【大数据应用开发】2023年全国职业院校技能大赛赛题第02套
需要技能竞赛软件测试资料的同学们可s聊我,详细了解目录
任务A:大数据平台搭建(容器环境)(15分)
任务B:离线数据处理(25分
任务C:数据挖掘(10分)
任务D:数据采集与实时计算(20分)
任务E:数据可视化(15分)
任务F:综合分析(10分)
任务A:大数据平台搭建(容器环境)(15分)
环境说明:
| 服务端登录地址详见各任务服务端说明。 补充说明:宿主机及各容器节点可通过Asbru工具或SSH客户端进行SSH访问。 |
子任务一:Hadoop 完全分布式安装配置
本任务需要使用root用户完成相关配置,安装Hadoop需要配置前置环境。命令中要求使用绝对路径,具体要求如下:
- 从宿主机/opt目录下将文件hadoop-3.1.3.tar.gz、jdk-8u212-linux-x64.tar.gz复制到容器Master中的/opt/software路径中(若路径不存在,则需新建),将Master节点JDK安装包解压到/opt/module路径中(若路径不存在,则需新建),将JDK解压命令复制并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
- 修改容器中/etc/profile文件,设置JDK环境变量并使其生效,配置完毕后在Master节点分别执行“java -version”和“javac”命令,将命令行执行结果分别截图并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
- 请完成host相关配置,将三个节点分别命名为master、slave1、slave2,并做免密登录,用scp命令并使用绝对路径从Master复制JDK解压后的安装文件到slave1、slave2节点(若路径不存在,则需新建),并配置slave1、slave2相关环境变量,将全部scp复制JDK的命令复制并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
- 在Master将Hadoop解压到/opt/module(若路径不存在,则需新建)目录下,并将解压包分发至slave1、slave2中,其中master、slave1、slave2节点均作为datanode,配置好相关环境,初始化Hadoop环境namenode,将初始化命令及初始化结果截图(截取初始化结果日志最后20行即可)粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
- 启动Hadoop集群(包括hdfs和yarn),使用jps命令查看Master节点与slave1节点的Java进程,将jps命令与结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下。
子任务二:Flume安装配置
本任务需要使用root用户完成相关配置,已安装Hadoop及需要配置前置环境,具体要求如下:
- 从宿主机/opt目录下将文件apache-flume-1.9.0-bin.tar.gz复制到容器Master中的/opt/software路径中(若路径不存在,则需新建),将Master节点Flume安装包解压到/opt/module目录下,将解压命令复制并粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
- 完善相关配置,设置Flume环境变量,并使环境变量生效,执行命令flume-ng version并将命令与结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
- 启动Flume传输Hadoop日志(namenode或datanode日志),查看HDFS中/tmp/flume目录下生成的内容,将查看命令及结果(至少5条结果)截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下。
子任务三:Flink on Yarn安装配置
本任务需要使用root用户完成相关配置,已安装Hadoop及需要配置前置环境,具体要求如下:
- 从宿主机/opt目录下将文件flink-1.14.0-bin-scala_2.12.tgz复制到容器Master中的/opt/software(若路径不存在,则需新建)中,将Flink包解压到路径/opt/module中(若路径不存在,则需新建),将完整解压命令复制粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
- 修改容器中/etc/profile文件,设置Flink环境变量并使环境变量生效。在容器中/opt目录下运行命令flink --version,将命令与结果截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下;
- 开启Hadoop集群,在yarn上以per job模式(即Job分离模式,不采用Session模式)运行 $FLINK_HOME/examples/batch/WordCount.jar,将运行结果最后10行截图粘贴至客户端桌面【Release\任务A提交结果.docx】中对应的任务序号下。
示例 :
flink run -m yarn-cluster -p 2 -yjm 2G -ytm 2G $FLINK_HOME/examples/batch/WordCount.jar
任务B:离线数据处理(25分)
环境说明:
| 服务端登录地址详见各任务服务端说明。 补充说明:各节点可通过Asbru工具或SSH客户端进行SSH访问; 主节点MySQL数据库用户名/密码:root/123456(已配置远程连接); Spark任务在Yarn上用Client运行,方便观察日志。 |
子任务一:数据抽取
编写Scala代码,使用Spark将MySQL的shtd_store库中表user_info、sku_info、base_province、base_region、order_info、order_detail的数据增量抽取到Hudi的ods_ds_hudi库(路径为/user/hive/warehouse/ods_ds_hudi.db)的user_info、sku_info、base_province、base_region、order_info、order_detail中。(若ods_ds_hudi库中部分表没有数据,正常抽取即可)
