informer学习笔记
一、informer讲解
infomer
要解决的三大问题:
- Attention计算的更快
- Decoder要一次性输出所有预测
- 堆叠encoder也要更快
1. Attention
在长序列中,并非每一个位置的Attention都重要,对于每一个Q来说,只有一小部分的K与其有较强的关系。
Transformer里,我们计算 Q K V QKV QKV 的时候,看一下 Q K QK QK 点积的热力图,越亮的部分表示 Q K QK QK 相关性越高。热力图中大部分为黑色,实验发现对于每个 Q Q Q 只有一小部分的 K K K 和它有较强的关系。
就下图来看,8000个样本,相关性较高的可能只有2000个不到。大部分时候 Q K QK QK 的关系都接近于0。

如下图,纵坐标为Q,横坐标为K。每一行即为一个Q与所有K相关性的结果。
红色部分就是一个“积极”的Q,我们可以从图中明显看出它和哪个K相关性较高。
绿色部分就是一个“懒惰”的Q,它和所有的K关系都很“一般”。

在实际计算中,这些“懒惰”的Q不仅无法提供有效的价值,而且在Q里大部分都是这些“懒惰”的家伙。
只选取“积极”的Q来计算注意力机制,而舍弃掉“懒惰”的Q的想法随之诞生。这就是Informer论文的核心:ProbSparse Attention。
简略介绍核心部分
ProbSparse Self-attention 计算方法
- 输入序列长度为96,首先在K中进行采样,
随机选25个K - 现在要选出来的是一些重要的Q,正常情况下需要每一个Q跟96个K进行计算
- 重要的Q不用非得计算那么多,跟部分K计算的结果也可以当做其分布
- 例如源码输出结果:32,8,96,25表示8头,96个Q分别跟25个K计算的内机
- 现在每一个Q有25个得分(分别跟25个K计算后得到的)

(其中第一项是 对于所有的key的Log-Sum-Exp (LSE),第二项是它们的算数平均值。)
6. 为了进一步加速,论文中的做法直接选最大值与均匀分布算差异
7. 在96个Q中,选出来差异最大的25个Q(根据序列长度来定的一个参数值)
8. 得到的QK的内积为:32,8(多头),25(Q的个数),96(K的个数),就是只选了25个Q(K为96个,因为要融合每一个K的特征)
9. 其他位置的Q直接用V(96个,表示每一个位置的特征)的均值来代替,看下图中绿色的部分,曲线接近于均值

10.也就是选出的25个Q会更新,其他剩余的都是均值向量
Self-attention Distilling计算方法
- 做完一次attention之后还要继续堆叠,只不过与传统的trnsformer不同,会先通过1D的
maxpooling操作来进行下采样,下次输入序列就变成48了 - 此时Q和K的采样由于序列长度变小,也会随之变小,例如由25–>20
- 重复堆叠就是informer的encoder架构了
- 不仅是下采样,还把stamp特征也融合进来了

