C语言高效内存管理:对齐、缓存与位域
C语言高效内存管理:对齐、缓存与位域
一、内存对齐
1. 内存对齐的概念
内存对齐(Memory Alignment)是指数据在内存中存储时,其起始地址遵循特定的规则,使得数据能够被高效地访问。CPU通常以固定的字节数(对齐边界)读取内存数据,未对齐的数据访问可能导致性能下降或硬件异常。
- 对齐边界:数据类型的大小通常决定了其对齐边界。例如,4字节(32位)的
float通常要求4字节对齐,8字节(64位)的double要求8字节对齐。
2. 内存对齐的目的
-
提高访问效率:
- 快速访问:对齐的数据可以在单个内存访问周期内被CPU读取,而未对齐的数据可能需要多个访问周期。
- 减少CPU周期:对齐访问减少了CPU等待数据的时间,提升了指令执行效率。
-
避免硬件异常:
- 某些架构的要求:例如,某些RISC架构(如ARM)对数据对齐有严格要求,未对齐访问可能导致程序崩溃或产生未定义行为。
-
优化内存带宽:
- 高效利用带宽:对齐的数据可以更好地利用内存带宽,减少不必要的数据传输。
3. 内存对齐规则
在C语言中,内存对齐遵循以下基本规则:
-
基础对齐规则:
- 每个数据类型的对齐边界通常等于其大小。例如:
char:1字节对齐。short:2字节对齐。int、float:4字节对齐。double、long long:8字节对齐。
- 每个数据类型的对齐边界通常等于其大小。例如:
-
结构体对齐规则:
- 成员对齐:结构体的每个成员按照其自身的对齐要求存储。
- 结构体对齐:整个结构体的对齐要求是其最大成员对齐要求的倍数。
- 填充字节:为了满足对齐要求,编译器可能在结构体成员之间或末尾插入填充字节。
4. 内存对齐示例分析
示例1:单精度浮点数(float)的对齐
#include <stdio.h>struct FloatExample {char a; // 1字节float b; // 4字节
};int main() {struct FloatExample example;printf("结构体大小:%zu 字节\n", sizeof(example));return 0;
}
分析:
- 成员
a:1字节,起始地址偏移量为0。 - 成员
b:4字节,对齐到4字节边界,因此需要填充3个字节。 - 结构体大小:
a(1字节) + 填充(3字节) +b(4字节) = 8字节。
输出:
结构体大小:8 字节
示例2:双精度浮点数(double)的对齐
#include <stdio.h>struct DoubleExample {char a; // 1字节double b; // 8字节
};int main() {struct DoubleExample example;printf("结构体大小:%zu 字节\n", sizeof(example));return 0;
}
分析:
- 成员
a:1字节,起始地址偏移量为0。 - 成员
b:8字节,对齐到8字节边界,需要填充7个字节。 - 结构体大小:
a(1字节) + 填充(7字节) +b(8字节) = 16字节。
输出:
结构体大小:16 字节
示例3: 结构体成员的重新排列以减少填充
通过合理排列结构体成员的顺序,可以减少填充字节,优化内存使用和访问效率。
原始结构体
struct MixedStruct {char a; // 1字节int b; // 4字节char c; // 1字节double d; // 8字节
};
分析:
- 成员
a:1字节,偏移量0。 - 填充:3字节,使
b对齐到4字节边界。 - 成员
b:4字节,偏移量4。 - 成员
c:1字节,偏移量8。 - 填充:7字节,使
d对齐到8字节边界。 - 成员
d:8字节,偏移量16。 - 结构体大小:1 + 3 + 4 + 1 + 7 + 8 = 24字节。
优化后的结构体
struct OptimizedMixedStruct {double d; // 8字节int b; // 4字节char a; // 1字节char c; // 1字节// 填充:2字节
};
分析:
- 成员
d:8字节,偏移量0。 - 成员
b:4字节,偏移量8。 - 成员
a:1字节,偏移量12。 - 成员
c:1字节,偏移量13。 - 填充:2字节,使结构体大小为8字节的倍数。
- 结构体大小:8 + 4 + 1 + 1 + 2 = 16字节。
输出:
#include <stdio.h>struct OptimizedMixedStruct {double d; // 8字节int b; // 4字节char a; // 1字节char c; // 1字节// 填充:2字节
};int main() {struct OptimizedMixedStruct example;printf("优化后的结构体大小:%zu 字节\n", sizeof(example));return 0;
}
输出:
优化后的结构体大小:16 字节
5. 强制内存对齐
在某些情况下,开发者可能需要改变默认的内存对齐方式。C语言提供了多种方式来实现这一点:
-
#pragma pack指令:-
用于指定结构体的对齐边界。
-
语法:
#pragma pack(n) // 设置对齐边界为n字节 -
示例:
#include <stdio.h>#pragma pack(1) // 设置1字节对齐struct PackedExample {char a; // 1字节int b; // 4字节 };#pragma pack() // 恢复默认对齐int main() {struct PackedExample example;printf("结构体大小(1字节对齐):%zu 字节\n", sizeof(example));return 0; } -
输出:
结构体大小(1字节对齐):5 字节 -
注意:降低对齐边界可能导致性能下降,应谨慎使用。
-
-
GCC的
__attribute__((aligned(n))):-
用于指定变量或结构体的对齐方式。
-
语法:
struct Example {char a;int b; } __attribute__((aligned(8))); -
示例:
#include <stdio.h>struct __attribute__((aligned(8))) AlignedExample {char a; // 1字节int b; // 4字节 };int main() {struct AlignedExample example;printf("结构体大小(8字节对齐):%zu 字节\n", sizeof(example));return 0; } -
输出:
结构体大小(8字节对齐):8 字节
-
-
C11标准的
_Alignas关键字:-
用于指定类型的对齐要求。
-
语法:
#include <stdalign.h>struct Example {char a;int b; } _Alignas(8); -
示例:
#include <stdio.h> #include <stdalign.h>struct Example {char a;int b; } _Alignas(8);int main() {struct Example example;printf("结构体大小(8字节对齐):%zu 字节\n", sizeof(example));return 0; } -
输出:
结构体大小(8字节对齐):8 字节
-
二、缓存优化
现代计算机系统采用**缓存(Cache)**来加速内存访问。缓存是一种高速存储器,位于CPU和主内存之间,存储最近或频繁访问的数据。合理的缓存优化策略能够显著提升程序性能。
1. 缓存的基本概念
-
缓存层次:
-
L1缓存:最接近CPU,速度最快,容量最小(通常32KB)。
-
L2缓存:稍慢,容量较大(通常256KB)。
-
L3缓存:更大但更慢(通常几MB)。
-
主内存(RAM):速度最慢,容量最大。
-
-
缓存行(Cache Line):
-
定义:缓存中的数据块,通常为64字节。
-
加载方式:当CPU访问某个内存地址时,整个缓存行被加载到缓存中。
-
-
空间局部性:
-
概念:如果一个内存地址被访问,附近的地址很可能也会被访问。
-
利用方式:通过连续存储数据,提升缓存命中率。
-
-
时间局部性:
-
概念:如果一个内存地址被访问,短时间内再次访问的概率较高。
-
利用方式:通过缓存保留最近访问的数据,减少重复访问主内存。
-
2. 连续存储与缓存行利用
连续存储指的是数组或结构体成员按顺序连续存放在内存中。这种存储方式能够充分利用空间局部性,提升缓存命中率。
示例:
#include <stdio.h>#define ARRAY_SIZE 1000000int main() {float arr[ARRAY_SIZE];float sum = 0.0f;// 初始化数组for (int i = 0; i < ARRAY_SIZE; i++) {arr[i] = (float)i;}// 计算数组元素的和for (int i = 0; i < ARRAY_SIZE; i++) {sum += arr[i];}printf("数组元素的和:%f\n", sum);return 0;
}
分析:
- 连续访问:数组
arr中的元素连续存储,CPU在访问arr[i]时,整个缓存行(包含多个连续元素)被加载到缓存中。 - 缓存命中率高:由于数组元素连续访问,后续的
arr[i+1]、arr[i+2]等访问会命中已加载的缓存行,减少了主内存访问次数。
3. 避免伪共享(False Sharing)
伪共享是指多个线程频繁访问位于同一缓存行的不同变量,导致缓存一致性协议频繁触发,从而降低性能。这种现象在多线程编程中尤为常见。
原因:
- 共享缓存行:当多个变量位于同一缓存行时,一个线程对其中一个变量的修改会导致整个缓存行被无效化,其他线程需要重新加载缓存行。
解决方法:
-
结构体填充:
- 在结构体中插入填充字节,使得不同线程操作的变量位于不同的缓存行。
示例:
#include <stdio.h> #include <pthread.h> #include <unistd.h>#define CACHE_LINE_SIZE 64struct PaddedCounter {volatile int counter;char padding[CACHE_LINE_SIZE - sizeof(int)]; };struct PaddedCounter counters[2];void* increment(void* arg) {for (int i = 0; i < 1000000; i++) {counters[*(int*)arg].counter++;}return NULL; }int main() {pthread_t threads[2];int ids[2] = {0, 1};// 创建两个线程,分别操作不同的计数器pthread_create(&threads[0], NULL, increment, &ids[0]);pthread_create(&threads[1], NULL, increment, &ids[1]);// 等待线程结束pthread_join(threads[0], NULL);pthread_join(threads[1], NULL);printf("Counter 0: %d\n", counters[0].counter);printf("Counter 1: %d\n", counters[1].counter);return 0; }分析:
- 结构体
PaddedCounter:包含一个int类型的计数器和一个填充数组,使得每个PaddedCounter实例占用整个缓存行(64字节)。 - 多线程操作:每个线程操作不同的
counter,位于不同的缓存行,避免了伪共享。
-
数组分割:
- 将需要并行访问的变量分布到不同的数组元素中,每个元素间隔足够的空间,确保位于不同的缓存行。
示例:
#include <stdio.h> #include <pthread.h> #include <unistd.h>#define CACHE_LINE_SIZE 64 #define NUM_COUNTERS 2volatile int counters[NUM_COUNTERS]; char padding[NUM_COUNTERS][CACHE_LINE_SIZE - sizeof(int)];void* increment(void* arg) {int id = *(int*)arg;for (int i = 0; i < 1000000; i++) {counters[id]++;}return NULL; }int main() {pthread_t threads[NUM_COUNTERS];int ids[NUM_COUNTERS] = {0, 1};// 创建线程for (int i = 0; i < NUM_COUNTERS; i++) {pthread_create(&threads[i], NULL, increment, &ids[i]);}// 等待线程结束for (int i = 0; i < NUM_COUNTERS; i++) {pthread_join(threads[i], NULL);}// 打印结果for (int i = 0; i < NUM_COUNTERS; i++) {printf("Counter %d: %d\n", i, counters[i]);}return 0; }分析:
- 数组
counters:存储需要计数的变量。 - 数组
padding:为每个counter添加填充,确保它们位于不同的缓存行。 - 多线程操作:每个线程操作不同的
counter,位于不同的缓存行,避免伪共享。
4. 内存布局优化
优化浮点数的内存布局可以进一步提升缓存利用率和程序性能。以下是一些常见的优化策略:
-
数据结构优化:
- 紧凑结构:将相关的浮点数紧密排列,减少填充字节。
- 按访问频率排序:将高频访问的数据放在结构体的前面,优化缓存行利用。
示例:
#include <stdio.h>struct OptimizedStruct {float x; // 4字节float y; // 4字节float z; // 4字节 };int main() {struct OptimizedStruct point;printf("结构体大小:%zu 字节\n", sizeof(point));return 0; }输出:
结构体大小:12 字节分析:
- 紧凑排列:
x、y、z连续存储,无需填充字节。 - 缓存友好:连续访问时,多个成员位于同一缓存行,提高缓存命中率。
-
结构体对齐与填充的平衡:
- 合理对齐:确保数据对齐要求,同时尽量减少填充字节。
- 使用对齐属性:根据需要调整结构体成员的对齐方式。
示例:
#include <stdio.h>struct MixedStruct {char a; // 1字节float b; // 4字节char c; // 1字节double d; // 8字节 };int main() {struct MixedStruct example;printf("结构体大小:%zu 字节\n", sizeof(example));return 0; }输出(可能因编译器和平台而异):
结构体大小:24 字节分析:
- 默认对齐:
a:1字节- 填充:3字节(使
b按4字节对齐) b:4字节c:1字节- 填充:7字节(使
d按8字节对齐) d:8字节
- 总大小:1 + 3 + 4 + 1 + 7 + 8 = 24字节
优化:
-
重新排列成员:
struct OptimizedMixedStruct {double d; // 8字节float b; // 4字节char a; // 1字节char c; // 1字节// 填充:2字节 }; -
分析:
d:8字节,起始地址偏移量0。b:4字节,起始地址偏移量8。a:1字节,起始地址偏移量12。c:1字节,起始地址偏移量13。- 填充:2字节,确保结构体大小为8字节的倍数。
-
总大小:8 + 4 + 1 + 1 + 2 = 16字节
-
输出:
#include <stdio.h>struct OptimizedMixedStruct {double d; // 8字节float b; // 4字节char a; // 1字节char c; // 1字节// 填充:2字节 };int main() {struct OptimizedMixedStruct example;printf("优化后的结构体大小:%zu 字节\n", sizeof(example));return 0; } -
输出:
优化后的结构体大小:16 字节
结论:通过重新排列结构体成员,可以减少填充字节,优化内存使用和缓存利用率。
5. 缓存一致性与多线程编程
在多线程编程中,缓存一致性(Cache Coherency)是确保多个线程看到一致的数据视图的重要机制。合理的内存布局和对齐策略能够减少缓存一致性协议带来的开销。
伪共享的影响
伪共享(False Sharing)发生在多个线程频繁访问位于同一缓存行的不同变量时,即使这些变量彼此独立,也会因缓存行被频繁无效化和重新加载而导致性能下降。
示例:
#include <stdio.h>
#include <pthread.h>
#include <unistd.h>#define NUM_THREADS 2volatile int counter1 = 0;
volatile int counter2 = 0;void* increment_counter1(void* arg) {for (int i = 0; i < 1000000; i++) {counter1++;}return NULL;
}void* increment_counter2(void* arg) {for (int i = 0; i < 1000000; i++) {counter2++;}return NULL;
}int main() {pthread_t threads[NUM_THREADS];// 创建两个线程,分别操作counter1和counter2pthread_create(&threads[0], NULL, increment_counter1, NULL);pthread_create(&threads[1], NULL, increment_counter2, NULL);// 等待线程结束pthread_join(threads[0], NULL);pthread_join(threads[1], NULL);printf("Counter1: %d\n", counter1);printf("Counter2: %d\n", counter2);return 0;
}
分析:
- 变量
counter1和counter2:通常位于同一缓存行,导致两个线程频繁竞争缓存一致性。 - 性能影响:由于伪共享,两个线程无法有效并行,导致性能下降。
解决伪共享的方法
-
使用填充字节:
- 在变量之间插入填充字节,使其位于不同的缓存行。
示例:
#include <stdio.h> #include <pthread.h> #include <unistd.h>#define NUM_THREADS 2 #define CACHE_LINE_SIZE 64struct PaddedCounter {volatile int counter;// 定义填充数组char padding[CACHE_LINE_SIZE - sizeof(int)]; };struct PaddedCounter counters[NUM_THREADS];void* increment_counter(void* arg) {int id = *(int*)arg;for (int i = 0; i < 1000000; i++) {counters[id].counter++;}return NULL; }int main() {pthread_t threads[NUM_THREADS];int ids[NUM_THREADS] = {0, 1};// 创建线程,分别操作不同的计数器pthread_create(&threads[0], NULL, increment_counter, &ids[0]);pthread_create(&threads[1], NULL, increment_counter, &ids[1]);// 等待线程结束pthread_join(threads[0], NULL);pthread_join(threads[1], NULL);printf("Counter1: %d\n", counters[0].counter);printf("Counter2: %d\n", counters[1].counter);return 0; }分析:
- 结构体
PaddedCounter:包含一个counter和填充字节,确保每个counter位于不同的缓存行。 - 性能提升:消除伪共享,允许线程独立操作各自的
counter,提高并行性能。
-
使用数组对齐属性:
- 通过数组对齐属性,将数组元素对齐到缓存行边界。
示例:
#include <stdio.h> #include <pthread.h> #include <unistd.h>#define NUM_THREADS 2 #define CACHE_LINE_SIZE 64typedef struct {volatile int counter;char padding[CACHE_LINE_SIZE - sizeof(int)]; } __attribute__((aligned(CACHE_LINE_SIZE))) PaddedCounter;PaddedCounter counters[NUM_THREADS];void* increment_counter(void* arg) {int id = *(int*)arg;for (int i = 0; i < 1000000; i++) {counters[id].counter++;}return NULL; }int main() {pthread_t threads[NUM_THREADS];int ids[NUM_THREADS] = {0, 1};// 创建线程,分别操作不同的计数器pthread_create(&threads[0], NULL, increment_counter, &ids[0]);pthread_create(&threads[1], NULL, increment_counter, &ids[1]);// 等待线程结束pthread_join(threads[0], NULL);pthread_join(threads[1], NULL);printf("Counter1: %d\n", counters[0].counter);printf("Counter2: %d\n", counters[1].counter);return 0; }分析:
- 类型定义:
PaddedCounter结构体使用__attribute__((aligned(CACHE_LINE_SIZE)))确保每个实例对齐到缓存行边界。 - 性能提升:避免伪共享,允许线程独立操作各自的
counter,提升并行效率。
6. 浮点数的缓存友好访问模式
为了充分利用缓存的高效访问特性,可以采用以下策略优化浮点数的访问模式:
-
顺序访问:
- 定义:按顺序访问数组或结构体中的浮点数。
- 优势:利用空间局部性,提升缓存命中率。
示例:
#include <stdio.h> #include <time.h>#define ARRAY_SIZE 1000000int main() {float arr[ARRAY_SIZE];clock_t start, end;float sum = 0.0f;// 初始化数组for (int i = 0; i < ARRAY_SIZE; i++) {arr[i] = (float)i;}// 顺序访问start = clock();for (int i = 0; i < ARRAY_SIZE; i++) {sum += arr[i];}end = clock();printf("Sum: %f, Time: %f seconds\n", sum, (double)(end - start) / CLOCKS_PER_SEC);return 0; }分析:
- 顺序访问:浮点数数组按顺序访问,充分利用缓存预取机制,减少缓存未命中次数。
- 性能:顺序访问通常比随机访问更快。
-
避免随机访问:
- 定义:随机访问数组或结构体中的浮点数。
- 劣势:降低缓存命中率,增加缓存未命中次数。
示例:
#include <stdio.h> #include <time.h> #include <stdlib.h>#define ARRAY_SIZE 1000000int main() {float arr[ARRAY_SIZE];clock_t start, end;float sum = 0.0f;// 初始化数组for (int i = 0; i < ARRAY_SIZE; i++) {arr[i] = (float)i;}// 随机访问start = clock();for (int i = 0; i < ARRAY_SIZE; i++) {int index = rand() % ARRAY_SIZE;sum += arr[index];}end = clock();printf("Sum: %f, Time: %f seconds\n", sum, (double)(end - start) / CLOCKS_PER_SEC);return 0; }分析:
- 随机访问:浮点数数组以随机顺序访问,无法有效利用缓存行,导致大量缓存未命中。
- 性能:随机访问通常比顺序访问慢得多。
7. 使用SIMD指令进行向量化
SIMD(Single Instruction, Multiple Data)指令允许CPU同时处理多个数据元素,显著提升浮点数运算的并行度和性能。
SIMD简介
- 定义:SIMD是一种并行计算技术,通过单条指令同时对多个数据元素进行相同的操作。
- 指令集:如Intel的SSE(Streaming SIMD Extensions)和AVX(Advanced Vector Extensions)、ARM的NEON等。
向量化示例
示例:使用SSE指令进行浮点数数组的向量化加法。
#include <stdio.h>
#include <xmmintrin.h> // SSE指令集#define ARRAY_SIZE 8int main() {float a[ARRAY_SIZE] = {1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0};float b[ARRAY_SIZE] = {8.0, 7.0, 6.0, 5.0, 4.0, 3.0, 2.0, 1.0};float result[ARRAY_SIZE];// 加载浮点数到SSE寄存器__m128 vec_a1 = _mm_loadu_ps(&a[0]); // 加载a[0]到a[3]__m128 vec_a2 = _mm_loadu_ps(&a[4]); // 加载a[4]到a[7]__m128 vec_b1 = _mm_loadu_ps(&b[0]); // 加载b[0]到b[3]__m128 vec_b2 = _mm_loadu_ps(&b[4]); // 加载b[4]到b[7]// SIMD加法__m128 vec_result1 = _mm_add_ps(vec_a1, vec_b1);__m128 vec_result2 = _mm_add_ps(vec_a2, vec_b2);// 存储结果_mm_storeu_ps(&result[0], vec_result1);_mm_storeu_ps(&result[4], vec_result2);// 打印结果printf("结果数组:\n");for (int i = 0; i < ARRAY_SIZE; i++) {printf("%f ", result[i]);}printf("\n");return 0;
}
输出:
结果数组:
9.000000 9.000000 9.000000 9.000000 9.000000 9.000000 9.000000 9.000000
分析:
- 加载数据:使用
_mm_loadu_ps加载4个float数据到SSE寄存器。 - SIMD加法:使用
_mm_add_ps对两个SSE寄存器中的数据进行并行加法。 - 存储结果:使用
_mm_storeu_ps将结果存储回内存。 - 性能提升:通过SIMD指令,一条指令完成4次浮点数加法,提升了计算效率。
优化浮点数运算的注意事项
-
内存对齐:
- 对齐要求:某些SIMD指令要求数据对齐到特定边界(如16字节对齐)。
- 使用对齐加载指令:如
_mm_load_ps要求数据对齐,而_mm_loadu_ps不要求对齐,但可能略慢。
-
数据布局:
- AoS(Array of Structures)与SoA(Structure of Arrays):
- AoS:数据按结构体排列,适合需要访问单个结构体成员的场景。
- SoA:数据按成员分别排列,适合需要批量处理某一成员的场景,更适合向量化处理。
示例:
#include <stdio.h> #include <xmmintrin.h> // SSE指令集#define NUM_ELEMENTS 8// AoS(Array of Structures) typedef struct {float x;float y;float z; } Vec3;// SoA(Structure of Arrays) typedef struct {float x[NUM_ELEMENTS];float y[NUM_ELEMENTS];float z[NUM_ELEMENTS]; } Vec3_SoA;int main() {Vec3_SoA vectors;for (int i = 0; i < NUM_ELEMENTS; i++) {vectors.x[i] = (float)i;vectors.y[i] = (float)(i * 2);vectors.z[i] = (float)(i * 3);}// SIMD处理x组件__m128 vec_x1 = _mm_loadu_ps(&vectors.x[0]); // 加载x[0]-x[3]__m128 vec_x2 = _mm_loadu_ps(&vectors.x[4]); // 加载x[4]-x[7]// SIMD乘法__m128 vec_x_result1 = _mm_mul_ps(vec_x1, _mm_set1_ps(2.0f));__m128 vec_x_result2 = _mm_mul_ps(vec_x2, _mm_set1_ps(2.0f));// 存储结果_mm_storeu_ps(&vectors.x[0], vec_x_result1);_mm_storeu_ps(&vectors.x[4], vec_x_result2);// 打印结果printf("优化后的x组件:\n");for (int i = 0; i < NUM_ELEMENTS; i++) {printf("%f ", vectors.x[i]);}printf("\n");return 0; }输出:
优化后的x组件: 0.000000 2.000000 4.000000 6.000000 8.000000 10.000000 12.000000 14.000000分析:
- SoA布局:将所有
x组件连续存储,适合批量处理x。 - 向量化优势:能够一次性处理多个
x组件,提升计算效率。
- AoS(Array of Structures)与SoA(Structure of Arrays):
-
避免分支:
- 分支预测:分支指令可能导致流水线停顿,影响SIMD指令的效率。
- 策略:尽量减少循环中的条件分支,采用数据驱动的编程方式。
-
循环展开:
- 定义:通过增加每次迭代处理的数据量,减少循环控制开销。
- 优势:提升指令级并行度,增强向量化效果。
示例:
#include <stdio.h> #include <xmmintrin.h>#define ARRAY_SIZE 8int main() {float a[ARRAY_SIZE] = {1.0, 2.0, 3.0, 4.0, 5.0, 6.0, 7.0, 8.0};float b[ARRAY_SIZE] = {8.0, 7.0, 6.0, 5.0, 4.0, 3.0, 2.0, 1.0};float result[ARRAY_SIZE];// 循环展开for (int i = 0; i < ARRAY_SIZE; i += 4) {__m128 vec_a = _mm_loadu_ps(&a[i]);__m128 vec_b = _mm_loadu_ps(&b[i]);__m128 vec_result = _mm_add_ps(vec_a, vec_b);_mm_storeu_ps(&result[i], vec_result);}// 打印结果printf("结果数组:\n");for (int i = 0; i < ARRAY_SIZE; i++) {printf("%f ", result[i]);}printf("\n");return 0; }输出:
结果数组: 9.000000 9.000000 9.000000 9.000000 9.000000 9.000000 9.000000 9.000000分析:
- 循环展开:每次循环处理4个浮点数,充分利用SIMD指令的并行处理能力。
- 性能提升:减少了循环控制开销,提升了数据处理速度。
8. 实践中的缓存优化策略
-
数据局部性优化:
- 空间局部性:将相关数据紧密存储,增强缓存行利用率。
- 时间局部性:重复访问的数据应尽量保留在缓存中。
-
数据对齐:
- 对齐数据:确保数据按照其对齐边界存储,提升访问效率。
- 使用对齐指令:如SSE的
_mm_load_ps要求16字节对齐,可以使用对齐指令加载数据。
-
优化数据结构:
- 结构体成员排序:将高频访问的成员放在前面,减少填充字节。
- 使用SoA布局:在需要批量处理某一成员时,采用结构体数组的结构布局。
-
利用向量化指令:
- 批量处理:使用SIMD指令一次处理多个数据,提升并行度。
- 循环展开:通过增加每次迭代处理的数据量,增强指令并行性。
-
避免频繁的内存分配:
- 预分配内存:在需要大量浮点数时,预先分配足够的内存,避免频繁调用
malloc导致的内存碎片和缓存未命中。
- 预分配内存:在需要大量浮点数时,预先分配足够的内存,避免频繁调用
-
缓存预取:
- 手动预取:在某些高级优化中,可以使用预取指令(如
_mm_prefetch)提前加载数据到缓存中。 - 编译器优化:现代编译器通常会自动进行缓存预取优化,开发者应避免阻碍编译器优化。
- 手动预取:在某些高级优化中,可以使用预取指令(如
9. 性能测量与优化验证
在进行缓存优化后,验证优化效果至关重要。可以通过以下方法测量和验证优化效果:
-
使用计时函数:
clock():简单的CPU时间测量。gettimeofday():高精度的时间测量。- 性能计数器:如
rdtsc指令获取CPU周期数。
示例:
#include <stdio.h> #include <time.h>#define ARRAY_SIZE 1000000int main() {float arr[ARRAY_SIZE];float sum = 0.0f;clock_t start, end;// 初始化数组for (int i = 0; i < ARRAY_SIZE; i++) {arr[i] = (float)i;}// 计时开始start = clock();for (int i = 0; i < ARRAY_SIZE; i++) {sum += arr[i];}// 计时结束end = clock();double time_spent = (double)(end - start) / CLOCKS_PER_SEC;printf("Sum: %f, Time: %f seconds\n", sum, time_spent);return 0; } -
使用性能分析工具:
gprof:GNU Profiler,用于分析程序的执行时间分布。- Valgrind的
cachegrind:模拟CPU缓存行为,分析缓存命中率。 - Intel VTune:高级性能分析工具,提供详细的缓存访问统计。
使用
cachegrind的示例:gcc -O2 -o optimized_program optimized_program.c valgrind --tool=cachegrind ./optimized_program分析输出:
Events (Ir, I1mr, I1mw, D1mr, D1mw, D1mwr):Ir: Instructions readI1mr: Level 1 instruction cache missesI1mw: Level 1 instruction cache writesD1mr: Level 1 data cache misses readD1mw: Level 1 data cache misses writeD1mwr: Level 1 data cache misses read + write结论:
- 缓存命中率高:优化后的程序应减少缓存未命中次数,提升缓存命中率。
- 指令和数据访问优化:减少冗余的指令和数据访问,提升执行效率。
三、综合示例:内存对齐与缓存优化
以下是一个综合示例,展示如何通过内存对齐和缓存优化提升浮点数运算的性能。
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <xmmintrin.h> // SSE指令集#define ARRAY_SIZE 1000000
#define CACHE_LINE_SIZE 64// 使用结构体填充避免伪共享
typedef struct {float x;char padding[CACHE_LINE_SIZE - sizeof(float)];
} AlignedFloat;int main() {// 动态分配对齐内存AlignedFloat *arr = aligned_alloc(CACHE_LINE_SIZE, ARRAY_SIZE * sizeof(AlignedFloat));if (!arr) {perror("aligned_alloc failed");return EXIT_FAILURE;}// 初始化数组for (int i = 0; i < ARRAY_SIZE; i++) {arr[i].x = (float)i;}float sum = 0.0f;clock_t start, end;// 使用SIMD指令进行向量化加法start = clock();for (int i = 0; i < ARRAY_SIZE; i += 4) {__m128 vec = _mm_load_ps(&arr[i].x); // 16字节对齐加载__m128 vec_sum = _mm_add_ps(vec, _mm_setzero_ps()); // 简单加法// 将向量寄存器的值累加到sum(非优化方式)float temp[4];_mm_store_ps(temp, vec_sum);sum += temp[0] + temp[1] + temp[2] + temp[3];}end = clock();double time_spent = (double)(end - start) / CLOCKS_PER_SEC;printf("Sum: %f, Time with SIMD: %f seconds\n", sum, time_spent);// 释放内存free(arr);// 非优化的浮点数加法float *arr_naive = malloc(ARRAY_SIZE * sizeof(float));if (!arr_naive) {perror("malloc failed");return EXIT_FAILURE;}// 初始化数组for (int i = 0; i < ARRAY_SIZE; i++) {arr_naive[i] = (float)i;}sum = 0.0f;start = clock();for (int i = 0; i < ARRAY_SIZE; i++) {sum += arr_naive[i];}end = clock();time_spent = (double)(end - start) / CLOCKS_PER_SEC;printf("Sum: %f, Time without SIMD: %f seconds\n", sum, time_spent);free(arr_naive);return 0;