- 抽取shtd_store库中user_info的增量数据进入Hudi的ods_ds_hudi库中表user_info。根据ods_ds_hudi.user_info表中operate_time或create_time作为增量字段(即MySQL中每条数据取这两个时间中较大的那个时间作为增量字段去和ods里的这两个字段中较大的时间进行比较),只将新增的数据抽入,字段名称、类型不变,同时添加分区,若operate_time为空,则用create_time填充,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,operate_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.user_info命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取shtd_store库中sku_info的增量数据进入Hudi的ods_ds_hudi库中表sku_info。根据ods_ds_hudi.sku_info表中create_time作为增量字段,只将新增的数据抽入,字段名称、类型不变,同时添加分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,operate_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.sku_info命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取shtd_store库中base_province的增量数据进入Hudi的ods_ds_hudi库中表base_province。根据ods_ds_hudi.base_province表中id作为增量字段,只将新增的数据抽入,字段名称、类型不变并添加字段create_time取当前时间,同时添加分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,create_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.base_province命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取shtd_store库中base_region的增量数据进入Hudi的ods_ds_hudi库中表base_region。根据ods_ds_hudi.base_region表中id作为增量字段,只将新增的数据抽入,字段名称、类型不变并添加字段create_time取当前时间,同时添加分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,create_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.base_region命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取shtd_store库中order_info的增量数据进入Hudi的ods_ds_hudi库中表order_info,根据ods_ds_hudi.order_info表中operate_time或create_time作为增量字段(即MySQL中每条数据取这两个时间中较大的那个时间作为增量字段去和ods里的这两个字段中较大的时间进行比较),只将新增的数据抽入,字段名称、类型不变,同时添加分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,operate_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.order_info命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取shtd_store库中order_detail的增量数据进入Hudi的ods_ds_hudi库中表order_detail,根据ods_ds_hudi.order_detail表中create_time作为增量字段,只将新增的数据抽入,字段名称、类型不变,同时添加分区,分区字段为etl_date,类型为String,且值为当前比赛日的前一天日期(分区字段格式为yyyyMMdd)。id作为primaryKey,create_time作为preCombineField。使用spark-shell执行show partitions ods_ds_hudi.order_detail命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下。
子任务二:数据清洗
编写Scala代码,使用Spark将ods库中相应表数据全量抽取到Hudi的dwd_ds_hudi库(路径为路径为/user/hive/warehouse/dwd_ds_hudi.db)中对应表中。表中有涉及到timestamp类型的,均要求按照yyyy-MM-dd HH:mm:ss,不记录毫秒数,若原数据中只有年月日,则在时分秒的位置添加00:00:00,添加之后使其符合yyyy-MM-dd HH:mm:ss。(若dwd_ds_hudi库中部分表没有数据,正常抽取即可)
- 抽取ods_ds_hudi库中user_info表中昨天的分区(子任务一生成的分区)数据,并结合dim_user_info最新分区现有的数据,根据id合并数据到dwd_ds_hudi库中dim_user_info的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段,根据operate_time排序取最新的一条),分区字段为etl_date且值与ods_ds_hudi库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。若该条记录第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均存当前操作时间,并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。id作为primaryKey,operate_time作为preCombineField。使用spark-shell执行show partitions dwd_ds_hudi.dim_user_info命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取ods_ds_hudi库sku_info表中昨天的分区(子任务一生成的分区)数据,并结合dim_sku_info最新分区现有的数据,根据id合并数据到dwd_ds_hudi库中dim_sku_info的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段,根据create_time排序取最新的一条),分区字段为etl_date且值与ods_ds_hudi库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。若该条数据第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。