HBase 性能优化 详解
HBase 是基于 Hadoop HDFS 之上的分布式 NoSQL 数据库,具有高伸缩性和强大的读写能力。然而,由于其分布式架构和复杂的数据存储模式,在高并发、大规模数据场景下,HBase 性能优化至关重要。从底层原理和源代码层面理解 HBase 的特性和性能,可以帮助我们根据不同业务场景进行有针对性的调优。
一、HBase 的架构概述
在深入讨论优化策略之前,先简单回顾 HBase 的核心架构和工作原理。想要详细了解可以看我的HBase架构介绍。
1.1 HBase 架构
HBase 的分布式存储体系结构由三部分组成:
- HMaster:负责元数据管理和 Region 的分配、迁移等操作。
- RegionServer:负责数据的读写,管理多个 Region,存储实际的数据。
- ZooKeeper:作为分布式协调服务,管理集群状态和协同操作。
HBase 通过分区(Region)存储数据,每个 Region 对应一定范围的 Row Key。当数据量超过设定的阈值时,Region 会进行自动切分。
1.2 数据存储原理
HBase 数据的存储基于 HDFS,主要由以下组件构成:
- MemStore:每个列族都有一个 MemStore,用于缓存写入的数据,当 MemStore 达到阈值时,会将数据写入磁盘,形成 HFile。
- HFile:存储在 HDFS 上的实际数据文件,存储格式为 SSTable。
- WAL (Write-Ahead Log):为确保数据写入的持久性,HBase 在写入数据前先记录 WAL,防止数据丢失。
- BlockCache:在读取时,HBase 将部分 HFile 数据缓存在内存中,提高读取速度。
二、HBase 性能优化的核心方向
从底层源码和系统原理出发,HBase 性能优化的方向主要包括:
- 硬件层面:包括内存、磁盘和网络优化。
- 系统配置层面:通过配置优化,包括 JVM、GC、RegionServer、WAL 等相关参数调整。
- 数据模型优化:从表设计和数据模型的角度优化,如预分区、合理设计 RowKey、列族优化等。
- 查询优化:如二级索引、过滤器、批量读取等操作的优化。
- 压缩与编码优化:数据压缩、编码策略可以减少 I/O 开销。
下面我们从这些方面进行详细分析。
三、HBase 性能优化措施及底层原理
3.1 硬件层面的优化
3.1.1 内存
HBase 强依赖内存,主要用于 MemStore、BlockCache 等缓存数据。因此,增加内存容量有助于减少磁盘 I/O 并提高性能。
- 增加 JVM 内存分配:为 RegionServer 分配更多的 JVM 堆内存,通过
hbase.regionserver.global.memstore.size和hfile.block.cache.size参数调整内存使用情况。 - JVM 参数调优:调整堆内存大小、垃圾回收机制(如 G1 或 CMS 收集器),减少 Full GC 频率和时间。
# 增加 JVM 堆内存
export HBASE_HEAPSIZE=8192 # 8GB 堆内存# 设置垃圾回收器为 G1
export HBASE_OPTS="$HBASE_OPTS -XX:+UseG1GC"
3.1.2 磁盘
-
磁盘类型和 RAID 配置:HBase 性能与磁盘 I/O 性能高度相关。使用 SSD 或 NVMe 磁盘,结合 RAID 0 提升读取吞吐量。
-
HDFS 参数调优:通过调整 HDFS 的复制因子、块大小 (
dfs.blocksize) 来优化数据访问性能。- 增加块大小减少每次 I/O 的块数量,适合大文件写入。
# HDFS 的复制因子和块大小
dfs.replication=3
dfs.blocksize=128m3.2 系统配置层面的优化
3.2.1 RegionServer 参数调优
- MemStore 大小调整:增加 MemStore 大小可以减少数据刷写到磁盘的频率,但同时也增加了内存消耗。可以通过
hbase.hregion.memstore.flush.size参数调整每个 Region 的 MemStore 大小。
# 调整 MemStore 刷新阈值
hbase.hregion.memstore.flush.size=128MB- BlockCache 大小调整:通过
hbase.block.cache.size调整 BlockCache 大小,提高热数据的命中率,减少磁盘 I/O。
# 调整 BlockCache 大小
hbase.block.cache.size=0.4 # 使用 40% 内存3.2.2 WAL (Write-Ahead Log) 调优
- 异步 WAL 机制:HBase 默认同步写 WAL,但异步写入可以提高写性能。可以通过
hbase.regionserver.wal.async.sync参数启用异步 WAL。
# 开启异步 WAL
hbase.regionserver.wal.async.sync=true- WAL 文件压缩:通过开启 WAL 压缩,减少写入的 I/O 大小,提升性能。
# 开启 WAL 文件压缩
hbase.regionserver.wal.enablecompression=true3.3 数据模型优化
3.3.1 RowKey 设计
-
避免热点:在设计 RowKey 时,避免顺序递增的 RowKey,因为它们会导致某些 Region 负载过高,造成写入热点。可以采用散列、前缀随机化等方法。
