LSTM变种模型
一、GRU
1.概念
GRU(门控循环单元,Gated Recurrent Unit)是一种循环神经网络(RNN)的变体,旨在解决标准 RNN 在处理长期依赖关系时遇到的梯度消失问题。GRU 通过引入门控机制简化了 LSTM(长短期记忆网络)的设计,使得模型更轻便,同时保留了 LSTM 的优点。
2.原理
2.1.两个重大改进
1.将输入门、遗忘门、输出门三个门变为更新门(Updata Gate)和重置门(Reset Gate)两个门。
2.将 (候选) 单元状态 与 隐藏状态 (输出) 合并,即只有 当前时刻候选隐藏状态 和 当前时刻隐藏状态
。
2.2模型结构
简化图:

内部结构:

GRU通过其门控机制能够有效地捕捉到序列数据中的时间动态,同时相较于LSTM来说,由于其结构更加简洁,通常参数更少,计算效率更高。
2.2.1 重置门

重置门决定在计算当前候选隐藏状态时,忽略多少过去的信息。

2.2.2 更新门

更新门决定了多少过去的信息将被保留。它使用前一时间步的隐藏状态 ( h_{t-1} ) 和当前输入 ( x_t ) 来计算得出。
2.2.3 候选隐藏状态

候选隐藏状态是当前时间步的建议更新,它包含了当前输入和过去的隐藏状态的信息。重置门的作用体现在它可以允许模型抛弃或保留之前的隐藏状态。

2.2.4 最终隐藏状态

最终隐藏状态是通过融合过去的隐藏状态和当前候选隐藏状态来计算得出的。更新门 控制了融合过去信息和当前信息的比例。

忘记传递下来的
中的某些信息,并加入当前节点输入的某些信息。这就是最终的记忆。
3. 代码实现
3.1 原生代码
import numpy as np class GRU:def __init__(self, input_size, hidden_size):self.input_size = input_sizeself.hidden_size = hidden_size# 初始化w和b 更新门self.W_z = np.random.rand(hidden_size, input_size + hidden_size)self.b_z = np.zeros(hidden_size)#重置门self.W_r = np.random.rand(hidden_size, input_size + hidden_size)self.b_r = np.zeros(hidden_size)#候选隐藏状态self.W_h = np.random.rand(hidden_size, input_size + hidden_size)self.b_h = np.zeros(hidden_size)def tanh(self, x):return np.tanh(x)def sigmoid(self, x):return 1 / (1 + np.exp(-x))def forward(self, x):#初始化隐藏状态h_prev=np.zeros((self.hidden_size,))concat_input=np.concatenate([x, h_prev],axis=0) z_t=self.sigmoid(np.dot(self.W_z,concat_input)+self.b_z)r_t=self.sigmoid(np.dot(self.W_r,concat_input)+self.b_r) concat_reset_input=np.concatenate([x,r_t*h_prev],axis=0)h_hat_t=self.tanh(np.dot(self.W_h,concat_reset_input)+self.b_h) h_t=(1-z_t)*h_prev+z_t*h_hat_t return h_t # 测试数据 input_size=3 hidden_size=2 seq_len=4 x=np.random.randn(seq_len,input_size) gru=GRU(input_size,hidden_size) all_h=[] for t in range(seq_len):h_t=gru.forward(x[t,:])all_h.append(h_t)print(h_t.shape) print(np.array(all_h).shape)
3.2 PyTorch
nn.GRUCell
import torch import torch.nn as nn class GRUCell(nn.Module): def __init__(self,input_size,hidden_size):super(GRUCell,self).__init__()self.input_size = input_sizeself.hidden_size = hidden_sizeself.gru_cell=nn.GRUCell(input_size,hidden_size)def forward(self,x):h_t=self.gru_cell(x)return h_t# 测试数据 input_size=3 hidden_size=2 seq_len=4 gru_model=GRUCell(input_size,hidden_size) x=torch.randn(seq_len,input_size) for t in range(seq_len):h_t=gru_model(x[t])print(h_t)
nn.GRU
import torch import torch.nn as nn class GRU(nn.Module):def __init__(self,input_size,hidden_size):super(GRU,self).__init__()self.input_size = input_sizeself.hidden_size = hidden_sizeself.gru=nn.GRU(input_size,hidden_size)def forward(self,x):out,_=self.gru(x)return out# 测试数据 input_size=3 hidden_size=2 seq_len=4 batch_size=5 x=torch.randn(seq_len,batch_size,input_size) gru_mosel=GRU(input_size,hidden_size) out=gru_mosel(x) print(out) print(out.shape)
二、BiLSTM
1.概述
双向长短期记忆网络(BiLSTM)是长短期记忆网络(LSTM)的扩展,旨在同时考虑序列数据中的过去和未来信息。BiLSTM 通过引入两个独立的 LSTM 层,一个正向处理输入序列,另一个逆向处理,使得每个时间步的输出包含了该时间步前后的信息。这种双向结构能够更有效地捕捉序列中的上下文关系,从而提高模型对语义的理解能力。
-
正向传递: 输入序列按照时间顺序被输入到第一个LSTM层。每个时间步的输出都会被计算并保留下来。
-
反向传递: 输入序列按照时间的逆序(即先输入最后一个元素)被输入到第二个LSTM层。与正向传递类似,每个时间步的输出都会被计算并保留下来。
-
合并输出: 在每个时间步,将两个LSTM层的输出通过某种方式合并(如拼接或加和)以得到最终的输出。

