【SQL】SQL查询语句
目录
🎄 基本查询语法
⭐查询多个字段
⭐设置别名
⭐去除重复记录
⭐ 数据准备
⭐ 案例
🎄 条件查询
⭐ 语法
⭐ 案例
🎄 聚合函数
⭐ 介绍
⭐ 常见的聚合函数
⭐ 语法
⭐ 案例
🎄 分组查询
⭐ 语法
⭐ where与having的区别
⭐ 案例
🎄 排序查询
⭐ 语法
⭐ 示例
🎄 分页查询
⭐ 语法
⭐ 案例
🎄 练习
🎄 执行顺序
⭐ 验证
- 📢博客主页:个人博客
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢未来很长,值得我们全力奔赴更美好的生活✨
📢前言
⭐ DQL-介绍
- DQL英文全称是Data Query Language(数据查询语言)。用来查询数据库中表的记录
- 同样DQL语言也是数据库中操作最频繁,最重要的语言。
⭐ 关键字: select
⭐ 查询命令
SELECT字段列表 FROM表名列表 WHERE条件列表 GROUP BY分组字段列表 HAVING分组后条件列表 ORDER BY排序字段列表 LIMIT分页参数
🎄 基本查询语法
- 📢 基本查询也就是不带任何条件
SELECT
字段列表
FROM
表名列表
⭐查询多个字段
- 📢 查询所有字段使用* 即可
| select 字段1,字段2,字段3...from 表名; |
| select * from 表名; |
⭐设置别名
- 📢 []内是可选的
| select 字段1 [as 别名1],字段2 [as 别名2 ]... from 表名; |
⭐去除重复记录
| select distinct 字段1 [as 别名1],字段2 [as 别名2 ]... from 表名; |
⭐ 数据准备
create table emp(
id int comment '编号',
workno varchar(10) comment '工号',
name varchar(10) comment '姓名',
gender char(1) comment '性别',
age tinyint unsigned comment '年龄',
idcard char(18) comment '身份证号',
workaddress varchar(50) comment '工作地址',
entrydate date comment '入职时间'
)comment '员工表';INSERT INTO emp VALUES (1, '00001', '柳岩666', '女', 20, '123456789012345678', '北京', '2000-01-01'),
(2, '00002', '张无忌', '男', 18, '123456789012345670', '北京', '2005-09-01'),
(3, '00003', '韦一笑', '男', 38, '123456789712345670', '上海', '2005-08-01'),
(4, '00004', '赵敏', '女', 18, '123456757123845670', '北京', '2009-12-01'),
(5, '00005', '小昭', '女', 16, '123456769012345678', '上海', '2007-07-01'),
(6, '00006', '杨逍', '男', 28, '12345678931234567X', '北京', '2006-01-01'),
(7, '00007', '范瑶', '男', 40, '123456789212345670', '北京', '2005-05-01'),
(8, '00008', '黛绮丝', '女', 38, '123456157123645670', '天津', '2015-05-01'),
(9, '00009', '范凉凉', '女', 45, '123156789012345678', '北京', '2010-04-01'),
(10, '00010', '陈友谅', '男', 53, '123456789012345670', '上海', '2011-01-01'),
(11, '00011', '张士诚', '男', 55, '123567897123465670', '江苏', '2015-05-01'),
(12, '00012', '常遇春', '男', 32, '123446757152345670', '北京', '2004-02-01'),
(13, '00013', '张三丰', '男', 88, '123656789012345678', '江苏', '2020-11-01'),
(14, '00014', '灭绝', '女', 65, '123456719012345670', '西安', '2019-05-01'),
(15, '00015', '胡青牛', '男', 70, '12345674971234567X', '西安', '2018-04-01'),(16, '00016', '周芷若', '女', 18, null, '北京', '2012-06-01')⭐ 案例
- 📢 查询指定字段 name, workno, age并返回
select name,workno,age from emp;- 📢查询返回所有字段
- 🙉 尽量不要写*,哪怕把所有的字段都罗列出来。
select * from emp;- 📢 查询所有员工的工作地址, 起别名
- 🙉 这里的as是可以省略的。
select workaddress as '工作地址' from emp;
select workaddress '工作地址' from emp;- 🙉 查询公司员工的上班地址有哪些(不要重复)
select distinct workaddress as '工作地址' from emp;🎄 条件查询
⭐ 语法
- 📢使用where来进行条件查询
select 字段列表 from 表名 where 条件列表;☀ 条件运算符
| 比较运算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| BETWEEN ... AND ... | 在某个范围之内(含最小、最大值) |
| IN(...) | 在in之后的列表中的值,多选一 |
| LIKE 占位符 | 模糊匹配(_匹配单个字符, %匹配任意个字符) |
| IS NULL | 是NULL |
☀ 逻辑运算符
| 逻辑运算符 | 功能 |
|---|---|
| AND 或 && | 并且 ( 多个条件同时成立 ) |
| OR 或 || | 或者 ( 多个条件任意一个成立 ) |
| NOT 或 ! | 非 , 不是 |
⭐ 案例
☀ 查询年龄等于88的员工
select name from emp where age = 88;
☀ 查询年龄小于 20 的员工信息
select name from emp where age < 20;☀ 查询年龄小于等于 20 的员工信息
select name from emp where age <= 20;☀ 查询没有身份证号的员工信息
select name from emp where idcard is null;☀ 查询有身份证号的员工信息
select name from emp where idcard is not null;☀ 查询年龄不等于 20 的员工信息
select name from emp where age != 20;
select name from emp where age <> 20;☀ 查询年龄不等于 20 的员工信息
select name from emp where age <> 20;☀ 查询年龄在15岁(包含) 到 20岁(包含)之间的员工信息
- 📢要注意between--and是左右包含的。
- 📢并且between之后跟的一定是最小值。
select name '姓名', age '年龄' from emp where age >= 15 && age <= 20;
select name '姓名', age '年龄' from emp where age >= 15 and age <= 20;
select name '姓名', age '年龄' from emp where age BETWEEN 15 and 20;☀ 查询性别为 女 且年龄小于 25岁的员工信息
