python 爬虫 入门 二、数据解析(正则、bs4、xpath)
目录
一、待匹配数据获取
二、正则
三、bs4
(一)、访问属性
(二)、获取标签的值
(三)、查询方法
四、xpath
后续:登录和代理
上一节我们已经知道了如何向服务器发送请求以获得数据,今天我们就来学习如何从获得的数据中找到自己需要的东西,使用数据解析的三种工具:正则、bs4、xpath。
一、待匹配数据获取
我们今天来试试国家数据网页,尝试获取下面这个框里面所有链接的url。


我们先右键网页,查看页面源代码(ps:F12元素里面的代码是网页的实时代码,和源代码有差异。)然后Ctrl+F搜索: 2020年投入产出表,可以看到有结果,前面的超链接就是我们需要的url。这表明数据是直接在网页源码中的,而不是通过脚本二次请求服务器生成的,可以直接通过页面源码找到。

接下来,使用上一节的代码来获取页面源代码。
import requestsurl = "https://data.stats.gov.cn/"
headers = {# 用户代理,某些网站验证用户代理,微微改一下,如果提示要验证码之类的,使用它"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0",
}
with requests.get(url=url, headers=headers,) as resp:resp.encoding = "utf-8"print(resp)with open("国家数据.html", mode="w",encoding="utf-8") as f:f.write(resp.text) # 读取到网页的页面源代码"我们下面的操作就只读取下载的html文件,而不反复请求服务器。
二、正则
使用正则表达式来匹配数据在很多python基础中都有,速度快,能适应复杂的需求,但是复杂的正则表达式不好写,难维护,容易出错。不过那些大语言模型写正则是一把好手。这里主要爬虫,关于正则表达式,给几个表看一看,用用就会了。这里贴一下python文档链接和几个表以待后续查看:正则表达式指南 — Python 3.11.10 文档
import re # 正则
| findall() | 以列表形式返回所有满足数据,没有返回空列表 |
| finditer() | 返回所有匹配结果的迭代器,建议使用for+group提取 |
| search() | 返回第一个匹配结果的match对象,使用group提取,没有返回None |
| match() | 从头开始匹配,返回match对象。 相当于在正则表达式前面加了^,没有返回None |
| compile() | 预加载正则表达式 |
| 量词 | 意义 |
| * | 0~∞次 |
| + | 1~∞次 |
| ? | 0~1次 |
| {n} | n次 |
| {n,} | n~∞次 |
| {n,m} | n~m次 |
| 元字符 | 意义 |
| . | 换行符以外任意字符 |
| \w | 字母数字下划线 |
| \s | 空白字符(空格 换行符 制表符) |
| \d | 数字 |
| \W | 非字母数字下划线 |
| \S | 非空白字符 |
| \D | 非数字 |
| \n | 换行符 |
| \t | 制表符 |
| ^ | 字符串开始 |
| $ | 字符串结尾 |
| a|b | 字符a或字符b |
| () | 匹配括号内的表达式 |
| [abc] | 匹配字符a或b或c |
| [^abc] | 匹配除了a、b、c的字符 |
| 规则 | 意义 |
| re.I | 忽略大小写 |
| re.L | 不建议使用,改用re.U |
| re.M | 多行匹配 |
| re.S | 令 . 可以匹配换行符 |
| re.U | 使用unicode字符集 |
| re.X | 忽略匹配表达式中的空白符和#,除非加\,令你可以在正则表达式中加注释 |
一个小细节,.*会贪婪匹配,越多越好,.*?会非贪婪匹配越少越好
好,基础知识都在上面,现在我们来尝试匹配网页吧。 通过在网页中查看,我们发现需要获取的url前后有<li><a href="和.+产出表</a><span>,所以我们可以根据这一点来写正则表达式,最终形成如下代码:
import re
path = "国家数据.html"
with open(path,mode="r", encoding="utf-8") as f: # 下载源码data = f.read()
regular = re.compile(r'<li><a href="(?P<url>.*)">(?P<year>.*)投入产出表</a><span>')
result_1 = regular.findall(data)
result_2 = regular.finditer(data)
result_3 = regular.search(data)
result_4 = regular.match(data)
print(result_1)
for i in result_2:print(i.group())print(i.group("url"))print(i.group("year"))
print(result_3.group())
print(result_4)这里面()划定了一个组,而?P<name>给组起了一个名字,结果如下:


finditer返回的迭代器是我最常用,也是我觉着最好用的。
三、bs4
bs4全称beautifulsoup4。它主要是创建解析树,用来导航、搜索、修改HTML和XML文档,效率可能比其他的略低,但比较健壮,不易出错。
from bs4 import BeautifulSoup # bs

