15分钟学 Python 第39天:Python 爬虫入门(五)
Day 39:Python 爬虫入门数据存储概述
在进行网页爬虫时,抓取到的数据需要存储以供后续分析和使用。常见的存储方式包括但不限于:
- 文件存储(如文本文件、CSV、JSON)
- 数据库存储(如SQLite、MySQL、MongoDB)
- 内存存储(如使用Python的数据结构)
每种存储方式有其优缺点,选择合适的存储方案可以提高数据处理效率。
一、文件存储
1.1 文本文件
文本文件是最简单的数据存储方式,适合于小规模数据。可以使用Python的内置文件操作来实现数据写入和读取。
示例代码:
# 写入数据到文本文件
data = "Hello, World!"
with open("output.txt", "w") as file:file.write(data)# 从文本文件读取数据
with open("output.txt", "r") as file:content = file.read()
print(content) # 输出: Hello, World!
1.2 CSV文件
CSV(Comma Separated Values)文件用于存储表格数据,适合处理结构化数据。可以使用Python的csv模块来处理CSV文件。
示例代码:
import csv# 写入数据到CSV文件
data = [["name", "age"], ["Alice", 30], ["Bob", 25]]
with open("output.csv", "w", newline="") as file:writer = csv.writer(file)writer.writerows(data)# 从CSV文件读取数据
with open("output.csv", "r") as file:reader = csv.reader(file)for row in reader:print(row) # 输出: ['name', 'age'], ['Alice', '30'], ['Bob', '25']
1.3 JSON文件
JSON(JavaScript Object Notation)文件适合存储嵌套的数据结构,易于人类阅读和书写。可以使用Python的json模块。
示例代码:
import json# 写入数据到JSON文件
data = {"users": [{"name": "Alice", "age": 30},{"name": "Bob", "age": 25}]
}
with open("output.json", "w") as file:json.dump(data, file)# 从JSON文件读取数据
with open("output.json", "r") as file:content = json.load(file)
print(content) # 输出: {'users': [{'name': 'Alice', 'age': 30}, {'name': 'Bob', 'age': 25}]}
二、数据库存储
对于大规模数据及高效查询,使用数据库存储更为合适。常用的数据库有SQLite、MySQL和MongoDB。
2.1 SQLite
SQLite是一个轻量级的关系数据库,适合小型应用。Python内置支持SQLite,通过sqlite3模块操作。
示例代码:
import sqlite3# 创建数据库连接
conn = sqlite3.connect('example.db')
c = conn.cursor()# 创建表
c.execute('''CREATE TABLE users (name text, age integer)''')# 插入数据
c.execute("INSERT INTO users VALUES ('Alice', 30)")
c.execute("INSERT INTO users VALUES ('Bob', 25)")# 提交并关闭连接
conn.commit()
conn.close()# 查询数据
conn = sqlite3.connect('example.db')
c = conn.cursor()
for row in c.execute('SELECT * FROM users'):print(row) # 输出: ('Alice', 30), ('Bob', 25)
conn.close()
2.2 MySQL
MySQL是一个广泛使用的关系数据库,适合大规模的应用。首先要安装mysql-connector-python模块。
示例代码:
import mysql.connector# 创建数据库连接
conn = mysql.connector.connect(host="localhost",user="yourusername",password="yourpassword",database="yourdatabase"
)
cursor = conn.cursor()# 创建表
cursor.execute("CREATE TABLE users (name VARCHAR(255), age INT)")# 插入数据
cursor.execute("INSERT INTO users (name, age) VALUES ('Alice', 30)")
cursor.execute("INSERT INTO users (name, age) VALUES ('Bob', 25)")# 提交事务并关闭连接
conn.commit()
cursor.close()
conn.close()# 查询数据
conn = mysql.connector.connect(host="localhost",user="yourusername",password="yourpassword",database="yourdatabase"
)
cursor = conn.cursor()cursor.execute("SELECT * FROM users")
for row in cursor.fetchall():print(row) # 输出: ('Alice', 30), ('Bob', 25)cursor.close()
conn.close()
2.3 MongoDB
MongoDB是一个文档型数据库,适合存储非结构化数据。使用pymongo模块进行操作。
示例代码:
from pymongo import MongoClient# 创建数据库连接
client = MongoClient('localhost', 27017)
db = client["testdb"]
collection = db["users"]# 插入数据
collection.insert_one({"name": "Alice", "age": 30})
collection.insert_one({"name": "Bob", "age": 25})# 查询数据
for user in collection.find():print(user) # 输出: {'_id': ..., 'name': 'Alice', 'age': 30}, {'_id': ..., 'name': 'Bob', 'age': 25}client.close()
三、内存存储
在某些情况下,可以将数据存储在内存中,适合快速处理和临时使用。使用Python的内置数据结构(如字典、列表)即可。
示例代码:
# 使用Python内置数据结构存储数据
data_storage = []# 存储数据
data_storage.append({"name": "Alice", "age": 30})
data_storage.append({"name": "Bob", "age": 25})# 读取数据
for item in data_storage:print(item) # 输出: {'name': 'Alice', 'age': 30}, {'name': 'Bob', 'age': 25}
四、选择适合的存储方式
在选择数据存储方式时,考虑以下几点:
- 数据规模:数据量小可使用文件存储,量大则应考虑数据库。
- 查询需求:如果需要复杂查询,选择数据库存储更为合适。
- 数据结构:嵌套数据优先考虑JSON文件或MongoDB。
- 性能要求:内存存储能提供最快的读取速度,但数据持久化不可用。
五、数据存储流程图
以下是一个简单的数据存储流程图,帮助理解数据存储的步骤:
[网页爬虫]|V
[数据提取]|V
[选择存储方式]|+----- [文件存储] -----+| || |+----- [数据库存储] --+| || |+----- [内存存储] ----+|V
[存储数据]
六、总结
数据存储是爬虫开发中的一个关键环节,不同的存储方式各有优劣,学习如何高效存储数据对于数据分析、后续利用都至关重要。通过上述讲解,您可以更好地选择数据存储方案以满足不同需求。

