深度学习500问——Chapter17:模型压缩及移动端部署(5)
文章目录
17.9.5 ShuffleNet- v1
17.9.6 ShuffleNet- v2
17.10 现有移动端开源框架及其特点
17.10.1 NCNN
17.10.2 QNNPACK
17.9.5 ShuffleNet- v1
ShuffleNet 是Face++团队提出的,晚于MobileNet两个月在arXiv上公开《ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices 》用于移动端前向部署的网络架构。ShuffleNet基于MobileNet的group思想,将卷积操作限制到特定的输入通道。而与之不同的是,ShuffleNet将输入的group进行打散,从而保证每个卷积核的感受野能够分散到不同group的输入中,增加了模型的学习能力。
5.1 设计思想
- 采用group conv减少大量参数
- roup conv与DW conv存在相同的“信息流通不畅”问题
- 采用channel shuffle解决上述问题
- MobileNet中采用PW conv解决上述问题,SheffleNet中采用channel shuffle
- 采用concat替换add操作
- avg pooling和DW conv(s=2)会减小feature map的分辨率,采用concat增加通道数从而弥补分辨率减小而带来信息的损失
5.2 网络架构
MobileNet中1*1卷积的操作占据了约95%的计算量,所以作者将1*1也更改为group卷积,使得相比MobileNet的计算量大大减少。

group卷积与DW存在同样使“通道信息交流不畅”的问题,MobileNet中采用PW conv解决上述问题,SheffleNet中采用channel shuffle。
ShuffleNet的shuffle操作如图所示:

avg pooling和DW conv(s=2)会减小feature map的分辨率,采用concat增加通道数从而弥补分辨率减小而带来信息的损失;实验表明:多多使用通道(提升通道的使用率),有助于提高小模型的准确率。

网络结构:

17.9.6 ShuffleNet- v2
huffleNet-v2 是Face++团队提出的《ShuffleNet V2: Practical Guidelines for Ecient CNN Architecture Design》,旨在设计一个轻量级但是保证精度、速度的深度网络。
6.1 设计思想
-
文中提出影响神经网络速度的4个因素:
- a. FLOPs(FLOPs就是网络执行了多少multiply-adds操作)
- b. MAC(内存访问成本)
- c. 并行度(如果网络并行度高,速度明显提升)
- d. 计算平台(GPU,ARM)
- ShuffleNet-v2 提出了4点网络结构设计策略:
- G1.输入输出的channel相同时,MAC最小
- G2.过度的组卷积会增加MAC
- G3.网络碎片化会降低并行度
- G4.元素级运算不可忽视
6.2 网络结构
depthwise convolution 和 瓶颈结构增加了 MAC,用了太多的 group,跨层连接中的 element-wise Add 操作也是可以优化的点。所以在 shuffleNet V2 中增加了几种新特性。
所谓的 channel split 其实就是将通道数一分为2,化成两分支来代替原先的分组卷积结构(G2),并且每个分支中的卷积层都是保持输入输出通道数相同(G1),其中一个分支不采取任何操作减少基本单元数(G3),最后使用了 concat 代替原来的 elementy-wise add,并且后面不加 ReLU 直接(G4),再加入channle shuffle 来增加通道之间的信息交流。 对于下采样层,在这一层中对通道数进行翻倍。 在网络结构的最后,即平均值池化层前加入一层 1x1 的卷积层来进一步的混合特征。

网络结构:

6.4 ShuffleNet-v2具有高精度的原因
- 由于高效,可以增加更多的channel,增加网络容量
- 采用split使得一部分特征直接与下面的block相连,特征复用(DenseNet)
17.10 现有移动端开源框架及其特点
17.10.1 NCNN
1、开源时间:2017年7月
2、开源用户:腾讯优图
3、GitHub地址:GitHub - Tencent/ncnn: ncnn is a high-performance neural network inference framework optimized for the mobile platform
4、特点:
- 1)NCNN考虑了手机端的硬件和系统差异以及调用方式,架构设计以手机端运行为主要原则。
- 2)无第三方依赖,跨平台,手机端 CPU 的速度快于目前所有已知的开源框架(以开源时间为参照对象)。
- 3)基于 ncnn,开发者能够将深度学习算法轻松移植到手机端高效执行,开发出人工智能 APP。
5、功能:
- NCNN支持卷积神经网络、多分支多输入的复杂网络结构,如vgg、googlenet、resnet、squeezenet 等。
- NCNN无需依赖任何第三方库。
- NCNN全部使用C/C++实现,以及跨平台的cmake编译系统,可轻松移植到其他系统和设备上。
- 汇编级优化,计算速度极快。使用ARM NEON指令集实现卷积层,全连接层,池化层等大部分 CNN 关键层。
- 精细的数据结构设计,没有采用需消耗大量内存的通常框架——im2col + 矩阵乘法,使得内存占用极低。
- 支持多核并行计算,优化CPU调度。
- 整体库体积小于500K,可精简到小于300K。
- 可扩展的模型设计,支持8bit 量化和半精度浮点存储。
- 支持直接内存引用加载网络模型。
- 可注册自定义层实现并扩展。
6、NCNN在Android端部署示例
- 1)选择合适的Android Studio版本并安装。
- 2)根据需求选择NDK版本并安装。
- 3)在Android Studio上配置NDK的环境变量。
- 4)根据自己需要编译NCNN sdk
mkdir build-android cd build-android cmake -DCMAKE_TOOLCHAIN_FILE=$ANDROID_NDK/build/cmake/android.toolchain.cmake \ -DANDROID_ABI="armeabi-v7a" -DANDROID_ARM_NEON=ON \ -DANDROID_PLATFORM=android-14 .. make make install 安装完成之后,install下有include和lib两个文件夹。
备注:
ANDROID_ABI 是架构名字,"armeabi-v7a" 支持绝大部分手机硬件
ANDROID_ARM_NEON 是否使用 NEON 指令集,设为 ON 支持绝大部分手机硬件
ANDROID_PLATFORM 指定最低系统版本,"android-14" 就是 android-4.0- 5)进行NDK开发。
1)assets文件夹下放置你的bin和param文件。
2)jni文件夹下放置你的cpp和mk文件。
3)修改你的app gradle文件。
4)配置Android.mk和Application.mk文件。
5)进行java接口的编写。
6)读取拷贝bin和param文件(有些则是pb文件,根据实际情况)。
7)进行模型的初始化和执行预测等操作。
8)build。
9)cd到src/main/jni目录下,执行ndk-build,生成.so文件。
10)接着就可写自己的操作处理需求。17.10.2 QNNPACK
全称:Quantized Neural Network PACKage(量化神经网络包)
1、开源时间:2018年10月
2、开源用户:Facebook
3、GitHub地址:https://github.com/pytorch/QNNPACK
4、特点:
1)低密度卷积优化函数库;
2)可在手机上实时运行Mask R-CNN 和 DensePose;
3) 能在性能受限的移动设备中用 100ms 以内的时间实施图像分类;
5、QNNPACK 如何提高效率?
1) QNNPACK 使用与安卓神经网络 API 兼容的线性量化方案
QNNPACK 的输入矩阵来自低精度、移动专用的计算机视觉模型。其它库在计算A和B矩阵相乘时,重新打包 A 和 B 矩阵以更好地利用缓存层次结构,希望在大量计算中分摊打包开销,QNNPACK 删除所有计算非必需的内存转换,针对 A和B矩阵相乘适用于一级缓存的情况进行了优化。

