【黑马点评优化】之使用Caffeine+Redis实现应用级二层缓存
【黑马点评优化】之使用Caffeine+Redis实现应用级二层缓存
- 1 缓存雪崩定义及解决方案
- 2 为什么要使用多级缓存
- 3 Redis+Caffeine实现应用层二级缓存原理
- 4 利用Caffeine+Redis解决Redis突然宕机导致的缓存雪崩问题
- 4.1 pom.xml文件引入相关依赖
- 4.2 本地缓存配置类
- 4.3 修改ShopServiceImpl中的queryById方法
- 5 测试
在这里修改一下黑马点评2商户查询的方法。使用Redis+Caffeine实现应用层二级缓存来解决缓存雪崩 的问题。
添加Caffeine的过程参考博客如下:
SpringBoot 集成 Caffeine、Redis实现双重缓存方式(-)caffeine redis-CSDN博客
1 缓存雪崩定义及解决方案
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
解决方案:
● 给不同的Key的TTL添加随机值 (同一时段,所以给不同key设置不同的TTL)
● 利用Redis集群提高服务的可用性
● 给缓存业务添加降级限流策略 (微服务)
● 给业务添加多级缓存
2 为什么要使用多级缓存
如果只使用redis来做缓存我们会有大量的请求到redis,但是每次请求的数据都是一样的,假如这一部分数据就放在应用服务器本地,那么就省去了请求redis的网络开销,请求速度就会快很多;
如果只使用Caffeine来做本地缓存,我们的应用服务器的内存是有限,并且单独为了缓存去扩展应用服务器是非常不划算。所以,只使用本地缓存也是有很大局限性的;
因此在项目中,我们可以将热点数据放本地缓存,作为一级缓存,将非热点数据放redis缓存,作为二级缓存,减少Redis的查询压力。
使用流程大致如下:
- 首先从一级缓存(caffeine-本地应用内)中查找数据;
- 如果没有的话,则从二级缓存(redis-内存)中查找数据;
- 如果还是没有的话,再从数据库(数据库-磁盘)中查找数据;
3 Redis+Caffeine实现应用层二级缓存原理
Redis 作为分布式缓存:
- Redis 具有高性能、丰富的数据结构和可扩展性,适合作为分布式缓存存储大量的数据。它可以在多服务器环境下共享缓存数据,提高系统的整体性能。
- 可以根据数据的特点选择合适的数据结构来存储数据,如使用哈希表存储对象、使用有序集合进行排行榜等操作。
- 配置 Redis 的持久化机制,以防止数据丢失。同时,考虑使用 Redis 的集群或主从复制来提高可用性和可扩展性。
Caffeine 作为本地缓存:
- Caffeine 是一个高效的本地缓存库,可以在应用程序内部实现缓存,减少对外部缓存服务的依赖,提高缓存的访问速度。
- Caffeine 支持自动过期功能,可以根据设定的时间自动清除过期的缓存数据,减少内存占用。
- 可以根据数据的访问频率和大小来调整 Caffeine 的缓存配置,如缓存的大小、过期时间等。
实现二级缓存架构
数据存储流程:
- 当应用程序需要访问数据时,首先从 Caffeine 本地缓存中查找数据。如果数据在 Caffeine 中存在,则直接返回数据,无需进一步访问 Redis 或数据库
- 如果数据不在 Caffeine 中,则从 Redis 分布式缓存中查找数据。如果数据在 Redis 中存在,则将数据加载到 Caffeine 中,并返回数据给应用程序。
- 如果数据不在 Redis 中,则从数据库中读取数据,并将数据同时存储到 Redis 和 Caffeine 中,然后返回数据给应用程序。
数据更新流程:
- 当数据在数据库中被更新时,需要同时更新 Redis 和 Caffeine 中的缓存数据,以保证数据的一致性
- 可以采用先更新数据库,然后删除 Redis 中的对应数据,让后续的访问从数据库中重新读取数据并更新到 Redis 和 Caffeine 中的方式来实现数据的更新。这种方式被称为 Cache Aside 模式。
缓存过期策略:
- 对于 Caffeine 本地缓存,可以设置自动过期时间,根据数据的变化频率和访问频率来调整过期时间,以避免内存占用过高。
- 对于 Redis 分布式缓存,可以根据业务需求设置合理的过期时间,或者采用主动更新的方式来保证缓存数据的有效性。
4 利用Caffeine+Redis解决Redis突然宕机导致的缓存雪崩问题
需求:修改根据id查询商铺的业务,基于二级缓存方式来解决缓存雪崩问题。
思路分析:当用户开始查询时,先查询本地缓存Caffeine,判断是否命中,如果没有命中则查询Redis,命中则直接返回。