Encoder改进后的结果
- 速度快效率高了,论文中的计算复杂度由 L 2 L^2 L2 --> L l o g l Llog_l Llogl
- 下采样之后,特征更明显,且跟之前的模式基本一致
参数解读
| 参数名称 | 参数类型 | 参数讲解 |
|---|---|---|
| model | str | 这是一个用于实验的参数设置,其中包含了三个选项: informer, informerstack, informerlight。根据实验需求,可以选择其中之一来进行实验,默认是使用informer模型。 |
| data | str | 数据,这个并不是数据集文件,而是你想要用官方定义的方法还是你自己的数据集进行定义数据加载器,如果是自己的数据集就输入custom。 |
| root_path | str | 这个是文件的路径,不要到具体的文件,到目录级别即可。 |
| data_path | str | 这个填写文件的名称。 |
| features | str | 这个是特征有三个选项:M,MS,S。分别是多元预测多元,多元预测单元,单元预测单元。 |
| target | str | 这个是数据集中想要预测的那一列数据,假设预测的是油温OT列就输入OT即可。 |
| freq | str | 时间的间隔,数据集每一条数据之间的时间间隔。 |
| checkpoints | str | 训练出来的模型保存路径。 |
| seq_len | int | 用过去的多少条数据来预测未来的数据。 |
| label_len | int | 可以裂解为更高的权重占比的部分,要小于seq_len。 |
| pred_len | int | 预测未来多少个时间点的数据。 |
| enc_in | int | 数据有多少列,要减去时间那一列。 |
| dec_in | int | 数据有多少列,要减去时间那一列。 |
| c_out | int | 如果features填写的是M那么和上面就一样,是数据列数。如果填写的是MS,那么这里要输入1,因为你的输出只有一列数据。 |
| d_model | int | 用于设置模型的维度,默认值为512。可以根据需要调整该参数的数值来改变模型的维度。 |
| n_heads | int | 用于设置模型中的注意力头数。默认值为8,表示模型会使用8个注意力头。(有时也会用数据有多少列作为头数,可以根据自己实际数据集情况设定) |
| e_layers | int | 用于设置编码器的层数。 |
| d_layers | int | 用于设置解码器的层数。 |
| s_layers | str | 用于设置堆叠编码器的层数。 |
| d_ff | int | 模型中全连接网络(FCN)的维度,默认值为2048。 |
| factor | int | ProbSparse自注意力中的因子,默认值为5。 |
| padding | int | 填充类型,默认值为0,如果不够数据就填写0。 |
| distil | bool | 是否在编码器中使用蒸馏操作。使用–distil参数表示不使用蒸馏操作,默认为True,也是论文中比较重要的一个改进。 |
| dropout | float | 丢弃的概率,防止过拟合。 |
| attn | str | 编码器中使用的注意力类型,默认为"prob"。这是论文的主要改进点,提出的注意力机制。 |
| embed | str | 时间特征的编码方式,默认为"timeF"。 |
| activation | str | 激活函数。 |
| output_attention | bool | 是否在编码器中输出注意力,默认为False。 |
| do_predict | bool | 是否进行预测。 |
| mix | bool | 在生成式解码器中是否使用混合注意力,默认为True。 |
| cols | str | 从数据文件中选择特定的列作为输入特征,不常用。 |
| num_workers | int | 线程(windows最好设置成0否则会报线程错误,linux系统随便设置)。 |
| itr | int | 实验运行的次数,默认为2。 |
| train_epochs | int | 训练的次数。 |
| batch_size | int | 一次往模型中输入多少条数据。 |
| patience | int | 早停机制,如果损失多少个epochs没有改变就停止训练。 |
| learning_rate | float | 学习率。 |
| des | str | 实验描述,默认为"test"。 |
| loss | str | 损失函数,默认为"mse"。 |
| lradj | str | 学习率的调整方式,默认为"type1"。 |
| use_amp | bool | 混合精度训练。 |
| inverse | bool | 是否将归一化后的数据转换为原始值,默认为False。如果你想要转换为原来的数据,改成True。 |
| use_gpu | bool | 是否使用GPU训练,根据自身情况来选择。 |
| gpu | int | GPU的编号。 |
| use_multi_gpu | bool | 是否使用多个GPU训练。 |
| devices | str | GPU的编号。 |
二、informer核心部分解读
1. Attention
高效自注意力机制
经典的自注意力机制(Vaswani等,2017)基于三元组输入,即查询(Query, Q Q Q)、键(Key, K K K)和值(Value, V V V),其执行的缩放点积计算定义如下:
A ( Q , K , V ) = Softmax ( Q ‾ K ⊤ d ) V A(Q, K, V) = \text{Softmax}\left(\frac{\overline{Q}K^\top}{\sqrt{d}}\right)V A(Q,K,V)=Softmax(dQK⊤)V
其中, Q ‾ ∈ R L Q × d \overline{Q} \in \mathbb{R}^{L_Q \times d} Q∈RLQ×d, K ∈ R L K × d K \in \mathbb{R}^{L_K \times d} K∈RLK×d, V ∈ R L V × d V \in \mathbb{R}^{L_V \times d} V∈RLV×d, d d d 是输入的维度。
为了进一步讨论自注意力机制,设 q i , k i , v i q_i, k_i, v_i qi,ki,vi 分别表示矩阵 Q , K , V Q, K, V Q,K,V 的第 i i i 行。根据(Tsai等,2019)的公式,第 i i i 个查询的注意力可以定义为概率形式的核平滑器(kernel smoother):
A ( q i , K , V ) = ∑ j k ( q i , k j ) v j ∑ l k ( q i , k l ) = E p ( k j ∣ q i ) [ v j ] A(q_i, K, V) = \sum_j k(q_i, k_j) \frac{v_j}{\sum_l k(q_i, k_l)} = \mathbb{E}_{p(k_j | q_i)}[v_j] A(qi,K,V)=j∑k(qi,kj)∑lk(qi,kl)vj=Ep(kj∣qi)[vj]
其中, k ( q i , k j ) k(q_i, k_j) k(qi,kj) 是查询 q i q_i qi 和键 k j k_j kj 之间的相似度函数,输出是基于查询 q i q_i qi 对所有键的概率加权值 v j v_j vj 的期望值 E p ( k j ∣ q i ) [ v j ] \mathbb{E}_{p(k_j | q_i)}[v_j] Ep(kj∣qi)[vj]。
在这里, p ( k j ∣ q i ) p(k_j | q_i) p(kj∣qi) 被定义为查询 q i q_i qi 对键 k j k_j kj 的注意力概率,它的计算公式为:
p ( k j ∣ q i ) = k ( q i , k j ) ∑ l k ( q i , k l ) p(k_j | q_i) = \frac{k(q_i, k_j)}{\sum_l k(q_i, k_l)} p(kj∣qi)=∑lk(qi,kl)k(qi,kj)
其中, k ( q i , k j ) k(q_i, k_j) k(qi,kj) 选择了非对称指数核函数:
k ( q i , k j ) = exp ( q i k j ⊤ d ) k(q_i, k_j) = \exp\left(\frac{q_i k_j^\top}{\sqrt{d}}\right) k(qi,kj)=exp(dqikj⊤)
自注意力通过计算这个概率 p ( k j ∣ q i ) p(k_j | q_i) p(kj∣qi),结合对应的值(value)来生成输出。这个过程需要二次时间复杂度的点积计算,且占用 O ( L Q L K ) O(L_Q L_K) O(LQLK) 的内存,这在提升预测能力时是一个主要的瓶颈。
此前的一些研究表明,自注意力概率的分布具有潜在的稀疏性。因此,研究者设计了在不显著影响性能的情况下,对所有 p ( k j ∣ q i ) p(k_j | q_i) p(kj∣qi) 进行“选择性”计算的策略。例如:
- Sparse Transformer(Child等,2019)结合了行输出和列输入的计算,稀疏性来自于分离的空间相关性。
- LogSparse Transformer(Li等,2019)注意到了自注意力中的周期模式,强制每个单元通过指数步长关注其前一个单元。
- Longformer(Beltagy等,2020)进一步扩展了前两者的工作,设计了更加复杂的稀疏配置。
然而,这些方法仅限于通过启发式方法进行的理论分析,它们对每个多头自注意力使用相同的策略,限制了进一步的改进空间。
查询稀疏性度量(Query Sparsity Measure)
根据公式 1 1 1,第 i i i 个查询对所有键的注意力被定义为概率 p ( k j ∣ q i ) p(k_j | q_i) p(kj∣qi),输出是其与值 v v v 的组合。主导的点积促使相应查询的注意力概率分布偏离均匀分布。如果 p ( k j ∣ q i ) p(k_j | q_i) p(kj∣qi) 接近均匀分布 q ( k j ∣ q i ) = 1 L K q(k_j | q_i) = \frac{1}{L_K} q(kj∣qi)=LK1,则自注意力将变成对值 V V V 的简单求和,从而对输入没有实际帮助且显得冗余。
自然地,分布 p p p 和 q q q 之间的“相似性”可以用来区分哪些查询是“重要的”。
Kullback-Leibler 散度
我们通过 Kullback-Leibler (KL) 散度 来衡量这种“相似性”,公式如下:
K L ( q ∥ p ) = ln ( ∑ l = 1 L K e q i k l ⊤ d ) − 1 L K ∑ j = 1 L K q i k j ⊤ d − ln L K KL(q \parallel p) = \ln \left( \sum_{l=1}^{L_K} e^{\frac{q_i k_l^\top}{\sqrt{d}}} \right) - \frac{1}{L_K} \sum_{j=1}^{L_K} \frac{q_i k_j^\top}{\sqrt{d}} - \ln L_K KL(q∥p)=ln(l=1∑LKedqikl⊤)−LK1j=1∑LKdqikj⊤−lnLK
解释:
- 公式中, q q q 是均匀分布,表示在没有显著注意力的情况下每个键被等概率关注。
- p p p 是真实的注意力分布,取决于每个查询和键的点积关系。
- KL 散度 用于衡量两个概率分布之间的差异: q q q 和 p p p。这里用于评估注意力分布与均匀分布之间的偏离程度。
稀疏度量定义
在忽略常数项后,稀疏度量可以简化为:
M ( q i , K ) = ln ( ∑ j = 1 L K e q i k j ⊤ d ) − 1 L K ∑ j = 1 L K q i k j ⊤ d (2) M(q_i, K) = \ln \left( \sum_{j=1}^{L_K} e^{\frac{q_i k_j^\top}{\sqrt{d}}} \right) - \frac{1}{L_K} \sum_{j=1}^{L_K} \frac{q_i k_j^\top}{\sqrt{d}} \tag{2} M(qi,K)=ln(j=1∑LKedqikj⊤)−LK1j=1∑LKdqikj⊤(2)
解释:
-
第一项是查询 $ q_i $ 对所有键的 对数-和-指数(Log-Sum-Exp, LSE),即:
LSE ( q i , K ) = ln ( ∑ j = 1 L K e q i k j ⊤ d ) \text{LSE}(q_i, K) = \ln \left( \sum_{j=1}^{L_K} e^{\frac{q_i k_j^\top}{\sqrt{d}}} \right) LSE(qi,K)=ln(j=1∑LKedqikj⊤)
它通常用于计算软最大值,从而度量各个键在查询 $ q_i $ 的作用下的总体影响。 -
第二项是所有键的点积值的 算术平均值,表示为:
1 L K ∑ j = 1 L K q i k j ⊤ d \frac{1}{L_K} \sum_{j=1}^{L_K} \frac{q_i k_j^\top}{\sqrt{d}} LK1j=1∑LKdqikj⊤
它反映了键对查询的整体平均响应。
ProbSparse自注意力机制
基于提出的稀疏度量方法,我们设计了ProbSparse自注意力机制,其中每个键(key)只与前 u u u个占主导地位的查询(queries)进行关联。具体形式如下:
A ( Q , K , V ) = Softmax ( Q K ⊤ d ) V (3) A(Q, K, V) = \text{Softmax} \left( \frac{Q K^\top}{\sqrt{d}} \right)V \tag{3} A(Q,K,V)=Softmax(dQK⊤)V(3)
其中, Q Q Q 是一个与查询 q q q 相同大小的稀疏矩阵,它只包含在稀疏度量 M ( q , K ) M(q, K) M(q,K) 下前 u u u个查询。由一个常数采样因子 c c c 控制,我们设置 u = c ⋅ ln L Q u = c \cdot \ln L_Q u=c⋅lnLQ,这使得ProbSparse自注意力只需计算每个查询-键对的 O ( ln L Q ) O(\ln L_Q) O(lnLQ) 点积,且该层的内存使用保持在 O ( L K ln L Q ) O(L_K \ln L_Q) O(LKlnLQ)。
在多头注意力的角度下,这种注意力机制为每个头生成了不同的稀疏查询-键对,从而避免了严重的信息损失。
问题与解决方案
然而,要计算所有查询的稀疏度量 M ( q i , K ) M(q_i, K) M(qi,K),需要计算每个查询-键对的点积,这导致时间复杂度为 O ( L Q L K ) O(L_Q L_K) O(LQLK),并且LSE操作(Log-Sum-Exp)可能存在数值稳定性问题。为了提高效率,我们提出了一个经验近似方法来快速获取查询稀疏性度量。
引理1:
对于每个查询 q i ∈ R d q_i \in \mathbb{R}^d qi∈Rd 和键 k j ∈ R d k_j \in \mathbb{R}^d kj∈Rd,有如下界限:
ln L K ≤ M ( q i , K ) ≤ max j { q i k j ⊤ d } − 1 L K ∑ j = 1 L K q i k j ⊤ d + ln L K \ln L_K \leq M(q_i, K) \leq \max_j \left\{ \frac{q_i k_j^\top}{\sqrt{d}} \right\} - \frac{1}{L_K} \sum_{j=1}^{L_K} \frac{q_i k_j^\top}{\sqrt{d}} + \ln L_K lnLK≤M(qi,K)≤jmax{dqikj⊤}−LK1j=1∑LKdqikj⊤+lnLK
当 q i ∈ K q_i \in K qi∈K 时,上述不等式同样成立。(详细证明见附录D.1)
稀疏度量的近似方法
基于引理1,我们提出了最大-均值度量,如下:
M ( q i , K ) = max j { q i k j ⊤ d } − 1 L K ∑ j = 1 L K q i k j ⊤ d (4) M(q_i, K) = \max_j \left\{ \frac{q_i k_j^\top}{\sqrt{d}} \right\} - \frac{1}{L_K} \sum_{j=1}^{L_K} \frac{q_i k_j^\top}{\sqrt{d}} \tag{4} M(qi,K)=jmax{dqikj⊤}−LK1j=1∑LKdqikj⊤(4)
通过边界松弛的方式,该公式在长尾分布下近似成立(见附录D.2)。在长尾分布中,我们只需随机采样 U = L K ln L Q U = L_K \ln L_Q U=LKlnLQ 个点积对来计算 M ( q i , K ) M(q_i, K) M(qi,K),即将其他点积对视为零。然后从这些采样的点积中选择稀疏的Top- u u u查询作为 Q Q Q。
注意:在稀疏度量 M ( q i , K ) M(q_i, K) M(qi,K) 中,最大算子对零值不敏感,且在数值上是稳定的。
复杂度分析
在实际应用中,查询和键的输入长度在自注意力计算中通常是相等的,即 L Q = L K = L L_Q = L_K = L LQ=LK=L。因此,总的ProbSparse自注意力机制的时间复杂度和空间复杂度为 O ( L ln L ) O(L \ln L) O(LlnL)。
如何筛选筛选“积极”的q
这样我们可以得到每个q的 M 得分,得分越大这个q越“积极”。
然后我们在全部的q里选择 M 得分较大的前U个,定义为“积极”的q。来进行QKV矩阵乘法的计算。(U的取值根据实际情况来定,原论文中序列长度为96,作者定义U=25,即选择得分较大的25个Q。)
明白了如何选择“积极”的q之后,大家肯定会想
- 为了求解这个度量得分 M ,还是要计算全部的QK点积,这样难道不是更“复杂”了吗?并没有减少计算量或者加快计算速度。
- 而且只计算“积极”的Q,“懒惰”的q就完全抛弃吗?矩阵的形状不就发生了变化吗?这会影响后续的计算吗?
我们来看看作者是如何解决这两个问题的,这部分隐藏在作者的实际代码实现里。
这里首先看第一点度量得分 M 的计算,我们只是想用这个得分去筛选“积极”的q,用所有的k参与计算,计算量确实太大了。实际上并没有计算全部的QK点积,而是进行了一个抽样。
正常情况下如上推导,将每个“积极”的Q和所有k(原论文中是96个k)计算,但在论文源码的实践中,在计算前会随机选取一部分k(原论文中是25个k)来计算,也可以作为它的分布。

