基于组合模型的公交交通客流预测研究
摘 要
本研究致力于解决公交客流预测问题,旨在通过融合多种机器学习模型的强大能力,提升预测准确性,为城市公交系统的优化运营和交通管理提供科学依据。研究首先回顾了公交客流预测领域的相关文献,分析了传统统计方法在处理大规模和高维度数据时的局限性,并详细探讨了机器学习和深度学习技术在提高预测准确度和处理复杂数据特征方面的优势。
在数据收集阶段,本研究详细描述了数据的来源,包括天气状况、节假日信息等多种影响因素,强调了从高质量数据源获取数据的重要性。接着,研究着重于数据预处理和特征工程的过程,包括清洗数据、处理缺失值、识别和处理异常值,以及从时间戳信息中提取关键特征,如年、月、日和小时等。这些步骤对于确保数据质量和为模型训练提供准确的输入至关重要。
在模型构建阶段,本研究基于模型的预测性能、计算效率和适应性进行了详细的评估,选定了随机森林、XGBoost和LightGBM等单一模型作为基础模型,并通过细致的参数调优过程,确保了这些模型能够在特定的数据集上达到最优性能。
研究的核心在于组合模型的构建与实现,通过集成前述优化后的单一模型,并采用堆叠回归方法作为元模型,实现了预测性能的显著提升。通过对比实验,本研究展示了组合模型在预测精度、鲁棒性和泛化能力方面相比单一模型的明显优势。
最后,本研究通过一个实际的城市公交系统案例,展示了组合模型在真实世界应用中的有效性,证实了其在优化公交运营和提升城市交通管理效率方面的实用价值。同时,研究也讨论了存在的局限性和未来研究方向,指出了进一步提升数据质量、探索模型泛化能力和应用先进的机器学习算法的重要性。
总体而言,本研究不仅在理论上为公交客流预测提供了新的视角和方法,而且在实践层面为城市交通系统的高效运营和智能化管理提供了有效的技术支持,具有重要的学术价值和应用前景。
第1章 绪论
1.1 研究背景及意义
在城市交通系统中,公交作为主要的公共交通工具,承载了大量的人流,其运行效率和服务质量直接关联着城市的动脉。随着城市化进程的加快,公交客流量日益增长,公交系统面临着巨大的运营压力。准确预测公交客流对于优化公交资源分配、提高运营效率、缓解交通拥堵等具有重要的实际意义。传统的公交客流预测方法往往依赖于历史数据和经验模型.....
1.2 国内外研究现状与发展趋势
在国内外学术界和工业界,公交客流预测一直是城市交通研究的热点领域。近年来,由于大数据技术和人工智能算法的迅猛发展,这一领域的研究和实践取得了显著进展。国内研究多集中在传统统计模型和机器学习方法的应用.......
1.3 研究目的与主要内容
本研究旨在通过深入分析和研究公交客流量的影响因素,构建一个基于组合模型的公交客流量预测系统,以提高预测的准确性和可靠性,并为公交运营管理和城市交通规划提供科学的决策支持。鉴于目前公交客流预测领域面临的挑战和发展趋势,本研究的主要内容包括以下几个方面:
首要目标.......
1.4 文献综述
1.4.1 公交客流预测的传统方法
公交客流预测的传统方法主.......
1.4.2 机器学习与深度学习在公交客流预测中的应用
随着计算能力的提升和数据科学技术的进步,机器学习与深度学习在公交客流预测领域得.......
1.4.3 组合模型在其他领域的应用及其优势
组合模型作为一种将多个预测模.......
2.1 数据来源与收集
本研究采用的数据集是明尼阿波里斯都会区州际公路的交通流量数据,该数据集涵盖了2012年至2018年间的详细交通流量记录,以小时为单位记录。数据来源于加利福尼亚大学欧文分校机器学习存储库(UCI Machine Learning Repository),该存储库是一个广泛收集和共享机器学习和数据挖掘领域数据集的著名平台。具体数据集
该数据集不仅包含了每小时的交通流量统计,而且还综合了影响交通流量的多种因素,包括天气情况、节假日等。具体变量如下:
- 假期(Holiday):标识所记录时间是否为美国的公共假期,如国庆日、感恩节等,非假期时间则标记为"None"。
- 温度(Temp):以开尔文为单位记录的温度,这对于理解不同温度下的交通流量变化十分关键。
- 降雨量(Rain_1h):过去一小时内的降雨量,以毫米计,影响道路条件和驾驶者的出行选择。
