毕业设计项目——基于transformer的中文医疗领域命名实体识别(论文/代码)
完整的论文代码见文章末尾 以下为核心内容
摘要
近年来,随着深度学习技术的发展,基于Transformer和BERT的模型在自然语言处理领域取得了显著进展。在中文医疗领域,命名实体识别(Named Entity Recognition, NER)是一项重要任务,旨在从文本中识别出特定类别的命名实体,如疾病、药物、治疗方法等。传统方法在处理中文医疗领域NER时面临着语言复杂性和领域专业性等挑战,而基于Transformer和BERT的模型能够更好地捕捉句子中的上下文信息、语义关系和依赖关系,从而提升NER的准确性和泛化能力。通过结合Transformer和BERT的架构,以及预训练模型的迁移学习方法,可以有效地构建适用于中文医疗领域的NER模型,为医疗信息提取和医疗知识图谱构建等任务提供更加准确和高效的支持。
本文方法
Transformer模型设计与实现
使用transformer中的AutoModelForTokenClassification,基于上文的Bert分词模型,其用于进行标记分类(Token Classification)任务的模型训练和推理。
预训练的Transformer模型存在以下两个结构:
嵌入层(Embedding Layer):在Transformer模型中,嵌入层首先接收输入的标记(tokens)。这些标记通过BERT分词器处理后,转换为模型可以理解的数字ID。嵌入层包括词嵌入、位置嵌入和段落嵌入(对于处理多段落文本的模型而言)。这些嵌入结合起来,将每个标记转换为具有丰富语义和上下文信息的固定大小的向量表示。
Transformer编码器层:这些向量表示随后被送入多层的Transformer编码器。每一层编码器包括两个主要部分:多头自注意力机制和前馈神经网络。多头自注意力机制允许模型在处理每个标记时,考虑到其他标记的信息,从而捕捉复杂的依赖关系。前馈网络则进一步处理这些信息。残差连接和层归一化帮助改善训练过程中的稳定性和效率。
在预训练模型的基础上,为了进行标记分类任务,会增加一个特定的分类头。这通常是一个线性层,用于将Transformer模型最后一层的输出(每个标记的表示)映射到标记类别的概率分布上。
输入处理阶段,文本首先经过分词器处理,分解为标记,并转换为数字ID。这些ID通过嵌入层转换为向量,这些向量包含了标记的初步语义表示。
接着,这些向量通过多层Transformer编码器处理,每层都使用自注意力机制来理解标记之间的上下文关系。模型能够学习到每个标记与其他标记之间的相互作用,从而获得丰富的上下文化表示。通过Transformer编码器的处理,得到的每个标记的表示随后被送入分类头,这个线性层将每个标记的表示映射到预定义类别的概率分布上,从而完成标记分类任务。
最终模型输出每个标记的类别预测,这些预测用于识别文本中的实体名。在训练阶段,模型使用带标签的数据进行微调,通过计算预测类别分布和实际标签之间的损失(通常是交叉熵损失),并通过反向传播更新模型参数,以最小化这一损失。在推理(或测试)阶段,模型对新的未标记文本进行标记分类预测,基于学习到的表示和分类头,模型能够为每个输入标记分配最可能的标签。
自注意力机制优化
传统的Transformer模型在计算注意力时,会对所有的输入序列进行全注意力计算,这导致了巨大的计算和存储开销。在医疗NER任务中,可以通过稀疏化注意力来减少计算量。具体来说,只关注与当前词条最相关的其他几个词条,而不是整个序列。本文使用局部窗口注意力机制来优化模型。
局部窗口注意力机制的核心思想是:在自注意力的计算中,不是考虑整个序列的全局信息,而是只关注每个词条周围的有限范围内的其他词条。这种方法基于的假设是,文本中很多重要的信息和依赖通常局限在词条的近邻范围内,特别是在医疗文本中,相关的医学术语和描述往往在相对集中的文本区域内出现。
可以为每个词条定义一个固定大小的窗口(例如,前后各包含5个词条),只计算窗口内词条之间的注意力。这种方法在保持上下文相关性的同时,显著降低了计算量。
在本文的医疗NER任务中,选择前后各3至5个词的窗口大小。修改传统的Transformer模型中的注意力计算方式,在局部窗口注意力机制中,只计算窗口内词条之间的注意力分数。
这可以通过掩码操作实现,即在计算注意力分数时,将窗口外的词条对应的分数设为一个非常小的值(或负无穷),这样在应用softmax函数时,这些词条的影响就被忽略了。使用局部窗口注意力不需要改变Transformer的基本结构,仅需修改注意力层的计算方式。
结果展示
NER任务常用BIO(Begin-Inside-Outside)标注模式来标识实体的边界。在这种标注体系中,每个标签都有其特定的含义:“B”(开始)标签标记实体的开始,“I”(中间)标签标记实体内部的字符,“E”(结束)标签标记实体的结束,而“O”(非实体)标签则用于标记不属于任何实体的字符。此外,标注中的数字0通常用于表示句子的分隔或其他特殊情况。
例如,在一串序列标签[1, 2, 2, 2, 3, 4, 4, 4, 4, 4, 4, 4, 0, 0]中,标签组合[1, 2, 2, 2, 3]代表一个完整的实体,其内部结构表明了实体的起始、中间部分以及结束,这使得模型能够清晰地识别并界定实体的范围。在实际的文本分析中,这可以直接转化为实体“半月板钙化”的检测,其中“半月板”由标签1(B)开始,“钙化”由标签3(E)结束。
当我们将这些序列标签映射回原始文本时,可以得到精确的实体识别结果,例如,{‘start’: 0, ‘end’: 3, ‘word’: ‘瘦脸针’}。这表明模型不仅能识别出“瘦脸针”这一实体,还能定位其在原文中的确切位置。