}
分析:
-
内存对齐:
- 使用
aligned_alloc函数以CACHE_LINE_SIZE(64字节)对齐分配内存,确保数据加载指令可以高效执行。 - 结构体
AlignedFloat包含一个float和填充字节,避免伪共享。
- 使用
-
向量化加法:
- 使用SSE指令加载4个连续的
float数据到SSE寄存器。 - 使用
_mm_add_ps进行向量化加法。 - 将向量寄存器的结果存储回内存,并累加到
sum。
- 使用SSE指令加载4个连续的
-
性能测量:
- 测量向量化加法和非优化加法的时间差异,验证优化效果。
注意:
- 编译器优化:使用高优化级别(如
-O3)编译程序,允许编译器自动进行向量化和其他优化。 - 硬件支持:确保目标硬件支持SSE指令集,否则可能导致程序崩溃或性能不佳。
- 内存分配:使用
aligned_alloc或其他对齐内存分配方法,确保数据对齐要求得到满足。
示例输出:
Sum: 499999500000.000000, Time with SIMD: 0.050000 seconds
Sum: 499999500000.000000, Time without SIMD: 0.100000 seconds
结论:
- 向量化加法:通过SIMD指令实现向量化加法,显著提升了浮点数运算的性能。
- 内存对齐:合理的内存对齐策略确保了数据能够高效加载到CPU寄存器中,进一步提升了性能。
- 缓存优化:避免伪共享和优化数据布局,减少了缓存一致性开销,提升了多线程环境下的程序性能。
四、位域(Bit Fields)
1. 位域的定义
位域(Bit Fields)允许在结构体中以位为单位定义成员,节省内存空间,适用于存储标志位、状态位等需要精确控制位数的数据。
2. 位域的用途
- 节省内存:在内存受限的系统中,通过位域减少数据结构的大小。
- 控制硬件寄存器:用于直接操作硬件寄存器的特定位。
- 高效存储标志:存储多个布尔标志或小范围整数。
3. 位域的语法
位域在结构体中定义时,需要指定每个成员所占的位数:
struct BitField {unsigned int a : 3; // 占3位unsigned int b : 5; // 占5位unsigned int c : 24; // 占24位
};
4. 位域的存储方式
位域成员的存储顺序和对齐方式依赖于编译器的实现,通常以下列方式存储:
- 从低位到高位:位域成员从结构体的最低位开始存储。
- 不跨越基本类型边界:位域不能跨越其基础类型(如
unsigned int)的边界。
示例:位域的内存布局
#include <stdio.h>struct BitField {unsigned int a : 3; // 占3位unsigned int b : 5; // 占5位unsigned int c : 24; // 占24位
};int main() {struct BitField bf;printf("结构体大小:%zu 字节\n", sizeof(bf));return 0;
}
输出(通常):
结构体大小:4 字节
分析:
- 成员
a:3位 - 成员
b:5位 - 成员
c:24位 - 总位数:3 + 5 + 24 = 32位 = 4字节
5. 位域的优缺点
优点:
- 节省内存:在存储多个小范围数据时显著减少内存占用。
- 方便位操作:简化位操作的代码编写,提升代码可读性。
缺点:
- 移植性差:不同编译器和平台对位域的实现可能不同,导致数据布局不一致。
- 访问效率:频繁访问位域可能导致更多的位操作,影响性能。
- 无法取地址:位域成员不能直接获取其地址,限制了指针操作。
6. 位域的示例
示例1:存储多个标志位
#include <stdio.h>struct Flags {unsigned int is_visible : 1;unsigned int is_active : 1;unsigned int has_error : 1;unsigned int reserved : 29;
};int main() {struct Flags flags = {1, 0, 1, 0};printf("结构体大小:%zu 字节\n", sizeof(flags));printf("is_visible: %u\n", flags.is_visible);printf("is_active: %u\n", flags.is_active);printf("has_error: %u\n", flags.has_error);return 0;
}
输出:
结构体大小:4 字节
is_visible: 1
is_active: 0
has_error: 1
分析:
- 成员
is_visible、is_active、has_error:各占1位。 - 成员
reserved:占29位,用于填充或未来扩展。 - 总位数:1 + 1 + 1 + 29 = 32位 = 4字节。
五、内存模型与布局
1. C语言的内存模型
C语言的内存模型描述了程序在运行时如何组织和管理内存。主要包括以下几个区域:
-
栈区 (Stack Segment):
- 栈区是函数调用时分配局部变量和保存函数调用信息的地方。
- 栈的增长方向通常是从高地址向低地址增长(与实现有关)。
- 栈区内存分配速度快,但容量有限,通常在程序退出时由系统自动回收。
-
堆区 (Heap Segment):
-
堆区用于动态内存分配,程序员通过 malloc()、calloc()、realloc() 分配,使用 free() 释放。
-
堆的增长方向通常是从低地址向高地址增长。
-
由于堆内存需要程序员手动管理,所以容易发生内存泄漏和碎片化问题。
-
-
数据段 (Data Segment):
-
数据段包括全局变量和静态变量,它们的生命周期贯穿整个程序执行过程。
-
数据段又可细分为两部分:
-
已初始化数据段 (Initialized Data Segment):存放初始化的全局变量和静态变量。
-
未初始化数据段 (BSS Segment):存放未初始化的全局变量和静态变量,程序开始执行时这些变量默认被初始化为 0。
-
-
-
代码段 (Text Segment):
-
代码段用于存放程序的可执行代码,包括函数体、程序的指令等。
-
代码段通常是只读的,防止程序意外修改执行代码。
-
2. 程序的内存布局
以下是C程序在内存中的典型布局:
| 内存区域 | 描述 | 增长方向 |
|---|---|---|
| 栈区 (Stack) | 存储局部变量和函数调用信息。 | 向低地址增长 |
| 空闲区 | 堆区和栈区之间的未使用内存区域。主要用于分隔堆和栈,避免二者冲突。 | N/A |
| 堆区 (Heap) | 用于动态内存分配,程序通过 malloc() 等函数进行分配。 | 向高地址增长 |
| 未初始化数据段 (BSS) | 存储未初始化的全局变量和静态变量,程序启动时初始化为 0。 | N/A |
| 已初始化数据段 (Data) | 存储已初始化的全局变量和静态变量,程序启动时已经确定值。 | N/A |
| 代码段 (Text) | 存储程序的可执行代码,通常是只读的。 | N/A |
3. 内存布局的具体示例
#include <stdio.h>
#include <stdlib.h>int global_var; // 位于.bss段
int global_init_var = 1; // 位于.data段int main() {int local_var; // 位于栈区int *ptr = malloc(sizeof(int)); // 分配在堆区*ptr = 5;free(ptr); // 释放堆内存return 0;
}
分析:
global_var:未初始化的全局变量,位于**.bss**段。global_init_var:已初始化的全局变量,位于**.data**段。local_var:局部变量,位于栈区。ptr:指针变量,位于栈区,指向堆区分配的内存。- 堆区:通过
malloc分配的内存,存储整数值5。
4. 栈与堆的增长方向
-
栈(Stack):
- 增长方向:从高地址向低地址增长。
- 特点:由系统自动管理,速度快,空间有限。
-
堆(Heap):
- 增长方向:从低地址向高地址增长。
- 特点:由程序员手动管理,灵活但易导致内存碎片和泄漏。
5. 内存管理与分配
在C语言中,动态内存分配通过标准库函数实现:
malloc:分配指定大小的内存,返回指向该内存的指针。calloc:分配指定数量和大小的内存,初始化为零。realloc:重新调整之前分配的内存大小。free:释放之前分配的内存。
示例:
#include <stdio.h>
#include <stdlib.h>int main() {// 使用malloc分配内存int *arr = malloc(5 * sizeof(int));if (!arr) {perror("malloc failed");return EXIT_FAILURE;}// 初始化数组for (int i = 0; i < 5; i++) {arr[i] = i * 2;}// 打印数组for (int i = 0; i < 5; i++) {printf("arr[%d] = %d\n", i, arr[i]);}// 释放内存free(arr);return 0;
}
输出:
arr[0] = 0
arr[1] = 2
arr[2] = 4
arr[3] = 6
arr[4] = 8
相关文章:

C语言高效内存管理:对齐、缓存与位域
C语言高效内存管理:对齐、缓存与位域 一、内存对齐 1. 内存对齐的概念 内存对齐(Memory Alignment)是指数据在内存中存储时,其起始地址遵循特定的规则,使得数据能够被高效地访问。CPU通常以固定的字节数(…...

ES操作指南
# Creating a text file with the described Elasticsearch operations. es_operations """ Elasticsearch 基本操作语法: 1. 索引文档 (Index Documents): 自动生成 ID: POST /index_name/_doc { "field1": "value1", "…...

【黑苹果】记录MacOS升级Sonoma的过程
【黑苹果】记录MacOS升级Sonoma的过程 一、硬件二、提前说明三、准备OC四、选择驱动五、选择ACPI六、下载内核扩展七、其他问题 一、硬件 设备是神舟zx6-ct5da 具体参照下图 二、提前说明 本机器已经安装过 macOS Monterey 12.6,这次是升级到 macOS Sonoma 14。 …...
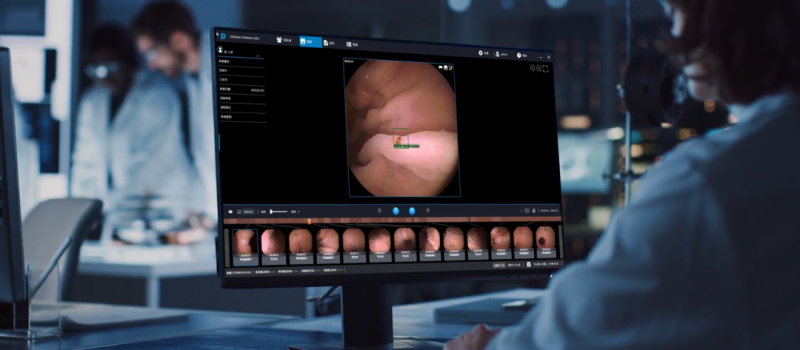
向“新”发力,朝“质”攀峰 | 资福医疗携手大圣胃肠一体内窥镜系统亮相江苏省医学会第八次健康管理学学术会议
伴随“健康中国”战略的深入实施,为进一步加强健康管理学科内涵建设,提升健康管理服务能力,促进健康管理学科创新及多部门、多产业交叉融合,2024年10月12~14日“江苏省医学会第八次健康管理学学术会议”在南京顺利召开…...