2. BILSTM模型应用背景
命名体识别

标注集
BMES标注集
分词的标注集并非只有一种,举例中文分词的情况,汉子作为词语开始Begin,结束End,中间Middle,单字Single,这四种情况就可以囊括所有的分词情况。于是就有了BMES标注集,这样的标注集在命名实体识别任务中也非常常见。

词性标注
在序列标注问题中单词序列就是x,词性序列就是y,当前词词性的判定需要综合考虑前后单词的词性。而标注集最著名的就是863标注集和北大标注集。

3. 代码实现
原生代码
import numpy as np import torch class BiLSTM():def __init__(self, input_size, hidden_size,output_size):self.input_size = input_sizeself.hidden_size = hidden_sizeself.output_size = output_size#正向self.lstm_forward = LSTM(input_size, hidden_size,output_size)#反向self.lstm_backward = LSTM(input_size, hidden_size,output_size)def forward(self,x):# 正向LSTMoutput,_,_=self.lstm_forward.forward(x)# 反向LSTM,np.flip()是将数组进行翻转output_backward,_,_=self.lstm_backward.forward(np.flip(x,1))#合并两层的隐藏状态combine_output=[np.concatenate((x,y),axis=0) for x,y in zip(output,output_backward)]return combine_outputclass LSTM:def __init__(self, input_size, hidden_size,output_size):""":param input_size: 词向量大小:param hidden_size: 隐藏层大小:param output_size: 输出类别"""self.input_size = input_sizeself.hidden_size = hidden_sizeself.output_size = output_size # 初始化权重和偏置 我们把结构图上的W U 拼接在了一起 所以参数是 input_size+hidden_sizeself.w_f = np.random.rand(hidden_size, input_size+hidden_size)self.b_f = np.random.rand(hidden_size) self.w_i = np.random.rand(hidden_size, input_size+hidden_size)self.b_i = np.random.rand(hidden_size) self.w_c = np.random.rand(hidden_size, input_size+hidden_size)self.b_c = np.random.rand(hidden_size) self.w_o = np.random.rand(hidden_size, input_size+hidden_size)self.b_o = np.random.rand(hidden_size) # 输出层self.w_y = np.random.rand(output_size, hidden_size)self.b_y = np.random.rand(output_size) def tanh(self,x):return np.tanh(x) def sigmoid(self,x):return 1/(1+np.exp(-x)) def forward(self,x):h_t = np.zeros((self.hidden_size,)) # 初始隐藏状态c_t = np.zeros((self.hidden_size,)) # 初始细胞状态 h_states = [] # 存储每个时间步的隐藏状态c_states = [] # 存储每个时间步的细胞状态 for t in range(x.shape[0]):x_t = x[t] # 当前时间步的输入# concatenate 将x_t和h_t拼接 垂直方向x_t = np.concatenate([x_t,h_t]) # 遗忘门f_t = self.sigmoid(np.dot(self.w_f,x_t)+self.b_f) # 输入门i_t = self.sigmoid(np.dot(self.w_i,x_t)+self.b_i)# 候选细胞状态c_hat_t = self.tanh(np.dot(self.w_c,x_t)+self.b_c) # 更新细胞状态c_t = f_t*c_t + i_t*c_hat_t # 输出门o_t = self.sigmoid(np.dot(self.w_o,x_t)+self.b_o)# 更新隐藏状态h_t = o_t*self.tanh(c_t) # 