- 降雪量(Snow_1h):过去一小时内的降雪量,以毫米计,降雪对交通流量的影响尤为显著。
- 云量(Clouds_all):天空云量的百分比,反映了天气状况对交通的潜在影响。
- 主要天气(Weather_main):描述天气的主要类别,如晴天、多云、雨天等。
- 天气描述(Weather_description):对主要天气的进一步描述,如“散云”、“破云”等,提供了更详细的天气信息。
- 日期和时间(Date_time):记录的具体日期和时间,精确到小时,为研究提供了时间序列分析的可能性。
- 交通流量(Traffic_volume):目标变量,记录每小时的车流量,为研究交通模式和预测交通流量提供了基础。
数据收集工作由明尼阿波里斯和圣保罗都会区的州际公路自动车流量检测系统完成,确保了数据的真实性和准确性。通过分析这些数据,研究人员可以探究不同天气条件、时间和节假日对交通流量的影响,为城市交通管理和规划提供科学依据。
2.2 数据预处理与特征工程
在本研究中,数据预处理和特征工程是构建高效预测模型的重要步骤。我们关注的数据集包含了交通流量及其相关因素,如天气状况、日期和时间等。为了确保模型能够从这些数据中学习到有用的信息,我们必须首先清洗和转换数据,使其适合进行机器学习分析。
数据预处理流程开始于删除重复的记录。这一步是必要的,因为重复的数据可能会扭曲模型的训练过程,导致过拟合。紧接着,我们对数据集进行了缺失值检查,发现数据集中没有显著的缺失值。这一发现表明数据的完整性较高,不需要进行进一步的缺失值处理。
接下来,我们将date_time字段从字符串转换为日期时间格式,这使得我们能够从中提取出年、月、日和小时等时间单位。这些衍生的时间特征对于我们的分析至.........
第3章 单一模型的选择与构建
3.1 单一模型的选择依据
在处理时间序列回归问题时,模型选择是一个关键环节,它直接影响到预测的准确性和可靠性。随机森林、XGBoost和LightGBM是当前数据科学领域中广泛应用于回归问题的三种强大模型,每种模型都有其独特的优势,适用于不同类型的时间序列数据和预测需求。
3.2 单一模型的构建与参数调优
在本研究中,我们关注于构建和优化单一模型来预测给定的时间序列数据。特别地,我们集中在三种流行的机器学习算法上:随机森林、XGBoost和LightGBM。这些模型因其在处理复杂数据集时表现出的高效性和准确性而被广泛采用。构建模型的过程涉及到模型的初始化、训练和预测,而参数调优则是通过网格搜索方法来实现的,旨在进一步提升模型性能。
随机森林模型是以决策树为基础构建的集成学习模型,它通过创建多个决策树并综合它们的预测结果来提高预测的准确性和稳定性。我们初始化了一个随机森林回归器,并设置了100棵树作为模型的基础。通过在训练数据上训练该模型,我们能够得到对测试集的预测结果。进一步,我们计算了模型在测试集上的均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)和R²值,以全面评估模型的性能。结果显示,随机森林模型在测试集上的R²值接近0.78,表明模型能够较好地解释目标变量的方差。
接下来,我们采用XGBoost和LightGBM两种基于梯度提升的算法。XGBoost是一种优化的分布式梯度提升库,能够有效地处理大规模数据,而LightGBM则是一种基于梯度提升的轻量级框架,特别适合处理大数据集。与随机森林模型相同,我们分别初始化了XGBoost和LightGBM模型,并在训练集上进行了训练。通过在测试集上的预测,我们发现这两种模型的性能与随机森林模型相似,R²值均接近0.78,这表明它们同样能够有效地预测时间序列数据。
为了进一步提升模型性能,我们对每种模型进行了参数优化。通过网格搜索方法,我们探索了模型的关键参数,如随机森林的树的数量、最大深度、最小样本分割数和最小样本叶节点数;XGBoost的树的数量、最大深度、学习率和子样本比例;以及LightGBM的树的数量、最大深度、学习率、叶子数量和子样本比例。网格搜索在指定的参数范围内尝试所有可能的参数组合,以找到最优化模型性能的参数设置。通过在训练集上进行交叉验证,我们能够确定每个模型的最佳参数组合,并使用这些参数重新训练模型。