基础用法就是先使用 bs = BeautifulSoup(data, "html.parser") 将html代码交给bs4处理为树形结构,然后在得到的bs对象中查找需要的数据。
处理后数据是一个BeautifulSoup,即文档,文档中有许多tag(标签),标签也能够包含标签,就像上图的<div>、<a>、<li>一样。我们可以通过bs.ul来访问第一个ul标签。有的标签具有属性,像是最外层的div标签就有id属性、第一个a有href属性一样。可以像是访问字典一样,通过bs.ul.li.a["href"]或者bs.ul.li.a.get("href")来访问属性的值。如果属性有多个值或者属性名字为class,会返回列表。

除了tag以外,还有NavigableString(标签的值)以及Comment(注释和特殊字符串),标签的值一般是字符串,字符串中无法包含其他标签,同时无法编辑,只能替换。可以通过.string、.text获取标签的字符串。若标签内非字符串,第一种返回None,第二种会将内容转化为纯文本输出

我们要筛查的话,可以使用find()或者find_all()方法来的到一个对象或者所以符合要求的对象,
find_all比find只多了一个limit参数,其他的参数相同

好,总结一下。
(一)、访问属性
标签["属性名"]
标签("属性名")
class返回列表,其他的返回字符串
(二)、获取标签的值
.string 空返回None
.text 返回内容纯文本
(三)、查询方法
find(name , attrs , recursive , string)
find_all(name , attrs , recursive , string, limit)
标签名,属性名和属性值(class_特殊),搜索全部子孙节点,字符串内容,最大返回数
除此之外,还有css选择器,但我没看,觉得不够用的可以再去学习一下。
利用上述知识,我们可以使用下面代码获得所需数据了:
from bs4 import BeautifulSoup # bspath = "国家数据.html"
with open(path, mode="r", encoding="utf-8") as f: # 下载源码data = f.read()
bs = BeautifulSoup(data, "html.parser") # html代码交给bs处理'
ul = bs.find("ul", class_="active clearfix") # 查找标签名为ul,属性class值为”active clearfix“的tag
data = ul.find_all("a") # 查找所有a标签
for i in data:print(i["href"], i.string)很简短,不是吗。

四、xpath
这东西比bs快点,而且有开发工具加持,能够精准定位。它和bs4挺像的,是一种专门用于XML文档定位和选择节点的语言。但用起来也挺难,这里说点简单的先用上。
from lxml import etree # 导入
xpath的节点就像是上面的tag,树形结构,跟文件夹似的,使用etree.HTML(data)来处理数据。
首先是xpath支持路径表达式,和我们常见的文件路径相似:
| / | 根节点开始 |
| // | 不考虑位置 |
| . | 当前节点 |
| .. | 父节点 |
| @ | 选取属性 |
| * | 通配符,任何 |
| | | 或 |
| nodename | 所有子节点 |
| text() | 获取文本 |
我们可以通过.xpath来执行路径表达式。比如还是上文中的登录部分,我们想获取登录的文本,可以使用tree.xpath("/html/body/div[2]/div/div/ul/li[1]/a/text()")来得到结果,什么?很长,长就对了,这就就不是给人数的。(注意,它的下标从1开始)

