(全网独家)面试要懂运维真实案例:HDFS重新平衡(HDFS Balancer)没触发问题排查
在面试时,面试官为了考察面试者是否真的有经验,经常会问运维集群时遇到什么问题,解决具体流程。下面是自己遇到HDFS Balancer没执行,花了半天时间进行排查,全网独家的案例和解决方案。
目录
使用CDH自带重新平衡操作
用命令行来进行操作
平衡操作的触发依赖以下几个条件:
如何排查非 HDFS 使用的空间
1. 检查磁盘使用情况
具体步骤:
2. 排查常见的非 HDFS 空间占用来源
3. 自动化检查工具
4. 清理策略
HDFS Balancer使用高级技巧
设置包含和排除节点
设置最大迁移速率
增加并发迁移线程数
使用CDH自带重新平衡操作
在CDH的所有主机看到有1台服务器的磁盘空间使用80%多,别的服务器才使用50%多。在CDH6.3.2的HDFS管理界面,操作选择重新平衡,在之前公司用过好多次,现在竟然没有作用。

用命令行来进行操作
可以用下面的命令来查看hdfs balancer的操作参数:
hdfs balancer -help

于是怀疑是不是阈值低了,或者CDH没开启配置。用下面的命令
阈值(threshold)用于控制触发平衡的使用率差异。CDH默认的阈值是10%,即当节点间磁盘使用率差异超过10%时,Balancer会启动平衡操作。可以通过以下命令来调整阈值,更低的阈值更容易触发:
hdfs balancer -threshold 5用上面的命令行还是没有触发。觉得很不合理,阈值是超过5%。
平衡操作的触发依赖以下几个条件:
-
节点磁盘使用率差异超过阈值:默认的平衡器阈值是 10%。如果一个DataNode的磁盘使用率比集群中其他节点的平均使用率高出10%,那么HDFS Balancer 就会触发数据块迁移操作。
-
HDFS 集群运行状态正常:Balancer 只在 HDFS 集群处于健康状态时运行。如果集群正在进行某些维护任务(如升级、修复等),Balancer 不会执行。
-
没有手动排除的节点:如果某些节点被排除在Balancer操作之外(通过 -exclude 参数或配置信息),这些节点将不会参与平衡操作,即使它们的使用率超出阈值。
为什么没触发平衡操作,HDFS Balancer计算的是节点DFS的磁盘空间使用率,并不包括不是不是HDFS占用的空间。
可以用hdfs dfsadmin -report 来观察集群配置情况。观察到
Hostname: cdh01
Rack: /default
Decommission Status : Normal
Configured Capacity: 16656052023296 (15.15 TB)
DFS Used: 4840676593599 (4.40 TB)
Non DFS Used: 8188630638657 (7.45 TB)
DFS Remaining: 2785643620165 (2.53 TB)
DFS Used%: 29.06%
DFS Remaining%: 16.72%
Configured Cache Capacity: 4294967296 (4 GB)
Cache Used: 0 (0 B)
Cache Remaining: 4294967296 (4 GB)
Cache Used%: 0.00%
Cache Remaining%: 100.00%
Xceivers: 31
Last contact: Fri Oct 11 15:09:51 CST 2024
Last Block Report: Fri Oct 11 15:03:24 CST 2024Hostname: cdh02
Rack: /default
Decommission Status : Normal
Configured Capacity: 16656052023296 (15.15 TB)
DFS Used: 4827967553247 (4.39 TB)
Non DFS Used: 2653966696737 (2.41 TB)
DFS Remaining: 8333836684496 (7.58 TB)
DFS Used%: 28.99%
DFS Remaining%: 50.03%
Configured Cache Capacity: 4294967296 (4 GB)
Cache Used: 0 (0 B)
Cache Remaining: 4294967296 (4 GB)
Cache Used%: 0.00%
Cache Remaining%: 100.00%
Xceivers: 15
