重学SpringBoot3-集成Redis(五)之布隆过滤器
更多SpringBoot3内容请关注我的专栏:《SpringBoot3》
期待您的点赞👍收藏⭐评论✍
重学SpringBoot3-集成Redis(五)之布隆过滤器
- 1. 什么是布隆过滤器?
- 基本概念
- 适用场景
- 2. 使用 Redis 实现布隆过滤器
- 项目依赖
- Redis 配置
- 3. 创建布隆过滤器服务
- 4. 布隆过滤器的初始化
- 5. 使用布隆过滤器进行缓存穿透防护
- 6. 测试效果
- 6.1. 启动项目
- 6.2. 查询存在的商品
- 6.3. 查询不存在的商品
- 7. 总结
在高并发场景下,缓存是提升系统性能的重要手段。然而,常规缓存机制中,若遇到大量无效请求访问(请求的 key 不存在于缓存或数据库),就会导致 缓存穿透。为了应对这种问题,布隆过滤器 和 缓存空值 是应对缓存穿透的两大主流方案,布隆过滤器适用于大规模、复杂场景,缓存空值适用于小规模场景。布隆过滤器(Bloom Filter) 能够通过哈希算法判断一个 key 是否可能存在,减少无效请求对数据库的压力。
本篇博客将介绍如何使用 Spring Boot 3 和 Redis 实现布隆过滤器,并结合示例代码来详细讲解布隆过滤器的原理和在 Redis 中的实现方式。
1. 什么是布隆过滤器?
基本概念
布隆过滤器是一种空间效率高的 概率性数据结构,用于快速判断某个元素是否在集合中。它有以下特点:
- 内存占用小:相比传统的集合结构,布隆过滤器的内存使用更少。
- 可能存在误判:布隆过滤器只能确定某个元素“可能存在”或“绝对不存在”。但存在误判的概率可以通过调整参数降低。
- 不支持删除:布隆过滤器不支持删除已添加的元素,删除某个元素会导致误判率增加。