保存每个时间步的隐藏状态和细胞状态h_states.append(h_t)c_states.append(c_t) # 输出层 对最后一个时间步的隐藏状态进行预测,分类类别y_t = np.dot(self.w_y,h_t)+self.b_y# 转成张量形式 dim 0 表示行的维度output = torch.softmax(torch.tensor(y_t),dim=0) return np.array(h_states), np.array(c_states), output # 测试数据 input_size=3 hidden_size=8 output_size=5 seq_len=4 x=np.random.randn(seq_len,input_size) bilstm=BiLSTM(input_size,hidden_size,output_size) outputs=bilstm.forward(x) print(outputs) print(np.array(outputs).shape)
# --------------------------------------------------------------------------- import numpy as np # 创建一个包含两个二维数组的列表 inputs = [np.array([[0.1], [0.2], [0.3]]), np.array([[0.4], [0.5], [0.6]])] # 使用 numpy 库中的 np.stack 函数。这会将输入的二维数组堆叠在一起,从而形成一个新的三维数组 inputs_3d = np.stack(inputs) # 将三维数组转换为列表 list_from_3d_array = inputs_3d.tolist() print(list_from_3d_array)
Pytorch
import torch import torch.nn as nn class BiLSTM(nn.Module):def __init__(self, input_size, hidden_size,output_size):super(BiLSTM, self).__init__()#定义双向LSTMself.lstm=nn.LSTM(input_size,hidden_size,bidirectional=True)#输出层 因为双向LSTM的输出是双向的,所以第一个参数是隐藏层*2self.linear=nn.Linear(hidden_size*2,output_size) def forward(self,x):out,_=self.lstm(x)linear_out=self.linear(out)return linear_out# 测试数据 input_size=3 hidden_size=8 output_size=5 seq_len=4 batch_size=6 x=torch.randn(seq_len,batch_size,input_size) model=BiLSTM(input_size,hidden_size,output_size) outputs=model(x) print(outputs) print(outputs.shape)
相关文章:
LSTM变种模型
一、GRU 1.概念 GRU(门控循环单元,Gated Recurrent Unit)是一种循环神经网络(RNN)的变体,旨在解决标准 RNN 在处理长期依赖关系时遇到的梯度消失问题。GRU 通过引入门控机制简化了 LSTM(长短期…...

Python进阶--函数进阶
目录 1. 函数多返回值 2. 函数多种传参方式 (1). 位置参数 (2). 关键字参数 (3). 缺省参数 (4). 不定长参数 3. 匿名函数 (1). 函数作为参数传递 (2). lambda匿名函数 1. 函数多返回值 def return_num():return 1# 返回1之后就不会再向下继续执行函数体return 2 resu…...

elasticsearch 8.2 设置账号密码
背景:单节点集群数据写入测试-CSDN博客 前述项目支持设置账号密码,但8+版本似乎不能那么做了。 ERROR: [1] bootstrap checks failed. You must address the points described in the following [1] lines before starting Elasticsearch. bootstrap check failure [1] of…...

JavaScript代码如何测试?
测试JavaScript代码是确保其功能、性能和可靠性的关键步骤。以下是一些详细的步骤和方法,用于测试JavaScript代码: 1、编写测试用例 首先,你需要为要测试的JavaScript代码编写测试用例。这些用例应该涵盖代码的各种功能和场景,包…...
案例分享—国外ui设计优秀案例
国外企业更注重用户体验设计,倾向于简洁清晰的设计风格,以提高用户的使用体验和操作效率。他们注重“简约至上”的设计理念,认为简洁的设计可以减少用户的认知负担,提高用户的工作效率。 设计师在界面设计中往往更加注重创意性和个…...