select name '姓名', age '年龄' from emp where age < 25 and gender = '女';☀ 查询年龄等于18 或 20 或 40 的员工信息
- 📢 in是只要满足其一即可;
select name '姓名', age '年龄' from emp where age = 18 or age = 20 or age = 40;
select name '姓名', age '年龄' from emp where age in(18,20,40);☀ 查询姓名为两个字的员工信息
select * from emp where name like '__';☀ 查询身份证号最后一位是X的员工信息
- 📢 默认是不区分大小写的。
select * from emp where idcard like '%X';
select * from emp where idcard like '_________________X';🎄 聚合函数
- 📢通常在条件查询中会配合聚合函数来进行查询。
⭐ 介绍
- 📢 作用与某一列。将一列数据作为一个整体,进行纵向计算。
⭐ 常见的聚合函数
| 函数 | 功能 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
⭐ 语法
- 📢 注意 : NULL值是不参与所有聚合函数运算的。
select 聚合函数(字段列表) FROM 表名;⭐ 案例
☀ 统计该企业员工数量
- 📢 注意 :如果查询的数据中有NULL值是不会被统计在里面的。
- 📢 使用count(1) 是一种优化。
select count(*) from emp;
select count(idcard) from emp;
select count(1) from emp;☀ 统计该企业员工的平均年龄
select avg(age) from emp;☀ 统计该企业员工的最大年龄
select max(age) from emp;
☀ 统计该企业员工的最小年龄
select min(age) from emp;☀ 统计西安地区员工的年龄之和
select sum(age) from emp WHERE workaddress = '西安';🎄 分组查询
- 📢 通常配合着聚合来实现
⭐ 语法
select 字段列表 from 表名 [where 条件] group by 分组字段名 [having 分组后过滤条件];⭐ where与having的区别
- 📢 二者都是根据条件来过滤并查询数据的,但却有不同的作用
- 📢 执行时机不同: where是在分组之前过滤,不满足where条件,不参与分组;而having是分组 之后对结果进行过滤
- 📢 判断条件不同: where 不能对聚合函数进行判断,而 having 可以。
📢 注意事项:• 分组之后,查询的字段一般为 聚合函数和分组字段 ,查询其他字段无任何意义。• 可以这样理解,聚合函数是在分组的后进行计算的。所有聚合函数优先having
• 执行顺序 : where > 聚合函数 > having 。• 支持多字段分组 , 具体语法为 : group by columnA,columnB
⭐ 案例
☀ 根据性别分组 , 统计男性员工 和 女性员工的数量
- 📢 可以这样理解上面注意事项的顺序,如果我们在这条语句的gender前面加上name这个字段,即使sql是执行成功的,但是他是没有任何意义的。
select gender,count(age) from emp group by gender;☀ 根据性别分组 , 统计男性员工 和 女性员工的平均年龄
select gender,avg(age) from emp group by gender;☀ 查询年龄小于45的员工 , 并根据工作地址分组 , 获取员工数量大于等于3的工作地址
- 📢 分组前先写出where 条件 也就是小于45的员工,先写出优先条件的sql语句,where age < = 45
- 📢 接下来写出分组条件 group by workaddress
- 📢 最后写出要查询的信息 count(*) 员工数量,以及对最后查询的结果再次having过滤
- 📢 这里要注意的是对查询的员工数量进行了重命名 在having过滤时再次用到了这个重命名的字段进行having过滤
select workaddress,count(*) work_count from emp where age < 45 group by workaddress having work_count >=3;☀ 统计各个工作地址上班的男性及女性员工的数量
- 📢 在要查询的字段中添加其他字段是没有意义的。
select workaddress, gender,count(*) from emp group by workaddress,gender;🎄 排序查询
⭐ 语法
- 📢 排序支持多个字段排序
- 📢 默认值: ASC升序
- 📢 desc: 降序
- 📢如果多字段,第一个字段相同时,根据第二个字段顺序排序。
- 📢如果是升序, 可以不指定排序方式ASC
select 字段列表 from 表名 order by 字段1 排序方式1,字段2 排序方式2;⭐ 示例
- 📢我们先对分组查询中最后一个示例进行降序排序。
- 📢 排序一般是最后的操作。除了limit。
select workaddress, gender,count(*) people_num from emp group by gender,workaddress order by people_num desc;☀ 根据年龄对公司的员工进行升序排序
select * from emp order by age;☀ 根据入职时间, 对员工进行降序排序
select * from emp order by entrydate desc;☀ 根据年龄对公司的员工进行升序排序 , 年龄相同 , 再按照入职时间进行降序排序
select * from emp order by age asc,entrydate desc;🎄 分页查询
⭐ 语法
- 📢 起始索引从0 开始,起始索引 = (查询页码 - 1 ) * 每页显示记录数。
- 📢 分页查询是数据库的方言,不同的数据库有不同的实现,MySQL 中是 LIMIT
- 📢 如果查询的是第一页数据,起始索引可以省略,直接简写为 limit 10 。
select 字段列表 from 表名 limit 起始索引,查询记录数⭐ 案例
☀ 查询第1页员工数据, 每页展示10条记录
select * from emp limit 10;
select * from emp limit 0,10;☀ 查询第2页员工数据, 每页展示10条记录
select * from emp limit 10,10;🎄 练习
- (1)查询年龄为20,21,22,23岁的女性员工信息。
select * from emp where gender = '女' and age in(20,21,22,23);- (2) 查询性别为 男 ,并且年龄在 20-40 岁 ( 含 ) 以内的姓名为三个字的员工
select * from emp where gender = '男' and age BETWEEN 20 and 40 and name like '___';
select * from emp where gender = '男' and (age >= 20 and age <= 40) and name like '___';- (3) 统计员工表中, 年龄小于60岁的 , 男性员工和女性员工的人数。
select gender,count(*) from emp where age < 60 group by gender;- (4) 查询所有年龄小于等于35岁员工的姓名和年龄,并对查询结果按年龄升序排序,如果年龄相同按入职时间降序排序。
select name,age,entrydate from emp where age <= 35 order by age asc,entrydate desc;- (5)查询性别为男,且年龄在20-40 岁(含)以内的前5个员工信息,对查询的结果按年龄升序排序,年龄相同按入职时间升序排序。
select * from emp where gender = '男' and (age BETWEEN 20 and 40 ) order by age asc,entrydate desc LIMIT 0,5;🎄 执行顺序