适用场景
布隆过滤器在以下场景中非常适用:
- 防止缓存穿透:将不存在的 key 存储在布隆过滤器中,避免大量无效请求直接查询数据库。
- 防止重复数据:在大规模数据处理中,使用布隆过滤器避免重复处理相同的数据。
2. 使用 Redis 实现布隆过滤器
Redis 提供了开箱即用的布隆过滤器功能,通过 Redis 的插件 RedisBloom,安装过程参考:Redis安装RedisBloom,我们可以非常方便地使用布隆过滤器存储和管理 key。
项目依赖
首先,在 Spring Boot 项目中引入相关依赖,可参考之前文章。需要 Redis 的支持,以及 Spring Data Redis 来实现与 Redis 的交互。
注意: Redisson 提供了对布隆过滤器的支持,具体实现会利用它的 API。
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency><groupId>org.redisson</groupId><artifactId>redisson-spring-boot-starter</artifactId><version>3.20.0</version>
</dependency>
Redis 配置
在 application.yml 文件中配置 Redis 的连接信息,详细请参考上一章重学SpringBoot3-集成Redis(四)之Redisson,进行 Redisson 配置。
spring:redis:redisson:config: |singleServerConfig:address: redis://1.94.26.81:6379 # Redis 连接地址,前缀为 redis://password: redis123456 # 如果 Redis 需要密码认证,则填写密码timeout: 3000 # 命令执行超时时间(毫秒)
配置类中初始化 Redisson 客户端:
package com.coderjia.boot310redis.config;import org.redisson.Redisson;
import org.redisson.api.RedissonClient;
import org.redisson.config.Config;
import org.redisson.spring.starter.RedissonProperties;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;/*** @author CoderJia* @create 2024/10/5 下午 04:53* @Description**/
@Configuration
public class RedissonConfig {@Autowiredprivate RedissonProperties redissonProperties;@Beanpublic RedissonClient redissonClient() throws Exception{Config config = Config.fromYAML(redissonProperties.getConfig());Redisson.create(config);System.out.println("Redisson 已启动");return Redisson.create(config);}}
3. 创建布隆过滤器服务
接下来,我们需要定义一个服务来管理布隆过滤器。利用 Redisson 提供的 API,可以轻松实现布隆过滤器。
import org.redisson.api.RBloomFilter;
import org.redisson.api.RedissonClient;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Service;@Service
public class BloomFilterService {private static final String BLOOM_FILTER_NAME = "bloomFilter";@Autowiredprivate RedissonClient redissonClient;// 初始化布隆过滤器public void initBloomFilter(long expectedInsertions, double falseProbability) {RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter(BLOOM_FILTER_NAME);bloomFilter.tryInit(expectedInsertions, falseProbability);}// 添加元素到布隆过滤器中public void addToBloomFilter(String key) {RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter(BLOOM_FILTER_NAME);bloomFilter.add(key);}// 检查元素是否存在于布隆过滤器中public boolean mightContain(String key) {RBloomFilter<String> bloomFilter = redissonClient.getBloomFilter(BLOOM_FILTER_NAME);return bloomFilter.contains(key);}