id作为primaryKey,dwd_modify_time作为preCombineField。使用spark-shell查询表dim_sku_info的字段id、sku_desc、dwd_insert_user、dwd_modify_time、etl_date,条件为最新分区的数据,id大于等于15且小于等于20,并且按照id升序排序,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取ods_ds_hudi库base_province表中昨天的分区(子任务一生成的分区)数据,并结合dim_province最新分区现有的数据,根据id合并数据到dwd_ds_hudi库中dim_province的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段,根据create_time排序取最新的一条),分区字段为etl_date且值与ods_ds_hudi库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。若该条数据第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。id作为primaryKey,dwd_modify_time作为preCombineField。使用spark-shell在表dwd.dim_province最新分区中,查询该分区中数据的条数,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 抽取ods_ds_hudi库base_region表中昨天的分区(子任务一生成的分区)数据,并结合dim_region最新分区现有的数据,根据id合并数据到dwd_ds_hudi库中dim_region的分区表(合并是指对dwd层数据进行插入或修改,需修改的数据以id为合并字段,根据create_time排序取最新的一条),分区字段为etl_date且值与ods_ds_hudi库的相对应表该值相等,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”。若该条数据第一次进入数仓dwd层则dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。若该数据在进入dwd层时发生了合并修改,则dwd_insert_time时间不变,dwd_modify_time存当前操作时间,其余列存最新的值。id作为primaryKey,dwd_modify_time作为preCombineField。使用spark-shell在表dwd.dim_region最新分区中,查询该分区中数据的条数,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 将ods_ds_hudi库中order_info表昨天的分区(子任务一生成的分区)数据抽取到dwd_ds_hudi库中fact_order_info的动态分区表,分区字段为etl_date,类型为String,取create_time值并将格式转换为yyyyMMdd,同时若operate_time为空,则用create_time填充,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。id作为primaryKey,operate_time作为preCombineField。使用spark-shell执行show partitions dwd.fact_order_info命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 将ods_ds_hudi库中order_detail表昨天的分区(子任务一中生成的分区)数据抽取到dwd_ds_hudi库中fact_order_detail的动态分区表,分区字段为etl_date,类型为String,取create_time值并将格式转换为yyyyMMdd,并添加dwd_insert_user、dwd_insert_time、dwd_modify_user、dwd_modify_time四列,其中dwd_insert_user、dwd_modify_user均填写“user1”,dwd_insert_time、dwd_modify_time均填写当前操作时间,并进行数据类型转换。id作为primaryKey,dwd_modify_time作为preCombineField。使用spark-shell执行show partitions dwd_ds_hudi.fact_order_detail命令,将结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下。
子任务三:指标计算
编写Scala代码,使用Spark计算相关指标。
注:在指标计算中,不考虑订单信息表中order_status字段的值,将所有订单视为有效订单。计算订单金额或订单总金额时只使用final_total_amount字段。需注意dwd_ds_hudi所有的维表取最新的分区。
- 本任务基于以下2、3、4小题完成,使用Azkaban完成第2、3、4题任务代码的调度。工作流要求,使用shell输出“开始”作为工作流的第一个job(job1),2、3、4题任务为串行任务且它们依赖job1的完成(命名为job2、job3、job4),job2、job3、job4完成之后使用shell输出“结束”作为工作流的最后一个job(endjob),endjob依赖job2、job3、job4,并将最终任务调度完成后的工作流截图,将截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
- 根据dwd_ds_hudi层表统计每人每天下单的数量和下单的总金额,存入Hudi的dws_ds_hudi层的user_consumption_day_aggr表中(表结构如下),然后使用spark -shell按照客户主键、订单总金额均为降序排序,查询出前5条,将SQL语句复制粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下
字段
类型
中文含义
备注
uuid
string
随机字符
随机字符,保证不同即可,作为primaryKey
user_id
int
客户主键
user_name
string
客户名称
total_amount
double
订单总金额
当天订单总金额。
total_count
int
订单总数
当天订单总数。同时可作为preCombineField(作为合并字段时,无意义,因为主键为随机生成)
year
int
年
订单产生的年,为动态分区字段
month
int
月
订单产生的月,为动态分区字段
day
int
日
订单产生的日,为动态分区字段
