【知识科普】GraphQL一个强大的API查询语言
文章目录
- 概述
- 📚 GraphQL 的类型系统是如何工作的?
- 🔍 能否举例说明 GraphQL 的类型系统在实际应用中是如何工作的?
- 位置
- 步骤 1: 定义类型
- 步骤 2: 实现解析器
- 步骤 3: 客户端查询
- 步骤 4: 执行查询
- 🛠️ 在实际开发中,如何使用 GraphQL 进行数据的版本控制?
- 适用场景
- 1. 多端应用
- 2. 微服务架构
- 3. 数据聚合
- 4. 实时更新
- 5. 代码生成工具支持
- 6. 性能优化
- 7. 其他场景
- 与传统RESTful API风格接口对比详细说明
- Spring整合GraphQL
- 1. 添加依赖
- 2. 定义 GraphQL Schema
- 3. 实现 Data Fetchers
- 4. 配置 GraphQL
- 5. 运行和测试
- 6. 高级特性
- 总结
- 参考文献
概述
GraphQL是一种用于API的查询语言,也是一个服务端的运行时,用于执行基于类型系统的查询。它允许客户端根据需求精确地获取数据,减少冗余数据的传输,并且使得API的演进更加容易。以下是GraphQL的一些核心概念和特点:
-
类型系统:GraphQL使用类型来保证应用只请求可能的数据,并提供了清晰的辅助性错误信息。这些类型系统允许客户端了解它可以请求哪些数据,并且确保请求的数据是有效的。
-
查询语言:GraphQL查询语言允许客户端精确地指定它需要哪些数据,而不是获取由服务器预定义的资源。这样,客户端可以控制它获取的数据,而不是服务器。
-
服务端运行时:GraphQL作为一个服务端运行时,可以执行基于类型系统的查询。它并没有和任何特定数据库或者存储引擎绑定,而是依靠现有的代码和数据支撑。
-
单一请求获取多个资源:GraphQL可以通过一次请求就获取多个资源,而不像传统的REST API那样需要从多个URL加载资源。这样可以减少网络请求的数量,提高应用的性能。
-
无版本演进:向GraphQL API添加新字段和类型时,不影响现有查询。老旧的字段可以被废弃,并且从工具中隐藏。这样,GraphQL API使得应用始终能够使用新的特性,并鼓励使用更加简洁、更好维护的服务端代码。
-
使用现有的数据和代码:GraphQL让你的整个应用共享一套API,而不用被限制于特定存储引擎。GraphQL引擎已经有多种语言实现,通过GraphQL API能够更好利用现有的数据和代码。
-
强大的开发者工具:GraphQL的类型系统使得构建强大的开发者工具变得更加简单,如GraphQL Playground和GraphiQL。这些工具提供了高级代码智能提示和错误高亮,使得开发和调试变得更加容易。
-
模式(Schema):GraphQL的模式定义了字段的类型、数据的结构,描述了接口数据请求的规则。模式使用一个简单的强类型模式语法,称为模式描述语言(Schema Definition Language, SDL)。
-
Resolver函数:GraphQL服务是通过定义类型和类型上的字段来创建的,然后给每个类型上的每个字段提供解析函数。这些解析函数负责返回字段的值。
-
