权重衰减与暂退法——paddle部分
权重衰减与暂退法——paddle部分
本文部分为paddle框架以及部分理论分析,torch框架对应代码可见权重衰减与暂退法torch
import paddle
print("paddle version:",paddle.__version__)
paddle version: 2.6.1
当我们谈论机器学习模型的性能时,经常会提到两个关键指标:训练误差和泛化误差。这两个误差度量有助于我们了解模型的学习效果和预测未知数据的能力。下面,我将结合一个简单的例子来详细介绍这两个概念。
训练误差
训练误差是模型在训练数据集上的表现。它衡量了模型对于已经见过的数据的拟合程度。训练误差低意味着模型能够很好地学习和复现训练集中的数据规律和特征。
假设我们有一个简单的线性回归模型,用于预测房屋的价格。训练数据集包含了100套房屋的面积和价格。我们使用这个数据集来训练模型,使其能够根据房屋面积预测价格。
训练完成后,我们在同样的训练数据集上评估模型的性能。如果模型预测的价格与真实价格相差很小,那么训练误差就低。反之,如果预测价格与真实价格相差较大,则训练误差高。
泛化误差
泛化误差是模型在未见过的数据(即测试数据)上的表现。它衡量了模型对于新数据的预测能力,是评估模型泛化性能的重要指标。一个具有良好泛化能力的模型能够在未见过的数据上做出准确的预测。
接着训练误差中的例子,在训练完线性回归模型后,我们获得了一个新的、独立的数据集,其中包含了另外20套房屋的面积和价格。这些数据在训练过程中模型是未见过的。
当我们在这个新数据集上评估模型时,模型根据房屋面积预测出的价格与实际价格的差距,就反映了模型的泛化误差。如果预测价格与真实价格相差很小,说明模型的泛化误差低,泛化能力强。相反,如果预测价格与真实价格相差较大,则说明模型的泛化误差高。
训练误差和泛化误差都是评估机器学习模型性能的重要指标。训练误差低表明模型能够很好地拟合训练数据,而泛化误差低则表明模型能够很好地预测未见过的数据。理想情况下,我们希望模型既有较低的训练误差,也有较低的泛化误差,这通常需要在模型的复杂度和泛化能力之间找到平衡。
然而,在实际应用中,过度追求训练误差的最小化可能导致模型过度拟合训练数据,从而损害了其在新数据上的预测能力(即增加了泛化误差)。因此,我们通常需要使用正则化技术(如L1、L2正则化、暂退法等)来防止过拟合,以提高模型的泛化性能。
在比较训练和验证误差时,需留意两种典型状况。首先,应警惕训练误差与验证误差均处于较高水平,但两者间差距甚微的情形。若模型无法有效降低训练误差,这可能表明模型复杂度不足,难以捕捉数据的内在模式。同时,由于训练和验证误差间的差距较小,意味着模型的泛化误差并不大。因此,我们可以考虑采用更复杂的模型来尝试降低训练误差。这种情况通常被称为欠拟合。
反之,当训练误差显著低于验证误差时,则需警惕过拟合的风险。值得注意的是,过拟合并非总是负面的。在深度学习领域,表现最佳的预测模型通常在训练数据上的表现会明显优于在验证数据上的表现。归根结底,我们更加关注的是验证误差本身,而非训练误差与验证误差之间的差异。
模型是否出现过拟合或欠拟合,可能受到模型复杂度以及可用训练数据集规模的影响。
权重衰减
权重衰减,也称为L2正则化,是一种常用的正则化技术,用于防止过拟合。它通过在损失函数中加入权重的平方和来惩罚大的权重,从而减少模型对训练数据的依赖。权重衰减的核心思想是在原损失函数的基础上,根据权值的大小加入一个惩罚项。具体而言,假设原损失函数为 L ( w ) L(\mathbf{w}) L(w),其中 w \mathbf{w} w代表模型的权值,则加入权重衰减后的损失函数可表示为:
L ′ ( w ) = L ( w ) + λ R ( w ) L'(\mathbf{w}) = L(\mathbf{w}) + \lambda R(\mathbf{w}) L′(w)=L(w)+λR(w)
其中, L ′ ( w ) L'(\mathbf{w}) L′(w)是正则化后的损失函数, λ \lambda λ是权重衰减参数(超参数), R ( w ) R(\mathbf{w}) R(w)是正则化项。在实际应用中,最常用的正则化项是L2范数(亦称Ridge正则化),即权值平方和的一半:
R ( w ) = 1 2 ∑ i w i 2 R(\mathbf{w}) = \frac{1}{2} \sum_{i} w_i^2 R(w)=21i∑wi2
因此,正则化后的损失函数可进一步表示为:
L ′ ( w ) = L ( w ) + λ 2 ∑ i w i 2 L'(\mathbf{w}) = L(\mathbf{w}) + \frac{\lambda}{2} \sum_{i} w_i^2 L′(w)=L(w)+2λi∑wi2
在利用梯度下降法最小化正则化后的损失函数时,权值更新规则会发生相应变化。标准梯度下降的权值更新规则为:
w ← w − η ∇ L ( w ) \mathbf{w} \leftarrow \mathbf{w} - \eta \nabla L(\mathbf{w}) w←w−η∇L(w)
其中, η \eta η是学习率, ∇ L ( w ) \nabla L(\mathbf{w}) ∇L(w)是损失函数关于权值的梯度。而在引入权重衰减后,更新规则变为:
w ← w − η ( ∇ L ( w ) + λ w ) \mathbf{w} \leftarrow \mathbf{w} - \eta (\nabla L(\mathbf{w}) + \lambda \mathbf{w}) w←w−η(∇L(w)+λw)
这表明,在每次更新时,除了考虑损失函数的梯度外,还会根据权值大小施加一个收缩项,使权值向零收缩。权重衰减作为一种有效的正则化技术,通过向损失函数中加入基于权值大小的惩罚项,有助于防止机器学习模型过拟合。它鼓励模型保持较小的权值,从而倾向于生成更简单的模型,这些模型通常对未见数据具有更好的泛化能力。通过调整权重衰减参数 λ \lambda λ,可以控制惩罚项的力度,进而影响模型的复杂度和泛化性能。
接下来,我们设计一段代码,来测试一下权重衰减的效果。
# 首先我们生成一些具有线性关系的数据
def synthetic_data_linear(w, b, num_examples):"""生成y=Xw+b+噪声"""X = paddle.normal(-1, 1, (num_examples, len(w)))y = paddle.matmul(X, w) + by += paddle.normal(-0.1, 0.1, y.shape)return X, y.reshape((-1, 1))true_w = paddle.to_tensor([-0.1, -0.2, -0.3, -0.4, -0.5, -1.0, 1, 0.5, 0.4, 0.3, 0.2, 0.1]) # 参数这样设置是为了让数据期望变为0
true_b = paddle.to_tensor(0.6)
features_train, labels_train = synthetic_data_linear(true_w, true_b, 500)