- 根据dwd_ds_hudi库中的表统计每个省每月下单的数量和下单的总金额,并按照year,month,region_id进行分组,按照total_amount逆序排序,形成sequence值,将计算结果存入Hudi的dws_ds_hudi数据库province_consumption_day_aggr表中(表结构如下),然后使用spark-shell根据订单总数、订单总金额、省份表主键均为降序排序,查询出前5条,在查询时对于订单总金额字段将其转为bigint类型(避免用科学计数法展示),将SQL语句复制粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
字段
类型
中文含义
备注
uuid
string
随机字符
随机字符,保证不同即可,作为primaryKey
province_id
int
省份表主键
province_name
string
省份名称
region_id
int
地区主键
region_name
string
地区名称
total_amount
double
订单总金额
当月订单总金额
total_count
int
订单总数
当月订单总数。同时可作为preCombineField(作为合并字段时,无意义,因为主键为随机生成)
sequence
int
次序
year
int
年
订单产生的年,为动态分区字段
month
int
月
订单产生的月,为动态分区字段
- 请根据dws_ds_hudi库中的表计算出每个省份2020年4月的平均订单金额和该省所在地区平均订单金额相比较结果(“高/低/相同”),存入ClickHouse数据库shtd_result的provinceavgcmpregion表中(表结构如下),然后在Linux的ClickHouse命令行中根据省份表主键、省平均订单金额、地区平均订单金额均为降序排序,查询出前5条,将SQL语句复制粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下,将执行结果截图粘贴至客户端桌面【Release\任务B提交结果.docx】中对应的任务序号下;
字段
类型
中文含义
备注
provinceid
int
省份表主键
provincename
text
省份名称
provinceavgconsumption
double
该省平均订单金额
region_id
int
地区表主键
region_name
text
地区名称
regionavgconsumption
double
地区平均订单金额
该省所在地区平均订单金额
comparison
text
比较结果
省平均订单金额和该省所在地区平均订单金额比较结果,值为:高/低/相同
任务C:数据挖掘(10分)
环境说明:
| 服务端登录地址详见各任务服务端说明。 补充说明:各节点可通过Asbru工具或SSH客户端进行SSH访问; 主节点MySQL数据库用户名/密码:root/123456(已配置远程连接); Spark任务在Yarn上用Client运行,方便观察日志。 该任务均使用Scala编写,利用Spark相关库完成。 |
子任务一:特征工程
剔除订单信息表与订单详细信息表中用户id与商品id不存在现有的维表中的记录,同时建议多利用缓存并充分考虑并行度来优化代码,达到更快的计算效果。
- 根据Hudi的dwd库中相关表或MySQL中shtd_store中相关表(order_detail、sku_info),计算出与用户id为6708的用户所购买相同商品种类最多的前10位用户(只考虑他俩购买过多少种相同的商品,不考虑相同的商品买了多少次),将10位用户id进行输出,若与多个用户购买的商品种类相同,则输出结果按照用户id升序排序,输出格式如下,将结果截图粘贴至客户端桌面【Release\任务C提交结果.docx】中对应的任务序号下;
结果格式如下:
-------------------相同种类前10的id结果展示为:--------------------
1,2,901,4,5,21,32,91,14,52
- 根据Hudi的dwd库中相关表或MySQL中shtd_store中相关商品表(sku_info),获取id、spu_id、price、weight、tm_id、category3_id 这六个字段并进行数据预处理,对price、weight进行规范化(StandardScaler)处理,对spu_id、tm_id、category3_id进行one-hot编码处理(若该商品属于该品牌则置为1,否则置为0),并按照id进行升序排序,在集群中输出第一条数据前10列(无需展示字段名),将结果截图粘贴至客户端桌面【Release\任务C提交结果.docx】中对应的任务序号下。
| 字段 | 类型 | 中文含义 | 备注 |
| id | double | 主键 | |
| price | double | 价格 | |
| weight | double | 重量 | |
| spu_id#1 | double | spu_id 1 | 若属于该spu_id,则内容为1否则为0 |
| spu_id#2 | double | spu_id 2 | 若属于该spu_id,则内容为1否则为0 |
| ..... | double | ||
| tm_id#1 | double | 品牌1 | 若属于该品牌,则内容为1否则为0 |
| tm_id#2 | double | 品牌2 | 若属于该品牌,则内容为1否则为0 |
| …… | double | ||
| category3_id#1 | double | 分类级别3 1 | 若属于该分类级别3,则内容为1否则为0 |
| category3_id#2 | double | 分类级别3 2 | 若属于该分类级别3,则内容为1否则为0 |
| …… |
结果格式如下:
--------------------第一条数据前10列结果展示为:---------------------
1.0,0.892346,1.72568,0.0,0.0,0.0,0.0,1.0,0.0,0.0
子任务二:推荐系统
- 根据子任务一的结果,计算出与用户id为6708的用户所购买相同商品种类最多的前10位用户id(只考虑他俩购买过多少种相同的商品,不考虑相同的商品买了多少次),并根据Hudi的dwd库中相关表或MySQL数据库shtd_store中相关表,获取到这10位用户已购买过的商品,并剔除用户6708已购买的商品,通过计算这10位用户已购买的商品(剔除用户6708已购买的商品)与用户6708已购买的商品数据集中商品的余弦相似度累加再求均值,输出均值前5商品id作为推荐使用,将执行结果截图粘贴至客户端桌面【Release\任务C提交结果.docx】中对应的任务序号下。
结果格式如下:
------------------------推荐Top5结果如下------------------------
相似度top1(商品id:1,平均相似度:0.983456)
相似度top2(商品id:71,平均相似度:0.782672)