查询和变更:GraphQL支持查询(query)和变更(mutation)。查询用于获取数据,而变更用于修改数据。此外,GraphQL还支持订阅(subscription),允许客户端订阅数据的变化,并接收实时更新。
GraphQL的这些特性使得它成为一个强大且灵活的工具,适用于构建现代Web应用的API。更多关于GraphQL的信息,可以参考GraphQL官方文档。
📚 GraphQL 的类型系统是如何工作的?
GraphQL的类型系统是其核心特性之一,它定义了数据的结构和允许的操作。以下是GraphQL类型系统的工作方式和一些关键概念:
-
类型系统(Type System):
GraphQL的类型系统允许你定义数据的结构,包括对象类型、标量类型、枚举类型、列表和非空类型。这些类型定义了可以查询的数据和操作的数据类型。 -
对象类型和字段(Object Types and Fields):
对象类型是GraphQL中最基本的组件,它定义了可以获取的对象类型和这些对象的字段。字段可以是其他对象类型,也可以是标量类型,它们代表了数据的叶子节点。 -
参数(Arguments):
GraphQL对象类型上的字段可以有零个或多个参数。所有参数都是具名的,这意味着在查询时必须指定参数名称。 -
查询和变更类型(The Query and Mutation Types):
每个GraphQL服务都有一个query类型,可能有一个mutation类型。这些类型定义了GraphQL查询的入口点,允许客户端通过这些类型来获取或修改数据。 -
标量类型(Scalar Types):
标量类型是GraphQL中的基本数据类型,如Int、Float、String、Boolean和ID。它们是不可再分的最小数据单元。 -
枚举类型(Enumeration Types):
枚举类型是一种特殊的标量类型,它限制在一个预定义的值集合内。这使得字段的值只能是这个集合中的一个。 -
列表和非空(Lists and Non-Null):
GraphQL支持列表类型和非空类型修饰符。列表类型修饰符允许字段返回一个值的数组,而非空类型修饰符确保字段总是返回一个值,不会返回null。 -
接口(Interfaces):
接口是GraphQL中用于定义抽象类型的功能。对象类型可以实现一个或多个接口,这意味着它们必须包含接口定义的所有字段。 -
输入类型(Input Types):
输入类型用于定义传递给字段参数的复杂对象结构。它们在变更操作中特别有用,允许客户端传递一个对象作为参数。 -
执行过程:
GraphQL查询的执行过程涉及到解析器(resolvers)的调用。每个字段都有一个对应的解析器函数,负责返回字段的值。如果字段返回的是对象类型,查询会递归地继续执行,直到所有字段都是标量类型。
GraphQL的类型系统为构建强大、灵活和可维护的API提供了坚实的基础。通过类型系统,GraphQL确保了客户端和服务器之间数据交换的一致性和可预测性。
🔍 能否举例说明 GraphQL 的类型系统在实际应用中是如何工作的?
当然可以。让我们通过一个实际的例子来说明GraphQL类型系统在应用中是如何工作的。假设我们正在构建一个电影信息查询的API,我们需要定义一些类型来表示电影、导演、演员等实体,并且允许客户端查询这些信息。
位置

