00MB | 256.00MB Code Cache | 240.00MB | 2.44MB Compressed Class Space | 1,024.00MB | 0.00MB PS Survivor Space | 42.50MB | 42.50MB PS Old Gen | 683.00MB | 683.00MB Metaspace | -0.00MB | 0.00MB 2023-03-28 14:57:22.075 [main] INFO Engine -
{"content":[{"reader":{"name":"mysqlreader","parameter":{"connection":[{"jdbcUrl":["jdbc:mysql://hadoop102:3306/gmall"],"querySql":["select id,name,region_id,area_code,iso_code,iso_3166_2 from base_province where id>=3"]}],"password":"*********","username":"root"}},"writer":{"name":"hdfswriter","parameter":{"column":[{"name":"id","type":"bigint"},{"name":"name","type":"string"},{"name":"region_id","type":"string"},{"name":"area_code","type":"string"},{"name":"iso_code","type":"string"},{"name":"iso_3166_2","type":"string"}],"compress":"gzip","defaultFS":"hdfs://hadoop102:8020","fieldDelimiter":"\t","fileName":"base_province","fileType":"text","path":"/base_province","writeMode":"append"}}}],"setting":{"speed":{"channel":1}}
}2023-03-28 14:57:22.110 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2023-03-28 14:57:22.113 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2023-03-28 14:57:22.114 [main] INFO JobContainer - DataX jobContainer starts job.
2023-03-28 14:57:22.117 [main] INFO JobContainer - Set jobId = 0
2023-03-28 14:57:22.608 [job-0] INFO OriginalConfPretreatmentUtil - Available jdbcUrl:jdbc:mysql://hadoop102:3306/gmall?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true.
Mar 28, 2023 2:57:23 PM org.apache.hadoop.util.NativeCodeLoader <clinit>
WARNING: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2023-03-28 14:57:24.896 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2023-03-28 14:57:24.897 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do prepare work .
2023-03-28 14:57:24.898 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] do prepare work .
2023-03-28 14:57:25.190 [job-0] INFO HdfsWriter$Job - 由于您配置了writeMode append, 写入前不做清理工作, [/base_province] 目录下写入相应文件名前缀 [base_province] 的文件
2023-03-28 14:57:25.190 [job-0] INFO JobContainer - jobContainer starts to do split ...
2023-03-28 14:57:25.191 [job-0] INFO JobContainer - Job set Channel-Number to 1 channels.
2023-03-28 14:57:25.196 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] splits to [1] tasks.
2023-03-28 14:57:25.197 [job-0] INFO HdfsWriter$Job - begin do split...
2023-03-28 14:57:25.204 [job-0] INFO HdfsWriter$Job - splited write file name:[hdfs://hadoop102:8020/base_province__75aba932_44d5_4da1_a91a_49d0597a43bd/base_province__56819f80_e08e_49ef_b6a6_d9549a8f865a]
2023-03-28 14:57:25.204 [job-0] INFO HdfsWriter$Job - end do split.
2023-03-28 14:57:25.204 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] splits to [1] tasks.
2023-03-28 14:57:25.270 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2023-03-28 14:57:25.275 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2023-03-28 14:57:25.277 [job-0] INFO JobContainer - Running by standalone Mode.
2023-03-28 14:57:25.305 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.
2023-03-28 14:57:25.310 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.
2023-03-28 14:57:25.320 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2023-03-28 14:57:25.345 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
2023-03-28 14:57:25.351 [0-0-0-reader] INFO CommonRdbmsReader$Task - Begin to read record by Sql: [select id,name,region_id,area_code,iso_code,iso_3166_2 from base_province where id>=3
] jdbcUrl:[jdbc:mysql://hadoop102:3306/gmall?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].
2023-03-28 14:57:25.444 [0-0-0-writer] INFO HdfsWriter$Task - begin do write...
2023-03-28 14:57:25.445 [0-0-0-writer] INFO HdfsWriter$Task - write to file : [hdfs://hadoop102:8020/base_province__75aba932_44d5_4da1_a91a_49d0597a43bd/base_province__56819f80_e08e_49ef_b6a6_d9549a8f865a]
2023-03-28 14:57:26.370 [0-0-0-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select id,name,region_id,area_code,iso_code,iso_3166_2 from base_province where id>=3
] jdbcUrl:[jdbc:mysql://hadoop102:3306/gmall?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].
2023-03-28 14:57:27.783 [0-0-0-writer] INFO HdfsWriter$Task - end do write
2023-03-28 14:57:27.848 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[2515]ms
2023-03-28 14:57:27.849 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2023-03-28 14:57:35.336 [job-0] INFO StandAloneJobContainerCommunicator - Total 32 records, 667 bytes | Speed 66B/s, 3 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.024s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-03-28 14:57:35.336 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2023-03-28 14:57:35.337 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] do post work.
2023-03-28 14:57:35.337 [job-0] INFO HdfsWriter$Job - start rename file [hdfs://hadoop102:8020/base_province__75aba932_44d5_4da1_a91a_49d0597a43bd/base_province__56819f80_e08e_49ef_b6a6_d9549a8f865a.gz] to file [hdfs://hadoop102:8020/base_province/base_province__56819f80_e08e_49ef_b6a6_d9549a8f865a.gz].
2023-03-28 14:57:35.348 [job-0] INFO HdfsWriter$Job - finish rename file [hdfs://hadoop102:8020/base_province__75aba932_44d5_4da1_a91a_49d0597a43bd/base_province__56819f80_e08e_49ef_b6a6_d9549a8f865a.gz] to file [hdfs://hadoop102:8020/base_province/base_province__56819f80_e08e_49ef_b6a6_d9549a8f865a.gz].
2023-03-28 14:57:35.348 [job-0] INFO HdfsWriter$Job - start delete tmp dir [hdfs://hadoop102:8020/base_province__75aba932_44d5_4da1_a91a_49d0597a43bd] .
2023-03-28 14:57:35.356 [job-0] INFO HdfsWriter$Job - finish delete tmp dir [hdfs://hadoop102:8020/base_province__75aba932_44d5_4da1_a91a_49d0597a43bd] .
2023-03-28 14:57:35.357 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do post work.
2023-03-28 14:57:35.357 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2023-03-28 14:57:35.358 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /opt/module/datax/hook
2023-03-28 14:57:35.461 [job-0] INFO JobContainer - [total cpu info] => averageCpu | maxDeltaCpu | minDeltaCpu -1.00% | -1.00% | -1.00%[total gc info] => NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime PS MarkSweep | 1 | 1 | 1 | 0.237s | 0.237s | 0.237s PS Scavenge | 1 | 1 | 1 | 0.122s | 0.122s | 0.122s 2023-03-28 14:57:35.461 [job-0] INFO JobContainer - PerfTrace not enable!
2023-03-28 14:57:35.461 [job-0] INFO StandAloneJobContainerCommunicator - Total 32 records, 667 bytes | Speed 66B/s, 3 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.024s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-03-28 14:57:35.463 [job-0] INFO JobContainer -
任务启动时刻 : 2023-03-28 14:57:22
任务结束时刻 : 2023-03-28 14:57:35
任务总计耗时 : 13s
任务平均流量 : 66B/s
记录写入速度 : 3rec/s
读出记录总数 : 32
读写失败总数 : 0[maxwell@hadoop102 datax]$ 4)查看结果
(1)DataX打印日志