这就要说到上面的开发工具加持了,打开开发工具的元素页面,右键需要的元素,就能够直接复制元素的Xpath地址了。

我们再来看看这条代码:tree.xpath("//*[@id='top']/div/div/ul/li[1]/a/text()")照样能找到位置,它用了谓语表达式,[@id='top']代表标签有个叫id的属性,值为'top',还能写出一些其他的谓语表达式,比如[last()]表示最后一个节点,[text()="登录"]选择文本为登录的节点,[id>1]选择id值大于1的节点等。
xpath还有一些接口:
| xpath() | 路径表达式获取节点列表 |
| find() | 查第一个匹配的节点 |
| findall() | 查所有匹配节点 |
| text | 获取文本内容 |
| attrib | 获取节点属性 |
好的,现在我们开始获取所需数据吧,要获得想要元素的位置,一点点找太麻烦了,我们可以使用左上角的检查工具,然后鼠标移动到所需的数据上,就能知道这个数据是从哪段代码中显示的了。


from lxml import etreepath = "国家数据.html"
with open(path, mode="r", encoding="utf-8") as f: # 下载源码data = f.read()
tree = etree.HTML(data)
ul1 = tree.xpath("/html/body/div[6]/div[3]/div[2]/div[2]/ul[1]")[0]
ul2 = tree.xpath('//ul[@class="active clearfix"]')[0]
print(ul1 == ul2)
out_data = ul1.xpath('./li/a')
print(out_data == ul1.findall("li/a"))
print(out_data == tree.xpath('//ul[@class="active clearfix"]//a'))
for i in out_data:print(i.attrib["href"],i.text) 方法很多,选种喜欢的用就行。
方法很多,选种喜欢的用就行。
注意上面获得的url前面拼接上原网址才是完整url。
后续:登录和代理
改天写如何处理登录以及代理,详情见三、登录以及代理。
相关文章:
python 爬虫 入门 二、数据解析(正则、bs4、xpath)
目录 一、待匹配数据获取 二、正则 三、bs4 (一)、访问属性 (二)、获取标签的值 (三)、查询方法 四、xpath 后续:登录和代理 上一节我们已经知道了如何向服务器发送请求以获得数据&#x…...

PTX 汇编代码语法
PTX(Parallel Thread Execution)汇编是 NVIDIA 为其 GPU 提供的一种并行指令集架构(ISA),用于编写 GPU 设备代码。PTX 是一种中间表示(IR),在 CUDA 代码编译时生成,之后会…...

【mysql】统计两个相邻任务/事件的间隔时间以及每个任务的平均用时
准备步骤1. 设置查询参数部分1.1 设置需要分析的起始时间1.2. 设置需要分析的时间的长度(分析的结束时间)1.3. 设置分析内容1.4. 设置需要分析的表和字段 2. 自动计算分析2.1 设置起始序号2.2. 筛选user_log表数据并生成带序号的临时表temp_ria2.3. 通过…...

RHCE——笔记
第一章——例行性工作 1:单一致性的例行性工作 仅处理执行一次就结束 at命令 /etc/at.allow —— 写在该文件的人可以使用at命令 /etc/at.deny —— 黑名单 两个文件都不存在,则只有root可以使用 #at工作调度对应的系统服务 [rootlocalhost ~]# p…...

Spring Boot在知识管理中的应用
1系统概述 1.1 研究背景 如今互联网高速发展,网络遍布全球,通过互联网发布的消息能快而方便的传播到世界每个角落,并且互联网上能传播的信息也很广,比如文字、图片、声音、视频等。从而,这种种好处使得互联网成了信息传…...

OpenCV高级图形用户界面(14)交互式地选择一个或多个感兴趣区域函数selectROIs()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 允许用户在给定的图像上选择多个 ROI。 该函数创建一个窗口,并允许用户使用鼠标来选择多个 ROI。控制方式:使用空格键或…...

字节青训营入营考核部分题解
题库链接:https://juejin.cn/problemset?utm_sourceschool&utm_mediumyouthcamp&utm_campaignexamine 1. 计算从x到y的最小步数 问题描述 AB 实验同学每天都很苦恼如何可以更好地进行 AB 实验,每一步的流程很重要,我们目标为了…...

Android调用系统打印图片
拍摄和分享照片是移动设备最受欢迎的用途之一。如果您的应用 拍摄照片、展示照片或允许用户分享图片,则应考虑启用打印功能 和图片。Android 支持库提供了一个便捷的功能,支持使用 只需编写极少的代码和一组简单的打印版式选项。 本节课介绍如何使用 v4…...

