PEFT库和transformers库在NLP大模型中的使用和常用方法详解
PEFT(Parameter-Efficient Fine-Tuning)库是一个用于有效微调大型预训练语言模型的工具,尤其是在计算资源有限的情况下。它提供了一系列技术,旨在提高微调过程的效率和灵活性。以下是PEFT库的详细解读以及一些常用方法的总结:
PEFT库详解
-
参数高效微调的概念
- PEFT旨在通过只微调模型的一部分参数(而不是整个模型)来减少计算和内存开销。这对于大型语言模型(如BERT、GPT等)尤其重要,因为它们的参数数量通常非常庞大。
-
常见方法
- PEFT包括几种不同的策略,每种策略都有其适用场景和优缺点。以下是一些最常用的PEFT方法:
常用的PEFT方法总结
-
LoRA(Low-Rank Adaptation)
- 原理:通过在预训练模型的权重矩阵中添加低秩矩阵,LoRA将大模型的微调问题转化为对小矩阵的优化。
- 优点:显著减少训练时所需的参数,降低计算复杂度。
- 使用场景:适合在计算资源有限的情况下进行快速微调。
-
from transformers import AutoModelForSequenceClassification, AutoTokenizer from peft import LoRAConfig, get_peft_model# 加载预训练模型和分词器 model_name = "distilbert-base-uncased" model = AutoModelForSequenceClassification.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name)# 配置LoRA lora_config = LoRAConfig(r=8, # 低秩适配的秩lora_alpha=32,lora_dropout=0.1 )# 应用LoRA lora_model = get_peft_model(model, lora_config)# 训练代码(略)
-
Adapter
- 原理:在预训练模型的不同层之间插入小型的“适配器”网络,只微调适配器参数,保留主模型的权重不变。
- 优点:适配器可以在不同任务之间共享,大幅度减少微调时的参数数量。
- 使用场景:适用于需要频繁在不同任务之间切换的情况。
-
from transformers import AutoModelForSequenceClassification, AutoTokenizer from peft import AdapterConfig, get_peft_model# 加载预训练模型和分词器 model_name = "distilbert-base-uncased" model = AutoModelForSequenceClassification.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name)# 配置Adapter adapter_config = AdapterConfig(reduction_factor=2,non_linearity="relu" )# 应用Adapter adapter_model = get_peft_model(model, adapter_config)# 训练代码(略)
-
Prefix Tuning
- 原理:在输入序列前添加一个学习到的前缀,这个前缀在微调过程中进行优化,而主模型的参数保持不变。
- 优点:可以实现快速微调,同时保留主模型的知识。
- 使用场景:适合文本生成和对话系统等任务。
-
from transformers import AutoModelForCausalLM, AutoTokenizer from peft import PrefixTuningConfig, get_peft_model# 加载预训练模型和分词器 model_name = "gpt2" model = AutoModelForCausalLM.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name)# 配置Prefix Tuning prefix_config = PrefixTuningConfig(prefix_length=10, # 前缀长度task_type="text-generation" )# 应用Prefix Tuning prefix_model = get_peft_model(model, prefix_config)# 训练代码(略)
-
Prompt Tuning
- 原理:通过优化输入提示(prompt)的参数来指导模型生成所需的输出。
- 优点:相较于传统微调方法,减少了对模型整体参数的依赖。
- 使用场景:适用于自然语言处理中的各种任务,如文本分类和问答。
-
from transformers import AutoModelForSequenceClassification, AutoTokenizer from peft import PromptTuningConfig, get_peft_model# 加载预训练模型和分词器 model_name = "distilbert-base-uncased" model = AutoModelForSequenceClassification.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name)# 配置Prompt Tuning prompt_config = PromptTuningConfig(prompt_length=5, # 提示长度task_type="classification" )# 应用Prompt Tuning prompt_model = get_peft_model(model, prompt_config)# 训练代码(略)
-
BitFit
- 原理:只对模型的偏置参数进行微调,保持权重参数不变。
- 优点:极大地减少了微调的参数数量,同时在许多任务中表现良好。
- 使用场景:适用于资源受限的场景。
-
from transformers import AutoModelForSequenceClassification, AutoTokenizer from peft import BitFitConfig, get_peft_model# 加载预训练模型和分词器 model_name = "distilbert-base-uncased" model = AutoModelForSequenceClassification.from_pretrained(model_name) tokenizer = AutoTokenizer.from_pretrained(model_name)# 配置BitFit bitfit_config = BitFitConfig()# 应用BitFit bitfit_model = get_peft_model(model, bitfit_config)# 训练代码(略)