怎么样今天的内容还满意吗?再次感谢观众老爷的观看。
最后,祝您早日实现财务自由,还请给个赞,谢谢!
相关文章:
15分钟学 Python 第39天:Python 爬虫入门(五)
Day 39:Python 爬虫入门数据存储概述 在进行网页爬虫时,抓取到的数据需要存储以供后续分析和使用。常见的存储方式包括但不限于: 文件存储(如文本文件、CSV、JSON)数据库存储(如SQLite、MySQL、MongoDB&a…...

使用Pytorch构建自定义层并在模型中使用
使用Pytorch构建自定义层并在模型中使用 继承自nn.Module类,自定义名称为NoisyLinear的线性层,并在新模型定义过程中使用该自定义层。完整代码可以在jupyter nbviewer中在线访问。 import torch import torch.nn as nn from torch.utils.data import T…...
:从前序与中序遍历序列构造二叉树)
学习记录:js算法(五十六):从前序与中序遍历序列构造二叉树
文章目录 从前序与中序遍历序列构造二叉树我的思路网上思路 总结 从前序与中序遍历序列构造二叉树 给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。 示…...

qt使用QDomDocument读写xml文件
在使用QDomDocument读写xml之前需要在工程文件添加: QT xml 1.生成xml文件 void createXml(QString xmlName) {QFile file(xmlName);if (!file.open(QIODevice::WriteOnly | QIODevice::Truncate |QIODevice::Text))return false;QDomDocument doc;QDomProcessin…...

Oracle架构之表空间详解
文章目录 1 表空间介绍1.1 简介1.2 表空间分类1.2.1 SYSTEM 表空间1.2.2 SYSAUX 表空间1.2.3 UNDO 表空间1.2.4 USERS 表空间 1.3 表空间字典与本地管理1.3.1 字典管理表空间(Dictionary Management Tablespace,DMT)1.3.2 本地管理方式的表空…...

springboot整合seata
一、准备 docker部署seata-server 1.5.2参考:docker安装各个组件的命令 二、springboot集成seata 2.1 引入依赖 <dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-seata</artifactId>&…...
【二次向用户申请授权】程序访问控制)
鸿蒙开发(NEXT/API 12)【二次向用户申请授权】程序访问控制
当应用通过[requestPermissionsFromUser()]拉起弹框[请求用户授权]时,用户拒绝授权。应用将无法再次通过requestPermissionsFromUser拉起弹框,需要用户在系统应用“设置”的界面中,手动授予权限。 在“设置”应用中的路径: 路径…...

docker export/import 和 docker save/load 的区别
Docker export/import 和 docker save/load 都是用于容器和镜像的备份和迁移,但它们有一些关键的区别: docker export/import: export 作用于容器,import 创建镜像导出的是容器的文件系统,不包含镜像的元数据丢失了镜像的层级结构…...

明星周边销售网站开发:SpringBoot技术全解析
1系统概述 1.1 研究背景 如今互联网高速发展,网络遍布全球,通过互联网发布的消息能快而方便的传播到世界每个角落,并且互联网上能传播的信息也很广,比如文字、图片、声音、视频等。从而,这种种好处使得互联网成了信息传…...