直观的从上图可以看出。我们只选取9个k也可以大致知道这个曲线变化的情况。
由此,我们只需要一部分的k就可以对全部Q的“积极”性进行排序,然后进行选择。
“懒惰”的q是不是就完全不要了呢?
根据上述的内容,我们允许每个k仅关注U个“积极”的q来获得ProbSparse自注意力:
A ( Q , K , V ) = Softmax ( Q ‾ K ⊤ d ) V A(Q, K, V) = \text{Softmax}\left(\frac{\overline{Q}K^\top}{\sqrt{d}}\right)V A(Q,K,V)=Softmax(dQK⊤)V
其中, Q ‾ ∈ R L Q × d \overline{Q} \in \mathbb{R}^{L_Q \times d} Q∈RLQ×d 就是top u个queries选拔后的。
回顾一下原始的Transformer计算时的过程:

我们按照原论文中的数据,假设序列长度为96。
这里的维度是:
softmax ( Q K T d ) ∈ R 96 × 96 \text{softmax} \left( \frac{QK^T}{\sqrt{d}} \right) \in \mathbb{R}^{96 \times 96} softmax(dQKT)∈R96×96
V ∈ R 96 × 64 V \in \mathbb{R}^{96 \times 64} V∈R96×64
因此最终输出为:
Z ∈ R 96 × 64 Z \in \mathbb{R}^{96 \times 64} Z∈R96×64
如果我们选择 U = 25 U=25 U=25 个“积极”的查询 Q Q Q 来计算:
softmax ( Q ˉ K T d ) ∈ R 25 × 96 \text{softmax} \left( \frac{\bar{Q}K^T}{\sqrt{d}} \right) \in \mathbb{R}^{25 \times 96} softmax(dQˉKT)∈R25×96
V ∈ R 96 × 64 V \in \mathbb{R}^{96 \times 64} V∈R96×64
因此最终输出为:
Z ∈ R 25 × 64 Z \in \mathbb{R}^{25 \times 64} Z∈R25×64
对于剩余的“懒惰”的查询 q q q,作者采取的办法是,用 V V V 向量的平均来代替这些查询对应的时间点的向量。
2. Embedding

嵌入层包含三种主要的嵌入方式:
- 值嵌入(Value Embedding)
- 位置嵌入(Positional Embedding)
- 时间嵌入(Temporal Embedding)
从上图看到,在原始向量上不止增加了Transformer架构必备的PositionEmbedding(位置编码)还增加了与时间相关的各种编码。
在 LSTF 问题中,捕获远程独立性的能力需要全局信息,例如分层时间戳(周、月和年)和不可知时间戳(假期、事件)。
具体在这里增加什么样的GlobalTimeStamp还需要根据实际问题来确认,如果计算高铁动车车站的人流量,显然“假期”的时间差就是十分重要的。如果计算公交地铁等通勤交通工具的人流量,显然“星期”可以更多的揭示是否为工作日。

3. Encoder
编码器:在内存限制下处理更长的序列输入
编码器被设计用于提取长序列输入中的稳健的远程依赖关系。在输入表示之后,第 t t t 个序列输入 X t X^t Xt 变形为一个矩阵 X en t ∈ R L x × d model X^t_{\text{en}} \in \mathbb{R}^{L_x \times d_{\text{model}}} Xent∈RLx×dmodel。为了更清晰地展示编码器的结构,图3中给出了编码器的简图。

在这个架构中我们拿出一个Encoder(也就是一个梯形)来看作者在哪些方面做了改进。
论文中提出了一种新的EncoderStack结构,由多个Encoder和蒸馏层组合而成。我们拿出单个Encoder来看,如下图:

这里先看一下左边绿色的部分,是Encoder的输入。由上面深绿色的scalar和下面浅绿色的stamp组成。
- 深绿色的scalar就相当于我们之前Transformer里的input-embedding 是我们原始输入的向量。
- 浅绿色的stamp包含之前Transformer里的 Positional Ecoding(位置编码)来表示输入序列的相对位置。在时序预测任务中,这个stamp其实由LocalTimeStamp(也就是位置编码)和GobalTimeStamp(与时序相关的编码)共同构成。
我们在后面编码部分再详细展开Encoder的输入部分。我们来看一下后面Encoder的结构
自注意力蒸馏(Self-attention Distilling)
作为ProbSparse自注意力机制的自然结果,编码器的特征映射中包含了冗余的值 V V V 的组合。为了减少冗余,我们使用了蒸馏操作,该操作优先保留主导特征,使得下一层的自注意力特征图更加集中。这一操作在时间维度上大幅裁剪了输入数据,如图3中注意力块的n头权重矩阵(重叠的红色方块)所示。受膨胀卷积(Yu等,2017;Gupta和Rush,2017)的启发,我们的“蒸馏”过程将第 j j j 层的输入传递到第 ( j + 1 ) (j + 1) (j+1) 层,具体过程如下:
X j + 1 t = MaxPool ( ELU ( Conv1d ( [ X j t ] AB ) ) ) (5) X^t_{j+1} = \text{MaxPool} \left( \text{ELU} \left( \text{Conv1d}([X^t_j]_{\text{AB}}) \right) \right) \tag{5} Xj+1t=MaxPool(ELU(Conv1d([Xjt]AB)))(5)
其中, [ ⋅ ] AB [·]_{\text{AB}} [⋅]AB 代表注意力块,它包含了多头ProbSparse自注意力以及一些基本操作, Conv1d ( ⋅ ) \text{Conv1d}(·) Conv1d(⋅) 是在时间维度上执行的一维卷积操作(核宽度为3),并伴随了ELU(Clevert等,2016)激活函数。之后,我们添加了一个步幅为2的最大池化层,对 X t X^t Xt 进行下采样,堆叠一层后将 X t X^t Xt 缩小为一半,从而将整个内存使用量减少到 O ( ( 2 − ε ) L log L ) O((2 - \varepsilon) L \log L) O((2−ε)LlogL),其中 ε \varepsilon ε 是一个较小的数。
为了增强蒸馏操作的鲁棒性,我们构建了主堆栈的副本,每个副本的输入大小逐渐减少,像金字塔一样逐层减少自注意力蒸馏层的数量,最终使得它们的输出维度对齐。这样,我们可以将所有堆栈的输出进行拼接,得到编码器的最终隐藏表示。
详细解释:
-
自注意力蒸馏:自注意力机制往往会带来冗余的信息组合,特别是在长序列任务中,因此需要蒸馏操作来集中保留最重要的信息。通过该操作,输入的时间维度得到了显著减少,同时仍保留了主要特征。这类似于卷积操作中的膨胀卷积,通过扩大感受野获取更大的上下文信息。
-
卷积与池化:使用一维卷积(Conv1d)和ELU激活函数,处理时间维度信息;随后,通过最大池化(MaxPool)进行下采样,将输入长度减半,进一步减少内存使用。
-
内存优化:该机制通过减少每一层的输入大小,使得内存使用量大大降低,且通过金字塔结构减少层数,确保输出维度一致性。
-
金字塔结构:编码器的最终输出通过对多层堆栈进行拼接得到。随着层数的减少,每层输出的维度保持一致,确保最终隐藏表示的信息完备性和有效性。
这种设计使得编码器能够在有限的内存条件下高效处理长序列输入,并通过蒸馏和金字塔结构保留重要特征,同时避免信息丢失。
EncoderStack结构介绍
作者为了提高encoder的鲁棒性,还提出了一个strick。上面的Encoder是主stack,输入整个embedding后经过了三个Attention Block,最终得到Feature Map。
还可以再复制一份具有一半输入的embedding(直接取96个时间点的后48个),让它让经过两个Attention Block(标注处理流程是“similar operation”也就是相同的处理流程),最终会得到和上面维度相同的Feature Map,然后把两个Feature Map拼接。作者认为这种方式对短周期的数据可能更有效一些。
输入:32 × \times × 8 × \times × 96 × \times × 512
输出:32 × \times × 8 × \times × 48 × \times × 512
论文中提出的EncoderStack 其实是由多个Encoder 和蒸馏层组合而成的

那么我们来详细解释一下上面的这张图。
1.每个水平stack代表一个单独的Encoder Module;
啥意思呢?
也就是说,下面用红色笔圈出来的这一坨是第一个stack
而剩下那部分是第二个stack
下面的stack还写了similar operation

2.上面的stack是主stack,它接收整个输入序列,而第二个stack取输入的一半,并且第二个stack扔掉一层自我注意蒸馏层的数量,使这两个stack的输出维度使对齐的;
这句话的意思是,红色圈圈的部分中输入减半,作为第二个stack的输入。(这里减半的处理方法就是直接用96个时间点的后48个得到一半)


3.红色层是自我注意机制的点积矩阵,通过对各层进行自我注意蒸馏得到级联降低;
这一句说的就是蒸馏的操作了,也就是上面手画图例的convLayer,还是通过一维卷积来进行蒸馏的。
4.连接2个stack的特征映射作为编码器的输出。
最后很简单,把手画图里的Encoder1 和 Encoder2 25和26的输出连接起来,就能得到最终的51维输出了。(这里的51或许还是因为卷积取整,导致这个数看起来不太整)

有下面的热力图发现,使用这样的注意力机制和Encoder结构,特征更为明显且与之前的模式基本一致。

4. Decoder

解码器:通过一次前向过程生成长序列输出
解码器采用了标准的结构(Vaswani等,2017),如图2所示,由两层相同的多头注意力层堆叠而成。然而,在长序列预测中,我们采用了一种生成式推理方法,以缓解长序列预测中速度的下降问题。
我们将解码器输入如下向量:
X de t = Concat ( X token t , X 0 t ) ∈ R ( L token + L y ) × d model X^t_{\text{de}} = \text{Concat}(X^t_{\text{token}}, X^t_0) \in \mathbb{R}^{(L_{\text{token}} + L_y) \times d_{\text{model}}} Xdet=Concat(Xtokent,X0t)∈R(Ltoken+Ly)×dmodel
其中, X token t ∈ R L token × d model X^t_{\text{token}} \in \mathbb{R}^{L_{\text{token}} \times d_{\text{model}}} Xtokent∈RLtoken×dmodel 是起始标记(start token), X 0 t ∈ R L y × d model X^t_0 \in \mathbb{R}^{L_y \times d_{\text{model}}} X0t∈RLy×dmodel 是目标序列的占位符(值设为0)。在ProbSparse自注意力计算中,应用了遮掩多头注意力机制(masked multi-head attention),通过将遮掩的点积值设为 − ∞ -\infty −∞ 来防止每个位置关注到未来的时刻位置,从而避免自回归问题。最后,通过全连接层获取最终输出,其输出维度 d y d_y dy 取决于我们执行的是单变量预测还是多变量预测。
生成式推理

