【SSM详细教程】-04-Spring基于注解的组件扫描
精品专题:
01.《C语言从不挂科到高绩点》课程详细笔记
https://blog.csdn.net/yueyehuguang/category_12753294.html?spm=1001.2014.3001.5482 https://blog.csdn.net/yueyehuguang/category_12753294.html?spm=1001.2014.3001.5482
https://blog.csdn.net/yueyehuguang/category_12753294.html?spm=1001.2014.3001.5482
02. 《SpringBoot详细教程》课程详细笔记
https://blog.csdn.net/yueyehuguang/category_12789841.html?spm=1001.2014.3001.5482![]() https://blog.csdn.net/yueyehuguang/category_12789841.html?spm=1001.2014.3001.548203.《SpringBoot电脑商城项目》课程详细笔记
https://blog.csdn.net/yueyehuguang/category_12789841.html?spm=1001.2014.3001.548203.《SpringBoot电脑商城项目》课程详细笔记
https://blog.csdn.net/yueyehuguang/category_12752883.html?spm=1001.2014.3001.5482![]() https://blog.csdn.net/yueyehuguang/category_12752883.html?spm=1001.2014.3001.548204.《VUE3.0 核心教程》课程详细笔记
https://blog.csdn.net/yueyehuguang/category_12752883.html?spm=1001.2014.3001.548204.《VUE3.0 核心教程》课程详细笔记
https://blog.csdn.net/yueyehuguang/category_12769996.html?spm=1001.2014.3001.5482![]() https://blog.csdn.net/yueyehuguang/category_12769996.html?spm=1001.2014.3001.5482
https://blog.csdn.net/yueyehuguang/category_12769996.html?spm=1001.2014.3001.5482
================================
|| 持续分享系列教程,关注一下不迷路 ||
|| 视频教程:小破站:墨轩大楼 ||
================================
1. 什么是组件扫描
指定一个包路径,Spring会自动扫描该包及其子包所有组件类,当发现组件类定义前有特定的注解标记时,就将该组件纳入到Spring容器中。等价于原有XML配置中的<bean>定义功能。
组件扫描可以代替大量XML配置的<bean>定义。
1.1. 指定扫描类路径
使用组件扫描,首先需要在applicationContext.xml配置文件中指定扫描类路径,如下所示:
<context:component-scan base-package="com.moxuan" />上面配置,容器实例化时会自动扫描com.moxuan包及其子包下面所有组件类。
1.2. 自动扫描的注解标记
指定扫描类路径后,并不是该路径下所有组件类都扫描到Spring容器的,只有在组件类定义前面有以下注解标记时,才会扫描到spring容器中:
| 注解标记 | 描述 |
| @Component | 通用注解 |
| @Name | 通用注解 |
| @Repository | 持久化层组件注解 |
| @Service | 业务层组件注解 |
| @Controller | 控制层组件注解 |
1.3. 自动扫描组件的命名
当一个组件在扫描过程中被检测到时,会生成一个默认id值,默认id为小写开头的类名,也可以在注解标记中自定义id。看下面案例:
首先在application.xml中配置注解扫描包路径:
<context:component-scan base-package="com.moxuan"></context:component-scan>然后在com.moxuan的子包entity中新建Cat类 ,使用默认id值,具体代码如下:
package com.moxuan.entity;import lombok.Data;
import org.springframework.stereotype.Component;@Component // 此处不加名字,采用默认id
@Data
public class Cat {private String name;private String color;
}
然后在com.moxuan的子包entity中新建Dog类 ,指定一个id名字,具体代码如下:
package com.moxuan.entity;import lombok.Data;
import org.springframework.stereotype.Component;@Component("myDog") // 此处指定了名字,就不再使用默认的id了
@Data
public class Dog {private String name;private String type;
}
分别在测试方法中获取cat和dog对象,具体如下:
/**
* 自动扫描组件的命名
*/
@Test
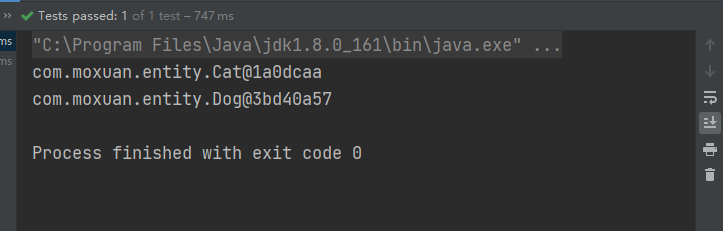
public void test01(){AbstractApplicationContext context =new ClassPathXmlApplicationContext("application.xml");Cat cat = context.getBean("cat",Cat.class);System.out.println(cat);Dog dog = context.getBean("myDog",Dog.class);System.out.println(dog);
}运行效果:
2. 指定组件的作用域
通常受Spring管理的组件,默认的作用域是Singleton,如果需要其他的作用域可以使用@Scope注解,只要在注解中提供作用域的名称即可。看下面代码:
Cat类代码不变:
package com.moxuan.entity;import lombok.Data;
import org.springframework.stereotype.Component;@Component // 此处不加名字,采用默认id
@Data
public class Cat {private String name;private String color;
}Dog类新增@Scope注解,指定为prototype:
package com.moxuan.entity;import lombok.Data;
import org.springframework.context.annotation.Scope;
import org.springframework.stereotype.Component;@Scope("prototype")
@Component("myDog") // 此处指定了名字,就不再使用默认的id了
@Data
public class Dog {private String name;private String type;
}
编写测试方法:
@Test
public void test02(){AbstractApplicationContext context =new ClassPathXmlApplicationContext("application.xml");Cat cat1 = context.getBean("cat",Cat.class);Cat cat2 = context.getBean("cat",Cat.class);System.out.println(cat1==cat2); // trueDog dog1 = context.getBean("myDog",Dog.class);Dog dog2 = context.getBean("myDog",Dog.class);System.out.println(dog1==dog2); //false}cat未指定作用域,默认的作用域是Singleton,所以可以看到虽然我们获取了两次对象,但是由于默认的作用域是Singleton,单例模式,只有一个对象,所以比较的时候,值为true。而Dog上面我使用@Scope指定了非单例模式,两次获取到的对象不是同一个,所以比较结果为false。
3. 初始化和销毁回调的控制
@PostConstruct 和 @PreDestroy 注解标记分别用于指定初始化和销毁回调函数,使用示例如下:
首先添加ExampleBean,分别添加初始化和销毁方法,并使用两个注解,具体如下:
package com.moxuan.entity;import org.springframework.stereotype.Component;import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;@Component
public class ExampleBean {public ExampleBean(){System.out.println("构造函数执行。..");}@PostConstructpublic void init(){System.out.println("初始化方法被调用了");}@PreDestroypublic void destroy(){System.out.println("销毁方法被调用了");}
}
编写测试方法,具体代码如下:
/**
* 测试初始化和销毁注解
*/
@Test
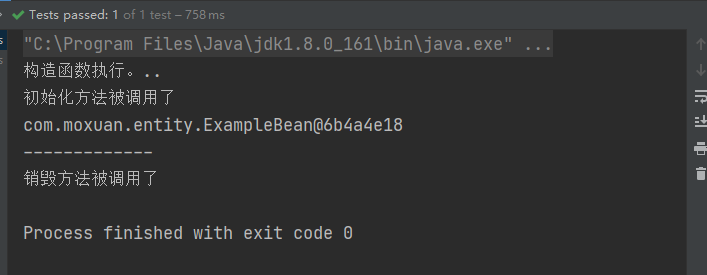
public void test03(){AbstractApplicationContext context =new ClassPathXmlApplicationContext("application.xml");ExampleBean eb = context.getBean("exampleBean",ExampleBean.class);System.out.println(eb);System.out.println("-------------");context.close();// 关闭容器,测试销毁
}运行效果如图所示:
4. 指定依赖注入关系
具有依赖关系的Bean对象,利用下面任意一种注解都可以实现关系注入:
@Resource
@Autowired / @Qulifier
@Inject / @Named
4.1. @Resource 注解
@Resource 注解标记可以用在字段定义或setter方法定义前面,默认首先按名称匹配注入,如果匹配不到再按照类型匹配注入。
首先创建武器类Weapon.java,代码如下:
package com.moxuan.entity;import lombok.Data;
import org.springframework.stereotype.Component;@Component
@Data
public class Weapon {private String name;public Weapon(){this.name = "擎天柱";}
}
再创建一个装备类Equip.java,代码如下:
package com.moxuan.entity;import lombok.Data;
import org.springframework.stereotype.Component;@Data
@Component
public class Equip {private String name;public Equip(){this.name = "皇帝的新衣";}
}接下来创建Hero.java,使用@Resource进行属性注入:
package com.moxuan.entity;import lombok.Data;
import org.springframework.stereotype.Component;import javax.annotation.Resource;@Component
@Data
public class Hero {@Resource //根据属性名去匹配private Weapon weapon;@Resource(name="weapon") // 指定属性名去匹配private Weapon weapon01;@Resource // 根据类型匹配private Weapon weapon02;private Equip equip;@Resource // 作用在setter方法上public void setEquip(Equip equip) {this.equip = equip;}