网络最快的速度光速,因此‘‘光网络‘‘由此产生
世界上有一种最快的速度又是光,以前传统以太网络规划满足不了现在的需求。 一 有线网规划 二 无线网规划...
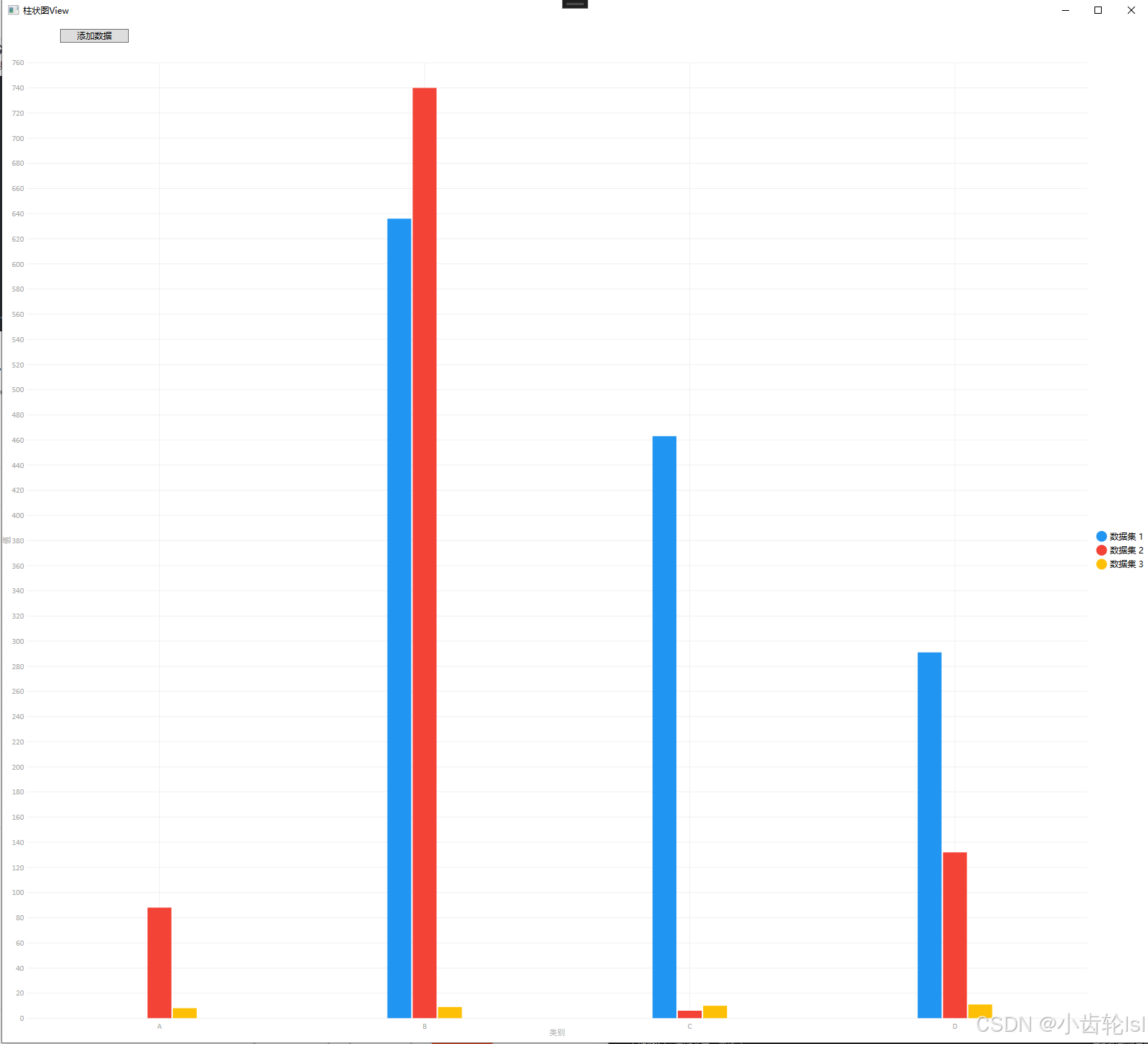
WPF -- LiveCharts的使用和源码
LiveCharts 是一个开源的 .NET 图表库,特别适用于 WPF、WinForms 和其他 .NET 平台。它提供了丰富的图表类型和功能,使开发者能够轻松地在应用程序中创建动态和交互式图表。下面我将使用WPF平台创建一个测试实例。 一、LiveCharts的安装和使用 1.安装N…...