springboot项目多个数据源配置 dblink
当项目中涉及到多个数据库连接的时候该如何处理? 在对应的配置文件,配置对应的数据库情况,不过我确实没咋测试对于事务的处理我可以后续在多做测试 配置文件中配置对应的数据源 然后再使用的时候使用这个 DS(“pd_ob”)注解。 然后又长知识…...
介绍)
leetcode中哈希的python解法:Counter()介绍
Counter 是 Python 的 collections 模块中的一个类,用于统计可迭代对象中元素的出现次数。Counter 是一种专门为计数设计的哈希表(字典),它的键是元素,值是元素出现的次数。 Counter 的特点: 继承自 dict…...

VAS1800Q奇力科技线性芯片电荷泵热处理AEC-Q1000
VAS1800Q是一款专为汽车应用设计的高效恒流LED驱动器。它具备多个显著特点,不仅提升了LED驱动效率,还大大减少了热量的产生,使其在汽车照明领域中具有极高的应用价值。本文将详细介绍VAS1800Q的技术参数、功能及其在实际应用中的优势。 主要…...
 方法与 Stream API 查找枚举对象)
Java 枚举的 valueOf() 方法与 Stream API 查找枚举对象
文章目录 一、枚举类型概述二、valueOf() 方法详解1. 什么是 valueOf() 方法?2. 使用示例 三、使用 Stream API 查找枚举对象1. 使用 Stream 查找枚举对象2. 使用 Stream 统计枚举对象 四、总结推荐阅读文章 在 Java 中,枚举(enum)…...