模型结果评估
数据集及序列标注方法
i2b2 (Informatics for Integrating Biology and the Bedside): i2b2是医疗领域常用的一个数据集,旨在促进生物医学研究和健康信息的集成。i2b2组织的挑战赛提供了多个与医疗文本处理相关的任务,包括但不限于患者病史的时间线分析、药物和疾病名称的提取等。这些数据集通常由临床笔记、病历摘要等构成。
MIMIC-III (Medical Information Mart for Intensive Care III): MIMIC-III是一个公开可用的大型数据库,包含了来自数千名重症监护病人的详细健康信息。数据内容丰富,包括病人的生理参数、实验室检测结果、医疗报告等。研究人员常用MIMIC-III来开展医疗NER等自然语言处理任务,以自动从文本中识别和分类医疗相关的实体。
BIO是一种简单的序列标注方案,其中"B"代表实体的开始,"I"代表实体的内部,"O"代表非实体。例如,在标注疾病名称时,“B-Disease”表示疾病名称的开始,“I-Disease”表示疾病名称的内部部分。这种方法适用于多种类型的实体识别任务,特别是在医疗领域中,能够有效地识别出疾病、症状、药物等实体的边界。
对比试验
本节的目标是验证所提出的基于Transformer的医疗NER模型在医疗实体识别任务上是否超过现有的标准方法或模型。
通过在数据集上进行对比实验,这些模型在专业实体的识别任务上的表现被详细评估和比较。实验结果揭示了每种模型在实体识别精度上的表现,展现了从BiLSTM-CRF到BERT及其变种模型,到本文的基于Transformer和bert分词模型的的逐步优化和性能提升的过程。