features_test, labels_test = synthetic_data_linear(true_w, true_b, 100)
接下来,我们设计一个多层感知机用来拟合数据,并加入权重衰减。
import paddle
from paddle import nn, optimizer, metric
from paddle.io import DataLoader, TensorDataset # 设定超参数
learning_rate = 0.0005 # 学习率
batch_size = 32 # 批大小
epochs = 20 # 迭代轮数
weight_decay = 0.01 # 权重衰减系数 # 假设 features_train, labels_train, features_test, labels_test 已经定义
# 将生成的数据放入DataLoader中
train_dataset = TensorDataset([features_train, labels_train])
test_dataset = TensorDataset([features_test, labels_test]) train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False) # 定义模型架构
class Net(nn.Layer): def __init__(self): super(Net, self).__init__() self.fc1 = nn.Linear(in_features=12, out_features=64) self.fc2 = nn.Linear(in_features=64, out_features=32) self.fc3 = nn.Linear(in_features=32, out_features=1) def forward(self, x): x = paddle.nn.functional.relu(self.fc1(x)) x = paddle.nn.functional.relu(self.fc2(x)) x = self.fc3(x) return x # 实例化模型,定义损失函数和优化器
model = Net()
criterion = nn.MSELoss()
optimizer = optimizer.Adam(parameters=model.parameters(), learning_rate=learning_rate, weight_decay=weight_decay) # 训练模型
for epoch in range(epochs): for i, (inputs, labels) in enumerate(train_loader()): optimizer.clear_grad() # 清空梯度 outputs = model(inputs) # 前向传播 loss = criterion(outputs, labels) # 计算损失 loss.backward() # 反向传播,计算梯度 optimizer.step() # 更新权重 print(f'Epoch {epoch+1}/{epochs}, Loss: {loss.numpy()}')Epoch 1/20, Loss: 3.785010814666748
Epoch 2/20, Loss: 2.1164350509643555
Epoch 3/20, Loss: 1.5388102531433105
Epoch 4/20, Loss: 1.3123598098754883
Epoch 5/20, Loss: 0.6921118497848511
Epoch 6/20, Loss: 1.0337700843811035
Epoch 7/20, Loss: 0.2292252779006958
Epoch 8/20, Loss: 0.10593529790639877
Epoch 9/20, Loss: 0.10887137055397034
Epoch 10/20, Loss: 0.1404935121536255
Epoch 11/20, Loss: 0.06174668297171593
Epoch 12/20, Loss: 0.07750072330236435
Epoch 13/20, Loss: 0.10734034329652786
Epoch 14/20, Loss: 0.06168760731816292
Epoch 15/20, Loss: 0.12108119577169418
Epoch 16/20, Loss: 0.0296523068100214
Epoch 17/20, Loss: 0.045584000647068024
Epoch 18/20, Loss: 0.03694814816117287
Epoch 19/20, Loss: 0.04852581024169922
Epoch 20/20, Loss: 0.0757991150021553
接下来让我们在训练集和测试集上分别测试模型损失。
# 测试模型在训练集上精度
model.eval() # 将模型设置为评估模式
for inputs, labels in train_loader(): outputs = model(inputs) loss = criterion(outputs, labels) print(f'loss of the network on the train dataset: {loss.numpy()}') break# 测试模型在测试集上精度
model.eval() # 将模型设置为评估模式
for inputs, labels in test_loader(): outputs = model(inputs) loss = criterion(outputs, labels) print(f'loss of the network on the test dataset: {loss.numpy()}') break
loss of the network on the train dataset: 0.0469328910112381
loss of the network on the test dataset: 0.1441607028245926
可以看到此时训练集和测试集上模型出现一定的过拟合,接下来我们将取消权重衰减这一过程看看。
model = Net()
criterion = nn.MSELoss()
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=learning_rate, weight_decay=0.) # 训练模型
for epoch in range(epochs): for i, (inputs, labels) in enumerate(train_loader()): optimizer.clear_grad() # 清空梯度 outputs = model(inputs) # 前向传播 loss = criterion(outputs, labels) # 计算损失 loss.backward() # 反向传播,计算梯度 optimizer.step() # 更新权重 print(f'Epoch {epoch+1}/{epochs}, Loss: {loss.numpy()}')# 测试模型在训练集上精度