相似度top3(商品id:22,平均相似度:0.7635246)
相似度top4(商品id:351,平均相似度:0.7335748)
相似度top5(商品id:14,平均相似度:0.522356)
任务D:数据采集与实时计算(20分)
环境说明:
| 服务端登录地址详见各任务服务端说明。 补充说明:各节点可通过Asbru工具或SSH客户端进行SSH访问; Flink任务在Yarn上用per job模式(即Job分离模式,不采用Session模式),方便Yarn回收资源。 |
子任务一:实时数据采集
- 在主节点使用Flume采集实时数据生成器10050端口的socket数据,将数据存入到Kafka的Topic中(Topic名称为order,分区数为4),使用Kafka自带的消费者消费order(Topic)中的数据,将前2条数据的结果截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下;
- 采用多路复用模式,Flume接收数据注入kafka 的同时,将数据备份到HDFS目录/user/test/flumebackup下,将查看备份目录下的第一个文件的前2条数据的命令与结果截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下。
子任务二:使用Flink处理Kafka中的数据
编写Scala代码,使用Flink消费Kafka中Topic为order的数据并进行相应的数据统计计算(订单信息对应表结构order_info,订单详细信息对应表结构order_detail(来源类型和来源编号这两个字段不考虑,所以在实时数据中不会出现),同时计算中使用order_info或order_detail表中create_time或operate_time取两者中值较大者作为EventTime,若operate_time为空值或无此列,则使用create_time填充,允许数据延迟5s,订单状态order_status分别为1001:创建订单、1002:支付订单、1003:取消订单、1004:完成订单、1005:申请退回、1006:退回完成。另外对于数据结果展示时,不要采用例如:1.9786518E7的科学计数法)。
- 使用Flink消费Kafka中的数据,统计商城实时订单数量(需要考虑订单状态,若有取消订单、申请退回、退回完成则不计入订单数量,其他状态则累加),将key设置成totalcount存入Redis中。使用redis cli以get key方式获取totalcount值,将结果截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下,需两次截图,第一次截图和第二次截图间隔1分钟以上,第一次截图放前面,第二次截图放后面;
- 在任务1进行的同时,使用侧边流,统计每分钟申请退回订单的数量,将key设置成refundcountminute存入Redis中。使用redis cli以get key方式获取refundcountminute值,将结果截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下,需两次截图,第一次截图和第二次截图间隔1分钟以上,第一次截图放前面,第二次截图放后面;
- 在任务1进行的同时,使用侧边流,计算每分钟内状态为取消订单占所有订单的占比,将key设置成cancelrate存入Redis中,value存放取消订单的占比(为百分比,保留百分比后的一位小数,四舍五入,例如12.1%)。使用redis cli以get key方式获取cancelrate值,将结果截图粘贴至客户端桌面【Release\任务D提交结果.docx】中对应的任务序号下,需两次截图,第一次截图和第二次截图间隔1分钟以上,第一次截图放前面,第二次截图放后面。
任务E:数据可视化(15分)
环境说明:
| 数据接口地址及接口描述详见各任务服务端说明。 |
子任务一:用柱状图展示各省份消费额的中位数
编写Vue工程代码,根据接口,用柱状图展示2020年部分省份所有订单消费额的中位数(前10省份,降序排列,若有小数则四舍五入保留两位),同时将用于图表展示的数据结构在浏览器的console中进行打印输出,将图表可视化结果和浏览器console打印结果分别截图并粘贴至客户端桌面【Release\任务E提交结果.docx】中对应的任务序号下。
子任务二:用玫瑰图展示各地区消费能力
编写Vue工程代码,根据接口,用基础南丁格尔玫瑰图展示2020年各地区的消费总额占比,同时将用于图表展示的数据结构在浏览器的console中进行打印输出,将图表可视化结果和浏览器console打印结果分别截图并粘贴至客户端桌面【Release\任务E提交结果.docx】中对应的任务序号下。
子任务三:用折线图展示每年上架商品数量的变化
编写Vue工程代码,根据接口,用折线图展示每年上架商品数量的变化情况,同时将用于图表展示的数据结构在浏览器的console中进行打印输出,将图表可视化结果和浏览器console打印结果分别截图并粘贴至客户端桌面【Release\任务E提交结果.docx】中对应的任务序号下。
子任务四:用条形图展示消费总额最高的省份
编写Vue工程代码,根据接口,用条形图展示2020年消费总额最高的10个省份,同时将用于图表展示的数据结构在浏览器的console中进行打印输出,将图表可视化结果和浏览器console打印结果分别截图并粘贴至客户端桌面【Release\任务E提交结果.docx】中对应的任务序号下。
子任务五:用折柱混合图展示省份平均消费额和地区平均消费额
编写Vue工程代码,根据接口,用折柱混合图展示2020年各省份平均消费额(四舍五入保留两位小数)和地区平均消费额(四舍五入保留两位小数)的对比情况,柱状图展示平均消费额最高的5个省份,折线图展示这5个省所在的地区的平均消费额变化,同时将用于图表展示的数据结构在浏览器的console中进行打印输出,将图表可视化结果和浏览器console打印结果分别截图并粘贴至客户端桌面【Release\任务E提交结果.docx】中对应的任务序号下。
任务F:综合分析(10分)
子任务一:Kafka中的数据如何保证不丢失?
在任务D中使用到了Kafka,将内容编写至客户端桌面【Release\任务F提交结果.docx】中对应的任务序号下。
子任务二:请描述HBase的rowkey设计原则。
请简要概述HBase的rowkey的重要性并说明在设计rowkey时应遵循哪些原则,将内容编写至客户端桌面【Release\任务F提交结果.docx】中对应的任务序号下。
子任务三:Spark的数据本地性有哪几种,分别表示什么?
在任务B与任务C中使用到了Spark,其中有些JOB运行较慢,有些较快,一部分原因与数据位置和计算位置相关,其数据本地性可以在SparkUI中查看到。请问Spark的数据本地性有哪几种(英文)?分别表示的含义是什么(中文)?将内容编写至客户端桌面【Release\任务F提交结果.docx】中对应的任务序号下。
相关文章:

【大数据应用开发】2023年全国职业院校技能大赛赛题第02套
需要技能竞赛软件测试资料的同学们可s聊我,详细了解 目录 任务A:大数据平台搭建(容器环境)(15分) 任务B:离线数据处理(25分 任务C:数据挖掘(10分…...

2. 将GitHub上的开源项目导入(clone)到(Linux)服务器上——深度学习·科研实践·从0到1
目录 1. 在github上搜项目 (以OpenOcc为例) 2. 转移到码云Gitee上 3. 进入Linux服务器终端 (jupyter lab) 4. 常用Linux命令 5. 进入对应文件夹中导入项目(代码) 注意:系统盘和数据盘 1. 在github上搜项目 (以OpenOcc为例) 把链接复制下…...

毕业设计项目——基于transformer的中文医疗领域命名实体识别(论文/代码)
完整的论文代码见文章末尾 以下为核心内容 摘要 近年来,随着深度学习技术的发展,基于Transformer和BERT的模型在自然语言处理领域取得了显著进展。在中文医疗领域,命名实体识别(Named Entity Recognition, NER)是一项重要任务,旨…...
)
电子信息类专业技术学习及比赛路线总结(大一到大三)
本文主要是总结到目前为止电子信息类的专业技能、比赛路线,以后会持续更新,希望能为那些热爱电子技术或渴望学习课本之外知识的小伙伴们提供帮助,参加学科竞赛和找工作必备。(毕竟很多课本上的内容都没什么用 ) 1.单片…...
的所有输出保存到log/txt中?)
怎么将bash(sh)的所有输出保存到log/txt中?
tee 命令 这会将所有输出同时显示在屏幕上并追加到日志文件中。 bash your_script.sh 2>&1 | tee -a log_file.txt 其他方法不可用 只使用 >> 不会将除了print之外的所有保存 bash your_script.sh >> log_file.txt >> 和 2>&1一起只会保存在日…...

