Python机器学习数据清洗到特征工程策略
Python机器学习数据清洗到特征工程策略
目录
- ✨ 数据清洗:处理缺失值与异常值的策略
- 🔄 特征选择:筛选与数据目标高度相关的特征
- 🛠 特征工程:数据转换与生成新特征的多样化方法
- 📊 类别型变量的数值化:数值编码与独热编码的实践
- 🚀 数据标准化与归一化:确保特征数据的一致性
- 💡 时间序列数据的预处理:日期特征提取与滞后特征生成
1. ✨ 数据清洗:处理缺失值与异常值的策略
在机器学习任务中,数据预处理的首要步骤是数据清洗。数据清洗的目的是识别和处理缺失值、重复数据以及异常值,以确保数据的完整性与质量。未经过清洗的原始数据通常存在各种不完美,这些问题若不处理,将直接影响模型的训练效果与预测结果。常见的数据清洗步骤包括处理缺失值、重复值和异常值。
处理缺失值
缺失值是数据预处理中最常见的问题之一。缺失值的处理方式有很多种,包括删除缺失值所在的行、用统计量(如均值、中位数等)填充,或使用插值法、建模填充等高级方法。以下是几种处理缺失值的方式:
-
删除缺失值:当缺失值的比例较小或该特征对模型无关紧要时,可以选择直接删除这些数据行。Pandas库中的
dropna()函数可以方便地执行这一操作:import pandas as pd# 创建包含缺失值的DataFrame data = {'Age': [25, 30, None, 35], 'Salary': [50000, None, 60000, 65000]} df = pd.DataFrame(data)# 删除包含缺失值的行 df_cleaned = df.dropna() print(df_cleaned) -
填充缺失值:如果删除数据行会导致样本量不足,可以采用均值、中位数或众数来填充缺失值。Pandas库的
fillna()函数可以直接进行填充操作:# 用列的均值填充缺失值 df_filled = df.fillna(df.mean()) print(df_filled) -
插值法填充:对于时间序列数据或有序数据,可以采用插值法来填充缺失值,以保证数据的连续性和合理性。通过插值法,可以根据数据的趋势进行预测填充:
# 使用插值法填充缺失值 df_interpolated = df.interpolate() print(df_interpolated)
处理重复值
重复值通常会降低模型的泛化能力,使模型对某些特定模式产生偏倚。因此,必须检测并处理重复数据。在Pandas中,可以使用duplicated()和drop_duplicates()方法来检测和删除重复值。
# 检查重复值
duplicates = df.duplicated()# 删除重复值
df_no_duplicates = df.drop_duplicates()
print(df_no_duplicates)
处理异常值
异常值(outliers)是指偏离数据整体分布规律的值,它们可能对模型产生极大的负面影响。在处理异常值时,可以采用统计分析法(如箱线图法)或基于算法的检测方法(如局部异常因子)。一种常见的处理方法是将异常值替换为特定的统计值,或者通过过滤策略删除异常值。
import numpy as np# 创建包含异常值的数据
data_with_outliers = {'Age': [22, 25, 30, 120, 28], 'Salary': [50000, 60000, 55000, 90000, 65000]}
df_outliers = pd.DataFrame(data_with_outliers)# 使用Z-score方法识别异常值
df_outliers['Age_Zscore'] = (df_outliers['Age'] - df_outliers['Age'].mean()) / df_outliers['Age'].std()
df_outliers = df_outliers[(df_outliers['Age_Zscore'].abs() <= 3)] # 保留Z-score在3以内的数据
print(df_outliers)
清洗后的数据更加可靠且具备更好的模型适应性。通过合理处理缺失值、重复值与异常值,可以大大提高机器学习模型的训练效果。
2. 🔄 特征选择:筛选与数据目标高度相关的特征
特征选择是机器学习中提高模型性能和可解释性的重要步骤。特征选择的目的是筛选出对目标变量最有帮助的特征,同时删除不相关或冗余的特征,以减少数据噪音、提高模型效率。
过滤法
过滤法通过统计指标(如相关系数、卡方检验、互信息等)来评估每个特征与目标变量之间的关联性。相关性高的特征保留,相关性低的特征则删除。这种方法简单高效,适用于大规模数据集。
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.datasets import load_iris# 加载Iris数据集
X, y = load_iris(return_X_y=True)# 选择与目标变量最相关的两个特征
selector = SelectKBest(score_func=f_classif, k=2)
X_new = selector.fit_transform(X, y)
print(X_new)
包装法
包装法则通过反复训练模型来评估特征的组合效果。递归特征消除(Recursive Feature Elimination, RFE)是一种常见的包装法,通过递归地移除最不重要的特征,最终选出最优特征子集。
from sklearn.feature_selection import RFE
from sklearn.ensemble import RandomForestClassifier# 使用随机森林作为基模型
model = RandomForestClassifier()# 实例化递归特征消除工具
rfe = RFE(estimator=model, n_features_to_select=2)# 进行特征选择
X_rfe = rfe.fit_transform(X, y)
print(X_rfe)
嵌入法
嵌入法则结合了模型训练和特征选择过程,直接通过模型的权重或特征重要性来决定特征的去留。例如,决策树和随机森林等模型本身就能够评估特征的重要性。
# 使用随机森林评估特征重要性
model.fit(X, y)
importances = model.feature_importances_# 打印特征的重要性
for i, importance in enumerate(importances):print(f"Feature {i}: Importance {importance}")
特征选择不仅能够提高模型的性能,还可以减少过拟合风险,使模型的泛化能力更强。通过合理选择特征,可以有效提高机器学习模型的精度和效率。
3. 🛠 特征工程:数据转换与生成新特征的多样化方法
特征工程是一项非常关键的任务,涉及对原始数据进行处理、转化甚至生成新特征。高质量的特征工程可以极大提升模型的表现。特征工程包括对连续变量的处理、离散化,以及生成派生特征等。
数值特征的处理
数值型特征往往需要进行适当的变换,以便更好地用于机器学习模型中。常见的操作包括对数变换、平方根变换等,以解决特征的分布不均衡问题。
import numpy as np# 对数变换
df['log_Age'] = np.log(df['Age'] + 1)# 平方根变换
df['sqrt_Age'] = np.sqrt(df['Age'])
离散化
对于连续变量,可以将其离散化为多个区间,从而帮助模型更好地捕捉变量的分布特征。cut()函数可以将数据分箱处理:
# 使用Pandas对连续变量进行分箱
df['Age_binned'] = pd.cut(df['Age'], bins=[0, 20, 40, 60, 80], labels=['Young', 'Adult', 'Middle-aged', 'Senior'])
print(df)
派生特征
派生特征是从已有数据中创建的新特征。例如,在时间序列数据中,可以提取出月份、季度等时间特征,这样能够增强模型对时间模式的捕捉能力。
# 提取日期特征
df['date'] = pd.to_datetime(df['date'])
df['month'] = df['date'].dt.month
df['quarter'] = df['date'].dt.quarter
特征工程通过合理转换与生成特征,能够帮助模型更好地学习数据中的模式,提高预测效果。
相关文章:

Python机器学习数据清洗到特征工程策略
Python机器学习数据清洗到特征工程策略 目录 ✨ 数据清洗:处理缺失值与异常值的策略🔄 特征选择:筛选与数据目标高度相关的特征🛠 特征工程:数据转换与生成新特征的多样化方法📊 类别型变量的数值化&…...

多线程-进阶(2)CountDownLatchConcurrentHashMapSemaphore
目的; JUC(java.util.concurrent) 的常⻅类 接着上一节课到 1.信号量 Semaphore 信号量, ⽤来表⽰ "可⽤资源的个数". 本质上就是⼀个计数器。 理解信号量 可以把信号量想象成是停⻋场的展⽰牌: 当前有⻋位 100 个. 表⽰有 100 个可⽤资源. 当有⻋开进去的时候,…...
密码管理器KeePass的安装及使用
文章目录 软件下载安装汉化新建数据库创建\移动\修改 群组添加/修改/删除/移动 记录展示、搜索、锁定单独使用keepass生成密码的功能AES-256的密钥长度为256位,为啥可以设置超过32个字符的密钥? 软件下载 安装 分别解压:KeePass-2.53.1.zip&…...

星海智算:【萤火遛AI-Stable-Diffusion】无需部署一键启动
部署流程 1、注册算力云平台:星海智算 https://gpu.spacehpc.com/ 2、创建实例,镜像请依次点击:“镜像市场”->“更换”->“AI绘画”->“萤火遛AI-Stable Diffusion”。 程序首次启动可能需要几分钟,待实例显示“运行…...

JS生成器的特殊用法:委托yield*
yield 的基本用法 yield 用于在生成器函数中暂停函数执行,并返回一个值给外部调用者。当生成器再次被调用时,会从暂停的地方继续执行。 示例: function* simpleGenerator() {yield 1;yield 2;yield 3; }const gen simpleGenerator();cons…...
找不到 ‘vector_types.h‘)
【CuPy报错】NVRTC_ERROR_COMPILATION (6)找不到 ‘vector_types.h‘
cupy安装不要再使用pip install cupy了, 已经替换成基于版本安装了pip install cupy-cuda12x,详见cupy官网。 安装完成后,在import cupy之后报错,找不到 ‘vector_types.h’: CompileException: /home/zoe/venv/lib/python3.10/…...