spring 如何将mutipartFile转存到本地磁盘
两者的区别和联系 MutipartFile是spring的一部分,File则是java的标准类MutipartFile用于接收web传递的文件,File操作本地系统的文件 MutipartFile 转换File的三种方式 使用MutipartFile 自带的transferTo方法使用java自带的FileOutPutStream流使用java自…...

【学术会议-6】激发灵感-计算机科学与技术学术会议邀您参与,共享学术盛宴,塑造明天的科技梦想!
【学术会议-6】激发灵感-计算机科学与技术学术会议邀您参与,共享学术盛宴,塑造明天的科技梦想! 【学术会议-6】激发灵感-计算机科学与技术学术会议邀您参与,共享学术盛宴,塑造明天的科技梦想! 文章目录 【…...
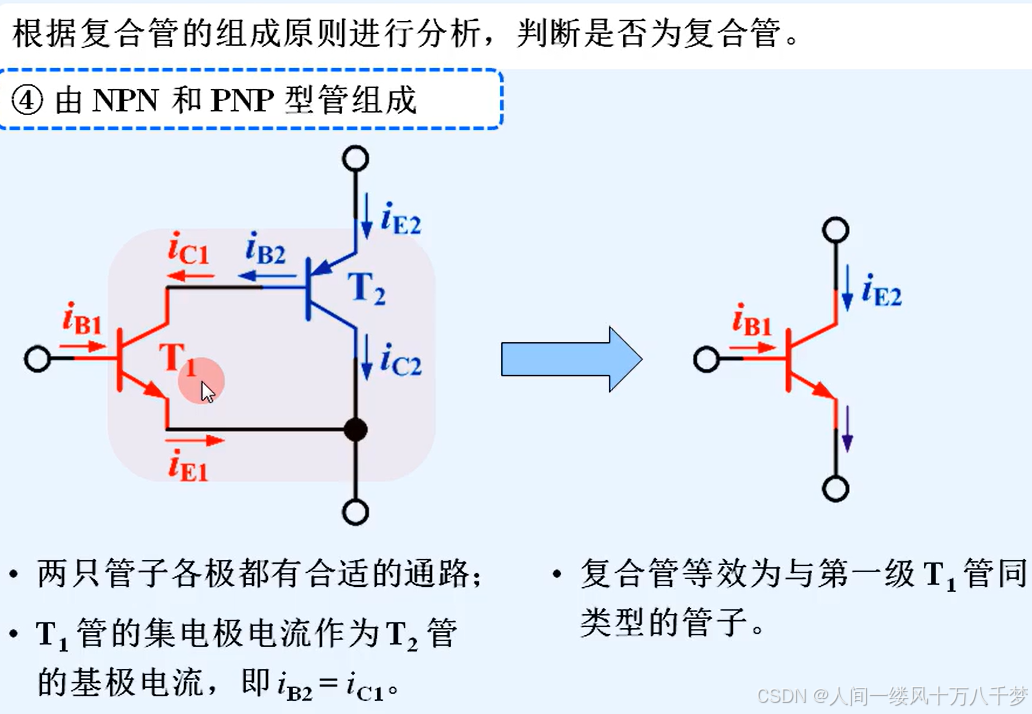
模电基础(晶体管放大电路)
1.放大电路 1.1基本共射放大电路工作原理 1.1.1电路的组成和作用 各器件的作用 (1)(交流电源):输入电路的有用信号,也就是我们需要去放大的信号 (2)(反馈…...