图 1网格搜索展示
优化后的模型在测试集上的性能有所提升,随机森林、XGBoost和LightGBM模型的R²值均显示了轻微的增加,表明参数优化有助于提高模型的预测准确性。特别地,优化后的随机森林模型在测试集上的R²值提高到了0.78,而XGBoost和LightGBM模型的R²值也接近此水平。这些结果证实了参数优化对于提升模型性能的重要性,并且突显了网格搜索作为一种有效的参数优化技术。
总之,通过构建随机森林、XGBoost和LightGBM三种单一模型并进行参数优化,我们能够有效地预测时间序列数据。每种模型的初始化、训练和预测步骤为我们提供了对数据集特征的深入理解,而参数优化进一步提升了模型的预测性能。这一过程不仅展示了机器学习在时间序列预测中的应用,也强调了参数优化在提升模型性能中的关键作用。
图 2 优化结果展示
第4章 组合模型的设计与实现
4.1 组合模型的设计思路
在本研究中,我们采用了堆叠回归(StackingRegressor)作为组合模型的核心框架,以整合随机森林、XGBoost和LightGBM三种不同的单一模型,目的是利用各个模型的优势,提高整体预测性能。堆叠模型的设计思路是在原有基模型的预测基础上,引入一个元模型(Meta Model),通过元模型学习如何最优地结合各个基模型的预测结果。
在构建堆叠模型时,首先定义了三个基模型:优化后的随机森林、XGBoost和LightGBM。这三个模型在许多回归问题上已经证明了它们的有效性,分别代表了基于树的集成学习、梯度提升机和轻量级梯度提升框架的不同算法。通过将这些强大的模型作为基模型,我们能够捕获数据中的不同模式和关系,从而提高预测的准确性和鲁棒性。
接下来,我们选用线性回归作为元模型。线性回归是一种简单而有效的模型,它的主要优点在于模型解释性强和计算效率高。在堆叠模型中,元模型的作用是学习如何根据基模型的预测结果来生成最终的预测值。具体而言,它将各个基模型的预测结果作为输入特征,通过训练过程来确定每个基模型预测的权重。这种方法允许元模型自动学习到最佳的结合方式,即在最终预测中各个基模型应该占据多少比重。
为了确保.......
4.2 组合模型的构建与训练
在本研究中,我们采用了一种组合模型的策略,即堆叠回归(StackingRegressor),以提高时间序列预测的准确性。堆叠回归是一种高级的集成学习技术,它通过将多个不同的基模型的预测结果作为输入,训练一个元模型来生成最终的预测。这种方法充分利用了不同模型的优势,通过学习如何最好地结合它们的预测,以达到比任何单一模型都更好的性能。
图 3 组合模型构建代码展示
在我们的堆叠模型中,我们选择了三种经过参数优化的模型作为基模型:随机森林、XGBoost和LightGBM。这些模型都是基于树的算法,已经证明在各种回归任务中具有强大的性能。通过网格搜索,我们为每个模型找到了最佳的参数设置,这确保了它们在单独预测时能够达到较高的准确性。随机森林模型以其鲁棒性和易解释性而受到青睐,XGBoost和LightGBM则因其高效的处理大规模数据和高准确性而被广泛应用。
在确定了基模型后,我们选择线性回归作为元模型。线性回归是一种简单但强大的线性模型,它试图找到一个最佳的线性组合来映射输入特征到目标变量。在这种情况下,输入特征是基模型的预测值。选择线性回归作为元模型的原因是其简单性和解释性,它为基模型的预测赋予了不同的权重,使得组合模型能够从中学习并提取有价值的信息。
我们通过交叉验证的方法来训练堆叠模型,这不仅有助于防止过拟合,而且还能保证模型具有良好的泛化能力。通过这种方式,元模型能够有效地学习如何结合基模型的预测,以产生更准确的最终预测。
堆叠模型在测试集上的性能表明,这种组合策略是成功的。与之前通过网格搜索优化的单一模型相比,堆叠模型在均方误差(MSE)、均方根误差(RMSE)、平均绝对误差(MAE)和R²这些评估指标上都显示出了优异的性能,R²值达到了0.78,这表明堆叠模型能够解释目标变量方差的78%,而且均方根误差,其他的误差值都是有所降低。这个结果证实了堆叠回归在提升预测准确性方面的有效性,尤其是当基模型具有互补特性时。
总的来说,组合模型的设计思路是通过整合不同模型的独特优势来提高预测性能。通过精心选择基模型并对它们进行参数优化,我们确保了模型在单独预测时的准确性。随后,通过将这些预测结果作为输入来训练一个元模型,我们能够进一步提升性能,实现了比任何单一模型都更高的预测准确性。这种方法展示了集成学习在解决复杂预测问题中的强大潜力。
第5章 模型评估与比较
5.1 评估指标的选择
选择合适的评估指标是评估和比较模型性能的关键,这不仅影响对模型预测能力的准确理解,还决定了模型优化的方向和重点。在公交客流预测的场景中,评估指标需要能够全面反映模型的预测
5.2 组合模型与单一模型的性能比较
在公交客流预测的研究中,对组合模型与单一模型的性能进行比较是评估组合模型有效性的关键步骤。这一比较不仅涉及模型预测准确性的直接对比,还包括模型的稳定性、泛化能力以及对不同数据特征的适应性等方面的评估。
在本研究中,我们通过对单一模型和组合模型的性能进行比较,揭示了集成学习策略的优势和潜力。参数优化后的基础模型,即随机森林、XGBoost和LightGBM,在测试集上的性能指标表明,这些单一模型已经表现出了相当的预测能力,其中随机森林和LightGBM的R²值均为0.78,XGBoost稍低,为0.77。这些模型的均方误差(MSE)和均方根误差(RMSE)也相差不大,展现了它们在处理时间序列数据上的有效性。
然而,当我们转向组合模型——特别是我们构建的堆叠模型时,我们观察到一个细微但重要的性能提升。堆叠模型的R²值仍然保持在0.78,与单一模型相当,但其均方误差(MSE)和均方根误差(RMSE)略有下降,平均绝对误差(MAE)也有所降低。尽管这些改进看似微小,但它们揭示了组合模型在预测性能上的稳定性和鲁棒性。
组合模型之所以展现出这种优势,主要归因于其能够整合多个模型的预测并从中学习的能力。在堆叠回归的框架下,不同基模型的预测结果被用作元模型的输入特征。这种方法允许元模型捕捉到各个基模型在特定情况下的强项和弱点,从而更加智能地结合它们的预测。例如,某个基模型可能在特定类型的数据分布上表现得更好,而另一个模型则可能在处理异常值时更为出色。通过堆叠模型,我们能够利用这些互补的特性,实现更加准确和稳健的预测。
此外,堆叠模型通过引入一个元模型增加了额外的学习层次,这为预测任务引入了更高级别的抽象。元模型的训练过程本质上是在学习如何最优化地组合基模型的预测,这一过程可以被视为一种自动的权重分配机制,其中权重是基于基模型在特定任务上的表现而确定的。