(2)查看HDFS文件
[maxwell@hadoop102 datax]$ hadoop fs -cat /base_province/* | zcat[maxwell@hadoop102 datax]$ hadoop fs -cat /base_province/base_province__56819f80_e08e_49ef_b6a6_d9549a8f865a.gz | zcat
2023-03-28 15:01:15,378 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
3 山西 1 140000 CN-14 CN-SX
4 内蒙古 1 150000 CN-15 CN-NM
5 河北 1 130000 CN-13 CN-HE
6 上海 2 310000 CN-31 CN-SH
7 江苏 2 320000 CN-32 CN-JS
8 浙江 2 330000 CN-33 CN-ZJ
9 安徽 2 340000 CN-34 CN-AH
10 福建 2 350000 CN-35 CN-FJ
11 江西 2 360000 CN-36 CN-JX
12 山东 2 370000 CN-37 CN-SD
14 台湾 2 710000 CN-71 CN-TW
15 黑龙江 3 230000 CN-23 CN-HL
16 吉林 3 220000 CN-22 CN-JL
17 辽宁 3 210000 CN-21 CN-LN
18 陕西 7 610000 CN-61 CN-SN
19 甘肃 7 620000 CN-62 CN-GS
20 青海 7 630000 CN-63 CN-QH
21 宁夏 7 640000 CN-64 CN-NX
22 新疆 7 650000 CN-65 CN-XJ
23 河南 4 410000 CN-41 CN-HA
24 湖北 4 420000 CN-42 CN-HB
25 湖南 4 430000 CN-43 CN-HN
26 广东 5 440000 CN-44 CN-GD
27 广西 5 450000 CN-45 CN-GX
28 海南 5 460000 CN-46 CN-HI
29 香港 5 810000 CN-91 CN-HK
30 澳门 5 820000 CN-92 CN-MO
31 四川 6 510000 CN-51 CN-SC
32 贵州 6 520000 CN-52 CN-GZ
33 云南 6 530000 CN-53 CN-YN
13 重庆 6 500000 CN-50 CN-CQ
34 西藏 6 540000 CN-54 CN-XZ
[maxwell@hadoop102 datax]$
4.2.3 DataX传参
通常情况下,离线数据同步任务需要每日定时重复执行,故HDFS上的目标路径通常会包含一层日期,以对每日同步的数据加以区分,也就是说每日同步数据的目标路径不是固定不变的,因此DataX配置文件中HDFS Writer的path参数的值应该是动态的。为实现这一效果,就需要使用DataX传参的功能.
DataX传参的用法如下,在JSON配置文件中使用${param}引用参数,在提交任务时使用-p"-Dparam=value"传入参数值,具体示例如下。
1)编写配置文件
(1)修改配置文件base_province.json
[maxwell@hadoop102 ~]$ vim /opt/module/datax/job/base_province.json(2)配置文件内容如下
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"connection": [{"jdbcUrl": ["jdbc:mysql://hadoop102:3306/gmall"],"querySql": ["select id,name,region_id,area_code,iso_code,iso_3166_2 from base_province where id>=3"]}],"password": "XXXXXXXX","username": "root"}},"writer": {"name": "hdfswriter","parameter": {"column": [{"name": "id","type": "bigint"},{"name": "name","type": "string"},{"name": "region_id","type": "string"},{"name": "area_code","type": "string"},{"name": "iso_code","type": "string"},{"name": "iso_3166_2","type": "string"}],"compress": "gzip","defaultFS": "hdfs://hadoop102:8020","fieldDelimiter": "\t","fileName": "base_province","fileType": "text","path": "/base_province/${dt}","writeMode": "append"}}}],"setting": {"speed": {"channel": 1}}}
}
2)提交任务
(1)创建目标路径
[maxwell@hadoop102 datax]$ hadoop fs -mkdir /base_province/2020-06-14(2)进入DataX根目录
[maxwell@hadoop102 datax]$ cd /opt/module/datax (3)执行如下命令
[maxwell@hadoop102 datax]$ python bin/datax.py -p"-Ddt=2020-06-14" job/base_province.json
[maxwell@hadoop102 datax]$ hadoop fs -mkdir /base_province/2020-06-14
[maxwell@hadoop102 datax]$
[maxwell@hadoop102 datax]$ python bin/datax.py -p"-Ddt=2020-06-14" job/base_province.json DataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.2023-03-28 15:23:24.284 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2023-03-28 15:23:24.294 [main] INFO Engine - the machine info => osInfo: Oracle Corporation 1.8 25.212-b10jvmInfo: Linux amd64 3.10.0-862.el7.x86_64cpu num: 2totalPhysicalMemory: -0.00GfreePhysicalMemory: -0.00GmaxFileDescriptorCount: -1currentOpenFileDescriptorCount: -1GC Names [PS MarkSweep, PS Scavenge]MEMORY_NAME | allocation_size | init_size PS Eden Space | 256.00MB | 256.00MB Code Cache | 240.00MB | 2.44MB Compressed Class Space | 1,024.00MB | 0.00MB PS Survivor Space | 42.50MB | 42.50MB PS Old Gen | 683.00MB | 683.00MB Metaspace | -0.00MB | 0.00MB 2023-03-28 15:23:24.324 [main] INFO Engine -
{"content":[{"reader":{"name":"mysqlreader","parameter":{"column":["id","name","region_id","area_code","iso_code","iso_3166_2"],"connection":[{"jdbcUrl":["jdbc:mysql://hadoop102:3306/gmall"],"table":["base_province"]}],"password":"*********","splitPk":"","username":"root","where":"id>=3"}},"writer":{"name":"hdfswriter","parameter":{"column":[{"name":"id","type":"bigint"},{"name":"name","type":"string"},{"name":"region_id","type":"string"},{"name":"area_code","type":"string"},{"name":"iso_code","type":"string"},{"name":"iso_3166_2","type":"string"}],"compress":"gzip","defaultFS":"hdfs://hadoop102:8020","fieldDelimiter":"\t","fileName":"base_province","fileType":"text","path":"/base_province/2020-06-14","writeMode":"append"}}}],"setting":{"speed":{"channel":1}}
}2023-03-28 15:23:24.350 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2023-03-28 15:23:24.354 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2023-03-28 15:23:24.355 [main] INFO JobContainer - DataX jobContainer starts job.
2023-03-28 15:23:24.358 [main] INFO JobContainer - Set jobId = 0
2023-03-28 15:23:24.755 [job-0] INFO OriginalConfPretreatmentUtil - Available jdbcUrl:jdbc:mysql://hadoop102:3306/gmall?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true.
2023-03-28 15:23:24.800 [job-0] INFO OriginalConfPretreatmentUtil - table:[base_province] has columns:[id,name,region_id,area_code,iso_code,iso_3166_2].
Mar 28, 2023 3:23:25 PM org.apache.hadoop.util.NativeCodeLoader <clinit>
WARNING: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2023-03-28 15:23:26.393 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2023-03-28 15:23:26.397 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do prepare work .
2023-03-28 15:23:26.398 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] do prepare work .
2023-03-28 15:23:26.528 [job-0] INFO HdfsWriter$Job - 由于您配置了writeMode append, 写入前不做清理工作, [/base_province/2020-06-14] 目录下写入相应文件名前缀 [base_province] 的文件
2023-03-28 15:23:26.529 [job-0] INFO JobContainer - jobContainer starts to do split ...
2023-03-28 15:23:26.529 [job-0] INFO JobContainer - Job set Channel-Number to 1 channels.
2023-03-28 15:23:26.537 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] splits to [1] tasks.
2023-03-28 15:23:26.537 [job-0] INFO HdfsWriter$Job - begin do split...
2023-03-28 15:23:26.549 [job-0] INFO HdfsWriter$Job - splited write file name:[hdfs://hadoop102:8020/base_province/2020-06-14__b59d4632_e3df_45be_a183_12965d29c548/base_province__d255e044_e839_42c0_8330_18b5712ecf52]
2023-03-28 15:23:26.549 [job-0] INFO HdfsWriter$Job - end do split.
2023-03-28 15:23:26.549 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] splits to [1] tasks.
2023-03-28 15:23:26.573 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2023-03-28 15:23:26.577 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2023-03-28 15:23:26.579 [job-0] INFO JobContainer - Running by standalone Mode.
2023-03-28 15:23:26.598 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [1] tasks.
2023-03-28 15:23:26.602 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.
2023-03-28 15:23:26.602 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2023-03-28 15:23:26.615 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
2023-03-28 15:23:26.619 [0-0-0-reader] INFO CommonRdbmsReader$Task - Begin to read record by Sql: [select id,name,region_id,area_code,iso_code,iso_3166_2 from base_province where (id>=3)
] jdbcUrl:[jdbc:mysql://hadoop102:3306/gmall?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].
2023-03-28 15:23:26.641 [0-0-0-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select id,name,region_id,area_code,iso_code,iso_3166_2 from base_province where (id>=3)
] jdbcUrl:[jdbc:mysql://hadoop102:3306/gmall?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].
2023-03-28 15:23:26.678 [0-0-0-writer] INFO HdfsWriter$Task - begin do write...
2023-03-28 15:23:26.679 [0-0-0-writer] INFO HdfsWriter$Task - write to file : [hdfs://hadoop102:8020/base_province/2020-06-14__b59d4632_e3df_45be_a183_12965d29c548/base_province__d255e044_e839_42c0_8330_18b5712ecf52]
2023-03-28 15:23:27.070 [0-0-0-writer] INFO HdfsWriter$Task - end do write
2023-03-28 15:23:27.131 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[517]ms
2023-03-28 15:23:27.132 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2023-03-28 15:23:36.614 [job-0] INFO StandAloneJobContainerCommunicator - Total 32 records, 667 bytes | Speed 66B/s, 3 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-03-28 15:23:36.614 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2023-03-28 15:23:36.614 [job-0] INFO JobContainer - DataX Writer.Job [hdfswriter] do post work.
2023-03-28 15:23:36.615 [job-0] INFO HdfsWriter$Job - start rename file [hdfs://hadoop102:8020/base_province/2020-06-14__b59d4632_e3df_45be_a183_12965d29c548/base_province__d255e044_e839_42c0_8330_18b5712ecf52.gz] to file [hdfs://hadoop102:8020/base_province/2020-06-14/base_province__d255e044_e839_42c0_8330_18b5712ecf52.gz].
2023-03-28 15:23:36.626 [job-0] INFO HdfsWriter$Job - finish rename file [hdfs://hadoop102:8020/base_province/2020-06-14__b59d4632_e3df_45be_a183_12965d29c548/base_province__d255e044_e839_42c0_8330_18b5712ecf52.gz] to file [hdfs://hadoop102:8020/base_province/2020-06-14/base_province__d255e044_e839_42c0_8330_18b5712ecf52.gz].
2023-03-28 15:23:36.626 [job-0] INFO HdfsWriter$Job - start delete tmp dir [hdfs://hadoop102:8020/base_province/2020-06-14__b59d4632_e3df_45be_a183_12965d29c548] .
2023-03-28 15:23:36.639 [job-0] INFO HdfsWriter$Job - finish delete tmp dir [hdfs://hadoop102:8020/base_province/2020-06-14__b59d4632_e3df_45be_a183_12965d29c548] .
2023-03-28 15:23:36.640 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do post work.
2023-03-28 15:23:36.640 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2023-03-28 15:23:36.680 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /opt/module/datax/hook
2023-03-28 15:23:36.783 [job-0] INFO JobContainer - [total cpu info] => averageCpu | maxDeltaCpu | minDeltaCpu -1.00% | -1.00% | -1.00%[total gc info] => NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime PS MarkSweep | 1 | 1 | 1 | 0.054s | 0.054s | 0.054s PS Scavenge | 1 | 1 | 1 | 0.028s | 0.028s | 0.028s 2023-03-28 15:23:36.784 [job-0] INFO JobContainer - PerfTrace not enable!
2023-03-28 15:23:36.785 [job-0] INFO StandAloneJobContainerCommunicator - Total 32 records, 667 bytes | Speed 66B/s, 3 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-03-28 15:23:36.786 [job-0] INFO JobContainer -
任务启动时刻 : 2023-03-28 15:23:24
任务结束时刻 : 2023-03-28 15:23:36
任务总计耗时 : 12s
任务平均流量 : 66B/s
记录写入速度 : 3rec/s
读出记录总数 : 32
读写失败总数 : 0[maxwell@hadoop102 datax]$ 3)查看结果
[maxwell@hadoop102 datax]$ hadoop fs -ls /base_province
Found 2 items
drwxr-xr-x - atguigu supergroup 0 2021-10-15 21:41 /base_province/2020-06-14

