mongodb的相关关键字说明
以下是MongoDB中一些数据库相关的关键字说明:
1. 数据库(Database)
- 概念
- 数据库是MongoDB中数据存储的最高层级容器,类似于关系型数据库中的数据库概念。一个MongoDB服务器实例可以包含多个数据库,每个数据库可以有自己独立的集合和文档。
- 操作相关关键字
use:用于切换到指定的数据库,如果数据库不存在则创建该数据库。例如:use mydb会切换到mydb数据库,如果mydb不存在则创建它。show dbs或show databases:用于显示当前MongoDB服务器实例中所有的数据库列表。但需要注意的是,它只会显示有数据的数据库(即数据库中至少有一个集合包含文档)或者已经分配了一定磁盘空间的数据库。
2. 集合(Collection)
- 概念
- 集合是MongoDB中一组文档的容器,类似于关系型数据库中的表。一个数据库可以包含多个集合,集合中的文档可以有不同的结构(即字段可以不同,但都符合MongoDB的文档格式要求)。
- 操作相关关键字
db.createCollection("collection_name"):用于在当前数据库中手动创建一个名为collection_name的集合。例如:db.createCollection("users")会创建一个名为users的集合。需要注意的是,如果向一个不存在的集合中插入文档时,MongoDB会自动创建该集合,所以手动创建集合不是必需的操作。show collections或show tables:用于显示当前数据库中所有的集合列表。例如,在切换到mydb数据库后,执行show collections会显示mydb数据库中的所有集合。db.collection_name.drop():用于删除当前数据库中名为collection_name的集合。例如:db.users.drop()会删除users集合。
3. 文档(Document)
- 概念
- 文档是MongoDB中数据的基本单元,它是一个类似于JSON格式的键值对数据结构,也被称为BSON(Binary JSON)格式。文档可以包含不同类型的数据字段,并且可以嵌套其他文档或数组。
- 操作相关关键字
db.collection_name.insert(document):用于向collection_name集合中插入一个文档。例如:db.users.insert({"name":"John","age":30})会向users集合中插入一个包含name和age字段的文档。这里的文档格式是一个JSON风格的对象,其中键是字段名,值是对应的数据。db.collection_name.find():用于查询collection_name集合中的所有文档。例如:db.users.find()会返回users集合中的所有文档。可以使用查询条件来筛选特定的文档,例如:db.users.find({"age":30})会返回users集合中age为30的文档。db.collection_name.update(query, update):用于更新collection_name集合中符合query条件的文档。例如:db.users.update({"age":30},{"$set":{"age":31}})会将users集合中age为30的文档的age字段更新为31。这里的$set是一个更新操作符,用于指定要更新的字段和值。db.collection_name.remove(query):用于删除collection_name集合中符合query条件的文档。例如:db.users.remove({"age":30})会删除users集合中age为30的文档。
4. 索引(Index)
- 概念
- 索引是一种数据结构,用于提高数据查询的效率。在MongoDB中,索引可以基于文档中的一个或多个字段创建,类似于关系型数据库中的索引。通过创建索引,可以加快对文档的查找、排序和分组操作。
- 操作相关关键字
db.collection_name.ensureIndex({field: direction}):用于在collection_name集合中基于field字段创建一个索引,direction可以是1(表示升序)或 -1(表示降序)。例如:db.users.ensureIndex({"name":1})会在users集合中基于name字段创建一个升序索引。创建索引可以提高对name字段的查询效率,例如在执行db.users.find({"name":"John"})查询时,如果有name索引,查询速度会更快。db.collection_name.getIndexes():用于获取collection_name集合中所有的索引列表。例如:db.users.getIndexes()会返回users集合中所有的索引信息,包括索引名称、基于的字段、排序方向等。db.collection_name.dropIndex("index_name"):用于删除collection_name集合中名为index_name的索引。例如:db.users.dropIndex("name_1")会删除users集合中基于name字段创建的名为name_1的索引。
5. 聚合(Aggregation)
- 概念
- 聚合是一种对数据进行处理和分析的操作,用于从多个文档中提取信息、进行计算和分组等。在MongoDB中,聚合操作是通过聚合管道(Aggregation Pipeline)来实现的,聚合管道是一系列的阶段(Stage)组成,每个阶段对输入的数据进行一种特定的操作,然后将结果传递给下一个阶段。
- 操作相关关键字
db.collection_name.aggregate(pipeline):用于在collection_name集合中执行聚合操作,pipeline是一个包含聚合阶段的数组。例如:db.users.aggregate([{"$match":{"age":30}},{"$group":{"_id":"$gender","count":{"$sum":1}}}])会先筛选出age为30的文档,然后根据gender字段进行分组,并计算每组的数量。这里的$match和$group是聚合管道中的两个常见阶段,$match用于筛选数据,$group用于分组数据。$sum、$avg、$max、$min、$push、$addToSet、$first、$last等:这些是聚合管道中常用的操作符,用于进行求和、求平均、求最大值、求最小值、将值推送到数组、将值添加到不重复数组、获取第一个文档的值、获取最后一个文档的值等操作。例如,在上述聚合操作中,$sum用于计算每组的数量。
6. 用户和权限(User and Permission)
- 概念
- MongoDB支持用户认证和权限管理,用户可以被赋予不同的角色和权限,以控制对数据库、集合和文档的访问。
- 操作相关关键字
use admin:用于切换到admin数据库,admin数据库是用于管理用户和权限的核心数据库。在创建用户、授予权限等操作时,通常需要先切换到admin数据库。db.createUser(user_document):用于在当前数据库(通常是admin数据库)中创建一个用户。user_document是一个包含用户信息的文档,包括用户名、密码、角色等。例如:db.createUser({"user":"john","pwd":"123456","roles":[{"role":"readWrite","db":"mydb"}]})会创建一个名为john的用户,密码为123456,并赋予其对mydb数据库的读写权限。db.auth(user_name, password):用于对用户进行认证,验证用户提供的用户名和密码是否正确。例如:db.auth("john","123456")会验证john用户的密码是否正确。如果认证成功,用户就可以根据其被赋予的权限访问相应的数据库、集合和文档。db.grantRolesToUser(user_name, roles):用于向用户授予角色。roles是一个包含角色信息的数组。例如:db.grantRolesToUser("john",[{"role":"readOnly","db":"mydb"}])会向john用户授予对mydb数据库的只读权限。db.revokeRolesFromUser(user_name, roles):用于从用户那里收回角色。例如:db.revokeRolesFromUser("john",[{"role":"readOnly","db":"mydb"}])会从john用户那里收回对mydb数据库的只读权限。
相关文章:

mongodb的相关关键字说明
以下是MongoDB中一些数据库相关的关键字说明: 1. 数据库(Database) 概念 数据库是MongoDB中数据存储的最高层级容器,类似于关系型数据库中的数据库概念。一个MongoDB服务器实例可以包含多个数据库,每个数据库可以有自…...
强化学习之DDPG算法
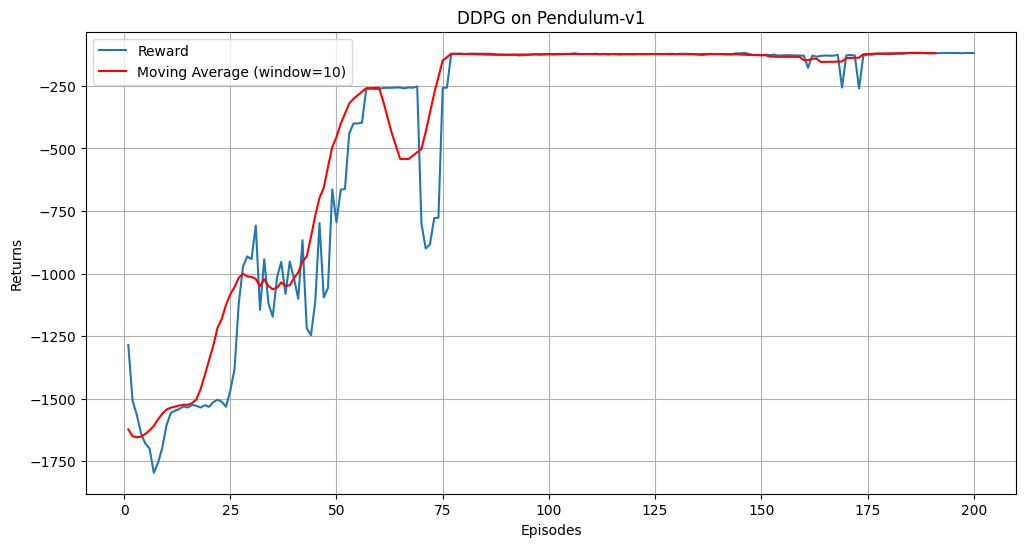
前言: 在正文开始之前,首先给大家介绍一个不错的人工智能学习教程:https://www.captainbed.cn/bbs。其中包含了机器学习、深度学习、强化学习等系列教程,感兴趣的读者可以自行查阅。 一、算法介绍 深度确定性策略梯度 ࿰…...