4.1 pom.xml文件引入相关依赖
<!--引入本地缓存Caffine--><dependency><groupId>com.github.ben-manes.caffeine</groupId><artifactId>caffeine</artifactId><version>2.9.2</version></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId></dependency>
4.2 本地缓存配置类
Config目录下新建本地缓存配置类,LocalCacheConfiguration
package com.hmdp.config;import com.github.benmanes.caffeine.cache.Caffeine;
import org.springframework.cache.CacheManager;
import org.springframework.cache.caffeine.CaffeineCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.concurrent.TimeUnit;import com.github.benmanes.caffeine.cache.Cache;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;import java.util.concurrent.TimeUnit;/*** 本地缓存Caffeine配置类*/
@Configuration
public class LocalCacheConfiguration {@Bean("localCacheManager")public Cache<String, Object> localCacheManager() {return Caffeine.newBuilder()//写入或者更新5s后,缓存过期并失效, 实际项目中肯定不会那么短时间就过期,根据具体情况设置即可.expireAfterWrite(120, TimeUnit.SECONDS)// 初始的缓存空间大小.initialCapacity(50)// 缓存的最大条数,通过 Window TinyLfu算法控制整个缓存大小.maximumSize(500)//打开数据收集功能.recordStats().build();}}
4.3 修改ShopServiceImpl中的queryById方法
public class ShopServiceImpl extends ServiceImpl<ShopMapper, Shop> implements IShopService {@Resourceprivate Cache<String,Object> caffeineCache;// @Cacheable(value = "shop",key = "#id")/public Result queryById(Long id){//1.从Caffeine中查询数据Object o = caffeineCache.getIfPresent(CACHE_SHOP_KEY + id);if(Objects.nonNull(o)){log.info("从Caffeine中查询到数据...");return Result.ok( o);}//缓存穿透Shop shop = cacheClient.queryWithPassThrough(CACHE_SHOP_KEY,id,Shop.class,this::getById,CACHE_SHOP_TTL,TimeUnit.MINUTES);if(shop != null){log.info("从Redis中查到数据");caffeineCache.put(CACHE_SHOP_KEY+id,shop);}if(shop == null){return Result.fail("店铺不存在!");}//7.返回数据return Result.ok(shop);}
}
- caffeineCache.put(user.getId(), user):保存本地缓存;
- caffeineCache.invalidate(id):移除指定的本地缓存;
- caffeineCache.getIfPresent(id): 从本地缓存中获取值,如果缓存中不存指定的值,则方法将返回 null;
- caffeineCache.get(id, Function<>): 从本地缓存中获取值,该方法还支持将一个参数为 key 的 Function 作为参数传入。如果缓存中不存在该 key,则该函数将用于提供默认值,该值在计算后插入缓存中,如果缓存的元素无法生成或者在生成的过程中抛出异常而导致生成元素失败,则返回null。
5 测试
运行启动类,使用前后端联调来测试查询商铺信息功能。运行结果如下,首次查询Caffeine中没有数据,所以输出从Redis中查询,第二次查询相同店铺时,从Caffeine中查询。

相关文章:
【黑马点评优化】之使用Caffeine+Redis实现应用级二层缓存
【黑马点评优化】之使用CaffeineRedis实现应用级二层缓存 1 缓存雪崩定义及解决方案2 为什么要使用多级缓存3 RedisCaffeine实现应用层二级缓存原理4 利用CaffeineRedis解决Redis突然宕机导致的缓存雪崩问题4.1 pom.xml文件引入相关依赖4.2 本地缓存配置类4.3 修改ShopServiceI…...

CEEMDAN +组合预测模型(BiLSTM-Attention + ARIMA)
往期精彩内容: 时序预测:LSTM、ARIMA、Holt-Winters、SARIMA模型的分析与比较 全是干货 | 数据集、学习资料、建模资源分享! EMD、EEMD、FEEMD、CEEMD、CEEMDAN的区别、原理和Python实现(一)EMD-CSDN博客 EMD、EEM…...

2.1.ReactOS系统中断描述符的格式KIDTENTRY结构体
2.1.ReactOS系统中断描述符的格式KIDTENTRY结构体 2.1.ReactOS系统中断描述符的格式KIDTENTRY结构体 文章目录 2.1.ReactOS系统中断描述符的格式KIDTENTRY结构体KIDTENTRY KIDTENTRY 数据结构KIDTENTRY定义了CPU对中断描述符的格式 // // …...