实验模型(基于Transformer):这是表格中性能最优的模型,实现了82.00%的准确率和83.50%的召回率,以及82.74%的F1分数。这个结果不仅证明了Transformer架构在处理复杂语言模型中的强大能力,也展示了在模型设计和训练过程中可能采取的优化措施的有效性,使得模型在专业实体识别任务上达到了更高的准确性和鲁棒性。
总体来看,从BiLSTM-CRF到基于Transformer的实验模型,可以观察到随着模型结构的复杂化和优化,NER任务的性能表现逐步提升。Transformer架构在命名实体识别(NER)上之所以展现出优越性,主要归功于以下几个关键特性:
Transformer模型的核心是自注意力机制,它允许模型在处理序列的每个元素时,同时考虑序列中的所有其他元素。这使得模型能够捕捉长距离依赖性,从而更好地理解上下文,这在NER任务中尤为重要。
与循环神经网络(RNN)不同,Transformer不需要按顺序处理序列数据,从而允许并行计算,大幅提高了训练效率。其通常由多个编码器和解码器层堆叠而成,每一层都能够学习序列的不同表示,从更抽象的层面捕捉语言的语义和结构信息。
获取方式

具有完备代码和论文以及其他材料。
点这里
相关文章:
毕业设计项目——基于transformer的中文医疗领域命名实体识别(论文/代码)
完整的论文代码见文章末尾 以下为核心内容 摘要 近年来,随着深度学习技术的发展,基于Transformer和BERT的模型在自然语言处理领域取得了显著进展。在中文医疗领域,命名实体识别(Named Entity Recognition, NER)是一项重要任务,旨…...
)
电子信息类专业技术学习及比赛路线总结(大一到大三)
本文主要是总结到目前为止电子信息类的专业技能、比赛路线,以后会持续更新,希望能为那些热爱电子技术或渴望学习课本之外知识的小伙伴们提供帮助,参加学科竞赛和找工作必备。(毕竟很多课本上的内容都没什么用 ) 1.单片…...
的所有输出保存到log/txt中?)
怎么将bash(sh)的所有输出保存到log/txt中?
tee 命令 这会将所有输出同时显示在屏幕上并追加到日志文件中。 bash your_script.sh 2>&1 | tee -a log_file.txt 其他方法不可用 只使用 >> 不会将除了print之外的所有保存 bash your_script.sh >> log_file.txt >> 和 2>&1一起只会保存在日…...

腾讯云服务器上使用Nginx部署的静态网站打开速度慢的原因分析及优化解决方案
目录 前言1. 网站打开速度慢的原因分析1.1 服务器配置不足1.2 网络延迟1.3 Nginx配置不合理1.4 静态资源未优化 2. 网站速度的测试与分析2.1 使用浏览器开发者工具分析2.2 在线工具测试 3. 网站优化的具体方法3.1 服务器配置优化3.2 CDN加速与DNS优化3.3 优化Nginx配置3.3.1 启…...
如何移除 iPhone 上的网络锁?本文筛选了一些适合您的工具
您是否对 iPhone 运营商的网络感到困惑?不用担心,我们将向您介绍 8 大免费 iPhone 解锁服务。这些工具可以帮助您移除 iPhone 上的网络锁,并使您能够永久在网络上使用您的设备。如果您想免费解锁 iPhone,请阅读本文并找到最适合您…...

深度学习:CycleGAN图像风格迁移转换
目录 基础概念 模型工作流程 循环一致性 几个基本概念 假图像(Fake Image) 重建图像(Reconstructed Image) 身份映射图像(Identity Mapping Image) CyclyGAN损失函数 对抗损失 身份鉴别损失 Cyc…...

pytorch和yolo区别
PyTorch与YOLO的区别:一个简明的科普 在深度学习的领域,有许多工具和框架帮助研究人员和开发者快速实现复杂的模型。其中,PyTorch与YOLO(You Only Look Once)是两个非常重要的名词。本文旨在探讨这两个技术之间的区别&…...
使用树莓派搭建音乐服务器
目录 引言一、搭建Navidrome二、服务穿透三、音流配置 引言 本人手机存储空间128G,网易云音乐6个G,本就不富裕的空间更是雪上加霜,而且重点是,我根本没有听几首歌,清除缓存后,整个软件都还是占用了5个G左右…...

单链表的分解
编写算法创建以整数为数据元素的单向链表,实现将其分解成两个链表,其中一个全部为奇数,另一个全部为偶数(尽量利用已知的存储空间)。 输入格式: 1 2 3 4 5 6 7 8 9 0 输出格式: 1 3 5 7 9 2 4 6 8 输入样例: …...