【进阶OpenCV】 (16)-- 人脸识别 -- FisherFaces算法
文章目录 FisherFaces算法一、算法原理二、算法优势与局限三、算法实现1. 图像预处理2. 创建FisherFace人脸特征识别器3. 训练模型4. 测试图像 总结 FisherFaces算法 PCA方法是EigenFaces人脸识别的核心,但是其具有明显的缺点,在操作过程中会损失许多人…...

电脑主机配置
显卡: 查看显卡:设备管理器--显示适配器 RTX4060 RTX和GTX区别: GTX是NVIDIA公司旧款显卡,RTX比GTX好但是贵 处理器CPU: Intel(R) Core(TM) i5-10400F CPU 2.90GHz 2.90 GHz 10400F:10指的是第几代…...
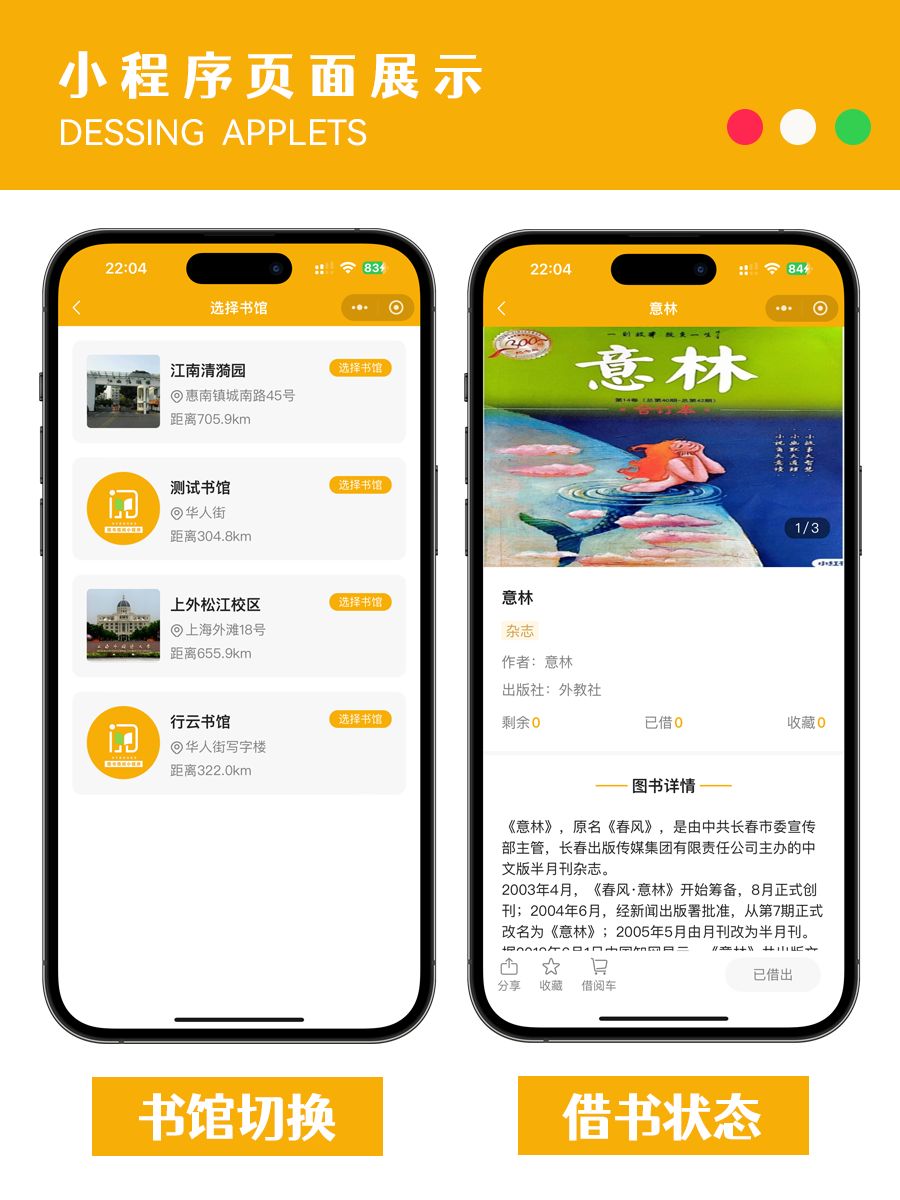
图书借阅小程序开源独立版
图书借阅微信小程序,多书馆切换模式,书馆一键同步图书信息,开通会员即可在线借书,一书一码书馆员工手机扫码出入库从会员到书馆每一步信息把控图书借阅小程序,让阅读触手可及在这个快节奏的时代,你是否渴望…...