4.3 同步HDFS数据到MySQL案例
案例要求:同步HDFS上的/base_province目录下的数据到MySQL gmall 数据库下的test_province表。
需求分析:要实现该功能,需选用HDFSReader和MySQLWriter。
1)编写配置文件
(1)创建配置文件test_province.json
[maxwell@hadoop102 ~]$ vim /opt/module/datax/job/base_province.json(2)配置文件内容如下
{"job": {"content": [{"reader": {"name": "hdfsreader","parameter": {"defaultFS": "hdfs://hadoop102:8020","path": "/base_province","column": ["*"],"fileType": "text","compress": "gzip","encoding": "UTF-8","nullFormat": "\\N","fieldDelimiter": "\t",}},"writer": {"name": "mysqlwriter","parameter": {"username": "root","password": "XXXXXXX","connection": [{"table": ["test_province"],"jdbcUrl": "jdbc:mysql://hadoop102:3306/gmall?useUnicode=true&characterEncoding=utf-8"}],"column": ["id","name","region_id","area_code","iso_code","iso_3166_2"],"writeMode": "replace"}}}],"setting": {"speed": {"channel": 1}}}
}
2)配置文件说明
(1)Reader参数说明

(2)Writer参数说明

3)提交任务
(1)在MySQL中创建gmall.test_province表
DROP TABLE IF EXISTS `test_province`;
CREATE TABLE `test_province` (`id` bigint(20) NOT NULL,`name` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`region_id` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`area_code` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`iso_code` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,`iso_3166_2` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE = InnoDB CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;