1)优化了L1缓存计算,不需要输出中间结果,直接输出最终结果,节省内存带宽和缓存占用。
具体分析:
- 常规实现:在量化矩阵-矩阵乘法中,8位整数的乘积通常会被累加至 32 位的中间结果中,随后重新量化以产生 8 位的输出。遇到大矩阵尺寸时,比如有时K太大,A和B的面板无法直接转入缓存,此时,需利用缓存层次结构,借助GEMM将A和B的面板沿着K维分割成固定大小的子面板,以便于每个子面板都能适应L1缓存,随后为每个子面板调用微内核。这一缓存优化需要 PDOT 为内核输出 32 位中间结果,最终将它们相加并重新量化为 8 位整数。
- 优化实现:由于 ONNPACK 对于面板 A 和 B 总是适应 L1 缓存的移动神经网络进行了优化,因此它在调用微内核时处理整个 A 和 B 的面板。而由于无需在微内核之外积累 32 位的中间结果,QNNPACK 会将 32 位的中间结果整合进微内核中并写出 8 位值,这节省了内存带宽和缓存占用。

2)取消了矩阵 A 的重新打包。
-
常规实现:
矩阵 B 包含静态权重,可以一次性转换成任何内存布局,但矩阵 A 包含卷积输入,每次推理运行都会改变。因此,重新打包矩阵 A 在每次运行时都会产生开销。尽管存在开销,传统的 GEMM实现还是出于以下两个原因对矩阵 A 进行重新打包:a 缓存关联性及微内核效率受限。如果不重新打包,微内核将不得不读取被潜在的大跨距隔开的几行A。如果这个跨距恰好是 2 的许多次幂的倍数,面板中不同行 A 的元素可能会落入同一缓存集中。如果冲突的行数超过了缓存关联性,它们就会相互驱逐,性能也会大幅下降。b 打包对微内核效率的影响与当前所有移动处理器支持的 SIMD 向量指令的使用密切相关。这些指令加载、存储或者计算小型的固定大小元素向量,而不是单个标量(scalar)。在矩阵相乘中,充分利用向量指令达到高性能很重要。在传统的 GEMM 实现中,微内核把 MR 元素重新打包到向量暂存器里的 MR 线路中。优化实现:
a 当面板适配一级缓存时,不会存在缓存关联性及微内核效率受限的问题。b 在 QNNPACK 实现中,MR 元素在存储中不是连续的,微内核需要把它们加载到不同的向量暂存器中。越来越大的暂存器压力迫使 QNNPACK 使用较小的 MRxNR 拼贴,但实际上这种差异很小,而且可以通过消除打包开销来补偿。例如,在 32 位 ARM 架构上,QNNPACK 使用 4×8 微内核,其中 57% 的向量指令是乘-加;另一方面,gemmlowp 库使用效率稍高的 4×12 微内核,其中 60% 的向量指令是乘-加。微内核加载 A 的多个行,乘以 B 的满列,结果相加,然后完成再量化并记下量化和。A 和 B 的元素被量化为 8 位整数,但乘积结果相加到 32 位。大部分 ARM 和 ARM64 处理器没有直接完成这一运算的指令,所以它必须分解为多个支持运算。QNNPACK 提供微内核的两个版本,其不同之处在于用于乘以 8 位值并将它们累加到 32 位的指令序列。2) 从矩阵相乘到卷积

传统实现:
简单的 1×1 卷积可直接映射到矩阵相乘
但对于具备较大卷积核、padding 或子采样(步幅)的卷积而言则并非如此。但是,这些较复杂的卷积能够通过记忆变换 im2col 映射到矩阵相乘。对于每个输出像素,im2col 复制输入图像的图像块并将其计算为 2D 矩阵。由于每个输出像素都受 KHxKWxC 输入像素值的影响(KH 和 KW 分别指卷积核的高度和宽度,C 指输入图像中的通道数),因此该矩阵的大小是输入图像的 KHxKW 倍,im2col 给内存占用和性能都带来了一定的开销。和 Caffe 一样,大部分深度学习框架转而使用基于 im2col 的实现,利用现有的高度优化矩阵相乘库来执行卷积操作。
优化实现:
Facebook 研究者在 QNNPACK 中实现了一种更高效的算法。
- 他们没有变换卷积输入使其适应矩阵相乘的实现,而是调整 PDOT 微内核的实现,在运行中执行 im2col 变换。这样就无需将输入张量的实际输入复制到 im2col 缓存,而是使用输入像素行的指针设置 indirection buffer,输入像素与每个输出像素的计算有关。
- 研究者还修改了矩阵相乘微内核,以便从 indirection buffer 加载虚构矩阵(imaginary matrix)A 的行指针,indirection buffer 通常比 im2col buffer 小得多。
- 此外,如果两次推断运行的输入张量存储位置不变,则 indirection buffer 还可使用输入张量行的指针进行初始化,然后在多次推断运行中重新使用。研究者观察到具备 indirection buffer 的微内核不仅消除了 im2col 变换的开销,其性能也比矩阵相乘微内核略好(可能由于输入行在计算不同输出像素时被重用)。
3) 深度卷积