flutter TextField限制中文,ios自带中文输入法变英文输入问题解决
由于业务需求,要限制TextField只能输入中文,但是测试在iOS测试机发现自带中文输入法会变英文输入问题,安卓没有问题,并且只有iOS自带输入法有问题,搜狗等输入法没问题。我们目前使用flutter2.5.3版本,高版本…...

ThreadLocal的应用场景
ThreadLocal介绍 ThreadLocal为每个线程都提供了变量的副本,使得每个线程访问各自独立的对象,这样就隔离了多个线程对数据的共享,使得线程安全。ThreadLocal有如下方法: 方法声明 描述public void set(T value)设置当前线程绑定的…...

Python--plt.errorbar学习笔记
plt.errorbar 是 Matplotlib 库中的一个函数,用于绘制带有误差条的图形。下面给出的代码行的详细解释: import numpy as np from scipy.special import kv, erfc from scipy.integrate import dblquad import matplotlib.pyplot as plt import scipy.in…...

文件信息类QFileInfo
常用方法: 构造函数 //参数:文件的绝对路径或相对路径 [explicit] QFileInfo::QFileInfo(const QString &path) 设置文件路径 可构造一个空的QFileInfo的对象,然后设置路径 //参数:文件的绝对路径或相对路径 void QFileI…...

堆排序(C++实现)
参考: 面试官:请写一个堆排序_哔哩哔哩_bilibiliC实现排序算法_c从小到大排序-CSDN博客 堆的基本概念 堆排实际上是利用堆的性质来进行排序。堆可以看做一颗完全二叉树。 堆分为两类: 最大堆(大顶堆):除根…...

Qt中加入UI文件
将 UI 文件整合到 Qt 项目 使用 Qt Designer 创建 UI 文件: 在 Qt Creator 中使用 Qt Designer 创建 UI 文件,设计所需的界面。确保在设计中包含所需的控件(如按钮、文本框等),并为每个控件设置明确的对象名称…...

Redisson使用全解
redisson使用全解——redisson官方文档注释(上篇)_redisson官网中文-CSDN博客 redisson使用全解——redisson官方文档注释(中篇)-CSDN博客 redisson使用全解——redisson官方文档注释(下篇)_redisson官网…...

Go4 和对 Go 的贡献
本篇内容是根据2017年4月份Go4 and Contributing to Go音频录制内容的整理与翻译, Brad Fitzpatrick 加入节目谈论成为开源 Go 的代言人、让社区参与 bug 分类、Go 的潜在未来以及其他有趣的 Go 项目和新闻。 过程中为符合中文惯用表达有适当删改, 版权归原作者所有. Erik St…...

区间动态规划
区间动态规划(Interval DP)是动态规划的一种重要变种,特别适用于解决一类具有区间性质的问题。典型的应用场景是给定一个区间,要求我们在满足某些条件下进行最优划分或合并。本文将从区间DP的基本思想、常见问题模型以及算法实现几…...

什么情况下需要使用电压探头
高压探头是一种专门设计用于测量高压电路或设备的探头,其作用是在电路测试和测量中提供安全、准确的信号捕获,并确保操作人员的安全。这些探头通常用于测量高压电源、变压器、电力系统、医疗设备以及其他需要处理高电压的设备或系统。 而高压差分探头差分…...
)
数据结构——八大排序(下)
数据结构中的八大排序算法是计算机科学领域经典的排序方法,它们各自具有不同的特点和适用场景。以下是这八大排序算法的详细介绍: 五、选择排序(Selection Sort) 核心思想:每一轮从未排序的元素中选择最小࿰…...

Linux系统:Ubuntu上安装Chrome浏览器
Ubuntu系统版本:23.04 在Ubuntu系统上安装Google Chrome浏览器,可以通过以下步骤进行: 终端输入以下命令,先更新软件源: sudo apt update 或 sudo apt upgrade终端输入以下命令,下载最新的Google Chrome .…...

Redis位图BitMap
一、为什么使用位图? 使用位图能有效实现 用户签到 等行为,用数据库表记录签到,将占用很多存储;但使用 位图BitMap,就能 大大减少存储占用 二、关于位图 本质上是String类型,最小长度8位(一个字…...