}
代码解释
- 初始化布隆过滤器:
initBloomFilter方法可以根据期望插入的数量和误判率初始化布隆过滤器。布隆过滤器的大小和哈希函数数量根据这些参数自动计算。 - 添加元素:
addToBloomFilter方法向布隆过滤器中添加新的 key。 - 判断元素是否存在:
mightContain方法用来判断某个 key 是否在布隆过滤器中。
4. 布隆过滤器的初始化
通常我们会在应用启动时初始化布隆过滤器,并将数据库中的所有 key 预先加入过滤器。
package com.coderjia.boot310redis.config;import com.coderjia.boot310redis.bean.Product;
import com.coderjia.boot310redis.dao.ProductMapper;
import com.coderjia.boot310redis.service.BloomFilterService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.stereotype.Component;import java.util.List;/*** @author CoderJia* @create 2024/10/6 下午 12:38* @Description**/
@Slf4j
@Component
public class BloomFilterInitializer implements CommandLineRunner {@Autowiredprivate BloomFilterService bloomFilterService;@Autowiredprivate ProductMapper productMapper;@Overridepublic void run(String... args) throws Exception {// 查询所有产品数据List<Product> all = productMapper.findAll();// 初始化布隆过滤器bloomFilterService.initBloomFilter(all.size(), 0.01);// 将所有产品的ID加入布隆过滤器all.forEach(product -> {bloomFilterService.addToBloomFilter(product.getId().toString());});log.info("初始化布隆过滤器完成,添加产品数:{}", all.size());}
}
代码解释
- 在应用启动时,通过
CommandLineRunner初始化布隆过滤器,并将数据库中的所有商品 ID 加入过滤器中。
5. 使用布隆过滤器进行缓存穿透防护
接下来,我们通过一个简单的示例,结合 Redis 的缓存功能和布隆过滤器,展示如何防止缓存穿透。
package com.coderjia.boot310redis.service;import com.coderjia.boot310redis.bean.Product;
import com.coderjia.boot310redis.dao.ProductMapper;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.cache.annotation.Cacheable;
import org.springframework.stereotype.Service;/*** @author CoderJia* @create 2024/10/6 下午 12:37* @Description**/
@Slf4j
@Service
public class ProductService {@Autowiredprivate BloomFilterService bloomFilterService;@Autowiredprivate ProductMapper productMapper;@Cacheable(value = "product", key = "#p0")public Product getProductById(Long id) {// 使用布隆过滤器防止缓存穿透if (!bloomFilterService.mightContain(id.toString())) {throw new IllegalArgumentException("Product not found!");}log.info("准备查询产品信息,id:{}", id);return productMapper.findById(id).orElseThrow(() -> new IllegalArgumentException("Product not found!"));}
}代码解释
- 在查询商品前,首先通过布隆过滤器判断 key 是否可能存在。若布隆过滤器判断 key 不存在,则直接抛出异常,避免查询数据库。