----------------------------------------------------------------------------------------------------------------------
transformers库概述
transformers库是由Hugging Face开发的一个开源库,专门用于处理自然语言处理(NLP)任务。它提供了预训练的模型、简单的API和丰富的功能,使得使用大型语言模型变得更加方便。以下是transformers库的详解和一些最常用的方法总结。
1. 加载模型和分词器
from_pretrained(model_name):- 用途:从Hugging Face Model Hub加载预训练模型和分词器。
from_pretrained(model_name)方法用于从Hugging Face Model Hub加载预训练模型及其配置。可以通过指定模型的名称、路径或标识符来获取预训练的模型。(这里我常常自己先下载下来,不然的话huggingface社区老没办法从本地登进去) - 示例:
model = AutoModel.from_pretrained("bert-base-uncased")
- 用途:从Hugging Face Model Hub加载预训练模型和分词器。
2. 分词器(Tokenizer)
tokenizer(text):- 用途:将文本转化为模型可接受的输入格式,包括分词、编码等。
- 参数:可以设置
return_tensors参数指定返回的张量格式(如"pt"表示PyTorch)。 - 示例:
inputs = tokenizer("Hello, world!", return_tensors="pt") -
Hugging Face提供多种类型的分词器,主要包括:
BertTokenizer BERT - 用于NLP任务的分词器 - 使用WordPiece分词 - 处理复杂句子和OOV词效果好 GPT2Tokenizer GPT-2 - 通过 from_pretrained加载- 使用Byte Pair Encoding (BPE)分词 - 适合文本生成和补全 T5Tokenizer T5 - 提供tokenization和编码功能 - 使用SentencePiece分词 - 支持多种任务,灵活性高 RobertaTokenizer RoBERTa - 支持填充、截断和解码功能 - 训练数据更丰富,取消特殊标记 - 在上下文理解方面表现优秀 AutoTokenizer 多种模型 - 方便集成和使用 - 自动选择适合的分词器 - 提高开发效率,适合快速实验 - BertTokenizer:用于BERT模型。
- GPT2Tokenizer:用于GPT-2模型。
- T5Tokenizer:用于T5模型。
- RobertaTokenizer:用于RoBERTa模型。
- AutoTokenizer:自动选择适当的分词器,根据给定的模型名称。
3. 推理
model(inputs):- 用途:推理(Inference)是指使用训练好的模型对新输入进行预测或生成输出的过程。在自然语言处理(NLP)和深度学习中,推理是模型应用的关键步骤,通常在模型训练完成后进行。以下是推理的基本概念和过程,(在这里我理解为,推理是对经过分词处理的输入数据进行推断,输出模型的预测结果。)目的:推理的目的是对未知数据进行预测,例如分类、生成文本、回答问题等。输入与输出:推理通常接收原始输入(如文本、图像等),并输出模型的预测结果(如分类标签、生成的文本等)。
- 示例:
outputs = model(**inputs)
4. Pipeline
pipeline(task):- 用途:创建一个简化的任务接口,支持文本分类、问答、翻译等多种任务。
- 示例:
classifier = pipeline("sentiment-analysis") - 使用方法:
result = classifier("I love this movie!")
5. Trainer
Trainer:- 用途:用于模型的训练和评估,简化了训练过程。
- 方法:
train():开始训练模型。evaluate():评估模型在验证集上的表现。save_model():保存微调后的模型。
6. 保存和加载模型
save_pretrained(directory):- 用途:将模型和分词器保存到指定目录。
- 示例:
model.save_pretrained("./my_model")
from_pretrained(directory):- 用途:从本地目录加载已保存的模型和分词器。
- 示例:
model = AutoModel.from_pretrained("./my_model")
7. 自定义数据集
Dataset:- 用途:自定义数据集类,继承自
torch.utils.data.Dataset,实现数据的加载和预处理。 - 方法:
__len__():返回数据集大小。__getitem__(idx):返回指定索引的数据样本。
- 用途:自定义数据集类,继承自
8. 模型评估
evaluate():- 用途:在验证集上评估模型性能,返回各类指标(如损失、准确率等)。
- 示例:
metrics = trainer.evaluate(eval_dataset=eval_dataset)
9. 文本生成
model.generate():- 用途:用于生成文本,例如进行对话生成或续写。
- 示例:
generated_ids = model.generate(input_ids, max_length=50)
10. 模型的选择
AutoModel、AutoModelForSequenceClassification等:- 用途:根据任务选择合适的模型架构。
- 示例:
model = AutoModelForSequenceClassification.from_pretrained("distilbert-base-uncased")
相关文章:
PEFT库和transformers库在NLP大模型中的使用和常用方法详解
PEFT(Parameter-Efficient Fine-Tuning)库是一个用于有效微调大型预训练语言模型的工具,尤其是在计算资源有限的情况下。它提供了一系列技术,旨在提高微调过程的效率和灵活性。以下是PEFT库的详细解读以及一些常用方法的总结&…...