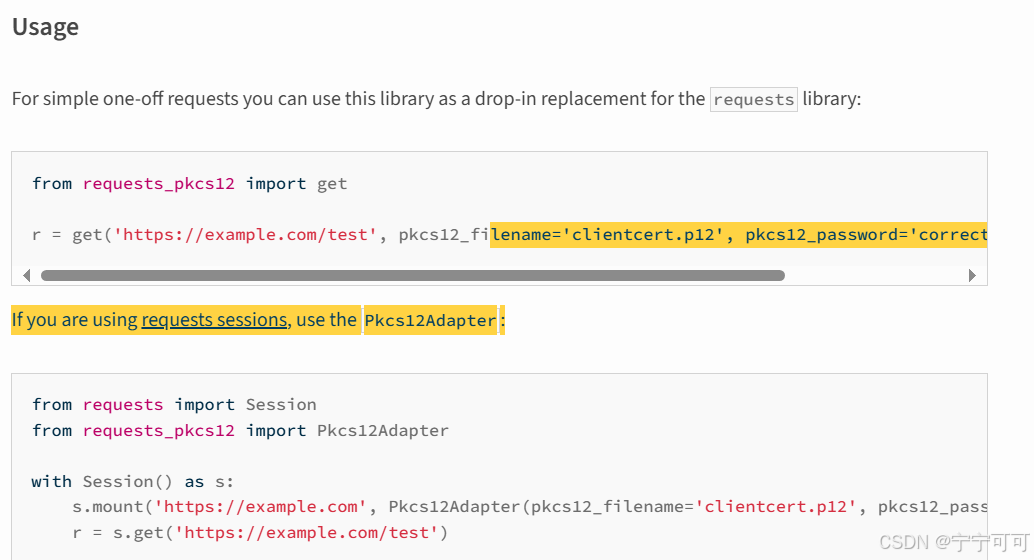
Python3 接口自动化测试,HTTPS下载文件(GET方法和POST方法)
Python3 接口自动化测试,HTTPS下载文件(GET方法和POST方法) requests-pkcs12 PyPI python中如何使用requests模块下载文件并获取进度提示 1、GET方法 1.1、调用 # 下载客户端(GET)def download_client_get(self, header_all):try:url = self.host + "/xxx/v1/xxx-mod…...
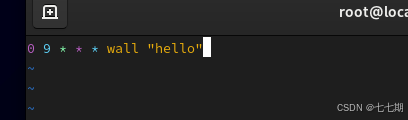
rhce:列行性(at和cron)
配置 at练习 设置时间提醒 定义一分钟后显示命令,使用atq查看 cron练习 配置 systemctl status crond 查看文件所在位置 ll /var/spool/cron/ 主要功能 开始操作 进入界面操作每天早上9点说hello crontab -e 五个星号分别代表分时日月周,其次是执…...