}
最后编写测试方法,代码如下:
/**
* 测试@Resource
*/
@Test
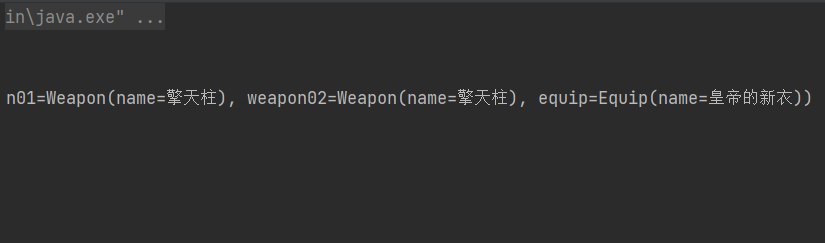
public void test04(){AbstractApplicationContext context =new ClassPathXmlApplicationContext("application.xml");Hero hero = context.getBean("hero", Hero.class);System.out.println(hero);
}运行效果:
4.2. @Autowired 注解
@Autowired 注解标记也可以用在字段定义或setter方法定义前面,默认按类型匹配注入
首先新建一个Computer类,添加相应属性
package com.moxuan.entity;import lombok.Data;
import org.springframework.stereotype.Component;@Data
@Component
public class Computer {private String mainBoard;private String hdd;private String ram;public Computer(){this.mainBoard = "技嘉";this.hdd = "希捷";this.ram = "金士顿";}
}
然后添加Programmer类,分别定义两个Computer属性,并分别对两个属性在属性前和setter方法前使用@Autowired注解。
package com.moxuan.entity;import lombok.Data;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;@Component
@Data
public class Programmer {@Autowiredprivate Computer com1;private Computer com2;@Autowiredpublic void setCom2(Computer com2) {this.com2 = com2;}
}
最后编写测试方法,代码如下:
/**
* 测试@Autowired
*/
@Test
public void test05(){AbstractApplicationContext context =new ClassPathXmlApplicationContext("application.xml");Programmer pro = context.getBean("programmer",Programmer.class);System.out.println(pro);
}运行效果如图所示:
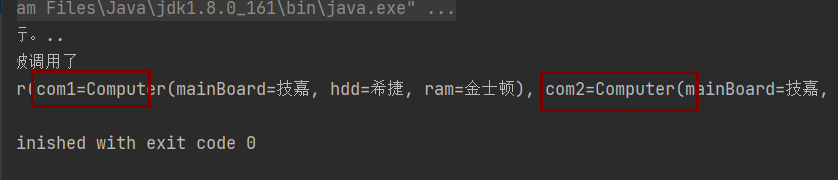
此时发现两种方式都能够成功注入属性值。
由于@Autowired 注解方式是按照类型去匹配注入的,如果出现两个类型相同的Bean,会根据属性名去匹配Bean,如果匹配得到就能注入成功,反之匹配不到就会报错。
首先,去掉Computer类上面的注解
package com.moxuan.entity;import lombok.Data;
import org.springframework.stereotype.Component;@Data
//@Component
public class Computer {private String mainBoard;private String hdd;private String ram;public Computer(){this.mainBoard = "技嘉";this.hdd = "希捷";this.ram = "金士顿";}
}在applicationContext.xml中添加bean配置,配置两个Computer类型的bean,注入不同的属性,代码如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:context="http://www.springframework.org/schema/context"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd"><context:component-scan base-package="com.moxuan"></context:component-scan><bean id="com1" class="com.moxuan.entity.Computer"><property name="mainBoard" value="技嘉" /><property name="hdd" value="希捷" /><property name="ram" value="金士顿"/></bean><bean id="com2" class="com.moxuan.entity.Computer"><property name="mainBoard" value="华硕" /><property name="hdd" value="西部" /><property name="ram" value="金士顿"/></bean>
</beans>Programmer类中保留之前的代码,代码如下:
package com.moxuan.entity;import lombok.Data;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;@Component
@Data
public class Programmer {@Autowiredprivate Computer com1;private Computer com2;@Autowiredpublic void setCom2(Computer com2) {this.com2 = com2;}
}
测试方法如下:
/**
* 测试@Autowired
*/
@Test
public void test05(){AbstractApplicationContext context =new ClassPathXmlApplicationContext("application.xml");Programmer pro = context.getBean("programmer",Programmer.class);System.out.println("com1:"+pro.getCom1());System.out.println("com2:"+pro.getCom2());
}运行效果:

此时会发现,application.xml中配置的id为com1的bean 注入给了Programmer中com1属性。而com2的bean注入给了Programmer中的com2属性。不难看出,当有多个类型相同的bean时@Autowired会自动根据名称去匹配。
但是当没有匹配到名字相同的bean时,就会出错,比如下面,我们将配置文件中两个Bean的id分别修改为computer1和computer2,代码如下:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xmlns:context="http://www.springframework.org/schema/context"xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context https://www.springframework.org/schema/context/spring-context.xsd"><context:component-scan base-package="com.moxuan"></context:component-scan><bean id="computer1" class="com.moxuan.entity.Computer"><property name="mainBoard" value="技嘉" /><property name="hdd" value="希捷" /><property name="ram" value="金士顿"/></bean><bean id="computer2" class="com.moxuan.entity.Computer"><property name="mainBoard" value="华硕" /><property name="hdd" value="西部" /><property name="ram" value="金士顿"/></bean>
</beans>再次运行测试方法时,会出现下图问题:
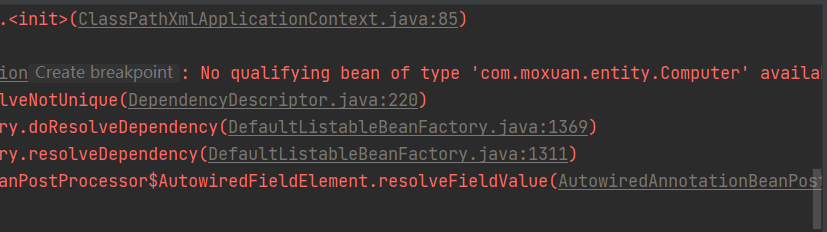
4.3. @Qualifier 注解
在前面的操作中,如果使用@Autowired 注解,会优先根据类型去匹配,如果存在多个类型相同的bean时,会根据名称去匹配,如果名称匹配不成功,就会报错。而@Qualifier 注解可以用来和@Autowired 进行配合,解决当属性名和bean中的id不同时注入错误的问题。
修改前面的Programmer类如下:
package com.moxuan.entity;import lombok.Data;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.stereotype.Component;@Component
@Data
public class Programmer {@Autowired@Qualifier("computer1")private Computer com1;private Computer com2;@Autowiredpublic void setCom2(@Qualifier("computer2") Computer com2) {this.com2 = com2;}