机器学习:知识蒸馏(Knowledge Distillation,KD)
知识蒸馏(Knowledge Distillation,KD)作为深度学习领域中的一种模型压缩技术,主要用于将大规模、复杂的神经网络模型(即教师模型)压缩为较小的、轻量化的模型(即学生模型)。在实际应…...

【C++入门篇 - 3】:从C到C++第二篇
文章目录 从C到C第二篇new和delete命名空间命名空间的访问 cin和coutstring的基本使用 从C到C第二篇 new和delete 在C中用来向系统申请堆区的内存空间 New的作用相当于C语言中的malloc Delete的作用相当于C语言中的free 注意:在C语言中,如果内存不够…...

YOLOv8模型改进 第七讲 一种新颖的注意力机制 Outlook Attention
随着目标检测技术的不断发展,YOLOv8 作为最新一代的目标检测模型,已经在多个基准数据集上展现了其卓越的性能。然而,在复杂场景中,如何进一步提升模型的检测精度和鲁棒性依然是一个重要挑战。本文将探讨将 Outlook Attention 机制…...
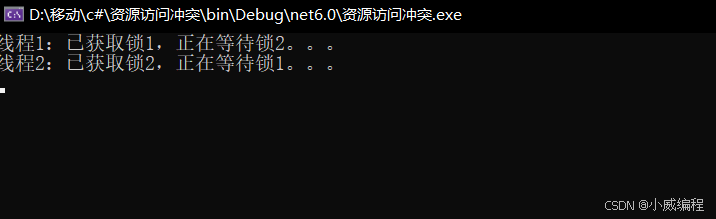
C#多线程基本使用和探讨
线程是并发编程的基础概念之一。在现代应用程序中,我们通常需要执行多个任务并行处理,以提高性能。C# 提供了多种并发编程工具,如Thread、Task、异步编程和Parallel等。 Thread 类 Thread 类是最基本的线程实现方法。使用Thread类࿰…...

PHP DateTime基础用法
PHP DateTime 的用法详解 一、引言 在开发 PHP 应用程序时,处理日期和时间是一个至关重要的任务。PHP 提供了强大的日期和时间处理功能,其中 DateTime 类是最常用的工具之一。DateTime 类提供了丰富的方法来创建、格式化、计算和比较日期时间ÿ…...

一次Fegin CPU占用过高导致的事故
记录一下 一次应用事故分析、排查、处理 背景介绍 9号上午收到CPU告警,同时业务反馈依赖该服务的上游服务接口响应耗时太长 应用告警-CPU使用率 告警变更 【WARNING】项目XXX,集群qd-aliyun,分区bbbb-prod,应用customer,实例customer-6fb6448688-m47jz, POD实例CP…...

【Go初阶】两万字快速入门Go语言
初见golang语法 package mainimport "fmt"func main() {/* 简单的程序 万能的hello world */fmt.Println("Hello Go")} 第一行代码package main定义了包名。你必须在源文件中非注释的第一行指明这个文件属于哪个包,如:package main…...

【React】使用 react hooks 需要遵守的原则
1)只能在顶层调用Hooks 这是指你不能在循环、条件语句或嵌套函数中调用Hooks。确保每次组件渲染时,Hooks的调用顺序保持一致。因此,你应该始终在React函数组件的最顶层调用Hooks。 React依赖于Hooks的调用顺序。如果这些调用在不同的渲染中顺…...

Python编程:创意爱心表白代码集
在寻找一种特别的方式来表达你的爱意吗?使用Python编程,你可以创造出独一无二的爱心图案,为你的表白增添一份特别的浪漫。这里为你精选了六种不同风格的爱心表白代码,让你的创意和情感通过代码展现出来。 话不多说,咱…...

腾讯IM SDK:TUIKit发送多张图片
一、问题描述 在使用腾讯IM DEMO(https://github.com/TencentCloud/chat-uikit-vue.git)时发现其只支持发送一张图片: 二、解决方案 // src\TUIKit\components\TUIChat\message-input-toolbar\image-upload\index.vue<inputref"inp…...

《本地部署开源大模型》在Ubuntu 22.04系统下ChatGLM3-6B高效微调实战
在Ubuntu 22.04系统下ChatGLM3-6B高效微调实战 无论是在单机单卡(一台机器上只有一块GPU)还是单机多卡(一台机器上有多块GPU)的硬件配置上启动ChatGLM3-6B模型,其前置环境配置和项目文件是相同的。如果大家对配置过程还…...

Python 脚本来自动发送每日电子邮件报告
安装必要的库 我们将使用 smtplib 发送邮件,以及 email.mime 来创建电子邮件内容。另外,为了让脚本自动定时运行,可以使用操作系统的计划任务工具(如 Linux 的 cron 或 Windows 的 Task Scheduler)。 创建邮件内容 使…...