kubernetes给service动态增加服务端口
根据kubernetes官方文档的说明,service的ports规则支持merge操作: portsServicePort arraypatch strategy: mergepatch merge key: portThe list of ports that are exposed by this service. More info: https://kubernetes.io/docs/concepts/services-…...
如何将 html 渲染后的节点传递给后端?
问题 现在我有一个动态的 html 节点,我想用 vue 渲染后,传递给后端保存 思路 本来想给html的,发现样式是个问题 在一个是打印成pdf,然后上传,这个操作就变多了 最后的思路是通过 html2canvas 转化成 canvas 然后变成…...
ubuntu24 finalshell 无法连接ubuntu服务器, 客户端无法连接ubuntu, 无法远程连接ubuntu。
场景: 虚拟机新创建一个最小化的ubuntu服务器,使用finalshell连接服务,发现连接不上。 1. 查看防火墙ufw 是否开启,22端口是否放行 2. 查看是否安装openssh server, 并配置 我的问题是安装了openssh server 但是没有配置root可…...

牛客编程初学者入门训练——BC19 牛牛的对齐
BC19 牛牛的对齐 描述 读入 3 个整数,牛牛尝试以后两个数字占 8 个空格的宽度靠右对齐输出。 输入描述: 输入三个整数,用空格隔开。 输出描述: 输出 3 个整数以第二三个数字占 8 个空格靠右对齐输出 示例1 输入:…...

log file sync 内部执行过程
通常oracle的log file sync执行大致印象是等待cpu、log file parallel write、等待cpu,遇到问题主要考虑lgwr自适应模式参数要关闭、io性能、cpu瓶颈、归档数量和大小等,但是内部执行内容其实很多,尤其是有ADG了以后。 log file sync主要执行…...

潮州东方轻奢风全屋高定找哪家
开篇引言根据《2026年中国全屋定制行业发展报告》,潮州市全屋定制市场规模同比增长38%,其中全屋高端定制细分市场同比增长52%。目前,潮州市家庭全屋定制需求占比72%,高端定制需求占比45%。为了帮助潮州市消费者选择合规、靠谱、差…...

机器学习与SHAP在教育公平研究中的应用:精准定位学业困境根源
1. 项目概述:当机器学习遇见教育公平,我们如何精准定位学业困境的根源?在拉丁美洲的教育研究领域,一个长期困扰政策制定者和研究者的核心问题是:究竟是什么因素,在复杂的社会经济背景下,系统性地…...

钱钟书《围城》第1-5章阅读笔记:一场关于人生困境的提前预演
前言 钱钟书先生的《围城》被誉为"新儒林外史",是中国现代文学史上风格独特的讽刺经典。这部创作于20世纪40年代的长篇小说,以抗战初期为背景,通过主人公方鸿渐的人生轨迹,深刻揭示了知识分子群体的精神困境与人性弱点。…...

2026论文降AI怎么挑?亲测好用工具附免费降AI指南
“您的论文AIGC率为42%,超出学校30%的合格线,请修改后重新提交。”赶毕业论文的同学这段时间估计没少收到这样的提醒。2026年知网、万方、维普等主流平台的AI检测算法持续迭代,把AI生成内容改到符合学校要求,已经成了毕业生的刚需…...

如何进行TVA仿真引擎的“光照地狱”训练?
重磅预告:本专栏将独家连载系列丛书《智能体视觉技术与应用》部分精华内容,该书是世界首套系统阐述“因式智能体”视觉理论与实践的专著,特邀美国 TypeOne 公司首席科学家、斯坦福大学博士 Bohan 担任技术顾问。Bohan先生师从美国三院院士、“…...

PCL 法向量夹角剔除错误匹配点对【2026最新版】
目录 一、 算法简介 1、主要函数 2、参考文献 二、 代码实现 三、 结果展示 四、 参考链接 博客长期更新,本文最新更新时间为:2026年5月24日。代码在PCL1.15.1中测试通过 一、 算法简介 在三维点云配准中,对应点(correspondence)的准确性直接决定了配准算法的精度和鲁棒性…...

告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data
告别手动复制!用这个自定义编辑器脚本一键备份/克隆Unity Terrain Data在Unity关卡设计和技术美术的工作流中,地形数据的灵活复用往往意味着反复的手动操作——导出高度图、备份材质参数、复制植被分布,每个环节都可能成为效率瓶颈。想象这样…...

人工智能的伦理与安全:这3个问题,软件测试从业者必须重视
随着大语言模型、生成式AI的爆发式落地,人工智能已经从实验室走向千行百业的生产场景,深刻改变着软件开发与交付的逻辑。对于直接把控产品质量关口的软件测试从业者来说,我们的职责早已不再是单纯验证功能可用性、排查性能bug那么简单——AI系…...

从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法
从《王者荣耀》野怪巡逻到RTS单位集结:拆解Unity Navigation系统在实战中的4种高级用法在MOBA游戏中,野怪沿着固定路线巡逻时突然转向追击玩家;RTS战场上,上百个单位向同一目标点移动却能保持整齐队形;潜行游戏中&…...

ImageGlass:一个支持90+图像格式的轻量级Windows图片查看器
ImageGlass:一个支持90图像格式的轻量级Windows图片查看器 【免费下载链接】ImageGlass 🏞 A lightweight, versatile image viewer 项目地址: https://gitcode.com/gh_mirrors/im/ImageGlass 还在为Windows自带的图片查看器功能单一而烦恼吗&…...