⭐ 验证
- 查询年龄大于15的员工姓名、年龄,并根据年龄进行升序排序。
select name,age from emp where age > 15 order by age;- 在查询时,我们给emp表起一个别名 e,然后在select 及 where中使用该别名。
select e.name,e.age from emp e where e.age > 15 order by age;- 执行上述 SQL 语句后,我们看到依然可以正常的查询到结果
- 此时就说明: from 先执行 , 然后 where 和 select 执行。
- 那 where 和 select 到底哪个先执行呢 ?
- 我们给select后面的字段起别名,然后在 where 中使用这个别名,然后看看是否可以执行成功。
select e.name ename ,e.age eage from emp e where eage > 15 order by age;- 执行结果后会发现sql报错,表示在where查询时 eage的别名还没有生成。
- 接下来我们在order by中使用select中生产的别名,看会不会报错
select e.name ename ,e.age eage from emp e where e.age > 15 order by eage;- 执行代码没有报错,就表示order by是在select之后执行的。
相关文章:
【SQL】SQL查询语句
目录 🎄 基本查询语法 ⭐查询多个字段 ⭐设置别名 ⭐去除重复记录 ⭐ 数据准备 ⭐ 案例 🎄 条件查询 ⭐ 语法 ⭐ 案例 🎄 聚合函数 ⭐ 介绍 ⭐ 常见的聚合函数 ⭐ 语法 ⭐ 案例 🎄 分组查询 ⭐ 语法 ⭐ where与having的区…...
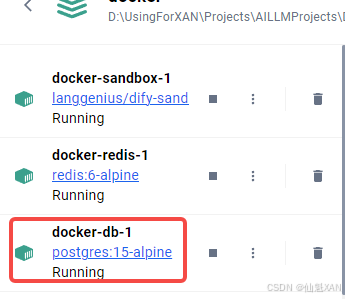
AGI 之 【Dify】 之 使用 Docker 在 Windows 端本地部署 Dify 大语言模型(LLM)应用开发平台
AGI 之 【Dify】 之 使用 Docker 在 Windows 端本地部署 Dify 大语言模型(LLM)应用开发平台 目录 AGI 之 【Dify】 之 使用 Docker 在 Windows 端本地部署 Dify 大语言模型(LLM)应用开发平台 一、简单介绍 二、Docker 下载安…...