// 通过散列 RowKey 来避免热点 String rowKey = MD5Hash.getMD5AsHex(Bytes.toBytes(originalRowKey)) + originalRowKey; -
预分区:在建表时,预先定义多个 Region,避免数据写入集中到一个 Region。
# 创建表时预分区
create 'my_table', 'cf', {NUMREGIONS => 10, SPLITALGO => 'HexStringSplit'}
3.3.2 列族设计
- 减少列族数量:HBase 每个列族都有独立的 MemStore 和 WAL,过多的列族会导致性能下降。应尽量减少列族数量,且同一列族下的列应频繁一起访问。
3.4 查询优化
3.4.1 批量操作
- 批量写入:通过批量 Put 操作,可以减少 RPC 次数,提升写入性能。
List<Put> puts = new ArrayList<>();
for (Data data : dataList) {Put put = new Put(Bytes.toBytes(data.getRowKey()));put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("column"), Bytes.toBytes(data.getValue()));puts.add(put);
}
table.put(puts); // 批量写入
- 批量扫描:在查询大量数据时,使用批量扫描 (
setBatch()) 提高查询性能,减少客户端与服务器的交互次数。
Scan scan = new Scan();
scan.setBatch(1000); // 每次批量获取 1000 条记录
3.4.2 过滤器优化
- 过滤器:使用合适的过滤器可以减少扫描范围,提高查询效率。例如,使用
RowFilter或PrefixFilter限制扫描的行。
Filter filter = new PrefixFilter(Bytes.toBytes("prefix"));
Scan scan = new Scan();
scan.setFilter(filter); // 只扫描匹配特定前缀的行
3.5 压缩与编码优化
3.5.1 数据压缩
压缩可以减少 HFile 大小,从而减少磁盘 I/O,但会增加 CPU 的开销。常见的压缩算法有 LZO、Snappy 和 GZIP。一般推荐使用 Snappy 或 LZO。
# 设置列族压缩方式
alter 'my_table', {NAME => 'cf', COMPRESSION => 'SNAPPY'}3.5.2 数据编码
HBase 支持对 HFile 数据块进行编码,如 PREFIX、DIFF、FAST_DIFF 等。编码可以减少存储空间,提高读取效率。
# 设置列族编码方式
alter 'my_table', {NAME => 'cf', DATA_BLOCK_ENCODING => 'FAST_DIFF'}四、常见场景下的 HBase 性能优化
针对不同的业务场景,HBase 的性能优化策略也有所不同:
4.1 大数据量写入场景
对于日志系统、传感器数据等大量数据实时写入的场景:
- 设计合理的 RowKey,避免写入热点。
- 增加 MemStore 大小,减少刷写频率。
- 使用异步 WAL 写入,提升写入吞吐量。
- 采用批量写入,减少 RPC 请求次数。
4.2 低延迟读取场景
对于实时查询或低延迟读取的场景,如实时监控数据查询:
- 增大 BlockCache 大小,缓存热数据。
- 通过过滤器减少扫描范围。
- 使用合适的编码与压缩方式,减小数据存储体积。
4.3 分析型场景
对于需要扫描大量数据的分析场景,如数据仓库:
- 使用批量扫描和过滤器,减少 RPC 次数。
- 使用预分区策略,加快数据扫描速度。
- 增大 HDFS 块大小,减少 I/O 开销。
五、行业案例分析
5.1 金融行业
在金融行业,HBase 常用于实时交易数据的存储与分析。金融交易数据要求高吞吐量和高可用性:
- 设计基于时间戳的 RowKey,结合前缀随机化避免写入热点。
- 启用 WAL 压缩,减少 I/O 开销。
- 通过二级索引加速查询,如交易类型和用户维度的索引。
5.2 电信行业
在电信行业,HBase 通常用于大规模用户数据、话单数据的存储和查询:
- 使用批量写入优化话单数据的存储性能。
- 通过 Snappy 压缩大幅减少数据存储空间。
- 使用 Scan 扫描时,结合过滤器减少不必要的 I/O 操作。
5.3 物联网行业
在物联网场景下,HBase 用于存储传感器数据和设备数据,数据写入频繁且读取密集:
- RowKey 基于设备 ID 和时间戳,避免热点问题。
- 使用合适的 Region 分裂策略,均衡数据存储。
- 增大 MemStore 缓存,减少频繁刷盘操作。
六、总结
HBase 性能优化涉及硬件、系统配置、数据模型和查询方式等多个方面。在具体的业务场景中,需要根据 HBase 的架构和底层原理进行有针对性的调整。例如,增加内存、调整 JVM 参数、合理设计 RowKey、采用批量操作和压缩编码策略等。针对不同行业的业务需求,通过定制化的优化措施,可以大幅提升 HBase 的性能,实现高效的读写和查询操作。
相关文章:

HBase 性能优化 详解
HBase 是基于 Hadoop HDFS 之上的分布式 NoSQL 数据库,具有高伸缩性和强大的读写能力。然而,由于其分布式架构和复杂的数据存储模式,在高并发、大规模数据场景下,HBase 性能优化至关重要。从底层原理和源代码层面理解 HBase 的特性…...

杭电2041-2050
2041 这里进入递归专题了 #include<bits/stdc.h> #include<iostream> //简单递归 using namespace std; long long int M[45]; int main() {int n;M[1]1;M[2]1;for(int i3;i<45;i){M[i]M[i-1]M[i-2];}while(cin>>n){while(n--){int m;cin>>m;cout…...

Ambari搭建Hadoop集群 — — 问题总结
Ambari搭建Hadoop集群 — — 问题总结 一、部署教程: 参考链接:基于Ambari搭建大数据分析平台-CSDN博客 二、问题总结: 1. VMwear Workstation 查看网关 2. 资源分配 参考: 硬盘:master(29 GBÿ…...

如何用python抓取豆瓣电影TOP250
1.如何获取网站信息? (1)调用requests库、bs4库 #检查库是否下载好的方法:打开终端界面(terminal)输入pip install bs4, 如果返回的信息里有Successfully installed bs4 说明安装成功(request…...

鸽笼原理与递归 - 离散数学系列(四)
目录 1. 鸽笼原理 鸽笼原理的定义 鸽笼原理的示例 鸽笼原理的应用 2. 递归的定义与应用 什么是递归? 递归的示例 递归与迭代的对比 3. 实际应用 鸽笼原理的实际应用 递归的实际应用 4. 例题与练习 例题1:鸽笼原理应用 例题2:递归…...

Ubuntu 20.04常见配置(含yum源替换、桌面安装、防火墙设置、ntp配置)
Ubuntu 20.04常见配置 1. yum源配置2. 安装桌面及图形化2.1 安装图形化桌面2.1.1 选择安装gnome桌面2.1.2 选择安装xface桌面 2.2 安装VNC-Server 3. ufw防火墙策略4. 时区设置及NTP时间同步4.1 时区设置4.2 NTP安装及时间同步4.2.1 服务端(例:172.16.32…...

AI学习指南深度学习篇-生成对抗网络的基本原理
AI学习指南深度学习篇-生成对抗网络的基本原理 引言 生成对抗网络(Generative Adversarial Networks, GANs)是近年来深度学习领域的一个重要研究方向。GANs通过一种创新的对抗训练机制,能够生成高质量的样本,其应用范围广泛&…...