静止坐标系和旋转坐标系变换的线性化,锁相环线性化通用推导
将笛卡尔坐标系的电压 [ U x , U y ] [U_x, U_y] [Ux,Uy] 通过旋转变换(由锁相环角度 θ P L L \theta_{PLL} θPLL 控制)转换为 dq 坐标系下的电压 [ U d , U q ] [U_d, U_q] [Ud,Uq]。这个公式是非线性的,因为它涉及到正弦和余弦函数。 图片中的推导过程主要…...

AI学习指南深度学习篇-学习率衰减的变体及扩展应用
AI学习指南深度学习篇 - 学习率衰减的变体及扩展应用 在深度学习的训练过程中,学习率的选择对模型的收敛速度和最终效果有重要影响。为了提升模型性能,学习率衰减(Learning Rate Decay)作为一种优化技术被广泛应用。本文将探讨多…...

成都睿明智科技有限公司真实可靠吗?
在这个日新月异的电商时代,抖音作为短视频与直播电商的佼佼者,正以前所未有的速度重塑着消费者的购物习惯。而在这片充满机遇与挑战的蓝海中,成都睿明智科技有限公司以其独到的眼光和专业的服务,成为了众多商家信赖的合作伙伴。今…...
力扣6~10题
题6(中等): 思路: 这个相较于前面只能是简单,个人认为,会print打印菱形都能搞这个,直接设置一个2阶数组就好了,只要注意位置变化就好了 python代码: def convert(self,…...
IntelliJ IDEA 2024.2 新特性概览
文章目录 1、重点特性:1.1 改进的 Spring Data JPA 支持1.2 改进的 cron 表达式支持1.3 使用 GraalJS 作为 HTTP 客户端的执行引擎1.4 更快的编码时间1.5 K2 模式下的 Kotlin 性能和稳定性改进 2、用户体验2.1 改进的全行代码补全2.2 新 UI 成为所有用户的默认界面2.3 Search E…...
——初识list)
C++基础(12)——初识list
目录 1.list的简介(引用自cplusplus官网) 2.list的相关使用 2.1有关list的定义 2.1.1方式一(构造某类型的空容器) 2.1.2方式二(构造n个val的容器) 2.1.3方式三(拷贝构造) 2.1.4…...