三、ElementPlus下拉搜索加弹窗组件的封装
近期产品提出了一个需求,要求一个form的表单里面的一个组件既可以下拉模糊搜索,又可以弹窗搜索,我就为这个封装了一个组件,下面看效果图。 效果大家看到了,下面就看组件封装和实现方法 第一步,组件封装&…...

androidStudio编译导致的同名.so文件冲突问题解决
files found with path lib/arm64-v8a/libserial_port.so from inputs: ...\build\intermediates\library_jni\debug\jni\arm64-v8a\libserial_port.so C:\Users\...\.gradle\caches\transforms-3\...\jni\arm64-v8a\XXX.so 解决方式如下: 1.将gradle缓存文件删…...

大学新生编程入门指南:如何选择编程语言与制定学习计划
大学新生编程入门指南:如何选择编程语言与制定学习计划 编程已成为当代大学生的必备技能,尤其是在信息技术高速发展的今天,编程能力不仅能帮助你在课堂学习中脱颖而出,更能为未来职业生涯打下坚实的基础。然而,面对如…...

SpringAI快速上手
一、导入依赖 镜像(导入maven依赖) <repositories><repository><id>spring-snapshots</id><name>Spring Snapshots</name><url>https://repo.spring.io/snapshot</url><releases><enabled>…...

07 django管理系统 - 部门管理 - 搜索部门
在dept_list.html中,添加搜索框 <div class"container-fluid"><div style"margin-bottom: 10px" class"clearfix"><div class"panel panel-default"><!-- Default panel contents --><div clas…...

数据操作学习
1.导入torch。虽然被称为PyTorch,但应导入torch而不是pytorch import torch 2.张量表示一个数值组成的数组,这个数组可能有多个维度 xtorch.arange(12)x 3.通过张量的shape属性来访问张量的形状和张量中元素的总数 x.shape x.numel() 4.要改变张量的形…...

什么是网络代理
了解网络代理 网络代理是一种特殊的网络服务,它允许一个网络终端(通常指客户端)通过这个服务与另一个网络终端(通常指服务器)进行非直接的连接。网络代理服务器位于发送主机和接收主机之间,接收网络请求&a…...

安防监控摄像头图传模组,1公里WiFi无线传输方案,监控新科技
在数字化浪潮汹涌的今天,安防监控领域也迎来了技术革新的春风。今天,我们就来聊聊这一领域的产品——摄像头图传模组,以及它如何借助飞睿智能1公里WiFi无线传输技术,为安防监控带来未有的便利与高效。 一、安防监控的新篇章 随着…...

问:JVM中GC类型有哪些?触发条件有哪些?区别是啥?
在Java虚拟机(JVM)中,垃圾收集(GC)是自动管理内存的关键机制。GC负责识别并回收那些不再被程序使用的对象,以释放内存空间。根据回收的区域和策略的不同,JVM中的GC可以分为多种类型。 一、GC的…...

【操作系统的使用】Linux 输入输出重定向:掌握控制台的高级用法
文章目录 Linux 输入输出重定向:掌握控制台的高级用法输出重定向将命令输出保存到文件将命令输出追加到文件 输入重定向从文件读取输入 管道操作将多个命令的输出链接起来 错误重定向将错误信息保存到文件同时重定向输出和错误信息 Linux 输入输出重定向:…...