Last contact: Fri Oct 11 15:44:00 CST 2024
Last Block Report: Fri Oct 11 12:34:33 CST 2024Hostname: cdh03
Rack: /default
Decommission Status : Normal
Configured Capacity: 16656052023296 (15.15 TB)
DFS Used: 4746786218883 (4.32 TB)
Non DFS Used: 2817949895805 (2.56 TB)
DFS Remaining: 8250599884860 (7.50 TB)
DFS Used%: 28.50%
DFS Remaining%: 49.54%
Configured Cache Capacity: 4294967296 (4 GB)
Cache Used: 0 (0 B)
Cache Remaining: 4294967296 (4 GB)
Cache Used%: 0.00%
Cache Remaining%: 100.00%
Xceivers: 25
Last contact: Fri Oct 11 15:43:59 CST 2024
Last Block Report: Fri Oct 11 14:15:08 CST 2024
上面的3个节点,cdh01的磁盘空间使用了80%多,另外2个节点磁盘空间只使用50%多。但为什么没有触发,觉得应该是由于HDFS Balance应该只是看DFS Used,这3个节点利用率差不多,所以没有触发操作。
如何排查非 HDFS 使用的空间
1. 检查磁盘使用情况
使用 Linux 命令行工具来查看文件系统中各个目录的磁盘使用情况。可以通过 du 命令逐层排查,识别占用大量空间的文件或目录。
具体步骤:
-
查看磁盘总使用情况
使用df -h命令查看各个挂载点的磁盘使用情况。df -h输出示例:
Filesystem Size Used Avail Use% Mounted on /dev/sda1 500G 450G 50G 90% /Filesystem Size Used Avail Use% Mounted on /dev/sda1 500G 450G 50G 90% /重点关注非 HDFS 数据所在的文件系统挂载点,确认使用情况。
-
使用
du排查具体目录
使用du命令可以查看目录的具体磁盘使用情况,并逐层定位占用磁盘空间较大的目录或文件。可以从根目录(或dfs.data.dir的父目录)开始进行排查。du -h --max-depth=1 /输出示例:
12G /var 30G /usr 8.1G /lib 50G /home 90G /此时,可以看到
/var、/usr、/home等目录的使用情况。通过将--max-depth参数调整为更深的层级,可以进一步深入查看子目录的使用情况。 -
递归查找特定目录内占用空间较大的文件 一旦发现了占用较大空间的目录,可以进一步使用
du命令查找目录内的文件或子目录。du -h --max-depth=1 /var例如:
2.5G /var/log 9.5G /var/lib 12G /var -
查看具体文件大小 一旦定位到具体的子目录,可以使用
ls -lh命令查看目录内的文件及其大小。ls -lh /var/log
2. 排查常见的非 HDFS 空间占用来源
以下是一些常见的占用非 HDFS 空间的地方:
-
系统日志文件 日志文件通常存储在
/var/log目录下,特别是 Hadoop 相关日志文件(如 HDFS、YARN、MapReduce)可能会占用大量空间。
检查/var/log目录下是否有过大的日志文件,例如:ls -lh /var/log可以定期清理旧日志或配置日志轮转机制(log rotation),避免日志文件无限增长。
-
本地临时文件 Hadoop 的数据节点和其他服务可能会在本地磁盘上创建临时文件,这些文件可能会积累过多,尤其是在任务失败或系统崩溃后。检查
/tmp或/var/tmp等临时目录的空间使用:du -h --max-depth=1 /tmp -
YARN/Nodemanager 的本地目录 Hadoop 的 YARN 框架在节点上运行任务时,会产生本地数据,特别是在 YARN Nodemanager 的本地目录中。这个目录通常配置为
yarn.nodemanager.local-dirs,可以查找该配置指向的目录并检查使用情况。du -h --max-depth=1 /path/to/yarn/local-dir -