model.eval() # 将模型设置为评估模式
for inputs, labels in train_loader(): outputs = model(inputs) loss = criterion(outputs, labels) print(f'loss of the network on the train dataset: {loss.numpy()}') break# 测试模型在测试集上精度
model.eval() # 将模型设置为评估模式
for inputs, labels in test_loader(): outputs = model(inputs) loss = criterion(outputs, labels) print(f'loss of the network on the test dataset: {loss.numpy()}') break
Epoch 1/20, Loss: 5.025182723999023
Epoch 2/20, Loss: 2.0165629386901855
Epoch 3/20, Loss: 2.3256301879882812
Epoch 4/20, Loss: 0.9198152422904968
Epoch 5/20, Loss: 0.8756014108657837
Epoch 6/20, Loss: 0.6894010305404663
Epoch 7/20, Loss: 0.3395043611526489
Epoch 8/20, Loss: 0.07653199136257172
Epoch 9/20, Loss: 0.24273991584777832
Epoch 10/20, Loss: 0.12393765896558762
Epoch 11/20, Loss: 0.13507765531539917
Epoch 12/20, Loss: 0.07301098853349686
Epoch 13/20, Loss: 0.08159870654344559
Epoch 14/20, Loss: 0.0694296807050705
Epoch 15/20, Loss: 0.07280569523572922
Epoch 16/20, Loss: 0.14888818562030792
Epoch 17/20, Loss: 0.07028432190418243
Epoch 18/20, Loss: 0.060749806463718414
Epoch 19/20, Loss: 0.10886208713054657
Epoch 20/20, Loss: 0.06935202330350876
loss of the network on the train dataset: 0.04380759596824646
loss of the network on the test dataset: 0.17632871866226196
可以看到此时模型过拟合程度明显加深。
实际上,当模型训练的数据量足够大时,过拟合问题并不明显,此时权重衰减几乎不会起到作用。
暂退法(Dropout)
暂退法(Dropout)是一种常用的正则化方法,它通过在训练过程中随机丢弃部分神经元来减少模型参数间的关联性,从而达到减少过拟合的效果。暂退法在训练过程中,每次前向传播时,随机丢弃一部分神经元,并将其输出置为0。在测试过程中,不进行暂退操作。
在训练过程中,对于神经网络中的每一层,每个神经元以概率( p )保留,以概率( 1-p )丢弃。这可以用数学公式表示为:
z ( l ) = r ( l ) ⊙ a ( l − 1 ) \mathbf{z}^{(l)} = \mathbf{r}^{(l)} \odot \mathbf{a}^{(l-1)} z(l)=r(l)⊙a(l−1)
其中:
- $ \mathbf{z}^{(l)} 是应用 D r o p o u t 后第 是应用Dropout后第 是应用Dropout后第 l $层的输入。
- $ \mathbf{a}^{(l-1)} $是前一层的激活。
- $ \mathbf{r}^{(l)} 是一个二元掩码向量,其中每个元素都是从参数为 是一个二元掩码向量,其中每个元素都是从参数为 是一个二元掩码向量,其中每个元素都是从参数为 p 的伯努利分布中抽取的。 的伯努利分布中抽取的。 的伯努利分布中抽取的。 \odot $表示元素乘法。
(伯努利分布(Bernoulli Distribution)也被称为0-1分布或两点分布,是一种离散概率分布,用于描述一个只有两种可能结果的随机试验,通常用来表示成功或失败、是或否等二选一的情况。
具体来说,如果随机变量X只有两个可能的取值0和1:
事件发生、成功的概率为p(0<p<1);
事件不发生、失败的概率则为q=1-p。)
让我们用代码演示一下暂退法的过程:
# 定义一个测试网络
class Net_Isdropout(nn.Layer):def __init__(self):super(Net_Isdropout, self).__init__()self.fc1 = nn.Linear(12, 5)self.dropout = nn.Dropout(p=0.5) # 丢弃概率为0.5def forward(self, x):# 随机丢弃一部分神经元,并将其输出置为0x = self.fc1(x)x = self.dropout(x)return xdef forward_withoutdropout(self, x):# 不丢弃任何神经元x = self.fc1(x)return x# 让我们测试一下
model = Net_Isdropout()
x_test = paddle.randn((1, 12))
print(model.forward(x_test))
print(model.forward_withoutdropout(x_test))
Tensor(shape=[1, 5], dtype=float32, place=Place(gpu:0), stop_gradient=False,[[-3.09885454, 0. , -0.11287704, 3.01251793, 0. ]])
Tensor(shape=[1, 5], dtype=float32, place=Place(gpu:0), stop_gradient=False,[[-1.54942727, 0.48976105, -0.05643852, 1.50625896, 0.48890206]])
可以看到,经过dropout层输出后,部分神经元的输出被置为0,即被丢弃了。接下来让我们继续使用上方的数据集,重新设计网络看一下dropout的效果吧。