(2)进入DataX根目录
[maxwell@hadoop102 datax]$ cd /opt/module/datax (3)执行如下命令
[maxwell@hadoop102 datax]$ python bin/datax.py job/test_province.json 4)查看结果
(1)DataX打印日志
[maxwell@hadoop102 datax]$ cd job/
[maxwell@hadoop102 job]$ vim test_province.json
[maxwell@hadoop102 job]$
[maxwell@hadoop102 job]$ cd ..
[maxwell@hadoop102 datax]$
[maxwell@hadoop102 datax]$ python bin/datax.py job/test_province.jsonDataX (DATAX-OPENSOURCE-3.0), From Alibaba !
Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.2023-03-28 15:40:51.707 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl
2023-03-28 15:40:51.714 [main] INFO Engine - the machine info => osInfo: Oracle Corporation 1.8 25.212-b10jvmInfo: Linux amd64 3.10.0-862.el7.x86_64cpu num: 2totalPhysicalMemory: -0.00GfreePhysicalMemory: -0.00GmaxFileDescriptorCount: -1currentOpenFileDescriptorCount: -1GC Names [PS MarkSweep, PS Scavenge]MEMORY_NAME | allocation_size | init_size PS Eden Space | 256.00MB | 256.00MB Code Cache | 240.00MB | 2.44MB Compressed Class Space | 1,024.00MB | 0.00MB PS Survivor Space | 42.50MB | 42.50MB PS Old Gen | 683.00MB | 683.00MB Metaspace | -0.00MB | 0.00MB 2023-03-28 15:40:51.735 [main] INFO Engine -
{"content":[{"reader":{"name":"hdfsreader","parameter":{"column":["*"],"compress":"gzip","defaultFS":"hdfs://hadoop102:8020","encoding":"UTF-8","fieldDelimiter":"\t","fileType":"text","nullFormat":"\\N","path":"/base_province"}},"writer":{"name":"mysqlwriter","parameter":{"column":["id","name","region_id","area_code","iso_code","iso_3166_2"],"connection":[{"jdbcUrl":"jdbc:mysql://hadoop102:3306/gmall?useUnicode=true&characterEncoding=utf-8","table":["test_province"]}],"password":"*********","username":"root","writeMode":"replace"}}}],"setting":{"speed":{"channel":1}}
}2023-03-28 15:40:51.756 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null
2023-03-28 15:40:51.758 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=0
2023-03-28 15:40:51.758 [main] INFO JobContainer - DataX jobContainer starts job.
2023-03-28 15:40:51.762 [main] INFO JobContainer - Set jobId = 0
2023-03-28 15:40:51.782 [job-0] INFO HdfsReader$Job - init() begin...
2023-03-28 15:40:52.081 [job-0] INFO HdfsReader$Job - hadoopConfig details:{"finalParameters":[]}
2023-03-28 15:40:52.082 [job-0] INFO HdfsReader$Job - init() ok and end...
2023-03-28 15:40:52.556 [job-0] INFO OriginalConfPretreatmentUtil - table:[test_province] all columns:[
id,name,region_id,area_code,iso_code,iso_3166_2
].
2023-03-28 15:40:52.575 [job-0] INFO OriginalConfPretreatmentUtil - Write data [
replace INTO %s (id,name,region_id,area_code,iso_code,iso_3166_2) VALUES(?,?,?,?,?,?)
], which jdbcUrl like:[jdbc:mysql://hadoop102:3306/gmall?useUnicode=true&characterEncoding=utf-8&yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true]
2023-03-28 15:40:52.576 [job-0] INFO JobContainer - jobContainer starts to do prepare ...
2023-03-28 15:40:52.576 [job-0] INFO JobContainer - DataX Reader.Job [hdfsreader] do prepare work .
2023-03-28 15:40:52.576 [job-0] INFO HdfsReader$Job - prepare(), start to getAllFiles...
2023-03-28 15:40:52.576 [job-0] INFO HdfsReader$Job - get HDFS all files in path = [/base_province]
Mar 28, 2023 3:40:52 PM org.apache.hadoop.util.NativeCodeLoader <clinit>
WARNING: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2023-03-28 15:40:53.889 [job-0] INFO HdfsReader$Job - [hdfs://hadoop102:8020/base_province/2020-06-14] 是目录, 递归获取该目录下的文件
2023-03-28 15:40:54.039 [job-0] INFO HdfsReader$Job - [hdfs://hadoop102:8020/base_province/2020-06-14/base_province__d255e044_e839_42c0_8330_18b5712ecf52.gz]是[text]类型的文件, 将该文件加入source files列表
2023-03-28 15:40:54.059 [job-0] INFO HdfsReader$Job - [hdfs://hadoop102:8020/base_province/base_province__56819f80_e08e_49ef_b6a6_d9549a8f865a.gz]是[text]类型的文件, 将该文件加入source files列表
2023-03-28 15:40:54.059 [job-0] INFO HdfsReader$Job - 您即将读取的文件数为: [2], 列表为: [hdfs://hadoop102:8020/base_province/2020-06-14/base_province__d255e044_e839_42c0_8330_18b5712ecf52.gz,hdfs://hadoop102:8020/base_province/base_province__56819f80_e08e_49ef_b6a6_d9549a8f865a.gz]
2023-03-28 15:40:54.060 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] do prepare work .
2023-03-28 15:40:54.061 [job-0] INFO JobContainer - jobContainer starts to do split ...
2023-03-28 15:40:54.061 [job-0] INFO JobContainer - Job set Channel-Number to 1 channels.
2023-03-28 15:40:54.061 [job-0] INFO HdfsReader$Job - split() begin...
2023-03-28 15:40:54.062 [job-0] INFO JobContainer - DataX Reader.Job [hdfsreader] splits to [2] tasks.