机器学习摘下诺奖桂冠
前言 近日,2024年诺贝尔物理学奖颁发给了机器学习与神经网络领域的研究者,这是历史上首次出现这样的情况。这项奖项原本只授予对自然现象和物质的物理学研究作出重大贡献的科学家,如今却将全球范围内对机器学习和神经网络的研究和开发作为了一…...

营销邮件软件:提升邮件营销效率必备工具!
营销邮件软件选择技巧?免费高效的邮件营销软件推荐? 如何高效地管理和优化邮件营销活动成为了企业面临的一大挑战。营销邮件软件成为提升邮件营销效率的必备工具。MailBing将深入探讨营销邮件软件的功能、优势以及如何选择合适的工具。 营销邮件软件&a…...

鸿蒙开发 四十五 鸿蒙状态管理(嵌套对象界面更新)
当运行时的状态变量变化,UI重新渲染,在ArkUI中称为状态管理机制,前提是变量必须被装饰器修饰。不是状态变量的所有更改都会引起刷新,只有可以被框架观测到的更改才会引起UI刷新。其中boolen、string、number类型,可观察…...

第 6 章:vue-router
1. router 相关理解 1.1 vue-router 的理解 vue 的一个插件库,专门用来实现 SPA 应用 1.2 对 SPA 应用的理解 单页 Web 应用(single page web application,SPA)。整个应用只有一个完整的页面。点击页面中的导航链接不会刷新页…...
_随记2)
PaddleOCR模型转换、部署全流程(Ubuntu系统)_随记2
本篇衔接文章1、环境流程需要看随记1就可以 PaddleOCR环境搭建、模型训练、推理、部署全流程(Ubuntu系统)_随记1 一、ONNX导出 1、环境准备 主要参考官方技术文档:官方技术文档 未完做完更新... 参考:PaddleOCR-PP-OCRv4推理详解…...
Tableau 2024.3 发布!表格可视化项扩展、空间参数和 Cloud 管理器等,助力企业大规模分析
在升级至最新版前,先来详细一览 Tableau 2024.2 的最新特性吧~ Tableau 发布新版本啦!作为今年的收官之作,Tableau 2024.3 在延续经典之余,也为用户带来了不少惊喜,让企业数据分析之旅更加丰富多彩。 使用 Tableau Cl…...