# 定义模型架构
class Net(nn.Layer): def __init__(self): super(Net, self).__init__() self.fc1 = nn.Linear(12, 64) self.fc2 = nn.Linear(64, 32) self.fc3 = nn.Linear(32, 1) self.dropout = nn.Dropout(p=0.2) # 丢弃概率为0.2self.relu = nn.ReLU() # 激活函数def forward(self, x): x = self.relu(self.fc1(x)) x = self.dropout(x) # 随机丢弃一部分神经元,并将其输出置为0x = self.relu(self.fc2(x)) x = self.fc3(x) return x def forward_withoutdropout(self, x):# 不丢弃任何神经元x = self.relu(self.fc1(x))x = self.relu(self.fc2(x))x = self.fc3(x)return x# 实例化模型,定义损失函数和优化器
model = Net()
criterion = nn.MSELoss()
optimizer = paddle.optimizer.Adam(parameters=model.parameters(), learning_rate=learning_rate, weight_decay=0.) # 训练模型
for epoch in range(epochs): for i, (inputs, labels) in enumerate(train_loader()): optimizer.clear_grad() # 清空梯度 outputs = model(inputs) # 前向传播 loss = criterion(outputs, labels) # 计算损失 loss.backward() # 反向传播,计算梯度 optimizer.step() # 更新权重 print(f'Epoch {epoch+1}/{epochs}, Loss: {loss.numpy()}')# 测试模型在训练集上精度
model.eval() # 将模型设置为评估模式
for inputs, labels in train_loader(): outputs = model(inputs) loss = criterion(outputs, labels) print(f'loss of the network on the train dataset: {loss.numpy()}') break# 测试模型在测试集上精度
model.eval() # 将模型设置为评估模式
for inputs, labels in test_loader(): outputs = model(inputs) loss = criterion(outputs, labels) print(f'loss of the network on the test dataset: {loss.numpy()}') break
Epoch 1/20, Loss: 3.613870859146118
Epoch 2/20, Loss: 2.803053379058838
Epoch 3/20, Loss: 1.438267469406128
Epoch 4/20, Loss: 1.964662790298462
Epoch 5/20, Loss: 0.7751991152763367
Epoch 6/20, Loss: 1.1017379760742188
Epoch 7/20, Loss: 1.1961350440979004
Epoch 8/20, Loss: 0.5335128903388977
Epoch 9/20, Loss: 0.8920736312866211
Epoch 10/20, Loss: 0.7742461562156677
Epoch 11/20, Loss: 0.48358154296875
Epoch 12/20, Loss: 0.26389363408088684
Epoch 13/20, Loss: 0.2960830628871918
Epoch 14/20, Loss: 0.21180494129657745
Epoch 15/20, Loss: 0.48852062225341797
Epoch 16/20, Loss: 0.19977638125419617
Epoch 17/20, Loss: 0.4302082657814026
Epoch 18/20, Loss: 0.45645689964294434
Epoch 19/20, Loss: 0.23454374074935913
Epoch 20/20, Loss: 0.45955249667167664
loss of the network on the train dataset: 0.06621350347995758
loss of the network on the test dataset: 0.0869474783539772
此时模型并没有过拟合,与之前权重衰减为0的情况做对比,可以发现暂退法具有一定的正则化效果。
除了权重衰减(也称为L2正则化)和暂退法(Dropout)之外,还有其他几种常见的正则化方法,用于防止模型过拟合:
-
L1正则化:与L2正则化类似,L1正则化是在损失函数中添加一个与模型参数(权重)绝对值之和成正比的项。L1正则化有助于产生稀疏权重矩阵,即使得模型中的很多参数变为零,从而简化模型并防止过拟合。
-
数据增强:虽然数据增强不直接作用于模型参数,但它是一种有效的正则化技术,通过增加训练数据的多样性来提高模型的泛化能力。例如,在图像识别任务中,可以通过旋转、平移、缩放、颜色变换等方式对原始图像进行变换,生成新的训练样本。
-
提前终止:这是一种简单而有效的正则化策略。在训练过程中,我们会监控模型在验证集上的性能。当验证集上的误差开始上升时(即模型开始出现过拟合迹象),我们就提前终止训练。这样可以防止模型在训练数据上过度优化,从而提高其在未知数据上的泛化能力。
-
集成方法:集成方法,如Bagging和Boosting,也可以通过结合多个模型的预测结果来提高泛化能力。虽然这些方法本身并不直接对模型进行正则化,但它们通过组合多个可能过度拟合的模型来减少过拟合的风险。
-
批量归一化(Batch Normalization):虽然批量归一化主要用于加速神经网络的训练和提高模型性能,但它也有助于减少内部协变量偏移,从而间接起到正则化的作用。通过规范化每一层的输入,批量归一化可以使模型更加稳定,并减少过拟合的风险。
-
对抗训练:对抗训练是一种通过向输入数据添加微小扰动来增强模型鲁棒性的方法。这些扰动被设计为最大化模型的损失函数,从而使模型在面对轻微变化的数据时仍然能够保持稳定的性能。对抗训练可以视为一种正则化技术,因为它有助于减少模型对训练数据的依赖性,并提高其泛化能力。
-
混合正则化:有时可以将多种正则化方法结合使用,例如同时应用L1和L2正则化(也称为Elastic Net正则化),以结合两者的优点。这种方法可以帮助模型在稀疏性和稳定性之间找到平衡。
选择哪种正则化方法取决于具体的应用场景和数据集特性。在实际应用中,可能需要通过实验来确定最佳的正则化策略。
相关文章:

权重衰减与暂退法——paddle部分
权重衰减与暂退法——paddle部分 本文部分为paddle框架以及部分理论分析,torch框架对应代码可见权重衰减与暂退法torch import paddle print("paddle version:",paddle.__version__)paddle version: 2.6.1当我们谈论机器学习模型的性能时,经…...

golang获取当天最小的时间,以DateTime的string格式返回
推荐学习文档 golang应用级os框架,欢迎stargolang应用级os框架使用案例,欢迎star案例:基于golang开发的一款超有个性的旅游计划app经历golang实战大纲golang优秀开发常用开源库汇总想学习更多golang知识,这里有免费的golang学习笔…...

2025 - 中医学基础 - 考研 - 职称
2025 - 中医学基础 - 考研 - 职称 第1章 中医学导论 1.中医学的指导思想是()( ) [单选] A.阴阳学说 B.五行学说 C.精气学说 D.整体观念 E.辨证论治 正确答案: D 2.中医学的理论核心是&…...

Pandas库
一、安装 Pandas是一个基于Python构建的专门进行数据操作和分析的开源软件库,它提供了高效的数据结构和丰富的数据操作工具。 安装 pip install pandas 二、核心数据结构 Pandas库中最常用的数据类型是Series和DataFrame: Series:一维数…...