Decoder的输入如下:
在 Informer 模型的解码器中,输入序列由两部分拼接而成:起始标记(Start Token) 和 预测序列占位符,分别对应 X token X_{\text{token}} Xtoken 和 X 0 X_0 X0。
解码器的输入可以表示为:
X de = { X token , X 0 } X_{\text{de}} = \{ X_{\text{token}}, X_0 \} Xde={Xtoken,X0}
- X token ∈ R L token × d model X_{\text{token}} \in \mathbb{R}^{L_{\text{token}} \times d_{\text{model}}} Xtoken∈RLtoken×dmodel:表示开始的 token(起始标记),即已知的序列片段。它通常选取预测序列之前的一段已知序列,例如过去的几天的温度数据。
- X 0 ∈ R L y × d model X_0 \in \mathbb{R}^{L_y \times d_{\text{model}}} X0∈RLy×dmodel:表示预测序列的占位符,其维度与目标预测序列一致,初始化时通常用 0 填充。
如果我们想要预测7天的温度,decoder就需要输入前面1-7天的温度,后面用0填充8-14天需要预测的温度的位置,这就是一种Mask的机制。
-
已知的温度数据(Start Token, X token X_{\text{token}} Xtoken):
- 例如,在预测未来 7 天的温度时,我们可以使用前 48 个时间步的已知温度数据作为起始标记。这些数据包含了历史的上下文信息,为解码器提供了预测未来值的重要依据。
- 因此, X token X_{\text{token}} Xtoken 的维度为 48 × d model 48 \times d_{\text{model}} 48×dmodel。
-
预测序列的占位符( X 0 X_0 X0):
- 对于未来 7 天的预测,我们需要一个长度为 24 个时间步的占位符,这些占位符的初始值设为 0。这些 0 值会被逐渐替换为模型的预测结果。
- X 0 X_0 X0 的维度为 24 × d model 24 \times d_{\text{model}} 24×dmodel。
因此,解码器的输入序列 X de X_{\text{de}} Xde 的整体维度为:
X de ∈ R ( 48 + 24 ) × d model = R 72 × d model X_{\text{de}} \in \mathbb{R}^{(48 + 24) \times d_{\text{model}}} = \mathbb{R}^{72 \times d_{\text{model}}} Xde∈R(48+24)×dmodel=R72×dmodel
这种输入方式适用于长序列时间序列预测,尤其是在处理长时间段的数据时,它能够有效减少计算时间,并且可以一次性输出整个预测序列。