步骤 1: 定义类型
首先,我们定义GraphQL的类型系统,包括对象类型、标量类型、枚举类型和接口。
# 枚举类型,表示电影的类型
enum MovieType {ACTIONCOMEDYDRAMASCI_FI
}# 对象类型,表示电影
type Movie {id: ID!title: String!releaseYear: Intdirector: Directoractors: [Actor]genre: MovieType
}# 对象类型,表示导演
type Director {id: ID!name: String!moviesDirected: [Movie]
}# 对象类型,表示演员
type Actor {id: ID!name: String!moviesActed: [Movie]
}# 查询类型,定义了客户端可以执行的查询操作
type Query {getMovie(id: ID!): MoviegetDirector(id: ID!): DirectorgetActor(id: ID!): Actor
}
在这个例子中,我们定义了Movie、Director和Actor三个对象类型,以及一个MovieType枚举类型。每个对象类型都有多个字段,这些字段可以是标量类型(如ID、String、Int)或其他对象类型(如Director、Actor)。
步骤 2: 实现解析器
接下来,我们需要为这些类型实现解析器(resolvers)。解析器是服务端的函数,它们定义了如何获取类型的字段值。
const resolvers = {Query: {getMovie: (_, { id }) => {// 实现根据ID获取电影的逻辑},getDirector: (_, { id }) => {// 实现根据ID获取导演的逻辑},getActor: (_, { id }) => {// 实现根据ID获取演员的逻辑},},Movie: {director: movie => {// 实现获取电影导演的逻辑},actors: movie => {// 实现获取电影演员的逻辑},},Director: {moviesDirected: director => {// 实现获取导演执导的电影的逻辑},},Actor: {moviesActed: actor => {// 实现获取演员出演的电影的逻辑},},
};
步骤 3: 客户端查询
现在,客户端可以使用GraphQL查询语言来查询数据。例如,客户端可能想要查询一部电影的详细信息,包括导演和演员。
query {getMovie(id: "1") {titlereleaseYeardirector {namemoviesDirected {title}}actors {name}}
}
步骤 4: 执行查询
当客户端发送查询到服务端时,GraphQL服务器将执行以下步骤:
- 验证查询:确保查询符合定义的类型系统。
- 执行解析器:根据查询中的字段调用相应的解析器函数。
- 返回结果:将解析器返回的数据组合成JSON格式的结果。
这个过程展示了GraphQL类型系统如何定义数据的结构和允许的操作,以及服务端如何根据这些类型系统执行查询和返回数据。GraphQL的类型系统为客户端提供了强大的数据查询能力,同时确保了服务端的数据结构和API的一致性。
🛠️ 在实际开发中,如何使用 GraphQL 进行数据的版本控制?
在实际开发中,GraphQL的类型系统为我们提供了一种灵活而强大的数据查询和管理方式。以下是如何使用GraphQL进行数据版本控制的一些策略:
-
非破坏性变更:
GraphQL的一个核心原则是,向API添加新功能时,不会造成破坏性变更。这意味着可以在不改变现有客户端行为的情况下,向GraphQL schema添加新类型和字段。例如,如果有一个Query类型,可以在这个类型上添加新的字段,而不会影响现有的客户端查询。 -
类型演化:
随着时间的推移,数据模型可能会发生变化。GraphQL允许通过在现有类型上添加新字段或创建新的子类型来演化类型。这样,旧的字段可以被废弃,但仍然保留在schema中,直到确定所有客户端都已经不再使用它们。这允许客户端逐步迁移到新的类型和字段上。 -
版本控制策略:
尽管GraphQL鼓励通过schema的持续演进来避免版本控制,但在某些情况下,可能仍然需要对API进行版本控制。在这种情况下,可以在schema中定义不同的版本字段,或者使用不同的schema来表示不同的API版本。例如,可以创建一个QueryV2类型,用于表示新版本的查询操作。 -
使用Directive进行版本控制:
GraphQL允许使用指令(Directive)来添加元数据,这些指令可以用来控制字段的版本。例如,可以定义一个@deprecated指令,用于标记不再推荐使用的字段。这样,客户端开发者可以看到哪些字段已经被废弃,并计划迁移到新的字段上。 -
向后兼容:
在GraphQL中,可以通过在schema中保留旧字段的同时添加新字段来实现向后兼容。这允许旧的客户端继续使用旧字段,而新的客户端可以使用新字段。随着时间的推移,可以逐步淘汰旧字段,并最终从schema中移除它们。 -
变更日志和文档:
维护一个详细的变更日志和文档,记录schema的变更历史,这对于客户端开发者来说是非常重要的。这可以帮助他们理解哪些字段已经被废弃,以及应该使用哪些新字段来替代。变更日志应该包括每个字段的添加、废弃和移除的时间点。