什么是网络安全
网络安全是指通过采取必要措施,防范对网络的攻击、侵入、干扰、破坏和非法使用以及意外事故,使网络处于稳定可靠运行的状态,以及保障网络数据的完整性、保密性、可用性的能力。 网络安全涉及多个层面,包括硬件、软件及其系统中数…...

Redis list 类型
list类型 类型介绍 列表类型 list 相当于 数组或者顺序表 list内部的编码方式更接近于 双端队列 ,支持头插 头删 尾插 尾删。 需要注意的是,Redis的下标支持负数下标。 比如数组大小为5,那么要访问下标为 -2 的值可以理解为访问 5 - 2 3 …...

Linux更改固定IP地址
1.VMware里更改虚拟网络 一: 二: 三:确定就好了 2.修改Linux系统的固定IP 一:进入此文件 效果如下: 执行以下命令: 此时IP已更改 3.远程连接 这个是前提!!! 更改网络编辑器后网络适配器可能会修改,我就是遇着这个,困住我了一会 一:可以以主机IP对应连接 连接成功 二:主机名连…...

Qt+大恒相机回调图片刷新使用方式
一、前言 上篇文章介绍了如何调用大恒SDK获得回调图片,这篇介绍如何使用这些图片并刷新到界面上。考虑到相机的帧率很高,比如200fps是很高的回调频率。那么我们的刷新频率是做不到这么快,也没必要这么快。一般刷新在60帧左右就够了。 二、思路…...

Docker 环境下 PostgreSQL 监控实战:从 Exporter 到 Prometheus 的部署详解
Docker 环境下 PostgreSQL 监控实战:从 Exporter 到 Prometheus 的部署详解 文章目录 Docker 环境下 PostgreSQL 监控实战:从 Exporter 到 Prometheus 的部署详解一 节点简述二 节点监控部署1)创建 PostgreSQL 的 exporter 账号2)…...

构建带有调试符号的srsRAN 4G
### 构建带有调试符号 首先确保已下载srsRAN 4G,并已创建并导航至构建文件夹: bash git clone https://github.com/srsran/srsran_4g.git cd srsRAN_4G mkdir build cd build 若srsRAN 4G已构建完成,应清除原有构建文件夹后继续。 可以使…...
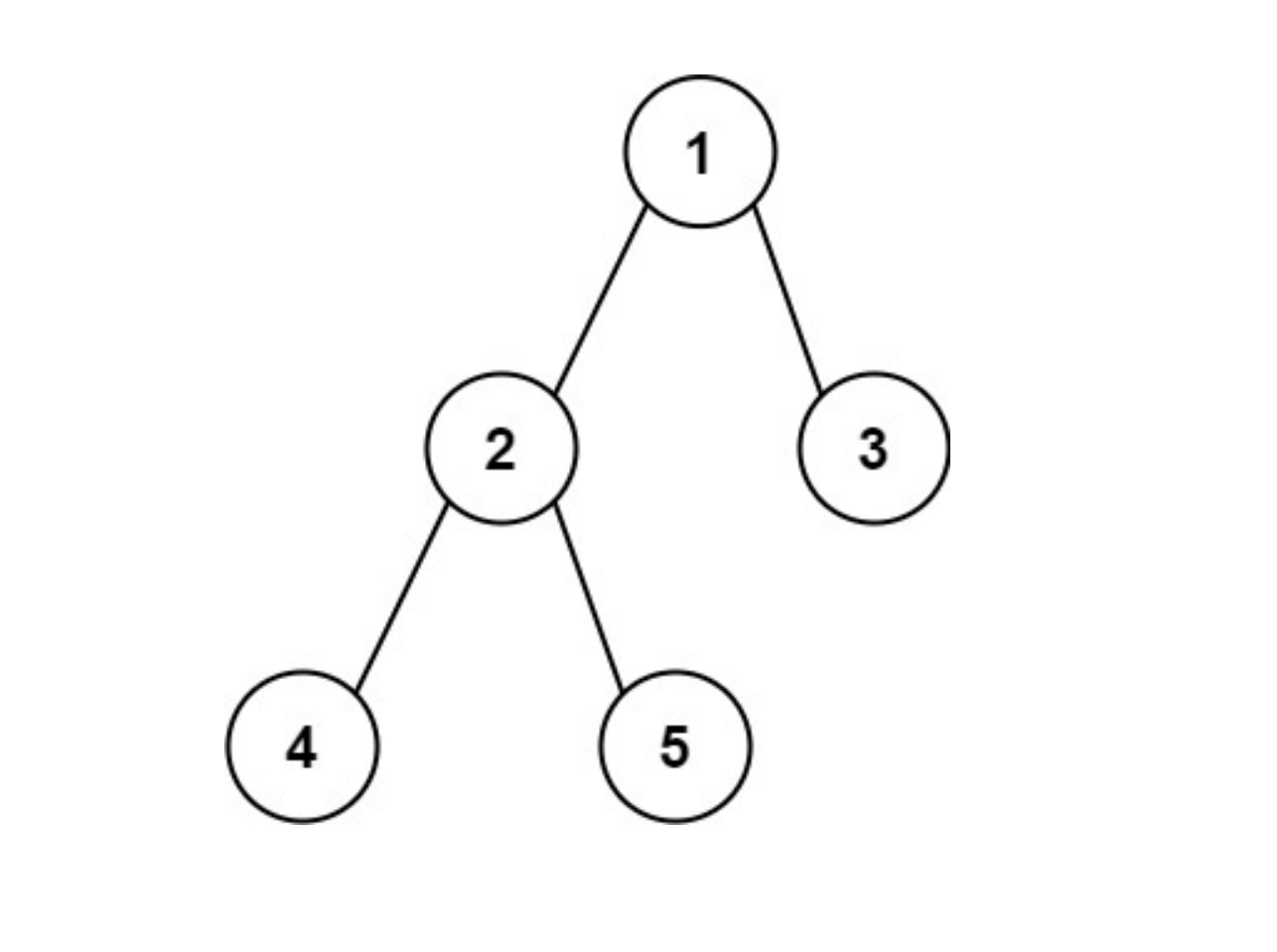
算法题总结(十)——二叉树上
#二叉树的递归遍历 // 前序遍历递归LC144_二叉树的前序遍历 class Solution {public List<Integer> preorderTraversal(TreeNode root) {List<Integer> result new ArrayList<Integer>(); //也可以把result 作为全局变量,只需要一个函数即可。…...