起始标记在自然语言处理中的“动态解码”(Devlin等,2018)中已被高效应用,我们将其扩展为生成式推理方式。与选择特定的标记作为token不同,我们从输入序列中采样长度为 L token L_{\text{token}} Ltoken 的子序列,例如从输出序列之前的某段已知数据中选择。
例如,在预测168个点(实验中为7天的温度预测)时,我们会选择目标序列之前的已知5天数据作为“start-token”,并将生成式推理解码器的输入设置为 X de = { X 5d , X 0 } X_{\text{de}} = \{X_{\text{5d}}, X_0\} Xde={X5d,X0},其中 X 0 X_0 X0 包含目标序列的时间戳,即目标周的上下文信息。这样,解码器可以通过一次前向过程生成预测输出,而无需像传统的编码器-解码器架构那样进行耗时的“动态解码”。
损失函数
我们选择均方误差(MSE)损失函数,用于对目标序列的预测进行优化。损失从解码器的输出开始,反向传播回整个模型中。
主要要点:
- 遮掩多头注意力:在ProbSparse自注意力计算中,遮掩未来的时间步,防止自回归。
- 生成式推理:采用一个起始标记(start token)作为输入,通过一次前向推理生成整个输出,避免了动态解码的开销。
- 损失函数:使用MSE损失函数进行优化,针对目标序列的预测。
这种生成式解码器设计,能够在保持高效计算的同时,处理长序列的生成问题,从而在长时间序列预测任务中表现优异。
三、文章难点部分理解
1. 如何理解注意力的概率形式
A ( q i , K , V ) = ∑ j k ( q i , k j ) ∑ l k ( q i , k l ) v j = E p ( k j ∣ q i ) [ v j ] A(q_i, K, V) = \sum_j \frac{k(q_i, k_j)}{\sum_l k(q_i, k_l)} v_j = E_{p(k_j | q_i)}[v_j] A(qi,K,V)=j∑∑lk(qi,kl)k(qi,kj)vj=Ep(kj∣qi)[vj]
其中:
- A ( q i , K , V ) A(q_i, K, V) A(qi,K,V):表示第 i i i 个查询 q i q_i qi 通过注意力机制得到的输出。
- k ( q i , k j ) k(q_i, k_j) k(qi,kj):是查询 q i q_i qi 与键 k j k_j kj 之间的 核函数,用来衡量它们的相似性。
- ∑ j \sum_j ∑j:是对所有键 k j k_j kj 进行求和操作。
我们将这段公式分成几个部分来进行详细分析:
1. 核函数 k ( q i , k j ) k(q_i, k_j) k(qi,kj)
核函数 k ( q i , k j ) k(q_i, k_j) k(qi,kj) 用来衡量 查询 q i q_i qi 和 键 k j k_j kj 之间的相似性。它的具体形式为:
k ( q i , k j ) = exp ( q i k j ⊤ d ) k(q_i, k_j) = \exp\left(\frac{q_i k_j^\top}{\sqrt{d}}\right) k(qi,kj)=exp(dqikj⊤)
- 点积计算: q i k j ⊤ q_i k_j^\top qikj⊤ 表示查询 q i q_i qi 和键 k j k_j kj 之间的点积,衡量它们的相似度。
- 缩放因子:除以 d \sqrt{d} d 是为了防止点积的数值过大,确保模型的数值稳定。
- 指数映射:使用 exp ( ⋅ ) \exp(\cdot) exp(⋅) 将相似度映射到非负值,使得相似性得分越大,对应的指数值也越大,这样能够更好地用于注意力加权。
2. 注意力概率 p ( k j ∣ q i ) p(k_j | q_i) p(kj∣qi)
注意力分数 p ( k j ∣ q i ) p(k_j | q_i) p(kj∣qi) 是基于查询和键的相似性来定义的一个 概率分布,表示为:
p ( k j ∣ q i ) = k ( q i , k j ) ∑ l k ( q i , k l ) p(k_j | q_i) = \frac{k(q_i, k_j)}{\sum_l k(q_i, k_l)} p(kj∣qi)=∑lk(qi,kl)k(qi,kj)
- 分子部分: k ( q i , k j ) k(q_i, k_j) k(qi,kj) 是查询和键之间的相似性。
- 分母部分:对所有键的相似性求和,以将分子部分标准化,使得所有键的相似度和为 1,类似于 Softmax 操作。
这个 p ( k j ∣ q i ) p(k_j | q_i) p(kj∣qi) 表示 查询 q i q_i qi 下对应 键 k j k_j kj 的注意力概率。通过这个概率,模型可以决定如何对不同的值进行加权。
3. 加权求和值
接下来,我们通过注意力概率对值向量进行加权求和:
A ( q i , K , V ) = ∑ j p ( k j ∣ q i ) v j = ∑ j k ( q i , k j ) ∑ l k ( q i , k l ) v j A(q_i, K, V) = \sum_j p(k_j | q_i) v_j = \sum_j \frac{k(q_i, k_j)}{\sum_l k(q_i, k_l)} v_j A(qi,K,V)=j∑p(kj∣qi)vj=j∑∑lk(qi,kl)k(qi,kj)vj
- 加权求和:每个 值向量 v j v_j vj 都通过 注意力概率 p ( k j ∣ q i ) p(k_j | q_i) p(kj∣qi) 进行加权,然后将所有加权后的值向量进行求和,得到输出。
- 这个加权和表示了第 i i i 个查询 q i q_i qi 对应的所有值 V V V 的线性组合,其中的权重由查询与键的相似性决定。
4. 自注意力作为期望值的表示
最后,将注意力的计算表示为一个 期望值:
A ( q i , K , V ) = E p ( k j ∣ q i ) [ v j ] A(q_i, K, V) = E_{p(k_j | q_i)}[v_j] A(qi,K,V)=Ep(kj∣qi)[vj]
- 这里的期望值表示 查询 q i q_i qi 在 概率分布 p ( k j ∣ q i ) p(k_j | q_i) p(kj∣qi) 下对 值 v j v_j vj 的期望。
- 换句话说,自注意力机制可以理解为:给定一个查询 q i q_i qi,根据它与每个键的相似性来构建一个概率分布,然后在这个概率分布下对所有值进行加权求和,得到一个期望值。
注:期望公式:
对于离散随机变量 X X X,其取值为 x 1 , x 2 , … , x n x_1, x_2, \dots, x_n x1,x2,…,xn,对应的概率为 P ( X = x i ) = p i P(X = x_i) = p_i P(X=xi)=pi,则期望 E [ X ] E[X] E[X] 定义为:
E [ X ] = ∑ i x i ⋅ p i E[X] = \sum_{i} x_i \cdot p_i E[X]=i∑xi⋅pi
直观理解
这段公式描述了自注意力机制的核心思想:给定一个 查询 q i q_i qi,模型会计算它与所有 键 k j k_j kj 的相似度,通过相似度的相对大小计算一个概率分布,最后根据这个概率分布对所有 值 v j v_j vj 进行加权求和,得到输出。这样的过程可以看作是对所有值的一个 加权平均,权重由查询和键之间的相似性决定。
-
查询、键和值的关系:查询用来发起问题,键用来匹配问题的相关性,值则是需要综合的信息。通过注意力机制,模型会对查询关注的键进行匹配,并用匹配到的相关键来影响值的加权求和。
-
期望表示:这种概率分布的期望值表示方式有助于理解注意力机制的本质,即它是一种基于相似性关系的加权平均。它通过计算出一个概率分布,再根据该分布对所有值进行加权求和,最终得到的结果会更加倾向于那些与查询最相关的部分。
2. Kullback-Leibler 散度
Kullback-Leibler 散度(简称 KL 散度,也称为 相对熵)是一种用来衡量两个概率分布之间差异的非对称度量。KL散度最常用于信息论和机器学习中,来比较一个“真实”分布和一个“估计”分布的相似度。它描述了从一个概率分布 Q Q Q 到另一个概率分布 P P P 的信息损失。
D K L ( P ∥ Q ) = ∑ x P ( x ) log P ( x ) Q ( x ) D_{KL}(P \parallel Q) = \sum_{x} P(x) \log \frac{P(x)}{Q(x)} DKL(P∥Q)=x∑P(x)logQ(x)P(x)
或者在连续情况下:
D K L ( P ∥ Q ) = ∫ P ( x ) log P ( x ) Q ( x ) d x D_{KL}(P \parallel Q) = \int P(x) \log \frac{P(x)}{Q(x)} \, dx DKL(P∥Q)=∫P(x)logQ(x)P(x)dx
这里:
- P ( x ) P(x) P(x) 表示真实的概率分布。
- Q ( x ) Q(x) Q(x) 表示近似的概率分布。
- log P ( x ) Q ( x ) \log \frac{P(x)}{Q(x)} logQ(x)P(x) 表示两个概率之间的信息差异。
KL 散度衡量的是如果用分布 Q Q Q 来近似分布 P P P,需要付出的信息损失是多少。它的单位是“比特”(如果使用以 2 为底的对数)或者“nat”(如果使用自然对数)。
- 当 P P P 和 Q Q Q 很接近时,KL 散度的值会很小。
- 当 P P P 和 Q Q Q 相差很大时,KL 散度的值会变得很大。
KL 散度是非负的,即 D K L ( P ∥ Q ) ≥ 0 D_{KL}(P \parallel Q) \geq 0 DKL(P∥Q)≥0,且当且仅当 P = Q P = Q P=Q 时,KL 散度为零。值得注意的是,KL 散度不是对称的,即 D K L ( P ∥ Q ) ≠ D K L ( Q ∥ P ) D_{KL}(P \parallel Q) \neq D_{KL}(Q \parallel P) DKL(P∥Q)=DKL(Q∥P)。
文章中的推导
在自注意力机制中,查询 ( q i q_i qi) 对所有键 ( k j k_j kj) 的注意力权重 p ( k j ∣ q i ) p(k_j|q_i) p(kj∣qi) 定义为一个概率分布。输出结果是查询与对应值 ( v j v_j vj) 的组合。具体来说,查询和键的点积通过 softmax 函数转化为注意力权重分布。这个过程通过衡量查询与键之间的相似性来计算权重分布。
如果 p ( k j ∣ q i ) p(k_j|q_i) p(kj∣qi) 接近于均匀分布 q ( k j ∣ q i ) = 1 L K q(k_j|q_i) = \frac{1}{L_K} q(kj∣qi)=LK1,那么自注意力机制将会变得“冗余”,因为输出将趋向于所有值的简单加权和。为了衡量查询的重要性,我们使用 KL 散度来测量注意力分布 p p p 和均匀分布 q q q 之间的相似度。
KL散度的推导
KL散度的一般形式为:
D K L ( q ∥ p ) = ∑ j = 1 L K q ( k j ∣ q i ) log q ( k j ∣ q i ) p ( k j ∣ q i ) D_{KL}(q \parallel p) = \sum_{j=1}^{L_K} q(k_j|q_i) \log \frac{q(k_j|q_i)}{p(k_j|q_i)} DKL(q∥p)=j=1∑LKq(kj∣qi)logp(kj∣qi)q(kj∣qi)
由于 q ( k j ∣ q i ) = 1 L K q(k_j|q_i) = \frac{1}{L_K} q(kj∣qi)=LK1 是均匀分布,带入 KL 散度公式得到:
D K L ( q ∥ p ) = 1 L K ∑ j = 1 L K log 1 L K p ( k j ∣ q i ) D_{KL}(q \parallel p) = \frac{1}{L_K} \sum_{j=1}^{L_K} \log \frac{\frac{1}{L_K}}{p(k_j|q_i)} DKL(q∥p)=LK1j=1∑LKlogp(kj∣qi)LK1
通过对 log 1 L K \log \frac{1}{L_K} logLK1 进行展开:
D K L ( q ∥ p ) = 1 L K ∑ j = 1 L K ( − log L K − log p ( k j ∣ q i ) ) D_{KL}(q \parallel p) = \frac{1}{L_K} \sum_{j=1}^{L_K} \left( - \log L_K - \log p(k_j|q_i) \right) DKL(q∥p)=LK1j=1∑LK(−logLK−logp(kj∣qi))
= − log L K − 1 L K ∑ j = 1 L K log p ( k j ∣ q i ) = - \log L_K - \frac{1}{L_K} \sum_{j=1}^{L_K} \log p(k_j|q_i) =−logLK−LK1j=1∑LKlogp(kj∣qi)
定义查询的稀疏性度量 M ( q i , K ) M(q_i, K) M(qi,K)
我们通过 Log-Sum-Exp(LSE)函数来定义注意力概率分布的稀疏性度量。稀疏性度量 M ( q i , K ) M(q_i, K) M(qi,K) 的第一部分是 LSE,用来捕捉注意力分布的“峰值”,而第二部分是对所有键的注意力权重的算术平均。
稀疏性度量 M ( q i , K ) M(q_i, K) M(qi,K) 的表达式为:
M ( q i , K ) = log ∑ j = 1 L K exp ( q i k j T d ) − 1 L K ∑ j = 1 L K q i k j T d M(q_i, K) = \log \sum_{j=1}^{L_K} \exp \left( \frac{q_i k_j^T}{\sqrt{d}} \right) - \frac{1}{L_K} \sum_{j=1}^{L_K} \frac{q_i k_j^T}{\sqrt{d}} M(qi,K)=logj=1∑LKexp(dqikjT)−LK1j=1∑LKdqikjT
- 第一项是 Log-Sum-Exp,代表了查询 q i q_i qi 与所有键 k j k_j kj 的点积分数的加权指数和的对数。
- 第二项是这些点积分数的算术平均。
通过 M ( q i , K ) M(q_i, K) M(qi,K),我们可以识别出那些具有较大稀疏性的查询,也就是那些注意力权重分布更“分散”的查询。较大的 M ( q i , K ) M(q_i, K) M(qi,K) 意味着该查询的注意力分布可能包含主导的点积对,从而在注意力机制中具有更大的重要性。
3. LSE公式近似
Log-Sum-Exp(LSE)是常用于自注意力机制中的一项操作,它是一个平滑的最大化操作,用于增强较大值的贡献。对于查询 q i q_i qi 和键 K K K 的LSE定义如下:
LSE ( q i , K ) = ln ( ∑ j = 1 L K e q i k j ⊤ d ) \text{LSE}(q_i, K) = \ln \left( \sum_{j=1}^{L_K} e^{\frac{q_i k_j^\top}{\sqrt{d}}} \right) LSE(qi,K)=ln(j=1∑LKedqikj⊤)
然而,LSE操作的计算复杂度为 O ( L K ) O(L_K) O(LK),在处理大规模数据或长序列时,计算成本较高。因此,我们通常需要对LSE进行近似来降低计算复杂度。
LSE常常近似为输入中的最大值,因为在Log-Sum-Exp的计算中,最大值项对总和起主导作用,而较小的指数项会趋近于0。此时,LSE可以近似为:
LSE ( q i , K ) ≈ max j { q i k j ⊤ d } \text{LSE}(q_i, K) \approx \max_j \left\{ \frac{q_i k_j^\top}{\sqrt{d}} \right\} LSE(qi,K)≈jmax{dqikj⊤}
这是因为在求和操作中,指数函数会显著放大较大的值,较小的值在总和中的贡献可以忽略不计。因此,取最大项作为近似,可以显著减少计算量。
4. 自注意力蒸馏公式解析
公式:
X j + 1 t = MaxPool ( ELU ( Conv1d ( [ X j t ] AB ) ) ) X_{j+1}^t = \text{MaxPool}\left(\text{ELU}\left(\text{Conv1d}\left([X_j^t]_{\text{AB}}\right)\right)\right) Xj+1t=MaxPool(ELU(Conv1d([Xjt]AB)))
这是编码器中的自注意力蒸馏操作的一步。下面我们逐步详细解释这个公式的各个部分:
1. 输入: [ X j t ] AB [X_j^t]_{\text{AB}} [Xjt]AB
X j t X_j^t Xjt 是第 j j j 层第 t t t 个序列输入,表示这一层的输入矩阵。这个输入经过一个注意力块,表示为 [ X j t ] AB [X_j^t]_{\text{AB}} [Xjt]AB,其中的 AB 是指Attention Block(注意力块),这个块通常包括多头ProbSparse自注意力机制及相关的操作。
2. Conv1d (一维卷积)
Conv1d ( [ X j t ] AB ) \text{Conv1d}([X_j^t]_{\text{AB}}) Conv1d([Xjt]AB)
该部分对经过注意力块处理后的输入进行一维卷积操作。Conv1d 是一个一维卷积函数,它沿着时间维度(通常是序列的长度方向)应用卷积核。在这个场景中,卷积核的大小(宽度)为3,即在时间维度上,卷积操作会关注当前时间步及其前后各一个时间步。
作用:
- 提取序列在时间维度上的局部特征。
- 增强特征的表达能力,使得编码器能够更好地捕捉输入中局部的时序依赖。
3. ELU (指数线性单元)
ELU ( ⋅ ) \text{ELU}(·) ELU(⋅)
卷积后的结果通过ELU激活函数进行非线性变换。ELU(Exponential Linear Unit)是一种常用的激活函数,其定义为:
ELU ( x ) = { x , x > 0 α ( e x − 1 ) , x ≤ 0 \text{ELU}(x) = \begin{cases} x, & x > 0 \\ \alpha(e^x - 1), & x \leq 0 \end{cases} ELU(x)={x,α(ex−1),x>0x≤0
其中, α \alpha α 是一个参数,通常默认为1。ELU 与常用的 ReLU 激活函数类似,但它在 x ≤ 0 x \leq 0 x≤0 时更平滑,有助于防止梯度消失问题,并加速模型的训练。
作用:
- 引入非线性,使得模型能够学习复杂的特征。
- ELU 相比于 ReLU 具有更好的收敛速度和梯度稳定性。
4. MaxPool (最大池化)
MaxPool ( ⋅ ) \text{MaxPool}(·) MaxPool(⋅)
池化层通常用于减少数据的尺寸,减少计算量,并提高模型的鲁棒性。在这里,**最大池化(Max Pooling)**操作对数据进行下采样,选择局部窗口内的最大值作为输出。通常的窗口大小为2,步幅也是2,表示它将每两个时间步合并为一个时间步。
作用:
- 减少输入的时间维度大小,将序列长度减少一半。
- 保留序列中的显著特征,并减少冗余信息。
- 降低计算复杂度和内存使用量。
5. 输出: X j + 1 t X_{j+1}^t Xj+1t
经过上述操作后,输出为 X j + 1 t X_{j+1}^t Xj+1t,即第 j + 1 j+1 j+1 层第 t t t 个序列的输入。通过这些卷积、激活函数和池化操作,时间维度的输入被大幅减少,保留了重要的特征,同时消除了冗余。
相关文章:
informer学习笔记
一、informer讲解 infomer 要解决的三大问题: Attention计算的更快Decoder要一次性输出所有预测堆叠encoder也要更快 1. Attention 在长序列中,并非每一个位置的Attention都重要,对于每一个Q来说,只有一小部分的K与其有较强的…...