STM32+ADC+扫描模式
1 ADC简介 1 ADC(模拟到数字量的桥梁) 2 DAC(数字量到模拟的桥梁),例如:PWM(只有完全导通和断开的状态,无功率损耗的状态) DAC主要用于波形生成(信号发生器和音频解码器) 3 模拟看门狗自动监…...

R语言绘制散点图
散点图是一种在直角坐标系中用数据点直观呈现两个变量之间关系、可检测异常值并探索数据分布的可视化图表。它是一种常用的数据可视化工具,我们通过不同的参数调整和包的使用,可以创建出满足各种需求的散点图。 常用绘制散点图的函数有plot()函数和ggpl…...

安装最新 MySQL 8.0 数据库(教学用)
安装 MySQL 8.0 数据库(教学用) 文章目录 安装 MySQL 8.0 数据库(教学用)前言MySQL历史一、第一步二、下载三、安装四、使用五、语法总结 前言 根据 DB-Engines 网站的数据库流行度排名(2024年)࿰…...
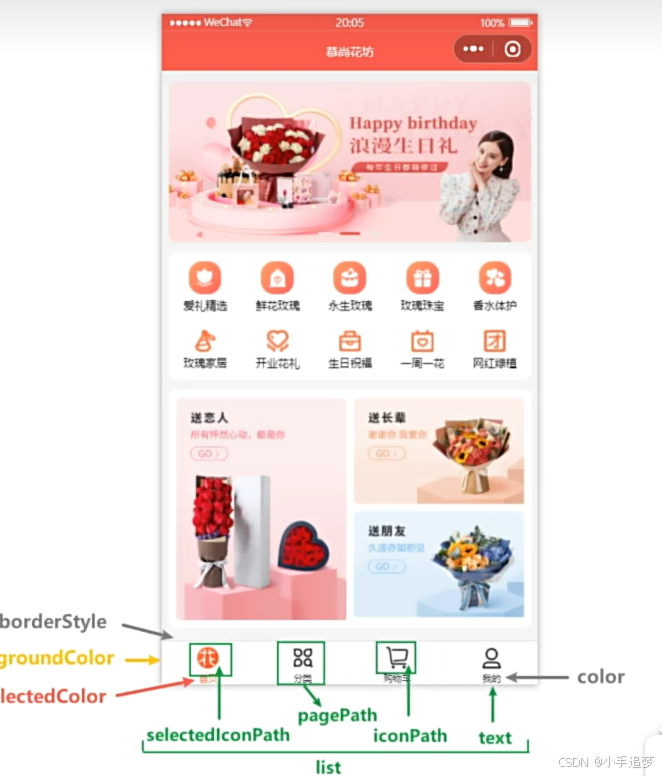
微信小程序开发-配置文件详解
文章目录 一,小程序创建的配置文件介绍二,配置文件-全局配置-pages 配置作用:注意事项:示例: 三,配置文件-全局配置-window 配置示例: 四,配置文件-全局配置-tabbar 配置核心作用&am…...

TCP/UDP初识
TCP是面向连接的、可靠的、基于字节流的传输层协议。 面向连接:一定是一对一连接,不能像 UDP 协议可以一个主机同时向多个主机发送消息 可靠的:无论的网络链路中出现了怎样的链路变化,TCP 都可以保证一个报文一定能够到达接收端…...

【大数据】在线分析、近线分析与离线分析
文章目录 1. 在线分析(Online Analytics)定义特点应用场景技术栈 2. 近线分析(Nearline Analytics)定义特点应用场景技术栈 3. 离线分析(Offline Analytics)定义特点应用场景技术栈 总结 在线分析ÿ…...

【unity进阶知识9】序列化字典,场景,vector,color,Quaternion
文章目录 前言一、可序列化字典类普通字典简单的使用可序列化字典简单的使用 二、序列化场景三、序列化vector四、序列化color五、序列化旋转Quaternion完结 前言 自定义序列化的主要原因: 可读性:使数据结构更清晰,便于理解和维护。优化 I…...