}运行测试方法,结果如下:
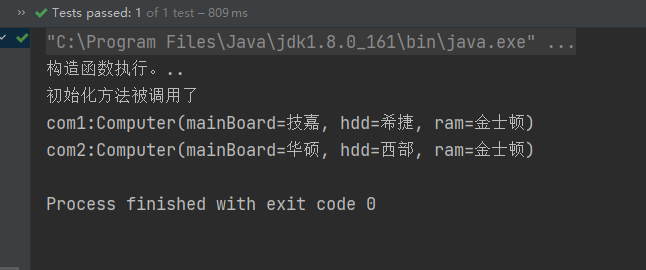
我们可以发现,这回也注入成功了。所以使用@Autowired 注入时,需要注入指定名称的Bean时,可以使用@Qualifier 去注入指定名称的Bean
总结:@Autowired 自动装配的流程如下图所示:
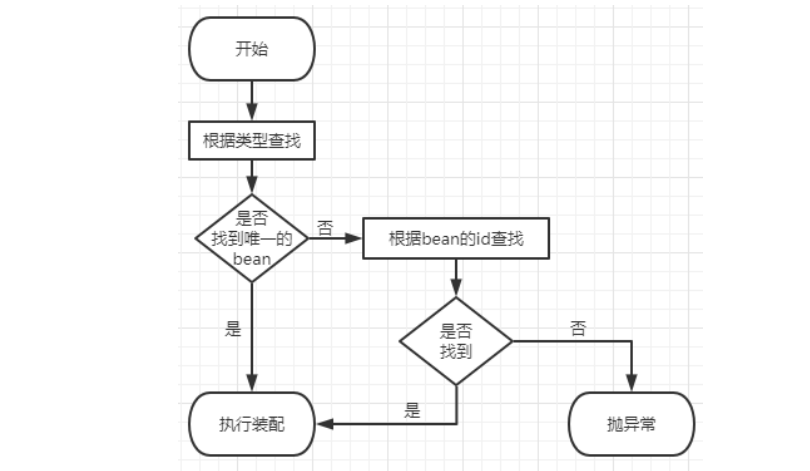
首先根据所需要的组件类型到IOC容器中查找
- 如果能够找到唯一的bean:直接执行装配
- 如果完全找不到匹配这个类型的bean:装配失败
如果匹配到的bean不止一个
- 没有@Qualifier注解:根据@Autowired标记位置成员变量的变量名作为bean的id进行匹配
- 如果能够找到:执行装配
- 如果找不到:装配失败
- 使用@Qualifier注解:根据@Qualifier注解中指定的名称作为bean的id进行匹配
- 能够找到:执行装配
- 找不到:装配失败
4.4. @Value注解
@Value 注解可以注入Spring表达式的值,使用方法步骤如下:
- 首先在项目resources目录中添加properties文件,比如:mysql.properties,内容如下:
driver=com.mysql.jdbc.Driver
url=jdbc:mysql:///moxuan
username=root
password=123456- 在application.xml配置中,引入mysql.properties文件
<util:properties location="classpath:mysql.properties" id="jdbc"></util:properties>- 添加MySQLUtils类,代码如下:
package com.moxuan.entity;import lombok.Data;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.stereotype.Component;@Component
@Data
public class MySQLUtils {@Value("#{jdbc.driver}")private String driver;@Value("#{jdbc.url}")private String url;@Value("#{jdbc.username}")private String user;@Value("#{jdbc.password}")private String password;
}
- 添加测试方法如下:
@Test
public void test06(){AbstractApplicationContext context =new ClassPathXmlApplicationContext("application.xml");MySQLUtils utils = context.getBean("mySQLUtils",MySQLUtils.class);System.out.println(utils);
}运行结果:

相关文章:
【SSM详细教程】-04-Spring基于注解的组件扫描
精品专题: 01.《C语言从不挂科到高绩点》课程详细笔记 https://blog.csdn.net/yueyehuguang/category_12753294.html?spm1001.2014.3001.5482https://blog.csdn.net/yueyehuguang/category_12753294.html?spm1001.2014.3001.5482 02. 《SpringBoot详细教程》课…...

Keepalived:构建高可用性的秘密武器
Keepalived:构建高可用性的秘密武器 在现代的IT环境中,高可用性是确保业务连续性和用户体验的关键要素。一旦系统出现故障或停机,企业可能会面临巨大的经济损失和声誉损害。因此,实施高可用性解决方案至关重要。Keepalived作为一…...

【C++刷题】力扣-#228-汇总区间
题目描述 给定一个整数数组 nums,返回所有唯一的区间,这些区间包含数组中的每个数字,形式为 [a, b],其中 a 和 b 是数字的最小和最大值。 示例 示例 1: 输入: nums [0,1,2,4,5,7] 输出: [["0,2"],["4,5"],…...

交通银行核心系统分布式实践
1、背景:客户需求和痛点 交通银行已有核心ECIF、贷记卡核心、借记卡新核心等数百套系统上线OceanBase分布式数据库。其中,贷记卡(俗称信用卡)属于 A类核心业务系统,支撑了信用卡授权、用卡、额度、账务等核心业务功能,约7千万卡量,日交易量和数据量都在千万级别。 交通银行…...

深入剖析:.Net8 引入非root用户运行的新特性提升应用安全性
在云原生的时代,容器化技术如Docker和Kubernetes已经成为现代软件开发的重要基石。随着.Net8的发布,微软进一步优化了这些环境的支持,特别是在提升容器应用安全性方面迈出了重要一步。本文将深入探讨.Net8中非根用户功能的新增特性࿰…...

多签机制简明理解及实例说明
目录 Multisignature机制简明理解及实例说明 Multisignature机制中的公钥、私钥、Nonce及签名验签详解 加密货币托管账户的多重签名机制 Multisignature机制简明理解及实例说明 一、基本概念 Multisignature(多重签名)机制是一种先进的加密技术,它允许一笔交易必须由多…...

PCL 点云配准 LM-ICP算法(精配准)
目录 一、概述 1.1原理 1.2实现步骤 1.3应用场景 二、代码实现 2.1关键函数 2.1.1 法线计算函数 2.1.2 执行 LM-ICP 函数 2.2完整代码 三、实现效果 PCL点云算法汇总及实战案例汇总的目录地址链接: PCL点云算法与项目实战案例汇总(长期更新&a…...

Mac 编译 Unreal 源码版本
在Mac上编译Unreal Engine源码需要遵循以下步骤: 安装必要的依赖项: Xcode Python(建议使用2.7版本) Java(使用JDK 8) CMake Ninja SVN(用于获取某些依赖项) 获取Unreal Engi…...

开源vGPU方案 HAMi实现细粒度GPU切分——筑梦之路
前言 为什么需要 GPU 共享、切分等方案? 在使用GPU的过程中我们会发现,直接在裸机环境使用,都可以多个进程共享 GPU,怎么到 k8s 环境就不行了? 1. 资源感知 在 k8s 中资源是和节点绑定的,对于 GPU 资源…...
性能测试工具JMeter
本次使用的博客系统的url: http://8.137.19.140:9090/blog_edit.html 1. JMeter介绍 环境要求:要求java,jdk版本大于8; Apache JMeter 是 Apache 组织基于 Java 开发的压⼒测试⼯具,⽤于对软件做性能测试;…...