应用程序生成的临时数据 如果节点上运行了其他应用程序或服务(例如数据库、监控系统),这些服务生成的文件可能占用较多磁盘空间。可以检查
/opt、/usr/local或者特定应用程序的存储目录。
3. 自动化检查工具
如果你不想手动排查,可以使用一些系统工具或脚本帮助识别大文件:
-
ncdu工具ncdu是一个基于 ncurses 的磁盘使用分析工具,可以通过图形化界面方便地查看每个目录占用的空间。 安装并使用:sudo apt-get install ncdu # Ubuntu/Debian sudo yum install ncdu # CentOS/RHEL ncdu / -
find命令查找大文件 你也可以使用find命令直接查找系统中超过一定大小的文件。例如,查找系统中超过 1 GB 的文件:find / -type f -size +1G -exec ls -lh {} \; | awk '{ print $9 ": " $5 }'
4. 清理策略
排查到占用大量非 HDFS 空间的文件后,可以采取以下措施进行清理和优化:
- 删除不必要的日志文件或临时文件。
- 配置日志轮转:通过设置
logrotate来自动清理过时的日志文件。 - 定期清理临时目录:通过计划任务 (
cron) 定期清理/tmp、YARN 本地目录等临时存储。 - 调整系统或应用程序配置:检查 Hadoop 或其他服务的配置文件,避免过度使用磁盘空间(例如设置合理的本地临时文件清理策略)。
HDFS Balancer使用高级技巧
设置包含和排除节点
如果想对特定节点进行平衡操作,或者排除某些节点,可以使用 -include 或 -exclude 参数。例如:
- 包含节点:
hdfs balancer -include <node1,node2,...>
只对指定的节点进行平衡操作。
- 排除节点:
hdfs balancer -exclude <node1,node2,...>
排除指定的节点不进行平衡操作。
设置最大迁移速率
平衡操作可能会消耗较多带宽和系统资源,因此可以控制最大数据迁移速率。HDFS中通过参数 dfs.balance.bandwidthPerSec 控制每秒最大数据传输速率。默认值是 1 MiB/s,如果要加快或减慢平衡过程,可以通过以下方式修改:
- 修改 HDFS 配置文件
hdfs-site.xml 中的 dfs.balance.bandwidthPerSec 值:
<property><name>dfs.balance.bandwidthPerSec</name><value>10485760</value> <!-- 10 MiB/s -->
</property>
- 或者在命令行运行 Balancer 时指定速率:
hdfs balancer -bandwidth <字节数/秒>例如,设置为每秒传输 10 MiB 数据:
hdfs balancer -bandwidth 10485760增加并发迁移线程数
在一些大集群中,默认的并发迁移线程数可能不足以快速完成平衡操作。可以通过增加 dfs.balancer.moverThreads 参数,来允许更多的数据块同时迁移。例如,默认值是1000,可以根据集群负载情况适当增大这个值:
<property><name>dfs.balancer.moverThreads</name><value>2000</value></property>小结
HDFS Balancer 判断节点是否不平衡,主要依据的是每个节点的 磁盘使用率差异(DFS的使用率),不包括非DFS空间。集群节点之间的磁盘利用率一旦超过设定的阈值(threshold),HDFS Balancer 就会认为集群处于不平衡状态,进而触发数据块迁移操作。具体步骤如下:
- 收集节点磁盘使用情况:HDFS NameNode 会定期统计所有 DataNode 的磁盘使用情况。
- 比较节点之间的使用率差异:Balancer 会根据设定的 阈值(threshold),比较集群中不同节点的磁盘使用率。如果某些节点的使用率比其他节点高出设定的阈值,Balancer 就会认为集群不均衡。
- 决定数据块迁移:当节点间的使用率差异超过阈值,Balancer 会尝试将一些数据块从高使用率的节点迁移到低使用率的节点,以减小这种差异。
相关文章:
(全网独家)面试要懂运维真实案例:HDFS重新平衡(HDFS Balancer)没触发问题排查
在面试时,面试官为了考察面试者是否真的有经验,经常会问运维集群时遇到什么问题,解决具体流程。下面是自己遇到HDFS Balancer没执行,花了半天时间进行排查,全网独家的案例和解决方案。 目录 使用CDH自带重新平衡操作…...