系统架构设计师论文《论NoSQL数据库技术及其应用》精选试读
论文真题 随着互联网web2.0网站的兴起,传统关系数据库在应对web2.0 网站,特别是超大规模和高并发的web2.0纯动态SNS网站上已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展…...
产品经理产出的原型设计 - 需求文档应该怎么制作?
需求文档,产品经理最终产出的文档,也是产品设计最终的表述形式。本次分享呢,就是介绍如何写好一份需求文档。 所有元件均可复用,可作为管理端原型设计模板,按照实际项目需求进行功能拓展。有需要的话可分享源文件。 …...
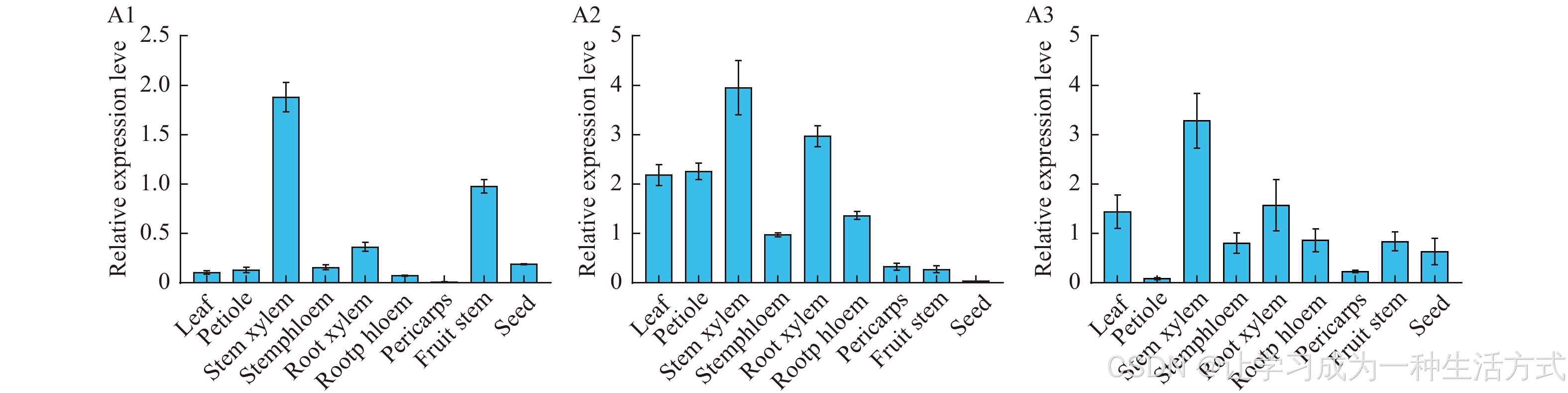
phenylalanine ammonia-lyase苯丙氨酸解氨酶PAL功能验证-文献精读61
Molecular cloning and characterization of three phenylalanine ammonia-lyase genes from Schisandra chinensis 五味子中三种苯丙氨酸解氨酶基因的分子克隆及特性分析 摘要 苯丙氨酸解氨酶(PAL)催化L-苯丙氨酸向反式肉桂酸的转化,是植物…...

柯桥生活口语学习之在化妆品店可以用到的韩语句子
화장품을 사고 싶어요. 我想买化妆品。 어떤 화장품을 원하세요? 您想买什么化妆品。 스킨로션을 찾고 있어요. 我想买化妆水,乳液。 피부 타입은 어떠세요? 您是什么皮肤类型? 민감성 피부예요. 我是敏感性皮肤。 평소에 쓰시는 제품은 뭐예…...

Ubuntu 安装 Docker Compose
安装Docker Compose # 删除现有的 docker-compose(如果存在) sudo rm -f /usr/local/bin/docker-compose # 下载最新的 docker-compose 二进制文件 sudo curl -L "https://github.com/docker/compose/releases/latest/download/docker-compose-…...
C++面试速通宝典——7
150. 数据库连接池的作用 数据库连接池的作用包括以下几个方面: 资源重用:连接池允许多个客户端共享有限的数据库连接,减少频繁创建和销毁连接的开销,从而提高资源的利用率。 统一的连接管理:连接池集中管理数据库连…...
毕业设计 大数据电影数据分析与可视化系统
文章目录 0 简介1 课题背景2 效果实现3 爬虫及实现4 Flask框架5 Ajax技术6 Echarts7 最后 0 简介 今天学长向大家介绍一个机器视觉的毕设项目 🚩基于大数据的电影数据分析与可视化系统 项目运行效果(视频): 毕业设计 大数据电影评论情感分析 …...

第三届图像处理、计算机视觉与机器学习国际学术会议(ICICML 2024)
目录 重要信息 大会简介 组织单位 大会成员 征稿主题 会议日程 参会方式 重要信息 大会官网:www.icicml.org 大会时间:2024年11月22日-24日 大会地点:中国 深圳 大会简介 第三届图像处理、计算机视觉与机器学…...

OJ在线评测系统 微服务技术入门 单体项目改造为微服务 用Redis改造单机分布式锁登录
单体项目改造为微服务 什么是微服务 服务:提供某类功能的代码 微服务:专注于提供某类特定功能的代码 而不是把所有的代码放到同一个项目里 会把一个大的项目按照一定的功能逻辑进行划分 拆分成多个子模块 每个子模块可以独立运行 独立负责一类功能 …...

【机器学习】网络安全——异常检测与入侵防御系统
我的主页:2的n次方_ 随着全球互联网和数字基础设施的不断扩展,网络攻击的数量和复杂性都在显著增加。从传统的病毒和蠕虫攻击到现代复杂的高级持续性威胁(APT),网络攻击呈现出更加智能化和隐蔽化的趋势。面对这样的…...