通过上述策略,可以在GraphQL中实现细粒度的数据版本控制,使得API的演进更加平滑,同时减少对现有客户端的影响。这些策略有助于确保GraphQL API的可维护性和可扩展性,同时也提高了客户端开发者的体验。
适用场景
GraphQL是一种用于API的查询语言,它提供了灵活、可扩展、缓存友好和强类型系统等特点,适用于多种场景。以下是对GraphQL适用场景的详细归纳:
1. 多端应用
- Web应用:GraphQL适用于Web应用场景,特别是单页面应用程序(SPA)等需要大量数据的前端应用。它能够减少请求次数,降低数据传输量,提高响应速度和灵活性。
- 移动应用:对于iOS、Android等移动应用,GraphQL同样表现出色。它能够根据客户端需求返回必要的信息,减少不必要的数据传输,提高用户体验。
2. 微服务架构
微服务架构通常由许多小型服务组成,这些服务负责处理特定领域或功能区域。GraphQL可以作为微服务之间进行通信的标准化接口,简化整个系统架构,并使得添加新功能变得更加容易。通过GraphQL,客户端可以一次性获取多个微服务的数据,而无需分别调用每个服务的API。
3. 数据聚合
在某些情况下,需要从多个来源获取数据并将其聚合到单个响应中。例如,在电子商务网站上搜索商品时,可能需要同时检索产品名称、描述、价格、库存等信息。GraphQL可以轻松地编写一个查询来检索所有这些信息,并将结果聚合到单个响应中,从而简化客户端的数据处理逻辑。
4. 实时更新
GraphQL支持订阅模式(subscription),能够通过WebSocket等协议建立长连接,实现实时更新。这对于需要及时反馈用户操作结果或其他事件(如推送消息)的应用场景非常有用。例如,在直播、游戏等实时数据交互场景中,GraphQL可以确保客户端能够及时获取最新的数据更新。
5. 代码生成工具支持
GraphQL具有强类型约束和自我描述性质量,这意味着可以根据GraphQL的schema自动生成前后台交互所需代码(包括请求参数验证)。这减少了手写代码出错的风险,并提高了开发效率。
6. 性能优化
由于GraphQL可以精确控制返回字段数量和内容,因此相比REST API更容易做到精细调节性能表现。通过只请求必要的数据,GraphQL可以降低数据传输量,减轻服务器负载,并加快数据传输速度。同时,强类型约束机制也保证了请求参数的正确性,从而避免了潜在的安全漏洞问题。
7. 其他场景
除了上述场景外,GraphQL还适用于许多其他场景。例如,在测试驱动开发(TDD)中,GraphQL可以帮助开发人员更准确地模拟和验证API行为;在文档生成器中,GraphQL的schema可以作为生成API文档的依据;在数据可视化工具中,GraphQL可以方便地获取所需的数据并进行展示等。
综上所述,GraphQL凭借其灵活、可扩展、缓存友好和强类型系统等特点,在多种场景下都表现出色。无论是多端应用、微服务架构、数据聚合还是实时更新等场景,GraphQL都能为开发人员提供高效、便捷的数据交互方式。
与传统RESTful API风格接口对比详细说明
GraphQL和RESTful API是两种流行的API设计范式,它们在多个方面有着显著的区别:
-
数据获取效率:
- RESTful API:通常需要多个请求才能获取相关联的数据,可能导致过度获取(Over-fetching)或获取不足(Under-fetching)。
- GraphQL:允许客户端在一个请求中精确指定所需的数据,服务器则返回所请求的数据,提高了数据获取的效率。
-
灵活性与版本控制:
- RESTful API:随着时间的推移,可能需要创建多个版本的API端点,增加了维护的复杂性。
- GraphQL:通过逐步添加新字段并废弃旧字段,可以实现平滑的版本演进,不需要显式的版本号。
-
文档和类型系统:
- RESTful API:通常需要额外的文档来描述每个端点的功能和参数。
- GraphQL:具有自描述的模式(Schema),客户端可以通过内省(Introspection)查询获取API的完整结构,拥有强大的类型系统,可以在编译时捕获许多潜在错误。
-
缓存策略:
- RESTful API:基于HTTP语义,可以充分利用HTTP缓存机制,每个资源都有唯一的URL,便于在各层进行缓存。
- GraphQL:缓存相对复杂,由于使用单一端点,无法直接使用HTTP缓存,通常需要在客户端实现缓存逻辑。
-
文件上传:
- RESTful API:对文件上传有良好的支持,可以直接使用multipart/form-data。
- GraphQL:本身不支持文件上传,需要额外的规范如graphql-multipart-request-spec来实现,增加了实现的复杂度。
-
错误处理:
- RESTful API:使用HTTP状态码来表示请求的结果,详细错误信息通常包含在响应体中。
- GraphQL:总是返回200 OK,将错误信息放在响应的errors字段中,提供了更细粒度的错误报告,但也增加了客户端的处理复杂度。
-
性能考虑:
- RESTful API:可能面临过度获取和获取不足的问题,浪费带宽或需要额外请求。
- GraphQL:解决了这些问题,但可能引入新的性能挑战,如嵌套查询可能导致N+1问题,需要通过数据加载优化来解决。