【数据结构笔记】搜索树
二叉搜索树 任一节点x的左/右子树中,所有非空节点均不大于(不小于)x 必须是所有的非空节点,仅左右孩子不够(左孩子的右孩子可能很大)一棵二叉树是二叉搜索树当且仅当中序遍历序列是单调非降序列 两棵二叉…...

如何使用UART(STM32 HAL库)
UART (通用异步收发器)是在 USART (通用同步异步收发器)基础上裁剪掉了同步通信功能,只剩下异步通信功能。关于通信和串口的基本知识,可参见文章《串口通信简介-CSDN博客》和《数据通信的一些基础概念-CSDN…...

星巴克英语
用流利的英文点星巴克 一杯咖啡 英文中文英文中文barista咖啡师coffee maker家用咖啡机cup sleeve杯套coffee stirrer咖啡棒coffee cup lid咖啡杯盖子straw吸管latte art咖啡拉花for here内用to go外带 例句: Could I have a cup sleeve for my coffee , please…...

权重衰减与暂退法——paddle部分
权重衰减与暂退法——paddle部分 本文部分为paddle框架以及部分理论分析,torch框架对应代码可见权重衰减与暂退法torch import paddle print("paddle version:",paddle.__version__)paddle version: 2.6.1当我们谈论机器学习模型的性能时,经…...

golang获取当天最小的时间,以DateTime的string格式返回
推荐学习文档 golang应用级os框架,欢迎stargolang应用级os框架使用案例,欢迎star案例:基于golang开发的一款超有个性的旅游计划app经历golang实战大纲golang优秀开发常用开源库汇总想学习更多golang知识,这里有免费的golang学习笔…...

2025 - 中医学基础 - 考研 - 职称
2025 - 中医学基础 - 考研 - 职称 第1章 中医学导论 1.中医学的指导思想是()( ) [单选] A.阴阳学说 B.五行学说 C.精气学说 D.整体观念 E.辨证论治 正确答案: D 2.中医学的理论核心是&…...

Pandas库
一、安装 Pandas是一个基于Python构建的专门进行数据操作和分析的开源软件库,它提供了高效的数据结构和丰富的数据操作工具。 安装 pip install pandas 二、核心数据结构 Pandas库中最常用的数据类型是Series和DataFrame: Series:一维数…...

Qt网络编程: 构建高效的HTTP文件下载器
文章目录 注意事项调用示例在使用Qt进行HTTP下载时,通常会使用QNetworkAccessManager类来管理HTTP请求和响应。这个类提供了进行网络请求的能力,包括下载文件。下面是使用Qt进行HTTP下载的一个示例,以及在实现时应考虑的一些注意事项。 注意事项 1.错误处理 始终检查QNetwo…...

Python 将Word, Excel, PDF和PPT文档转换为OFD格式
目录 使用工具 Python 将Word文档转换为OFD Python 将Excel文档转换为OFD Python 将PDF文档转换为OFD Python 将PPT文档转换为OFD OFD(Open Fixed-layout Document)是中国国家标准的电子文档格式,主要用于政府、金融等行业的正式文档传输…...
QD1-P21-P22 CSS 基础语法、注释、使用方法
本节学习:CSS 基础语法和注释,以及如何使用CSS定义的样式。 本节视频 https://www.bilibili.com/video/BV1n64y1U7oj?p21 CSS 基本语法 CSS(层叠样式表)的基本语法相对简单,由选择器和一组包含在花括号 {} 中的声…...