【MySQL】MySQL 数据库主从复制详解
目录 1. 基本概念1.1 主从架构1.2 复制类型 2. 工作原理2.1 复制过程2.2 主要组件 3. 配置步骤3.1 准备工作3.2 在主服务器上配置3.3 在从服务器上配置 4. 监控和维护4.1 监控复制状态4.2 处理复制延迟4.3 故障恢复 5. 备份策略5.1 逻辑备份与物理备份5.2 增量备份 6. 使用场景…...

一种格式化printf hex 数据的方法
格式化输出HEX数据 调试过程中通常需要个格式化输出16进制数据,为了方便美观可以参考如下方法。 #define __is_print(ch) ((unsigned int)((ch) - ) < 127u - )/*** dump_hex* * brief hex打印* * param buf: 需要打印的原始数据* param size: 原始数据类型*…...
在LabVIEW中如何读取EXCEL
在LabVIEW中读取Excel文件通常使用“报告生成工具包”(Report Generation Toolkit)。以下是详细步骤: 安装工具包:确保已安装“报告生成工具包”。这通常随LabVIEW一起提供,但需要单独安装。 创建VI: 打…...

布匹瑕疵检测数据集 4类 2800张 布料缺陷 带标注 voc yolo
布匹瑕疵检测数据集 4类 2800张 布料缺陷 带标注 voc yolo 对应标注,格式VOC (XML),选配Y0L0(TXT) label| pic_ num| box_ _num hole: (425, 481) suspension_ wire: (1739, 1782) topbasi: (46, 46) dirty: (613&…...

灵动微高集成度电机MCU单片机
由于锂电技术的持续进步、消费者需求的演变、工具种类的革新以及应用领域的扩展,电动工具行业正呈现出无绳化、锂电化、大功率化、小型化、智能化和一机多能化的发展趋势。无绳化和锂电化的电动工具因其便携性和高效能的特性,已成为市场增长的重要驱动力…...