图 4 组合模型的预测值与真实值对比
第6章 实际应用与案例分析
6.1 实际应用场景
将理论模型转化为实际应用,解决现实问题,是公交客流预测研究的最终目的。在本研究中,所构建的组合模型不仅在理论上具有坚实基础,而且在多个实际应用场景中显示出了卓越的
6.2 案例分析与结果讨论
在深入研究和应用组合模型对公交客流进行预测的过程中,通过对一个具体城市公交系统的案例进行分析,展示了模型的实际效果和应用潜力。本案例涉及该城市的主要公交线路,
第7章 结论与展望
7.1 研究结论
XXX
7.2 研究限制与未来展望
XXX
每文一语
看透生命也许就是一种自我提升
相关文章:
基于组合模型的公交交通客流预测研究
摘 要 本研究致力于解决公交客流预测问题,旨在通过融合多种机器学习模型的强大能力,提升预测准确性,为城市公交系统的优化运营和交通管理提供科学依据。研究首先回顾了公交客流预测领域的相关文献,分析了传统统计方法在处理大规…...

docker环境redis启动失败
现象: 查看日志错误为 Bad file format reading the append only file: make a backup of your AOF file, then use ./redis-check-aof --fix <filename> 经查询为aof文件损坏导致,修复aof即可 解决方法: 1.查看执行的docker命令&…...