2023-03-28 15:40:54.062 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] splits to [2] tasks.
2023-03-28 15:40:54.075 [job-0] INFO JobContainer - jobContainer starts to do schedule ...
2023-03-28 15:40:54.082 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.
2023-03-28 15:40:54.085 [job-0] INFO JobContainer - Running by standalone Mode.
2023-03-28 15:40:54.101 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [1] channels for [2] tasks.
2023-03-28 15:40:54.105 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.
2023-03-28 15:40:54.106 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.
2023-03-28 15:40:54.120 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started
2023-03-28 15:40:54.157 [0-0-0-reader] INFO HdfsReader$Job - hadoopConfig details:{"finalParameters":["mapreduce.job.end-notification.max.retry.interval","mapreduce.job.end-notification.max.attempts"]}
2023-03-28 15:40:54.179 [0-0-0-reader] INFO Reader$Task - read start
2023-03-28 15:40:54.180 [0-0-0-reader] INFO Reader$Task - reading file : [hdfs://hadoop102:8020/base_province/2020-06-14/base_province__d255e044_e839_42c0_8330_18b5712ecf52.gz]
2023-03-28 15:40:54.215 [0-0-0-reader] INFO UnstructuredStorageReaderUtil - CsvReader使用默认值[{"captureRawRecord":true,"columnCount":0,"comment":"#","currentRecord":-1,"delimiter":"\t","escapeMode":1,"headerCount":0,"rawRecord":"","recordDelimiter":"\u0000","safetySwitch":false,"skipEmptyRecords":true,"textQualifier":"\"","trimWhitespace":true,"useComments":false,"useTextQualifier":true,"values":[]}],csvReaderConfig值为[null]
2023-03-28 15:40:54.222 [0-0-0-reader] INFO Reader$Task - end read source files...
2023-03-28 15:40:54.438 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[323]ms
2023-03-28 15:40:54.460 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[1] attemptCount[1] is started
2023-03-28 15:40:54.556 [0-0-1-reader] INFO HdfsReader$Job - hadoopConfig details:{"finalParameters":["mapreduce.job.end-notification.max.retry.interval","mapreduce.job.end-notification.max.attempts"]}
2023-03-28 15:40:54.556 [0-0-1-reader] INFO Reader$Task - read start
2023-03-28 15:40:54.556 [0-0-1-reader] INFO Reader$Task - reading file : [hdfs://hadoop102:8020/base_province/base_province__56819f80_e08e_49ef_b6a6_d9549a8f865a.gz]
2023-03-28 15:40:54.612 [0-0-1-reader] INFO UnstructuredStorageReaderUtil - CsvReader使用默认值[{"captureRawRecord":true,"columnCount":0,"comment":"#","currentRecord":-1,"delimiter":"\t","escapeMode":1,"headerCount":0,"rawRecord":"","recordDelimiter":"\u0000","safetySwitch":false,"skipEmptyRecords":true,"textQualifier":"\"","trimWhitespace":true,"useComments":false,"useTextQualifier":true,"values":[]}],csvReaderConfig值为[null]
2023-03-28 15:40:54.629 [0-0-1-reader] INFO Reader$Task - end read source files...
2023-03-28 15:40:54.905 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[1] is successed, used[464]ms
2023-03-28 15:40:54.905 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.
2023-03-28 15:41:04.114 [job-0] INFO StandAloneJobContainerCommunicator - Total 64 records, 1334 bytes | Speed 133B/s, 6 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-03-28 15:41:04.114 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.
2023-03-28 15:41:04.114 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] do post work.
2023-03-28 15:41:04.114 [job-0] INFO JobContainer - DataX Reader.Job [hdfsreader] do post work.
2023-03-28 15:41:04.115 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.
2023-03-28 15:41:04.115 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /opt/module/datax/hook
2023-03-28 15:41:04.116 [job-0] INFO JobContainer - [total cpu info] => averageCpu | maxDeltaCpu | minDeltaCpu -1.00% | -1.00% | -1.00%[total gc info] => NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTime PS MarkSweep | 1 | 1 | 1 | 0.043s | 0.043s | 0.043s PS Scavenge | 1 | 1 | 1 | 0.176s | 0.176s | 0.176s 2023-03-28 15:41:04.116 [job-0] INFO JobContainer - PerfTrace not enable!
2023-03-28 15:41:04.117 [job-0] INFO StandAloneJobContainerCommunicator - Total 64 records, 1334 bytes | Speed 133B/s, 6 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%
2023-03-28 15:41:04.117 [job-0] INFO JobContainer -
任务启动时刻 : 2023-03-28 15:40:51
任务结束时刻 : 2023-03-28 15:41:04
任务总计耗时 : 12s
任务平均流量 : 133B/s
记录写入速度 : 6rec/s
读出记录总数 : 64
读写失败总数 : 0[maxwell@hadoop102 datax]$ 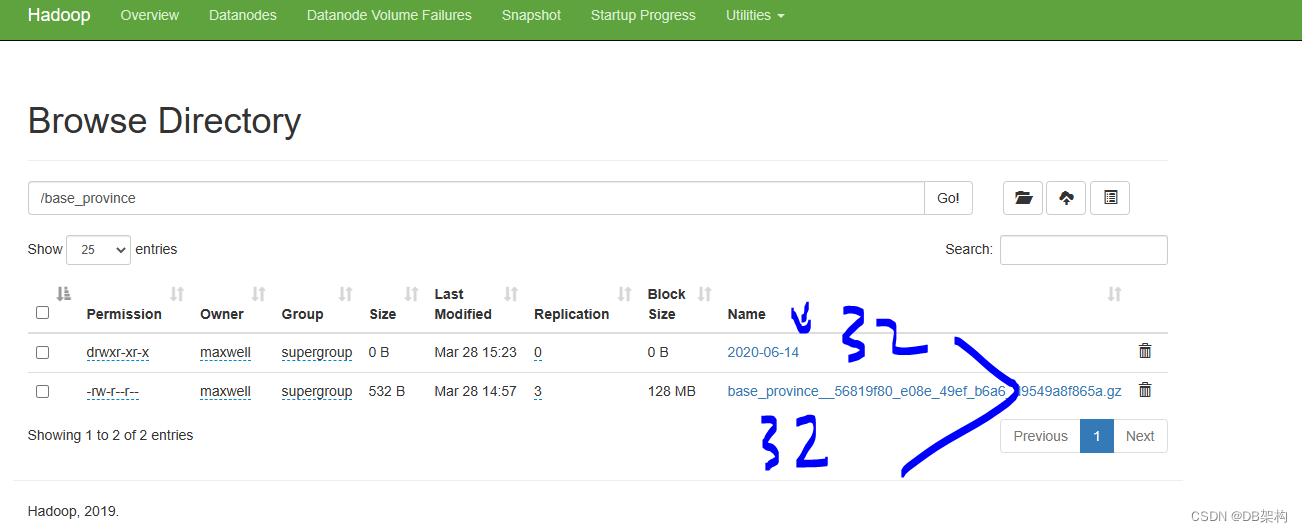
(2)查看MySQL目标表数据