分组卷积(grouped convolution)将输入和输出通道分割成多组,然后对每个组进行分别处理。在有限条件下,当组数等于通道数时,该卷积就是深度卷积,常用于当前的神经网络架构中。深度卷积对每个通道分别执行空间滤波,展示了与正常卷积非常不同的计算模式。因此,通常要向深度卷积提供单独实现,QNNPACK 包括一个高度优化版本 3×3 深度卷积。
深度卷积的传统实现是每次都在卷积核元素上迭代,然后将一个卷积核行和一个输入行的结果累加到输出行。对于一个 3×3 的深度卷积,此类实现将把每个输出行更新 9 次。在 QNNPACK 中,研究者计算所有 3×3 卷积核行和 3×3 输入行的结果,一次性累加到输出行,然后再处理下个输出行。
QNNPACK 实现高性能的关键因素在于完美利用通用暂存器(GPR)来展开卷积核元素上的循环,同时避免在 hot loop 中重新加载地址寄存器。32-bit ARM 架构将实现限制在 14 个 GPR。在 3×3 深度卷积中,需要读取 9 个输入行和 9 个卷积核行。这意味着如果想完全展开循环必须存储 18 个地址。然而,实践中推断时卷积核不会发生变化。因此 Facebook 研究者使用之前在 CxKHxKW 中的滤波器,将它们封装进 [C/8]xKWxKHx8,这样就可以仅使用具备地址增量(address increment)的一个 GPR 访问所有滤波器。(研究者使用数字 8 的原因在于,在一个命令中加载 8 个元素然后减去零,在 128-bit NEON 暂存器中生成 8 个 16-bit 值。)然后使用 9 个输入行指针,指针将滤波器重新装进 10 个 GPR,完全展开滤波器元素上的循环。64-bit ARM 架构相比 32-bit 架构,GPR 的数量翻了一倍。QNNPACK 利用额外的 ARM64 GPR,一次性存储 3×5 输入行的指针,并计算 3 个输出行。
7、性能优势:
测试结果显示出 QNNPACK 在端到端基准上的性能优势。在量化当前最优 MobileNetV2 架构上,基于QNNPACK 的 Caffe2 算子的速度大约是 TensorFlow Lite 速度的 2 倍,在多种手机上都是如此。除了 QNNPACK 之外,Facebook 还开源了 Caffe2 quantized MobileNet v2 模型,其 top-1 准确率比相应的 TensorFlow 模型高出 1.3%。
MobileNetV1
MobileNetV1 架构在使用深度卷积(depthwise convolution)使模型更适合移动设备方面具备开创性。MobileNetV1 包括几乎整个 1×1 卷积和 3×3 卷积。Facebook 研究者将量化 MobileNetV1 模型从 TensorFlow Lite 转换而来,并在 TensorFlow Lite 和 QNNPACK 的 32-bit ARM 设备上对 MobileNetV1 进行基准测试。二者运行时均使用 4 线程,研究者观察到 QNNPACK 的运行速度几何平均值是 TensorFlow Lite 的 1.8 倍。

MobileNetV2
作为移动视觉任务的当前最优架构之一,MobileNetV2 引入了瓶颈构造块和瓶颈之间的捷径连接。研究者在 MobileNetV2 分类模型的量化版上对比基于 QNNPACK 的 Caffe2 算子和 TensorFlow Lite 实现。使用的量化 Caffe2 MobileNetV2 模型已开源,量化 TensorFlow Lite 模型来自官方库:https://github.com/tensorflow/tensorflow/blob/master/tensorflow/contrib/lite/g3doc/models.md。下表展示了二者在常用测试集上的 top1 准确率:

Facebook 研究者利用这些模型建立了 Facebook AI 性能评估平台(https://github.com/facebook/FAI-PEP)的基准,该基准基于 32-bit ARM 环境的大量手机设备。对于 TensorFlow Lite 线程设置,研究者尝试了一到四个线程,并报告了最快速的结果。结果显示 TensorFlow Lite 使用四线程的性能最优,因此后续研究中使用四线程来对比 TensorFlow Lite 和 QNNPACK。下表展示了结果,以及在典型智能手机和高端机上,基于 QNNPACK 的算子速度比 TensorFlow Lite 快得多。

Facebook开源高性能内核库QNNPACK 百度安全验证 Facebook开源移动端深度学习加速框架,比TensorFlow Lite快一倍_DW卷积
支持移动端深度学习的几种开源框架 支持移动端深度学习的几种开源框架_tiny-cnn 移动端-CSDN博客
相关文章:
深度学习500问——Chapter17:模型压缩及移动端部署(5)
文章目录 17.9.5 ShuffleNet- v1 17.9.6 ShuffleNet- v2 17.10 现有移动端开源框架及其特点 17.10.1 NCNN 17.10.2 QNNPACK 17.9.5 ShuffleNet- v1 ShuffleNet 是Face团队提出的,晚于MobileNet两个月在arXiv上公开《ShuffleNet: An Extremely Efficient…...

分布式ID多种生成方式
分布式ID 雪花算法(时间戳41机器编号10自增序列号10) 作用:希望ID按照时间进行有序生成 原理: 即一台带有编号的服务器在毫秒级时间戳内生成带有自增序号的ID,这个ID保证了自增性和唯一性 雪花算法根据结构的生成ID个数的上线时…...

时间序列预测(六)——循环神经网络(RNN)
目录 一、RNN的基本原理 1、正向传播(Forward Pass): 2、计算损失(Loss Calculation) 3、反向传播——反向传播通过时间(Backpropagation Through Time,BPTT) 4、梯度更新&…...

Day2算法
Day2算法 1.算法的基本概念 算法: 对特定问题求解步骤的一种描述,他叔指令的有限序列,其中的每条指令表示一个或多个操作。 算法的特性: 1.有穷性: 一个算法必须总在执行有穷步之后结束,且每一步都可…...

智洋创新嵌入式面试题汇总及参考答案
堆和栈有什么区别 内存分配方式 栈由编译器自动分配和释放,函数执行时,函数内局部变量等会在栈上分配空间,函数执行结束后自动回收。例如在一个简单的函数int add(int a, int b)中,参数a和b以及函数内部的一些临时变量都会在栈上分配空间,函数调用结束后这些空间就会被释放…...
)
无线网卡知识的学习-- wireless基础知识(nl80211)
1. 基本概念 mac80211 :这是最底层的模块,与hardware offloading 关联最多。 mac80211 的工作是给出硬件的所有功能与硬件进行交互。(Kernel态) cfg80211:是设备和用户之间的桥梁,cfg80211的工作则是观察跟踪wlan设备的实际状态. (Kernel态) nl80211: 介于用户空间与内核…...

除了 Python,还有哪些语言适合做爬虫?
以下几种语言也适合做爬虫: 一、Java* 优势: 强大的性能和稳定性:Java 运行在 Java 虚拟机(JVM)上,具有良好的跨平台性和出色的内存管理机制,能够处理大规模的并发请求和数据抓取任务&#x…...

JS | JS中类的 prototype 属性和__proto__属性
大多数浏览器的 ES5 实现之中,每一个对象都有__proto__属性,指向对应的构造函数的prototype属性。Class 作为构造函数的语法糖,同时有prototype属性和__proto__属性,因此同时存在两条继承链。 构造函数的子类有prototype属性。 …...