Qt网络编程: 构建高效的HTTP文件下载器
文章目录 注意事项调用示例在使用Qt进行HTTP下载时,通常会使用QNetworkAccessManager类来管理HTTP请求和响应。这个类提供了进行网络请求的能力,包括下载文件。下面是使用Qt进行HTTP下载的一个示例,以及在实现时应考虑的一些注意事项。 注意事项 1.错误处理 始终检查QNetwo…...

Python 将Word, Excel, PDF和PPT文档转换为OFD格式
目录 使用工具 Python 将Word文档转换为OFD Python 将Excel文档转换为OFD Python 将PDF文档转换为OFD Python 将PPT文档转换为OFD OFD(Open Fixed-layout Document)是中国国家标准的电子文档格式,主要用于政府、金融等行业的正式文档传输…...
QD1-P21-P22 CSS 基础语法、注释、使用方法
本节学习:CSS 基础语法和注释,以及如何使用CSS定义的样式。 本节视频 https://www.bilibili.com/video/BV1n64y1U7oj?p21 CSS 基本语法 CSS(层叠样式表)的基本语法相对简单,由选择器和一组包含在花括号 {} 中的声…...

您是否也在寻找免费的 PDF 编辑器工具?10个备选PDF 编辑器工具
您是否也在寻找免费的 PDF 编辑器工具? 如果是,那么您在互联网上处于最佳位置! 本指南中提到的所有 10 大免费 PDF 编辑器工具都易于使用,可以允许您添加文本、更改图像、添加图形、填写表格、添加签名等等。 因此,…...
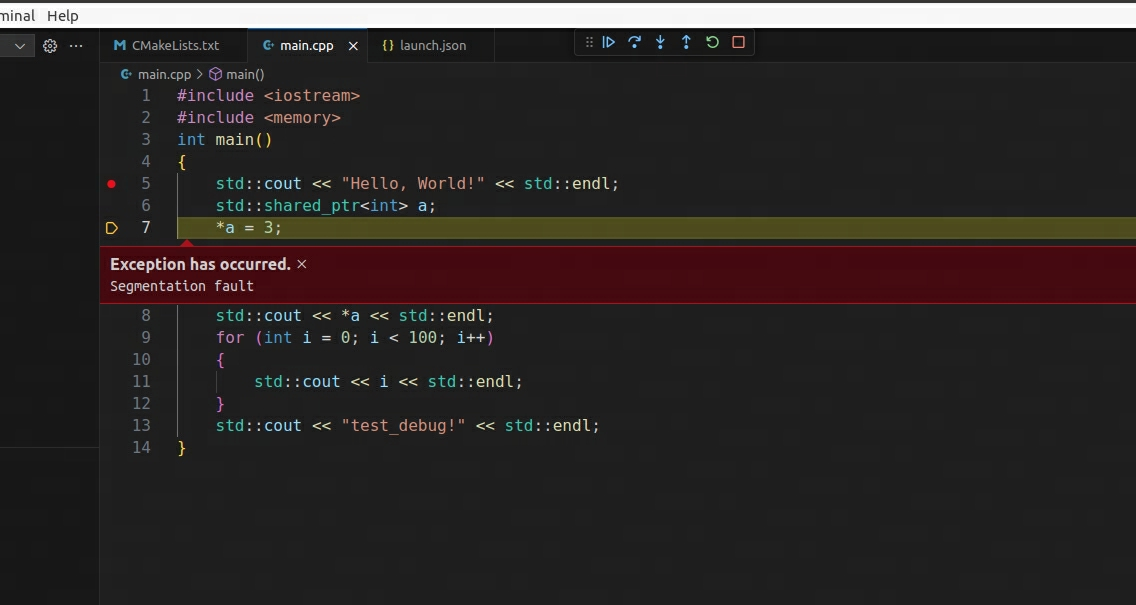
C++调试方法(Vscode)(一) ——本地调试
初学者在调试一段代码的时候,经常出于不明原因,写出bug,导致程序崩溃。但是定位崩溃的地方时,往往采用简单而朴素的方法:即采用cout或者printf进行输出。这种方式既原始,又低效。一个合格的工程师应该是通过…...