5. DataX优化
5.1 速度控制
DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制你的作业速度,让你的作业在数据库可以承受的范围内达到最佳的同步速度。
关键优化参数如下:
| 参数 | 说明 |
| job.setting.speed.channel | 并发数 |
| job.setting.speed.record | 总record限速 |
| job.setting.speed.byte | 总byte限速 |
| core.transport.channel.speed.record | 单个channel的record限速,默认值为10000(10000条/s) |
| core.transport.channel.speed.byte | 单个channel的byte限速,默认值1024*1024(1M/s) |
注意事项:
1.若配置了总record限速,则必须配置单个channel的record限速
2.若配置了总byte限速,则必须配置单个channe的byte限速
3.若配置了总record限速和总byte限速,channel并发数参数就会失效。因为配置了总record限速和总byte限速之后,实际channel并发数是通过计算得到的:
计算公式为:
min(总byte限速/单个channel的byte限速,总record限速/单个channel的record限速)
配置示例:
{"core": {"transport": {"channel": {"speed": {"byte": 1048576 //单个channel byte限速1M/s}}}},"job": {"setting": {"speed": {"byte" : 5242880 //总byte限速5M/s}},...}
}
5.2 内存调整
当提升DataX Job内Channel并发数时,内存的占用会显著增加,因为DataX作为数据交换通道,在内存中会缓存较多的数据。例如Channel中会有一个Buffer,作为临时的数据交换的缓冲区,而在部分Reader和Writer的中,也会存在一些Buffer,为了防止OOM等错误,需调大JVM的堆内存。
建议将内存设置为4G或者8G,这个也可以根据实际情况来调整。
调整JVM xms xmx参数的两种方式:一种是直接更改datax.py脚本;另一种是在启动的时候,加上对应的参数,如下:
python datax/bin/datax.py --jvm="-Xms8G -Xmx8G" /path/to/your/job.json相关文章:
关于数据同步工具DataX部署
1.DataX简介 1.1 DataX概述 DataX 是阿里巴巴开源的一个异构数据源离线同步工具,致力于实现包括关系型数据库(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各种异构数据源之间稳定高效的数据同步功能。 源码地址:GitHub - alibaba/DataX: DataX是…...