腾讯云服务器上使用Nginx部署的静态网站打开速度慢的原因分析及优化解决方案
目录 前言1. 网站打开速度慢的原因分析1.1 服务器配置不足1.2 网络延迟1.3 Nginx配置不合理1.4 静态资源未优化 2. 网站速度的测试与分析2.1 使用浏览器开发者工具分析2.2 在线工具测试 3. 网站优化的具体方法3.1 服务器配置优化3.2 CDN加速与DNS优化3.3 优化Nginx配置3.3.1 启…...
如何移除 iPhone 上的网络锁?本文筛选了一些适合您的工具
您是否对 iPhone 运营商的网络感到困惑?不用担心,我们将向您介绍 8 大免费 iPhone 解锁服务。这些工具可以帮助您移除 iPhone 上的网络锁,并使您能够永久在网络上使用您的设备。如果您想免费解锁 iPhone,请阅读本文并找到最适合您…...

深度学习:CycleGAN图像风格迁移转换
目录 基础概念 模型工作流程 循环一致性 几个基本概念 假图像(Fake Image) 重建图像(Reconstructed Image) 身份映射图像(Identity Mapping Image) CyclyGAN损失函数 对抗损失 身份鉴别损失 Cyc…...

pytorch和yolo区别
PyTorch与YOLO的区别:一个简明的科普 在深度学习的领域,有许多工具和框架帮助研究人员和开发者快速实现复杂的模型。其中,PyTorch与YOLO(You Only Look Once)是两个非常重要的名词。本文旨在探讨这两个技术之间的区别&…...
使用树莓派搭建音乐服务器
目录 引言一、搭建Navidrome二、服务穿透三、音流配置 引言 本人手机存储空间128G,网易云音乐6个G,本就不富裕的空间更是雪上加霜,而且重点是,我根本没有听几首歌,清除缓存后,整个软件都还是占用了5个G左右…...

单链表的分解
编写算法创建以整数为数据元素的单向链表,实现将其分解成两个链表,其中一个全部为奇数,另一个全部为偶数(尽量利用已知的存储空间)。 输入格式: 1 2 3 4 5 6 7 8 9 0 输出格式: 1 3 5 7 9 2 4 6 8 输入样例: …...

[OS] 4.Linux 内核
1. 下载 Linux 内核源代码 首先,你需要从官方站点或镜像站点下载 Linux 内核源代码。 官方源代码:The Linux Kernel Archives 清华大学镜像站点:Index of /kernel/v5.x/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror 下载 .t…...

flutter_鸿蒙next_Dart基础③函数
目录 说在前面 1. 函数的基本定义 例子 代码解释 2. 函数的调用 代码解释 3. 可选参数与命名参数 可选参数 代码解释 调用示例 命名参数 代码解释 调用示例 4. 匿名函数与高阶函数 例子 代码解释 说在最后 说在前面 在 Dart 编程语言中,函数是构建…...

基于猎豹优化算法(The Cheetah Optimizer,CO)的多无人机协同三维路径规划(提供MATLAB代码)
一、猎豹优化算法 猎豹优化算法(The Cheetah Optimizer,CO)由MohammadAminAkbari等人于2022年提出,该算法性能高效,思路新颖。 参考文献: Akbari, M.A., Zare, M., Azizipanah-abarghooee, R. et al. The…...

Linux:进程的创建、终止和等待
一、进程创建 1.1 fork函数初识 #include pid_t fork(void); 返回值:子进程中返回0,父进程返回子进程id,出错返回-1 调用fork函数后,内核做了下面的工作: 1、创建了一个子进程的PCB结构体、并拷贝一份相同的进程地址…...

数值优化基础——基于优化的规划算法
1 最优化问题的一般形式 最优化问题:满足一系列约束的可行域内,找到使得目标函数最小的解 min f ( x ) s.t. x...

括号匹配——(栈实现)
题目链接 有效的括号https://leetcode.cn/problems/valid-parentheses/description/ 题目要求 样例 解题代码 import java.util.*; class Solution {public boolean isValid(String str) {Stack<Character> stacknew Stack<>();for(int i0;i<str.length();i)…...

【Java 并发编程】初识多线程
前言 到目前为止,我们学到的都是有关 “顺序” 编程的知识,即程序中所有事物在任意时刻都只能执行一个步骤。例如:在我们的 main 方法中,都是多个操作以 “从上至下” 的顺序调用方法以至结束的。 虽然 “顺序” 编程能够解决相当…...