[OS] 4.Linux 内核
1. 下载 Linux 内核源代码 首先,你需要从官方站点或镜像站点下载 Linux 内核源代码。 官方源代码:The Linux Kernel Archives 清华大学镜像站点:Index of /kernel/v5.x/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror 下载 .t…...

flutter_鸿蒙next_Dart基础③函数
目录 说在前面 1. 函数的基本定义 例子 代码解释 2. 函数的调用 代码解释 3. 可选参数与命名参数 可选参数 代码解释 调用示例 命名参数 代码解释 调用示例 4. 匿名函数与高阶函数 例子 代码解释 说在最后 说在前面 在 Dart 编程语言中,函数是构建…...

基于猎豹优化算法(The Cheetah Optimizer,CO)的多无人机协同三维路径规划(提供MATLAB代码)
一、猎豹优化算法 猎豹优化算法(The Cheetah Optimizer,CO)由MohammadAminAkbari等人于2022年提出,该算法性能高效,思路新颖。 参考文献: Akbari, M.A., Zare, M., Azizipanah-abarghooee, R. et al. The…...

Linux:进程的创建、终止和等待
一、进程创建 1.1 fork函数初识 #include pid_t fork(void); 返回值:子进程中返回0,父进程返回子进程id,出错返回-1 调用fork函数后,内核做了下面的工作: 1、创建了一个子进程的PCB结构体、并拷贝一份相同的进程地址…...

数值优化基础——基于优化的规划算法
1 最优化问题的一般形式 最优化问题:满足一系列约束的可行域内,找到使得目标函数最小的解 min f ( x ) s.t. x...

括号匹配——(栈实现)
题目链接 有效的括号https://leetcode.cn/problems/valid-parentheses/description/ 题目要求 样例 解题代码 import java.util.*; class Solution {public boolean isValid(String str) {Stack<Character> stacknew Stack<>();for(int i0;i<str.length();i)…...

【Java 并发编程】初识多线程
前言 到目前为止,我们学到的都是有关 “顺序” 编程的知识,即程序中所有事物在任意时刻都只能执行一个步骤。例如:在我们的 main 方法中,都是多个操作以 “从上至下” 的顺序调用方法以至结束的。 虽然 “顺序” 编程能够解决相当…...

Linux下载安装MySQL8.4
这里写目录标题 一、准备工作查看系统环境查看系统架构卸载已安装的版本 二、下载MySQL安装包官网地址 三、安装过程上传到服务器目录解压缩,设置目录及权限配置my.cnf文件初始化数据库配置MySQL开放端口 一、准备工作 查看系统环境 确认Linux系统的版本和架构&am…...
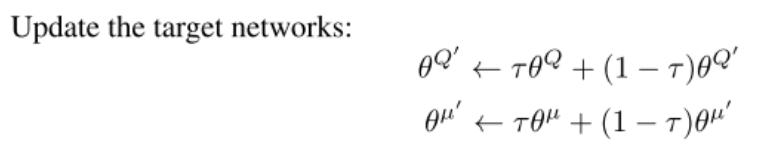
强化学习笔记之【DDPG算法】
强化学习笔记之【DDPG算法】 文章目录 强化学习笔记之【DDPG算法】前言:原论文伪代码DDPG算法DDPG 中的四个网络代码核心更新公式 前言: 本文为强化学习笔记第二篇,第一篇讲的是Q-learning和DQN 就是因为DDPG引入了Actor-Critic模型&#x…...

c++继承(下)
c继承(下) (1)继承与友元(2)继承与静态成员(3)多继承及其菱形继承问题3.1 继承模型3.2 虚继承3.3 多继承中指针偏移问题 (4)继承和组合(9…...

数据结构 ——— 单链表oj题:反转链表
目录 题目要求 手搓一个简易链表 代码实现 题目要求 给你单链表的头节点 head ,请你反转链表,并返回反转后的链表 手搓一个简易链表 代码演示: struct ListNode* n1 (struct ListNode*)malloc(sizeof(struct ListNode)); assert(n1);…...