您是否也在寻找免费的 PDF 编辑器工具?10个备选PDF 编辑器工具
您是否也在寻找免费的 PDF 编辑器工具? 如果是,那么您在互联网上处于最佳位置! 本指南中提到的所有 10 大免费 PDF 编辑器工具都易于使用,可以允许您添加文本、更改图像、添加图形、填写表格、添加签名等等。 因此,…...
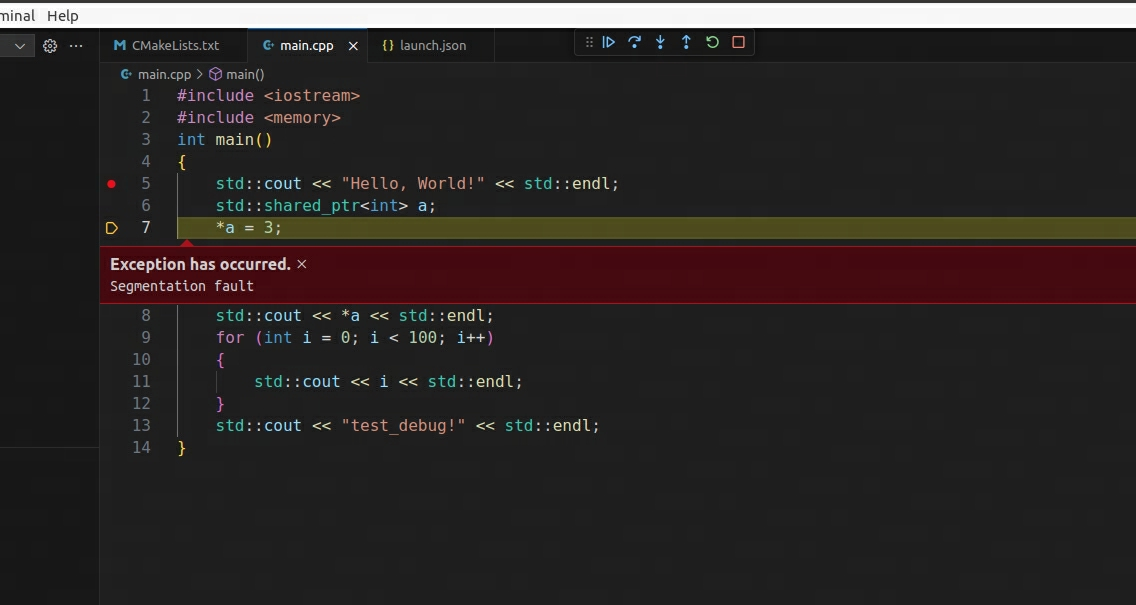
C++调试方法(Vscode)(一) ——本地调试
初学者在调试一段代码的时候,经常出于不明原因,写出bug,导致程序崩溃。但是定位崩溃的地方时,往往采用简单而朴素的方法:即采用cout或者printf进行输出。这种方式既原始,又低效。一个合格的工程师应该是通过…...

C语言 | Leetcode C语言题解之第460题LFU缓存
题目: 题解: /* 数值链表的节点定义。 */ typedef struct ValueListNode_s {int key;int value;int counter;struct ValueListNode_s *prev;struct ValueListNode_s *next; } ValueListNode;/* 计数链表的节点定义。 其中,head是数值链表的头…...
P4-隐性事实查询L2)
【AI论文精读12】RAG论文综述2(微软亚研院 2409)P4-隐性事实查询L2
AI知识点总结:【AI知识点】 AI论文精读、项目、思考:【AI修炼之路】 P1,P2,P3 四、隐性事实查询(L2) 4.1 概述 ps:P2有四种查询(L1,L2,L3,L4&…...

SpringBoot中间件Docker
Docker(属于C/S架构软件) 简介与概述 1.Docker 是一个开源的应用容器引擎,基于 Go 语言 并遵从 Apache2.0 协议开源。 Docker 可以让开发者打包他们的应用以及依赖包到一个轻量级、可移植的容器中,然后发布到任何流行的 Linux …...

计算机毕设选题推荐【大数据专业】
计算机毕设选题推荐【大数据专业】 大数据专业的毕业设计需要结合数据的采集、存储、处理与分析等方面的技能。为帮助同学们找到一个适合且具有实践性的选题,我们为大家整理了50个精选的毕设选题。这些选题涵盖了大数据分析、处理技术、可视化等多个方向࿰…...
Bootstrap 4 多媒体对象
Bootstrap 4 多媒体对象 引言 Bootstrap 4 是目前最受欢迎的前端框架之一,它提供了一套丰富的工具和组件,帮助开发者快速构建响应式和移动设备优先的网页。在本文中,我们将重点探讨 Bootstrap 4 中的多媒体对象(Media Object)组件,这是一种用于构建复杂和灵活布局的强大…...

Springmvc Thymeleaf 标签
Thymeleaf是一个适用于Java的模板引擎,它允许开发者将动态内容嵌入到HTML页面中。在SpringMVC框架中,Thymeleaf可以作为一个视图解析器,使得开发者能够轻松地创建动态网页。以下是关于SpringMVC中Thymeleaf标签的详细介绍: 一、T…...