Pandas库详细学习要点
Pandas库是一个基于Python的数据分析库,它提供了丰富的数据结构和数据分析工具,非常适合数据科学和数据分析领域的工作。以下是Pandas库详细学习的一些要点: 1. 数据结构 - Series:一维带标签数组,类似于NumPy中的一…...
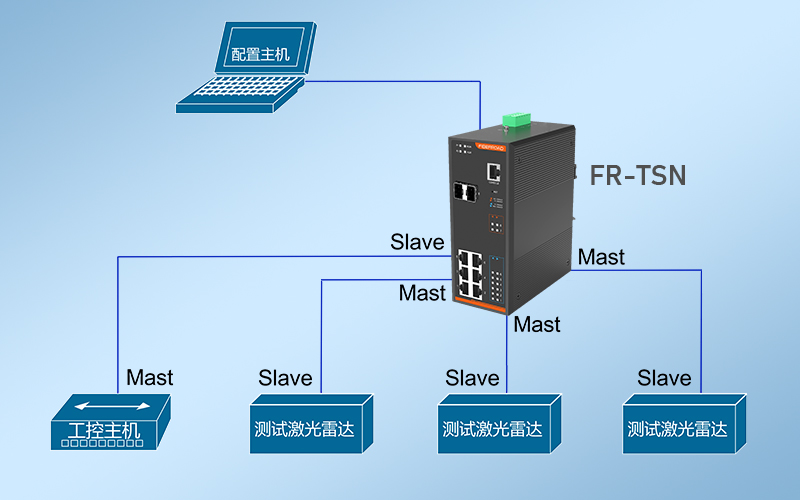
光路科技TSN交换机:驱动自动驾驶技术革新,保障高精度实时数据传输
自动驾驶技术正快速演进,对实时数据处理能力的需求激增。光路科技推出的TSN(时间敏感网络)交换机,在比亚迪最新车型中的成功应用,显著推动了这一领域的技术进步。 自动驾驶技术面临的挑战 自动驾驶系统需整合来自雷达…...
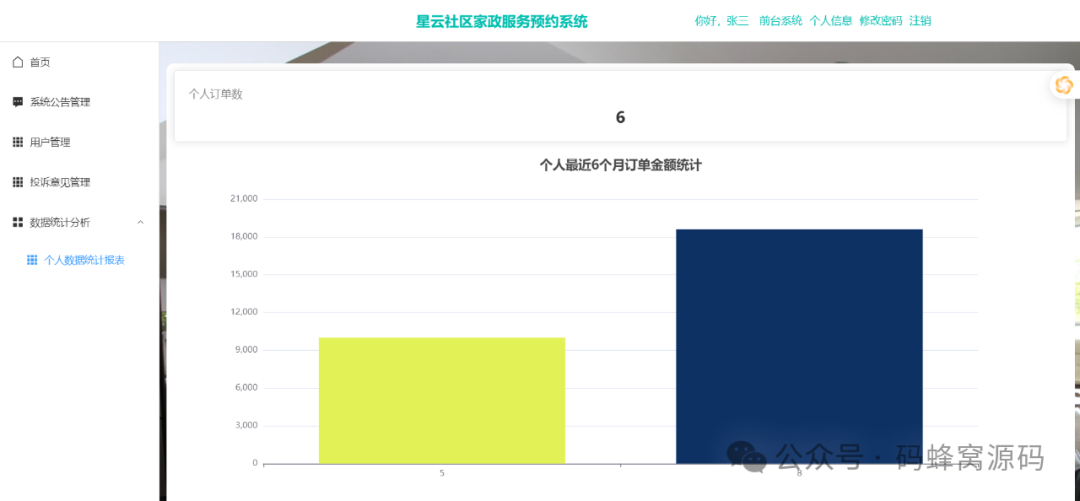
【含开题报告+文档+PPT+源码】基于SpringBoot的社区家政服务预约系统设计与实现【包运行成功】
开题报告 社区家政服务是满足居民日常生活需求的重要组成部分,在现代社会中发挥着越来越重要的作用。随着城市化进程的不断加速,社区家政服务需求量呈现持续增长的趋势。然而,传统的家政服务模式存在一些问题,如预约流程繁琐、信…...

2024最新【Pycharm】史上最全PyCharm安装教程,图文教程(超详细)
1. PyCharm下载安装 完整安装包下载(包含Python和Pycharm专业版注册码):点击这里 1)访问官网 https://www.jetbrains.com/pycharm/download/#sectionwindows 下载「社区版 Community」 安装包。 2)下载完成后&#…...