- 如果布隆过滤器判断 key 可能存在,接着通过缓存获取商品数据。如果缓存未命中,则查询数据库。
productMapper 参考:
package com.coderjia.boot310redis.dao;import com.coderjia.boot310redis.bean.Product;
import org.apache.ibatis.annotations.Mapper;import java.util.List;
import java.util.Optional;/*** @author CoderJia* @create 2024/3/16 下午 05:22* @Description**/
@Mapper
public interface ProductMapper {Optional<Product> findById(Long id);List<Product> findAll();
}
Product 也很简单:
package com.coderjia.boot310redis.bean;import lombok.Data;import java.io.Serial;
import java.io.Serializable;/*** @author CoderJia* @create 2024/10/6 下午 12:46* @Description**/
@Data
public class Product implements Serializable {@Serialprivate static final long serialVersionUID = 1L;private Long id;private String name;
}
6. 测试效果
在你的业务逻辑中调用上面创建的 getProductById 方法。
package com.coderjia.boot310redis.demos.web;import com.coderjia.boot310redis.bean.Product;
import com.coderjia.boot310redis.service.LockService;
import com.coderjia.boot310redis.service.ProductService;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;/*** @author CoderJia* @create 2024/10/5 下午 05:14* @Description**/
@Slf4j
@RestController
public class LockController {@Autowiredprivate ProductService productService;@GetMapping("/get-product")public Product getProduct(@RequestParam("id") Long id) {log.info("准备产品产品信息,id:{}", id);try {Product product = productService.getProductById(id);return product;}catch (Exception e) {log.error("获取产品信息异常,id:{}", id, e);return null;}}
}
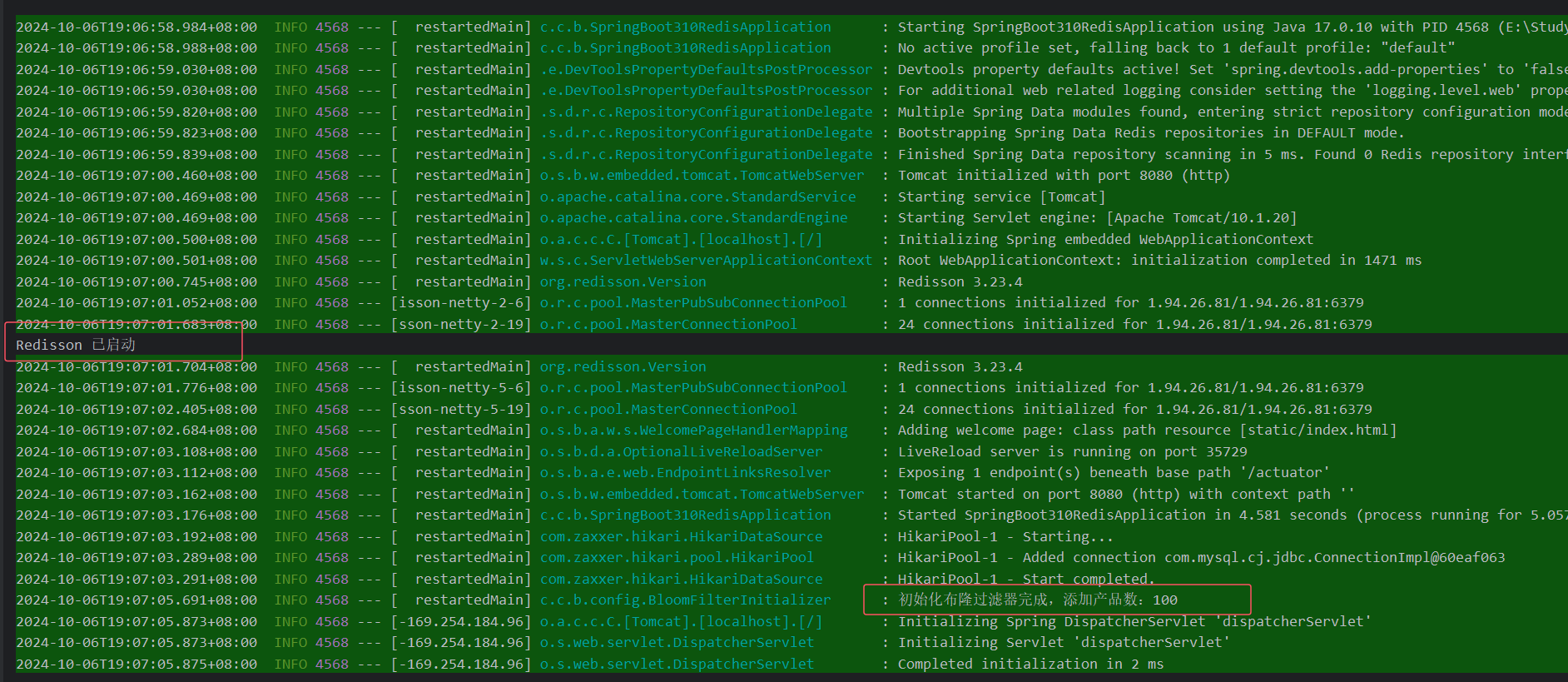
6.1. 启动项目
可以看到布隆过滤器的初始化过程,查询出所有的产品信息并添加到布隆过滤器中。
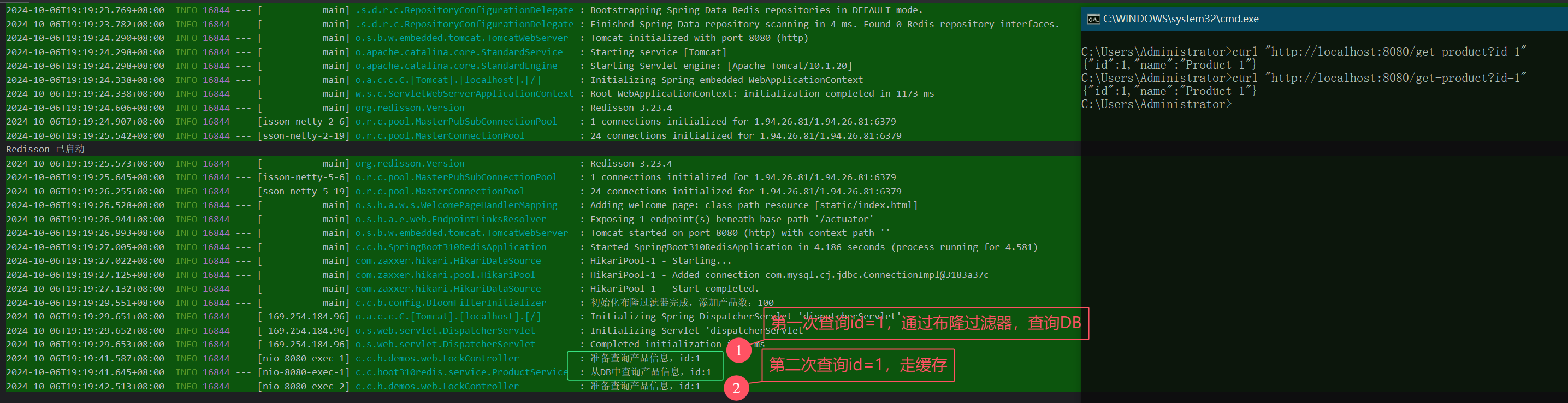
6.2. 查询存在的商品
调用 curl "http://localhost:8080/get-product?id=1" 接口:
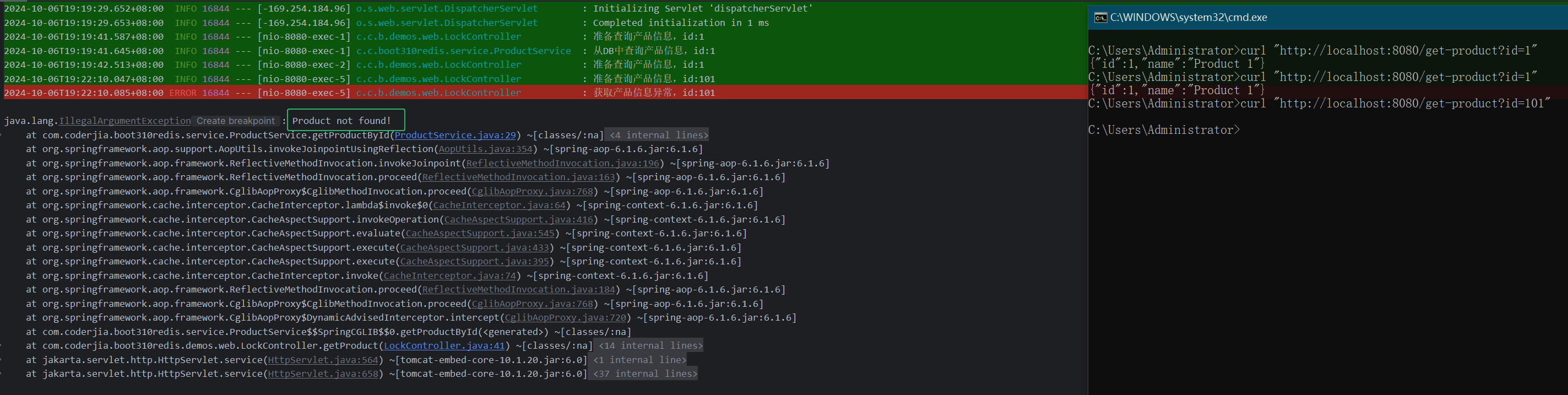
6.3. 查询不存在的商品
调用 curl "http://localhost:8080/get-product?id=101" 接口,产品不存在布隆过滤器器中,直接报错。
7. 总结
通过结合 Spring Boot 3、Redis 和 Redisson,我们可以非常方便地实现布隆过滤器,来防止缓存穿透问题。在高并发场景下,布隆过滤器是一种有效的工具,可以降低数据库的压力,提升系统性能。布隆过滤器并不是万能的,在某些场景下会有少量误判,但结合 Redis 的强大功能,它依然是防止缓存穿透的最佳选择之一。
关键点总结
- 布隆过滤器通过空间换时间,能够快速判断元素是否存在,减少无效请求。
- Redisson 提供了开箱即用的布隆过滤器 API,大大简化了开发工作。
- 在结合缓存时,布隆过滤器可以显著减少数据库查询,提升系统性能。
相关文章:
重学SpringBoot3-集成Redis(五)之布隆过滤器
更多SpringBoot3内容请关注我的专栏:《SpringBoot3》 期待您的点赞👍收藏⭐评论✍ 重学SpringBoot3-集成Redis(五)之布隆过滤器 1. 什么是布隆过滤器?基本概念适用场景 2. 使用 Redis 实现布隆过滤器项目依赖Redis 配置…...