-
工具生态:
- RESTful API:拥有成熟的工具生态,如Swagger/OpenAPI用于文档和代码生成,Postman用于API测试等。
- GraphQL:工具链正在快速发展,如GraphiQL用于交互式查询,Apollo Studio用于性能监控等,但整体生态相比REST还不够成熟。
在选择API范式时,需要考虑项目复杂度、团队经验、客户端类型、系统规模和现有架构等因素。GraphQL在灵活性和效率上领先,而REST在简单性和成熟度上占优。未来,这两种范式可能长期共存,共同推动API设计的发展。
Spring整合GraphQL
Spring for GraphQL 是一个用于构建 GraphQL API 的 Spring 框架,它提供了一套完整的工具和集成,使得在 Spring 应用程序中构建 GraphQL 服务变得简单。以下是使用 Spring for GraphQL 构建 GraphQL API 的基本步骤:
1. 添加依赖
首先,你需要在项目的 pom.xml 文件中添加 Spring for GraphQL 的依赖。例如:
<dependencies><!-- Spring for GraphQL Starter --><dependency><groupId>org.springframework.experimental</groupId><artifactId>spring-graphql</artifactId><version>1.0.0</version></dependency><!-- Spring Web Starter --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- GraphQL Java Tools --><dependency><groupId>com.graphql-java-kickstart</groupId><artifactId>graphql-spring-boot-starter</artifactId><version>8.0.0</version></dependency><!-- Other dependencies -->
</dependencies>
2. 定义 GraphQL Schema
在 src/main/resources 目录下创建一个 .graphqls 文件来定义你的 GraphQL Schema。例如,创建 schema.graphqls:
type Query {fetchBooks: [Book]
}type Book {id: ID!name: String!author: String!ratings: [Rating]
}type Rating {id: ID!rating: Int!comment: Stringuser: String
}
3. 实现 Data Fetchers
创建 Data Fetcher 来处理 GraphQL 查询。你可以使用 @Controller 注解和 @QueryMapping 注解来实现:
import org.springframework.graphql.data.method.annotation.QueryMapping;
import org.springframework.stereotype.Controller;@Controller
public class BookController {@QueryMappingpublic List<Book> fetchBooks() {// 返回书籍列表}
}
4. 配置 GraphQL
如果需要,你可以在 application.properties 或 application.yml 文件中配置 GraphQL 的相关属性,例如启用 GraphiQL:
spring.graphql.graphiql.enabled=true
5. 运行和测试
启动 Spring Boot 应用程序,然后你可以通过 GraphiQL UI 来测试你的 GraphQL API。GraphiQL UI 默认在 /graphiql 路径下可用。
6. 高级特性
Spring for GraphQL 还支持许多高级特性,如自定义 Scalar 类型、Directive、复杂的数据加载策略等。你可以通过实现 RuntimeWiringConfigurer 接口来自定义你的 GraphQL Schema 和 Data Fetchers。
总结
Spring for GraphQL 提供了一种简洁的方式来构建 GraphQL API,它集成了 Spring 框架的强大功能,使得开发 GraphQL 服务变得简单而高效。通过上述步骤,你可以快速地在你的 Spring Boot 应用程序中实现 GraphQL API。更多详细信息和使用指南,可以参考 Spring for GraphQL 的官方文档 。
参考文献
GraphQL官网
相关文章:
【知识科普】GraphQL一个强大的API查询语言
文章目录 概述📚 GraphQL 的类型系统是如何工作的?🔍 能否举例说明 GraphQL 的类型系统在实际应用中是如何工作的?位置步骤 1: 定义类型步骤 2: 实现解析器步骤 3: 客户端查询步骤 4: 执行查询 🛠️ 在实际开发中&…...