用java来编写web界面
一、ssm框架整体目录架构 二、编写后端代码 1、编写实体层代码 实体层代码就是你的对象 entity package com.cv.entity;public class Apple {private Integer id;private String name;private Integer quantity;private Integer price;private Integer categoryId;public…...

AI量化交易框架解析:从架构设计到实战部署
1. 项目概述:一个AI驱动的加密资产对冲基金框架最近在GitHub上看到一个挺有意思的项目,叫“ai-hedge-fund-crypto”。光看名字,就能感受到一股浓浓的“量化AI加密”的混合气息。这其实是一个开源框架,旨在帮助开发者或量化研究员&…...

低温预警!固化慢、易开裂……密封胶冬季施工手册
低温预警!固化慢、易开裂……密封胶冬季施工手册 硅酮耐候密封胶主要作用是保障幕墙的气密性、水密性。其出现问题,可能会导致耐候密封失效,从而造成幕墙漏水漏气,影响幕墙的正常使用。耐候密封胶由于考虑到现场施工,几乎都是单组分硅酮密封胶产品。进入冬季,气候变化明…...

Windows Defender终极移除指南:高效卸载13项核心服务完整教程
Windows Defender终极移除指南:高效卸载13项核心服务完整教程 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.com/gh_mirr…...
)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战(含ifconfig与DHCP详解)
从零到联网:QNX Neutrino RTOS安装后的第一个网络配置实战 当你第一次看到QNX Neutrino RTOS的Photon桌面时,那种兴奋感可能很快会被一个现实问题冲淡——这个看起来酷炫的系统怎么连上网?作为实时操作系统领域的标杆,QNX在车载系…...
技术解析与应用前景)
量子私有信息检索(QPIR)技术解析与应用前景
1. 量子私有信息检索技术概述量子私有信息检索(Quantum Private Information Retrieval, QPIR)是密码学领域的一项突破性技术,它允许用户从数据库中检索特定条目而不泄露被查询的是哪个条目。这项技术的核心价值在于解决了隐私保护与数据获取…...

基于Sovereign-MCP-Servers构建私有AI工具链:从协议原理到Docker化部署
1. 项目概述与核心价值最近在折腾AI应用开发,特别是想给Claude、Cursor这类工具加上“联网”和“执行”能力时,绕不开一个概念:MCP(Model Context Protocol)。简单说,MCP就是一套标准协议,它能让…...

基于语义搜索的AI代码理解工具copaw-code深度解析
1. 项目概述:一个面向代码搜索与理解的AI工具 最近在GitHub上看到一个挺有意思的项目,叫 QSEEKING/copaw-code 。乍一看这个标题,可能会有点摸不着头脑,“copaw”是什么?但结合“code”和项目托管在QSEEKING这个组织…...

AI编程助手CodeBuddy:VS Code扩展的架构、部署与高效使用指南
1. 项目概述:CodeBuddy,你的AI编程伙伴最近在GitHub上看到一个挺有意思的项目,叫codebuddy,作者是olasunkanmi-SE。光看名字就能猜个大概——“代码伙伴”,这显然是一个旨在辅助编程的工具。作为一个在开发一线摸爬滚打…...

如何在Windows 11上让经典游戏重获新生:DDrawCompat兼容性解决方案详解
如何在Windows 11上让经典游戏重获新生:DDrawCompat兼容性解决方案详解 【免费下载链接】DDrawCompat DirectDraw and Direct3D 1-7 compatibility, performance and visual enhancements for Windows Vista, 7, 8, 10 and 11 项目地址: https://gitcode.com/gh_m…...

如何用Wedecode实现微信小程序源代码的完美还原:从加密包到可读代码的完整指南
如何用Wedecode实现微信小程序源代码的完美还原:从加密包到可读代码的完整指南 【免费下载链接】wedecode 全自动化,微信小程序 wxapkg 包 源代码还原工具, 线上代码安全审计,支持 Windows, Macos, Linux 项目地址: https://gitcode.com/gh…...