BGP路由原理详解
🐣个人主页 可惜已不在 🐤这篇在这个专栏 华为_可惜已不在的博客-CSDN博客 🐥有用的话就留下一个三连吧😼 目录 一. BGP简介: 二. BGP报文中的角色 BGP的报文 BGP处理过程 BGP有限状态机 BGP属性 三. BGP作用 四. BGP选路 …...

Pytorch实现心跳信号分类识别(支持LSTM,GRU,TCN模型)
Pytorch实现心跳信号分类识别(支持LSTM,GRU,TCN模型) 目录 Pytorch实现心跳信号分类识别(支持LSTM,GRU,TCN模型) 1. 项目说明 2. 数据说明 (1)心跳信号分类预测数据集 3. 模型训练 (1)项目安装 &am…...

AI股市预测的可参考价值有几何?
1. AI技术在股市预测中的应用 首先,AI技术在股市预测中的应用主要包括机器学习、深度学习、自然语言处理(NLP)和量化金融模型等。机器学习算法能够处理和分析大量的金融数据,从中寻找模式和规律。而深度学习特别是在处理复杂的非线…...

【大数据应用开发】2023年全国职业院校技能大赛赛题第02套
需要技能竞赛软件测试资料的同学们可s聊我,详细了解 目录 任务A:大数据平台搭建(容器环境)(15分) 任务B:离线数据处理(25分 任务C:数据挖掘(10分…...

2. 将GitHub上的开源项目导入(clone)到(Linux)服务器上——深度学习·科研实践·从0到1
目录 1. 在github上搜项目 (以OpenOcc为例) 2. 转移到码云Gitee上 3. 进入Linux服务器终端 (jupyter lab) 4. 常用Linux命令 5. 进入对应文件夹中导入项目(代码) 注意:系统盘和数据盘 1. 在github上搜项目 (以OpenOcc为例) 把链接复制下…...