Linux下载安装MySQL8.4
这里写目录标题 一、准备工作查看系统环境查看系统架构卸载已安装的版本 二、下载MySQL安装包官网地址 三、安装过程上传到服务器目录解压缩,设置目录及权限配置my.cnf文件初始化数据库配置MySQL开放端口 一、准备工作 查看系统环境 确认Linux系统的版本和架构&am…...
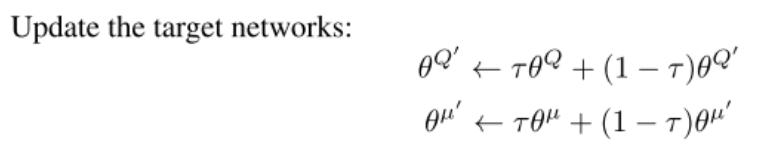
强化学习笔记之【DDPG算法】
强化学习笔记之【DDPG算法】 文章目录 强化学习笔记之【DDPG算法】前言:原论文伪代码DDPG算法DDPG 中的四个网络代码核心更新公式 前言: 本文为强化学习笔记第二篇,第一篇讲的是Q-learning和DQN 就是因为DDPG引入了Actor-Critic模型&#x…...
)
极简风项目交付倒计时!:紧急修复MJ --v 6.2中隐藏的1.33倍宽高比偏移Bug,避免客户验收驳回(含补救Prompt包)
更多请点击: https://intelliparadigm.com 第一章:极简风项目交付倒计时! 当交付周期压缩至 72 小时,极简风不再是一种美学选择,而是工程效率的刚性约束。我们摒弃冗余文档、跳过非核心评审环节,聚焦于可…...

Ix开源平台:基于Kubernetes的私有云与家庭实验室一体化管理方案
1. 项目概述与核心价值最近在折腾一个叫Ix的开源项目,它来自ix-infrastructure这个组织。乍一看这个名字,你可能觉得有点抽象,但如果你对自托管、家庭实验室、私有云或者想找一个更现代、更易用的 TrueNAS 替代品感兴趣,那这个项目…...

暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手
暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为暗黑破坏神3玩…...

YimMenu终极配置指南:从零开始掌握GTA V高级菜单工具
YimMenu终极配置指南:从零开始掌握GTA V高级菜单工具 【免费下载链接】YimMenu YimMenu, a GTA V menu protecting against a wide ranges of the public crashes and improving the overall experience. 项目地址: https://gitcode.com/GitHub_Trending/yi/YimMe…...

树莓派机械爪项目实战:从硬件连接到Python控制全解析
1. 项目概述:当树莓派遇上机械爪最近在折腾一个挺有意思的小项目,叫Demwunz/openclaw-pi-installation。光看这个名字,就能猜到个大概:这是一个为树莓派(Raspberry Pi)准备的机械爪(Claw&#x…...

基于声明式Web自动化框架Hydra的电商数据监控实战
1. 项目概述:一个被低估的自动化利器 如果你经常需要处理一些重复性的、基于Web界面的操作,比如批量下载某个网站的资源、定时填写表单、或者监控网页内容的变化,那么你很可能已经厌倦了手动点击和等待。传统的脚本编写,尤其是涉及…...

OpenClaw-Subcortex:轻量级自动化任务编排与执行框架详解
1. 项目概述与核心价值最近在折腾一些自动化工具,发现一个挺有意思的项目叫openclaw-subcortex。乍一看这个名字,可能有点摸不着头脑,又是“爪子”又是“皮层下”的,感觉像是什么生物或者神经科学的东西。但实际上,这是…...

LoRA模型合并实战:多技能大模型融合指南与vLLM+Copaw工具链解析
1. 项目概述:LoRA模型合并的“瑞士军刀” 在AIGC(人工智能生成内容)领域,模型微调是让大语言模型(LLM)或扩散模型适配特定任务、风格或知识库的核心手段。而LoRA(Low-Rank Adaptation࿰…...

基于HTML5 Canvas的轻量级图像标注库visual-annotator集成指南
1. 项目概述:一个为开发者打造的视觉标注利器如果你做过图像识别、目标检测或者任何需要处理大量图片标注的计算机视觉项目,那你一定对标注工具不陌生。从早期的LabelImg到后来的CVAT、Label Studio,工具的选择往往决定了你项目前期数据准备的…...

湿版摄影风格失效的5个致命误区,第4个连Midjourney官方文档都未披露——基于217组AB测试的权威归因报告
更多请点击: https://intelliparadigm.com 第一章:湿版摄影风格失效的5个致命误区,第4个连Midjourney官方文档都未披露——基于217组AB测试的权威归因报告 为何“wet plate collodion”提示词突然失灵? 在 Midjourney v6.1 及 N…...