传奇GOM引擎架设好进游戏后提示请关闭非法外挂,重新登录,如何处理?
今天在架设一个GOM引擎的版本时,进游戏之后刚开始是弹出一个对话框,提示请关闭非法外挂,重新登录,我用的是绿盟登陆器,同时用的也是绿盟插件,刚开始我以为是绿盟登录器的问题,于是就换成原版gom…...
视频写入类VideoWriter之标识视频编解码器函数fourcc()的使用)
OpenCV视频I/O(15)视频写入类VideoWriter之标识视频编解码器函数fourcc()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 将 4 个字符拼接成一个 FourCC 代码。 在 OpenCV 中,fourcc() 函数用于生成 FourCC 代码,这是一种用于标识视频编解码器的…...

rust log选型
考察了最火的tracing。但是该模块不支持compact,仅支持根据时间进行rotate。 daily Creates a daily-rotating file appender. hourly Creates an hourly-rotating file appender. minutely Creates a minutely-rotating file appender. This will rotate the log…...

数据库-分库分表
什么是分库分表 分库分表是一种数据库优化策略。 目的:为了解决由于单一的库表数据量过大而导致数据库性能降低的问题 分库:将原来独立的数据库拆分成若干数据库组成 分表:将原来的大表(存储近千万数据的表)拆分成若干个小表 什么时候考虑分…...

终极CoreCycler完全指南:5步掌握CPU单核稳定性测试与精准调校
终极CoreCycler完全指南:5步掌握CPU单核稳定性测试与精准调校 【免费下载链接】corecycler Script to test single core stability, e.g. for PBO & Curve Optimizer on AMD Ryzen or overclocking/undervolting on Intel processors 项目地址: https://gitco…...

终极跨平台漫画阅读方案:nhentai-cross全平台使用指南
终极跨平台漫画阅读方案:nhentai-cross全平台使用指南 【免费下载链接】nhentai-cross A nhentai client 项目地址: https://gitcode.com/gh_mirrors/nh/nhentai-cross 你是否厌倦了在不同设备间切换漫画阅读应用?nhentai-cross正是为你量身定制…...

跨越平台限制:如何用WorkshopDL免费获取Steam创意工坊模组
跨越平台限制:如何用WorkshopDL免费获取Steam创意工坊模组 【免费下载链接】WorkshopDL WorkshopDL - The Best Steam Workshop Downloader 项目地址: https://gitcode.com/gh_mirrors/wo/WorkshopDL 还在为Epic Games或GOG平台无法访问Steam创意工坊而烦恼吗…...

窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧
窗口大小控制神器:3分钟掌握WindowResizer的终极窗口调整技巧 【免费下载链接】WindowResizer 一个可以强制调整应用程序窗口大小的工具 项目地址: https://gitcode.com/gh_mirrors/wi/WindowResizer 还在为那些顽固的应用程序窗口而束手无策吗?是…...

基于GitHub Actions的自动化代码质量守护:CodeBuddy实战指南
1. 项目概述与核心价值最近在和一些团队做代码评审和协作时,我经常遇到一个痛点:大家写的代码风格各异,注释要么缺失要么过时,一些潜在的安全漏洞和性能问题在提交前很难被系统性地发现。虽然市面上有各种静态分析工具,…...

解锁Midjourney V6黑白摄影隐藏指令:5个未公开--stylize与--sref协同技法,92%用户至今不会用
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6黑白摄影的美学本质与技术觉醒 黑白摄影在 Midjourney V6 中已超越简单的色彩剥离,成为一场基于对比度张力、纹理显影与光影叙事的深度建模重构。V6 的隐式扩散架构强化了灰阶…...

【最新 v2.7.1 版本安装包】5 分钟搞定 OpenClaw,零基础无需命令一键部署保姆级教学
OpenClaw(小龙虾)Windows 一键部署保姆级教程 | 10 分钟搭建专属数字员工【点击下载最新OpenClaw安装包】 前言 2026 年开源圈热门 AI 智能体 OpenClaw(昵称小龙虾),GitHub 星标突破 28 万,凭借本地运行 …...

从刺绣到互动:用导电绣线与微控制器打造光控可穿戴艺术
1. 项目概述与核心价值最近在捣鼓一个特别有意思的玩意儿:把会发光的电子元件“绣”到衣服上,让它不仅能穿,还能跟你互动。这个光控发光琵琶鱼刺绣项目,就是一个绝佳的入门案例。它完美地融合了传统手工艺(刺绣&#x…...

3步玩转APK下载:开源APKMirror客户端的终极实战指南
3步玩转APK下载:开源APKMirror客户端的终极实战指南 【免费下载链接】APKMirror 项目地址: https://gitcode.com/gh_mirrors/ap/APKMirror 你是否曾因官方应用商店找不到某个历史版本而苦恼?是否担心第三方下载站点的安全性?今天&…...

使用taotoken聚合api后模型响应延迟的实际体感观察
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 使用taotoken聚合api后模型响应延迟的实际体感观察 作为一名日常需要调用多种大模型API的开发者,将多个供应商的API接入…...