毕业设计项目——基于transformer的中文医疗领域命名实体识别(论文/代码)
完整的论文代码见文章末尾 以下为核心内容 摘要 近年来,随着深度学习技术的发展,基于Transformer和BERT的模型在自然语言处理领域取得了显著进展。在中文医疗领域,命名实体识别(Named Entity Recognition, NER)是一项重要任务,旨…...
)
电子信息类专业技术学习及比赛路线总结(大一到大三)
本文主要是总结到目前为止电子信息类的专业技能、比赛路线,以后会持续更新,希望能为那些热爱电子技术或渴望学习课本之外知识的小伙伴们提供帮助,参加学科竞赛和找工作必备。(毕竟很多课本上的内容都没什么用 ) 1.单片…...
的所有输出保存到log/txt中?)
怎么将bash(sh)的所有输出保存到log/txt中?
tee 命令 这会将所有输出同时显示在屏幕上并追加到日志文件中。 bash your_script.sh 2>&1 | tee -a log_file.txt 其他方法不可用 只使用 >> 不会将除了print之外的所有保存 bash your_script.sh >> log_file.txt >> 和 2>&1一起只会保存在日…...

腾讯云服务器上使用Nginx部署的静态网站打开速度慢的原因分析及优化解决方案
目录 前言1. 网站打开速度慢的原因分析1.1 服务器配置不足1.2 网络延迟1.3 Nginx配置不合理1.4 静态资源未优化 2. 网站速度的测试与分析2.1 使用浏览器开发者工具分析2.2 在线工具测试 3. 网站优化的具体方法3.1 服务器配置优化3.2 CDN加速与DNS优化3.3 优化Nginx配置3.3.1 启…...
如何移除 iPhone 上的网络锁?本文筛选了一些适合您的工具
您是否对 iPhone 运营商的网络感到困惑?不用担心,我们将向您介绍 8 大免费 iPhone 解锁服务。这些工具可以帮助您移除 iPhone 上的网络锁,并使您能够永久在网络上使用您的设备。如果您想免费解锁 iPhone,请阅读本文并找到最适合您…...

深度学习:CycleGAN图像风格迁移转换
目录 基础概念 模型工作流程 循环一致性 几个基本概念 假图像(Fake Image) 重建图像(Reconstructed Image) 身份映射图像(Identity Mapping Image) CyclyGAN损失函数 对抗损失 身份鉴别损失 Cyc…...

pytorch和yolo区别
PyTorch与YOLO的区别:一个简明的科普 在深度学习的领域,有许多工具和框架帮助研究人员和开发者快速实现复杂的模型。其中,PyTorch与YOLO(You Only Look Once)是两个非常重要的名词。本文旨在探讨这两个技术之间的区别&…...
使用树莓派搭建音乐服务器
目录 引言一、搭建Navidrome二、服务穿透三、音流配置 引言 本人手机存储空间128G,网易云音乐6个G,本就不富裕的空间更是雪上加霜,而且重点是,我根本没有听几首歌,清除缓存后,整个软件都还是占用了5个G左右…...

单链表的分解
编写算法创建以整数为数据元素的单向链表,实现将其分解成两个链表,其中一个全部为奇数,另一个全部为偶数(尽量利用已知的存储空间)。 输入格式: 1 2 3 4 5 6 7 8 9 0 输出格式: 1 3 5 7 9 2 4 6 8 输入样例: …...

[OS] 4.Linux 内核
1. 下载 Linux 内核源代码 首先,你需要从官方站点或镜像站点下载 Linux 内核源代码。 官方源代码:The Linux Kernel Archives 清华大学镜像站点:Index of /kernel/v5.x/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror 下载 .t…...

flutter_鸿蒙next_Dart基础③函数
目录 说在前面 1. 函数的基本定义 例子 代码解释 2. 函数的调用 代码解释 3. 可选参数与命名参数 可选参数 代码解释 调用示例 命名参数 代码解释 调用示例 4. 匿名函数与高阶函数 例子 代码解释 说在最后 说在前面 在 Dart 编程语言中,函数是构建…...