大语言模型与ChatGPT:深入探索与应用
文章目录 1. 前言2. 大语言模型的概述2.1 什么是大语言模型?2.2 Transformer架构的核心2.3 预训练与微调 3. ChatGPT的架构与技术背景3.1 GPT模型的演进3.2 ChatGPT的工作原理 4. ChatGPT的实际应用4.1 日常对话助手4.2 内容生成与写作4.3 编程辅助4.4 教育与学习辅…...

【从零开始的LeetCode-算法】3164.优质数对的总数 II
给你两个整数数组 nums1 和 nums2,长度分别为 n 和 m。同时给你一个正整数 k。 如果 nums1[i] 可以被 nums2[j] * k 整除,则称数对 (i, j) 为 优质数对(0 < i < n - 1, 0 < j < m - 1)。 返回 优质数对 的总数。 示…...

小白也能学会:MogFace透明蒙版可视化,人脸检测不再难
小白也能学会:MogFace透明蒙版可视化,人脸检测不再难 1. 为什么需要透明蒙版可视化? 想象一下这样的场景:你拍了一张全家福,想用AI工具检测照片中有多少人。传统的检测工具会在每个人脸上画一个绿色的方框࿰…...

别再到处找了!这12个三维点云开源数据集,够你从入门到项目实战
三维点云实战指南:12个精选开源数据集与精准匹配策略 当你第一次打开三维点云处理软件,面对空白的项目界面,最迫切的问题往往是:"我该从哪里获取高质量的训练数据?"这个问题困扰过每一位初学者,…...
)
别再手动改稿了!用LaTeX的soul包搞定论文批注(删除线/高亮/引用兼容)
LaTeX高效批注指南:用soul包实现学术协作的优雅排版 当导师的红色批注铺满论文初稿,或是合作者发来二十处修改意见时,大多数研究者都会面临一个共同困境——如何在保留原始内容的同时清晰标记修改痕迹?传统的手动添加删除线或高亮…...

Linux系统CPU负载与使用率详解及性能监控
1. CPU负载与CPU使用率的本质区别在Linux系统监控和性能调优过程中,CPU负载和CPU使用率这两个指标经常被混淆使用。作为系统管理员,我曾多次遇到团队成员将这两个概念混为一谈的情况,这往往导致对系统性能问题的误判。让我们先从一个实际案例…...

在MATLAB中调用与可视化Lingbot-Depth-Pretrain-ViTL-14的深度估计结果
在MATLAB中调用与可视化Lingbot-Depth-Pretrain-ViTL-14的深度估计结果 对于很多从事计算机视觉、机器人或者测绘相关研究的工程师和学者来说,深度估计是一个基础又关键的任务。它能从一张普通的二维图片中,推测出每个像素点距离相机的远近,…...

Umi-OCR:重新定义本地化文字识别的工作流范式
Umi-OCR:重新定义本地化文字识别的工作流范式 【免费下载链接】Umi-OCR OCR software, free and offline. 开源、免费的离线OCR软件。支持截屏/批量导入图片,PDF文档识别,排除水印/页眉页脚,扫描/生成二维码。内置多国语言库。 …...
腾讯WorkBuddy 阿里JVS Claw 百度DuMate)
整理 主流国产AI龙虾的核心能力对比表(支持平台/部署方式/适用场景)腾讯WorkBuddy 阿里JVS Claw 百度DuMate
根据当前的资料,腾讯WorkBuddy和百度的DuMate当前有一定一定量的免费额度,大家可以用起来! 主流国产AI龙虾的核心能力对比表 五款主流国产AI龙虾的核心能力对比表已整理完成,涵盖支持平台、部署方式与适用场景三大维度ÿ…...

USB251xB集线器I²C控制库:嵌入式USB设备扩展实战指南
1. 项目概述SparkFun USB Hub Qwiic USB251x 是一款面向嵌入式原型开发与量产过渡阶段的轻量级 USB 2.0 集线器控制库,专为 SparkFun 自研的 Qwiic 兼容 USB251xB 系列 Hub 模块(SPX-18014)设计。该库并非通用 USB 协议栈,而是聚焦…...

突破资源封装壁垒:RePKG开源工具全维度应用指南
突破资源封装壁垒:RePKG开源工具全维度应用指南 【免费下载链接】repkg Wallpaper engine PKG extractor/TEX to image converter 项目地址: https://gitcode.com/gh_mirrors/re/repkg 问题:专用资源格式的困境与破局思路 如何突破专用格式的封锁…...

Qwen3-14B镜像轻量化设计:50GB系统盘+40GB数据盘高效空间管理
Qwen3-14B镜像轻量化设计:50GB系统盘40GB数据盘高效空间管理 1. 镜像概述与核心优势 Qwen3-14B私有部署镜像是一款专为RTX 4090D 24GB显存显卡优化的轻量化解决方案。通过精心设计的50GB系统盘40GB数据盘架构,实现了大模型部署的空间效率最大化。这个镜…...