Elasticsearch介绍和使用
一、Elasticsearch 强大的搜索和分析能力: Elasticsearch 是一个基于 Lucene 的分布式搜索和分析引擎。它能够快速地对大量数据进行全文搜索、结构化搜索和复杂的数据分析操作。对于大型数据集,它可以高效地处理各种查询需求,包括关键词搜索…...

【Flutter】基础入门:代码基本结构
通过这个简单的 Flutter 示例程序,我们可以快速了解 Flutter 的代码结构,理解每个部分的作用。 import package:flutter/material.dart; void main() { runApp(const MyApp()); } class MyApp extends StatelessWidget { const MyApp({super.key}…...

如何进行数据库缩容 | OceanBase应用实践
作者:关炳文,爱可生 DBA 团队成员,负责数据库相关技术支持。 本文详细介绍了OceanBase V3.2版的集群中,面对数据文件缩容的场景的一套缩容方案,作为大家的参考。 缩容场景 某银行运行的一套采用1-1-1架构的OceanBase…...

机器学习和深度学习的差别
定义和基本原理 机器学习: 定义:机器学习是一种让计算机自动从数据中学习规律和模式的方法,无需明确编程。它通过构建数学模型,利用已知数据进行训练,然后对新的数据进行预测或决策。基本原理:机器学习算…...

RAG拉满-上下文embedding与大模型cache
无论怎么选择RAG的切分方案,仍然切分不准确。 最近,anthropics给出了补充上下文的embedding的方案,RAG有了新的进展和突破。 从最基础的向量查询,到上下文embedding,再到rerank的测试准确度都有了明显的改善…...
CSS基础)
前端学习---(2)CSS基础
CSS 用来干什么? CSS 是用来指定文档如何展示给用户的一门语言——如网页的样式、布局、等等。 css语法: 选择器{ 属性名: 属性值; 属性名: 属性值; } h1 {color: red;font-size: 5em; }h1: 选择器 color: 属性 冒号之前是属性,冒号之后是值。 font-size…...
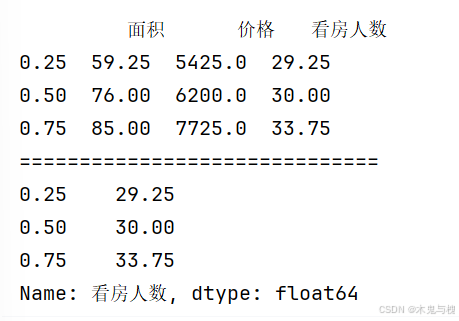
Pandas常用计算函数
目录 排序函数 nlargest函数 nsmallest函数 sort_values函数 df.sort_values Series.sort_values 聚合函数 corr函数-相关性 min函数-最小值 max函数-最大值 mean函数-平均值 sum函数-求和 count函数-统计非空数据 std函数-标准偏差 quantile函数-分位数 排序函…...