llama3 implemented from scratch 笔记
github地址:https://github.com/naklecha/llama3-from-scratch?tabreadme-ov-file 分词器的实现 from pathlib import Path import tiktoken from tiktoken.load import load_tiktoken_bpe import torch import json import matplotlib.pyplot as plttokenizer_p…...
照片在线转成二维码展示,更方便分享图片的好办法
怎么能把照片生成二维码后,分享给其他人展示呢?现在很多人为了能够更方便的将自己的图片展现给其他人会使用生成二维码的方式,将图片存储到云空间,通过扫码调取图片查看内容。与其他方式相比,这样会更加的方便…...
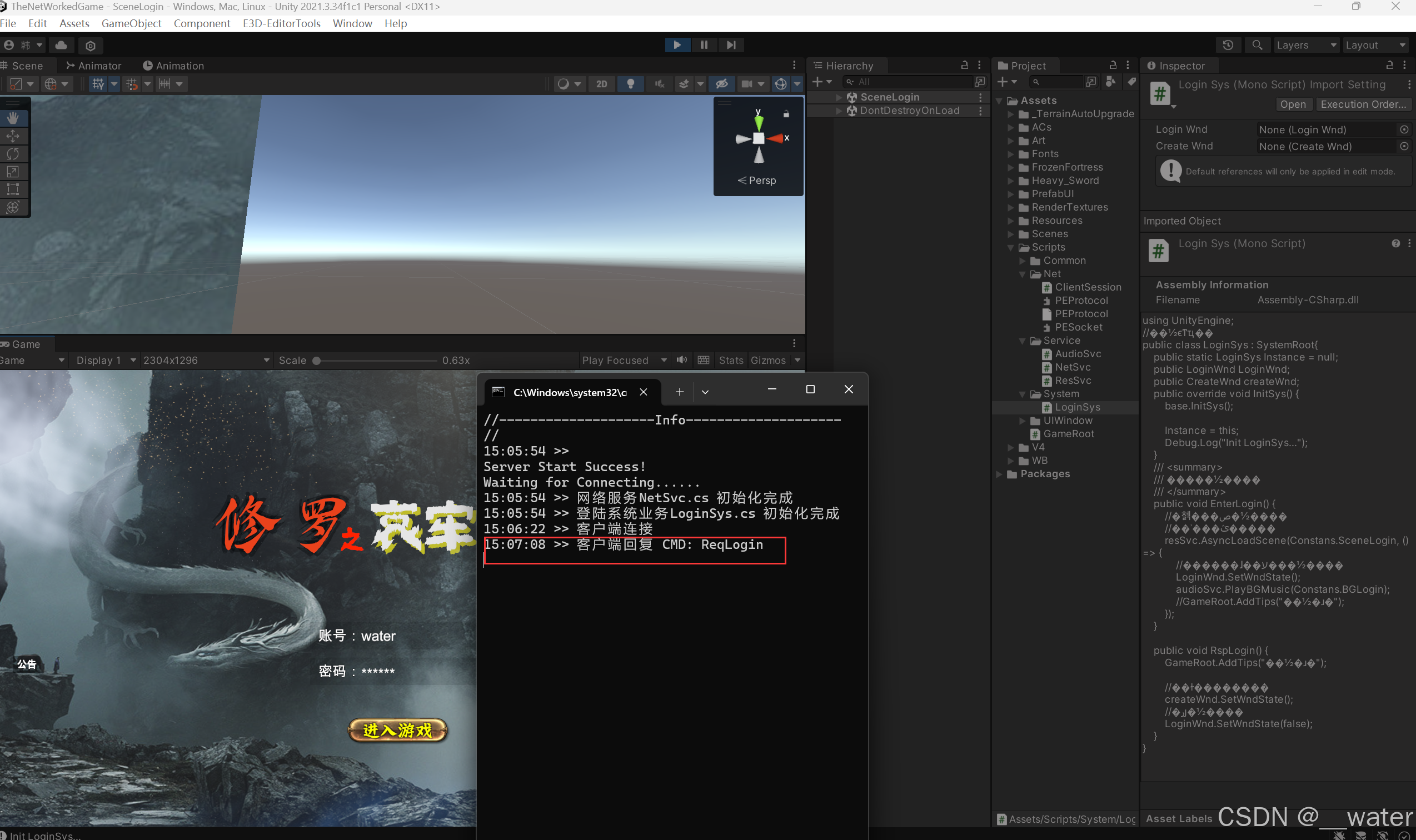
『网络游戏』登陆协议制定客户端发送账号密码CMD【19】
修改服务器脚本:ServerSession 修改服务器脚本:GameMsg 修改客户端脚本:ClientSession.cs 修改客户端脚本:NetSvc.cs 修改客户端脚本:WindowRoot.cs 修改客户端脚本:SystemRoot.cs 修改客户端脚本ÿ…...

独享动态IP是什么?它有什么独特优势吗?
在网络世界中,IP地址扮演着连接互联网的关键角色。随着互联网的发展,不同类型的IP地址也应运而生,其中独享动态ip作为一种新型IP地址,备受关注。本文将围绕它的定义及其独特优势展开探讨,以帮助读者更好地理解和利用这…...