Spring Boot 整合达梦
Maven 依赖 <dependency><groupId>com.dameng</groupId><artifactId>DmJdbcDriver18</artifactId><version>8.1.2.192</version></dependency> yml配置 datasource:master:url: jdbc:dm://192.168.211.113:30236username: WE…...

Vue.js 组件开发基本步骤
Vue.js 是一个构建用户界面的渐进式框架,它被设计为能够轻松地被集成进项目的部分功能,或者用于构建完整的前端应用。组件化是 Vue.js 的核心概念之一,它允许开发者将界面拆分成独立、可复用的组件,每个组件负责应用中的一小部分功…...

博客搭建之路:hexo使用next主题渲染流程图
文章目录 hexo使用next主题渲染流程图 hexo使用next主题渲染流程图 hexo版本5.0.2 npm版本6.14.7 next版本7.8.0 next主题的配置文件中搜索找到mermaid,把enable配置改为true mermaid:enable: true# Available themes: default | dark | forest | neutraltheme: de…...

【数据结构与算法】线性表顺序存储结构
文章目录 一.顺序表的存储结构定义1.1定义1.2 图示1.3结构代码*C语言的内存动态分配 二.顺序表基本运算*参数传递2.1建立2.2初始化(InitList(&L))2.3销毁(DestroyList(&L))2.4判断线性表是否为空表(ListEmpty(L))2.5求线性表的长度(ListLength(L))2.6输出线性表(DispLi…...
Unix Standardization and Implementations
Unix标准化 在Unix未制定较为完备的标准时,各个平台的系统调用方式各异,所开发出的应用程序存在可移植性差的特点,因此人们呼吁指定一套Unix标准来规范接口,增加应用程序的可移植性。所谓Unix标准即适用于Unix环境下的一系列函数…...

Windows 与 Java 环境下的 Redis 利用分析
1 前言 在最近的一次攻防演练中,遇到了两个未授权访问的 Redis 实例。起初以为可以直接利用,但后来发现竟然是Windows Java (Tomcat)。因为网上没有看到相关的利用文章,所以在经过摸索,成功解决之后决定简单写一写。 本文介绍了…...
机器视觉系统硬件组成之工业相机篇
工业相机是一种非常重要的机器视觉器件,它能够将被采集的图像信息通过电路转换成电信号,再通过模数转换器(ADC)将其转化为数字信号,最后以标准的视频信号输出。工业相机在机器视觉领域得到了广泛应用,包括质…...
离线安装bitnami-gitlab8.8.4+汉化
注意: 常规安装gitlab需要联网,而按装bitnami-gitlab无需联网(bitnami-gitlab用于内网环境无法联网时安装gitlab,两者是一个东西只是名字不一样)bitnami-gitlab-8.8.4版本可以汉化成功新用户注册账户无需激活也可以直接登录,因为…...
亚马逊日本站推出AI日语listing功能,Listing一键发布,轻松无忧!
随着大数据与人工智能技术的成熟,AI在电商的应用也越来越多,各大电商平台都在陆续引进AI人工智能,有客服方面的,也有发布Listing方面的。 10月17日消息,亚马逊日本站近日宣布推出一项支持日语的人工智能listing功能&am…...

Golang | Leetcode Golang题解之第475题供暖器
题目: 题解: func findRadius(houses, heaters []int) (ans int) {sort.Ints(houses)sort.Ints(heaters)j : 0for _, house : range houses {dis : abs(house - heaters[j])for j1 < len(heaters) && abs(house-heaters[j]) > abs(house-…...
【Vue】Vue3.0 (十二)、watchEffect 和watch的区别及使用
上篇文章: 【Vue】Vue3.0 (十二)、watch对ref定义的基本类型、对象类型;reactive定义的对象类型的监视使用 🏡作者主页:点击! 🤖Vue专栏:点击! ⏰️创作时间&…...