C++ | Leetcode C++题解之第473题火柴拼正方形
题目: 题解: class Solution { public:bool makesquare(vector<int>& matchsticks) {int totalLen accumulate(matchsticks.begin(), matchsticks.end(), 0);if (totalLen % 4 ! 0) {return false;}int len totalLen / 4, n matchsticks.s…...

深度解析RLS(Recursive Least Squares)算法
目录 一、引言二、RLS算法的基本思想三、RLS算法的数学推导四、RLS算法的特点五、RLS算法的应用场景六、RLS算法的局限性七、总结 一、引言 在自适应滤波领域,LMS(Least Mean Squares)算法因其计算简单、实现方便而广受欢迎。然而࿰…...

Centos 7.9NFS搭建
原创作者:运维工程师 谢晋 Centos 7.9NFS搭建 NFS服务端安装客户机访问共享配置 NFS服务端安装 SSH连接系统登录到服务端安装nfs服务 # yum -y install nfs-utils2. 安装完成后,查看需要共享的目录,这边共享的是/home目录,如…...

Python库numpy之三
Python库numpy之三 # NumPy数组创建函数二维数组创建函数numpy.eye应用例子numpy.diag应用例子numpy.vander应用例子 # NumPy数组创建函数 二维数组创建函数 numpy.eye 词法:numpy.eye(N, MNone, k0, dtype<class ‘float’>, order‘C’, *, deviceNone, …...

postgresql 安装
一、下载 PostgreSQL: File Browser 下载地址 PostgreSQL: File Browser 上传到服务器,并解压 二、安装依赖 yum install -y perl-ExtUtils-Embed readline-devel zlib-devel pam-devel libxml2-devel libxslt-devel openldap-devel 创建postgresql 和目录 useradd …...

基于机器学习的天气数据分析与预测系统
天气预报是日常生活中非常重要的信息来源,能够帮助人们合理安排日程、预防自然灾害。随着数据科学和机器学习的快速发展,传统的天气预报方法逐渐向基于数据驱动的机器学习方法转变。本文将探讨如何构建一个基于机器学习的天气数据分析与预测系统…...

Java项目-基于Springboot的在线外卖系统项目(源码+说明).zip
作者:计算机学长阿伟 开发技术:SpringBoot、SSM、Vue、MySQL、ElementUI等,“文末源码”。 开发运行环境 开发语言:Java数据库:MySQL技术:SpringBoot、Vue、Mybaits Plus、ELementUI工具:IDEA/…...

ANSYS Workbench纤维混凝土3D
在ANSYS Workbench建立三维纤维混凝土模型可采用CAD随机几何3D插件建模后导入,模型包含球体粗骨料、圆柱体长纤维、水泥砂浆基体等不同组分。 在CAD随机几何3D插件内设置模型参数后运行,即可在AutoCAD内建立三维纤维混凝土模型,插件支持任意…...

【Vue】Vue3.0(十)toRefs()和toRef()的区别及使用示例
上篇文章:Vue】Vue(九)OptionsAPI与CompositionAPI的区别 🏡作者主页:点击! 🤖Vue专栏:点击! ⏰️创作时间:2024年10月15日11点13分 文章目录 toRefs()和toRe…...
——使用随机森林方法进行土地分类)
中科星图(GVE)——使用随机森林方法进行土地分类
目录 简介 函数 gve.Classifier.smileRandomForest(numberOfTrees,variablesPerSplit,minLeafPopulation,bagFraction,maxNodes,seed) 代码 结果 简介 使用随机森林方法进行土地分类的步骤如下: 数据准备:收集所需的土地分类数据,并对数…...

【蓝队技能】【C2流量分析】MSFCSSliver
蓝队技能 MSF&CS&Sliver 蓝队技能总结前言一、MSF1.1 流量分析1.2 特征提取 二、CS1.1 流量分析1.2 特征提取 二、Sliver1. 特征分析 总结 前言 不同C2工具的流量特征都有细微差别,学会分析方法后就可以进行分析 一、MSF 1.1 流量分析 MSF流量特征过于明显…...

不推荐使用Scilab作为MATLAB的开源替代
安装了Scilab2024.1.0,随便试了几分钟就发现有严重影响使用的Bug(也可能是就是这样设计的,有一个所谓的“暂停模式”),复现步骤:主界面上点击“Scilab示例”按钮,打开“演示”窗口,点击左侧列表中的“多项式…...

政企数据安全:危机与出路
随着数字化转型的浪潮席卷全球,公共部门积累的数据量呈爆炸式增长。从公民个人信息到公共服务记录,从财政预算到基础设施管理数据——这些宝贵资源在提升政府治理效率的同时,也悄然成为网络犯罪分子的“新猎物”。当公共数据逐渐成为数字时代…...

千亿镁合金产业集群正在成形:成都、抚州、池州的新版图
一个新赛道的地理坐标 如果要在中国地图上标注一条正在成形的新兴产业集群走廊,高强镁合金这条线,值得被认真画出来。 成都龙泉驿——江西抚州临川——安徽池州高新区,三个坐标,三条生产线,一家公司,两年内…...

搞定这 5 个全栈电商项目,面试别再用 Todo-List 凑数了
找独立开发练手项目或者写简历项目时,最忌讳两件事:一是太简单(纯前端 Mock 数据,点两下就没了),二是太假(一上来就硬套微服务、消息队列、高并发,结果自己根本Hold不住)…...

2026 文章代码高亮方案选型
将基于 Prism.js 或 Highlight.js 的传统高亮方案与基于 Shiki 的现代化高亮方案进行对比,其核心区别在于底层解析原理的不同(正则表达式 vs. TextMate 语法树)。 以下是两种方案的底层原理、各自优缺点、核心对比矩阵以及适用场景的详细分析…...

Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参
Gazebo Sim多旋翼控制:四轴飞行器动力学建模与PID调参 【免费下载链接】gz-sim Open source robotics simulator. The latest version of Gazebo. 项目地址: https://gitcode.com/gh_mirrors/gz/gz-sim Gazebo Sim是一款功能强大的开源机器人模拟器ÿ…...

如何快速解锁艾尔登法环帧率限制:终极性能优化指南
如何快速解锁艾尔登法环帧率限制:终极性能优化指南 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/EldenR…...

【python】ImportError: DLL load failed while importing QtWidgets: 找不到指定的程序。重新安装后搞定
文章目录前言一、PyQt6引用后报错二、使用步骤总结前言 想做个好看的界面,引用了PyQt6,却产生了新问题。 pip install pyqt6-tools,优先做这个动作进行修复。 一、PyQt6引用后报错 python里引用: from PyQt6.QtWidgets import…...

解决方法:庐山派K230接串口没识别到端口问题
一、插入usb转串口工具之前二、插入usb转串口工具之后三、解决方法说明:🔍 核心原因:USB Serial 设备,没有被识别为 COM 口你现在看到的 USB Serial,说明开发板已经正常启动了,USB 也被电脑识别到了&#x…...

在Node.js服务中集成Taotoken实现稳定的大模型能力调用
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Node.js服务中集成Taotoken实现稳定的大模型能力调用 对于需要在后端服务中集成AI功能的Node.js开发者而言,直接对接…...

别再乱建索引了!用Explain的key_len字段,一眼看穿你的MySQL联合索引到底生效了几个字段
解密MySQL联合索引:用key_len精准判断索引生效范围 在数据库性能优化领域,联合索引的使用一直是个既基础又容易踩坑的话题。很多开发者虽然知道"最左匹配原则"这个名词,但在实际业务场景中,面对复杂的查询条件组合时&a…...