在JavaScript中,改变this指向的call,apply,bind有什么区别,原理分别是什么?
在JavaScript中,call、apply和bind方法都是用来改变函数执行时this指向的。 以下通过一个Demo帮助理解,代码如下: var obj {name: lisi,sayHello: function() {console.log(this.name)} } obj.sayHello()// lisifunction sayHello() {conso…...

Redis 缓存策略详解:提升性能的四种常见模式
在现代分布式系统中,缓存是提升性能和减轻数据库负载的关键组件。Redis 作为一种高性能的内存数据库,被广泛应用于缓存层。本文将深入探讨几种常用的 Redis 缓存策略,包括旁路缓存模式(Cache-Aside Pattern)、读穿透模…...
怎么建设网站吸引并留住客户
如何建设网站吸引并留住客户 在当今数字化时代,网站是企业与客户沟通的重要桥梁。一个设计精良、功能完备的网站不仅能吸引客户的注意,还能有效留住他们。以下是一些建设网站的关键策略。 **1. 用户体验优先** 网站的整体用户体验(UX&#x…...

培训行业为什么要搭建自己的知识付费小程序平台?集师知识付费系统 集师知识付费小程序 集师知识服务系统 集师线上培训系统 集师线上卖课小程序
在当今这个信息爆炸的时代,培训行业正面临前所未有的变革与挑战。传统的线下授课模式虽然经典,但在互联网技术的冲击下,其局限性日益凸显。为了更好地适应市场需求,提升服务效率与用户体验,培训行业亟需搭建自己的知识…...

Linux:Linux进程概念
✨✨✨学习的道路很枯燥,希望我们能并肩走下来! 文章目录 目录 文章目录 前言 一 冯诺依曼体系结构 二 操作系统(Operator System) 2.1 概念 2.2 设计OS的目的 编辑 2.3 OS如何进行管理 编辑2.4 总结 三 进程的标示符 3.1 基本概念…...

专题九_递归_算法专题详细总结
目录 递归 1.什么是递归? 2.为什么会用到递归? 3.如何理解递归? 1.递归展开的细节图 2.二叉树中的题目 3.宏观看待递归的过程 1) 不要在意细节的展开图 2) 把递归的函数当作一个黑盒 3) 相信这个黑盒一定能够完成这个任务 4.如何写…...
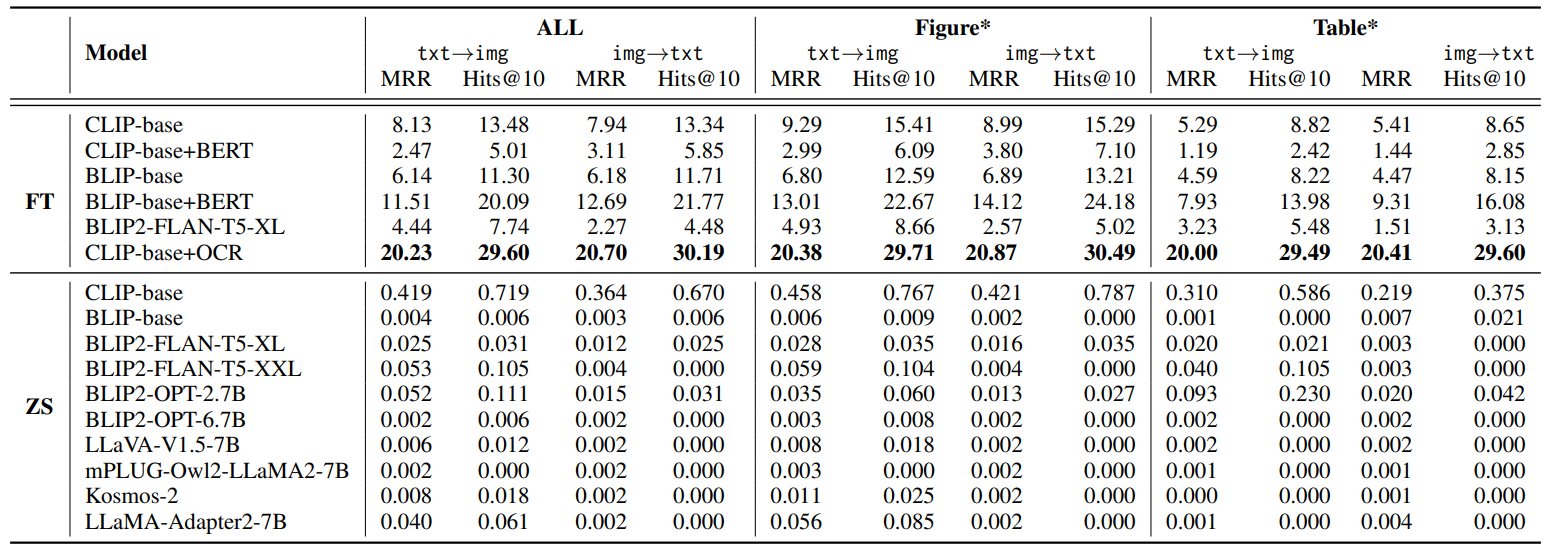
性能赶超GPT-4!多模态检索最新成果刷爆SOTA!顶会思路确定不学?
关注各大顶会的同学们都知道,今年多模态相关的主题可谓是火爆非常,有许多突破性成果被提出,比如最新的多模态检索增强框架MORE,生成性能猛超GPT-4! 再比如多模态检索模型MARVEL,在所有基准上实现SOTA&…...