gaussdb hccdp认证模拟题(单选)
1.在GaussDB逻辑架构中,由以下选项中的哪一个组件来负责提供集群日常运维、配置管理的管理接口、工具?(1 分) A. CN B. DN C. GTM D. OM --D 2.在以下命令中,使用以下哪一个选项中的命令可以以自定义归档形式导出表t1的定义…...
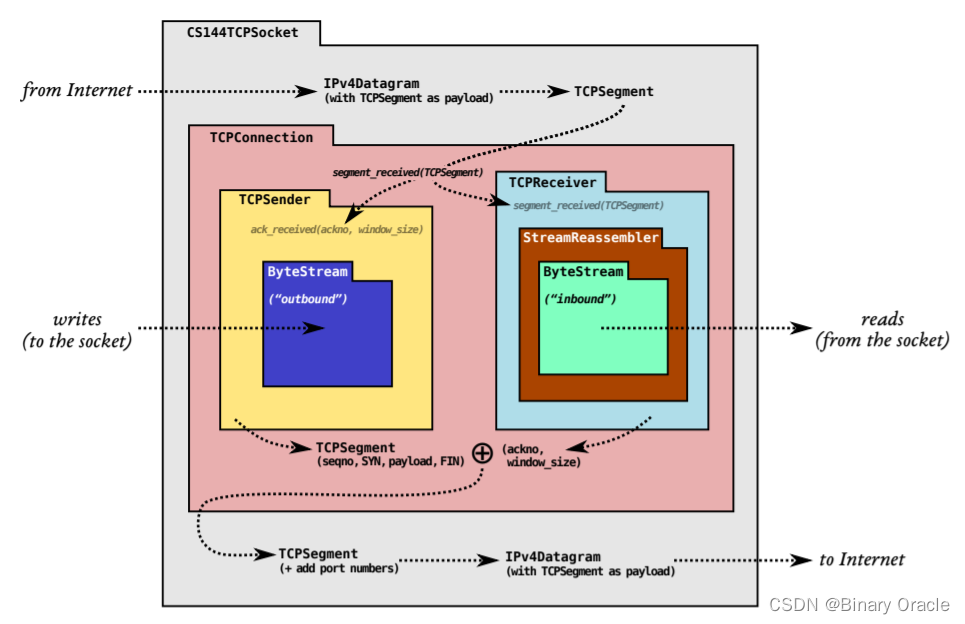
【斯坦福CS144】Lab1
一、实验目的 1.实现一个流重组器——一个将字节流的小块 (称为子串或段 )按正确顺序组装成连续的字节流的模块; 2.深入理解 TCP 协议的工作方式。 二、实验内容 编写一个名为"StreamReassembler"的数据结构,它负责…...

药箱里的药及其常见药的作用
药箱里有常备药,经常买药,但是忘了自己有什么药。容易之间弄混,以此作为更新存储的媒介。 1、阿莫西林胶囊 处方药 是指需要由医师或者医疗人员开局处方才能购买的药物(常见的OTC是非处方药的意思)。 截止时间 2024 10/10 药品资料汇总&am…...
)
Android屏幕旋转流程(2)
(1)疑问 (1)settings put system user_rotation 1是什么意思? 答:设置用户期望的屏幕转向,0代表:Surface.ROTATION_0竖屏;1代表:Surface.ROTATION_90横屏&a…...

gaussdb hccdp认证模拟题(判断)
1.在事务ACID特性中,原子性指的是事务必须始终保持系统处于一致的状态。(1 分) 错。 2.某IT公司在开发软件时,需要使用GaussDB数据库,因此需要实现软件和数据的链接,而DBeaver是一个通用的数据库管理工具和 SQL 客户端ÿ…...

高效架构设计:JPA 实现单据管理,MyBatis 赋能报表查询的最佳实践
在现代企业应用开发中,数据持久层的设计与实现是至关重要的部分。开发者常常会面临选择如何合理地使用不同的数据访问框架,以最大限度地提升系统性能和开发效率。本文将讨论一种有效的搭配方案:使用 JPA 处理单据的增删改查操作,使…...

深入理解 CSS 浮动(Float):详尽指南
“批判他人总是想的太简单 剖析自己总是想的太困难” 文章目录 前言文章有误敬请斧正 不胜感恩!目录1. 什么是 CSS 浮动?2. CSS 浮动的历史背景3. 基本用法float 属性值浮动元素的行为 4. 浮动对文档流的影响5. 清除浮动clear 属性清除浮动的技巧1. 使用…...

ElasticSearch学习笔记(三)Ubuntu 2204 server elasticsearch集群配置
如果你只是学习elasticsearch的增、删、改、查等相关操作,那么在windows上安装一个ES就可以了。但是你如果想在你的生产环境中使用Elasticsearch提供的强大的功能,那么还是建议你使用Linux操作系统。 本文以在Ubuntu 2204 server中安装elasticsearch 8.…...