YOLOv11改进策略【卷积层】| ParNet 即插即用模块 二次创新C3k2
一、本文介绍 本文记录的是利用ParNet中的基础模块优化YOLOv11的目标检测网络模型。 ParNet block是一个即插即用模块,能够在不增加深度的情况下增加感受野,更好地处理图像中的不同尺度特征,有助于网络对输入数据更全面地理解和学习,从而提升网络的特征提取能力和分类性能…...

学习threejs,网格深度材质MeshDepthMaterial
👨⚕️ 主页: gis分享者 👨⚕️ 感谢各位大佬 点赞👍 收藏⭐ 留言📝 加关注✅! 👨⚕️ 收录于专栏:threejs gis工程师 文章目录 一、🍀前言1.1 ☘️网格深度材质MeshDepthMate…...

作业本耐用度差距巨大?深圳大明印刷厂拆解合规工艺,告别定制作业本掉页开裂通病
在校园日常教学中,很多学校都会遇到同一个难题:同一学期采购的作业本、定制作业本,品质差距悬殊,有的完好无损用到期末,有的短短几周就出现书脊开裂、页面脱落、边角破损、翻页卡顿等问题。不少人误以为是学生使用习惯…...

2026年一键生成论文工具对比实测:5款神器从选题到格式全流程护航
写论文的焦虑,是每个科研人和学生都心照不宣的“隐形压力”。选题无从下手,文献检索耗时费力,逻辑框架反复推翻,格式排版让人抓狂,查重降重更是像在和系统玩“猫鼠游戏”。2026年的AI工具早已不是过去那种“打字机”&a…...

Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题
Windows Cleaner深度解析:5大核心模块彻底解决系统空间不足问题 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner Windows Cleaner是一款完全免费开源的…...

WebSocket实时通信架构进阶:Room、命名空间与集群部署
WebSocket实时通信架构进阶:Room、命名空间与集群部署 作者:Crown_22 | AI Agent & Hermes Agent 桌面程序开发者 前言 WebSocket已经成为实时应用的标准技术,但大多数教程只停留在"建立连接、发送消息"的基础阶段。在生产环境中,你需要处理Room管理、命名空…...

phpMyAdmin CVE-2018-12613:从文件读取到RCE的伪协议利用链
1. 这个漏洞不是“能读文件”那么简单,而是后台权限的彻底失守phpMyAdmin 4.8.1里那个CVE-2018-12613,很多人扫到就报个“存在文件包含”,顺手贴个?targetphp://filter/convert.base64-encode/resource/etc/passwd截图完事。我去年在给一家教…...

通过curl命令快速测试Taotoken大模型API的连通性与返回格式
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 通过curl命令快速测试Taotoken大模型API的连通性与返回格式 在集成大模型能力到应用时,开发者通常需要一种快速、轻量的…...
用Azure Kinect DK和Body Tracking SDK,5分钟实现一个实时人体骨骼点检测Demo(C++版)
5分钟实战:用Azure Kinect DK实现实时人体骨骼点追踪(C版) 当你第一次拿到Azure Kinect DK时,最令人兴奋的莫过于它强大的人体追踪能力。这款深度相机不仅能捕捉高清彩色图像,更能通过AI算法实时重建人体骨骼关节点。本…...

解决方法:庐山派K230接串口没识别到端口问题
一、插入usb转串口工具之前二、插入usb转串口工具之后三、解决方法说明:🔍 核心原因:USB Serial 设备,没有被识别为 COM 口你现在看到的 USB Serial,说明开发板已经正常启动了,USB 也被电脑识别到了&#x…...

如何用HsMod解锁炉石传说60+项隐藏功能:终极优化指南
如何用HsMod解锁炉石传说60项隐藏功能:终极优化指南 【免费下载链接】HsMod Hearthstone Modification Based on BepInEx 项目地址: https://gitcode.com/GitHub_Trending/hs/HsMod HsMod是一款基于BepInEx开发的炉石传说功能增强插件,为玩家提供…...

用图神经网络做缺陷定位,准确率比传统方法高出30%
在现代软件工程的复杂迷宫中,缺陷定位始终是测试团队面临的核心挑战。想象这样一个场景:一个电商系统在特定压力条件下偶发订单丢失,日志中只留下泛泛的超时错误,问题可能深藏在上百个微服务的调用链、分布式事务的竞态条件或某个…...