即时通讯增加kafka渠道
此次给im服务增加kafka渠道,刚好最近有对SpringCloudStream进行了解,刚好用来练练手 增加kafka渠道 pom.xml 引入stream相关依赖 <dependency><groupId>org.springframework.cloud</groupId><artifactId>spring-cloud-strea…...

建造者模式和工厂模式的区别
工厂模式和建造者模式都是创建型设计模式,它们的主要作用都是为了简化对象的创建过程,但是它们在设计意图和实现细节上有着显著的区别。 总结区别: 关注点不同: 工厂模式关注的是对象的创建。建造者模式关注的是对象的构造过程…...
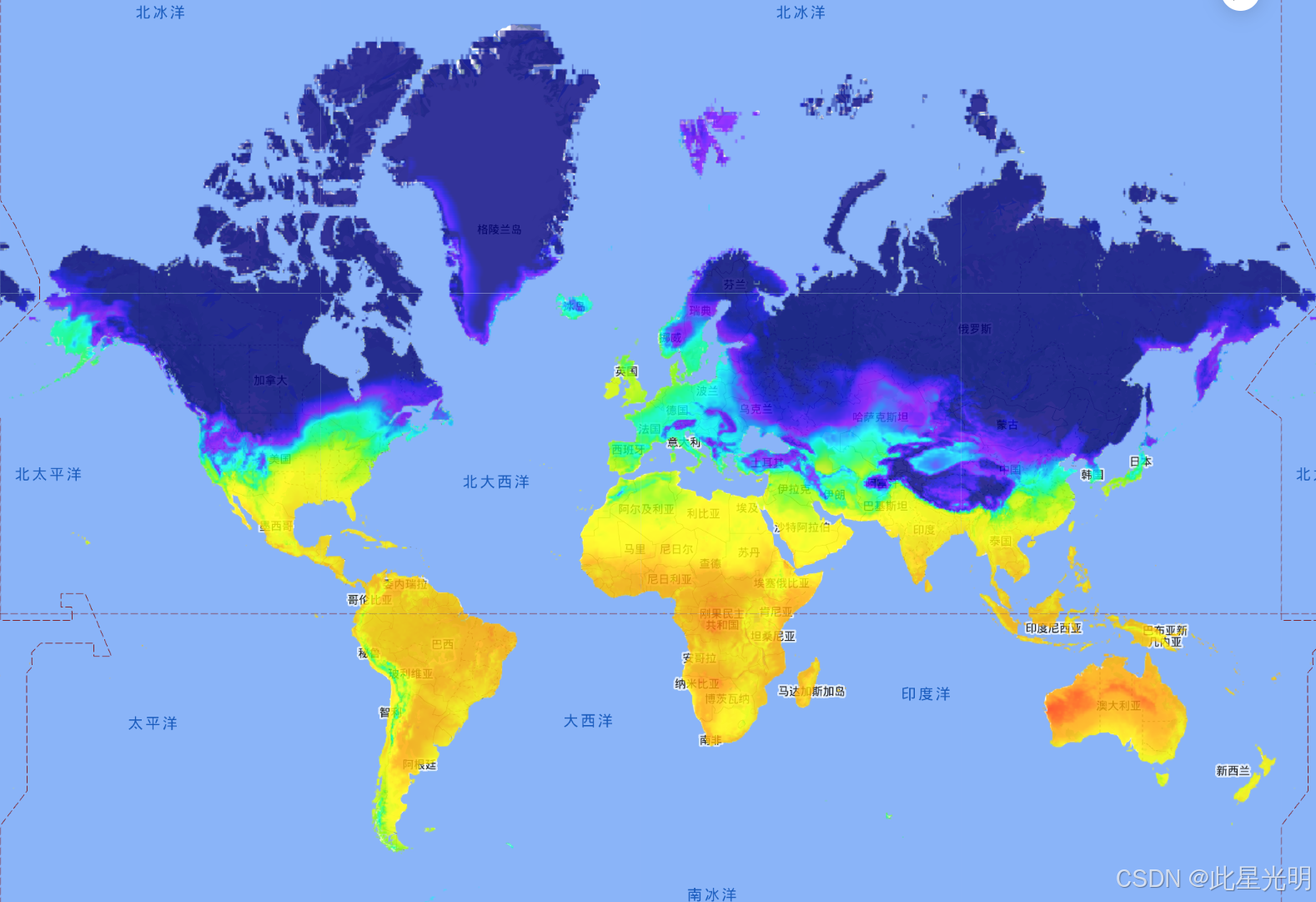
GEE数据集——ERA5-陆地每日汇总--ECMWF气候再分析数据集
目录 简介 数据集说明 Dataset Availability Dataset Provider Collection Snippet 空间信息 Resolution Bands Table 变量 代码 代码链接 结果 引用 许可 网址推荐 0代码在线构建地图应用 机器学习 简介 注(2024-04-19): …...