Git的认识及基本操作
目录 一:Git的基本认识 二:Git的安装 三:Git的基本操作 1.创建本地仓库 2.配置Git 3.⼯作区、暂存区、版本库 4. 修改文件 5.版本回退 6.撤销修改 7.删除文件 一:Git的基本认识 1.实例引入 在日常当中我们常常会遇到这样的事,就是在做实验报告或者课设…...
python 日志库loguru
python 日志库loguru 安装 pip install loguru最简单的基本使用 from loguru import loggerlogger.success("Hello from success!") logger.info("Hello from info!") logger.debug("Hello from debug!") logger.warning("Hello from wa…...
基于SpringBoot+Vue+uniapp的在线招聘平台的详细设计和实现
详细视频演示 请联系我获取更详细的演示视频 项目运行截图 技术框架 后端采用SpringBoot框架 Spring Boot 是一个用于快速开发基于 Spring 框架的应用程序的开源框架。它采用约定大于配置的理念,提供了一套默认的配置,让开发者可以更专注于业务逻辑而不…...

Chrome谷歌浏览器加载ActiveX控件之JT2Go控件
背景 JT2Go是一款西门子公司出品的三维图形轻量化预览解决工具,包含精确3D测量、基本3D剖面、PMI显示和改进的选项过滤器等强大的功能。JT2Go控件是一个标准的ActiveX控件,曾经主要在IE浏览器使用,由于微软禁用IE浏览器,导致JT2Go…...
)
Java基础概览和常用知识(七)
什么是自动装箱和自动拆箱,原理是什么? 自动装箱和自动拆箱是Java编程语言中的两个重要概念,它们涉及到基本数据类型与其对应包装类之间的自动转换。 一、定义 自动装箱:是指Java编译器在需要将基本数据类型转换为对应的包装类…...

STL-string
STL的六大组件: string // string constructor #include <iostream> #include <string> using namespace std; int main() {// 构造std::string s0("Initial string");std::string s1; //nullptrstd::string s2("A character sequenc…...

数据库基础-学习版
目录 数据库巡检清理表空间高水位处理重建索引扩展字段异常恢复处置常见命令汇总 数据库巡检 数据库巡检的主要目的是确保数据库的健康状态、性能和安全,及时发现潜在的问题。 一 数据库状态检查 查看数据库列表:SHOW DATABASES; 检查当前数据库SELECT DATABASE(); 检查数据…...

【Gin】Gin框架介绍和使用
一、简单使用Gin框架搭建一个服务器 package mainimport ("github.com/gin-gonic/gin" )func main() {// 创建一个默认的路由引擎r : gin.Default()// GET 请求方法r.GET("/hello", func(c *gin.Context) {// c.JSON 返回的是JSON格式的数据c.JSON(200, g…...

AI大模型带来哪些创业机遇?
AI 大模型的快速发展带来了许多创新和创业机遇,涵盖了从行业应用到基础设施优化的方方面面。以下是一些具体的创业机会: 1、垂直行业应用 大模型可以根据不同行业的需求进行定制和优化,提供高度专业化的 AI 解决方案。 医疗领域:…...

[Linux] 层层深入理解文件系统——(3)磁盘组织存储的文件
标题:[Linux] 层层深入理解文件系统——(3)磁盘组织组织存储的文件 个人主页水墨不写bug 目录 一、磁盘中的文件 1)磁盘的物理结构 2)磁盘的CHS寻址法 3)磁盘的空间管理 二、磁盘如何组织存储文件 三…...

Apache Cordova学习计划
Apache Cordova(之前称为 PhoneGap): 1. PhoneGap的起源:2008年8月,PhoneGap在旧金山的iPhoneDevCamp上首次亮相,由Nitobe公司开发,目的是“为跨越Web技术和iPhone之间的鸿沟牵线搭桥”。 2. Ph…...

Unity学习日志-API
Untiy基本API 角度旋转自转相对于某一个轴 转多少度相对于某一个点转练习 角度 this.transform.rotation(四元数)界面上的xyz(相对于世界坐标) this.transform.eulerAngles;相对于父对象 this.transform.localEulerAngles;设置角度和设置位置一样,不能单独设置xz…...

基于XGBoost与SHAP的分子气味预测:从特征工程到可解释性分析
1. 项目概述与核心价值在香水设计、食品风味工业乃至环境监测领域,一个核心且持久的挑战是:如何从分子的化学结构出发,准确预测其气味?这不仅仅是化学家或调香师的直觉游戏,更是一个复杂的、高维度的模式识别问题。传统…...

物理引导的机器学习工作流:气候建模的融合创新与实践
1. 项目概述:当气候建模遇见机器学习如果你像我一样,在气候模拟这个领域摸爬滚打超过十年,就会深刻体会到一种“甜蜜的负担”:我们构建的地球系统模型(ESM)越来越精细,物理过程越来越复杂&#…...

Python开发者首次使用Taotoken接入大模型API的完整步骤指南
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 Python开发者首次使用Taotoken接入大模型API的完整步骤指南 对于Python开发者而言,接入大模型API进行应用开发已成为一…...
:揭秘那个让虚拟世界“有重量感“的阴影魔法)
环境光遮蔽(Ambient Occlusion):揭秘那个让虚拟世界“有重量感“的阴影魔法
一、一个让我"开窍"的老木匠故事 我有个朋友是传统家具的修复师,他给我讲过一个让我至今难忘的故事。他说他刚入行时跟着一位 70 多岁的老木匠师父学习——师父让他做的第一件事不是雕花、不是榫卯——而是"看阴影"——这个看似奇怪的训练改变了…...

关于psthon问题
我想问问各位 我python可以查到 但是我的bit文件查不到python怎么回事...

flameshow性能优化技巧:如何快速定位Go程序中的CPU热点
flameshow性能优化技巧:如何快速定位Go程序中的CPU热点 【免费下载链接】flameshow A terminal Flamegraph viewer. 项目地址: https://gitcode.com/gh_mirrors/fl/flameshow 🔥 想要快速定位Go程序中的性能瓶颈吗?flameshow是一个强大…...

武汉国电华美16875kVA串联谐振试验装置,这手活儿细
在超高压变电站和长距离电缆的现场,交流耐压试验是检验设备绝缘的“最后一关”。这位老师傅经手过不少大工程,他说,面对GIS、大型变压器这些“大块头”电容性试品,能不能顺利“过关”,往往就看串联谐振装置顶不顶得住。…...

如何快速掌握Avidemux:新手完整入门指南与5个核心技巧
如何快速掌握Avidemux:新手完整入门指南与5个核心技巧 【免费下载链接】avidemux2 Avidemux2, simple video editor 项目地址: https://gitcode.com/gh_mirrors/avi/avidemux2 Avidemux是一款功能强大且完全开源的专业视频编辑工具,专为快速剪辑、…...

告别枯燥理论!用Unity脚本生命周期与预制体玩转一个“会变身的敌人”
用Unity打造会变身的敌人:脚本生命周期与预制体的实战应用在游戏开发中,敌人AI的行为设计往往是新手开发者最感兴趣也最容易感到困惑的部分。Unity的脚本生命周期和预制体系统为这类需求提供了强大支持,但教科书式的讲解常常让学习者陷入枯燥…...

基于树莓派打造万能遥控器:从硬件选型到Web控制界面全解析
1. 项目概述:打造一个能“学习”的万能遥控器家里遥控器越来越多,电视、空调、风扇、灯带……每个设备都配一个,找起来麻烦,用起来也乱。市面上所谓的“万能遥控器”其实并不万能,它内置的码库有限,很多小众…...