如何开发JetBrains插件
1 标题安装 IntelliJ IDEA 如果您还没有安装 IntelliJ IDEA,从官方网站下载并安装 IntelliJ IDEA Community Edition(免费)或 Ultimate Edition(付费)。 2 创建插件项目 在 IntelliJ IDEA 中,创建一个新…...

企业采购成本管理的难题及解决方案
企业采购成本控制是企业管理中的一个重要方面,也是一个不容易解决的难题。企业采购成本控制面临的难题包括以下几个方面: 1、采购流程复杂 企业采购通常需要经过一系列的流程,包括采购计划、采购申请、报价、比价、议标、合同签订、验收、付…...
实践)
龙蜥白皮书精选:基于 SM4 算法的文件加密(fscrypt)实践
文/张天佳 通常我们会以文件作为数据载体,使用磁盘,USB 闪存,SD 卡等存储介质进行数据存储,即便数据已经离线存储,仍然不能保证该存储介质不会丢失,如果丢失那么对于我们来说有可能是灾难性的事件。因此对…...
【SpringBoot入门】SpringBoot的配置
SpringBoot的配置文件一、SpringBoot配置文件分类二、yaml 概述三、多环境配置四、Value 和 ConfigurationProperties五、总结一、SpringBoot配置文件分类 SpringBoot 是基于约定的,很多配置都是默认的(主方法上SpringBootApplication注解的子注解Enabl…...

react 学习整理
如何使用引号传递字符串 常见的 <imgclassName avatersrc http://...alt gregorio y />或者声明变量来保存 export default function XXX(){ const avator avator const description gergorio y return (<image className XXXsrc {avator}alt {alt} />)…...

物理引擎系统-ode
物理引擎系统-ode 目录 物理引擎系统-ode 一、物理引擎系统-ode——processIslands 二、物理引擎系统-ode——processIslands 三、物理引擎系统-ode——processIslands 四、物理引擎系统-ode——processIslands 五、物理引擎系统-ode——processIslands 一、物理引…...

函数设计—参数规则
【规则1-1】参数的书写要完整,不要贪图省事只写参数的类型而省略参数名字。 如果函数没有参数,则用 void 填充。 例如: void SetValue(int width, int height); // 良好的风格 void SetValue(int, int); // 不良的风格 float GetValue(…...

rsync远程同步
目录 rsync rsync简介 rsync优点 同步方式 rsync名词解释 rsync工作原理 常用rsync命令 配置源的两种表达方法 远程同步实操 如何不想每次登录的时候输入密码 同步删除文件 定时完成操作 格式二 指定资源下载到/opt进行备份 通过信道协议同步数据编辑编辑 rs…...
【2020-07-24】)
中国大陆IP段(仅大陆地区)【2020-07-24】
中国大陆IP段(仅大陆地区)【2020-07-24】 1.1.8.0/24 1.2.4.0/24 1.8.1.0/24 1.8.8.0/24 1.18.128.0/24 1.24.0.0/13 1.45.0.0/16 1.48.0.0/14 1.56.0.0/13 1.68.0.0/14 1.80.0.0/13 1.88.0.0/14 1.92.0.0/20 1.93.0.0/16 1.94.0.0/15 1.119.0.0/17 1.11…...

从零开始的嵌入式Linux生活(一) 背景介绍
文章目录前言本系列文章的主要思想:本系列文章包括:一、什么是嵌入式开发二.嵌入式开发 - 由便宜到贵三.嵌入式开发的基本原理一个美好的假设:再来一个美好的假设美好的假设被打破了 - RTOS系统美好的假设又被打破了 - 嵌入式Linux系统老板飘…...

后缀为whl的文件是什么?如何安装whl文件?学习一下(22)
小朋友们好,大朋友们好! 我是猫妹,一名爱上Python编程的小学生。 欢迎和猫妹一起,趣味学Python。 今日主题 了解并使用Pyhton的库安装包文件whl。 什么是whl文件 whl格式本质上是一个压缩包,里面包含了py文件&am…...

整合Juit
整合Juit 1.SpringBoot整合Juit SpringBootTest class Springboot04JuitApplicationTests {AutowiredBookDao bookDao;Testvoid contextLoads() {System.out.println("test................");bookDao.save();} } 名称:SpringBootTest 类型&…...
C#,码海拾贝(11)——拉格朗日(Lagrange)三点式曲面插值算法,《C#数值计算算法编程》源代码升级改进版
本文开始是曲面插值(Surface Interpolation,也称作:二维插值,二元插值)。 数值计算三点式 数值计算三点式是一种常见的数值计算方法,它是通过对已知函数在某个点及其左右两个点处的函数值进行数值插值&…...
CentOS7系统安装MySQL 5.7
目录一、官网下载mysql5.7二、检查mysql依赖环境三、安装MySQL 5.7.281.将安装程序拷贝到/opt目录下2.安装四个安装包3.查看mysql版本4.服务的初始化5.启动mysql,并查看状态(加不加.service后缀都可以)6.查看mysql服务是否自启动(默认自启动)…...