Spring Boot 中的 @RequestMapping 和 Spring 中的 @RequestMapping 有什么区别?
在Spring框架中,RequestMapping注解用于映射Web请求到处理器(Controller)的方法上。在Spring Boot中,这个注解的使用方式和目的与Spring框架中是完全相同的。RequestMapping注解可以用于类或方法上,以声明请求的映射。…...
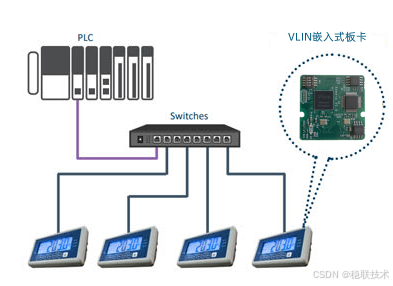
PROFINET开发或EtherNet/IP开发嵌入式归一板有用于工业称重秤
这是真实案例。然而,客户选择不展示其品牌名称。 Anybus嵌入式解决方案帮助工业称重设备制造商连接到任何工业网络。多网络连接使称重设备能够轻松访问不同的控制系统,从而加快上市时间。 我们最终找到了HMSNetworks的Anybus解决方案。他们的成熟技术和专…...

【Kafka】Kafka源码解析之producer过程解读
从本篇开始 打算用三篇文章 分别介绍下Producer生产消费,Consumer消费消息 以及Spring是如何集成Kafka 三部分,致于对于Broker的源码解析,因为是scala语言写的,暂时不打算进行学习分享。 总体介绍 clients : 保存的是Kafka客户端…...

深度学习笔记20_数据增强
🍨 本文为🔗365天深度学习训练营 中的学习记录博客🍖 原作者:K同学啊 | 接辅导、项目定制 一、我的环境 1.语言环境:Python 3.9 2.编译器:Pycharm 3.深度学习环境:TensorFlow 2.10.0 二、GPU设置…...

模板变量与php变量对比做判断
${item.create_name}如何与php变量对比 在PHP中,您可以通过将字符串内嵌到双引号中来将模板变量 ${item.create_name} 与PHP变量进行对比。如果您有一个PHP变量 $phpVariable 并且想要检查它是否与 ${item.create_name} 相同,您可以使用 str_replace 函…...

C语言 | Leetcode C语言题解之第485题最大连续1的个数
题目: 题解: int findMaxConsecutiveOnes(int* nums, int numsSize) {int maxCount 0, count 0;for (int i 0; i < numsSize; i) {if (nums[i] 1) {count;} else {maxCount fmax(maxCount, count);count 0;}}maxCount fmax(maxCount, count);…...

C语言复习概要(六)
公主请阅 1. 深入理解数组与指针在C语言中的应用1.1 数组名的理解 2. 使用指针访问数组3. 一维数组传参的本质4. 冒泡排序的实现5. 二级指针6. 指针数组7. 指针数组模拟二维数组8.总结 1. 深入理解数组与指针在C语言中的应用 数组与指针是C语言的核心概念之一,理解…...