基于 Qwen2.5-0.5B 微调训练 Ner 命名实体识别任务
一、Qwen2.5 & 数据集 Qwen2.5 是 Qwen 大型语言模型的最新系列,参数范围从 0.5B 到 72B 不等。 对比 Qwen2 最新的 Qwen2.5 进行了以下改进: 知识明显增加,并且大大提高了编码和数学能力。在指令跟随、生成长文本(超过 8K…...

16【Protues51单片机仿真】智能洗衣机倒计时系统
目录 一、主要功能 二、硬件资源 三、程序编程 四、实现现象 一、主要功能 用直流电机转动模拟洗衣机。要求 有弱洗、普通洗、强洗三种模式,可通过按键选择。可以设置洗衣时长,通关按键选择15、30、45、60、90分钟。时间到蜂鸣器报警提示。LCD 显示…...
爱心曲线公式大全
local r a*((math.sin(angle) * math.sqrt(math.abs(math.cos(angle)))) / (math.sin(angle) 1.4142) - 2 * math.sin(angle) 2) local x r * math.cos(angle) -- 计算对应的x值 local z r * math.sin(angle) 1.5*a - --曲线公式绘画 local function generateParabola()…...

新书速览|你好,C++
《你好,C》 本书内容 《你好,C》主要介绍C开发环境的搭建、基础语法知识、面向对象编程思想以及标准模板库的应用,特别针对初学者在学习C过程中可能遇到的难点提供了解决方案。全书共分13章,以一个工资程序的不断优化和完善为线索…...

ufw:Linux网络防火墙
一、命令简介 ufw(Uncomplicated Firewall)是一个为 Linux 系统提供简单易用的命令行界面的防火墙管理工具。它是基于 iptables 的,但提供了更简洁的语法和更直观的操作方式,使得配置防火墙变得更加简单,特别适…...

[C++]使用纯opencv部署yolov11-cls图像分类onnx模型
【算法介绍】 在C中使用纯OpenCV部署YOLOv11-cls图像分类ONNX模型是一项具有挑战性的任务,因为YOLOv11通常是用PyTorch等深度学习框架实现的,而OpenCV本身并不直接支持加载和运行PyTorch模型。然而,可以通过一些间接的方法来实现这一目标&am…...

如何使用Immersity AI将图片转换成3D效果视频
随着技术的进步,图片处理变得越来越强大和直观。借助Immersity AI这样的工具,我们现在可以轻松地将平面图片转换成3D效果视频。以下是如何使用Immersity AI进行这一转换的详细步骤。 第一步:访问Immersity AI网站 首先,打开你的…...