陪护小程序|护理陪护系统|陪护小程序成品
智能化,作为智慧医疗宏伟蓝图的基石,正引领着一场医疗服务的深刻变革。在这场变革的浪潮中,智慧医院小程序犹如璀璨新星,迅速崛起,而陪护小程序的诞生,更是如春风化雨,细腻地触及了老年病患、家…...

Windows驱动管理终极指南:DriverStore Explorer完全使用手册,轻松解决磁盘空间和驱动冲突问题
Windows驱动管理终极指南:DriverStore Explorer完全使用手册,轻松解决磁盘空间和驱动冲突问题 【免费下载链接】DriverStoreExplorer Driver Store Explorer 项目地址: https://gitcode.com/gh_mirrors/dr/DriverStoreExplorer 你是否曾经因为C盘…...

Codex 上下文提供详解与操作指南
1. 文档目标 这份文档解决的是一个非常实际的问题: 怎么给 Codex 足够完整的上下文什么信息是必须给的,什么信息是可选但高价值的怎样让 Codex 在一次任务里快速进入正确状态怎样避免“我已经说了很多,但结果还是不对”怎样把上下文提供方式变…...

CentOS 8 安装 Docker 超详细教程
CentOS 8 安装 Docker 超详细教程 适用于 CentOS 8 / CentOS Stream 8,从零开始直到运行第一个容器。 一、准备工作 1. 检查系统版本 cat /etc/redhat-release看到 CentOS Linux release 8.5.2111 或 CentOS Stream release 8 即可继续。 2. 卸载旧版本 Docker …...

Windows平台终极ADB驱动环境一键配置指南:告别繁琐,专注开发
Windows平台终极ADB驱动环境一键配置指南:告别繁琐,专注开发 【免费下载链接】Latest-adb-fastboot-installer-for-windows A Simple Android Driver installer tool for windows (Always installs the latest version) 项目地址: https://gitcode.com…...

从零构建卡牌游戏引擎:事件驱动架构与数据驱动设计实践
1. 项目概述:从零构建一个卡牌构筑游戏引擎最近在GitHub上看到一个挺有意思的项目,叫guladam/deck_builder_tutorial。光看名字,很多开发者,尤其是对游戏开发感兴趣的朋友,可能立刻就能会心一笑。没错,这正…...

基于容器化与微服务架构的无限路由器:云原生网络控制平台实践
1. 项目概述:一个“无限”路由器的诞生最近在折腾家庭网络和边缘计算项目时,我遇到了一个经典难题:如何在资源受限的硬件上,实现一个功能强大、可扩展且易于管理的网络路由与策略中心?市面上的成品路由器固件ÿ…...

从零构建千万级IM系统:微服务架构与核心消息流转实战
1. 项目概述:从零理解一个现代即时通讯系统的核心如果你正在寻找一个能支撑起千万级用户、功能对标主流商业产品的即时通讯(IM)系统开源实现,那么open-im-server绝对是一个绕不开的名字。这个由OpenIM项目开源的Go语言服务端&…...

不只是安装:用MATLAB+RTL-SDR硬件支持包快速上手你的第一个无线信号接收项目
不只是安装:用MATLABRTL-SDR硬件支持包快速上手你的第一个无线信号接收项目 当你第一次将RTL-SDR设备插入电脑,安装完MATLAB硬件支持包后,那种既兴奋又迷茫的感觉可能还记忆犹新。硬件已经就绪,软件也已安装,但接下来该…...

NoFences:三分钟让你的Windows桌面从混乱到有序的免费开源方案
NoFences:三分钟让你的Windows桌面从混乱到有序的免费开源方案 【免费下载链接】NoFences 🚧 Open Source Stardock Fences alternative 项目地址: https://gitcode.com/gh_mirrors/no/NoFences 你是否也曾面对满屏杂乱无章的图标感到无从下手&am…...

深度解析Beyond Compare 5密钥生成:从逆向工程到高效激活的实用指南
深度解析Beyond Compare 5密钥生成:从逆向工程到高效激活的实用指南 【免费下载链接】BCompare_Keygen Keygen for BCompare 5 项目地址: https://gitcode.com/gh_mirrors/bc/BCompare_Keygen 在软件授权验证领域,Beyond Compare 5的RSA加密机制一…...