CentOS8实战:ZeroTier构建安全异地虚拟局域网
1. 为什么选择ZeroTier替代传统内网穿透方案 最近在帮朋友搭建远程办公环境时,遇到了一个典型问题:分布在三个不同物理位置的服务器需要像在同一个办公室内网那样互相访问。最初考虑使用FRP方案,但实测下来发现几个痛点:首先是带宽…...
)
告别迷茫!在嵌入式Linux上用libwebsockets v4.0实现WebSocket客户端(含SSL配置避坑)
嵌入式Linux实战:libwebsockets v4.0客户端开发与SSL避坑指南 当树莓派的GPIO引脚需要与云端实时同步数据时,WebSocket往往是嵌入式开发者的首选协议。但面对内存仅512MB的ARMv7开发板,选用一个既支持SSL加密又能兼容C99标准的轻量级库&#…...

【ElevenLabs情绪模拟技术白皮书】:基于2,147小时情感语音标注数据集的11类基础情绪迁移模型验证报告
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs情绪模拟技术白皮书概述 ElevenLabs的情绪模拟技术并非简单调节音高或语速,而是基于多模态情感表征学习(Multimodal Affective Representation Learning, MARL&#x…...

Unity区域加载系统:实现开放世界无缝加载与内存优化
1. 项目概述:一个高效、可扩展的Unity区域加载系统 最近在做一个开放世界风格的项目,场景大了之后,加载卡顿和内存管理就成了老大难问题。传统的Unity场景加载,要么一股脑全塞进内存,要么就得自己写一堆脚本来手动控制…...

工作流编排核心原理与实践:从概念到MiniFlow系统实现
1. 项目概述:从代码仓库到工作流编排的实践最近在梳理团队内部的一些自动化流程,发现很多脚本和任务散落在各个角落,执行依赖混乱,出了问题排查起来像大海捞针。正好看到GitHub上有个叫dnh33/workflow-orchestration的项目&#x…...

如何用Wedecode实现微信小程序源代码的完美还原:从加密包到可读代码的完整指南
如何用Wedecode实现微信小程序源代码的完美还原:从加密包到可读代码的完整指南 【免费下载链接】wedecode 全自动化,微信小程序 wxapkg 包 源代码还原工具, 线上代码安全审计,支持 Windows, Macos, Linux 项目地址: https://gitcode.com/gh…...

OCT-X算法:早期胃癌AI检测的技术突破与应用
1. OCT-X算法:早期胃癌AI检测的技术突破在医疗影像分析领域,胃癌早期检测一直面临着巨大挑战。传统内窥镜检查依赖医生经验判断,存在主观性强、漏诊率高等问题。我们团队开发的OCT-X(One Class Twin Cross Learning)算…...

ITK-SNAP医学图像分割:破解三维解剖结构提取的工程难题
ITK-SNAP医学图像分割:破解三维解剖结构提取的工程难题 【免费下载链接】itksnap ITK-SNAP medical image segmentation tool 项目地址: https://gitcode.com/gh_mirrors/it/itksnap 当我们面对复杂的脑部MRI数据、肿瘤CT扫描或心血管影像时,最大…...

基于声明式Web自动化框架Hydra的电商数据监控实战
1. 项目概述:一个被低估的自动化利器 如果你经常需要处理一些重复性的、基于Web界面的操作,比如批量下载某个网站的资源、定时填写表单、或者监控网页内容的变化,那么你很可能已经厌倦了手动点击和等待。传统的脚本编写,尤其是涉及…...

AI Agent无障碍审查:自动化集成WCAG标准与axe-core实践
1. 项目概述:一个为AI助手打造的“无障碍”审查官最近在折腾AI应用开发,特别是那些能自动处理任务的智能体(AI Agent),发现一个挺有意思但容易被忽略的问题:我们费尽心思让AI能写代码、分析数据、生成报告&…...