基于猎豹优化算法(The Cheetah Optimizer,CO)的多无人机协同三维路径规划(提供MATLAB代码)
一、猎豹优化算法 猎豹优化算法(The Cheetah Optimizer,CO)由MohammadAminAkbari等人于2022年提出,该算法性能高效,思路新颖。 参考文献: Akbari, M.A., Zare, M., Azizipanah-abarghooee, R. et al. The…...

Linux:进程的创建、终止和等待
一、进程创建 1.1 fork函数初识 #include pid_t fork(void); 返回值:子进程中返回0,父进程返回子进程id,出错返回-1 调用fork函数后,内核做了下面的工作: 1、创建了一个子进程的PCB结构体、并拷贝一份相同的进程地址…...

数值优化基础——基于优化的规划算法
1 最优化问题的一般形式 最优化问题:满足一系列约束的可行域内,找到使得目标函数最小的解 min f ( x ) s.t. x...

对比直接使用厂商 API 体验 Taotoken 在模型切换上的便利性
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接使用厂商 API 体验 Taotoken 在模型切换上的便利性 在个人开发项目中接入大模型时,开发者通常面临一个选择&am…...

ARMv8-AArch64 异常处理实战:从寄存器解析到调试技巧
1. ARMv8-AArch64异常处理入门指南 第一次接触ARMv8架构的异常处理时,我被那一堆寄存器搞得头晕眼花。ELR、ESR、FAR...这些缩写看起来就像天书一样。但经过几个实际项目的磨练后,我发现只要掌握几个关键点,异常处理其实并没有想象中那么难。…...

OSINT自动化平台ClawShield:模块化架构与安全运营实战解析
1. 项目概述:一个面向安全运营的公开情报收集与分析平台最近在整理自己的开源项目收藏夹,发现一个挺有意思的仓库,叫SleuthCo/clawshield-public。乍一看这个名字,“ClawShield”,爪子与盾牌,就透着一股子攻…...

Excel MCP Server终极指南:3步实现无界面Excel自动化处理
Excel MCP Server终极指南:3步实现无界面Excel自动化处理 【免费下载链接】excel-mcp-server A Model Context Protocol server for Excel file manipulation 项目地址: https://gitcode.com/gh_mirrors/ex/excel-mcp-server 你是否厌倦了手动操作Excel的繁琐…...
)
别再死记硬背了!用MATLAB手把手教你画根轨迹图(附代码与避坑指南)
MATLAB实战:从零绘制根轨迹图的完整指南与避坑技巧 在控制系统的设计与分析中,根轨迹图是理解系统动态特性的重要工具。传统教学中,学生往往被要求死记硬背绘制规则,却难以理解其实际应用价值。本文将彻底改变这一现状——通过MAT…...
)
告别黑盒:5分钟为你的自定义CNN模型集成Grad-CAM可视化(附常见错误排查)
告别黑盒:5分钟为你的自定义CNN模型集成Grad-CAM可视化(附常见错误排查) 在深度学习项目中,我们常常陷入一个尴尬境地:模型准确率很高,但完全不知道它究竟"看"了图像的哪些部分做出决策。这种黑盒…...

DLSS Swapper终极指南:免费开源的游戏DLSS智能管理工具
DLSS Swapper终极指南:免费开源的游戏DLSS智能管理工具 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper DLSS Swapper是一款革命性的免费开源工具,专为PC游戏玩家设计,能够智能管理、…...

Vircadia Native Core:开源虚拟世界服务器核心架构与部署实战
1. 项目概述:一个开源虚拟世界的“引擎心脏”如果你对构建一个属于自己的、去中心化的虚拟世界(Metaverse)感兴趣,或者你正在寻找一个能支撑起大规模、高自由度社交与协作应用的底层平台,那么Vircadia Native Core绝对…...

可逆计算与量子电路合成:改进QM算法与全局优化
1. 可逆计算与量子电路合成基础在量子计算领域,可逆计算是一项关键技术,它不仅是实现低功耗设计的核心方法,更是量子电路合成的基础。传统计算机中的逻辑门大多是不可逆的,这意味着计算过程中会丢失信息并产生热量。而量子计算由于…...

FanControl终极指南:如何突破NVIDIA显卡风扇30%限制实现0 RPM静音控制
FanControl终极指南:如何突破NVIDIA显卡风扇30%限制实现0 RPM静音控制 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/Git…...