C语言 | Leetcode C语言题解之第460题LFU缓存
题目: 题解: /* 数值链表的节点定义。 */ typedef struct ValueListNode_s {int key;int value;int counter;struct ValueListNode_s *prev;struct ValueListNode_s *next; } ValueListNode;/* 计数链表的节点定义。 其中,head是数值链表的头…...
P4-隐性事实查询L2)
【AI论文精读12】RAG论文综述2(微软亚研院 2409)P4-隐性事实查询L2
AI知识点总结:【AI知识点】 AI论文精读、项目、思考:【AI修炼之路】 P1,P2,P3 四、隐性事实查询(L2) 4.1 概述 ps:P2有四种查询(L1,L2,L3,L4&…...

SpringBoot中间件Docker
Docker(属于C/S架构软件) 简介与概述 1.Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux …...

计算机毕设选题推荐【大数据专业】
计算机毕设选题推荐【大数据专业】 大数据专业的毕业设计需要结合数据的采集、存储、处理与分析等方面的技能。为帮助同学们找到一个适合且具有实践性的选题,我们为大家整理了50个精选的毕设选题。这些选题涵盖了大数据分析、处理技术、可视化等多个方向࿰…...
Bootstrap 4 多媒体对象
Bootstrap 4 多媒体对象 引言 Bootstrap 4 是目前最受欢迎的前端框架之一,它提供了一套丰富的工具和组件,帮助开发者快速构建响应式和移动设备优先的网页。在本文中,我们将重点探讨 Bootstrap 4 中的多媒体对象(Media Object)组件,这是一种用于构建复杂和灵活布局的强大…...

Springmvc Thymeleaf 标签
Thymeleaf是一个适用于Java的模板引擎,它允许开发者将动态内容嵌入到HTML页面中。在SpringMVC框架中,Thymeleaf可以作为一个视图解析器,使得开发者能够轻松地创建动态网页。以下是关于SpringMVC中Thymeleaf标签的详细介绍: 一、T…...

用java来编写web界面
一、ssm框架整体目录架构 二、编写后端代码 1、编写实体层代码 实体层代码就是你的对象 entity package com.cv.entity;public class Apple {private Integer id;private String name;private Integer quantity;private Integer price;private Integer categoryId;public…...

如何利用Fiddler进行抓包并自动化
首先一般使用Fiddler都是对手机模拟器进行抓包 接下来以MUMU模拟器为例 首先打开Fiddler-->tool-->options-->connection 将要打上的勾都打上,可以看到代理的端口是8888 打开HTTPS选项 把要打的勾打上,这样子才可以接收到HTTPS的包 MUMU打开…...

权重衰减与暂退法——pytorch与paddle实现模型正则化
权重衰减与暂退法——pytorch与paddle实现模型正则化 在深度学习中,模型正则化是一种至关重要的技术,它有助于防止模型过拟合,提高泛化能力。过拟合是指在训练数据上表现良好,但在测试数据或新数据上表现不佳的现象。为了缓解这一…...
MYSQL-windows安装配置两个或多个版本MYSQL
安装第一个mysql很简单,这里不再赘述。主要说说第二个怎么安装,服务怎么配置。 1. 从官网下载第二个MySQL并安装 一般都是免安装版了,下载解压到某个文件目录下(路径中尽量不要带空格或中文),再新建一个my.ini文件(或…...