Kubernetes ETCD的恢复与备份
在 Kubernetes 中,ETCD 扮演着至关重要的角色: 1. 集群状态存储 2. 服务发现 3. 配置管理 4. 分布式锁和协调 5. 故障恢复 ETCD 存储了 Kubernetes 集群中所有的状态信息,包括节点、Pod、Service、ConfigMap、Secrets 等。ETCD 支持服务发现…...

笔记整理—linux网络部分(2)Linux网络框架
前文说过,在OSI中将网络分为7层,这是理论上将其分为7层,但实际上可以将其分为4层。如TCP协议就是将其分为4层。理论只是提出一种指导意见,但不是行业范本。 驱动层只关系有没有接到包,不关心包经过多少次转发ÿ…...

深度学习500问——Chapter17:模型压缩及移动端部署(5)
文章目录 17.9.5 ShuffleNet- v1 17.9.6 ShuffleNet- v2 17.10 现有移动端开源框架及其特点 17.10.1 NCNN 17.10.2 QNNPACK 17.9.5 ShuffleNet- v1 ShuffleNet 是Face团队提出的,晚于MobileNet两个月在arXiv上公开《ShuffleNet: An Extremely Efficient…...

分布式ID多种生成方式
分布式ID 雪花算法(时间戳41机器编号10自增序列号10) 作用:希望ID按照时间进行有序生成 原理: 即一台带有编号的服务器在毫秒级时间戳内生成带有自增序号的ID,这个ID保证了自增性和唯一性 雪花算法根据结构的生成ID个数的上线时…...

时间序列预测(六)——循环神经网络(RNN)
目录 一、RNN的基本原理 1、正向传播(Forward Pass): 2、计算损失(Loss Calculation) 3、反向传播——反向传播通过时间(Backpropagation Through Time,BPTT) 4、梯度更新&…...

Day2算法
Day2算法 1.算法的基本概念 算法: 对特定问题求解步骤的一种描述,他叔指令的有限序列,其中的每条指令表示一个或多个操作。 算法的特性: 1.有穷性: 一个算法必须总在执行有穷步之后结束,且每一步都可…...

智洋创新嵌入式面试题汇总及参考答案
堆和栈有什么区别 内存分配方式 栈由编译器自动分配和释放,函数执行时,函数内局部变量等会在栈上分配空间,函数执行结束后自动回收。例如在一个简单的函数int add(int a, int b)中,参数a和b以及函数内部的一些临时变量都会在栈上分配空间,函数调用结束后这些空间就会被释放…...
)
无线网卡知识的学习-- wireless基础知识(nl80211)
1. 基本概念 mac80211 :这是最底层的模块,与hardware offloading 关联最多。 mac80211 的工作是给出硬件的所有功能与硬件进行交互。(Kernel态) cfg80211:是设备和用户之间的桥梁,cfg80211的工作则是观察跟踪wlan设备的实际状态. (Kernel态) nl80211: 介于用户空间与内核…...

除了 Python,还有哪些语言适合做爬虫?
以下几种语言也适合做爬虫: 一、Java* 优势: 强大的性能和稳定性:Java 运行在 Java 虚拟机(JVM)上,具有良好的跨平台性和出色的内存管理机制,能够处理大规模的并发请求和数据抓取任务&#x…...

JS | JS中类的 prototype 属性和__proto__属性
大多数浏览器的 ES5 实现之中,每一个对象都有__proto__属性,指向对应的构造函数的prototype属性。Class 作为构造函数的语法糖,同时有prototype属性和__proto__属性,因此同时存在两条继承链。 构造函数的子类有prototype属性。 …...

IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程
IPFS去中心化存储实战指南:黑马程序员音乐播放器项目开发完整教程 【免费下载链接】BlockChain 黑马程序员 120天全栈区块链开发 开源教程 项目地址: https://gitcode.com/gh_mirrors/blockchain95/BlockChain 你是否想过如何构建一个真正去中心化的音乐播放…...

如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了
如何用deberta-v3-base-zeroshot-v2.0构建企业级NLP应用?完整教程来了 【免费下载链接】deberta-v3-base-zeroshot-v2.0 项目地址: https://ai.gitcode.com/hf_mirrors/NingBo_Ascend/deberta-v3-base-zeroshot-v2.0 deberta-v3-base-zeroshot-v2.0是一款基…...

除了ulimit -c unlimited:深入理解Linux core dump机制与高级配置指南
深入Linux核心转储:从基础配置到生产环境实战指南当服务器上的关键应用突然崩溃时,系统管理员最需要的就是一份完整的"事故现场记录"。Linux的core dump机制正是为此而生,它能保存程序崩溃时的内存状态、寄存器值和调用堆栈&#x…...

Unity安卓构建72小时实战指南:从零到真机运行
1. 这不是“又一本Unity教程”,而是我带三个新人从零上线第一款安卓游戏的真实路径你点开这个标题,大概率正站在两个路口之间:一边是满屏“30天速成Unity”“零基础做爆款”的短视频封面,一边是你刚下载完Unity Hub、卡在Android …...

内网环境下Win7系统批量离线补丁部署实战指南
1. 内网Win7补丁部署的挑战与解决方案老旧Win7系统在内网环境中的安全隐患就像漏雨的屋顶,看似不影响日常使用,但随时可能引发严重后果。我经手过几十家单位的系统加固项目,发现这些场景存在三个典型痛点:首先是补丁来源问题&…...
)
别再只测accuracy!DeepSeek集成测试必须监控的5个隐性指标(P99首token延迟、context bleed率、tool-call schema漂移)
更多请点击: https://intelliparadigm.com 第一章:DeepSeek集成测试的核心范式演进 DeepSeek大模型的工程化落地对集成测试提出了全新挑战:传统基于接口响应码与字段校验的测试范式已难以覆盖语义一致性、推理链鲁棒性、上下文敏感度等高阶质…...

开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣?
开源 AI Agent Harness Engineering 框架全览:LangChain, AutoGPT, CrewAI 孰优孰劣? 关键词 AI Agent Harness Engineering、大语言模型编排(LLM Orchestration)、LangChain、AutoGPT、CrewAI、工具调用(Tool Calling)、多Agent协作、自主任务规划 摘要 随着大语言模型…...

5个必知的Universal-Updater高级功能:从QR扫描到后台安装
5个必知的Universal-Updater高级功能:从QR扫描到后台安装 【免费下载链接】Universal-Updater An easy to use app for installing and updating 3DS homebrew 项目地址: https://gitcode.com/gh_mirrors/un/Universal-Updater Universal-Updater是一款专为任…...

【数据结构与算法】数据结构基础——栈和队列
目录栈和队列1. 栈1.1 栈的概念1.2 栈的实现方式分析1.3 栈的实现1.3.1 栈的初始化与销毁1.3.2 入栈与出栈1.3.3 栈的判空与有效元素个数1.3.4 栈顶元素1.4 栈的扩展1.4.1 两栈共享空间2. 队列2.1 队列的概念2.2 队列的实现方式分析2.3 队列的实现2.3.1 队列的初始化与销毁2.3.…...
)
GIS工程应用记录(AI辅助编程)
问题的问题:语境坍缩“从各个角度提出问题,AI做出对应积极答复和修改,结果没有什么变化。”这,就是元问题最核心的症状。你尝试了所有你已知的“高级”协作手段,但就像重拳打在棉花上,AI永远在积极回应&…...