基于粒子群算法优化BP神经网络的高炉si预测,PSO-BP
目录 摘要 BP神经网络的原理 BP神经网络的定义 BP神经网络的基本结构 BP神经网络的神经元 BP神经网络的激活函数, BP神经网络的传递函数 粒子群算法的原理及步骤 基于粒子群算法改进优化BP神经网络的用电量预测 代码 效果图 结果分析 展望 参考 摘要 一般用启发式算法改进B…...

STM32输出PWM波控制电机转速,红外循迹避障智能车+L298N的详细使用手册、接线方法及工作原理,有代码
智能循迹红外避障小车 本设计的完整的系统主要包括STM32单片机最小系统、L298n电机驱动,超声波 ,舵机 ,红外模块等。寻迹小车相信大家都已经耳熟能祥了。 我们在这里主要讲一下L298N驱动电机和单片机输出PWM控制电机转速。 本设计软件系统采…...

3、AI的道德性测试
AI的道德性 AI系统的道德性如何保障是一个重要而复杂的问题,涉及到人工智能的发展、应用、监管、伦理、法律等多个方面。保障AI系统的道德性是一个很重要的问题,因为AI系统不仅会影响人类的生活和工作,也会涉及人类的价值观和伦理道德原则。针对这部分,也需要测试AI系统是…...

银行数字化转型导师坚鹏:银行业务需求分析师技能快速提升之道
银行业务需求分析师技能快速提升之道 ——以推动银行战略目标实现为核心,实现知行果合一课程背景: 很多银行都在开展业务需求分析工作,目前存在以下问题急需解决:不知道银行业务需求分析师掌握哪些关键知识?不清楚…...

C++IO流
文章目录一、CIO流体系二、C标准IO流三、C文件IO流1.ifstream2.ofstream一、CIO流体系 C流是指信息从外部输入设备向计算机内部输入,从内存向外部输出设备输出的过程,这种输入输出的过程非常形象地被称为流的概念。IO流指的就是输入输出流。 我们平时对…...

WindowsCleaner完整解析:如何用开源工具彻底解决Windows系统卡顿和C盘爆红问题
WindowsCleaner完整解析:如何用开源工具彻底解决Windows系统卡顿和C盘爆红问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否曾经在关键时刻被…...

Claude模型配置管理工具:从原理到实践,构建高效AI应用
1. 项目概述:一个为Claude模型量身定制的配置管理工具最近在折腾大语言模型本地部署和API调用时,我发现一个挺普遍的问题:虽然像Claude这样的模型能力很强,但每次想切换不同的使用场景——比如从写代码切换到写文案,或…...

Figma中文汉化插件完整指南:3分钟让Figma界面说中文的终极方案
Figma中文汉化插件完整指南:3分钟让Figma界面说中文的终极方案 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN 还在为Figma的英文界面而烦恼吗?对于中文设计师来…...

从零构建开源ADAS原型:车道检测、目标识别与PID控制实践
1. 项目概述:从零到一,构建一个开源的ADAS原型系统 最近几年,汽车行业最火的话题之一就是“智能驾驶”。无论是传统车企还是新势力,都在宣传自家的辅助驾驶功能,什么自适应巡航、车道保持、自动紧急制动,听…...

OpenCore Legacy Patcher:让你的老款Mac重获新生,畅享最新macOS系统
OpenCore Legacy Patcher:让你的老款Mac重获新生,畅享最新macOS系统 【免费下载链接】OpenCore-Legacy-Patcher Experience macOS just like before 项目地址: https://gitcode.com/GitHub_Trending/op/OpenCore-Legacy-Patcher 你是否有一台2008…...

【仅限首批内测用户验证】:Midjourney v8“隐性美学协议”曝光——92%设计师尚未察觉的4类负向提示陷阱
更多请点击: https://intelliparadigm.com 第一章:Midjourney v8“隐性美学协议”的本质解构 Midjourney v8 并未公开发布传统意义上的“美学参数文档”,其核心创新在于将图像生成的审美判断内化为一套不可见但可触发的上下文响应机制——即…...

React Styleguidist权限控制终极指南:如何实现私有组件文档访问限制
React Styleguidist权限控制终极指南:如何实现私有组件文档访问限制 【免费下载链接】react-styleguidist Isolated React component development environment with a living style guide 项目地址: https://gitcode.com/gh_mirrors/re/react-styleguidist R…...

OCPP 1.6 协议详解:ClearChargingProfile 清除充电配置文件指令
一、指令概述 ClearChargingProfile(清除充电配置文件)是OCPP 1.6协议中由中央系统发起的管理指令,用于删除充电桩的一个或多个充电配置文件。通过此指令,中央系统可以清理不再需要的配置文件,恢复默认设置࿰…...

番茄小说下载器:全平台小说下载与有声书生成解决方案
番茄小说下载器:全平台小说下载与有声书生成解决方案 【免费下载链接】Tomato-Novel-Downloader 番茄小说下载器不精简版 项目地址: https://gitcode.com/gh_mirrors/to/Tomato-Novel-Downloader 在数字阅读时代,你是否曾为无法离线阅读喜爱的小说…...

OpenClaw-RUH:基于深度学习的机器人灵巧抓取框架解析与实践
1. 项目概述:当AI遇上“机械爪”最近在AI和机器人交叉的圈子里,一个名为“OpenClaw-RUH”的项目引起了我的注意。乍一看这个标题,你可能会觉得它又是一个开源的机械臂控制项目。但当我深入其代码仓库和社区讨论后,发现它的野心远不…...