15分钟学Go 第3天:编写第一个Go程序
第3天:编写第一个Go程序 1. 引言 在学习Go语言的过程中,第一个程序通常是“Hello, World!”。这个经典的程序不仅教会你如何编写代码,还引导你理解Go语言的基本语法和结构。本节将详细介绍如何编写、运行并理解第一个Go程序,通过…...

简单的常见 http 响应状态码
简单的常见 http 响应状态码 HTTP状态码(HTTP Status Code)是用以表示网页服务器超文本传输协议响应状态的3位数字代码。它由 RFC 2616 规范定义,所有状态码的第一个数字代表了响应的五种状态之一。 1. 大体分类 状态码类别解释1xx信息性响…...

2024年【安全员-C证】复审考试及安全员-C证模拟考试题
安全员-C证考试是针对生产经营单位的安全生产管理人员进行的职业资格认证考试。考试内容涵盖安全生产法律法规、安全管理知识、安全技术措施等多个方面。通过考试,可以检验考生对安全生产知识的掌握程度,提高安全管理水平,确保生产安全。 二…...

RT-Thread之STM32使用定时器实现输入捕获
前言 基于RT-Thread的STM32开发,配置使用定时器实现输入捕获。 比如配置特定通道捕获上升沿,该通道对应的引脚有上升沿信号输入,则触发捕获中断。 一、新建工程 二、工程配置 1、打开CubeMX 进行工程配置 2、时钟使用外部高速晶振 3、配置…...

数字图像处理:图像分割应用
数字图像处理:图像分割应用 图像分割是图像处理中的一个关键步骤,其目的是将图像分成具有不同特征的区域,以便进一步的分析和处理。 1.1 阈值分割法 阈值分割法(Thresholding)是一种基于图像灰度级或颜色的分割方法&…...

Java面试宝典-并发编程学习02
目录 21、并行与并发有什么区别? 22、多线程中的上下文切换指的是什么? 23、Java 中用到的线程调度算法是什么? 24、Java中线程调度器和时间分片指的是什么? 25、什么是原子操作?Java中有哪些原子类? 26、w…...

【每日一题】洛谷 - 快速排序模板
今天的每日一题来自洛谷,题目要求对给定的 N N N 个正整数进行从小到大的排序,并输出结果。我们将使用经典的**快速排序算法(QuickSort)**来解决这一问题。下面我将从问题分析、代码实现、及快速排序的核心思想进行详细说明。 题…...

Django模型优化
1、创建一个Django项目 可参考之前的带你快速体验Django web应用 我使用的是mysql数据库。按照上述教程完成准备工作。 2、创建一个app并完成注册 demo主要来完成创建用户、修改用户、查询用户、删除用户的操作。 python manage.py startapp test0023、app的目录 新建templ…...