无线通信中的四个关键概念:OFDM、多径效应、CSI和信道均衡
无线通信中的四个关键概念:OFDM、多径效应、CSI和信道均衡 无线通信技术在现代通信系统中发挥着至关重要的作用。无论是日常的手机通信,还是复杂的物联网应用,理解无线信道的特性和优化信号传输的技术是关键。在本文中,我们将介绍…...
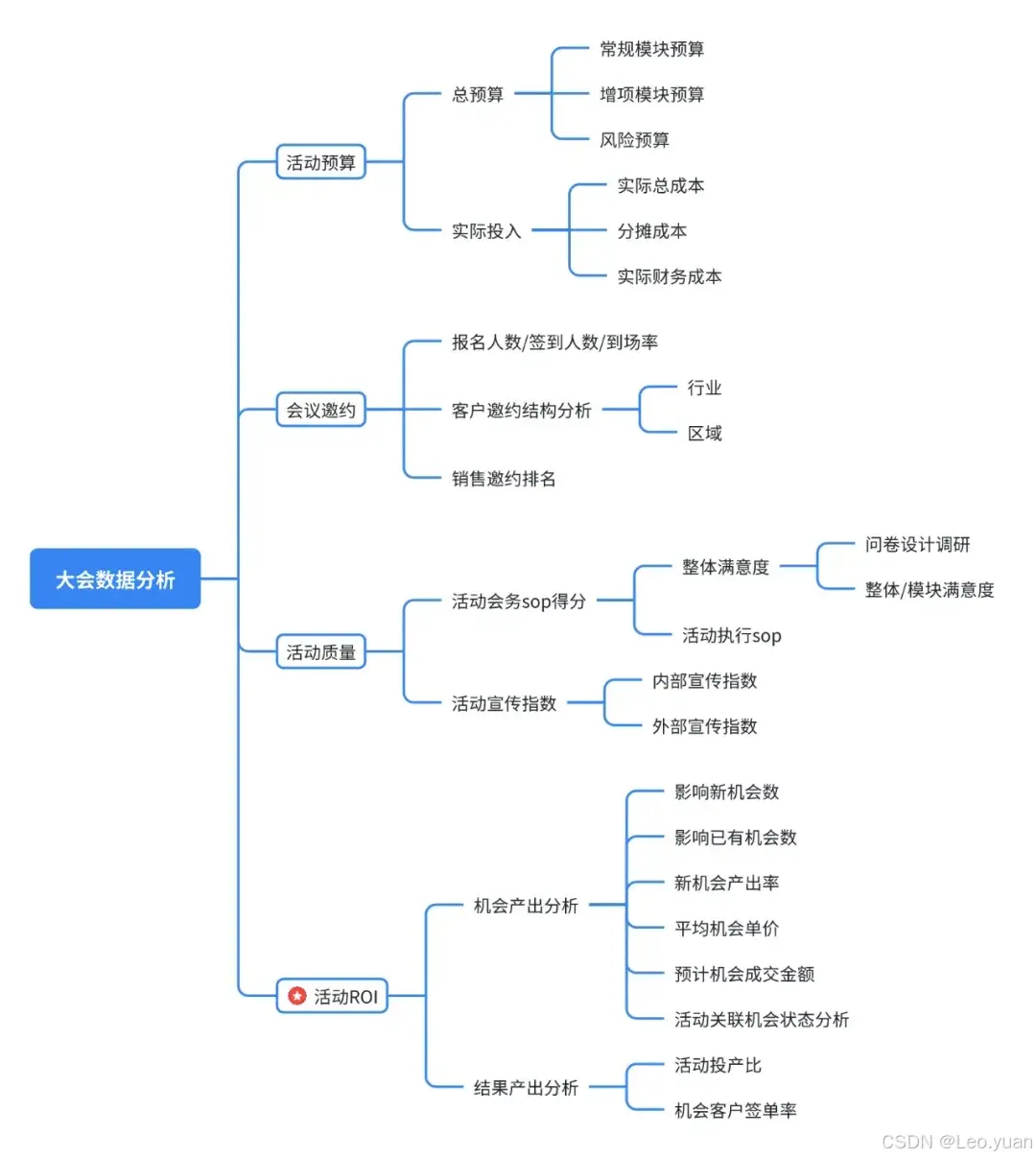
如何高效规划千人大会?数字化会议管理的实战经验分享!建议收藏!
在当今快节奏的商业环境中,大型会议不仅是企业展示自身实力、促进交流合作的重要平台,更是推动行业发展、分享创新思维的关键活动。然而,随着参会人数的增加,如何高效规划并管理一场千人大会,成为了组织者面临的巨大挑…...
)
mysql指令笔记(基本)
一、数据库操作 创建数据库:CREATE DATABASE database_name;选择数据库:USE database_name;删除数据库:DROP DATABASE database_name; 二、表操作 创建表:CREATE TABLE table_name (column1 datatype constraint, column2 datat…...

web前端-----html5----用户注册
以改图为例 <!DOCTYPE html> <html lang"en"> <head> <meta charset"UTF-8"> <meta name"viewport" content"widthdevice-width, initial-scale1.0"> <title>用户注册</title> </hea…...

bug的定义和测试
一、软件测试的生命周期 软件测试的⽣命周期是指测试流程,这个流程是按照⼀定顺序执⾏的⼀系列特定的步骤,去保证产品 质量符合需求。在软件测试⽣命周期流程中,每个活动都按照计划的系统的执⾏。每个阶段有不同的 ⽬标和交付产物 需求分析…...