PyQt 入门教程(2)搭建开发环境
文章目录 一、搭建开发环境1、安装PyQt5与pyqt5-tools2、配置QtDesigner3、配置Pyuic4、配置Pyrcc 一、搭建开发环境 1、安装PyQt5与pyqt5-tools PyQt5: PyQt的开发库。Pyqt5-tools: 它是一个包含多种工具的工具包,旨在帮助开发者更方便地使…...

Flink Kubernetes Operator
Flink Kubernetes Operator是一个用于在Kubernetes集群上管理Apache Flink应用的工具。 一、基本概念 Flink Kubernetes Operator允许用户通过Kubernetes的原生工具(如kubectl)来管理Flink应用程序及其生命周期。它简化了Flink应用在Kubernetes集群上的…...

用数字逻辑门复刻柏林钟:从二进制编码到硬件实现
1. 项目概述:用数字电路复刻“柏林钟”作为一个在柏林长大的孩子,我从小就对库达姆大街上的那座“柏林钟”着迷。它不像传统时钟那样用指针或数字告诉你时间,而是通过几排不同颜色的发光方块,以一种近乎艺术的方式呈现时间。这种独…...

Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器
Scroll Reverser:让Mac的多设备滚动体验回归直觉的免费神器 【免费下载链接】Scroll-Reverser Per-device scrolling prefs on macOS. 项目地址: https://gitcode.com/gh_mirrors/sc/Scroll-Reverser 你是否曾经在MacBook的触控板和鼠标之间切换时࿰…...

开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣?
开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣? 关键词 AI Agent Harness Engineering、大语言模型编排(LLM Orchestration)、LangChain、AutoGPT、CrewAI、工具调用(Tool Calling)、多Agent协作、自主任务规划 摘要 随着大语言模型…...

WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案
WarcraftHelper终极指南:魔兽争霸3兼容性问题一站式解决方案 【免费下载链接】WarcraftHelper Warcraft III Helper , support 1.20e, 1.24e, 1.26a, 1.27a, 1.27b 项目地址: https://gitcode.com/gh_mirrors/wa/WarcraftHelper 还在为《魔兽争霸3》在现代电…...

探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破
探索Windows 10上的Android世界:揭秘WSA-Windows-10项目的3个技术突破 【免费下载链接】WSA-Windows-10 This is a backport of Windows Subsystem for Android to Windows 10. 项目地址: https://gitcode.com/gh_mirrors/ws/WSA-Windows-10 想象一下&#…...
)
为什么你的DeepSeek微调loss震荡不止?(Meta/DeepSeek联合团队未公开的梯度裁剪+LoRA初始化双校准协议)
更多请点击: https://codechina.net 第一章:DeepSeek微调loss震荡的根本归因剖析 DeepSeek系列模型在微调过程中频繁出现loss剧烈震荡现象,其本质并非单一因素所致,而是数据、优化器、梯度动态与模型结构四者耦合失稳的系统性表现…...

Arduino土壤湿度监测仪制作:从传感器原理到自动灌溉实现
1. 项目概述:用Arduino Uno和LCD屏打造你的土壤湿度监测仪作为一个喜欢在阳台种点番茄、辣椒的业余园丁,我经常为浇水这事儿头疼。浇多了怕烂根,浇少了又怕旱着,光靠手指插土里感觉,实在是不准。后来玩上了Arduino&…...

终极虚拟显示器解决方案:ParsecVDisplay完整使用指南
终极虚拟显示器解决方案:ParsecVDisplay完整使用指南 【免费下载链接】parsec-vdd ✨ Perfect virtual display for game streaming 项目地址: https://gitcode.com/gh_mirrors/pa/parsec-vdd ParsecVDisplay是一个基于Parsec虚拟显示驱动(VDD)的独立应用程序…...
)
DeepSeek代码审查能力白皮书(2024企业级实测报告)
更多请点击: https://kaifayun.com 第一章:DeepSeek代码审查能力白皮书(2024企业级实测报告)概述 本报告基于2024年Q1至Q3期间,面向金融、电信与云原生三大垂直行业的17家头部企业客户开展的深度实测,覆盖…...

抖音批量下载工具:免费获取无水印视频的终极解决方案
抖音批量下载工具:免费获取无水印视频的终极解决方案 【免费下载链接】douyin-downloader A practical Douyin downloader for both single-item and profile batch downloads, with progress display, retries, SQLite deduplication, and browser fallback suppor…...