基于STM32的简易交通灯proteus仿真设计(仿真+程序+设计报告+讲解视频)
基于STM32的简易交通灯proteus仿真设计(仿真程序设计报告讲解视频) 仿真图proteus 8.9 程序编译器:keil 5 编程语言:C语言 设计编号:C0091 **1.**主要功能 功能说明: 以STM32单片机和数码管、LED灯设计简易交通…...

linux下新增加一块sata硬盘并使用
1)确认新硬盘能被正确识别到 2)对新硬盘进行分区 说明:fdisk指令中输入“m”,可以看到详细的指令含义。 3)确认新创建的分区 5)格式化新创建的分区 6)挂载新分区并使用...

为OpenClaw配置Taotoken作为其AI模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为OpenClaw配置Taotoken作为其AI模型供应商 基础教程类,指导使用OpenClaw这类Agent工具的开发者,如何将其后…...

SDXL动画生成实战:AnimateDiff与Hotshot-XL效果对比与配置详解
1. SDXL动画生成工具概览 最近在玩SDXL动画生成的朋友应该都听说过AnimateDiff和Hotshot-XL这两款神器。作为目前最主流的两个文生视频开源工具,它们都能基于SDXL模型将静态图片转换成动态视频。不过在实际使用中,我发现两者的效果差异还挺明显的。 先说…...

从‘KN’与‘taoN’反推Kp/Ki:一个让电机PI整定思路瞬间清晰的视角
从系统级特性反推PI参数:基于KN与taoN的电机控制整定方法论 在电机控制领域,PI参数整定一直是工程师面临的经典难题。传统方法往往直接调整Kp和Ki,却忽略了这两个参数背后隐藏的系统级特性——开环增益KN与微分时间常数taoN。这种"只见树…...

会话包装器设计:提升API连接弹性与可观测性的工程实践
1. 项目概述:一个被低估的会话管理利器如果你经常和API打交道,尤其是那些需要维护会话状态的服务,肯定遇到过这样的烦恼:每次请求都要手动处理token、处理重连逻辑、管理超时和重试,代码里到处都是重复的胶水代码。更头…...
)
手把手教你用kafka-storage.sh修复Kafka KRaft模式启动报错(附UUID生成与格式化全流程)
手把手教你用kafka-storage.sh修复Kafka KRaft模式启动报错(附UUID生成与格式化全流程) 当Kafka集群从ZooKeeper模式迁移到KRaft模式时,技术人员常会遇到因元数据问题导致的启动失败。本文将深入解析kafka-storage.sh工具的核心功能ÿ…...

【NotebookLM统计方法选择权威指南】:20年数据科学家亲授5大避坑法则与3步决策框架
更多请点击: https://kaifayun.com 更多请点击: https://intelliparadigm.com 第一章:NotebookLM统计方法选择的核心挑战与认知重构 NotebookLM 作为 Google 推出的面向研究者与知识工作者的 AI 助手,其核心能力依赖于对用户上传…...

Manage Buddy:轻量自托管团队协作工具的设计、部署与实战
1. 项目概述与核心价值最近在梳理团队内部工具链时,我重新审视了一个我们重度依赖的开源项目——maziminds/manage-buddy。这并非一个广为人知的明星项目,但在中小型技术团队,尤其是追求敏捷与效率的研发团队中,它扮演着“隐形冠军…...

3分钟解锁iOS激活锁:AppleRa1n离线绕过工具深度解析
3分钟解锁iOS激活锁:AppleRa1n离线绕过工具深度解析 【免费下载链接】applera1n icloud bypass for ios 15-16 项目地址: https://gitcode.com/gh_mirrors/ap/applera1n 你是否曾经面对一台被激活锁困住的iPhone感到束手无策?AppleRa1n正是为解决…...

【效率革命】PolyWindow插件:从多边形到精美窗户的3dMax一键生成秘籍
1. 为什么你需要PolyWindow插件? 如果你经常用3dMax做建筑可视化或室内设计,肯定遇到过这样的烦恼:项目里需要做几十个风格各异的窗户,每个都要手动建模、分格、赋材质,光是想到这个工作量就让人头皮发麻。我去年接的一…...

后端架构师转型AI智能体落地:收藏这份3个月进阶指南,轻松玩转不确定性系统
本文为后端/全栈/架构师提供了一条从零到一掌握AI智能体落地的技术路径。文章首先分析了架构师在AI智能体落地中的核心优势,如分布式系统设计、数据库设计、API封装等;接着,提出了一个分四阶段的三个月进阶计划,包括掌握核心范式、…...