6、Spring Boot 3.x集成RabbitMQ动态交换机、队列
一、前言 本篇主要是围绕着 Spring Boot 3.x 与 RabbitMQ 的动态配置集成,比如动态新增 RabbitMQ 交换机、队列等操作。二、默认RabbitMQ中的exchange、queue动态新增及监听 1、新增RabbitMQ配置 RabbitMQConfig.java import org.springframework.amqp.rabbit.a…...

STM32F407移植QP状态机踩坑实录:从编译报错到成功运行,我解决了这三个关键问题
STM32F407移植QP状态机踩坑实录:从编译报错到成功运行,我解决了这三个关键问题 在嵌入式开发中,状态机是一种极其重要的编程范式,它能有效管理复杂系统的行为逻辑。QP(Quantum Platform)作为一款轻量级的状…...

【ZYNQ】AXI4总线协议实战:从握手时序到PS-PL高效通信
1. AXI4总线协议基础:从握手信号到通道架构 第一次接触ZYNQ的PS-PL通信时,我被AXI4协议里那些VALID/READY信号搞得头晕眼花。直到在示波器上抓到真实的握手波形,才突然理解这个看似复杂的协议其实像极了我们日常的对话机制——只有当说话方准…...
:Agentic RAG——让 Agent 主导检索过程)
RAG 系列(十七):Agentic RAG——让 Agent 主导检索过程
Pipeline RAG 的沉默失败 前面十几篇一直在优化一件事:怎么让检索结果更好。更好的分块、更精准的排序、更聪明的问法、CRAG 纠偏、Graph RAG 关系遍历…… 但有一件事始终没变:无论检索结果好不好,都会被传给 LLM 生成答案。 Pipeline RAG 的流程是线性的、固定的: 问…...
)
从XTR文件看GNSS数据质量:如何利用Anubis报告优化你的测量方案(以GPS/BDS/Galileo为例)
从XTR文件解码GNSS数据质量:实战分析与优化策略 在GNSS测量领域,数据质量直接决定了最终定位结果的可靠性。XTR文件作为Anubis软件生成的质量报告,包含了大量反映GNSS观测质量的指标参数。对于有经验的工程师而言,这些数字不仅仅是…...

dotai:将AI大模型无缝集成到Shell终端的智能助手工具
1. 项目概述:当AI遇上你的终端如果你是一个重度命令行用户,每天在终端里敲击着ls、cd、git commit这些命令,有没有那么一瞬间,希望有个助手能帮你自动补全、解释命令,甚至直接帮你写出复杂的管道操作?dotai…...

防火墙和手动启动都试了?ArcGIS License Server无响应,可能是这两个核心文件在捣鬼
ArcGIS许可服务故障深度解析:当核心文件成为隐形杀手 当你面对ArcGIS License Server无响应的红色报错框,已经尝试了关闭防火墙、调整服务配置、甚至重启服务器等一系列标准操作后,那个令人沮丧的"cannot connect to license server sys…...

Redis高效开发工具集:从SCAN迭代到数据迁移的Python实践
1. 项目概述:一个Redis开发者的“瑞士军刀”如果你和我一样,日常开发中重度依赖Redis,那你一定遇到过这些场景:想快速查看某个大Key的内存占用,得写脚本遍历;想分析某个Pattern下的所有键,得手动…...

Docker Compose编排微服务
Docker Compose编排微服务 引言 Docker Compose是Docker官方提供的容器编排工具,用于定义和运行多容器Docker应用。通过Compose,可以使用YAML文件定义服务、网络、数据卷等资源,然后通过简单的命令启动和停止整个应用。Docker Compose特别适合…...

AI全栈开发实战:基于Cursor的智能代码生成与架构设计
1. 项目概述:当AI代码助手遇上全栈开发最近在GitHub上看到一个挺有意思的项目,叫“Cursor-FullStack-AI-App”。光看名字,你大概能猜到它和Cursor这个AI代码编辑器有关,并且涉及全栈应用开发。但它的价值远不止于此。作为一个在前…...

基于RAG与智能体技术构建专业客服AI:从知识注入到流程执行
1. 项目概述:一个面向客服场景的AI智能体指南最近在GitHub上看到一个挺有意思的项目,叫mrqhocungdungai-vn/hermes-cskh-guide。从名字就能猜个大概,这是一个关于“Hermes”的客服(CSKH)指南,而且看起来是越…...