Python实现火柴人的设计与实现
1.引言 火柴人(Stick Figure)是一种极简风格的图形,通常由简单的线段和圆圈组成,却能生动地表达人物的姿态和动作。火柴人不仅广泛应用于动画、漫画和涂鸦中,还可以作为图形学、人工智能等领域的教学和研究工具。本文…...
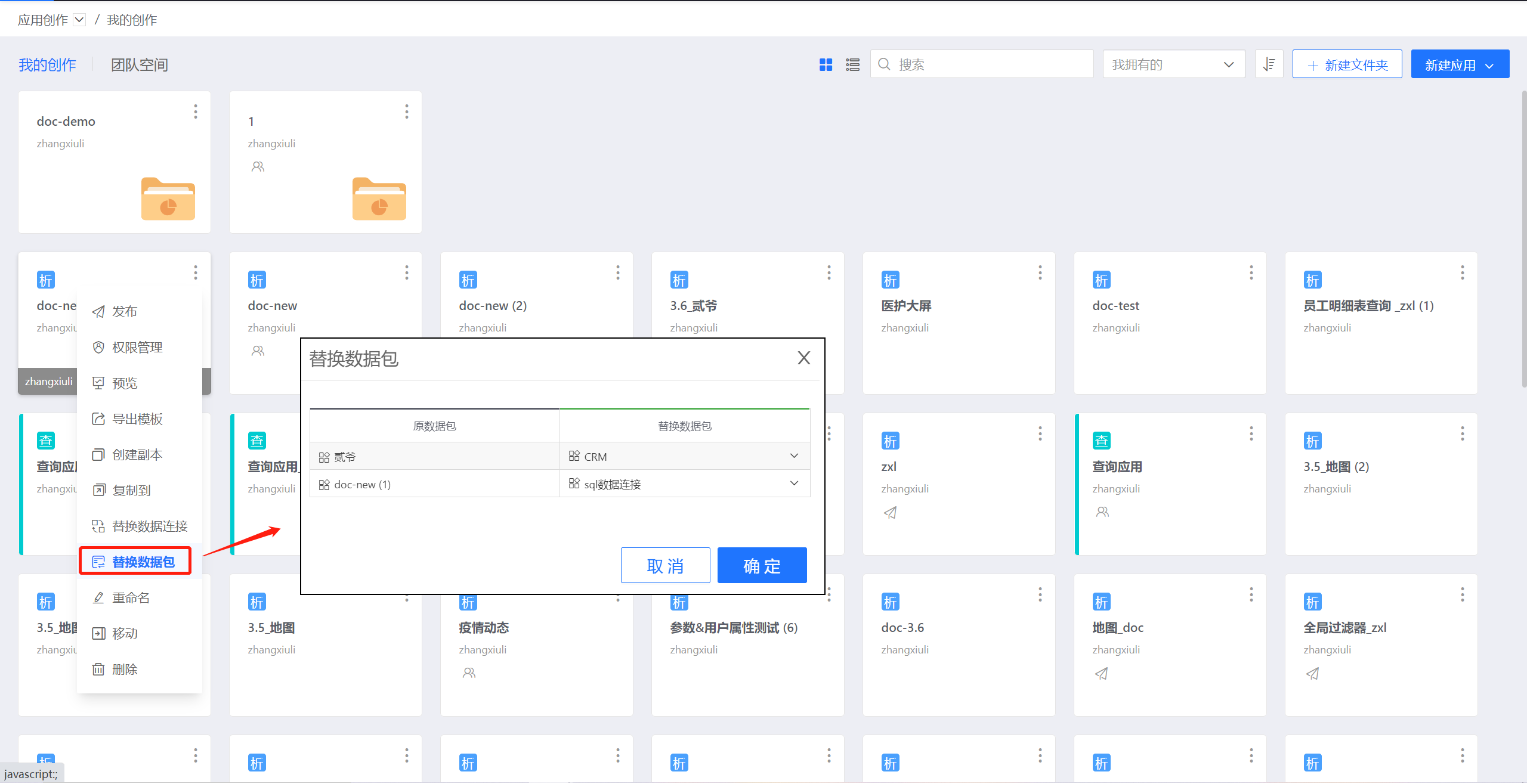
衡石分析平台系统分析人员手册-应用模版
应用模板 应用模板使分析成果能被快速复用,节省应用创作成本,提升应用创作效率。此外应用模板实现了应用在不同环境上快速迁移。 支持应用复制功能 用户可以从现有的分析成果关联到新的分析需求并快速完成修改。 支持应用导出为模板功能 实现多个用户…...

Git和SVN
一. Git和SVN的区别 1.1 Git是分布式的,SVN是集中式的 1.2 Git复杂概念多,SVN简单易上手 Git 的命令实在太多了,日常工作需要掌握 add, commit, status, fetch, push, rebase等,若要熟练掌握,还必须掌握 rebase和 m…...
宏与预处理 - <stddef.h> 和 <stdbool.h>)
【C语言教程】【常用类库】(十八)宏与预处理 - <stddef.h> 和 <stdbool.h>
18. 宏与预处理 - <stddef.h> 和 <stdbool.h> C语言的宏和预处理指令在程序编译之前就被执行,用于文件包含、符号定义、条件编译等操作。理解和运用宏和预处理可以提高代码的灵活性和可移植性。 18.1 宏定义与条件编译 18.1.1 #define 与参数化宏 #…...