PHP-laravel框架
laravel框架 laravel 搭建与路由基础 基本路由与视图路由 视图使用控制器模板分配变量...
永恒之蓝漏洞
MS17-010是微软于2017年3月发布的一个安全补丁,旨在修复Windows操作系统中的一个严重漏洞,该漏洞被称为“永恒之蓝”(EternalBlue)。这个漏洞影响了Windows的Server Message Block(SMB)协议,允许…...
Eking管理易 Html5Upload 前台任意文件上传漏洞复现
0x01 产品描述: Eking管理易是一款专为广告制品制作企业量身定制的管理软件产品,旨在帮助企业实现规范化、科学化管理,提升运营效率和降低运营成本。 该软件由广州易凯软件技术有限公司开发,基于JAVA企业版技术研发࿰…...
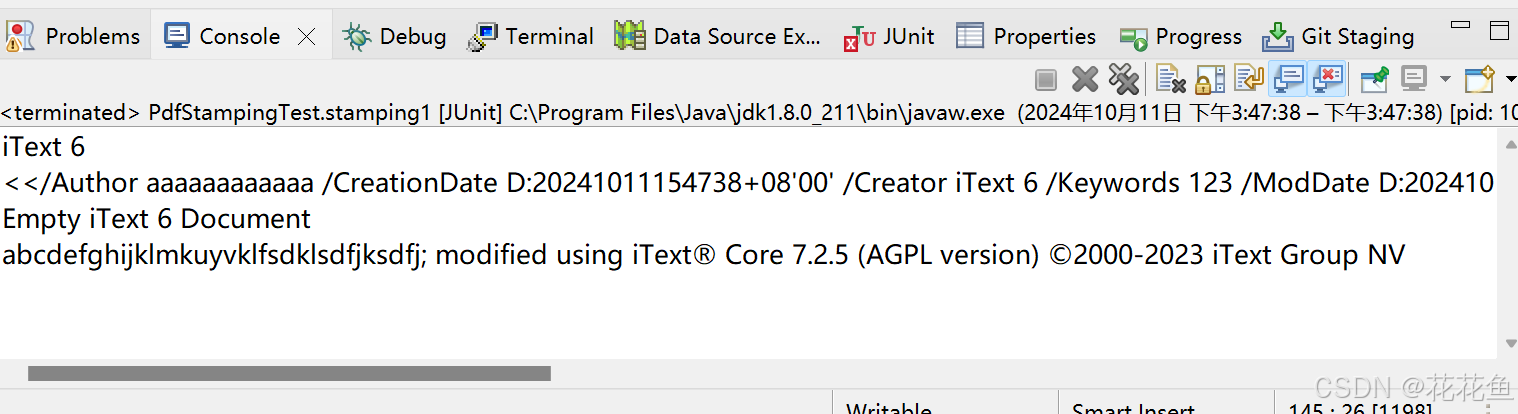
spring boot itext7 修改生成文档的作者、制作者、标题,并且读取相关的信息。
1、官方的example文件:iText GitHub itext-java-7.2.5\kernel\src\test\java\com\itextpdf\kernel\pdf\PdfStampingTest.java 2、修改代码: Testpublic void stamping1() throws IOException {String filename1 destinationFolder "stamping1_…...
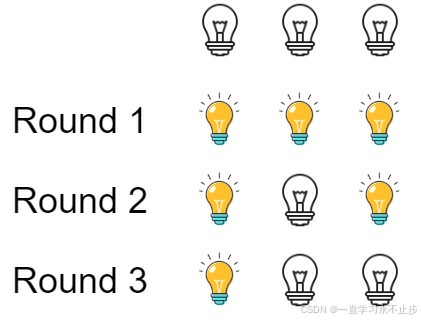
LeetCode题练习与总结:灯泡开关--319
一、题目描述 初始时有 n 个灯泡处于关闭状态。第一轮,你将会打开所有灯泡。接下来的第二轮,你将会每两个灯泡关闭第二个。 第三轮,你每三个灯泡就切换第三个灯泡的开关(即,打开变关闭,关闭变打开&#x…...
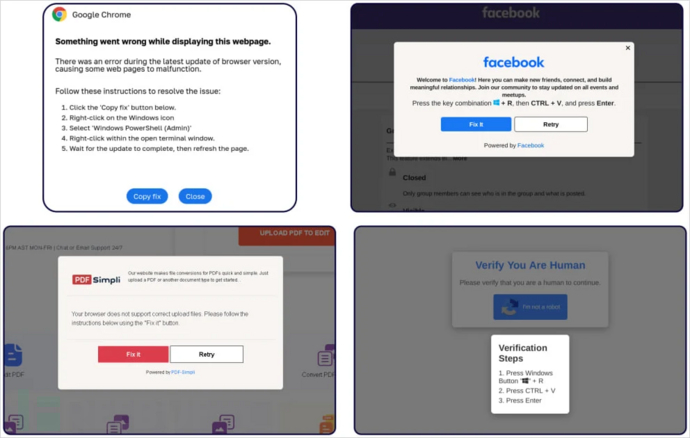
ClickFix攻击活动升级:可通过虚假谷歌会议画面传播恶意软件
最近,研究人员报告了一种新的 ClickFix 攻击活动,主要通过诱骗用户访问显示虚假连接错误的欺诈性 谷歌会议的页面,继而借此传播信息窃取恶意软件,主要针对 Windows 和 macOS 操作系统。 ClickFix是网络安全公司Proofpoint在5月份…...