Kamailio-Sngrep 短小精悍的利器
一个sip的抓包小工具,在GitHub上竟然能够积累1K的star,看来还是有点东西,当然官方的友链也是发挥了重要作用 首先送上项目地址,有能力的宝子可以自行查看 经典的网络抓包工具有很多,比如: Wireshark&…...

9.6 Linux_I/O_IO模型
基本概念 I/O执行过程与分类: 用户进程中的一个完整I/O分为 "用户进程空间->内核空间->设备空间(磁盘、网卡)" 这两个阶段。 I/O可以分为内存I/O、网络I/O、磁盘I/O 同步和异步是什么: 1、对于线程的请求调用,同步与异步…...

Agent开发面试通关攻略:吃透稳拿offer
阅读前置:2026年当下最卷也最缺人的AI岗位,一定是AI Agent开发。最近刷遍CSDN、牛客、力扣最新面经,发现一个非常明显的招聘趋势:普通大模型微调岗位饱和内卷,而AI Agent开发岗位人才严重缺口,薪资更高、竞…...
)
放弃编码器!纯靠MPU6050和PID算法,手把手教你用TT马达实现平衡小车稳定控制(STM32F103C8T6实战)
纯MPU6050STM32F103的TT马达平衡车实战:无编码器PID控制全解析当大多数平衡小车方案都在强调编码器对速度反馈的不可或缺性时,我们决定挑战一个更极简的配置:仅用5美元的TT马达、9轴的MPU6050和STM32F103C8T6最小系统板,完全舍弃编…...

人类防伪指南:为什么你越写错字,HR越信你是真人?
前言各位码农、算法侠、CtrlC/V十级学者请注意:你有没有过这样的经历?辛辛苦苦肝了一晚上文档,逻辑严密、语法丝滑、连Markdown都对齐得像军训方阵,结果老板幽幽来一句:“这真是你自己写的?”那一刻&#x…...

2027考研全套资料免费分享
备战27考研最全备考资料整理完毕,一路走来深知备考搜集资料耗费大量时间,浪费不少精力。特意整理2027考研全科完整版资源,全部打包汇总,零基础考生直接拿来就能使用,省去四处搜集资料的烦恼。资料内含:&…...

论文写作效率翻倍?okbiye 毕业论文 AI 功能全解析:从需求到终稿的规范路径
okbiye-免费查重复率aigc检测/开题报告/毕业论文/智能排版/文献综述/AI PPT毕业论文 - Okbiye智能写作https://www.okbiye.com/ai/bylw 一、从界面看本质:okbiye 毕业论文 AI 写作的设计逻辑 打开 okbiye 的毕业论文 AI 写作页面,首先能感受到的是清晰的…...

Qri高级功能:如何使用JSON Schema验证和描述数据集结构
Qri高级功能:如何使用JSON Schema验证和描述数据集结构 【免费下载链接】qri youre invited to a data party! 项目地址: https://gitcode.com/gh_mirrors/qr/qri Qri是一个强大的开源数据协作工具,它提供了丰富的功能来帮助用户管理、共享和验证…...
)
手把手教你用Mind+和Blynk,让手机轻松遥控掌控板(含自建服务器避坑指南)
从零搭建物联网控制平台:Mind与Blynk深度整合实战 当你第一次尝试用手机控制硬件设备时,那种"隔空取物"的奇妙感总会让人兴奋不已。想象一下,躺在沙发上就能调节书桌上的智能台灯亮度,或者在外出时随时查看家中的温湿度…...

CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战
CSharpVerbalExpressions常见问题解答:解决开发者遇到的10个典型挑战 【免费下载链接】CSharpVerbalExpressions 项目地址: https://gitcode.com/gh_mirrors/cs/CSharpVerbalExpressions CSharpVerbalExpressions是一个强大的C#库,它通过类自然语…...

告别Postman!用APIfox搞定接口测试+自动化,这份保姆级教程带你从环境配置到报告生成
从Postman到APIfox:接口测试自动化的高效迁移指南如果你还在为接口测试中的重复劳动和多环境切换头疼,是时候考虑从Postman迁移到APIfox了。作为一名经历过这个转型过程的开发者,我想分享一些实战经验,帮助你平滑过渡并最大化利用…...

LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换!
LeaguePrank:5分钟打造个性化英雄联盟客户端,段位头像随心换! 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 厌倦了千篇一律的英雄联盟客户端界面?想向好友展示王者段位却还在白…...