安全运营 -- GPO审计
0x00 背景 审计GPO,目的是审计哪些GPO权限分配不合理,包括但不限于审计预期以外的用户具有对GPO的写权限。 0x01 开启审核 在一台windows服务器上 开始 -- 运行 -- 输入 server manager 依次点击Manage -- Add Roles and Features Wizard 角色和功能…...

太顶了!输入主题,这几款AI论文软件自动生成毕业论文初稿!
毕业季论文焦虑?还在为选题、查资料、写大纲、润色修改熬夜到凌晨?别担心,现在只需输入主题,几款AI论文工具就能自动生成图文并茂的毕业论文初稿,从开题到定稿全流程搞定!千笔AI、ThouPen、豆包、DeepSeek、…...

HS2汉化补丁终极指南:轻松实现Honey Select 2中文界面
HS2汉化补丁终极指南:轻松实现Honey Select 2中文界面 【免费下载链接】HS2-HF_Patch Automatically translate, uncensor and update HoneySelect2! 项目地址: https://gitcode.com/gh_mirrors/hs/HS2-HF_Patch 还在为Honey Select 2的日文界面而困扰吗&…...

家庭宽带上网背后的隐形功臣:一文拆解光猫/路由器里的NAT和DHCP是怎么协同工作的
家庭网络中的隐形守护者:NAT与DHCP如何编织你的数字生活 当你躺在沙发上用手机追剧时,是否想过为什么所有家庭设备都能和平共处在同一网络?192.168.1.x这串神秘数字背后,藏着两套精密的协议系统——它们像建筑物的水电管线般隐形却…...

程序员需求攀升:数字化浪潮下的行业必然
在数字经济深度渗透的今天,软件开发行业正经历着前所未有的扩张期,程序员岗位需求的持续攀升成为行业发展的鲜明特征。作为与开发环节紧密联动的测试从业者,深入理解这一现象背后的逻辑,不仅能帮助我们把握行业趋势,更…...

2026年AI论文网站盘点:12款神器助你高效完成学术写作、润色和降重
随着 AI 技术的持续突破,2026 年的论文写作工具市场已迈入“智能化、精细化、合规化”的新阶段。从本科生的课程论文到研究生的学位论文,再到科研人员的期刊投稿,AI 工具正在深度融入各类学术场景,为不同层次的写作者提供精准支持…...

大学生零基础打CTF比赛全攻略:要学啥、怎么学,看完就能参赛
大学生零基础打CTF比赛全攻略:要学啥、怎么学,看完就能参赛(干货版) 摘要:对大学生来说,CTF(Capture The Flag,夺旗赛)不仅是网络安全领域最具实战性的竞赛,…...

为什么92%的Lovable新手在第5小时放弃?——资深架构师拆解3个致命认知盲区
更多请点击: https://codechina.net 第一章:Lovable应用开发入门与环境搭建 Lovable 是一个面向现代 Web 应用的轻量级全栈框架,专为快速构建可维护、可扩展且富有表现力的交互式应用而设计。它融合了声明式 UI、响应式状态管理与内置服务抽…...
3个核心功能:用HSTracker将炉石传说数据转化为你的制胜优势
3个核心功能:用HSTracker将炉石传说数据转化为你的制胜优势 【免费下载链接】HSTracker A deck tracker and deck manager for Hearthstone on macOS 项目地址: https://gitcode.com/gh_mirrors/hs/HSTracker 在炉石传说的竞技场上,每一张卡牌的抽…...
Pixelle-Video完整指南:5分钟掌握AI全自动短视频制作
Pixelle-Video完整指南:5分钟掌握AI全自动短视频制作 【免费下载链接】Pixelle-Video 🚀 AI 全自动短视频引擎 | AI Fully Automated Short Video Engine 项目地址: https://gitcode.com/GitHub_Trending/pi/Pixelle-Video Pixelle-Video是一款革…...

US Visa Bot:开源智能预约解决方案,告别签证等待焦虑
US Visa Bot:开源智能预约解决方案,告别签证等待焦虑 【免费下载链接】us-visa-bot US Visa Bot 项目地址: https://gitcode.com/gh_mirrors/us/us-visa-bot 您是否曾经为了一个美国签证面试日期而反复刷新页面,却总是错过最佳时机&am…...