迷茫!能走出迷茫?
我今年40有余,因资质平庸,及特殊的个人经历,仍奋斗在一线。上班近二十年,两件事对我人生走向影响最大,编程和炒股。 下个月要去一家新公司上班。今天算是在现公司工作交接的最后时段。在这家公司干了接近一年ÿ…...

6.2 遍历重定位表
本节我们将编写一个遍历重定位表的示例程序,打印重定位表。 本节必须掌握的知识点: 遍历重定位表 6.2.1 遍历重定位表 实验四十三:遍历重定位表 以下代码实现打印"c:\\notepad64.exe"进程重定位表的所有信息。 /*--------------…...

为什么92%的Sora 2初学者卡在第4步?——帧一致性崩塌诊断工具包+时间轴锚点校准法
更多请点击: https://kaifayun.com 第一章:Sora 2视频生成的核心原理与环境准备 Sora 2并非OpenAI官方发布的模型,而是社区基于Sora技术理念构建的开源复现与增强框架,其核心依托于时空联合建模的扩散变换器(Spacetim…...

Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 [特殊字符]
Spring Cloud AWS 实战教程:构建高可用 SQS 消息队列应用 🚀 【免费下载链接】spring-cloud-aws The New Home for Spring Cloud AWS 项目地址: https://gitcode.com/gh_mirrors/sp/spring-cloud-aws Spring Cloud AWS 是一个强大的开源框架&…...

③ AI副业第一步:如何找到适合自己的AI赚钱赛道
③ AI副业第一步:如何找到适合自己的AI赚钱赛道选对赛道,努力才有意义。选错赛道,越努力离钱越远。前言:为什么大多数人AI副业做不起来? 我观察了100想做AI副业的人,失败的原因高度一致: 失败路…...

别再手动改路径了!用LabVIEW + MATLAB Script做自动化测试,这份环境配置指南让你效率翻倍
LabVIEW与MATLAB深度整合:构建自动化测试系统的工程实践指南在工业自动化与测试测量领域,LabVIEW和MATLAB的组合堪称黄金搭档。LabVIEW擅长硬件接口和实时控制,而MATLAB在算法开发和数据分析方面具有无可比拟的优势。本文将深入探讨如何将两者…...

告别虚频困扰:用VASP+DynaPhoPy搞定高温材料声子谱的保姆级教程
高温材料声子谱计算实战:从虚频困境到非谐解决方案 引言:虚频问题的根源与突破路径 在计算材料学领域,声子谱分析是理解材料动力学稳定性和热力学性质的核心手段。然而许多研究者都遭遇过这样的困境:对实验合成的材料进行简谐近似…...

Owl-Alpha 新手快速上手指南
在处理大规模数据或构建高性能应用时,我们常常会遇到一个棘手的问题:如何在不阻塞主线程的情况下,高效地执行耗时任务?无论是处理图像、解析大型文件,还是进行复杂的数学运算,传统的单线程模式往往会让界面…...

3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程
3分钟解锁网易云音乐NCM文件:ncmdumpGUI小白也能懂的完整教程 【免费下载链接】ncmdumpGUI C#版本网易云音乐ncm文件格式转换,Windows图形界面版本 项目地址: https://gitcode.com/gh_mirrors/nc/ncmdumpGUI 你是否曾经下载了网易云音乐的歌曲&a…...

BetterJoy终极指南:3分钟让你的Switch手柄变身PC游戏神器
BetterJoy终极指南:3分钟让你的Switch手柄变身PC游戏神器 【免费下载链接】BetterJoy Allows the Nintendo Switch Pro Controller, Joycons and SNES controller to be used with CEMU, Citra, Dolphin, Yuzu and as generic XInput 项目地址: https://gitcode.c…...

终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接
终极STL到STEP转换指南:如何实现3D打印模型到CAD设计的无缝衔接 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 在数字化制造和工程设计领域,STL到STEP转换已成为连接3D…...

Unity项目实战:用TriLib插件动态加载FBX模型,5分钟搞定外部资源读取
Unity项目实战:用TriLib插件高效加载外部FBX模型的完整指南在VR展示、产品配置器等需要动态加载用户上传模型的场景中,如何快速实现外部FBX文件的读取是许多Unity开发者面临的挑战。传统的手动导入方式不仅效率低下,更无法满足运行时动态加载…...