【C语言】基础篇续
最大公约数HCF与最小公倍数LCM #include<stdio.h> int main(){int n1,n2,i,hcf,lcm;printf("Enter two numbers:");scanf("%d %d",&n1,&n2);for(i 1;i < n1 & i < n2;i){if(n1 % i 0 & n2 % i 0){hcf i;lcm (n1*n2)/hc…...

文件丢失一键找回,四大数据恢复免费版工具推荐!
丢失数据的情况虽然不经常出现,但一旦出现都会让人头疼不已,而这时候,要如何恢复丢失的数据呢?一款免费好用的数据恢复工具就派上用场了!接下来就为大家推荐几款好用的数据恢复工具! 福昕数据恢复 直达链…...

【学习笔记】手写一个简单的 Spring MVC
目录 一、什么是Spring MVC ? Spring 和 Spring MVC 的区别? Spring MVC 的运行流程? 二、实现步骤 1. DispatcherServlet 1. 创建一个中央分发器 拦截所有请求 测试 2. 接管 IOC 容器 1. 创建配置文件 2. 修改 web.xml 配置文件 …...

Linuxbonding链路生产排障流程
Linuxbonding链路生产排障流程这是一篇面向中级 Linux 使用者的技术文章,主题聚焦在bonding链路,重点讨论链路聚合、冗余切换和接口状态。在真实生产环境中,bonding链路相关问题往往不会以单一错误形式出现,而是混杂在日志、权限、…...

初创团队如何通过Taotoken的Token Plan实现成本可控的AI应用开发
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何通过Taotoken的Token Plan实现成本可控的AI应用开发 对于预算敏感的初创团队和独立开发者而言,在开发AI应…...

工作流编排核心原理与实践:从概念到MiniFlow系统实现
1. 项目概述:从代码仓库到工作流编排的实践最近在梳理团队内部的一些自动化流程,发现很多脚本和任务散落在各个角落,执行依赖混乱,出了问题排查起来像大海捞针。正好看到GitHub上有个叫dnh33/workflow-orchestration的项目&#x…...
)
别再手动调色了!用Matlab bar3函数一键生成论文级渐变三维柱状图(附完整代码)
别再手动调色了!用Matlab bar3函数一键生成论文级渐变三维柱状图(附完整代码) 科研图表的美观程度直接影响论文的第一印象,而三维柱状图在展示多维度数据时尤为常见。传统手动调整每个柱体的颜色、透明度、光照效果不仅耗时&#…...

系统管理员AI编程实战:基于Claude的运维自动化脚本开发指南
1. 项目概述:一个面向系统管理员的Claude-Code学习与实践仓库最近在整理自己的技术栈时,发现很多系统管理员同行对如何将大型语言模型(LLM)高效地融入日常运维工作流感到困惑。大家普遍觉得这些AI工具很强大,但具体到写…...

2026产品经理学数据分析对升职的价值
一、数据分析能力对产品经理升职的重要性数据分析能力已成为产品经理的核心竞争力之一。掌握数据分析技能可以帮助产品经理更精准地决策,提升产品成功率,从而在职业发展中占据优势。二、数据分析在产品经理工作中的具体应用通过数据分析优化产品功能迭代…...

在 1688、阿里国际站上,怎么分清哪些是真工厂、哪些是贸易商?一份采购辨别清单
跨境卖家和采购最常踩的坑,就是把贸易商当成了源头工厂。结果是:报价里多了一手差价、打样要等贸易商再转给后面的厂、出了质量问题没人能进车间整改。 平台上的"工厂认证"“源头工厂”"工厂直供"标签,看起来像是替你做了…...

学生综合素质评价系统设计实现【附程序】
✨ 长期致力于综合素质评价、AHP层次分析、BP神经网络、遗传算法研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅ 如需沟通交流,点击《获取方式》 (1)三层指标体系构建与AHP动态权重分配&…...

ModbusTool:工业自动化通信调试的技术实现与实践指南
ModbusTool:工业自动化通信调试的技术实现与实践指南 【免费下载链接】ModbusTool A modbus master and slave test tool with import and export functionality, supports TCP, UDP and RTU. 项目地址: https://gitcode.com/gh_mirrors/mo/ModbusTool 在工业…...

AMD Ryzen调试神器SMUDebugTool:免费开源工具让你的处理器性能飞起来!
AMD Ryzen调试神器SMUDebugTool:免费开源工具让你的处理器性能飞起来! 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Tab…...