CentOS 7下‘Development Tools’和‘开发工具’组有区别吗?实测告诉你答案
CentOS 7下‘Development Tools’与‘开发工具’的隐藏关联:技术细节全解析在Linux系统管理中,yum的软件包组功能一直是个既实用又充满谜团的领域。特别是当系统语言环境与软件包元数据语言不一致时,开发者们常常会遇到一个有趣的现象&#x…...

深圳实体门店有必要做GEO AI代运营吗
深圳实体门店有必要做GEO AI代运营吗一、开篇引言2026年深圳本地实体商业竞争进入白热化阶段,全城数百万家线下实体门店涵盖本地生活、家装工装、汽车服务、餐饮娱乐、教育培训等全品类,传统线下地推、门店自然客流、传统团购平台引流效果持续下滑&#…...

DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉!
更多请点击: https://kaifayun.com 第一章:DeepSeek系统设计辅助效能断崖式下降的3个信号,第2个90%工程师至今未察觉! 当 DeepSeek 的系统设计辅助能力突然变“笨”——接口建议频繁失准、上下文感知错乱、生成代码无法通过基础编…...

Java数组工具类实战:设计不可实例化的静态工具类
实现一个工具类 MathUtils,满足以下要求: 1. 所有方法均为静态,且该类不能从外部实例化(提示:使用私有构造器)。 2. 提供三个静态方法:- maxArray(int[] arr):返回较大值;…...

Simulink中Repeating Sequence锯齿波显示恒为0解决方案
锯齿波设置如图1时,其示波器显示恒为0(如图2)。图1图2于是新建模型,只添加Repeating Sequence模块,采用原始设置发现可以正常输出锯齿波,于是调整时间参数,发现当时间设置为≥[0 0.06]时可以正常…...

一次搞懂内存取证:用Volatility3和Cobalt Strike分析工具复现VNCTF‘来一把紧张刺激的CS’
实战内存取证:从Volatility3到Cobalt Strike信标分析全解析 在网络安全事件响应中,内存取证往往是发现高级威胁的最后一道防线。当攻击者使用文件无落地的技术时,传统的磁盘取证可能一无所获,而内存中却保留着攻击行为的完整痕迹。…...

AI圈神秘领袖Ilya一幅画引爆全网,OpenAI三件大事暗示AGI时代将至?
AI圈神秘精神领袖Ilya在Instagram上传一幅画引发疯狂解读,与此同时,OpenAI连续公布数学成果、升级Codex、筹备IPO,释放AGI到来的强烈信号。Ilya画作引猜测Ilya上传的画中,罗丹的「思考者」踩在芯片Die Shot上,右下角签…...
)
告别硬编码!在UE5.1里用蓝图动态配置MySQL连接参数(控件蓝图实战)
动态配置MySQL连接:UE5.1控件蓝图的工程化实践在游戏开发中,数据库连接往往是项目架构中不可或缺的一环。传统硬编码方式虽然简单直接,却带来了维护困难、安全性差、灵活性低等一系列问题。本文将深入探讨如何在UE5.1中构建一个完全动态化的M…...

Elden Ring帧率解锁终极指南:从60帧到144+的完整教程
Elden Ring帧率解锁终极指南:从60帧到144的完整教程 【免费下载链接】EldenRingFpsUnlockAndMore A small utility to remove frame rate limit, change FOV, add widescreen support and more for Elden Ring 项目地址: https://gitcode.com/gh_mirrors/el/Elden…...

UE4SS终极指南:从零开始掌握虚幻引擎脚本系统
UE4SS终极指南:从零开始掌握虚幻引擎脚本系统 【免费下载链接】RE-UE4SS Injectable LUA scripting system, SDK generator, live property editor and other dumping utilities for UE4/5 games 项目地址: https://gitcode.com/gh_mirrors/re/RE-UE4SS UE4S…...